一键训练大模型及部署GPU共享推理服务
通过创建ACK集群Pro版,使用云原生AI套件提交模型微调训练任务与部署GPU共享推理服务。支持快速创建Kubernetes集群,白屏配置任务数据共享存储和下载,并通过命令行工具Arena快速提交模型训练任务、部署推理服务。使用云原生AI套件可以让模型训练和推理提效,提高GPU资源利用率。
高效运行AI等异构工作负载云原生AI套件兼容Tensorflow、Pytorch、Horovod、Spark、Flink等主流开源或者用户自有的各种计算引擎和运行时,统一运行各类异构工作负载,统一管理作业生命周期,统一调度任务工作流,保证任务规模和性能。云原生AI套件一方面不断优化运行任务的性能、效率和成本,另一方面持续改善开发运维体验和...
来自:
解决方案
云消息队列 RocketMQ 版
云消息队列 RocketMQ 版是基于 Apache RocketMQ 构建的分布式消息中间件,广泛用于异步解耦、削峰填谷等场景。可支撑千万级并发、万亿级数据洪峰,更稳定,更安全。
可对接 Storm/Spark 实时流计算引擎,亦可对接 Hadoop/ODPS 等离线数据仓库系统.云消息队列 MQ.实时计算 Flink 版.推荐搭配使用.天猫双11大促,各个分会场琳琅满目的商品需要实时感知价格变化,大量并发访问数据库导致会场页面响应时间长,集中式缓存因为带宽瓶颈限制商品变更的访问流量,通过 RocketMQ 构建分布式缓存,...
来自:
云产品
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。
配置DataWorks和PAI 此方案通过DataWorks创建一个工作空间,选择MaxCompute作为计算引擎,并开 通PAIStudio作为机器学习服务(用于后续演示使用MaxCompute的SQL完成机器 学习)。通过odpscmd客户端在工作空间下创建外部项目(externalproject)与DLF 的元数据库做映射关联。前提是DLF已经授权给MaxCompute。目前DataWorks的...
DTS数据同步集成MaxCompute数仓
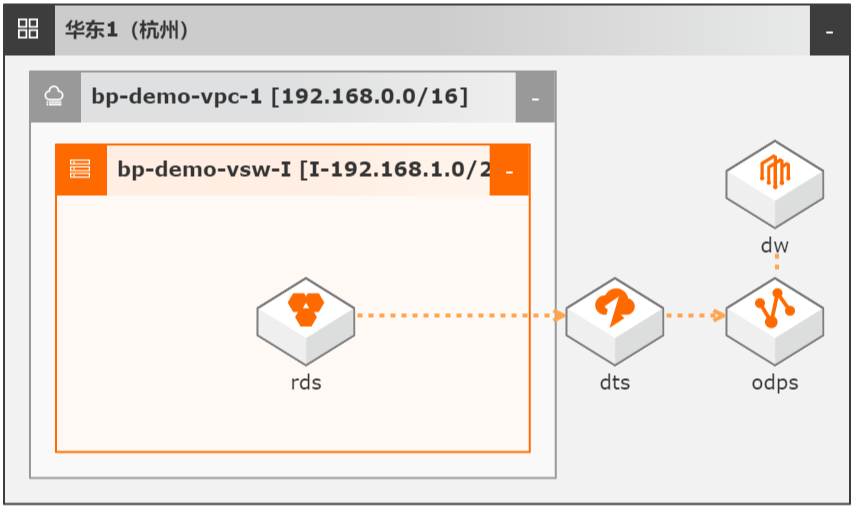
场景描述 本文Step by Step介绍了通过数据传输服务 DTS实现从云数据库RDS到MaxCompute的 数据同步集成,并介绍如何使用DTS和 MaxCompute数仓联合实现数据ETL幂等和数 据生命周期快速回溯。 解决问题 1.实现大数据实时同步集成。 2.实现数据ETL幂等。 3.实现数据生命周期快速回溯。 产品列表 MaxCompute 数据传输服务DTS DataWorks 云数据库RDS MySQL 版
步骤4 在选择引擎页面,在选择计算引擎服务区域,勾选 MaxCompute按量付费,单击下 一步。文档版本:20220126(发布日期)21 DTS数据同步集成 MaxCompute数仓 MaxCompute数仓搭建 步骤5 在引擎详情页,输入实例显示名称和 MaxCompute项目名称,单击创建工作空间。实例显示名称:bp_bigdata_warehouse MaxCompute项目名称:...
