云原生大数据计算服务MaxCompute
阿里云云原生大数据计算服务MaxCompute是面向分析的企业级云数仓,作为一体化大数据智能计算平台ODPS的大规模批量计算引擎,MaxCompute以 Serverless 架构提供快速、全托管的在线数据仓库服务,使您经济高效的分析处理海量数据,进行敏捷的业务洞察。
相反,如果完全基于开源的Hadoop框架,从服务部署、可视化开发、代码管理、任务调度、集群运维等多方面,均需要大量的人力来开发与维护。基于阿里云MaxCompute,不论是人力成本,还是计算成本,还是运维成本,都降到了最低.联合创始人 徐佳义.随着业务量的增长,在原有的自建集群上,出现了海量数据处理效率下降,离线数据...
来自:
云产品
EMR HBase on OSS存算分离集群快速恢复
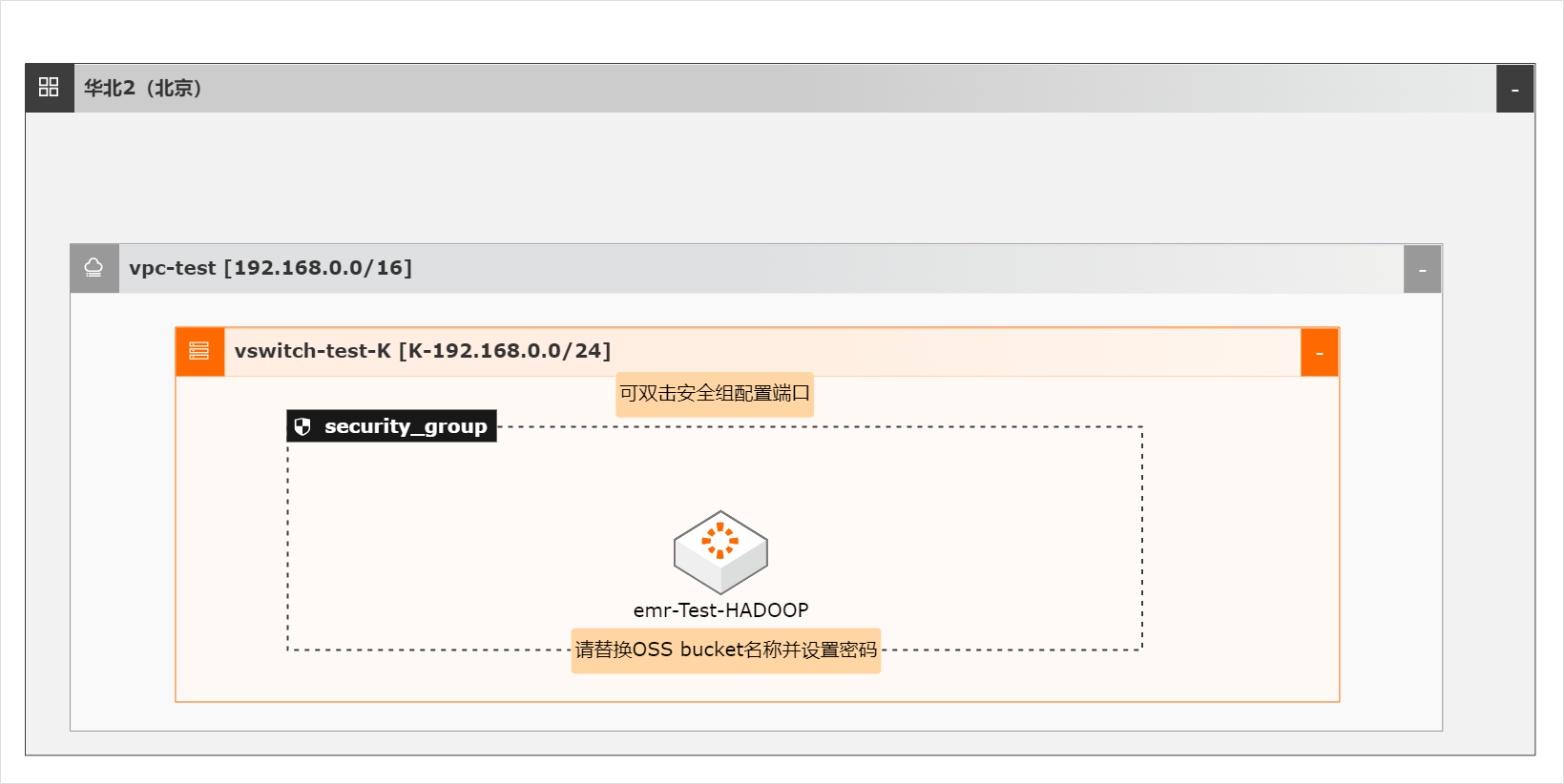
OSS-HDFS服务(JindoFS服务)是一款云原生数据湖存储产品。基于统一的元数据管理能力,在完全兼容HDFS文件系统接口的同时,提供充分的POSIX能力支持,能更好地满足大数据和AI等领域的数据湖计算场景。
