开源大数据平台 E-MapReduce 技术解决方案
阿里云开源大数据平台 E-MapReduce 技术解决方案,帮助您快速了解如何利用这款弹性伸缩、存算分离的企业级大数据平台服务来提升业务效率,降低成本。
计算与存储解耦合提供更灵活的系统架构设计,让计算、存储资源具备更好的可扩展性,对 Hadoop 生态体系有良好的支持能力,通过细粒度的权限控制、数据加密和日志记录与审计等机制保障数据安全。应用场景基于开源生态构建大数据分析支撑 Hadoop 开源生态构建大数据分析方案,解决了传统 Hadoop 在扩展性、运维模式、成本优化...
来自:
云产品
开源大数据平台 E-MapReduce 相关资源
阿里云大数据平台 E-MapReduce 提供详细的产品文档,面向开发者提供全方位的服务,有免费的实验课程和解决方案体验馆,帮助您快速上手。在阿里云 E-MapReduce 开发者社区,您可以和更多开发者交流。
查看详情前往帮助文档社区内容甄选基于EMR Serverless StarRocks一键玩转世界杯基于EMR离线数据分析数据湖构建DLF快速入门技术交流内容分类:博文问答电子书阿里云 EMR Serverless StarRocks OLAP 数据分析场景解析 阿里云 E-MapReduce Serverless StarRocks 版是阿里云提供的 Serverless StarRocks 全托管服务,提供高性能...
来自:
云产品
开源大数据平台 E-MapReduce 产品功能
阿里云开源大数据平台 E-MapReduce 为客户提供简单易集成的Hadoop、Hive、Spark、StarRocks、Flink、Presto、ClickHouse等开源大数据计算和存储引擎。EMR计算资源支持灵活的弹性控制。EMR支持on ECS、on ACK以及Serverless多种部署形态。
倚天ARM架构 EMR on ECS支持倚天架构,基于自研芯片倚天710,软硬协同,性价比提升40%以上。可视化弹性成本分析多维度了解集群资源使用量及成本分布,评估集群弹性成本节省效果,优化集群资源利用监控诊断集群监控提供丰富的服务监控指标和主机监控指标展示,通过可视化的方式快速定位服务和主机异常。事件中心EMR服务提供...
来自:
云产品
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。
业务架构基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测 最佳实践概述 方案架构 方案优势 兼顾数据湖的灵活性和云数据仓库的成长性 MaxCompute与EMR集群通过PrivateAccess网络连通,低延迟高带宽。数据湖中的Hive元数据映射为MaxCompute的外部项目,元数据由DLF统一管理,无需人 工干预。基于DataWorks强大的数据开发/...
开源大数据平台 E-MapReduce 产品概述
开源大数据平台 E-MapReduce是阿里云提供的云原生开源大数据平台,支持多种主流开源大数据组件,具备灵活弹性的资源调度和控制能力。适用于PB 级数据处理、交互分析和机器学习,帮助客户高效构建云端企业级数据湖技术架构。
EMR on ECSE-MapReduce Serverless StarRocks 版了解更多02猿辅导为了应对不同的业务场景,我们希望能够有一个引擎,可以完成在 AP 场景下的统一,这时就发现了 StarRocks,StarRocks 借助于它本身优秀的向量化引擎的能力,能够在大部分场景下性能提升显著,因此我们决定将更多的场景基于 StarRocks 来做。猿辅导大数据平台...