基于Elasticsearch的订单检索加速最佳实践
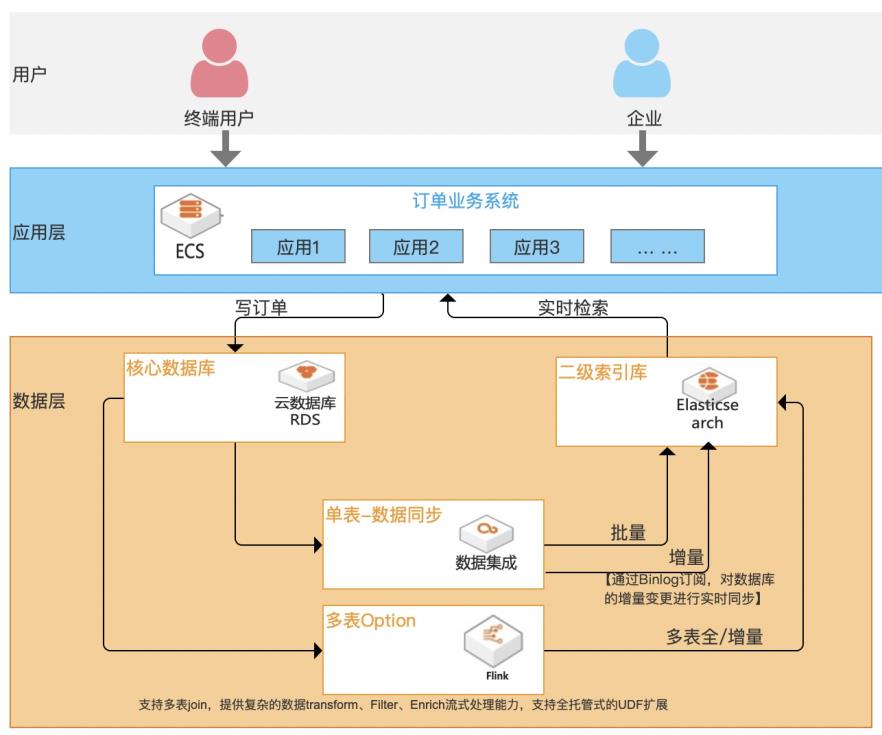
随着企业信息化程度越来越高,核心业务数据存储在传统关系型数据库中不可避免地会遇到一个问题:单表记录不断增多,数据检索速度会变慢,尤其是对中文的模糊查询(建立普通索引完全不起作用)。虽然数据库自身在不断完善,但效果有限且没办法灵活扩展,复杂场景无法应对。 本方案基于阿里云Elasticsearch作为二级索引库,数据集成产品提供Binlog实时订阅,实时解析、增量数据实时更新及二级索引库之间进行数据实时同步,为数据库提供“能力增益”, 不仅能从根本解决主库抗压问题,提升稳定性;同时支持高效率、高性能、高弹性、低成本、多复杂场景的检索加速服务。
更多 信息,请参见:www.aliyun.com/product/bigdata/product/elasticsearch 文档版本:20210517 III 基于 Elasticsearch的订单检索加速最佳实践 前言 DataWorks:DataWorks基于 MaxCompute/EMR/MC-Hologres等大数据计算引 擎,为客户提供专业高效、安全可靠的一站式大数据开发与治理平台,自带阿里巴 巴数据中台与数据治理...
大数据系统基准性能测试最佳实践
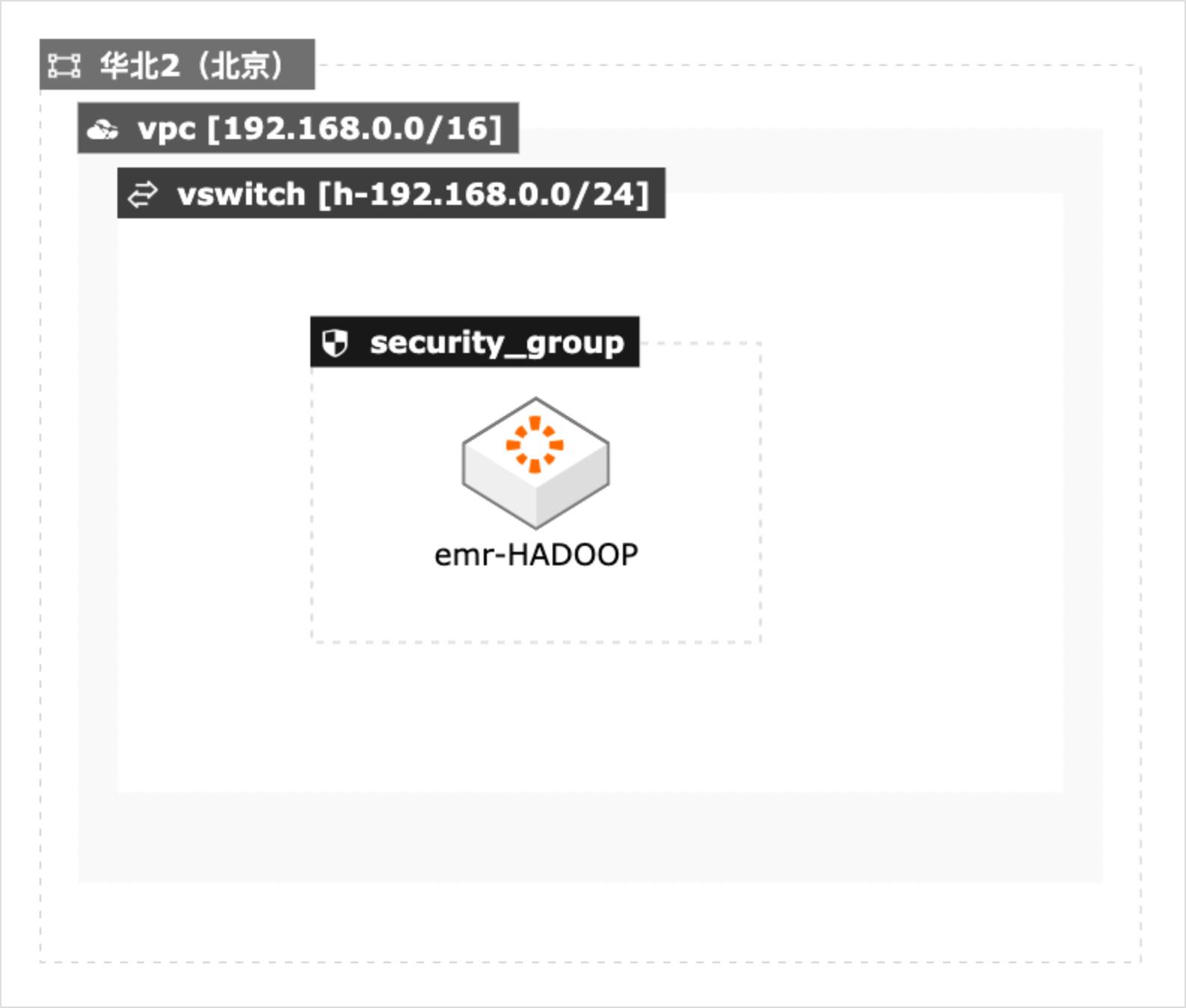
本方案适用于在阿里云上进行大数据基准性能测试的场景,包括 Teragen和Terasort测试,TestDFSIO测试。本文采用CADT工具结合阿里云的E-MapReduce服务快速构建测试集群,并提供了Teragen和Terasort测试,TestDFSIO测试的测试脚本,便于迅速开展测试。
