数据管理与服务
数据管理与服务作为阿里云产品六大版块之一,面向不同业务场景,阿里云提供数据存储、分析、应用等全链路能力,满足企业客户全方位的数据处理需求,实现计算和存储分离、资源解耦、数据移动减化,用以满足行业快速发展的需求和趋势,利用数据重塑其业务。
本篇全域数据集成向开发者介绍通过DataWorks数据集成在多表多表、多表到单表、单表到单表等场景下,进行实时或离线同步的技术选型与核心能力,并以MaxCompute与Hologres引擎为例,演示云上数据同步操作步骤最佳实践.全链路数据治理-全域数据集成.2021年10月20日,阿里云正式开源云原生分布式数据库PolarDB-X的源代码,将自...
来自:
云产品
基于Flink+ClickHouse构建实时游戏数据分析
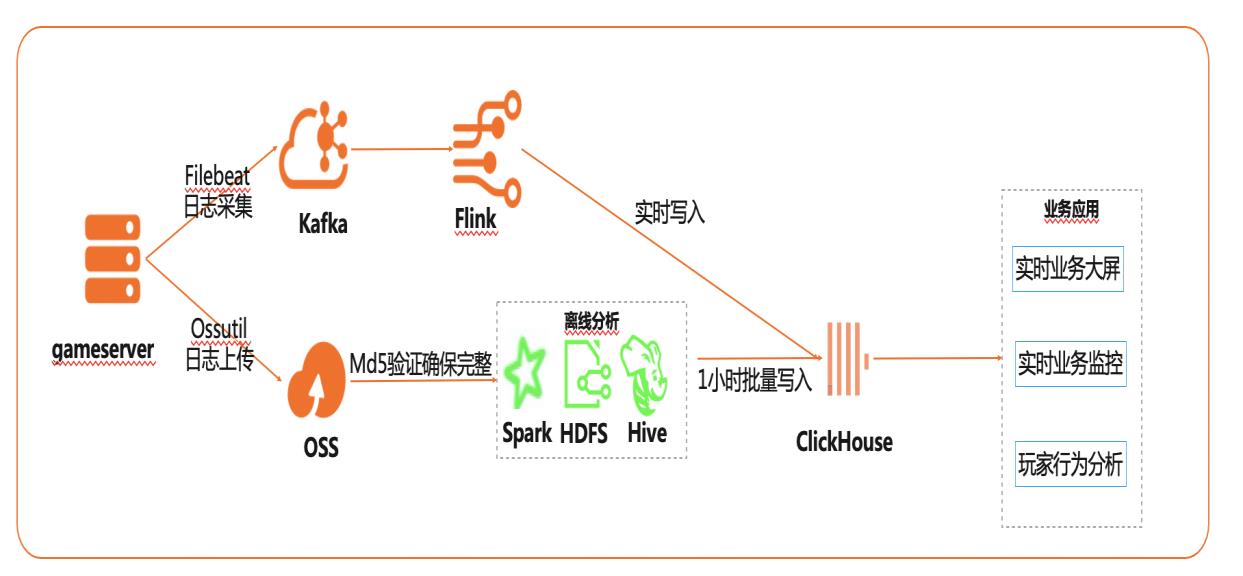
在互联网、游戏行业中,常常需要对用户行为日志进行分析,通过数据挖掘,来更好地支持业务运营,比如用户轨迹,热力图,登录行为分析,实时业务大屏等。当业务数据量达到千亿规模时,常常导致分析不实时,平均响应时间长达10分钟,影响业务的正常运营和发展。 本实践介绍如何快速收集海量用户行为数据,实现秒级响应的实时用户行为分析,并通过实时流计算Flink/Blink、云数据库ClickHouse等技术进行深入挖掘和分析,得到用户特征和画像,实现个性化系统推荐服务。 通过云数据库ClickHouse替换原有Presto数仓,对比开源Presto性能提升20倍。 利用云数据库ClickHouse极致分析性能,千亿级数据分析从10分钟缩短到30秒。 云数据库ClickHouse批量写入效率高,支持业务高峰每小时230亿的用户数据写入。 云数据库ClickHouse开箱即用,免运维,全球多Region部署,快速支持新游戏开服。 Flink+ClickHouse+QuickBI
本实践介绍如何快速收集海量用户行为数 据,实现秒级响应的实时用户行为分析,并 通过实时流计算、云数据库 ClickHouse等 技术进行深入挖掘和分析,得到用户特征和 画像,实现个性化系统推荐服务。产品列表 最佳实践频道 阿里云最佳实践分享群 专有网络 VPC 弹性公网 IP EIP 云服务器 ECS 消息队列 Kafka版 云数据库 ...
