云数据库HBase
阿里云云数据库 HBase 版(ApsaraDB for HBase)是基于 Hadoop 且100%兼容HBase协议的高性能、可弹性伸缩、面向列的分布式数据库,轻松支持PB级大数据存储,满足千万级QPS高吞吐随机读写场景。
支持海量全量数据快速批量导入以及实时增量数据快速写入,通过Spark轻松完成海量数据离线分析.冷热分离、异构存储、高压缩率。综合存储成本下降80%.HBase支持Spark Streaming流式处理,满足实时业务场景.海量全量数据快速导入.可以通过 BulkLoad 将海量全量数据快速导入HBase,轻松应对 百TB级海量数据快速写入HBase.用户...
来自:
云产品
云原生数据仓库AnalyticDB MySQL数据仓库
阿里云云原生数据仓库AnalyticDB MySQL版(简称AnalyticDB)是融合数据库、大数据技术于一体的云原生企业级数据仓库平台。云原生数据仓库AnalyticDB MySQL版支持数据实时写入和同步更新、实时计算和实时服务,可用于构建企业级报表系统、数据仓库和数据服务引擎。
支持将MySQL分库分表的数据聚合到同一张表中,提供全局数据分析能力.云服务器ECS.云数据库RDS MySQL版.推荐搭配产品.通用:BI报表分析加速.与多种BI工具高度兼容,开箱即用.更多应用场景请查看.查看更多商品.支持按小时设置计算资源弹性扩容规则,解决计算资源峰谷需求问题,降低计算资源成本.白天工作高峰期,准时弹出计算...
来自:
云产品
云数据库 SelectDB 版
阿里云数据库 SelectDB 是现代化实时数据仓库 SelectDB 在阿里云上的全托管服务,内核基于业界领先的开源分析型数据库 Apache Doris 研发,由阿里云和飞轮科技联合打造。阿里云数据库 SelectDB 聚焦于满足企业级大数据分析需求,广泛应用于实时报表分析、即席多维分析、日志检索分析、数据联邦与查询加速等场景,致力于为客户提供极致性能、简单易用的数据分析服务。
SelectDB 具有云原生存算分离、实时极速、融合统一、简单易用、开源开放等核心优势,提供万级 QPS 的实时报表查询、亚秒级的即席多维分析体验、近10倍性价比的日志分析方案、最高降本80%的湖仓一体分析平台。云数据库 SelectDB 版原理架构 云原生存算分离架构、多计算集群、共亨存储,让海量数据分析更快、成本更低。快速...
来自:
云产品
云数据库MongoDB版
阿里云云数据库MongoDB版是完全兼容MongoDB协议、高度兼容DynamoDB协议的在线文档型数据库服务。支持单节点、双节点、副本集和分片集群四种部署架构,能够满足不同的业务场景需要。
例如与阿里云原生数据湖分析服务DLA的Serverless Spark对接,满足在线交互式查询、批处理、机器学习等诉求.Serverless Spark对接MongoDB快速入门.便捷运维:专业监控和数据库管理平台,主动升级.可视化管理及运维平台,简单易用,系统主动升级至最新可靠版本.提供CPU利用率、IOPS、连接数、磁盘空间等实例信息实时监控及...
来自:
云产品
云数据库ClickHouse
云数据库ClickHouse 是阿里云提供的分布式实时分析型列式数据库服务。具有高性能、开箱即用、企业特性支持。广泛应用于流量分析、广告营销分析、行为分析、人群划分、客户画像、敏捷BI、数据集市、网络监控、分布式服务和链路监控等业务场景。
全球化部署开箱即用,快速支持海外游戏发行产品动态2020-02-07 新功能/规格 云数据库ClickHouse增加新规格 查看详情 2020-05-21 新功能/规格 云数据库 ClickHouse 接入数据管理服务 DMS 发布 查看详情 2020-06-01 新功能/规格 云数据库 ClickHouse 在线日志投递分析功能发布 查看详情 2020-06-28 新功能/规格 云数据库...
