实时数仓Hologres
Hologres(原交互式分析)是一站式实时数据仓库引擎,支持海量数据实时写入、实时更新、实时分析,支持标准SQL(兼容PostgreSQL协议),支持PB级数据多维分析(OLAP)与自助分析(Ad Hoc),支持高并发低延迟的在线数据服务(Serving),与MaxCompute、Flink、DataWorks深度融合,提供离在线一体化全栈数仓解决方案。
基于用户日志数据的实时多维分析.某货运物流公司其大数据部门一直在探索建设新一代数仓,但一直没有取得很大突破,无法让数据发挥更大价值。通过Hologres建立的新一代实时数仓,替换原有ES、HBase等架构,解决千万级订单数据实时分析慢和上百万货运司机物流实时调度难的问题.减少了维度退化的设计,支持千万订单数据实时...
来自:
云产品
云原生大数据计算服务MaxCompute
阿里云云原生大数据计算服务MaxCompute是面向分析的企业级云数仓,作为一体化大数据智能计算平台ODPS的大规模批量计算引擎,MaxCompute以 Serverless 架构提供快速、全托管的在线数据仓库服务,使您经济高效的分析处理海量数据,进行敏捷的业务洞察。
海量日志分析解决方案.查看更多>.各行业客户案例与最佳实践>.精选客户案例.资源规划管理及评估>.满足企业现实需求的 Serverless 算力方案,兼顾成本与性能的需要.MaxFrame 邀测.MaxFrame 邀测.MaxFrame 邀测.更多阿里云大数据.MaxCompute 资源抵扣包套餐(500CU*H+100GB存储)仅售 59元/年.MaxCompute 资源抵扣包套餐(500...
来自:
云产品
Spark on ECI大数据分析

场景描述 方案优势 1.计算引擎弹性扩缩容,兼顾资源弹性与计 算资源成本优化。 2.计算与存储分离架构,结合阿里云原生云 存储产品,海量数据湖优势。 3.Kubernetes原生的调度性能优势,提升在 大规模分析作业时的分析性能优势分。 4.集群资源隔离和按需分配。 解决问题 1.计算资源弹性能力不足,计算资源成本管 控能力欠缺. 2.集群资源调度能力和隔离能力不足。 3.计算与存储无法分离,大数据量分析时出 现数据存储资源瓶颈。 4.Spark submit方式提交分析作业参数支持 有限等缺点。 产品列表 容器服务Kubernetes版(ACK) 弹性容器实例(ECI) 文件存储HDFS 对象存储OSS 专有网络VPC 容器镜像服务ACR
文档版本:20200409 16 Spark on ECI大数据分析 应用开发 文档版本:20200409 17 Spark on ECI大数据分析 Spark on Kubernetes实践方案对比 3.Spark on Kubernetes实践方案对比 本章中,我们首先通过 Spark on 阿里云容器服务 Kubernetes版(ACK)并结合 Kubernetes原生的技术说明来解释 Spark on Kubernetes架构相比传统的...
SLS多云日志采集、处理及分析
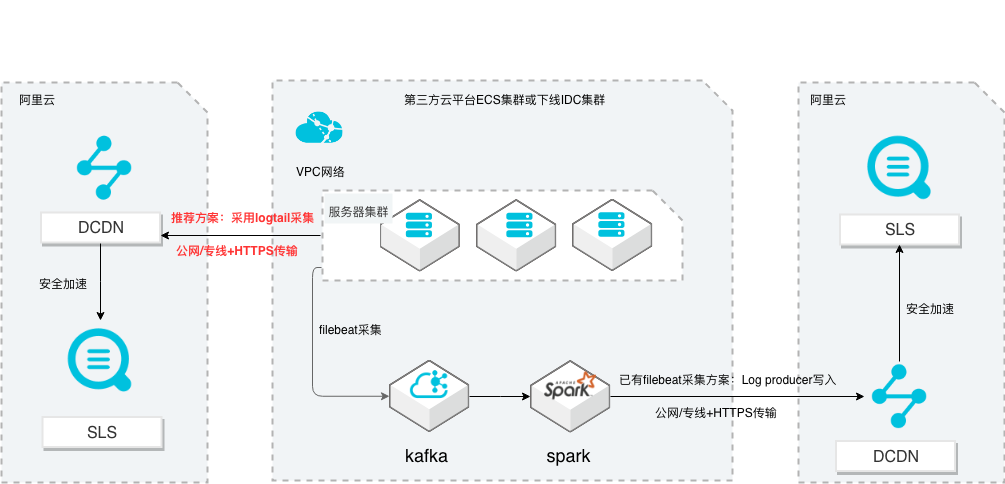