目前基于 Core Node扩容 HBase计算时会同步扩容 HDFS,但是本文中的 HDFS 集群本身只用于存储 WAL(Write Ahead Log),需要的存储空间较少,所以实际是能够通过计 算需求而非存储需求来调整 EMR集群大小,同时 OSS作为 云存储服务,扩容操作也比较简单。最佳实践频道 阿里云最佳实践分享群 阿里云 EMR HBase on OSS存算...
MaxCompute湖仓一体方案
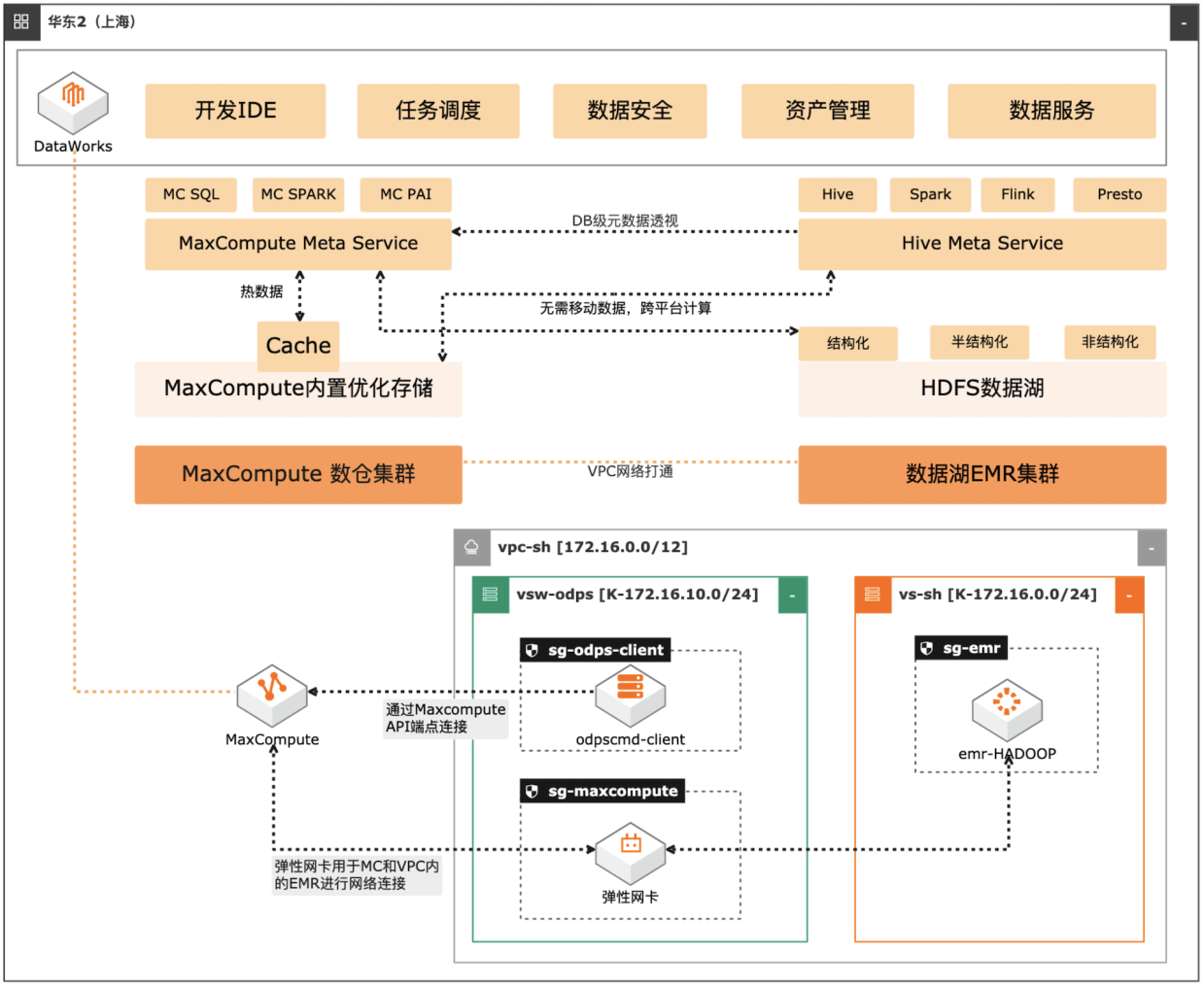
场景描述 自建数据湖与云数仓的融合解决方案,将 MaxCompute与自建的Hive集群做数据打 通,通过存储共享,元数据镜像等方式,解 决传统模式下的存储冗余,计算资源弹性能 力弱的痛点。可大幅度增强系统的资源弹 性,解决业务高峰期计算资源不足的问题。 方案优势 1.业务无侵入性:现有业务无需改造。 2.性能优化:MaxCompute在SQL上做 了大量优化与能力沉淀,可提高SQL 运行性能,降低计算成本。 3.灵活管理:元数据实时同步,无需额外 管理数据同步任务。 4.资源弹性:利用MaxCompute计算池 弹性进行海量数据计算。 解决问题 1.增强业务高峰期的资源弹性。 2.优化自建数据湖的数据治理能力。 3.减少跨平台数据处理的存储冗余。 产品列表 专有网络VPC 云服务器ECS 访问控制RAM 运维编排OOS MaxCompute(原ODPS) 云企业网CEN
Apache Hive:Apache Hive是基于 Hadoop的一个数据仓库工具,可以将结构化 的数据文件映射为一张数据库表,并提供简单的 SQL查询功能,可以将 SQL语 句转换为 MapReduce任务进行运行。其优点是学习成本低,可以通过类 SQL语 句快速实现简单的 MapReduce统计,不必开发专门的 MapReduce应用,十分适 合数据仓库的统计分析。...
云消息队列 Kafka 版
云消息队列 Kafka 版是阿里云基于Apache Kafka构建的大数据消息中间件,广泛用于日志收集和分析、数据处理等场景。可提供全托管服务,用户无需部署运维,更专业、更可靠、更安全。
支持实时在线分析系统和类似于Hadoop之类的离线分析系统;淘宝、天猫平台等公司每天都会产生大量的日志。Kafka 性能高效,同时 Kafka 的特性决定它非常适合作为\\.网站所有用户产生的行为信息极为庞大,需要非常高的吞吐量来支持;可对接 Storm/Spark 实时流计算引擎,亦可对接 Hadoop/ODPS 等离线数据仓库系统;高吞吐,...