来自:
云产品
MRACC加速倚天ECS实例Flink集群性能
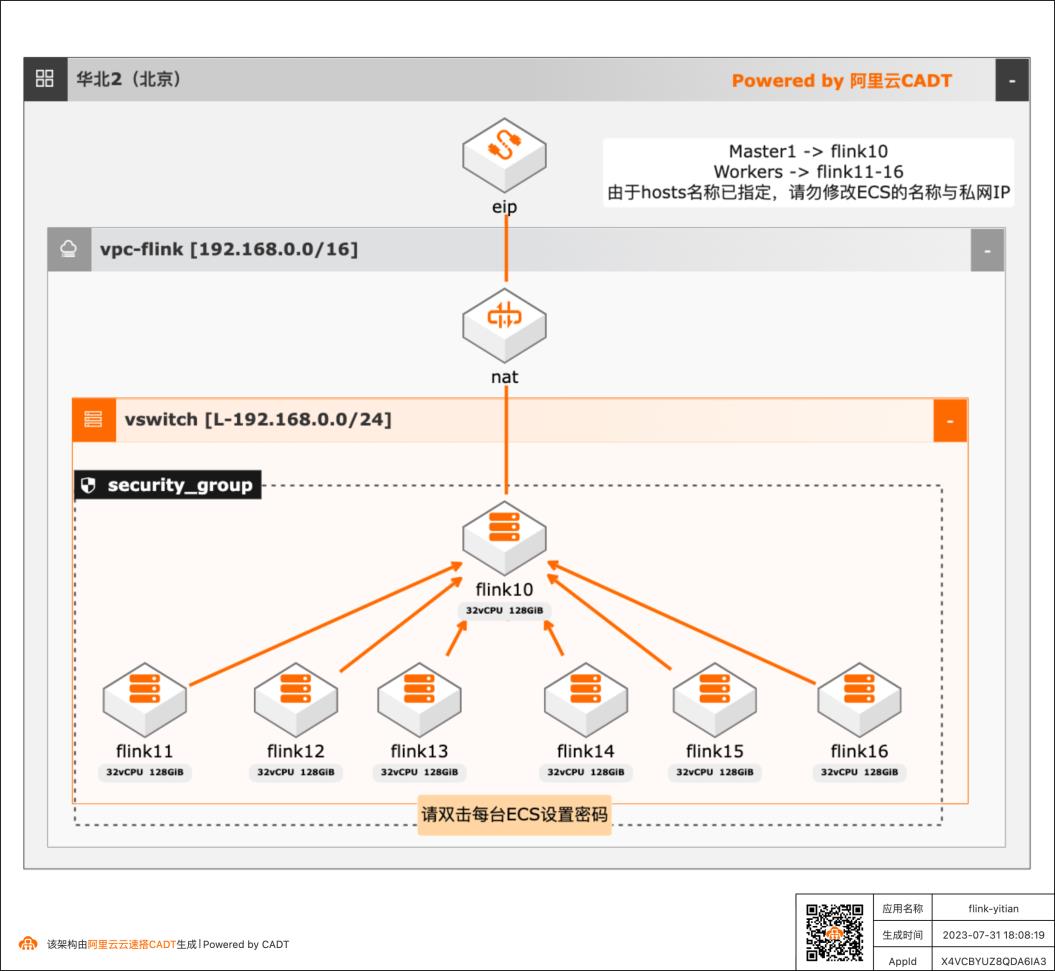
希望了解Flink集群on倚天的部署架构。 通过神龙大数据加速引擎 Mracc 提升Flink集群性能。 希望实测了解倚天ECS实例运行Flink集群的性能 架构设计:利用阿里云官方架构设计模版,在此基础上二次定制(调整规格、资源数量、配置调整)。 快速完成PoC和生产环境的设计和部署
cd/opt/fastmr/nexmark nohup sh test.sh&步骤2 通过日志文件查看压测脚本执行情况 tail-f/opt/fastmr/nexmark/nexmark.out 文档版本:20230801 18 MRACC加速倚天 ECS实例 Spark集群性能 部署基础环境 步骤3 通过日志文件查看压测数据生成进度 测试一共会跑 22个查询,大概需要 50分钟左右,若日志显示了 q22的Nexmark结 果...
