E-MapReduce Serverless Spark 版
E-MapReduce Serverless Spark 是阿里云 E-MapReduce 基于 Spark 提供的一款全托管、一站式的数据计算平台。它为用户提供任务开发、调试、发布、调度和运维等全方位的产品化服务,显著简化了大数据计算的工作流程,使用户能更专注于数据分析和价值提炼。
云原生极速计算引擎.支持计算存储分离,计算可弹性伸缩、存储可按量付费;对接 OSS-HDFS,完全兼容 HDFS 的云上存储,无缝平滑迁移上云;中心化的 DLF 元数据,全面打通湖仓元数据.开放化的数据湖架构.提供作业开发、调试、发布、调度等一站式数据开发体验;内置版本管理、开发与生产隔离,满足企业级开发与发布标准.一站式...
来自:
云产品
Databricks数据洞察
阿里云Databricks数据洞察是基于Apache Spark的全托管数据分析平台, 内核采用更高效、稳定的商业版Databricks Runtime和Delta Lake。可满足数据分析师、数据工程师和数据科学家在大数据场景下对数据湖分析、实时数仓、离线数仓、BI数据分析、AI机器学习等需求
在Apache Spark基础上做了大量的性能优化,且针对阿里云OSS做了I/O优化,提供了更快速、更高效的计算引擎.较开源Delta Lake,功能更完备,对核心功能点均有更深度的优化和性能提升.与阿里云RAM集成,可以根据用户和角色做权限控制,保障数据安全性.介绍Databricks数据洞察功能.介绍如何创建和释放集群.介绍如何创建作业及...
来自:
云产品
数据可视化DataV
数据可视化DataV是阿里云一款数据可视化应用搭建工具,旨让更多的人看到数据可视化的魅力,帮助非专业的工程师通过图形化的界面轻松搭建专业水准的可视化应用,满足您会议展览、业务监控、风险预警、地理信息分析等多种业务的展示需求。
城市孪生体管理能力,利用云原生时空数据库和孪生计算引擎,为海量城市要素提供可靠的存储、查询和计算能力;孪生应用构建能力,利用自研云渲染引擎以及低代码开发工具链,为数字孪生应用提供稳定、高效的应用运行平台;城市联合仿真能力,利用云原生联合仿真调度平台,为城市提供车流、人流的联合仿真能力;DataV-孪生仿真...
来自:
云产品
DataWorks
大数据开发治理平台 DataWorks基于MaxCompute/EMR/MC-Hologres等大数据计算引擎,为客户提供专业高效、安全可靠的一站式大数据开发与治理平台。每天阿里巴巴集团内部有数万名数据/算法工程师正在使用DataWorks,承担集团99%数据业务构建。
支持多种大数据引擎绑定 开放OpenAPI定制化对接能力.ODPS大规模批量计算引擎.ODPS实时交互式计算引擎.全托管Serverless Flink云服务.实时计算Flink版.AI工程化平台.机器学习平台PAI.开源大数据计算平台.阿里云上的半托管形态CDP企业数据云平台.100%兼容开源的分布式检索、分析套件.检索分析服务 Elasticsearch版.流式数据...
来自:
云产品
智能数据建设与治理Dataphin
Dataphin遵循阿里巴巴集团多年实战沉淀的大数据建设OneData体系(OneModel、OneID、OneService),集产品、技术、方法论于一体,一站式地为您提供集数据引入、规范定义、智能建模研发、数据萃取、数据资产管理、数据服务等的全链路智能数据构建及管理服务。助您打造属于自己的标准统一、资产化、服务化和闭环自优化的智能数据体系,驱动创新。
配置数据构建所需数据源,支持原始的业务源数据配置和大数据计算引擎及存储配置,大数据计算引擎及存储如:MaxCompute.支持全局架构逻辑空间和物理空间,包括通用业务概念定义、组织管理、计算存储管理.提供多种异构数据源的数据读写能力,提供脏数据过滤、流量控制等功能.依托集团内部多年大数据经验积累下的OneData方法论...
来自:
云产品
云上数据集成解决方案
云上数据集成解决方案提供可跨异构数据存储系统、可靠、安全、低成本、可弹性扩展的数据传输交互服务,有效帮助您解 决云环境、个人站点环境下异构数据存储系统的数据互通难题,让您数据不再成为孤岛!助您实现大数据分析和实时商务智能。
支持MaxCompute、AnalyticDB for PostgreSQL和Hologres等大数据计算引擎及其他数据源.详细了解>.支持的数据源.查看如何配置数据集成的数据源.详细了解>.如何进行增量数据同步.详细了解>.数据增量同步.数据集成整库迁移介绍.详细了解>.根据您提交的需求,将有售前专家免费服务!根据您提交的需求,将有售前专家免费服务!...
