Spark on ECI大数据分析

场景描述 方案优势 1.计算引擎弹性扩缩容,兼顾资源弹性与计 算资源成本优化。 2.计算与存储分离架构,结合阿里云原生云 存储产品,海量数据湖优势。 3.Kubernetes原生的调度性能优势,提升在 大规模分析作业时的分析性能优势分。 4.集群资源隔离和按需分配。 解决问题 1.计算资源弹性能力不足,计算资源成本管 控能力欠缺. 2.集群资源调度能力和隔离能力不足。 3.计算与存储无法分离,大数据量分析时出 现数据存储资源瓶颈。 4.Spark submit方式提交分析作业参数支持 有限等缺点。 产品列表 容器服务Kubernetes版(ACK) 弹性容器实例(ECI) 文件存储HDFS 对象存储OSS 专有网络VPC 容器镜像服务ACR
文档版本:20200409 16 Spark on ECI大数据分析 应用开发 文档版本:20200409 17 Spark on ECI大数据分析 Spark on Kubernetes实践方案对比 3.Spark on Kubernetes实践方案对比 本章中,我们首先通过 Spark on 阿里云容器服务 Kubernetes版(ACK)并结合 Kubernetes原生的技术说明来解释 Spark on Kubernetes架构相比传统的...
E-MapReduce Serverless Spark 版
E-MapReduce Serverless Spark 是阿里云 E-MapReduce 基于 Spark 提供的一款全托管、一站式的数据计算平台。它为用户提供任务开发、调试、发布、调度和运维等全方位的产品化服务,显著简化了大数据计算的工作流程,使用户能更专注于数据分析和价值提炼。
得益于其开放的产品架构,EMR Serverless Spark 使得在数据湖中对结构化和非结构化数据进行分析与处理变得简单高效。此外,其还内置了任务调度系统,允许用户轻松构建和管理数据 ETL 任务,实现数据管道的自动化和周期性数据处理。EMR Serverless Spark 还内嵌了先进的版本管理系统,并提供了开发与生产环境的完全隔离,...
来自:
云产品
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
需要有灵活可扩展的计算平台、弹性可伸缩集群资源及灵活管控的用户 名词解释 Databricks数据洞察:是基于 Apache Spark的全托管大数据分析平台,产品内核 引擎使用 Databricks Runtime,并针对阿里云平台进行优化,使用 Notebook交互 式数据分析,Python库便捷安装,使用 Delta表存储比其他使用 Spark查询性能 有 5-10倍的...
云原生大数据计算服务MaxCompute
阿里云云原生大数据计算服务MaxCompute是面向分析的企业级云数仓,作为一体化大数据智能计算平台ODPS的大规模批量计算引擎,MaxCompute以 Serverless 架构提供快速、全托管的在线数据仓库服务,使您经济高效的分析处理海量数据,进行敏捷的业务洞察。
内建Apache Spark引擎,提供完整的Spark功能;与MaxCompute计算资源、数据和权限体系深度集成.集成对数据湖(OSS或Hadoop HDFS)的访问分析,支持外表映射、Spark直接访问方式开展数据湖分析;在一套数仓服务和用户接口下,实现湖与仓的关联分析.支持流式采集和近实时分析.支持流式数据实时写入并在数据仓库中开展分析;与...
来自:
云产品
表格存储Tablestore
表格存储Tablestore是阿里云自研的面向海量结构化数据存储的Serverless分布式数据库,它可提供低成本、高性能的存储方案,同时也可提供稳定与极致的数据服务。
与Maxcompute、Spark、Flink等计算引擎集成,与Kafka、数据集成等链路组件无缝打通.易集成生态丰富.“存”享优惠,新老同享.一站式物联网存储解决方案.物联网数据存储发布会.存储标杆案例样板间重磅上线.表格存储支持数据投递数据湖OSS.表格存储支持Spark访问索引加速.表格存储支持通过DTS实时同步MySQL数据.表格存储产品...