云数据库HBase
阿里云云数据库 HBase 版(ApsaraDB for HBase)是基于 Hadoop 且100%兼容HBase协议的高性能、可弹性伸缩、面向列的分布式数据库,轻松支持PB级大数据存储,满足千万级QPS高吞吐随机读写场景。
云数据库 HBase 版是面向大数据领域的一站式NoSQL服务,100%兼容开源HBase并深度扩展,支持海量数据下的实时存储、高并发吞吐、轻SQL分析、全文检索、时序时空查询等能力,是风控、推荐、广告、物联网、车联网、Feeds流、数据大屏等场景首选数据库,是为淘宝、支付宝、菜鸟等众多阿里核心业务提供关键支撑的数据库.Lindorm...
来自:
云产品
云原生大数据计算服务MaxCompute
阿里云云原生大数据计算服务MaxCompute是面向分析的企业级云数仓,作为一体化大数据智能计算平台ODPS的大规模批量计算引擎,MaxCompute以 Serverless 架构提供快速、全托管的在线数据仓库服务,使您经济高效的分析处理海量数据,进行敏捷的业务洞察。
湖仓一体解决方案.5分钟的快速大数据分析方案.海量日志分析解决方案.查看更多>.各行业客户案例与最佳实践>.精选客户案例.资源规划管理及评估>.满足企业现实需求的 Serverless 算力方案,兼顾成本与性能的需要.MaxFrame 邀测.MaxFrame 邀测.MaxFrame 邀测.更多阿里云大数据.MaxCompute 资源抵扣包套餐(500CU*H+100GB存储)...
来自:
云产品
实时数仓Hologres
Hologres(原交互式分析)是一站式实时数据仓库引擎,支持海量数据实时写入、实时更新、实时分析,支持标准SQL(兼容PostgreSQL协议),支持PB级数据多维分析(OLAP)与自助分析(Ad Hoc),支持高并发低延迟的在线数据服务(Serving),与MaxCompute、Flink、DataWorks深度融合,提供离在线一体化全栈数仓解决方案。
某货运物流公司其大数据部门一直在探索建设新一代数仓,但一直没有取得很大突破,无法让数据发挥更大价值。通过Hologres建立的新一代实时数仓,替换原有ES、HBase等架构,解决千万级订单数据实时分析慢和上百万货运司机物流实时调度难的问题.减少了维度退化的设计,支持千万订单数据实时多维分析,提升业务查询灵活性和开发...
来自:
云产品
云数据库产品总览(瑶池)
阿里云提供完善的数据库解决方案,多款数据库产品,满足99%的业务场景,荣获Gartner、信通院等国内外多项认证。轻松满足高可靠、高可用性、高性能等数据库需求;运维工作量大幅减少,让企业一站式享受数据上云及分布式架构的技术红利!
本方案向客户提供ADB+DLA的数据仓库组合,完美解决大数据量分析和运营效率问题,实现海量数据实时写入和复杂ETL计算,用户画像、交互报表、实时数据服务等查询加速需求.ADB MySQL版完全兼容MySQL的语法和使用习惯,上手成本低.将重分析类SQL从RDS切换到ADB高性能库,亿级数据实时秒级拉取,可支持单表记录数百亿级.ADB支持...
来自:
云产品
容器服务Serverless版
容器服务Serverless版是一款基于阿里云弹性计算基础架构,完全兼容Kuberentes生态,安全、可靠的容器产品。通过该产品,无需管理和维护节点即可快速创建Kuberentes容器应用,并且根据应用配置的CPU和内存资源量按需付费,使您更专注应用本身,而非运行应用的基础设施。
根据业务数据处理需求,能够在短时间内快速创建大量计算任务,满足业务的大数据及 AI 在线处理诉求,广泛应用在 Spark、Presto 等数据计算场景.使用 ACK Serverless 集群无需进行容量规划,按需创建应用,降低计算成本.资源池闲置率高,成本居高不下.容器镜像服务 ACR.基于 Serverless 弹性低成本进行数据计算.使用 ACK ...