EMR的 SmartData组件是 EMR Jindo引 擎的主要存储部分,为 EMR各个计算引擎提供统一的存储优化、缓存优化、计算 缓存加速优化和多个存储功能扩展。详见 https://help.aliyun.com/document_detail/28068.html 云架构设计工具 CADT:是一款为上云应用提供自助式云架构管理的产品,显著 地降低应用云上管理的难度和时间成本。...
EMR本地盘实例大规模数据集测试
场景描述 阿里云为了满足大数据场景下的存储需求,在云 上推出了本地盘D1机型,这个系列提供了本地 盘而非云盘作为存储,提高了磁盘的吞吐能力, 发挥Hadoop的就近计算优势。阿里云EMR 产品针对本地盘机型,推出了一整套的自动化运 维方案,帮助用户方便可靠地使用本地盘机型, 不需要关注整个运维过程同时数据的高可靠和 服务的高可用。 解决问题 1.云盘多份冗余数据导致成本高 2.磁盘吞吐量不高 3.节点的高可靠分布问题 4.本地盘与节点的故障监控问题 5.数据迁移时自动决策问题 6.自动故障节点迁移与数据平衡问题 产品列表 EMR(E-MapReduce) 本地盘 VPC
testbench.settings的不同参数用于不同条件的测试,例如合并小文件、使用索引、join优化、使用 spark作为计算引擎,这里不再赘述。本实践采用并行模式、使用 tez作为测试引擎进行测试:注释掉 security模式相关的 两行配置并且添加后面六行配置以便适合 hive-testbench进行大规模数据集测试(比 如 1TB规模的数据集),然后...
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
深度融合 Databricks数据洞察与阿里云其它产品(例如,OSS、MongoDB、Elasticseach、RDS和 MaxCompute等)进行了深度整合,支持以这些产品作为 Spark计算引 擎的输入源或者输出目的地。文档版本:20210425 VI 自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 前置条件 前置条件 为了顺利完成本实践,您需要提前...