来自:
解决方案
数据管理与服务
数据管理与服务作为阿里云产品六大版块之一,面向不同业务场景,阿里云提供数据存储、分析、应用等全链路能力,满足企业客户全方位的数据处理需求,实现计算和存储分离、资源解耦、数据移动减化,用以满足行业快速发展的需求和趋势,利用数据重塑其业务。
随着大数据技术的发展,Spark 成为当今大数据领域受关注的计算引擎之一。在传统的生产环境中,Spark on YARN 成为主流的任务执行方式,而随着容器化概念以及存算分离思想的普及,尤其是 Spark3.1 版本下该模式的Spark on K8s 已成燎原之势.Spark on k8s 在阿里云 EMR 的优化实践.云原生关系型数据库 PolarDB.云原生数据仓库...
来自:
云产品
综合能源服务平台解决方案
阿里云综合能源服务平台解决方案以“厚平台、微应用”方式构建面向竞争性综合能源服务的业务中台,快速构建节电节能、电力需求侧、电务、能效管理、储能、微网一体化和能源电力交易等生态化应用。
数据可视化DataV.DataWorks基于MaxCompute/EMR/MC-Hologres等数据计算引擎,为客户提供专业高效、安全可靠的一站式大数据开发与治理平台,自带阿里巴巴数据中台与数据治理实践,赋能各行业数字化转型.一站式大数据开发Dataworks.阿里云机器学习平台PAI(Platform of Artificial Intelligence),为传统机器学习和深度学习...
来自:
解决方案
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
自定义 HDFS Sink.47 文档版本:20201020 IV 基于 Dataworks的大数据一站式开发及数据治理 最佳实践概述 最佳实践概述 概述 本实践基于 Dataworks做大数据一站式开发,包含数据实时采集到 kafka通过实时计 算对数据进行 ETL写入 HDFS,使用 Hive进行数据分析。通过 Dataworks进行数据 治理,数据地图查看数据信息和血缘关系...
云消息队列 Kafka 版
云消息队列 Kafka 版是阿里云基于Apache Kafka构建的大数据消息中间件,广泛用于日志收集和分析、数据处理等场景。可提供全托管服务,用户无需部署运维,更专业、更可靠、更安全。
而云消息队列 Kafka 版以及 Storm/Samza/Spark 等流计算引擎的出现,可以根据业务需求对数据进行计算分析,最终把结果保存或者分发给需要的组件.由于数据产生非常快且数据量大,需要非常高的可扩展性;可对接开源 Storm/Samza/Spark 以及 EMR、Blink、StreamCompute 等阿里云产品;实时计算 Flink版.云消息队列 MQ.应用实时...
来自:
云产品
Spark on ECI大数据分析

场景描述 方案优势 1.计算引擎弹性扩缩容,兼顾资源弹性与计 算资源成本优化。 2.计算与存储分离架构,结合阿里云原生云 存储产品,海量数据湖优势。 3.Kubernetes原生的调度性能优势,提升在 大规模分析作业时的分析性能优势分。 4.集群资源隔离和按需分配。 解决问题 1.计算资源弹性能力不足,计算资源成本管 控能力欠缺. 2.集群资源调度能力和隔离能力不足。 3.计算与存储无法分离,大数据量分析时出 现数据存储资源瓶颈。 4.Spark submit方式提交分析作业参数支持 有限等缺点。 产品列表 容器服务Kubernetes版(ACK) 弹性容器实例(ECI) 文件存储HDFS 对象存储OSS 专有网络VPC 容器镜像服务ACR
计算引擎弹性扩缩容,兼顾资源弹性与计 算资源成本优化。2.计算与存储分离架构,结合阿里云原生云 存储产品,海量数据湖优势。3.Kubernetes原生的调度性能优势,提升在 大规模分析作业时的分析性能优势分。4.集群资源隔离和按需分配。解决问题 产品列表 1.计算资源弹性能力不足,计算资源成本管 容器服务 Kubernetes版(ACK)...
工业控制性能优化解决方案
工业控制性能优化是基于对控制器的参数实时评估与监控,通过阿里云大数据处理和计算的能力,结合人工智能算法,机器学习的能力,为企业提供高效的性能评估与整定,更方便、快捷地完成回路控制性能的批量评估和整定优化工作,为企业提供最佳的控制性能优化解决方案。
利用回路日常运行数据进行系统辨识与统计分析并结合人工智能算法,针对全厂级大规模控制回路所产生的海量数据进行有效的信息挖掘和特征提取,在基于阿里云平台的高速实时计算引擎之上对控制回路的性能进行多尺度实时监控与评估并能够快速定位问题回路,明显提升系统日常维护效率和生产的平稳性,并最终实现节能降耗、减少...