来自:
云产品
开源Flink迁移实时计算Flink全托管版最佳实践
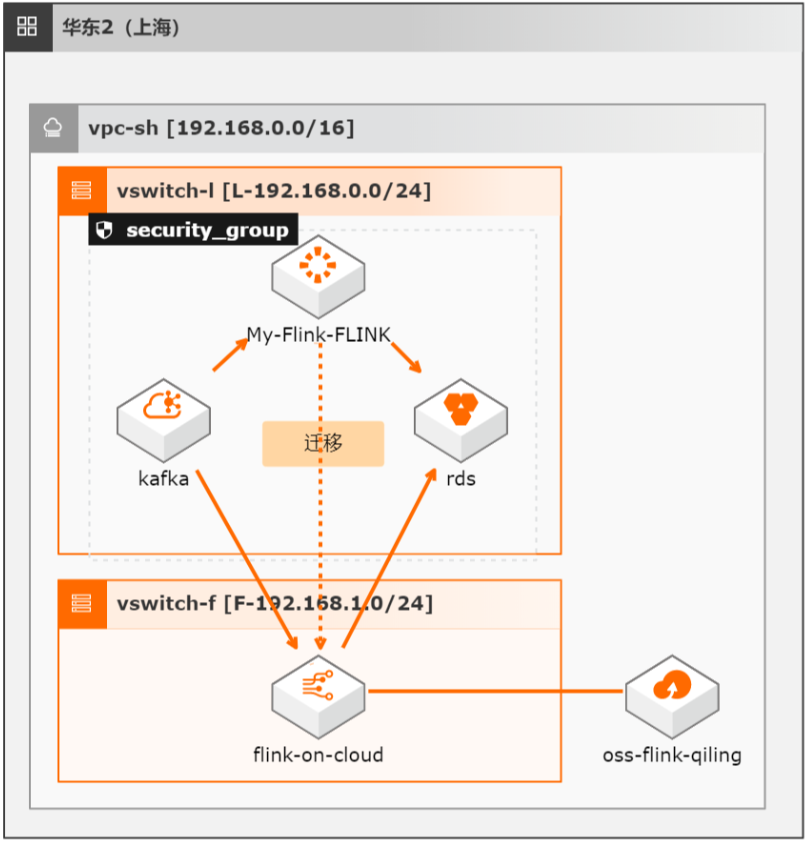
本方案介绍如何将自建开源Flink集群的流式任务(包含Datastream、Table/SQL、PyFlink任务)迁移至阿里云实时计算全托管版。
比如聚合任务按小时、天维度计算的聚合值,清洗任务加工的按天分区表等,在数据对比时就可以根据对应的时间周期来进对比,比如小时周期的任务实际已完整处理多个小时数据 后,就可以对比处理过的小时数 据,而天维度的聚合值,一般就需要等待新任务处理完完整的一天数 据后才能对比。2、数据规模 中小数据规模:建议进行全量...
多账号下企业分账
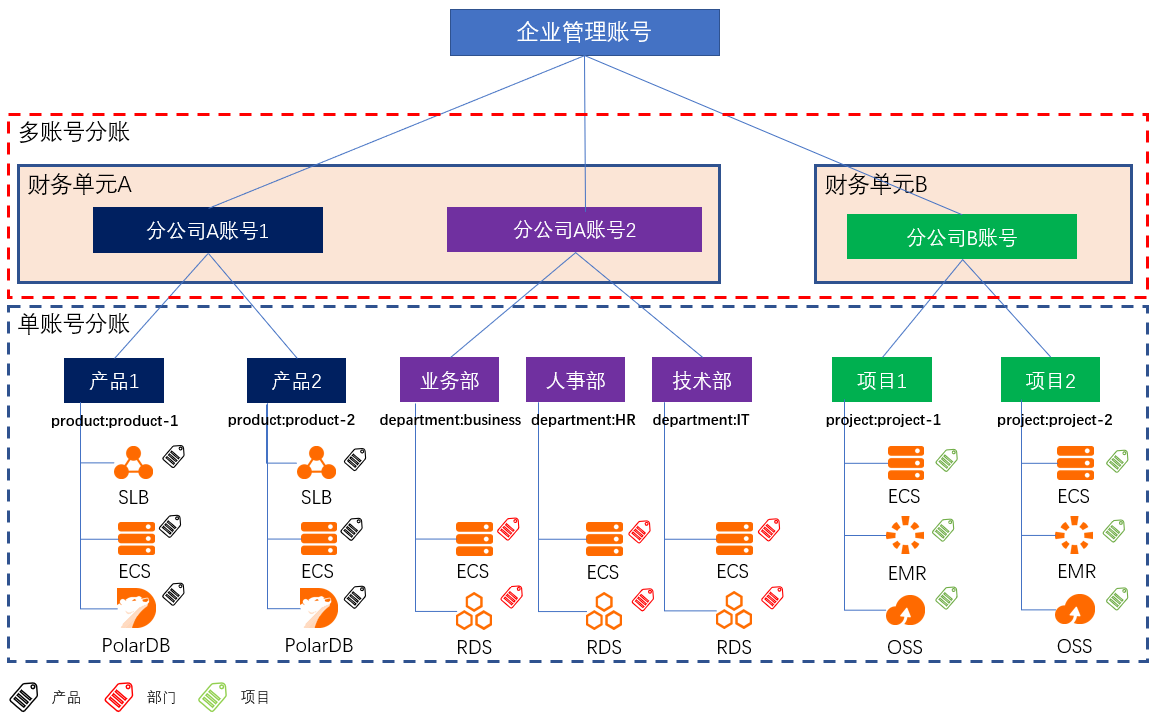
场景描述 财务分账,是根据企业的成本中心,将云上资源的成本划分到给各个项目组/业务部门;助力企业快速梳理云上成本结构,搭建复杂组织架构下的成本关系,便捷地进行财务和云上成本的管理。 大型企业或集团公司,由于组织架构复杂,业务复杂等原因,通常拥有多个阿里云账号来管理规模庞大的云上资源。针对云上资源,如何建立有效的分账方案,是财务关注的重要问题。 解决问题 解决CIO/CTO最关心的云上IT治理,IT成本核算等问题。 弄清楚企业内各部门成本及云上IT成本结构。 让CIO/CTO准确地掌握云上资源成本情况,清楚业务与成本的关系。 让采购/运维轻松搞定每月的IT成本汇报。