数据湖构建 Data Lake Formation
数据湖构建服务是阿里云上数据湖架构中的核心部分,助力用户构建数据湖系统。支持多数据源实时入湖,实现湖上元数据统一管理,提供企业级权限控制,无缝对接多种计算引擎,打破孤岛,洞察业务价值
构建在阿里云云服务器 ECS 上的开源 Hadoop、Spark、HBase、Hive、Flink 生态大数据 PaaS 产品.大数据计算服务·MaxCompute.提供快速、完全托管的PB级数据仓库解决方案,经济并高效的分析处理海量数据.兼容PostgreSQL协议的实时交互式分析产品.对象存储 OSS.海量、安全、低成本、高可靠的云存储服务,提供99.9999999999%的...
来自:
云产品
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。本章主要通过 hive对存储在 hdfs上的日志进行分析,获取错误日志记录。整体流程 如下:步骤1 创建业务流程 log_analyse 进入数据开发页面 新建业务流程 log_analyse:文档版本:20201020 32 基于 Dataworks的大数据一站式开发及数据治理 基于 hive的离线...
大数据workshop

大数据workshop
BI分 析,整个过程中使用到通过 VPC、ECS、RDS、Flink、DataHub、DTS、Hologres、QuickBI和 DataV等资源,本章通过 CADT工具部署资源。本实例架构图:文档版本:20210628(发布日期)9 阿里云最佳实践大数据 WorkShop 最佳实践项目实践(注:CADT暂不支持创建实时计算 Flink集群,下一章节将通过页面创建)需要注意:使用 ...
来自:
最佳实践
相关产品:块存储,云服务器ECS,云数据库RDS MySQL 版,对象存储 OSS,弹性公网IP,数据传输,DataWorks,大数据计算服务 MaxCompute,DataV数据可视化,实时计算,数据总线,Quick BI,Hologres
金融专属大数据workshop

实践目标 学习搭建一个实时数据仓库,掌握数据采集、存储、计算、输出、展示等整个业务流程。 整个实时数据仓库系统全部基于阿里云产品进行架构搭建,用户可以掌握并学会运用各个服务组件及各个组件之间如何联动。 理解阿里云原生实时离线一体数仓解决方案架构以及掌握交付落地的实践使用方法。 前置知识要求 熟练掌握SQL语法 对大数据体系系统知识有一定的了解
MaxCompute 交互式分析(Hologres)是为大数据设计的实时交互式 分析产品,它与MaxCompute无缝打通,支持数据实时写入,支持PB级数据进 行高并发、低延时的分析处理,兼容PostgreSQL协议,可以使用您最熟悉的BI 工具对海量数据进行自助的多维分析透视和业务探索,同时也支持超高QPS点查 能 力,满 足 数 仓 分 析、服 务 一...