来自:
云产品
自建Hadoop迁移到阿里云EMR
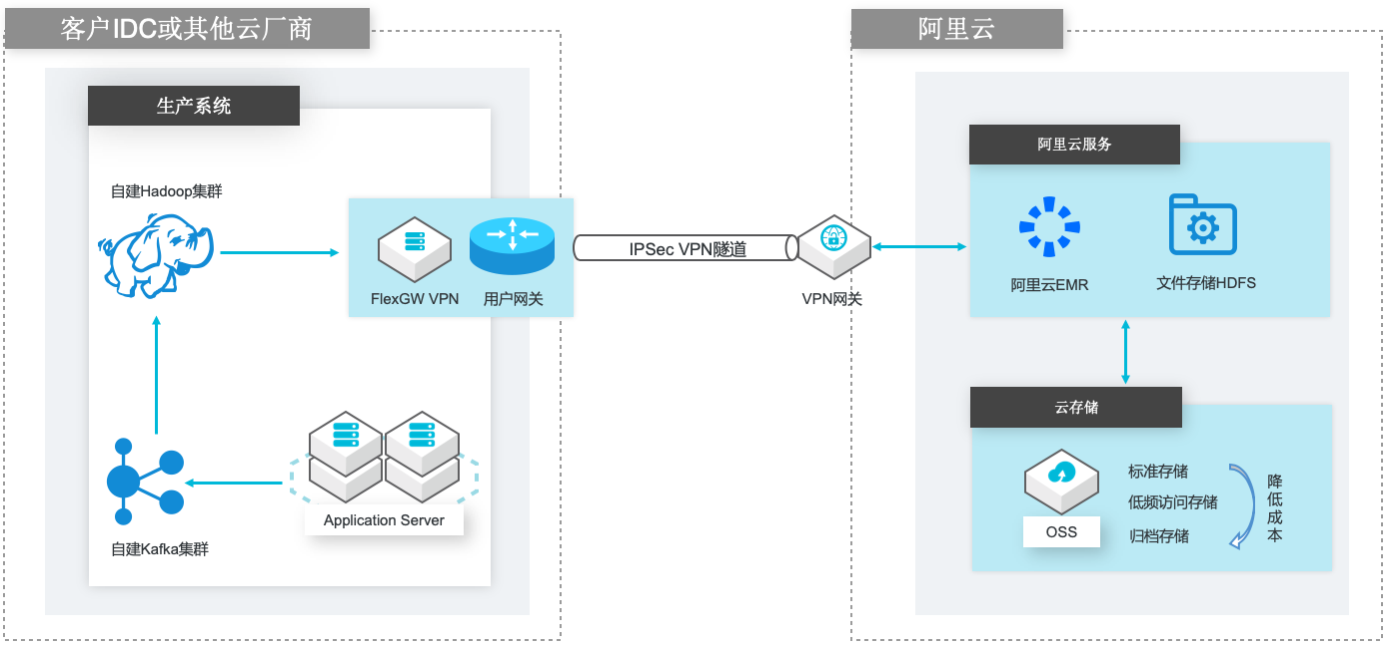
场景描述 场景1:自建Hadoop集群数据(HDFS)迁移到 阿里云EMR集群的HDFS文件系统; 场景2:自建Hadoop集群数据(HDFS)迁移到 计算存储分离架构的阿里云EMR集群,以OSS 和JindoFS作为EMR集群的后端存储。 解决的问题 客户自建Hadoop迁移到阿里云EMR集群的 技术方案; 基于IPSecVPN隧道构建安全和低成本数据 传输链路 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
场景2:自建 Hadoop集群数据(HDFS)迁移到计 基于 IPSec VPN隧道构建安全和低成本数据 算存储分离架构的阿里云 EMR集群,以 OSS 和 传输链路 JindoFS作为 EMR集群的后端存储。产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。文档模板(手册名称)/Error!Use the Home tab to apply 云服务器 ECS(产品名称)标题 to the ...
自建Hadoop迁移MaxCompute
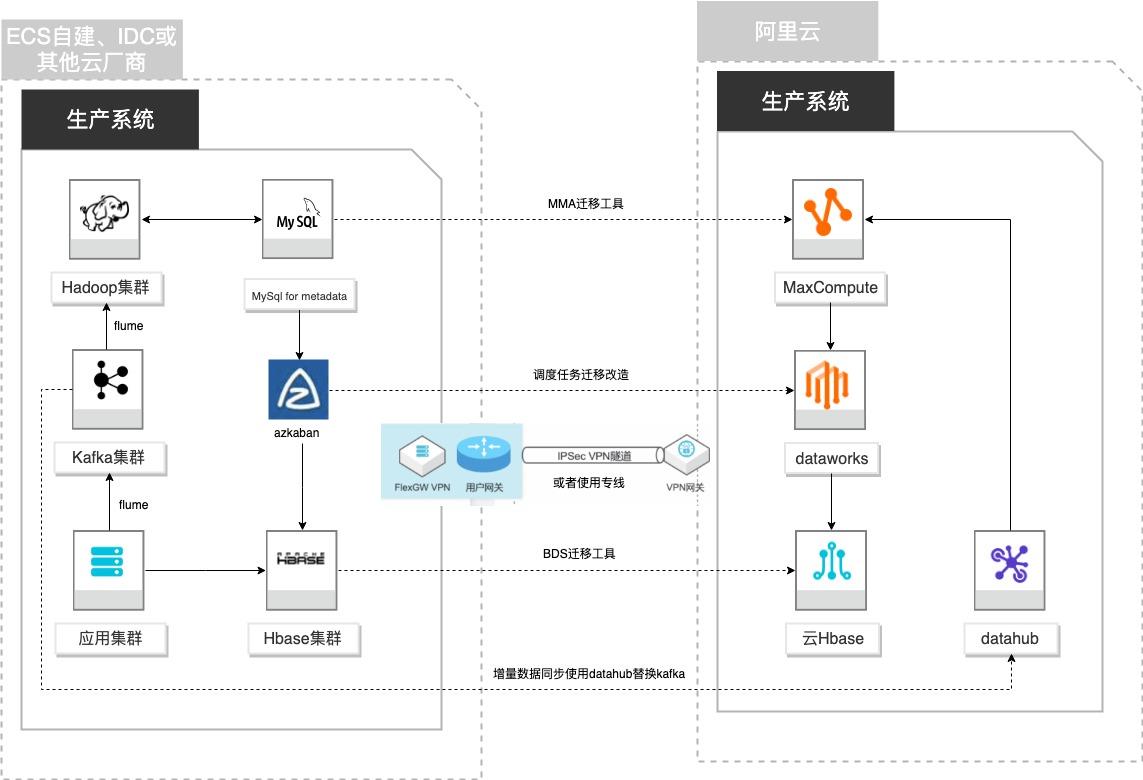
场景描述 客户基于ECS、IDC自建或在友商云平台自建了大数 据集群,为了降低企业大数据计算平台的成本,提高 大数据应用开发效率,更有效保障数据安全,把大数 据集群的数据、作业、调度任务以及业务数据库整体 迁移到MaxCompute和其他云产品。 解决的问题 自建Hadoop集群搬迁到MaxCompute 自建Hbase集群搬迁到云Hbase 自建Kafka或应用数据准实时同步到 MaxCompute 自建Azkaban任务迁移到Dataworks任务 产品列表 MaxCompute,Dataworks、云数据库Hbase版、Datahub、VPC,ECS。