来自:
云产品
Spark on ECI大数据分析

场景描述 方案优势 1.计算引擎弹性扩缩容,兼顾资源弹性与计 算资源成本优化。 2.计算与存储分离架构,结合阿里云原生云 存储产品,海量数据湖优势。 3.Kubernetes原生的调度性能优势,提升在 大规模分析作业时的分析性能优势分。 4.集群资源隔离和按需分配。 解决问题 1.计算资源弹性能力不足,计算资源成本管 控能力欠缺. 2.集群资源调度能力和隔离能力不足。 3.计算与存储无法分离,大数据量分析时出 现数据存储资源瓶颈。 4.Spark submit方式提交分析作业参数支持 有限等缺点。 产品列表 容器服务Kubernetes版(ACK) 弹性容器实例(ECI) 文件存储HDFS 对象存储OSS 专有网络VPC 容器镜像服务ACR
Spark on Yarn能够带来的优势,然后通过 Spark on ACK+ECI的方案来说明该方案能够在资 源弹性和成本方面,是客户应用 Spark on Kubernetes架构场景最值得推荐的方案架 构。3.1.Spark on ACK方案 步骤1 通过 kubectl远程连接集群。如何通过 kubectl连接集群可以参考阿里云 ACK控制台-集群基本信息的如下说明,过 程不再赘述...
多账号下企业分账
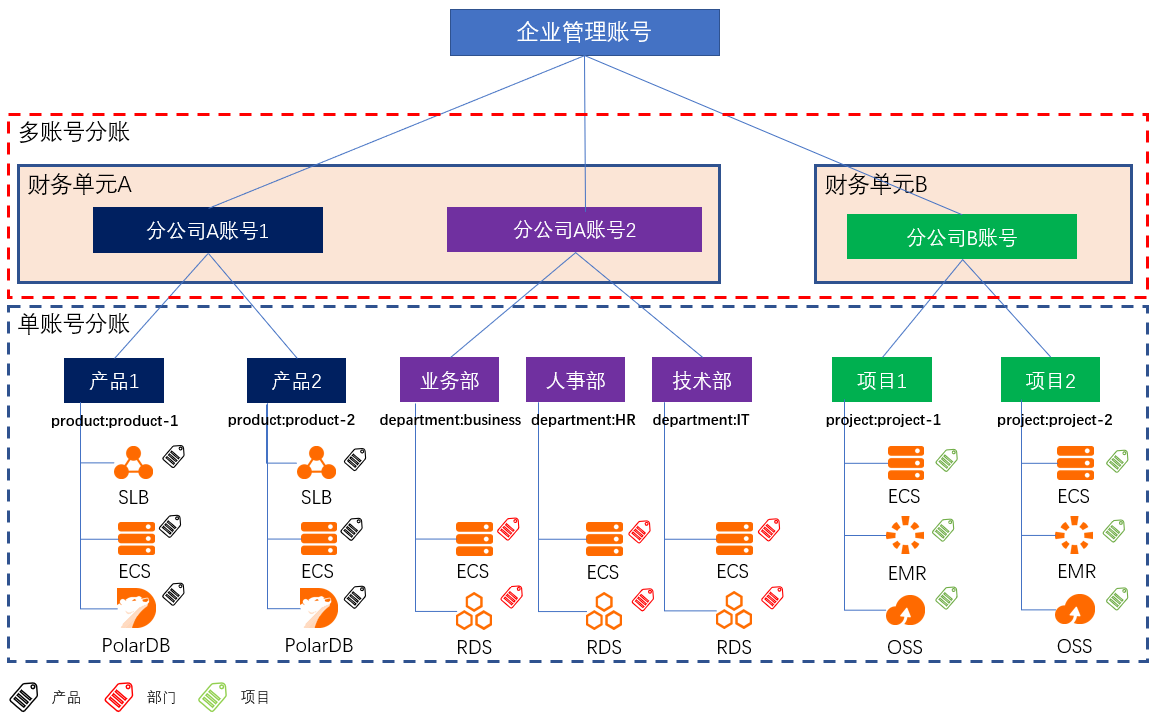
场景描述 财务分账,是根据企业的成本中心,将云上资源的成本划分到给各个项目组/业务部门;助力企业快速梳理云上成本结构,搭建复杂组织架构下的成本关系,便捷地进行财务和云上成本的管理。 大型企业或集团公司,由于组织架构复杂,业务复杂等原因,通常拥有多个阿里云账号来管理规模庞大的云上资源。针对云上资源,如何建立有效的分账方案,是财务关注的重要问题。 解决问题 解决CIO/CTO最关心的云上IT治理,IT成本核算等问题。 弄清楚企业内各部门成本及云上IT成本结构。 让CIO/CTO准确地掌握云上资源成本情况,清楚业务与成本的关系。 让采购/运维轻松搞定每月的IT成本汇报。
基 于阿里云分布式文件系统和 SSD盘高性能存储,RDS支持 MySQL、SQL Server、PostgreSQL、PPAS(Postgre Plus Advanced Server,高度兼容 Oracle数据库)和 MariaDB TX引擎,并且提供了容灾、备份、恢复、监控、迁移等方面的全套解 决方案。详见:https://www.aliyun.com/product/rds/mysql 负载均衡 SLB:阿里云提供全托管...