来自:
云产品
云原生数据仓库AnalyticDB MySQL数据仓库
阿里云云原生数据仓库AnalyticDB MySQL版(简称AnalyticDB)是融合数据库、大数据技术于一体的云原生企业级数据仓库平台。云原生数据仓库AnalyticDB MySQL版支持数据实时写入和同步更新、实时计算和实时服务,可用于构建企业级报表系统、数据仓库和数据服务引擎。
——打造一站式实时湖仓,可替换CDH/TDH/开源自建/云服务-Spark/Hive/Presto等.AnalyticDB MySQL湖仓版重磅发布.最佳实践和社区文章.支持按小时设置计算资源弹性扩容规则,解决计算资源峰谷需求问题,降低计算资源成本.白天工作高峰期,准时弹出计算资源,让业务查询更快,提高应用体验.白天查询业务高峰.晚上ETL高峰期,...
来自:
云产品
实时数仓Hologres
Hologres(原交互式分析)是一站式实时数据仓库引擎,支持海量数据实时写入、实时更新、实时分析,支持标准SQL(兼容PostgreSQL协议),支持PB级数据多维分析(OLAP)与自助分析(Ad Hoc),支持高并发低延迟的在线数据服务(Serving),与MaxCompute、Flink、DataWorks深度融合,提供离在线一体化全栈数仓解决方案。
与Flink、Spark等计算框架原生集成,通过内置Connector,支持高通量数据实时写入与更新,支持源表、结果表、维度表多种场景,支持多流合并等复杂操作.所见即所得的开发.数据实时写入即可查询,支持DB、Schema、Table三级体系,支持视图View,原生支持Update/Delete,支持关联、嵌套、窗口等丰富表达能力,支持半结构JSON...
来自:
云产品
云数据库 SelectDB 版
阿里云数据库 SelectDB 是现代化实时数据仓库 SelectDB 在阿里云上的全托管服务,内核基于业界领先的开源分析型数据库 Apache Doris 研发,由阿里云和飞轮科技联合打造。阿里云数据库 SelectDB 聚焦于满足企业级大数据分析需求,广泛应用于实时报表分析、即席多维分析、日志检索分析、数据联邦与查询加速等场景,致力于为客户提供极致性能、简单易用的数据分析服务。
简化统一开发体验基于 SelectDB 的湖仓互通、轻量级 ELT 能力,无缝完成数据源到数仓的数据同步、清洗过程,无需依赖 Spark 和 Flink。使用 SelectDB 作为统一查询网关,无需进行多系统切换及 SQL 方言兼容处理。极速数据分析基于 SelectDB 领先的查询分析引擎,结合数据缓存、统计信息收集等,SelectDB 分析性能可达 ...
来自:
云产品
Databricks数据洞察
阿里云Databricks数据洞察是基于Apache Spark的全托管数据分析平台, 内核采用更高效、稳定的商业版Databricks Runtime和Delta Lake。可满足数据分析师、数据工程师和数据科学家在大数据场景下对数据湖分析、实时数仓、离线数仓、BI数据分析、AI机器学习等需求
快速拉起Spark全托管的集群,操作简单,按需付费.全托管分析平台.用户根据需求设置节点数量,支持集群高可用.支持ECS通用型、计算型和内存型三种实例规格族.集群规模可动态扩展,调整计算资源大小,达到成本最优.多种用户角色共享数据,交互式协同合作.交互式协同工作.可以协同工作的工作空间,交互式的作业执行方式,支持...