适用场景 自建 Hadoop集群搬迁到 MaxCompute 自建 Hbase集群搬迁到云 Hbase 自建 Kafka或服务器数据实时同步到 MaxCompute 自建 Azkaban搬迁到 Dataworks 技术架构 本实践方案基于如下图所示的技术架构和主要流程编写操作步骤:文档版本:20210723 1 自建Hadoop迁移MaxCompute 最佳实践概述 方案优势 安全性:基于 IPSec ...
中小企业自建Hadoop集群上云解决方案
中小企业自建 Hadoop 集群上云解决方案,助力自建 Hadoop 用户快速构建云上半托管开源大数据平台,在保持原组件使用习惯延续的同时,充分利用云上服务特点,更加便捷地迭代企业大数据平台架构,聚焦业务价值开发。
基于阿里云 E-MapReduce、OSS、边缘网络加速等产品及服务,帮助自建 Hadoop 用户快速构建云上半托管开源大数据平台,在保持原自建 Hadoop 组件使用习惯延续的同时,充分利用云上服务特点,更加便捷地迭代企业大数据平台架构,聚焦业务价值开发.谢赟辉,靖鑫,也树.中小企业自建Hadoop集群上云解决方案.本方案核心产品延续开源...
来自:
解决方案
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
基于 DataWorks的大数据一站式开发及数据治理 最佳实践 业务架构 场景描述 解决问题 本实践基于 Dataworks做大数据一站式开发,包含 日志采集、处理及分析 数据实时采集到 kafka 通过实时计算对数据进行 日志使用 Flink实时写入 HDFS ETL写入 HDFS,使用 Hive进行数据分析。通过 日志数据实时 ETL Dataworks进行数据治理,...
