云数据库MongoDB版
阿里云云数据库MongoDB版是完全兼容MongoDB协议、高度兼容DynamoDB协议的在线文档型数据库服务。支持单节点、双节点、副本集和分片集群四种部署架构,能够满足不同的业务场景需要。
例如与阿里云原生数据湖分析服务DLA的Serverless Spark对接,满足在线交互式查询、批处理、机器学习等诉求.Serverless Spark对接MongoDB快速入门.云上云下数据互通,大数据Spark系统对接应用.数据生态:数据自由流转,应用更灵活.提供CPU利用率、IOPS、连接数、磁盘空间等实例信息实时监控及报警,随时随地了解实例动态....
来自:
云产品
云数据库ClickHouse
云数据库ClickHouse 是阿里云提供的分布式实时分析型列式数据库服务。具有高性能、开箱即用、企业特性支持。广泛应用于流量分析、广告营销分析、行为分析、人群划分、客户画像、敏捷BI、数据集市、网络监控、分布式服务和链路监控等业务场景。
使用限制,引擎选择,资源队列.MaxComputer,MySQL,OSS,SLS,Spark,Flink 数据导入.SQL Server是发行最早的商用数据库产品之一,支持复杂的SQL查询,性能优秀,对基于Windows平台.NET架构的应用程序具有完美的支持.云数据库RDS SQL Server 版.高可靠双机热备架构及可无缝扩展的集群架构,满足高读写性能场景及容量需弹性...
来自:
云产品
湖仓一体架构EMR元数据迁移DLF
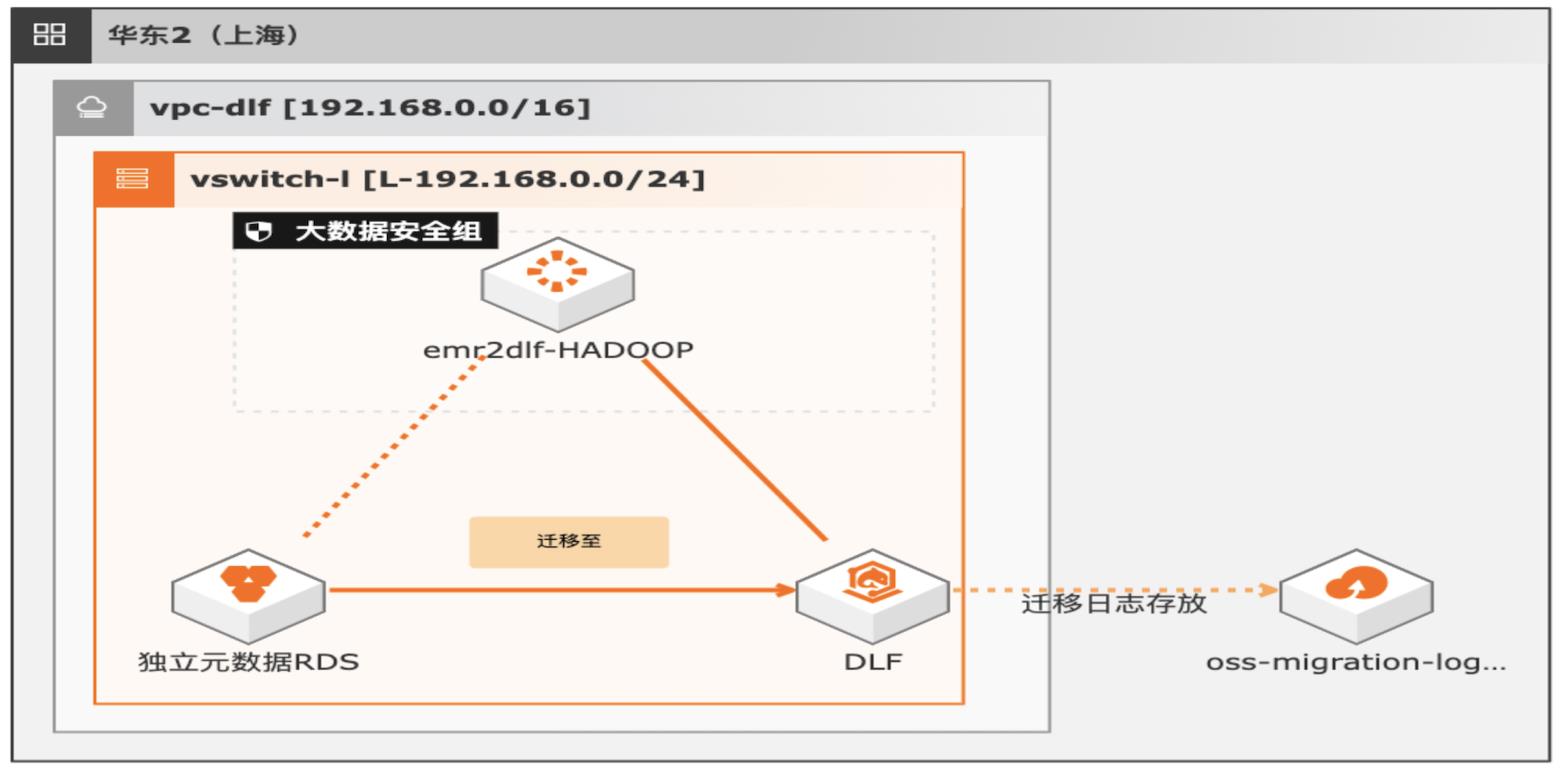
通过EMR+DLF数据湖方案,可以为企业提供数据湖内的统一的元数据管理,统一的权限管理,支持多源数据入湖以及一站式数据探索的能力。本方案支持已有EMR集群元数据库使用RDS或内置MySQL数据库迁移DLF,通过统一的元数据管理,多种数据源入湖,搭建高效的数据湖解决方案。