来自:
云产品
基于弹性供应组构建大数据分析集群
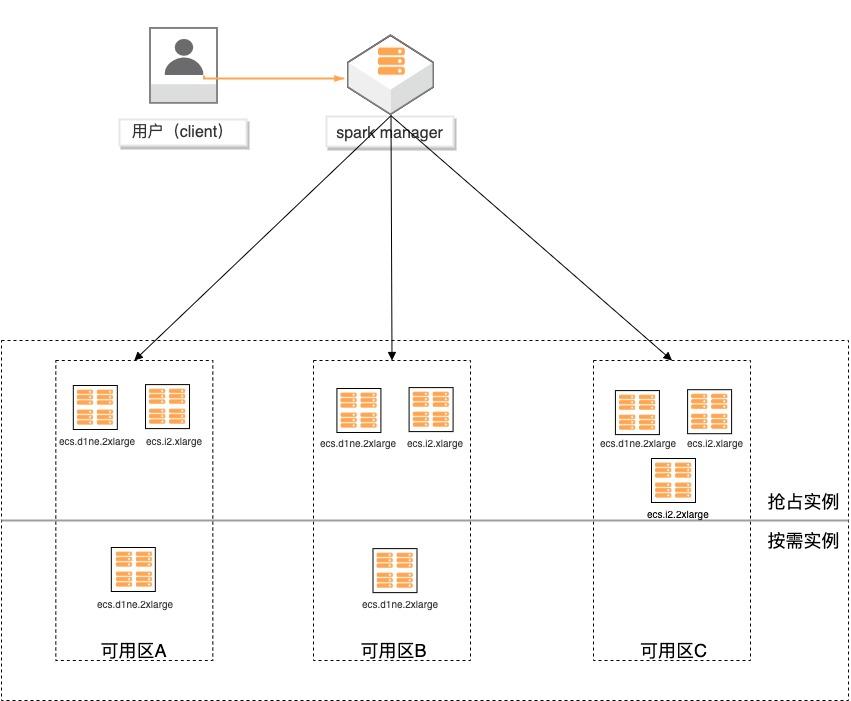
场景描述 基于弹性供应组(APG)搭建spark计算集 群,提供一键开启跨售卖方式、跨可用区、 跨实例规格的计算集群交付模式的实践。 方案优势 1.超低成本:跨售卖方式提供计算实 例,按秒计费,可全部使用spot实例 交付,最高可省90%成本。 2.稳定可靠:跨可用域、跨实例规格, 降低spot被集体释放的风险;自动托 管,分钟级巡检,动态保证集群的算 力。 3.快速交付:单次可在5分钟内交付 2000个实例。 4.多策略组合:可分别指定spot和按量 实例的交付策略,以及差额补足的策 略,包括成本最低、打散和折中。 解决问题 1.大规模计算集群成本高。 2.创建ECS实例方式单一,无法跨计费 方式、可用区及规格等核心参数。 3.当可用区资源紧张,无法自动保证基于 spot类型的稳定算力。 产品列表 专有网络VPC 云服务器ECS
基于弹性供应组构建大数据分析集群最佳实践 业务架构 场景描述 基于弹性供应组(APG)搭建 spark计算集 群,提供一键开启跨售卖方式、跨可用区、跨实例规格的计算集群交付模式的实践。方案优势 1.超低成本:跨售卖方式提供计算实 例,按秒计费,可全部使用 spot实例 交付,最高可省 90%成本。2.稳定可靠:跨可用域、跨实例...
云原生数据湖分析DLA
阿里云云原生数据湖分析是新一代大数据解决方案,采取计算与存储完全分离的架构,支持对象存储(OSS)、RDS(MySQL等)、NoSQL(MongoDB等)数据源的消息实时归档建仓,提供Presto和Spark引擎,满足在线交互式查询、流处理、批处理、机器学习等诉求。内置大量优化+弹性,比开源自建集群最高降低50%+的成本,最快可1分钟级拉起300个计算节点,快速满足业务资源要求。
互联网直接访问,开箱即用,按需付费,不需要长期持有分析成本,升级期间对业务影响小,产品迭代敏捷快速.Presto引擎.Presto引擎是数据湖分析基于Presto打造的交互式分析引擎,接入MySQL协议,可使用任何兼容MySQL协议的工具来进行数据分析,适合Adhoc查询、BI分析、轻量级ETL等数据分析场景.Spark引擎.Spark引擎是基于开源...