湖仓一体架构EMR元数据迁移DLF
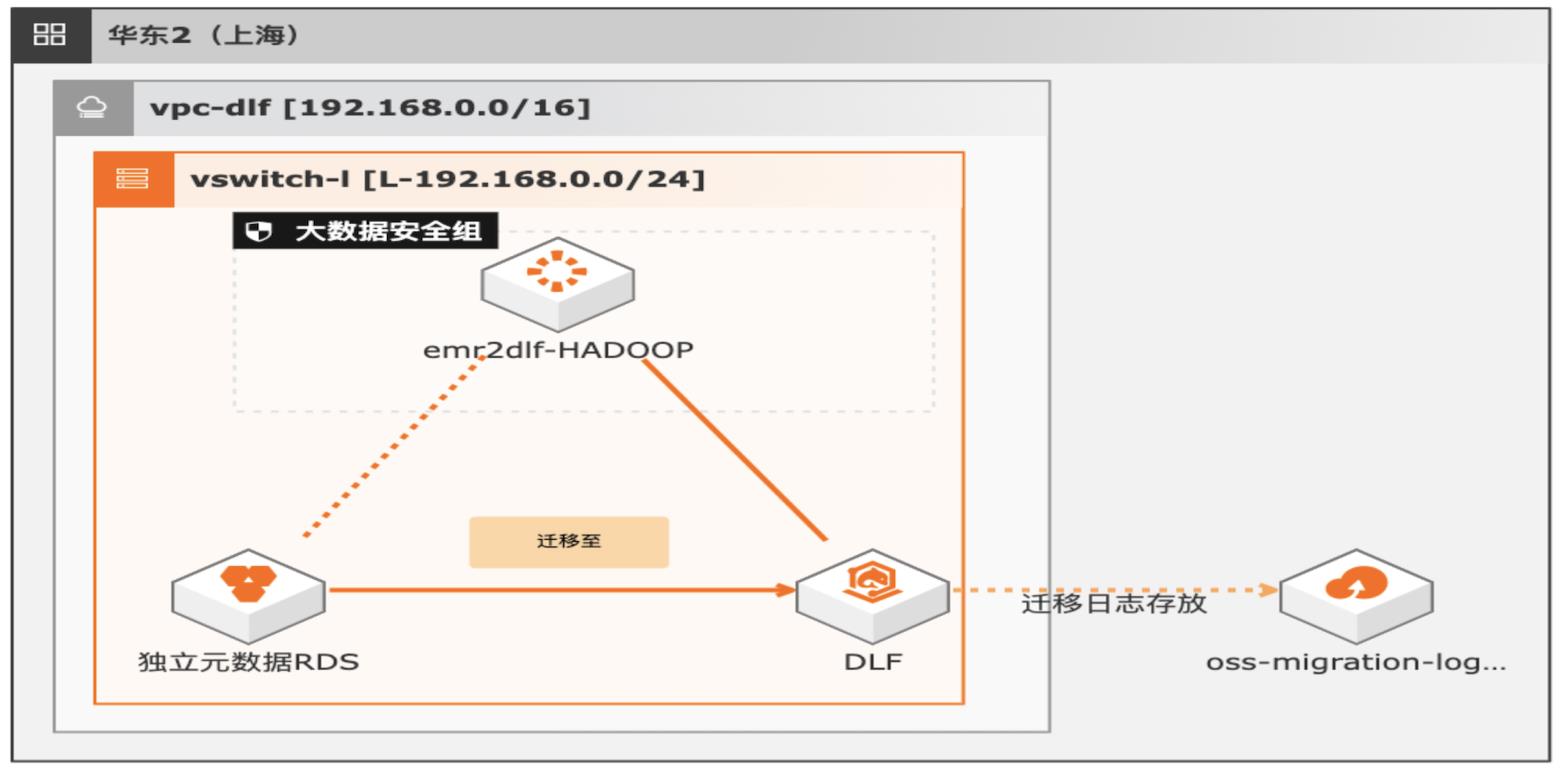
通过EMR+DLF数据湖方案,可以为企业提供数据湖内的统一的元数据管理,统一的权限管理,支持多源数据入湖以及一站式数据探索的能力。本方案支持已有EMR集群元数据库使用RDS或内置MySQL数据库迁移DLF,通过统一的元数据管理,多种数据源入湖,搭建高效的数据湖解决方案。
数据湖构建(Data Lake Formation,DLF)作为云原生数据湖架构核心组成部分,帮助用户简单快速地构 建云原生数据湖解决方案。数据湖构建提供湖上元数据统一管理、企业级权限控 制,并无缝对接多种计算引擎,打破数据孤岛,洞察业务价值。(https://www.aliyun.com/product/bigdata/dlf)云速搭 CADT:是一款为上云应用提供...