命令参考:spark-submit \-master yarn \-deploy-mode client \-driver-memory 2G \-executor-memory 2G \-executor-cores 4 \-num-executors 3 \-conf spark.sql.shuffle.partitions=200 \-conf spark.kryoserializer.buffer.max=128m \-conf spark.sql.autoBroadcastJoinThreshold=-1 \-conf spark.sql.adaptive.enabled=...
日志服务sls
日志服务(Log Service,简称Log)是针对实时数据一站式服务,在阿里集团经历大量大数据场景锤炼而成。无需开发就能快捷完成数据采集、消费、投递以及查询分析等功能,帮助提升运维、运营效率,建立DT时代海量日志处理能力。
全面兼容Flink,Spark等流批数据分析平台.具备PB/Day规模弹性伸缩能力;支持按量付费,仅需为实际用量付费,TCO降低50%以上.支持Log/Metric/Trace统一采集,支持服务器/应用/移动设备/网页/IoT等数据源接入,支持阿里云产品/开源系统/云间/云下日志数据接入.40+成熟接入方案,多客户端统一采集,支持内网、公网、全球加速...
来自:
云产品
云数据库HBase
阿里云云数据库 HBase 版(ApsaraDB for HBase)是基于 Hadoop 且100%兼容HBase协议的高性能、可弹性伸缩、面向列的分布式数据库,轻松支持PB级大数据存储,满足千万级QPS高吞吐随机读写场景。
综合存储成本下降80%.HBase支持Spark Streaming流式处理,满足实时业务场景.高效流式处理.可以通过 BulkLoad 将海量全量数据快速导入HBase,轻松应对 百TB级海量数据快速写入HBase.海量全量数据快速导入.云服务器 ECS.推荐搭配使用.海量数据存储与分析场景.支持海量全量数据存储和分析.存储用户行为数据,构建用户画像,...