场景描述 从第三方云平台或线下IDC服务器上采集 日志写入到阿里云日志服务,通过日志服务 进行数据分析,帮助提升运维、运营效率, 建立DT 时代海量日志处理能力。 针对未使用其他日志采集服务的用户,推荐 在他云或线下服务器安装logtail采集并使用 Https安全传输;针对已使用其他日志采集 工具并且已有日志服务需要继续服务的情 况,可以通过Log producer SDK写入日志 服务。 解决问题 1.第三方云平台或线下IDC客户需要使用 阿里云日志服务生态的用户。 2.第三方云平台或线下IDC服务器已有完 整日志采集、处理及分析的用户。 产品列表 E-MapReduce 专有网络VPC 云服务器ECS 日志服务LOG DCDN
文档版本:20211203 24 SLS多云日志采集、处理及分析 Logtail日志采集处理分析 注意:查询分析设置的修改操作只会对新写入的数据生效,如果您需要提前对查询分 析设置的某些字段分析统计生效,请使用指定字段查询的自定义方式在日志写入到日 志库之前进行开启统计查询。步骤4 再次启动日志发生器和停止日志发生器。按云...
云原生数据湖分析DLA
阿里云云原生数据湖分析是新一代大数据解决方案,采取计算与存储完全分离的架构,支持对象存储(OSS)、RDS(MySQL等)、NoSQL(MongoDB等)数据源的消息实时归档建仓,提供Presto和Spark引擎,满足在线交互式查询、流处理、批处理、机器学习等诉求。内置大量优化+弹性,比开源自建集群最高降低50%+的成本,最快可1分钟级拉起300个计算节点,快速满足业务资源要求。
数据湖分析Spark引擎支持Job级别的弹性,可设置长期保有资源(MIN)、弹性资源上限(MAX),MIN最小为0,实例可自动根据业务波峰波谷在MIN 与 MAX 之间弹性扩缩容,无需提前预留资源,降低成本的同时保持业务稳定运行;同时支持秒级拉起,目前每分钟可以拉起500~1000个计算节点,可以快速响应业务资源需求.可以自动为OSS上面...
来自:
云产品
电商网站数据埋点及分析
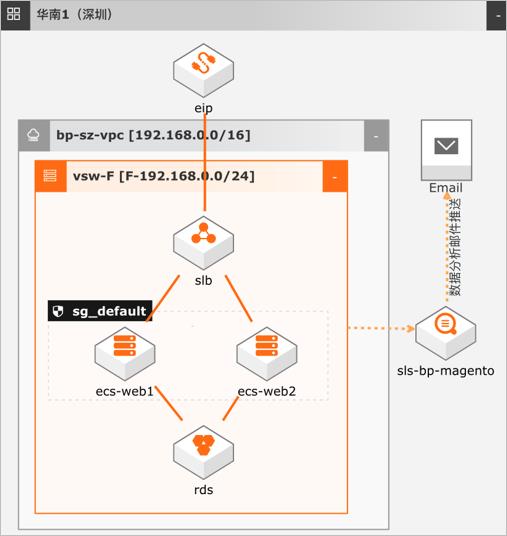
场景描述 数据埋点是数据产品经理、数据运营以及数据分 析师,基于业务需求(例如:CPC点击付费广 告中统计每一个广告位的点击次数),产品需求 (例如:推荐系统中推荐商品的曝光次数以及点 击的人数)对用户行为的每一个事件对应的位置 进行开发埋点,并通过SDK上报埋点的数据结 果,记录数据汇总后进行分析,推动产品优化或 指导运营。 解决问题 1.电商网站广告位效果统计分析 2.电网网站推荐商品曝光、点击、购买等行为统 计分析 3.电商网站用户分布分析 4.电商网站页面热点图分析等 产品列表 日志服务SLS Dataworks 云服务器ECS 云数据库RDS版 负载均衡SLB 专有网络VPC
文档版本:20220127 I 电商网站数据埋点及分析 前言 前言 概述 本文以电商网站为例,使用日志服务采集日志,RDS作为后端数据存储服务并使用日 志服务对数据进行分析。数据埋点是数据产品经理、数据运营以及数据分析师,基于 业务需求(例如:CPC点击付费广告中统计每一个广告位的点击次数),产品需求(例 如:推荐系统中...