基于弹性供应组构建大数据分析集群
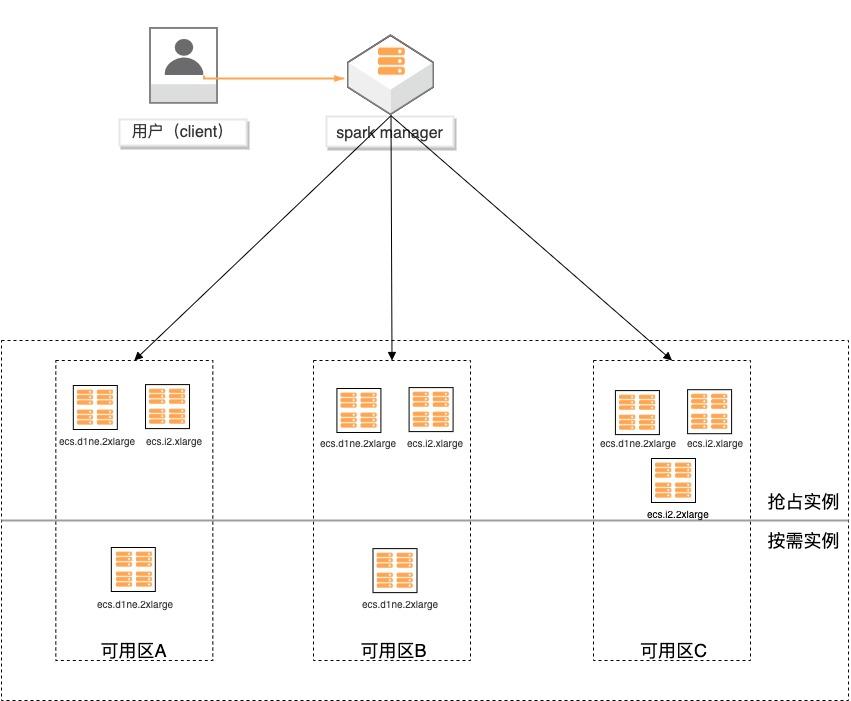
场景描述 基于弹性供应组(APG)搭建spark计算集 群,提供一键开启跨售卖方式、跨可用区、 跨实例规格的计算集群交付模式的实践。 方案优势 1.超低成本:跨售卖方式提供计算实 例,按秒计费,可全部使用spot实例 交付,最高可省90%成本。 2.稳定可靠:跨可用域、跨实例规格, 降低spot被集体释放的风险;自动托 管,分钟级巡检,动态保证集群的算 力。 3.快速交付:单次可在5分钟内交付 2000个实例。 4.多策略组合:可分别指定spot和按量 实例的交付策略,以及差额补足的策 略,包括成本最低、打散和折中。 解决问题 1.大规模计算集群成本高。 2.创建ECS实例方式单一,无法跨计费 方式、可用区及规格等核心参数。 3.当可用区资源紧张,无法自动保证基于 spot类型的稳定算力。 产品列表 专有网络VPC 云服务器ECS
基于弹性供应组构建大数据分析集群最佳实践 业务架构 场景描述 基于弹性供应组(APG)搭建 spark计算集 群,提供一键开启跨售卖方式、跨可用区、跨实例规格的计算集群交付模式的实践。方案优势 1.超低成本:跨售卖方式提供计算实 例,按秒计费,可全部使用 spot实例 交付,最高可省 90%成本。2.稳定可靠:跨可用域、跨实例...
自建Hive数仓迁移到阿里云EMR
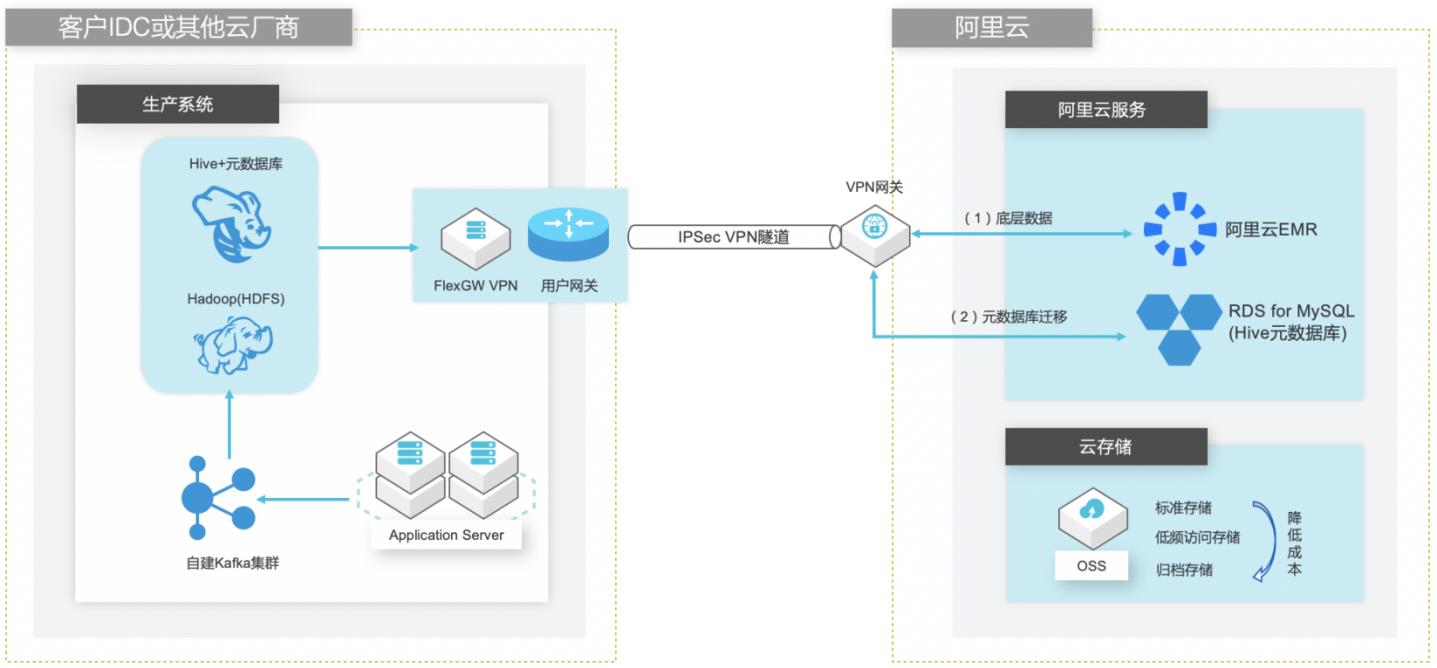
场景描述 客户在IDC或者公有云环境自建Hadoop集群构 建数据仓库和分析系统,购买阿里云EMR集群之 后,涉及到将数据仓库和Hive元数据的数据库迁 移上云。目前主流Hive数据仓库迁移场景为1.x 版本迁移到阿里云EMR(Hive2.x版本),涉及到 数据订正更新步骤。 解决的问题 Hive数据仓库的数据迁移方案 Hive元数据库的迁移方案 Hive跨版本迁移后的数据订正 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