来自:
最佳实践
相关产品:块存储,云服务器ECS,云数据库RDS MySQL 版,对象存储 OSS,弹性公网IP,数据传输,DataWorks,大数据计算服务 MaxCompute,DataV数据可视化,实时计算,数据总线,Quick BI,Hologres
自建Hive数仓迁移到阿里云EMR
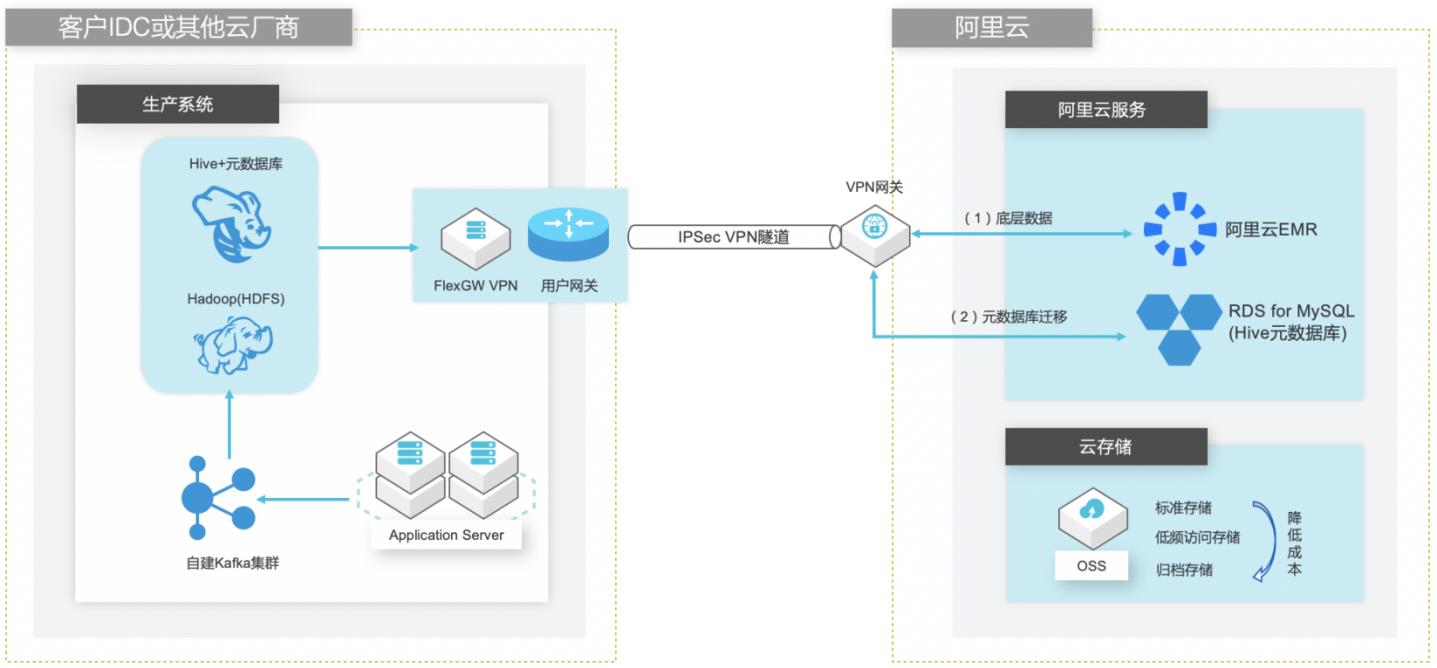
场景描述 客户在IDC或者公有云环境自建Hadoop集群构 建数据仓库和分析系统,购买阿里云EMR集群之 后,涉及到将数据仓库和Hive元数据的数据库迁 移上云。目前主流Hive数据仓库迁移场景为1.x 版本迁移到阿里云EMR(Hive2.x版本),涉及到 数据订正更新步骤。 解决的问题 Hive数据仓库的数据迁移方案 Hive元数据库的迁移方案 Hive跨版本迁移后的数据订正 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
自建 Hive数据仓库跨版本迁移到阿里云 EMR 场景描述 解决的问题 客户在IDC或者公有云环境自建Hadoop集群构建 Hive数据仓库的数据迁移方案 数据仓库和分析系统,购买阿里云 EMR集群之后,Hive元数据库的迁移方案 涉及到将数据仓库和Hive元数据的数据库迁移上 Hive跨版本迁移后的数据订正 云。目前主流 Hive数据仓库迁移场景...