来自:
云产品
CDH迁移升级CDP最佳实践
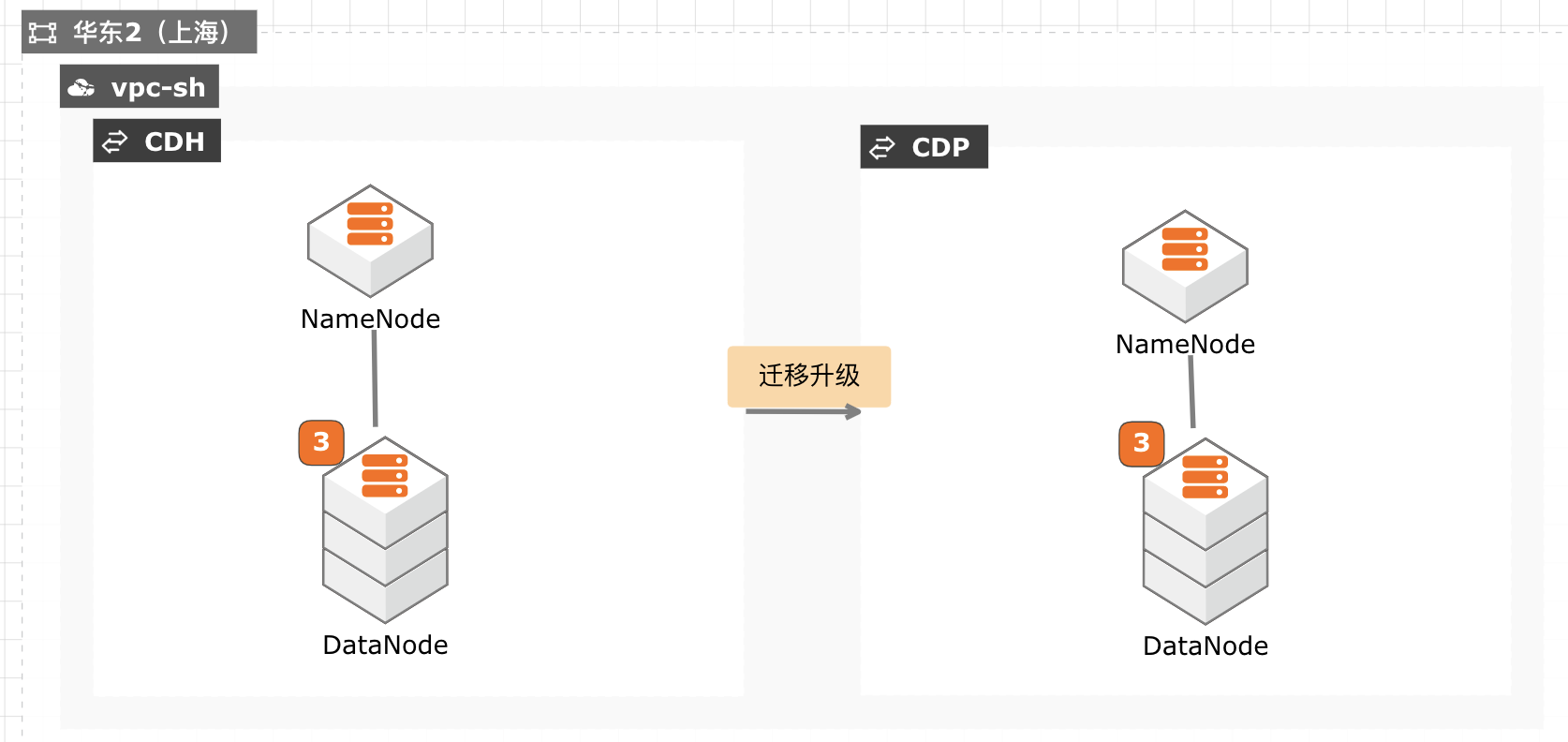
当前 CDH 免费版停止下载,终止服务,针对需要企业版服务能力并且CDH 升级过程对业务影响较小的客户,通过安装新的 CDP 集群,将现有数据拷贝至新集群,然后将新集群切换为生产集群,升级过程没有数据丢失风险,停机时间较短,适合大部分互联网客户升级使用。
安装 Spark2 说明:由于 Kudu迁移工具需 Spark2支持,CDH5可以支持 Spark和 Spark2两个环 境同时运行,如果集群上没有 Spark2请先进行安装。已经安装的略过此步骤。另外,kudu迁移也可以使用 kudu table copy来实现,也不需要安装 Spark2。把 Sparks2的安装包移动到/opt/cloudera/csd/目录下。mv cdh/spark2/*/opt/cloudera...