提供用户在云上 使用开源技术建设数据仓库、离线批处理、在线流式处理、即时查询、机器学习等 场景下的大数据解决方案。详见:https://www.aliyun.com/product/emapreduce 云架构设计工具 CADT:是一款为上云应用提供自助式云架构管理的产品,显著 地降低应用云上管理的难度和时间成本。本产品提供丰富的预制应用架构模板,...
SLS数据入湖Kafka最佳实践
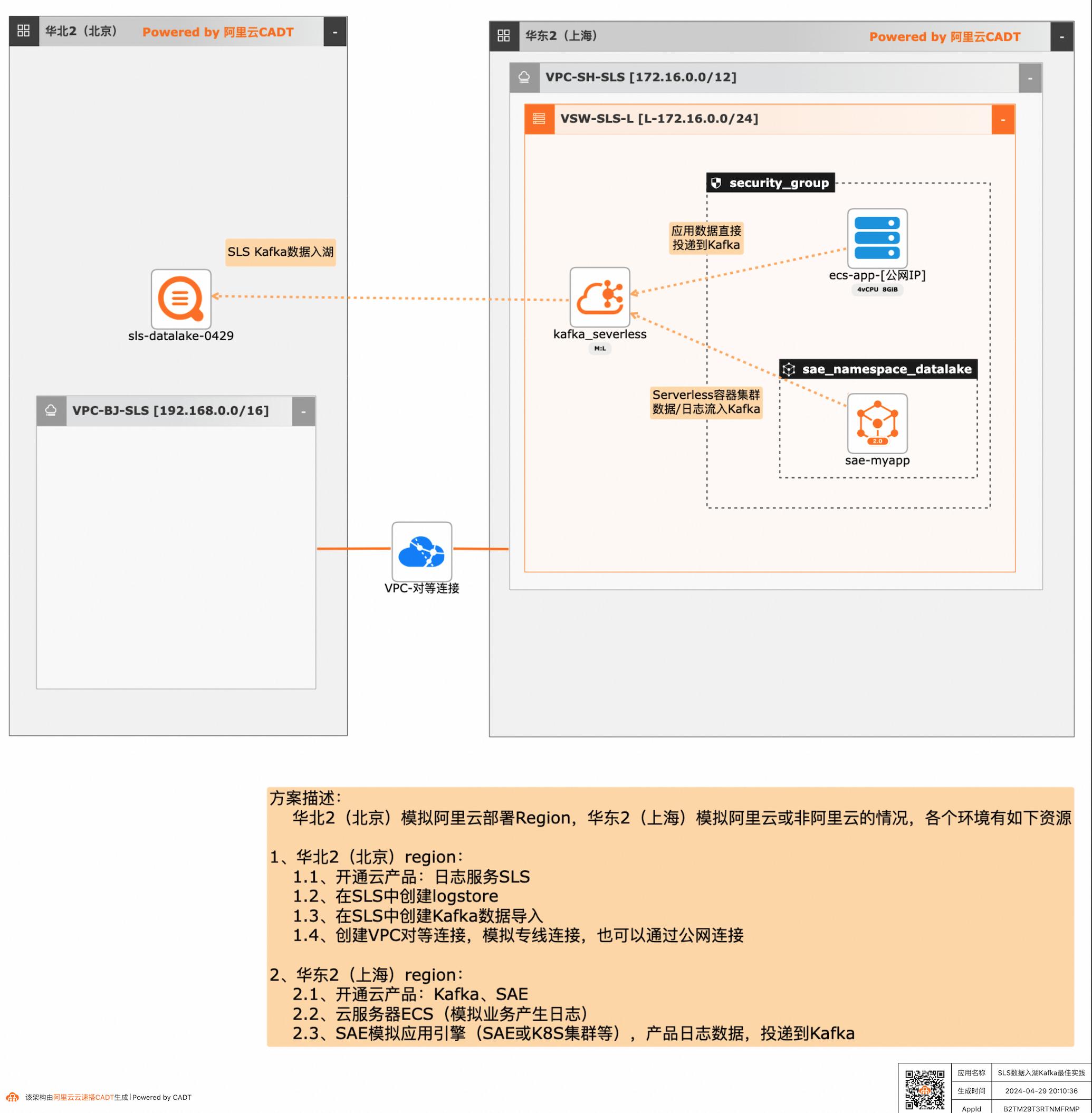
应用和数据分散在多云或混合云,在面对多云/混合云这样大的趋势下,数据无法进行统一的聚合、分析处理和导出等,本方案给出了在多云/混合云场景下,构建通过标准的Kafka协议和托管服务,SLS可以连接Kafka数据入湖导入,然后进行统一的海量数据的集中存储、智能转储、聚合分析查询等。
SLS 数据入湖 Kafka 最佳实践 业务架构 场景描述 应用和数据分散在多云或混合云,在面对多云/混合云这样大的趋势下,数据无法进行统一的 聚合、分析处理和导出等,本方案给出了在多 云/混合云场景下,构建通过标准的Kafka协议 和托管服务,SLS可以连接Kafka数据入湖导 入,然后进行统一的海量数据的集中存储、智 能转储、...