湖仓一体架构EMR元数据迁移DLF
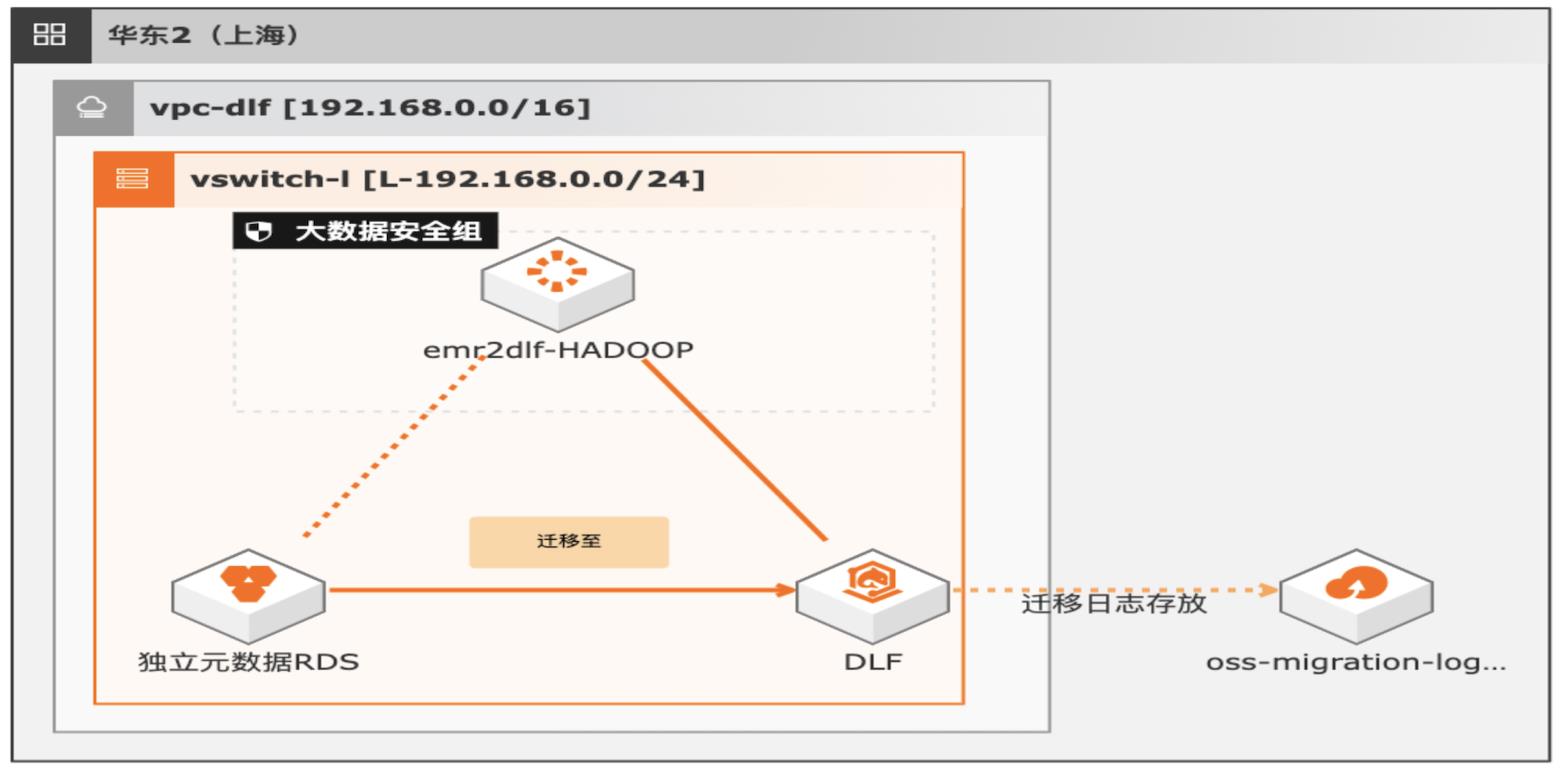
通过EMR+DLF数据湖方案,可以为企业提供数据湖内的统一的元数据管理,统一的权限管理,支持多源数据入湖以及一站式数据探索的能力。本方案支持已有EMR集群元数据库使用RDS或内置MySQL数据库迁移DLF,通过统一的元数据管理,多种数据源入湖,搭建高效的数据湖解决方案。
数据湖构建提供湖上元数据统一管理、企业级权限控 制,并无缝对接多种计算引擎,打破数据孤岛,洞察业务价值。(https://www.aliyun.com/product/bigdata/dlf)云速搭 CADT:是一款为上云应用提供自助式云架构管理的产品,显著地降低应 用云上管理的难度和时间成本。本产品提供丰富的预制应用架构模板,同时也支 持自助拖拽...