基于Flink+ClickHouse构建实时游戏数据分析
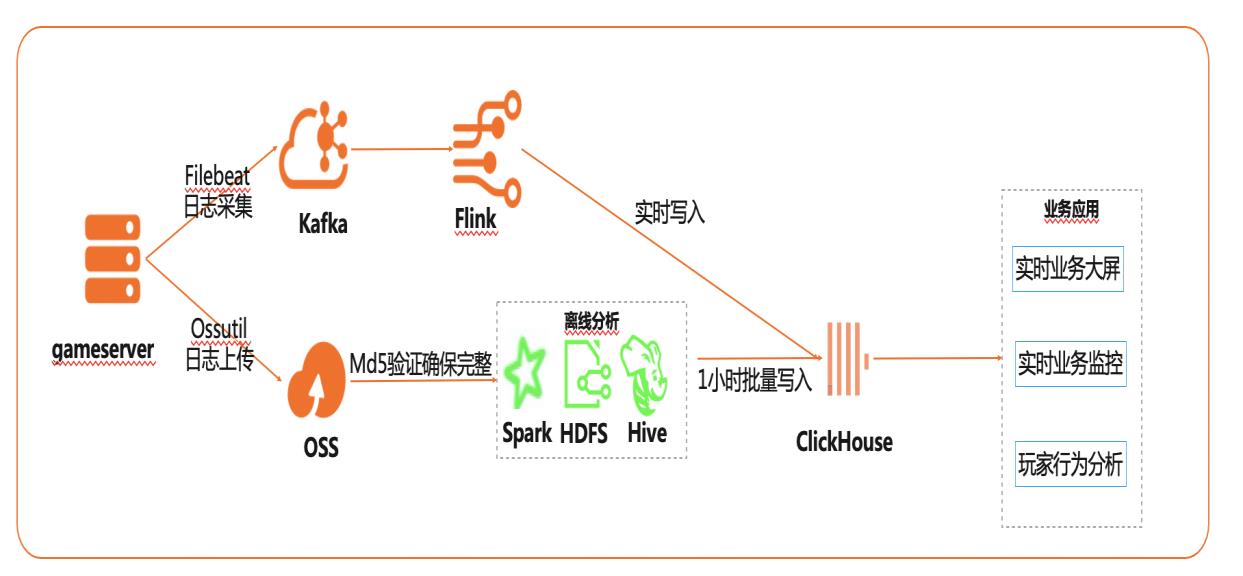
在互联网、游戏行业中,常常需要对用户行为日志进行分析,通过数据挖掘,来更好地支持业务运营,比如用户轨迹,热力图,登录行为分析,实时业务大屏等。当业务数据量达到千亿规模时,常常导致分析不实时,平均响应时间长达10分钟,影响业务的正常运营和发展。 本实践介绍如何快速收集海量用户行为数据,实现秒级响应的实时用户行为分析,并通过实时流计算Flink/Blink、云数据库ClickHouse等技术进行深入挖掘和分析,得到用户特征和画像,实现个性化系统推荐服务。 通过云数据库ClickHouse替换原有Presto数仓,对比开源Presto性能提升20倍。 利用云数据库ClickHouse极致分析性能,千亿级数据分析从10分钟缩短到30秒。 云数据库ClickHouse批量写入效率高,支持业务高峰每小时230亿的用户数据写入。 云数据库ClickHouse开箱即用,免运维,全球多Region部署,快速支持新游戏开服。 Flink+ClickHouse+QuickBI
Filebeat 可以监听指定的日 志文件或位置,从中收集日志事件并将其转发到 Elasticsearch或 Logstash进行索引,本实践采用 Filebeat收集 game-server的日志,并转发到 kafka。步骤1 在 ECS服务器上面,下载 Filebeat,为了兼容消息队列 kafka版本,推荐下载 filebeat-6.4.0-linux-x86_64:wget ...