开源Flink迁移实时计算Flink全托管版最佳实践
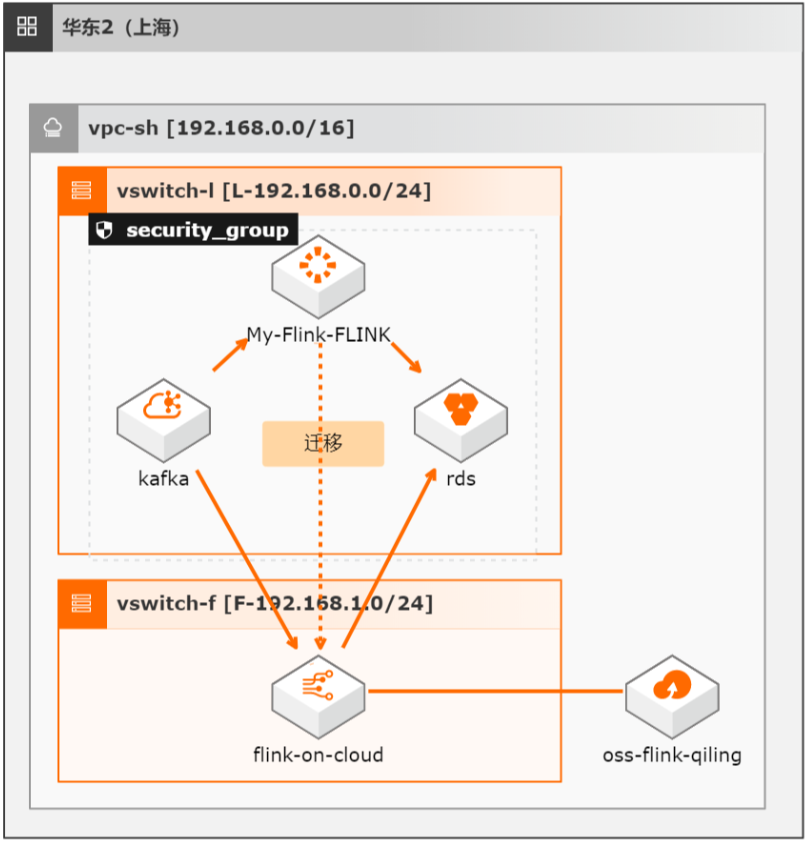
本方案介绍如何将自建开源Flink集群的流式任务(包含Datastream、Table/SQL、PyFlink任务)迁移至阿里云实时计算全托管版。
参见:https://www.aliyun.com/product/rds/mysql 消息队列 Kafka 版:是阿里云基于 Apache Kafka 构建的高吞吐量、高可扩展性 的分布式消息队列服务,广泛用于日志收集、监控数据聚合、流式数据处理、在线 和离线分析等场景,是大数据生态中不可或缺的产品之一,阿里云提供全托管服 务,用户无需部署运维,更专业、更可靠、...
自建Hadoop迁移到阿里云EMR
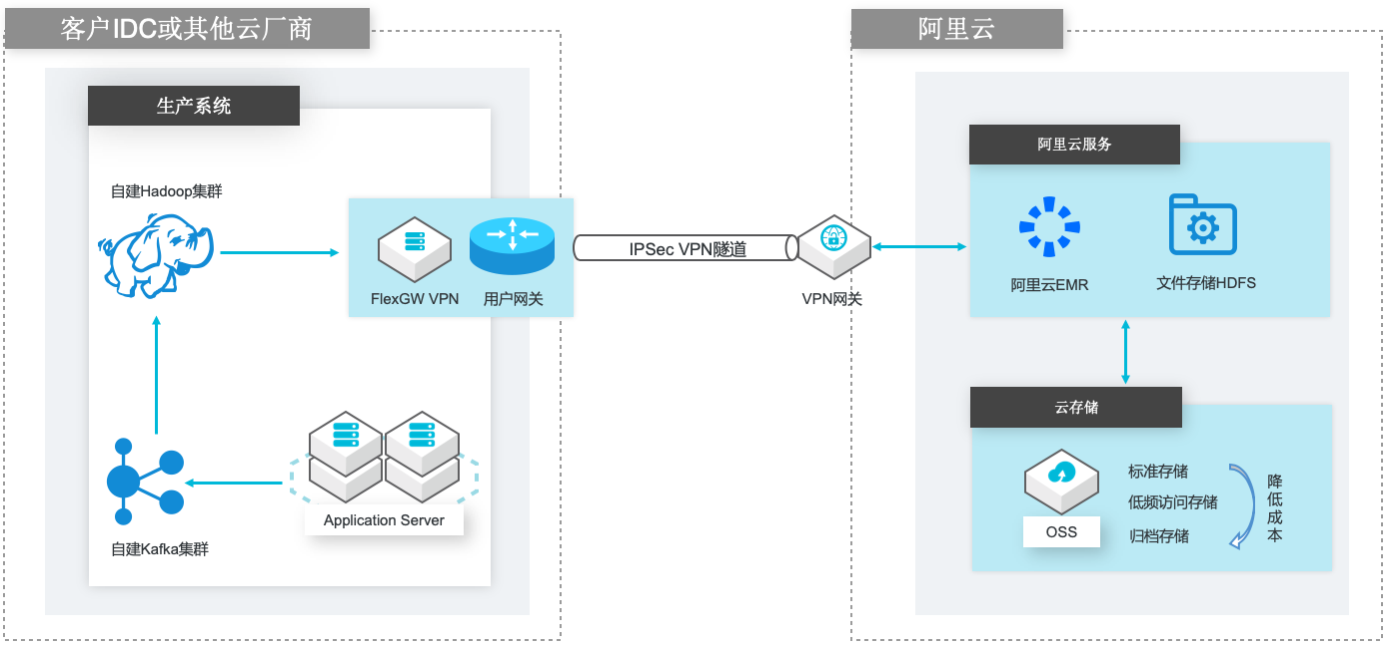
场景描述 场景1:自建Hadoop集群数据(HDFS)迁移到 阿里云EMR集群的HDFS文件系统; 场景2:自建Hadoop集群数据(HDFS)迁移到 计算存储分离架构的阿里云EMR集群,以OSS 和JindoFS作为EMR集群的后端存储。 解决的问题 客户自建Hadoop迁移到阿里云EMR集群的 技术方案; 基于IPSecVPN隧道构建安全和低成本数据 传输链路 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
Flume Flume是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日 志数据。它具有基于流数据流的简单灵活的体系结构。它具有可调整的可靠性机 制以及许多故障转移和恢复机制,具有强大的功能和容错能力。它使用一个简单 的可扩展数据模型,允许在线分析应用程序。文档版本:20200330 IV 自建Hadoop数据迁移到...