自建Hive数仓迁移到阿里云EMR
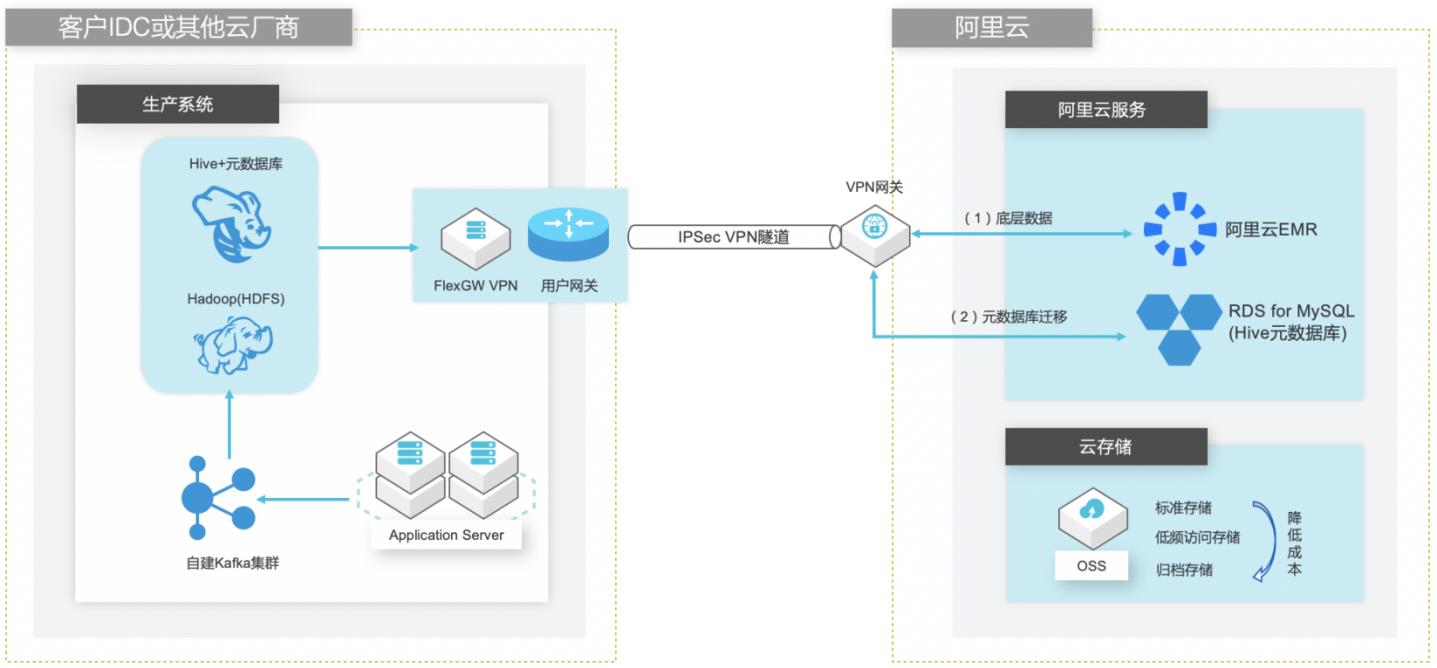
场景描述 客户在IDC或者公有云环境自建Hadoop集群构 建数据仓库和分析系统,购买阿里云EMR集群之 后,涉及到将数据仓库和Hive元数据的数据库迁 移上云。目前主流Hive数据仓库迁移场景为1.x 版本迁移到阿里云EMR(Hive2.x版本),涉及到 数据订正更新步骤。 解决的问题 Hive数据仓库的数据迁移方案 Hive元数据库的迁移方案 Hive跨版本迁移后的数据订正 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
深度整合 E-MapReduce 与阿里云其它产品(例如,OSS、MNS、RDS 和 MaxCompute 等)进行了深度整合,支持以这些产品作为 Hadoop/Spark计算引擎的输入源或者 文档版本:20210721 1 自建Hive数据仓库跨版本迁移到阿里云 EMR 最佳实践概述 输出目的地。安全 E-MapReduce整合了阿里云 RAM资源权限管理系统,通过主子账号对服务...
基于函数计算FC实现阿里云Kafka消息轻量级ETL处理
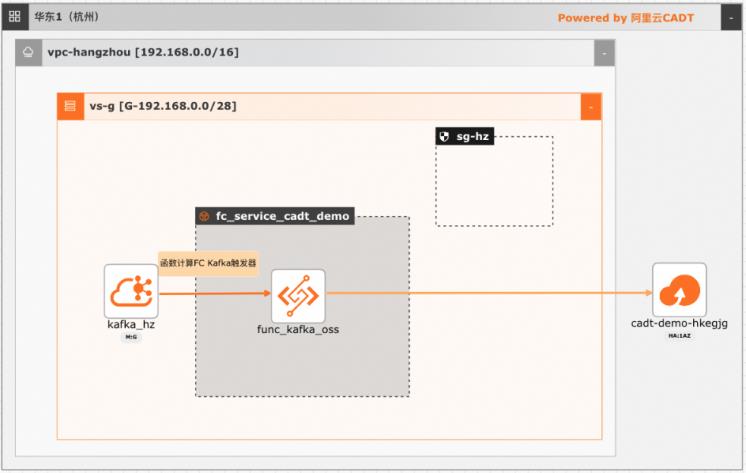
在大数据ETL场景,Kafka是数据的流转中心,Kafka中的数据一般是原始数据,可能存在多种数据混杂的情况,需要进一步做数据清洗后才能进行下一步的处理或者保存。利用函数计算FC,可以快速高效的搭建数据处理链路,用户只需要关注数据处理的逻辑,数据的触发,弹性伸缩,运维监控等阿里云函数计算都已经做了集成,函数计算FC也支持多种下游,OSS/数据库/消息队列/ES等都可以自定义的对接
使用函数计 算,您无需采购与管理服务器等基础设施,只需编写并上传代码或镜像。函数计算为您准 备好计算资源,弹性地、可靠地运行任务,并提供日志查询、性能监控和报警等功能。云消息队列 Kafka 版:云消息队列 Kafka 版是阿里云提供的分布式、高吞吐、可扩展的 消息队列服务。云消息队列 Kafka 版广泛用于日志收集、监控...