来自:
云产品
SLS多云日志采集、处理及分析
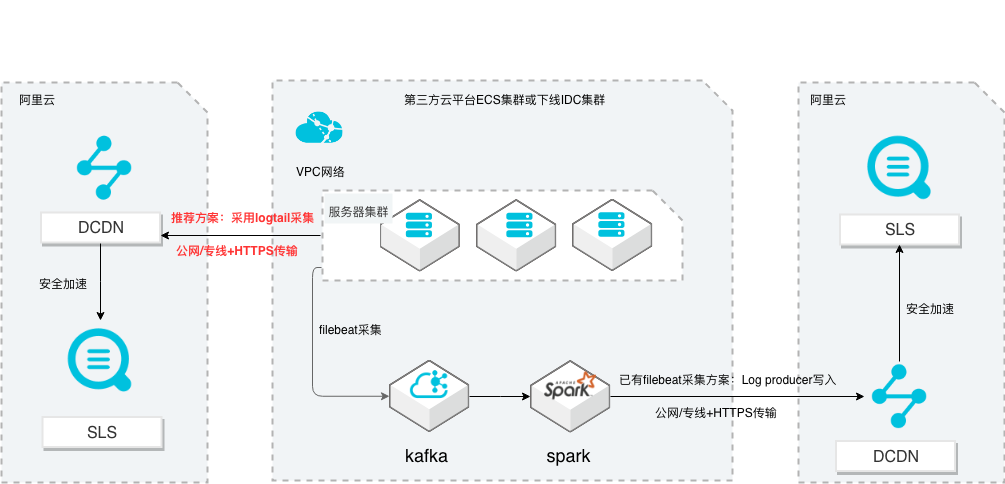
场景描述 从第三方云平台或线下IDC服务器上采集 日志写入到阿里云日志服务,通过日志服务 进行数据分析,帮助提升运维、运营效率, 建立DT 时代海量日志处理能力。 针对未使用其他日志采集服务的用户,推荐 在他云或线下服务器安装logtail采集并使用 Https安全传输;针对已使用其他日志采集 工具并且已有日志服务需要继续服务的情 况,可以通过Log producer SDK写入日志 服务。 解决问题 1.第三方云平台或线下IDC客户需要使用 阿里云日志服务生态的用户。 2.第三方云平台或线下IDC服务器已有完 整日志采集、处理及分析的用户。 产品列表 E-MapReduce 专有网络VPC 云服务器ECS 日志服务LOG DCDN
创建日志服务.54 9.Spark数据处理 Log producer写入日志服务.56 9.1.Git 作业源码.56 9.2.Spark作业处理 Log producer写入日志服务.57 附录 1:编写 Spark作业源码解读及问题排查.60 Spark作业源码解读.60 Spark作业源码编译及问题排查.63 文档版本:20211203 V SLS多云日志采集、处理及分析 目录 附录 2:日志服务器集群...
云消息队列 Kafka 版
云消息队列 Kafka 版是阿里云基于Apache Kafka构建的大数据消息中间件,广泛用于日志收集和分析、数据处理等场景。可提供全托管服务,用户无需部署运维,更专业、更可靠、更安全。
Kafka 性能高效,采集日志时业务无感知以及Hadoop/ODPS 等离线仓库存储和 Storm/Spark 等实时在线分析对接的特性决定它非常适合作为\\.构建应用系统和分析系统的桥梁,并将它们之间的关联解耦;应用与分析解耦.支持实时在线分析系统和类似于Hadoop之类的离线分析系统;在线/离线分析系统.云消息队列 MQ.应用实时监控服务 ...
来自:
云产品
云数据库 Cassandra 版
Cassandra是连续9年DB-Engines排名第一的宽表数据库,支持类SQL语法CQL,开发体验类似MySQL,可扩展PB级存储。推出企业版Lindorm for Cassandra云原生多模数据库,采用存储计算分离架构,支持海量数据的低成本存储和按需付费,具备更高性价比和更为丰富的企业级功能。
Presto满足在线交互式需求.Serverless分析引擎Spark&Presto.基于Spark RDD构建了统一的时空数据模型,方便建模.Ganos时空数据分析.综合治理,支持丰富的自研、开源引擎.Dataworks构建数据湖统一开发平台.云数据库Cassandra版支持节点升配及降配:从容应对可预知的业务潮汐。集群可小可大:单节点起配,起配门槛低。可扩展至...