Spark on ECI大数据分析

场景描述 方案优势 1.计算引擎弹性扩缩容,兼顾资源弹性与计 算资源成本优化。 2.计算与存储分离架构,结合阿里云原生云 存储产品,海量数据湖优势。 3.Kubernetes原生的调度性能优势,提升在 大规模分析作业时的分析性能优势分。 4.集群资源隔离和按需分配。 解决问题 1.计算资源弹性能力不足,计算资源成本管 控能力欠缺. 2.集群资源调度能力和隔离能力不足。 3.计算与存储无法分离,大数据量分析时出 现数据存储资源瓶颈。 4.Spark submit方式提交分析作业参数支持 有限等缺点。 产品列表 容器服务Kubernetes版(ACK) 弹性容器实例(ECI) 文件存储HDFS 对象存储OSS 专有网络VPC 容器镜像服务ACR
应用范围 需要使用 Spark on Kubernetes解决方案的用户 对 Spark大数据分析平台计算资源成本控制考虑的用户 需要有灵活可扩展计算平台资源弹性及管控的用户 名词解释 文件存储 HDFS:阿里云文件存储 HDFS是面向阿里云 ECS实例及容器服务等计 算资源的文件存储服务,允许用户像在 Hadoop分布式文件系统中管理和访问数 据,...