基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步
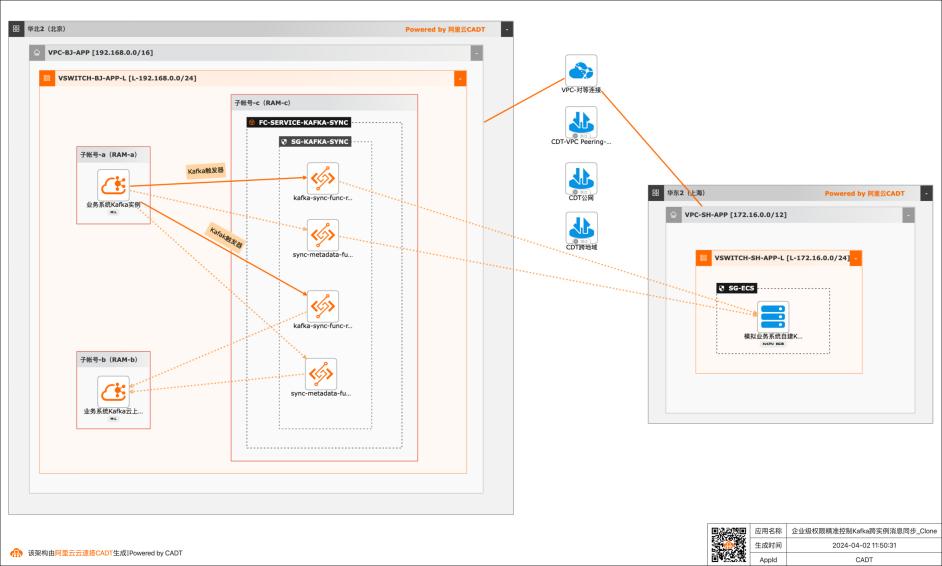
应用场景 在大数据场景,企业的Kafka实例可能存在多种情况,比如使用阿里云Kafka服务,可能是自建开源Kafka,或者是其他云上的云Kafka。不同的业务使用不同类型的Kafka实例,在这个前提下Kafka实例之间可能会需要消息同步的情况: 同帐号容灾场景:比如Kafka实例都是阿里云Kafka,但是Kafka实例会有主备之分,需要将主Kafka实例的消息实时同步到备Kafka。 跨帐号或异地容灾:这类场景比如主Kafka是阿里云Kafka,备Kafka是IDC开源自建Kafka,或者是其他云上的Kafka。 不同业务之间消息同步:因为现在的业务通常不会是信息孤岛,都需要消息互通,所以可能是A业务的Kafka实例消息需要同步到B业务的Kafka实例,并且这两个Kafka实例归属不同的RAM角色,有自己独自的权限控制。 解决问题 解决使用开源组件做消息同步的高成本问题。 解决使用开源组件做消息同步的并发性能、稳定性问题。 解决使用开源组件做消息同步的可靠性问题(重试机制,容错机制,死信队列等)。 大幅提升构建消息同步架构的效率,降低构建复杂度问题。
使用函数计 算,您无需采购与管理服务器等基础设施,只需编写并上传代码或镜像。函数计算为您准 备好计算资源,弹性地、可靠地运行任务,并提供日志查询、性能监控和报警等功能。 云消息队列Kafka 版:云消息队列Kafka 版是阿里云提供的分布式、高吞吐、可扩展的 消息队列服务。云消息队列Kafka版广泛用于日志收集、监控...
基于函数计算FC实现阿里云Kafka消息内容控制MongoDB DML操作