来自:
云产品
E-MapReduce
阿里云E-MapReduce(简称EMR)是阿里云云原生数据湖的核心计算引擎,全面支持Hadoop、Spark、HBase、Hive、Flink等大数据组件,为客户提供企业级开源大数据平台服务。通过有效弹性伸缩和数据分层存储机制,相较于传统HDFS固定集群方式,可节省50%以上的费用,同时支持创建抢占式实例,相比按量付费的购买方式,可节省50%~80%的费用。
提供Hadoop、Spark、Hive、Kafka、HBase、Presto、Impala、Hudi、StarRocks等开源组件.领先开源生态.通过控制台页面或OpenAPI即可快速的进行多种类型的集群创建,如Hadoop、Dataflow、Datascience、Druid、ZooKeeper等开源大数据框架,无需关心底层的硬件与软件部署.通过控制台页面或OpenAPI即可方便地增加或减少已有集群的...
来自:
云产品
云原生多模数据库Lindorm
云原生多模数据库Lindorm提供各规模、多模型的云原生数据库服务。可兼容HBase/Cassandra、OpenTSDB、Solr、SQL、HDFS等多种开源标准接口。支持海量数据的低成本存储处理和弹性按需付费,是互联网、IoT、车联网、广告、社交等场景首选数据库,也是为阿里核心业务提供支撑的数据库之一。
兼容多种开源标准接口,支持车联网、工业物联网等场景与Spark、Flink等多种计算引擎互联互通,无缝对接主流数据生态.数据生态融合.查看产品文档.云数据库多场景体验馆.免费专家服务.数据库专家讲堂.查看产品文档.云数据库多场景体验馆.免费专家服务.数据库专家讲堂.<查看数据库全部产品.云原生多模数据库Lindorm面向海量泛...
来自:
云产品
数据管理与服务
数据管理与服务作为阿里云产品六大版块之一,面向不同业务场景,阿里云提供数据存储、分析、应用等全链路能力,满足企业客户全方位的数据处理需求,实现计算和存储分离、资源解耦、数据移动减化,用以满足行业快速发展的需求和趋势,利用数据重塑其业务。
在传统的生产环境中,Spark on YARN 成为主流的任务执行方式,而随着容器化概念以及存算分离思想的普及,尤其是 Spark3.1 版本下该模式的Spark on K8s 已成燎原之势.Spark on k8s 在阿里云 EMR 的优化实践.云原生关系型数据库 PolarDB.云原生数据仓库 AnalyticDB MySQL 版.云原生多模数据库 Lindorm.云数据库 RDS MySQL 版....
来自:
云产品
MRACC加速倚天ECS实例Flink集群性能