来自:
解决方案
大数据近实时数据投递MaxCompute
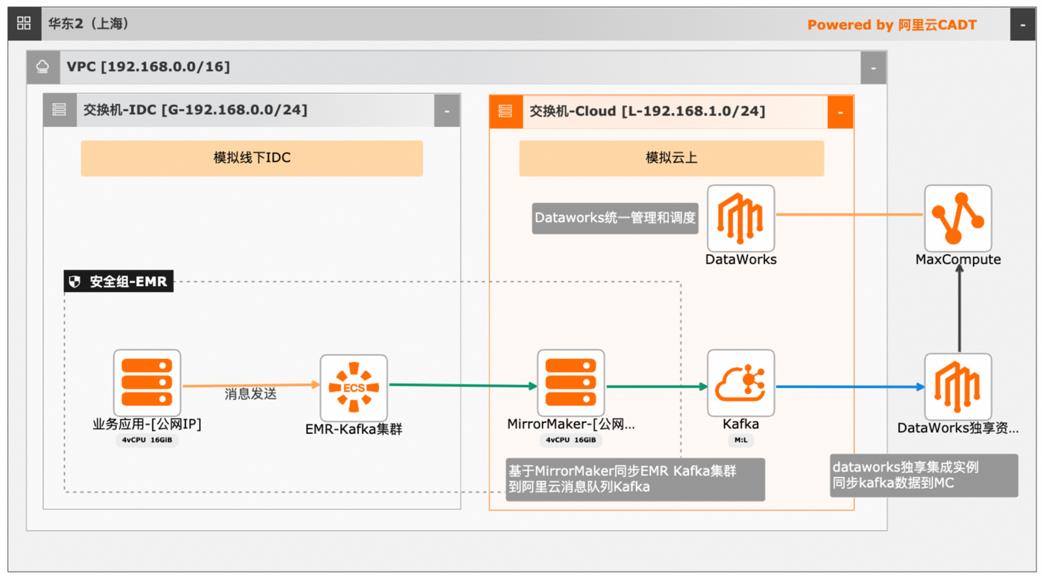
本文介绍离线大数据场景使MaxCompute构建云 上近实时数仓,打通云下数据上云链路,解决数据复杂类型支持和动态分区问题,满足高级数据处理需求的最佳实践。 l混合云环境下,现有业务系统零改造,打通数据上云链路。 l使用UDF实现复杂数据类型转换和数据动态分区。 l使用DataWorks配置周期调度业务流程,数据自动入仓。 l借助MaxCompute优化计算引擎,实现降本增效。 产品列表 云服务器ECS 专有网络VPC 访问控制RAM 数据总线DataHub E-MapReduceEMR DataWorks 大数据计算服务MaxCompute
MaxCompute支持 SQL、MapReduce、UDF(Java/Python)、Graph、基于 DAG的处理、交互式、内存计算、机器学习等计 算类型及 MPI迭代类算法。大幅简化了企业大数据平台的应用架构,具有强数据安 全、低成本、免运维、极致弹性扩展等特点。MaxCompute已与数据集成、DataWorks、QuickBI、机器学习 PAI、ADB、推荐引擎、移动数据...
云数据库MongoDB版
阿里云云数据库MongoDB版是完全兼容MongoDB协议、高度兼容DynamoDB协议的在线文档型数据库服务。支持单节点、双节点、副本集和分片集群四种部署架构,能够满足不同的业务场景需要。
数据库性能扩展.MongoDB在线数据实时写入后端数据库,再由专用计算引擎进行数据计算分析,分析结果再写回源数据库,以便业务快速访问计算结果,高效解决大数据业务场景海量数据复杂计算的难题.可进行数据库源数据访问.对大数据进行计算分析.异构数据库产品之间的数据流动.异构数据互通.负载均衡SLB.云服务器ECS.云数据库...
来自:
云产品
云速搭部署Flink应用

本水煎通过云速搭实现一个DataHub+Flink的实时流计算引擎架构,利用DataHub收集原始数据,推送到Flink进行基于流式数据的分析和应用。
文档版本:20211103 18 云速搭部署 Flink应用 CADT设计部署服务 此外,本实践创建的 datahub,可以将海量数据同步到实时流计算引擎 flink中,并进 行相关的作业开发。步骤10 开发配置 Flink 可参考 https://bp.aliyun.com/detail/155 中第 4章的“实时数仓搭建”。文档版本:20211103 19 云速搭部署 Flink应用 产品支持 3....
- 产品推荐
- 这些文档可能帮助您