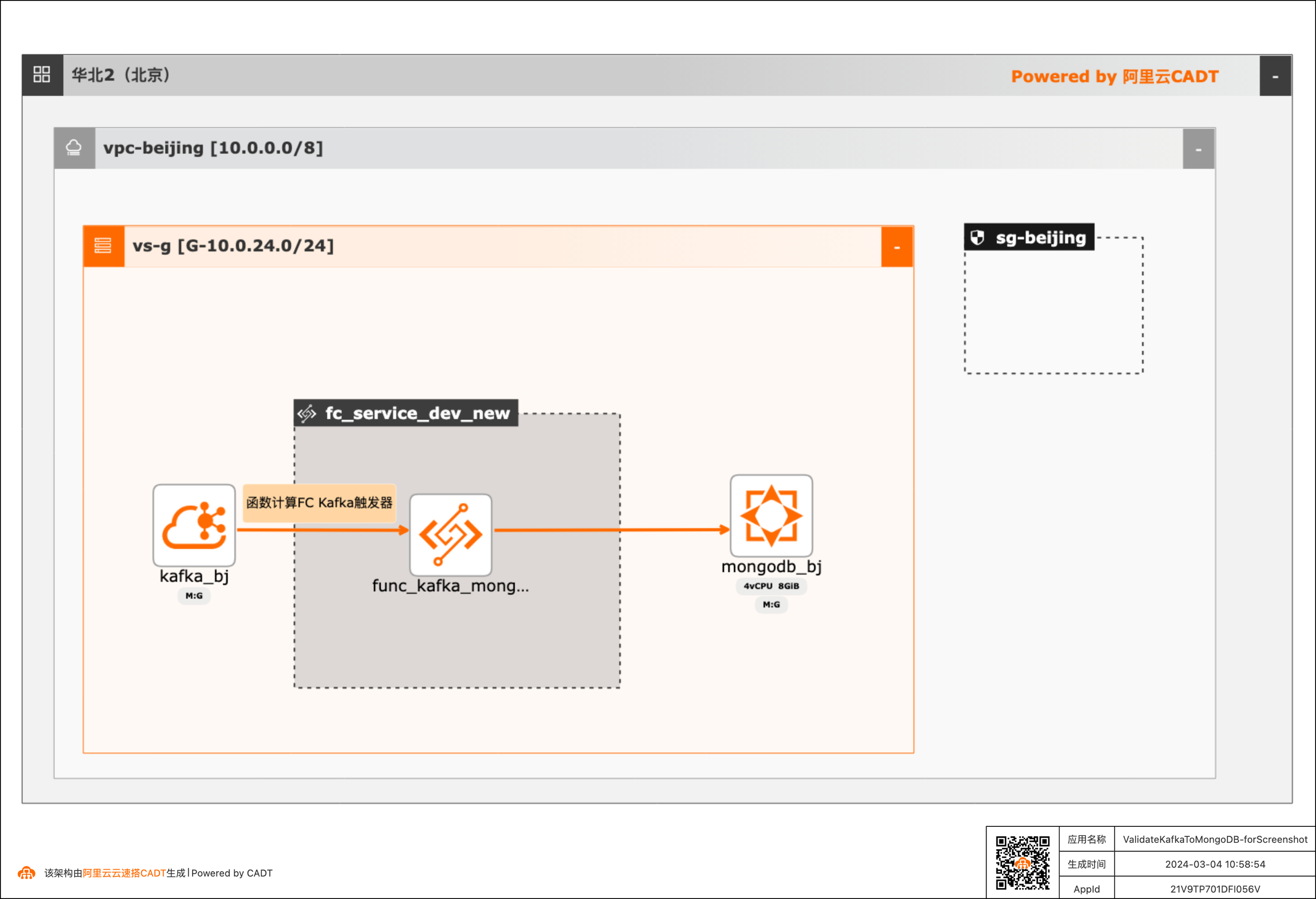
在大数据ETL场景,将Kafka中的消息流转到其他下游服务是很常见的场景,除了常规的消息流转外,很多场景还需要基于消息体内容做判断,然后决定下游服务做何种操作。 该方案实现了通过Kafka中消息Key的内容来判断应该对MongoDB做增、删、改的哪种DML操作。 当Kafka收到消息后,会自动触发函数计算中的函数,接收到消息,对消息内容做判断,然后再操作MongoDB。用户可以对提供的默认函数代码做修改,来满足更复杂的逻辑。 整体方案通过CADT可以一键拉起依赖的产品,并完成了大多数的配置,用户只需要到函数计算和MongoDB控制台做少量配置即可。
整体方案通过 CADT 可以一键拉起依赖的产品,并完成了大多数的配置,用户只需要到函数计 算和 MongoDB 控制台做少量配置即可。方案优势 l 可以实现根据 Kafka 消息的具体内容判断,该对 MongoDB 做哪种 DML 操作,灵活性和可 扩展性极高。l 函数计算具有完善的日志系统、容错机制。可以清晰的看到对每条消息的处理日志,...
MSE云原生网关解析body内容进行路由转发
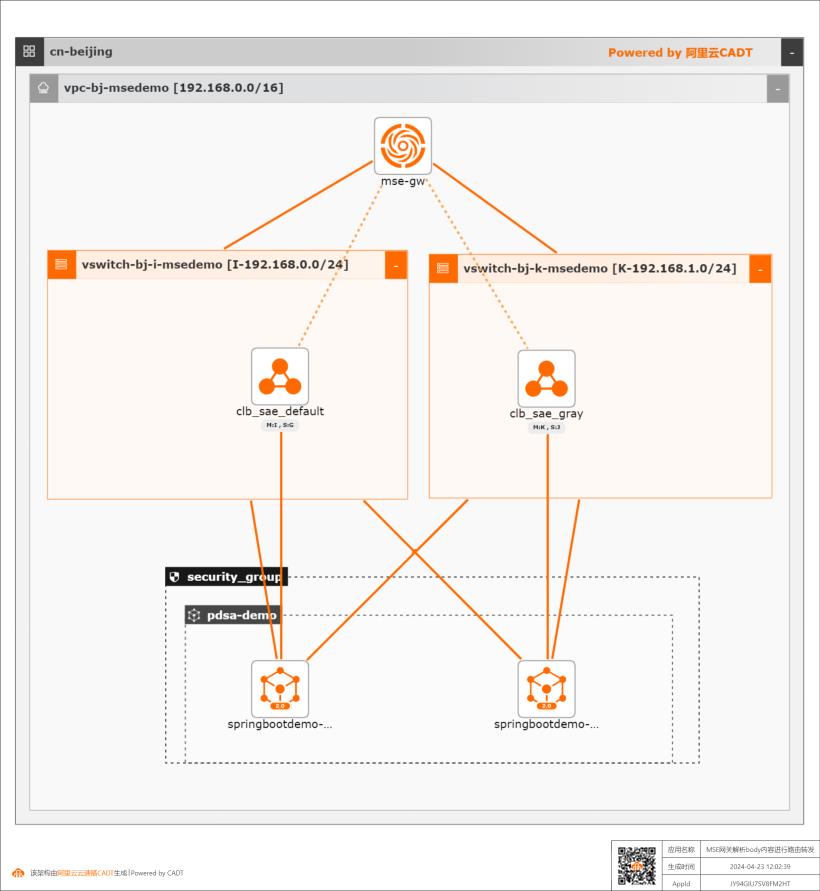
MSE云原生网关中通过自定义插件transformer解析body内容,并用以路由转发规则判断
步骤5 价格预估,如果上一个页面中的部署资源校验没有问题的话,点击【下一步:价格清单】按钮,即可触发整个应用的价格预估,系统会计算出当前所采用的产品及组件的价格 清单。文档版本:20240426 4 MSE云原生网关解析 body内容进行路由转发 部署基础环境 步骤6 确认订单,上述的价格清单确认无误后,点击【下一步:确认...