名词解释 Hive Apache Hive是基于 Hadoop的一个数据仓库工具,可以将结构化的数据文件映 射为一张数据库表,并提供简单的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce任务进行运行。其优点是学习成本低,可以通过类 SQL语句快速实 现简单的 MapReduce统计,不必开发专门的 MapReduce应用,十分适合数据仓 库的统计分析...
EMR集群安全认证和授权管理
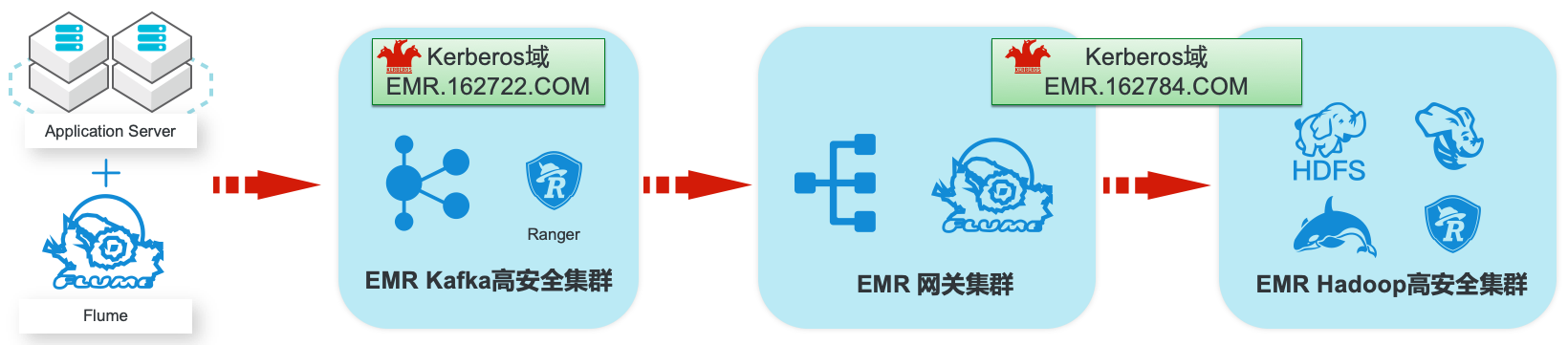
场景描述 阿里云EMR服务Kafka和Hadoop安全集群使 用Kerberos进行用户安全认证,通过Apache Ranger服务进行访问授权管理。本最佳实践中以 Apache Web服务器日志为例,演示基于Kafka 和Hadoop的生态组件构建日志大数据仓库,并 介绍在整个数据流程中,如何通过Kerberos和 Ranger进行认证和授权的相关配置。 解决问题 1.创建基于Kerberos的EMR Kafka和 Hadoop集群。 2.EMR服务的Kafka和Hadoop集群中 Kerberos相关配置和使用方法。 3.Ranger中添加Kafka、HDFS、Hive和 Hbase服务和访问策略。 4.Flume中和Kafka、HDFS相关的安全配 置。 产品列表:E-MapReduce、专有网络VPC、云服务器ECS、云数据库RDS版
本最佳实践方案中,相当于 Hadoop集群的 Kerberos域的 网关节点 Flume服务,访问 Kafka集群的 Kerberos域的 Kafka服务。步骤2 在两个 Kerberos域分别添加 Principal。Kafka安全集群 使用 root用户通过 SSH登录到 Kafka集群的 emr-header-1节点,进入 Kerberos 的 admin工具:sh/usr/lib/has-current/bin/hadmin-local.sh/...