EMR本地盘实例大规模数据集测试
场景描述 阿里云为了满足大数据场景下的存储需求,在云 上推出了本地盘D1机型,这个系列提供了本地 盘而非云盘作为存储,提高了磁盘的吞吐能力, 发挥Hadoop的就近计算优势。阿里云EMR 产品针对本地盘机型,推出了一整套的自动化运 维方案,帮助用户方便可靠地使用本地盘机型, 不需要关注整个运维过程同时数据的高可靠和 服务的高可用。 解决问题 1.云盘多份冗余数据导致成本高 2.磁盘吞吐量不高 3.节点的高可靠分布问题 4.本地盘与节点的故障监控问题 5.数据迁移时自动决策问题 6.自动故障节点迁移与数据平衡问题 产品列表 EMR(E-MapReduce) 本地盘 VPC
3GB日志,一年大约生成 1TB日志规模的用户使用阿里云 大数据集群进行性能测试方法指引。应用范围 需要使用阿里云 EMR+本地盘进行大数据业务前进行性能测试的用户 线下自建大数据集群用户需要迁移到阿里云云上 EMR+本地盘进行大数据分析性 能对比测试的用户 名词解释 VPC:Virtual Private Cloud,简称 VPC。基于阿里云创建...
云消息队列 RocketMQ 版
云消息队列 RocketMQ 版是基于 Apache RocketMQ 构建的分布式消息中间件,广泛用于异步解耦、削峰填谷等场景。可支撑千万级并发、万亿级数据洪峰,更稳定,更安全。
历年双 11 购物狂欢节零点千万级 TPS、万亿级数据洪峰,创造了全球最大的业务消息并发以及流转纪录(日志类消息除外);在始终保证高性能前提下,支持亿级消息堆积,不影响集群的正常服务,在削峰填谷(蓄洪)、微服务解耦的场景下尤为重要;提供丰富的消息类型,满足各种严苛场景下的高级特性需求,当前支持的消息类型涵盖...