容器计算服务 ACS
容器计算服务 ACS 是以 K8s 为使用界面供给容器算力资源的云计算服务,提供符合容器规范的算力资源。
产品解决方案文档与社区权益中心定价云市场合作伙伴支持与服务了解阿里云备案控制台 容器计算服务 ACS产品简介产品优势产品功能入门与试用产品定价安全合规常见问题容器计算服务 ACS以 K8s 为使用界面供给容器算力资源的云计算服务,提供符合容器规范的算力资源。申请试用公测试用快捷入口文档01:23新一代容器产品产品动态...
来自:
云产品
基于SAE的一站式Web服务托管方案
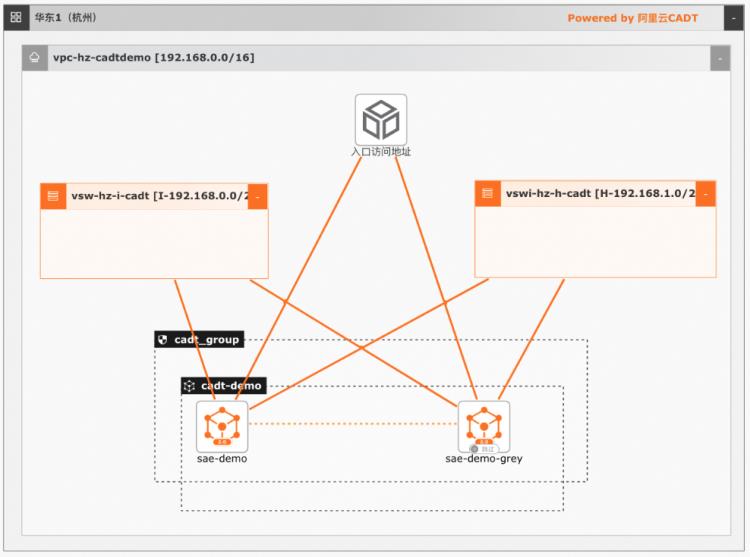
通过SAE提供的内置CICD能力,代码提交后可以触发自动构建,并部署应用到SAE,部署完成后,应用自动产生访问域名,外部请求通过域名可以直接访问应用。SAE提供了内置的可观测,灰度,回滚能力,通过控制台可以白屏化完成整个操作。SAE适合应用容器化快速上云,客户只需要提供代码仓库,后续的CICD,应用访问,弹性管理,运维监控,SAE都提供了内置的集成能力
Serverless应用引擎(SAE)•按量付费,没有资源闲置费用。云速搭 CADT 最佳实 践频道 http://bp.aliyun.com 阿里云最佳实践分享群 钉钉搜索钉群号 31852400入群 函数计算 FC用户交流群 钉钉搜索钉群号 11721331入群 基于 SAE 2.0的一站式 Web 服务托管方案 文档版本:20240430(发布日期)基于SAE 2.0的一站式 Web服务托管...
高效防护 Web 应用
随着网络技术的不断发展,您的Web应用如果没有流量入口的防护,会面临诸多风险。本方案以ECS实例接入WAF为例,推荐您使用Web应用防火墙(WAF)开启应用防护,避免网站服务器被恶意入侵导致性能异常等问题,保障网站的业务安全和数据安全。同时,为您节约开发成本,满足行业合规要求。
0day漏洞1小时自动应急,云端海量计算资源、大数据加持下的算法模型、威胁情报持续自动更新。部署和容灾多为本地机房部署,要全方位考虑从物理机房到软件系统的容灾机制。公共云/混合云/多云灵活部署,云上多集群自动容灾调度,自带一定程度的DDoS防御。计费方案一次性支出,大量闲置资源,扩容方案复杂。即开即用,即关即...
来自:
解决方案
- 产品推荐
- 这些文档可能帮助您