通过ES兼容接口方式使用Kibana访问SLS数据
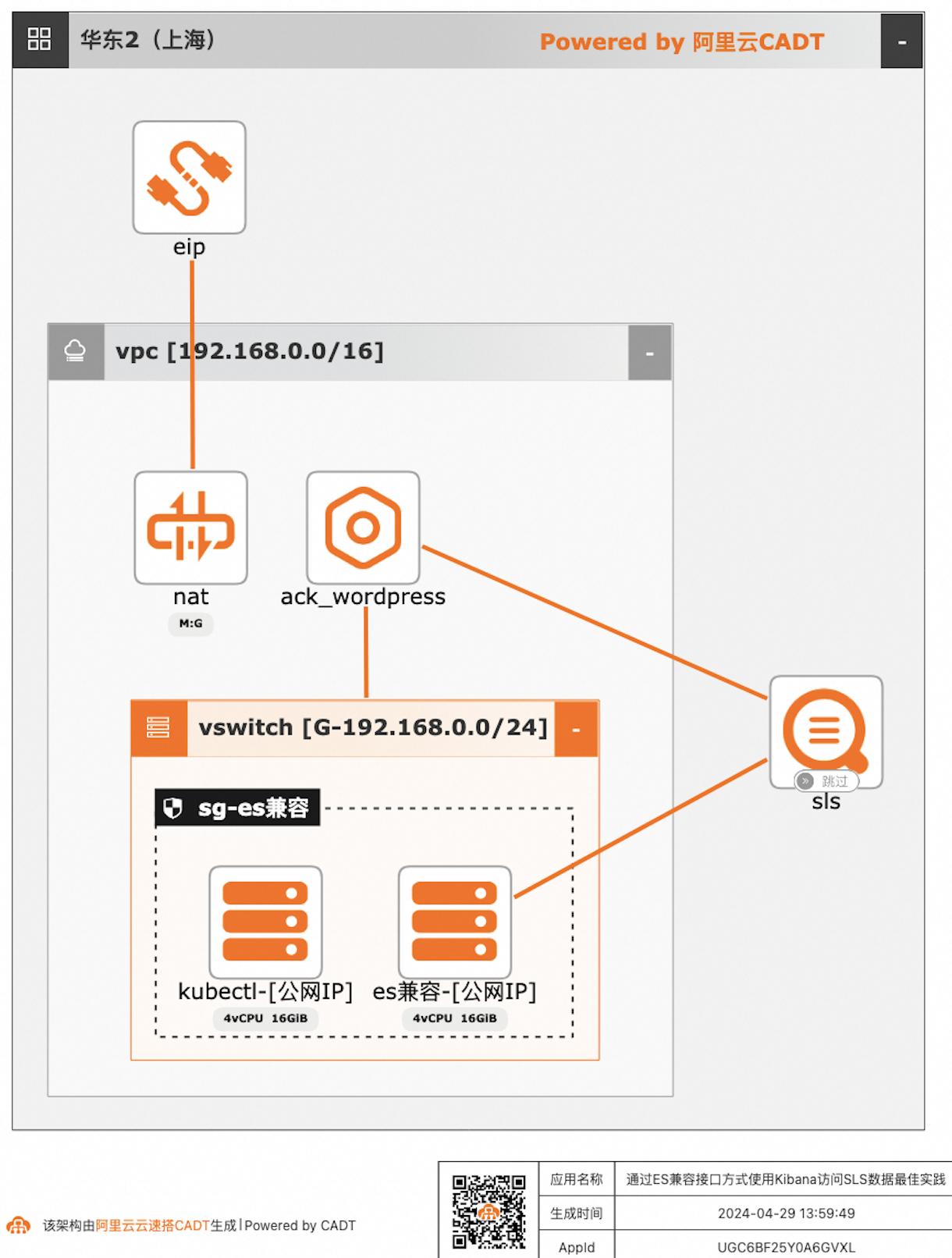
自建ELK日志系统的客户迁移到阿里云日志服务SLS后,对SLS查询分析语法不太熟悉的客户,可以继续沿用原有的查询分析习惯,在不改变使用方式习惯的情况下,通过Elasticsearch兼容接口的方式使用Kibana访问SLS。
通过ES兼容接口方式使用Kibana访问SLS数据最佳实践 业务架构 场景描述 日志服务SLS提供Elasticsearch兼容接口,支 持客户将日志采集到日志服务后,仍可以继续沿 用Elasticsearch的查询方案,即通过使用 Kibana访问日志服务的Elasticsearch兼容接 口,实现查询SLS数据。应用场景 自建ELK日志系统的客户迁移到阿里云日志服 务...