数据湖-在线学习场景数据分析

场景描述 本场景以在线教育中一个答题闯关类的应用为 例,使用WebServer来模拟演示这类日志数据 的分析处理。通过Nginx和Pythonflask搭建 WebServer,模拟应用中的关键页面,比如登 录、课程内容等,之后构造若干用户使用的模拟 日志数据,投递到数据湖进行分析后获取应用 PV、UV、课程内容访问排行、平均得分等等。 解决问题 基于数据湖(EMR+OSS)搭建大数据平台。 EMR和OSS使用和配置。 数据统一存储到OSS。 产品列表 E-MapReduce 对象存储OSS 云服务器ECS 访问控制RAM 专有网络VPC
借助EMR 可以简单快速的构建一个基于 Hadoop,Spark,Hive等大数据产品的计算集群,而且可以按需使用,其所有 Job完 文档版本:20200331 5数据湖-在线学习场景数据分析 数据湖 成之后,销毁集群,因为所有的数据都保存在OSS。此外,对于Hadoop集群上的任务,不同类型的任务对于机器配置的要求不同,比如 推荐和算法业务可能...
云存储解决方案
云存储解决方案面向大数据存储、多媒体存储(视频存储)、视频监控、基因生命科学、数据迁移、自动驾驶、在线教育、混合云存储、数据迁移、数据容灾备份等多个行业用户的多元化场景,提供更安全稳定、更优化、无缝上云的智能数据存储服务,为企业上云、实现数字化转型奠定数据基础。
基于多副本分布式技术,提供99.9999999%数据持久性.集成了阿里云云存储网关的企业级统一存储阵列.是一种预付费存储售卖形态,可抵扣按量付费账单.主要满足海量结构化数据的存储需求.为企业关键业务提供容灾服务,保障业务连性.提供实时数据的采集/清洗/分析/可视化服务.标题-copy-copy-copy-copy-copy.存储新人入门,存储...
来自:
解决方案
表格存储Tablestore
表格存储Tablestore是阿里云自研的面向海量结构化数据存储的Serverless分布式数据库,它可提供低成本、高性能的存储方案,同时也可提供稳定与极致的数据服务。
批计算支持MaxCompute以及EMR Hadoop/Spark/Hive等各类开源组件访问。实时计算支持阿里云流计算、函数计算等.接入数据集成,支持全量、增量数据通道.无缝对接数据湖OSS.支持数据实时投递数据湖OSS,按照列存方式存储。更高效支持海量数据计算.完善的大数据计算体系.支持多种大数据计算框架,打通在线存储、离线计算和实时...
来自:
云产品
云原生数据仓库AnalyticDB MySQL数据仓库
阿里云云原生数据仓库AnalyticDB MySQL版(简称AnalyticDB)是融合数据库、大数据技术于一体的云原生企业级数据仓库平台。云原生数据仓库AnalyticDB MySQL版支持数据实时写入和同步更新、实时计算和实时服务,可用于构建企业级报表系统、数据仓库和数据服务引擎。
查看数据全部产品.AnalyticDB MySQL是基于湖仓一体架构打造的实时湖仓,高度兼容MySQL,毫秒级更新,亚秒级查询。不论在数据湖中的非结构化/半结构化数据,还是在数据库中的结构化数据,都可使用AnalyticDB MySQL同时完成高吞吐离线处理和高性能在线分析,真正做到数据湖的规模,数据库的体验。帮助企业构建数据分析平台,...