中小企业CDH集群上云升级CDP解决方案
中小企业 CDH 集群上云升级 CDP 解决方案,助力原 CDH/HDP 的用户快捷升级到企业级 CDP 环境,并链接阿里云相关产品服务。同时,基于阿里云便捷的基础网络设施和云网络服务,能够快速构建云上云下互联的混合云架构。
基于 Apache Kafka,构建高性能、高可用的流式消息平台,并集合流式场景的其他工具如 NiFi、Flink、Spark Streaming 等,统一通过 CDP 开展相关工作.流式消息处理.流式消息处理.准实时分析需要对变化中的数据提供快速分析能力,包括结合历史数据和实时流数据进行汇总分析、预测和明细查询。在 CDP 平台上通过使用 Kudu+...
来自:
解决方案
中小企业自建Hadoop集群上云解决方案
中小企业自建 Hadoop 集群上云解决方案,助力自建 Hadoop 用户快速构建云上半托管开源大数据平台,在保持原组件使用习惯延续的同时,充分利用云上服务特点,更加便捷地迭代企业大数据平台架构,聚焦业务价值开发。
提供高性能、稳定版本 Hadoop、Spark、Hive、Flink、Kafka、Hbase、Presto、Impala、Hudi、ClickHouse 等开源大数据组件,可根据场景灵活搭配使用。采用 JindoFS+OSS,在保证数据可靠性的基础上,性能大幅提升.开源生态,性能优化.分钟级创建集群,支持对集群、节点和服务进行监控和运维操作,大幅提升运维工作效率,让数据...
来自:
解决方案
容器服务Serverless版
容器服务Serverless版是一款基于阿里云弹性计算基础架构,完全兼容Kuberentes生态,安全、可靠的容器产品。通过该产品,无需管理和维护节点即可快速创建Kuberentes容器应用,并且根据应用配置的CPU和内存资源量按需付费,使您更专注应用本身,而非运行应用的基础设施。
根据业务数据处理需求,能够在短时间内快速创建大量计算任务,满足业务的大数据及 AI 在线处理诉求,广泛应用在 Spark、Presto 等数据计算场景.使用 ACK Serverless 集群无需进行容量规划,按需创建应用,降低计算成本.资源池闲置率高,成本居高不下.容器镜像服务 ACR.基于 Serverless 弹性低成本进行数据计算.使用 ACK ...
来自:
云产品
云数据库产品总览(瑶池)
阿里云提供完善的数据库解决方案,多款数据库产品,满足99%的业务场景,荣获Gartner、信通院等国内外多项认证。轻松满足高可靠、高可用性、高性能等数据库需求;运维工作量大幅减少,让企业一站式享受数据上云及分布式架构的技术红利!
基于HBase SQL服务(Phoenix)+Spark构建实时计算和数据仓库解决方案,HBase SQL提供在线查询能力、Spark提供流式处理、复杂分析等能力,满足业务需求.借助PolarDB快速的弹性能力,在业务的高峰期临时增加数据库配置和集群规模,日常业务再进行降配操作,灵活应对业务变化,与之前的方案相比整体成本大大降低.阿里云Redis支持...
来自:
云产品
一键训练大模型及部署GPU共享推理服务
通过创建ACK集群Pro版,使用云原生AI套件提交模型微调训练任务与部署GPU共享推理服务。支持快速创建Kubernetes集群,白屏配置任务数据共享存储和下载,并通过命令行工具Arena快速提交模型训练任务、部署推理服务。使用云原生AI套件可以让模型训练和推理提效,提高GPU资源利用率。
高效运行AI等异构工作负载云原生AI套件兼容Tensorflow、Pytorch、Horovod、Spark、Flink等主流开源或者用户自有的各种计算引擎和运行时,统一运行各类异构工作负载,统一管理作业生命周期,统一调度任务工作流,保证任务规模和性能。云原生AI套件一方面不断优化运行任务的性能、效率和成本,另一方面持续改善开发运维体验和...