数据湖-在线学习场景数据分析

场景描述 本场景以在线教育中一个答题闯关类的应用为 例,使用WebServer来模拟演示这类日志数据 的分析处理。通过Nginx和Pythonflask搭建 WebServer,模拟应用中的关键页面,比如登 录、课程内容等,之后构造若干用户使用的模拟 日志数据,投递到数据湖进行分析后获取应用 PV、UV、课程内容访问排行、平均得分等等。 解决问题 基于数据湖(EMR+OSS)搭建大数据平台。 EMR和OSS使用和配置。 数据统一存储到OSS。 产品列表 E-MapReduce 对象存储OSS 云服务器ECS 访问控制RAM 专有网络VPC
场景描述 应用系统的日志数据一般包括Web日志和App日志,通过日志分析可以获取网站每 类页面或App内容的PV(PageView,页面访问量)值,UV(UserView,用户访问 量)、独立IP数,用户检索的关键词排行、用户访问最多的页面基础信息,甚至还可 以构建广告推荐模型、用户行为特征分析等来帮助运营决策。本场景以在线教育中一...
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。
配置PAI计算资源和日志转发 步骤1登录到PAI控制台,选择 步骤2 添加MaxCompute资源 工作空间资源配置:选择“MaxCompute资源”勾选:默认后付费Quota 自定义项目空间:本示例为“dlf_mc001”基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测 步骤3 SLS日志转发选择初始化创建的SLSporject和logstore 2.2.创建RAM用户 ...
云数据库 SelectDB 版
阿里云数据库 SelectDB 是现代化实时数据仓库 SelectDB 在阿里云上的全托管服务,内核基于业界领先的开源分析型数据库 Apache Doris 研发,由阿里云和飞轮科技联合打造。阿里云数据库 SelectDB 聚焦于满足企业级大数据分析需求,广泛应用于实时报表分析、即席多维分析、日志检索分析、数据联邦与查询加速等场景,致力于为客户提供极致性能、简单易用的数据分析服务。
SelectDB 具有云原生存算分离、实时极速、融合统一、简单易用、开源开放等核心优势,提供万级 QPS 的实时报表查询、亚秒级的即席多维分析体验、近10倍性价比的日志分析方案、最高降本80%的湖仓一体分析平台。云数据库 SelectDB 版原理架构 云原生存算分离架构、多计算集群、共亨存储,让海量数据分析更快、成本更低。快速...