ECS 数据备份与保护
随着企业核心业务规模不断扩大,需要根据业务需求对生产环境中的关键数据进行定期备份。
产品解决方案文档与社区权益中心定价云市场合作伙伴支持与服务了解阿里云备案控制台ECS 数据备份与保护方案介绍方案优势应用场景方案部署ECS 数据备份与保护随着企业核心业务规模不断扩大,需要根据业务需求对生产环境中的关键数据进行定期备份,在发生误操作、病毒感染、或攻击等情况时,能够快速从已有的快照恢复到某个...
来自:
解决方案
基于弹性供应组构建大数据分析集群
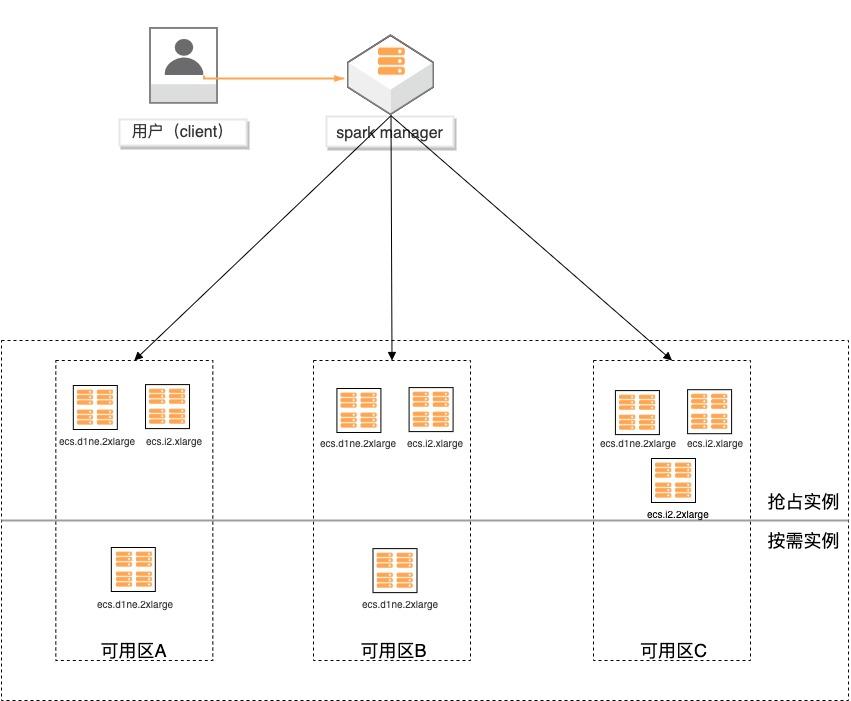
场景描述 基于弹性供应组(APG)搭建spark计算集 群,提供一键开启跨售卖方式、跨可用区、 跨实例规格的计算集群交付模式的实践。 方案优势 1.超低成本:跨售卖方式提供计算实 例,按秒计费,可全部使用spot实例 交付,最高可省90%成本。 2.稳定可靠:跨可用域、跨实例规格, 降低spot被集体释放的风险;自动托 管,分钟级巡检,动态保证集群的算 力。 3.快速交付:单次可在5分钟内交付 2000个实例。 4.多策略组合:可分别指定spot和按量 实例的交付策略,以及差额补足的策 略,包括成本最低、打散和折中。 解决问题 1.大规模计算集群成本高。 2.创建ECS实例方式单一,无法跨计费 方式、可用区及规格等核心参数。 3.当可用区资源紧张,无法自动保证基于 spot类型的稳定算力。 产品列表 专有网络VPC 云服务器ECS
本文采用 spark standalone集群模式演示基于弹性供应组构建大数据分析集群,spark standalone集群如下图所示:鉴于大数据集群对 IO高性能的要求,采用阿里云云服务器 ECS本地盘实例:D系列 和 I系列来作为 spark集群节点。1.2.集群计算能力规划 基于降成本的需要,您可以使用弹性供应组同时开出抢占式实例和按量付费实例,...
- 产品推荐
- 这些文档可能帮助您