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
详见:https://www.aliyun.com/product/oss Hive:Apache Hive是基于 Hadoop的一个数据仓库工具,可以将结构化的数据 文件映射为一张数据库表,并提供简单的 SQL查询功能,可以将 SQL语句转换 为 MapReduce任务进行运行。其优点是学习成本低,可以通过类 SQL语句快速 实现简单的 MapReduce统计,不必开发专门的 MapReduce...
块存储EBS
阿里云块存储EBS是为云服务器ECS提供的低时延、持久性、高可靠的块级随机存储,拥有丰富的产品类型,多元的存储特性,适用于自建数据库加速,快照数据保护等场景,ESSD PL3规格最高可提供100万IOPS以及4000MB/S吞吐能力,有效提升存储性能,大大降低成本。
提供高性能(单盘高达36万随机IOPS)、低时延(us级别)和媲美物理机的性价比,适合应用层具备高可用架构的业务场景使用,类似MySQL(Master/Slave架构)、Hadoop等.支持多个ECS实例并发读写访问的数据块级存储设备,具备多并发、高性能、高可靠等特性,适用于share-everything架构下对块存储设备的共享访问场景,譬如政府...
来自:
云产品
大数据系统基准性能测试最佳实践
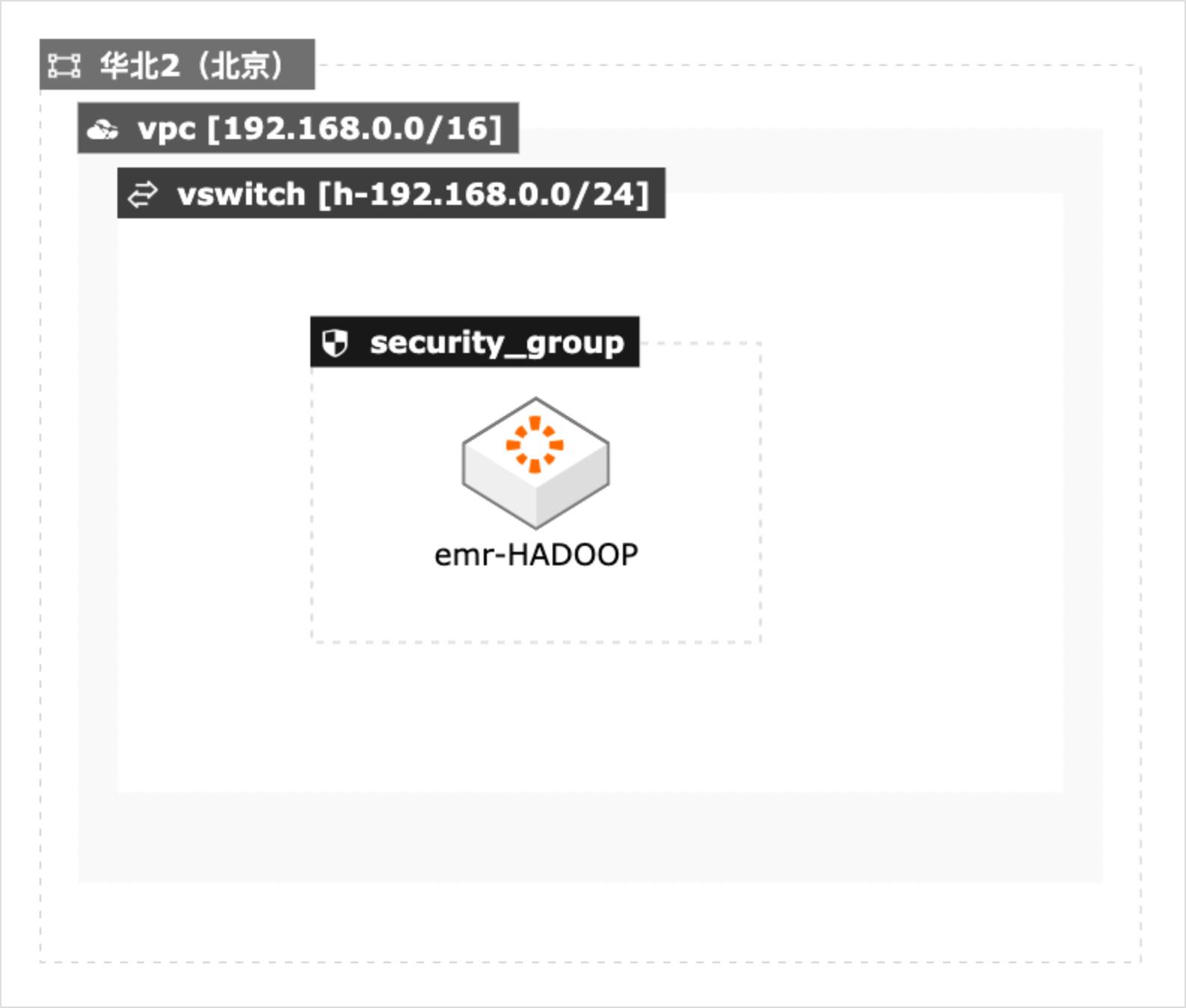
本方案适用于在阿里云上进行大数据基准性能测试的场景,包括 Teragen和Terasort测试,TestDFSIO测试。本文采用CADT工具结合阿里云的E-MapReduce服务快速构建测试集群,并提供了Teragen和Terasort测试,TestDFSIO测试的测试脚本,便于迅速开展测试。