来自:
云产品
云消息队列 RocketMQ 版
云消息队列 RocketMQ 版是基于 Apache RocketMQ 构建的分布式消息中间件,广泛用于异步解耦、削峰填谷等场景。可支撑千万级并发、万亿级数据洪峰,更稳定,更安全。
产品动态时间线组件.57A_【标题】文档与工具-copy.RocketMQ 在业务消息场景的优势详解.RocketMQ 5.0 架构解析:如何基于云原生架构支撑多元化场景.RocketMQ 5.0 无状态实时性消费详解.解读 RocketMQ 5.0 全新的高可用设计.从互联网到云时代,Apache RocketMQ 是如何演进的?RocketMQ 的消费者类型详解与最佳实践.RocketMQ ...
来自:
云产品
EMR本地盘实例大规模数据集测试
场景描述 阿里云为了满足大数据场景下的存储需求,在云 上推出了本地盘D1机型,这个系列提供了本地 盘而非云盘作为存储,提高了磁盘的吞吐能力, 发挥Hadoop的就近计算优势。阿里云EMR 产品针对本地盘机型,推出了一整套的自动化运 维方案,帮助用户方便可靠地使用本地盘机型, 不需要关注整个运维过程同时数据的高可靠和 服务的高可用。 解决问题 1.云盘多份冗余数据导致成本高 2.磁盘吞吐量不高 3.节点的高可靠分布问题 4.本地盘与节点的故障监控问题 5.数据迁移时自动决策问题 6.自动故障节点迁移与数据平衡问题 产品列表 EMR(E-MapReduce) 本地盘 VPC
EMR本地盘实例大规模数据集测试 最佳实践 方案架构 场景描述 阿里云为了满足大数据场景下的存储需求,在 云上推出了本地盘 D1机型,这个系列提供了 本地盘而非云盘作为存储,提高了磁盘的吞吐 能力,发挥 Hadoop的就近计算优势。阿里 云 EMR产品针对本地盘机型,推出了一整套 的自动化运维方案,帮助用户方便可靠地使用 ...