来自:
云产品
MRACC加速倚天ECS实例Flink集群性能
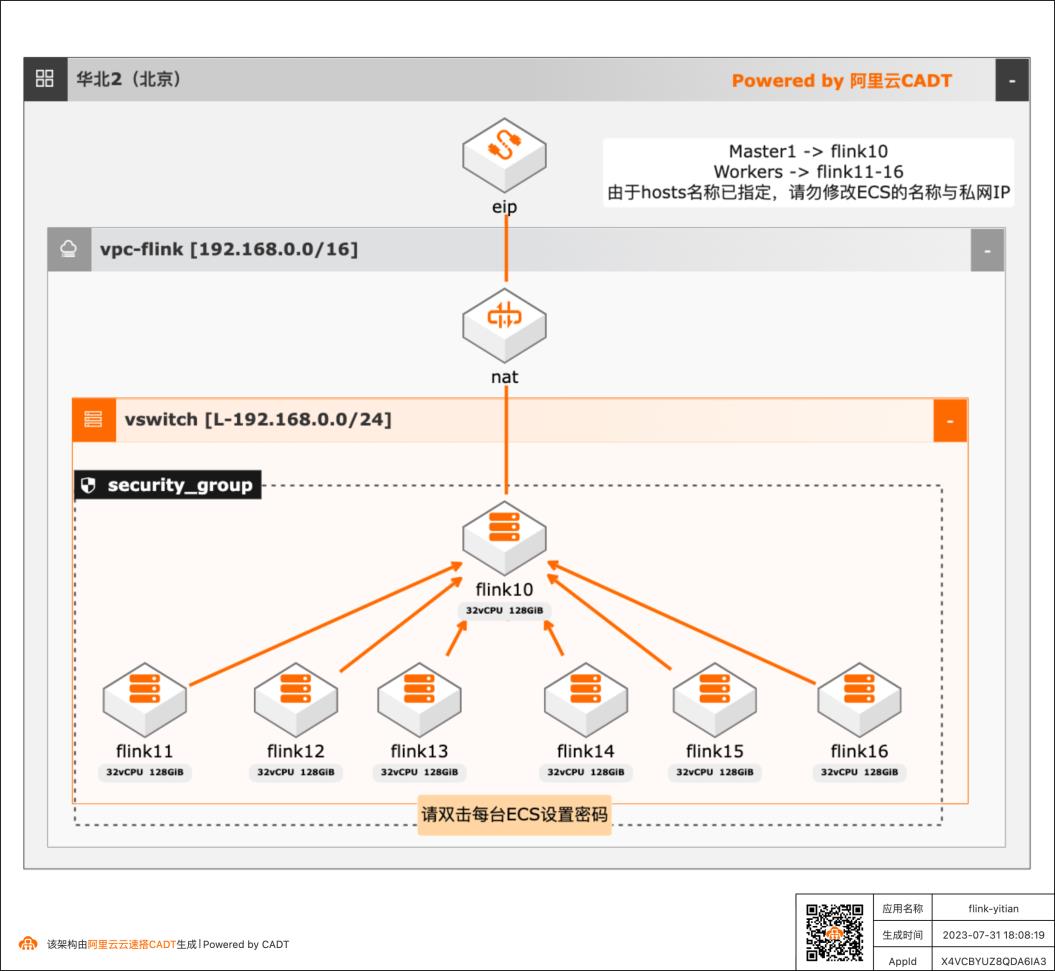
希望了解Flink集群on倚天的部署架构。 通过神龙大数据加速引擎 Mracc 提升Flink集群性能。 希望实测了解倚天ECS实例运行Flink集群的性能 架构设计:利用阿里云官方架构设计模版,在此基础上二次定制(调整规格、资源数量、配置调整)。 快速完成PoC和生产环境的设计和部署
cd/opt/fastmr/nexmark nohup sh test.sh&步骤2 通过日志文件查看压测脚本执行情况 tail-f/opt/fastmr/nexmark/nexmark.out 文档版本:20230801 18 MRACC加速倚天 ECS实例 Spark集群性能 部署基础环境 步骤3 通过日志文件查看压测数据生成进度 测试一共会跑 22个查询,大概需要 50分钟左右,若日志显示了 q22的Nexmark结 果...
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
需要有灵活可扩展的计算平台、弹性可伸缩集群资源及灵活管控的用户 名词解释 Databricks数据洞察:是基于 Apache Spark的全托管大数据分析平台,产品内核 引擎使用 Databricks Runtime,并针对阿里云平台进行优化,使用 Notebook交互 式数据分析,Python库便捷安装,使用 Delta表存储比其他使用 Spark查询性能 有 5-10倍的...
自建Hadoop迁移MaxCompute
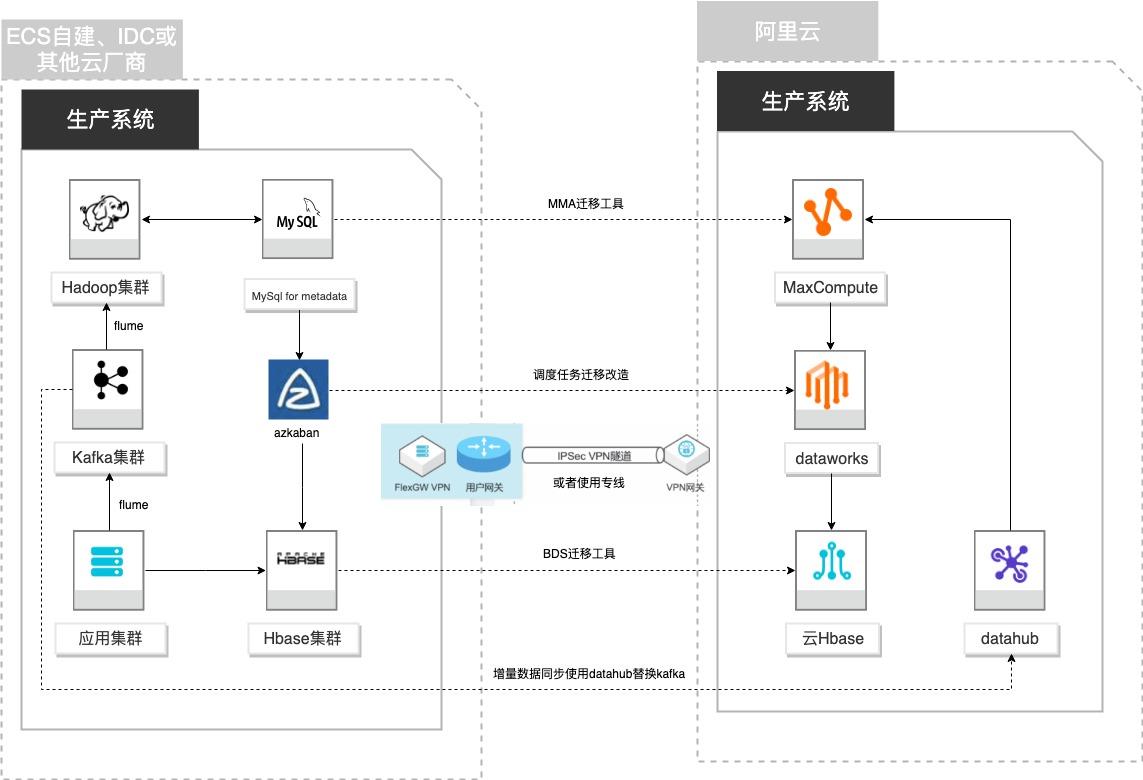
场景描述 客户基于ECS、IDC自建或在友商云平台自建了大数 据集群,为了降低企业大数据计算平台的成本,提高 大数据应用开发效率,更有效保障数据安全,把大数 据集群的数据、作业、调度任务以及业务数据库整体 迁移到MaxCompute和其他云产品。 解决的问题 自建Hadoop集群搬迁到MaxCompute 自建Hbase集群搬迁到云Hbase 自建Kafka或应用数据准实时同步到 MaxCompute 自建Azkaban任务迁移到Dataworks任务 产品列表 MaxCompute,Dataworks、云数据库Hbase版、Datahub、VPC,ECS。