来自:
解决方案
数据湖构建 Data Lake Formation
数据湖构建服务是阿里云上数据湖架构中的核心部分,助力用户构建数据湖系统。支持多数据源实时入湖,实现湖上元数据统一管理,提供企业级权限控制,无缝对接多种计算引擎,打破孤岛,洞察业务价值
构建在阿里云云服务器 ECS 上的开源 Hadoop、Spark、HBase、Hive、Flink 生态大数据 PaaS 产品.提供快速、完全托管的PB级数据仓库解决方案,经济并高效的分析处理海量数据.大数据计算服务·MaxCompute.兼容PostgreSQL协议的实时交互式分析产品.海量、安全、低成本、高可靠的云存储服务,提供99.9999999999%的数据可靠性....
来自:
云产品
EMR HBase on OSS存算分离集群快速恢复
OSS-HDFS服务(JindoFS服务)是一款云原生数据湖存储产品。基于统一的元数据管理能力,在完全兼容HDFS文件系统接口的同时,提供充分的POSIX能力支持,能更好地满足大数据和AI等领域的数据湖计算场景。
服务特性 OSS-HDFS服务支持的特性如下:HDFS兼容访问 OSS-HDFS 服务完全兼容 HDFS 接口,同时支持目录层级的操作,您只需集成 JindoSDK,即可为 Apache Hadoop的计算分析应用(例如 MapReduce、Hive、Spark、Flink等)提供了访问 HDFS服务的能力,像使用 Hadoop分布式文件系 统(HDFS)一样管理和访问数据。POSIX能力支持 ...
EMR本地盘实例大规模数据集测试
场景描述 阿里云为了满足大数据场景下的存储需求,在云 上推出了本地盘D1机型,这个系列提供了本地 盘而非云盘作为存储,提高了磁盘的吞吐能力, 发挥Hadoop的就近计算优势。阿里云EMR 产品针对本地盘机型,推出了一整套的自动化运 维方案,帮助用户方便可靠地使用本地盘机型, 不需要关注整个运维过程同时数据的高可靠和 服务的高可用。 解决问题 1.云盘多份冗余数据导致成本高 2.磁盘吞吐量不高 3.节点的高可靠分布问题 4.本地盘与节点的故障监控问题 5.数据迁移时自动决策问题 6.自动故障节点迁移与数据平衡问题 产品列表 EMR(E-MapReduce) 本地盘 VPC
EMR:E-MapReduce(EMR)是构建在阿里云云服务器 ECS上的开源 Hadoop、Spark、Hive、Flink 生态大数据产品,提供用户在云上使用开源技术建设数据仓 库、离线批处理、在线学习、即时查询、机器学习等场景下的大数据解决方案。PT测试:Power Test(PT)功耗测试,TPC-DS用于大数据性能测试的方法。大数据实例本地盘:阿里云为了...
大数据系统基准性能测试最佳实践
本方案适用于在阿里云上进行大数据基准性能测试的场景,包括 Teragen和Terasort测试,TestDFSIO测试。本文采用CADT工具结合阿里云的E-MapReduce服务快速构建测试集群,并提供了Teragen和Terasort测试,TestDFSIO测试的测试脚本,便于迅速开展测试。
EMR构建于云服务器 ECS上,基于开源的 Apache Hadoop和 Apache Spark,让您可以方便地使用 Hadoop和 Spark生态系统中的其他周边系统分析和 处理数据。EMR还可以与阿里云其他的云数据存储系统和数据库系统(例如,阿 里云 OSS和 RDS等)进行数据传输。EMR的 SmartData组件是 EMR Jindo引 擎的主要存储部分,为 EMR各个计算...
- 产品推荐
- 这些文档可能帮助您