CDH迁移升级CDP最佳实践
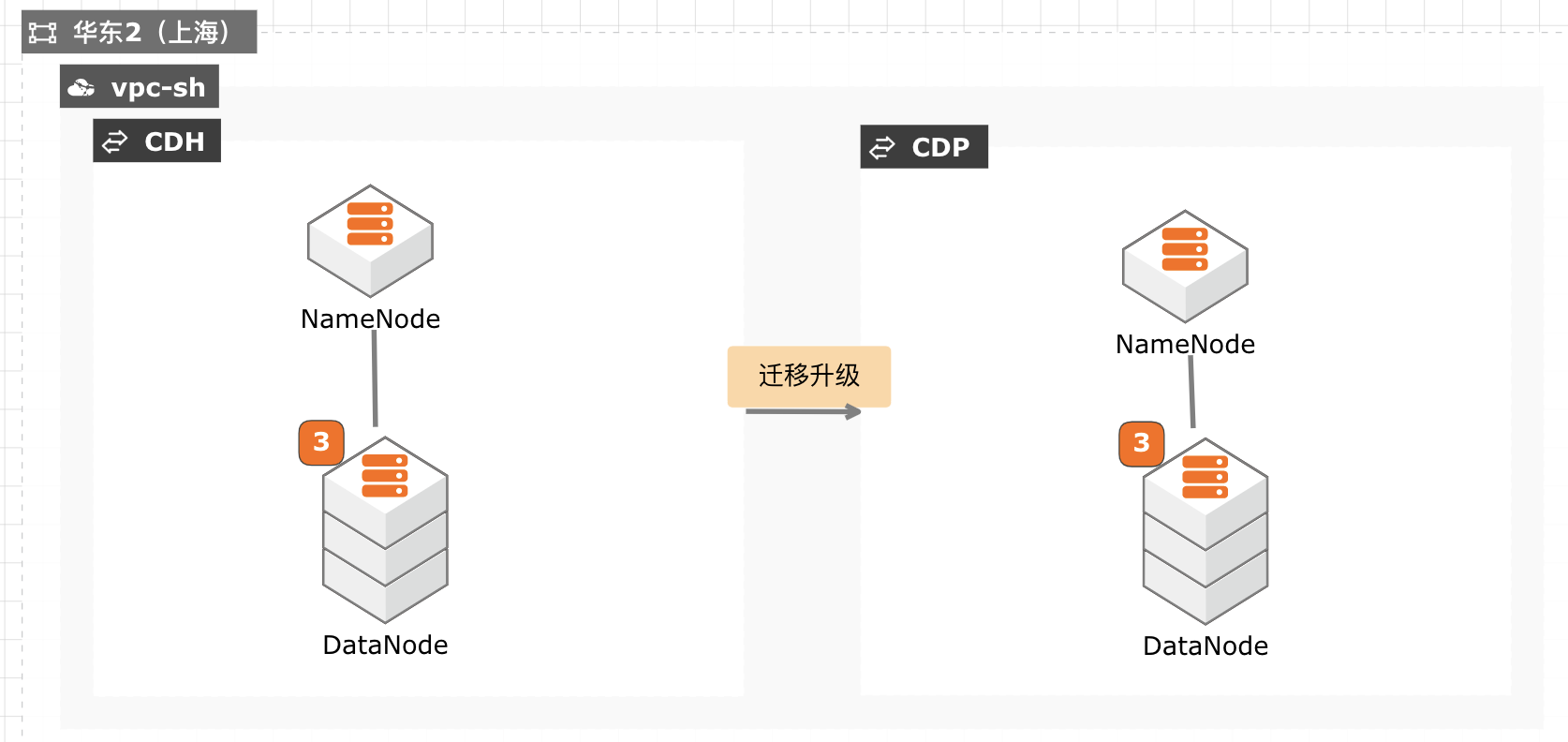
当前 CDH 免费版停止下载,终止服务,针对需要企业版服务能力并且CDH 升级过程对业务影响较小的客户,通过安装新的 CDP 集群,将现有数据拷贝至新集群,然后将新集群切换为生产集群,升级过程没有数据丢失风险,停机时间较短,适合大部分互联网客户升级使用。
适用场景 较短的停服时间升级 CDH至 CDP CDH的数据迁移至 CDP CDH组件升级至最新的 CDP组件 技术架构 本实践方案基于如下图所示的技术架构和主要流程编写操作步骤:迁移实施流程如下:文档版本:20211029 1 CDH迁移升级 CDP最佳实践 最佳实践概述 方案优势 没有数据丢失风险 较短的服务停机时间 文档版本:20211029 2 CDH...
混合云容灾HDR
阿里云混合云容灾HDR是为数据中心提供企业级应用的本地备份与云上容灾一体化服务。无需自建灾备中心、云下部署简单、云上资源全自动管理、控制台集中管控等。可提供低至秒级RPO和分钟级RTO的容灾服务,有效保障客户数据安全和业务连续性,相对自建灾备中心的方案,最多可节约高达 80% 的费用。
为了对智能制造的趋势以及数字化的全面转型,康斯特基于专业的技术与服务能力,与阿里云合作,经过深入交流沟通后,根据康斯特自身的业务和数据的特性,最终采用了全能备份型灾备解决方案,实现本地到云端的混合云架构部.阿里云混合云存储满足数据在本地数据中心和公共云之间的无缝流动。利用云端存储高可靠性,将医院海量...
来自:
云产品
- 产品推荐
- 这些文档可能帮助您