大数据系统基准性能测试 最佳实践 部署架构图 场景描述 本方案适用于大数据系统基准性能测 试的场景,这里以 Terasort&Teragen 测试,以及 TestDFSIO测试,来衡量 大数据系统的基准能力。解决问题 1.使用 CADT快速构建大数据系统 测试环境 2.进行 Terasort&Teragen 3.进行 TestDFSIO测试 产品列表 EMR 云服务器 ECS 云速搭 ...
SLS多云日志采集、处理及分析
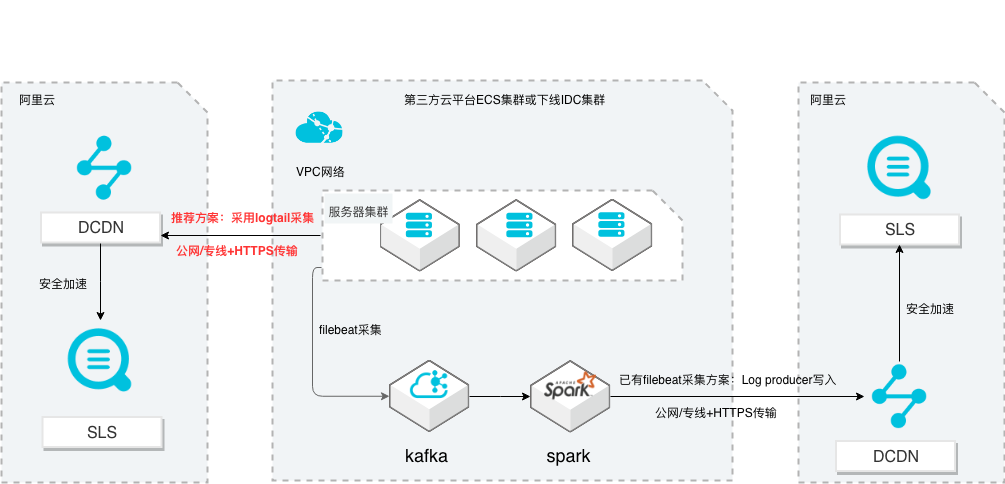
场景描述 从第三方云平台或线下IDC服务器上采集 日志写入到阿里云日志服务,通过日志服务 进行数据分析,帮助提升运维、运营效率, 建立DT 时代海量日志处理能力。 针对未使用其他日志采集服务的用户,推荐 在他云或线下服务器安装logtail采集并使用 Https安全传输;针对已使用其他日志采集 工具并且已有日志服务需要继续服务的情 况,可以通过Log producer SDK写入日志 服务。 解决问题 1.第三方云平台或线下IDC客户需要使用 阿里云日志服务生态的用户。 2.第三方云平台或线下IDC服务器已有完 整日志采集、处理及分析的用户。 产品列表 E-MapReduce 专有网络VPC 云服务器ECS 日志服务LOG DCDN
SLS多云日志采集、处理及分析 最佳实践 业务架构 场景描述 从第三方云平台或线下 IDC服务器上采集 日志写入到阿里云日志服务,通过日志服 务进行数据分析,帮助提升运维、运营效 率,建立 DT 时代海量日志处理能力。针对未使用其他日志采集服务的用户,推 荐在他云或线下服务器安装 logtail采集并使 用 Https安全传输;针对...
- 产品推荐
- 这些文档可能帮助您