Flume Flume是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日 志数据。它具有基于流数据流的简单灵活的体系结构。它具有可调整的可靠性机 制以及许多故障转移和恢复机制,具有强大的功能和容错能力。它使用一个简单 的可扩展数据模型,允许在线分析应用程序。文档版本:20210723 IV 自建Hadoop迁移...
云消息队列 Kafka 版
云消息队列 Kafka 版是阿里云基于Apache Kafka构建的大数据消息中间件,广泛用于日志收集和分析、数据处理等场景。可提供全托管服务,用户无需部署运维,更专业、更可靠、更安全。
构建日志分析平台.构建日志分析平台.通过云消息队列 Kafka 版可以实时收集网站活动数据(包括用户浏览页面、搜索及其他行为等)。发布-订阅的模式可以根据不同的业务数据类型,将消息发布到不同的 Topic;还可通过订阅消息的实时投递,将消息流用于实时监控与业务分析或加载到 Hadoop、ODPS 等离线数据仓库系统进行离线处理...
来自:
云产品
云消息队列 RocketMQ 版
云消息队列 RocketMQ 版是基于 Apache RocketMQ 构建的分布式消息中间件,广泛用于异步解耦、削峰填谷等场景。可支撑千万级并发、万亿级数据洪峰,更稳定,更安全。
可对接 Storm/Spark 实时流计算引擎,亦可对接 Hadoop/ODPS 等离线数据仓库系统.云消息队列 MQ.实时计算 Flink 版.推荐搭配使用.天猫双11大促,各个分会场琳琅满目的商品需要实时感知价格变化,大量并发访问数据库导致会场页面响应时间长,集中式缓存因为带宽瓶颈限制商品变更的访问流量,通过 RocketMQ 构建分布式缓存,...
来自:
云产品
大数据系统基准性能测试最佳实践
本方案适用于在阿里云上进行大数据基准性能测试的场景,包括 Teragen和Terasort测试,TestDFSIO测试。本文采用CADT工具结合阿里云的E-MapReduce服务快速构建测试集群,并提供了Teragen和Terasort测试,TestDFSIO测试的测试脚本,便于迅速开展测试。
EMR构建于云服务器 ECS上,基于开源的 Apache Hadoop和 Apache Spark,让您可以方便地使用 Hadoop和 Spark生态系统中的其他周边系统分析和 处理数据。EMR还可以与阿里云其他的云数据存储系统和数据库系统(例如,阿 里云 OSS和 RDS等)进行数据传输。EMR的 SmartData组件是 EMR Jindo引 擎的主要存储部分,为 EMR各个计算...
- 产品推荐
- 这些文档可能帮助您