来自:
云产品
EMR集群安全认证和授权管理
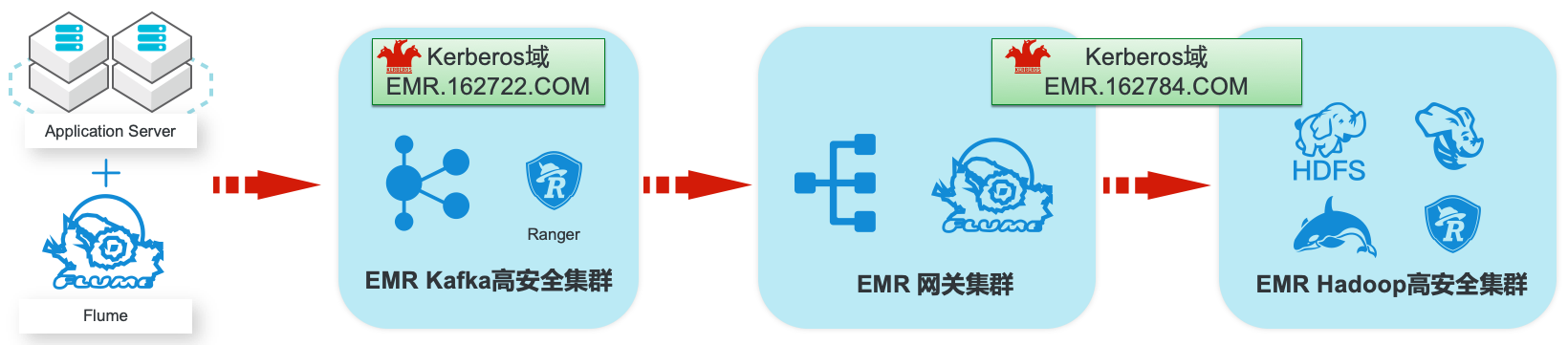
场景描述 阿里云EMR服务Kafka和Hadoop安全集群使 用Kerberos进行用户安全认证,通过Apache Ranger服务进行访问授权管理。本最佳实践中以 Apache Web服务器日志为例,演示基于Kafka 和Hadoop的生态组件构建日志大数据仓库,并 介绍在整个数据流程中,如何通过Kerberos和 Ranger进行认证和授权的相关配置。 解决问题 1.创建基于Kerberos的EMR Kafka和 Hadoop集群。 2.EMR服务的Kafka和Hadoop集群中 Kerberos相关配置和使用方法。 3.Ranger中添加Kafka、HDFS、Hive和 Hbase服务和访问策略。 4.Flume中和Kafka、HDFS相关的安全配 置。 产品列表:E-MapReduce、专有网络VPC、云服务器ECS、云数据库RDS版
步骤4 通过 HiveSQL对原始数据进行简单分析,并将结果插入都 HBase表中。insert into table hbase_external_table_job99_ip_statics select substring(md5(concat(substring(accesstime,2,11),ipaddr)),9,16)as key,substring(accesstime,2,11)as log_record_date,ipaddr,count(*)as ip_count_value,'20200313' as process_...
日志安全审计与合规性评估
日志安全审计与合规性评估方案旨在通过集中化采集、存储、分析来自多个系统、应用和设备的日志数据,确保企业数据和系统安全性与合规性。企业合规团队可基于日志审计来输出合规信息,帮助企业优化安全态势,确保业务连续性和数据安全。
日志安全审计与合规性评估方案旨在通过集中化采集、存储、分析来自多个系统、应用和设备的日志数据,确保企业数据和系统安全性与合规性。企业合规团队可基于日志审计来输出合规信息,帮助企业优化安全态势,确保业务连续性和数据安全。日志安全审计与合规性评估 日志安全审计与合规性评估方案旨在通过集中化采集、存储、...
来自:
技术解决方案
- 产品推荐
- 这些文档可能帮助您