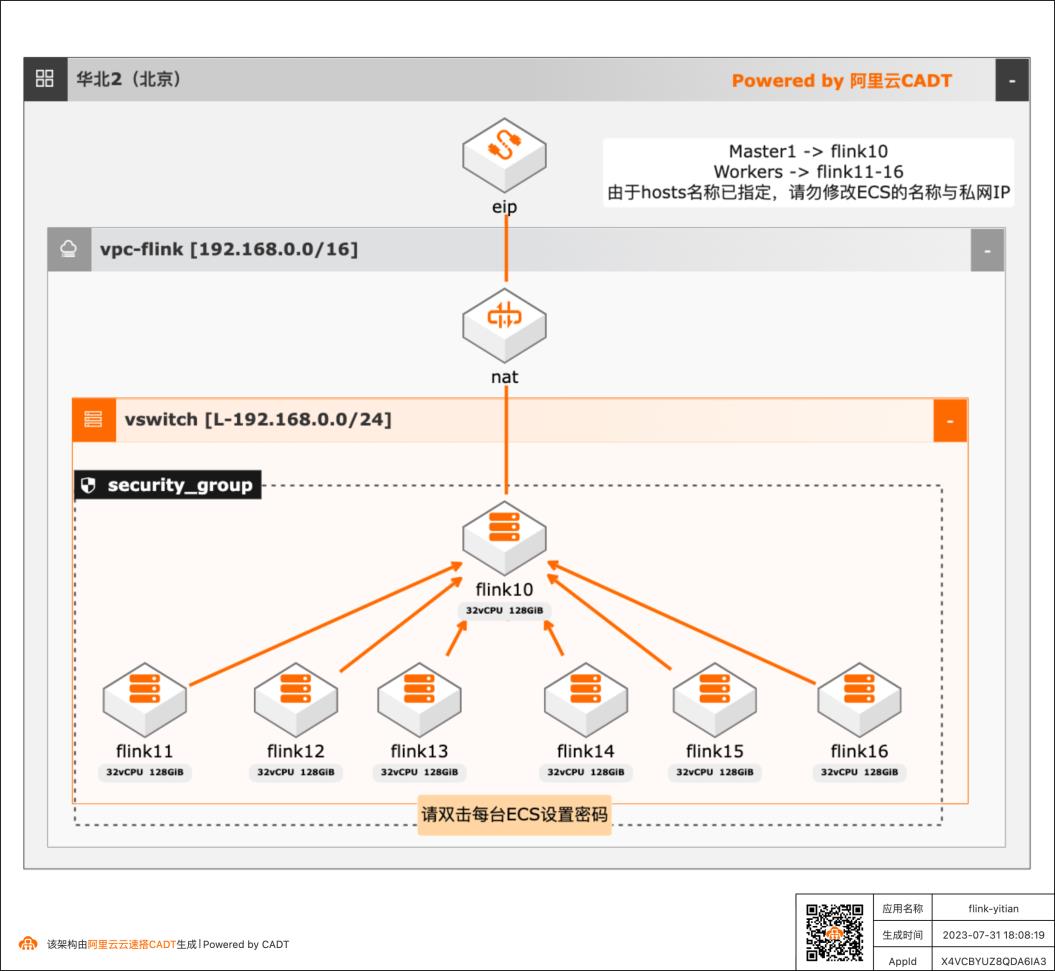
希望了解Flink集群on倚天的部署架构。 通过神龙大数据加速引擎 Mracc 提升Flink集群性能。 希望实测了解倚天ECS实例运行Flink集群的性能 架构设计:利用阿里云官方架构设计模版,在此基础上二次定制(调整规格、资源数量、配置调整)。 快速完成PoC和生产环境的设计和部署
cd/opt/fastmr/nexmark nohup sh test.sh&步骤2 通过日志文件查看压测脚本执行情况 tail-f/opt/fastmr/nexmark/nexmark.out 文档版本:20230801 18 MRACC加速倚天 ECS实例 Spark集群性能 部署基础环境 步骤3 通过日志文件查看压测数据生成进度 测试一共会跑 22个查询,大概需要 50分钟左右,若日志显示了 q22的Nexmark结 果...
微服务中心解决方案
注册中心和配置中心是 Dubbo 和 Spring Cloud 微服务架构中的重要组件,往往采用 ZooKeeper/Nacos/Eureka/Apollo 等开源方案进行自建,但因其依赖复杂,往往给客户带来的较高的建设和运维成本,同时,在 Hbase、Spark或Kafka 等大数据的环境下,会依赖 ZooKeeper 进行分布式系统的协调,此时,基于云上的托管服务,可以极大的降低运维复杂度,并提高应用可用性。
阿里云微服务中心解决了依赖 ZK/Nacos/Eureka 等开源注册和配置方案进行自建过程中引起的依赖复杂、建设和运维成本高的问题,同时,降低了在 Hbase、Spark或Kafka 等大数据的环境下的分布式系统协调难题,旨在打造云上微服务运维体系的闭环.微服务中心解决方案.微服务引擎MSE是一个面向业界主流开源微服务框架 Spring Cloud...
来自:
解决方案
阿里云大数据&AI
阿里云大数据和AI产品服务。开放数据处理服务ODPS提供强大的数据分析和管理功能;开源大数据产品支持更加灵活地构建大数据平台;AI和机器学习产品提供AI工程平台和智算服务。
支持Spark/Presto on K8s+Spark Remote Shuffle Service,并经过大规模生产环境实践验证.对象存储OSS.Databricks 数据洞察.推荐搭配使用.云原生数据湖.云原生数据湖.2021年3月,MaxCompute、DataWorks 等进入 Forrester Wave 2021 Q1 云数据仓库卓越表现者象限,成为入选此次评测的唯一中国厂商。以 MaxCompute 为核心代表...
来自:
云产品
- 产品推荐
- 这些文档可能帮助您