DataWorks
大数据开发治理平台 DataWorks基于MaxCompute/EMR/MC-Hologres等大数据计算引擎,为客户提供专业高效、安全可靠的一站式大数据开发与治理平台。每天阿里巴巴集团内部有数万名数据/算法工程师正在使用DataWorks,承担集团99%数据业务构建。
DataWorks on EMR全链路数据湖治理解决方案提供了基于EMR数据湖的一站式湖开发、运维、治理平台,帮助用户快速基于阿里云数据湖构建自己的数据中台.满分通过中国信通院云原生数据湖评测.DAMA(国际数据管理协会)是非营利性、专注数据管理和数字化的全球性专业组织,协会自 1980年成立以来,逐渐成为业界的标杆和权威。目前...
来自:
云产品
中小企业自建Hadoop集群上云解决方案
中小企业自建 Hadoop 集群上云解决方案,助力自建 Hadoop 用户快速构建云上半托管开源大数据平台,在保持原组件使用习惯延续的同时,充分利用云上服务特点,更加便捷地迭代企业大数据平台架构,聚焦业务价值开发。
该方案基于E-MapReduce服务,可结合使用习惯按需选择 ClickHouse、StarRocks、Presto、Impala、Druid 等模块并快速开通,用于支持即席查询、固化查询、宽表加速等场景,提升业务决策效率.多样化 OLAP 查询分析.多样化 OLAP 查询分析.向阿里云提交方案详情咨询.售前技术专家对接,评估需求.需求沟通明确,阿里云架构师及专业...
来自:
解决方案
数据管理与服务
数据管理与服务作为阿里云产品六大版块之一,面向不同业务场景,阿里云提供数据存储、分析、应用等全链路能力,满足企业客户全方位的数据处理需求,实现计算和存储分离、资源解耦、数据移动减化,用以满足行业快速发展的需求和趋势,利用数据重塑其业务。
开源大数据平台E-MapReduce将技术引领优势转化为云上产品服务能力,重磅发布E-MapReduce 2.0,面向未来构建下一代开源大数据基础设施,弹性优化能力提升3倍,伸缩规模达千台,3分钟即可创建100节点的数据湖集群.阿里云开源大数据产品矩阵再升级.2022云栖大会上,阿里云资深产品专家分享基于强大的大数据AI一体化的平台能力...
来自:
云产品
阿里云大数据&AI
阿里云大数据和AI产品服务。开放数据处理服务ODPS提供强大的数据分析和管理功能;开源大数据产品支持更加灵活地构建大数据平台;AI和机器学习产品提供AI工程平台和智算服务。
开源大数据平台 E-MapReduce.致力于数据分析、数据检索等场景服务.检索分析服务 Elasticsearch版.实现协同合作和数据共享.Databricks 数据洞察.开源大数据产品.灵活组合的AI产品体系.机器学习平台 PAI.智能推荐 AIRec.助力开发者快速搭建智能搜索服务.智能开放搜索 OpenSearch.ODPS(Open Data Platform and Service)是...
来自:
云产品
云消息队列 Confluent 版
云消息队列 Confluent 版是阿里云与 Apache Kafka 项目创始团队所创立的 Confluent 公司合作,基于 Apache Kafka 核心能力提供的企业级全托管消息队列服务,旨在为企业提供集成消息流式处理与大数据系统的一站式解决方案。
快速使用云消息队列 Confluent 版.云消息队列 Confluent 版所有文档.云消息队列 Confluent 版计费说明.阿里云与 Confluent 专家技术交流.Apache Kafka 全托管消息服务,大数据生态中不可或缺的消息产品,具备开箱即用、无缝迁移、安全...阿里云 Flink、Databricks、EMR等平台进行数据消费和分布式计算.阿里云产品集成互联互通.
来自:
云产品
RI和SCU全链路使用实践
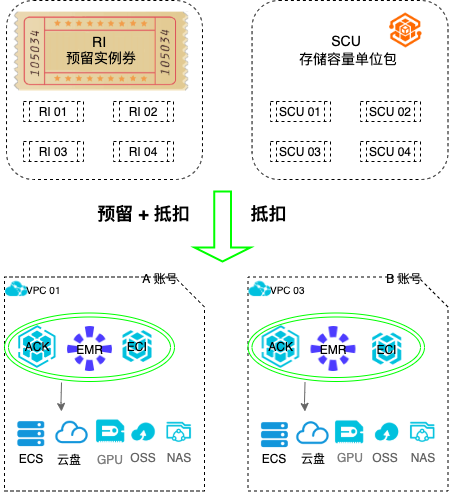
场景描述 随着云计算的不断发展,更多的企业会使用云计算,且会有越来 越多的企业和用户开始重视云上使用成本。 其中计算和存储是云资源使用的主要服务之一。采用预留实例券 业务架构(RI)和存储容量单位包(SCU)可以帮助客户灵活的节省成本。 本文提供全链路使用实践,帮助客户快速验证云上服务,更合理 的使用RI/SCU。借助覆盖率指标和智能推荐,有效管理云上资 源成本。 用户价值 使用RI 和SCU,可以灵活抵扣相关资源。随时创建释放, 稳态业务资源效率提高。 一份RI 可以抵扣ECS+ACK+EMR+ECI 等服务,跨服务高 度灵活,无需再分开购买。 SCU可以跨可用区抵扣某个地域下所有类型的按量付费云 盘,简化购买与管理复杂度。 RI+SCU 大幅降低按量场景的计算和存储成本。 产品列表 专有网络VPC、容器服务Kubernetes 版ACK 云服务器ECS、预留实例券RI、存储容量单位包SCU
其他场景资源说明 其他业务场景,举例:大数据业务,基于阿里云 E-MapReduce(www.aliyun.com/product/emapreduce)开通的计算资源 ECS、挂载的存储资源云盘,只要符合 RI/SCU的抵扣规则,均 可以账单抵扣。远程办公业务,基于云桌面(www.aliyun.com/product/gws)开通的计算资源 ECS、挂载的存储资源云盘,只要符合 RI/...
Databricks数据洞察
阿里云Databricks数据洞察是基于Apache Spark的全托管数据分析平台, 内核采用更高效、稳定的商业版Databricks Runtime和Delta Lake。可满足数据分析师、数据工程师和数据科学家在大数据场景下对数据湖分析、实时数仓、离线数仓、BI数据分析、AI机器学习等需求
百草味基于“EMR+Databricks+DLF”构建云上数据湖.Databricks Lakehouse+AI助力美的暖通云上IoT大数据建设.自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察.使用Databricks的Notebook进行机器学习开发.快速拉起Spark全托管的集群,操作简单,按需付费.全托管分析平台.用户根据需求设置节点数量,支持集群高可用.支持...
来自:
云产品
综合能源服务平台解决方案
阿里云综合能源服务平台解决方案以“厚平台、微应用”方式构建面向竞争性综合能源服务的业务中台,快速构建节电节能、电力需求侧、电务、能效管理、储能、微网一体化和能源电力交易等生态化应用。
数据可视化DataV.DataWorks基于MaxCompute/EMR/MC-Hologres等数据计算引擎,为客户提供专业高效、安全可靠的一站式大数据开发与治理平台,自带阿里巴巴数据中台与数据治理实践,赋能各行业数字化转型.一站式大数据开发Dataworks.阿里云机器学习平台PAI(Platform of Artificial Intelligence),为传统机器学习和深度学习...
来自:
解决方案
利用交互式分析(Hologres)进行数据查询
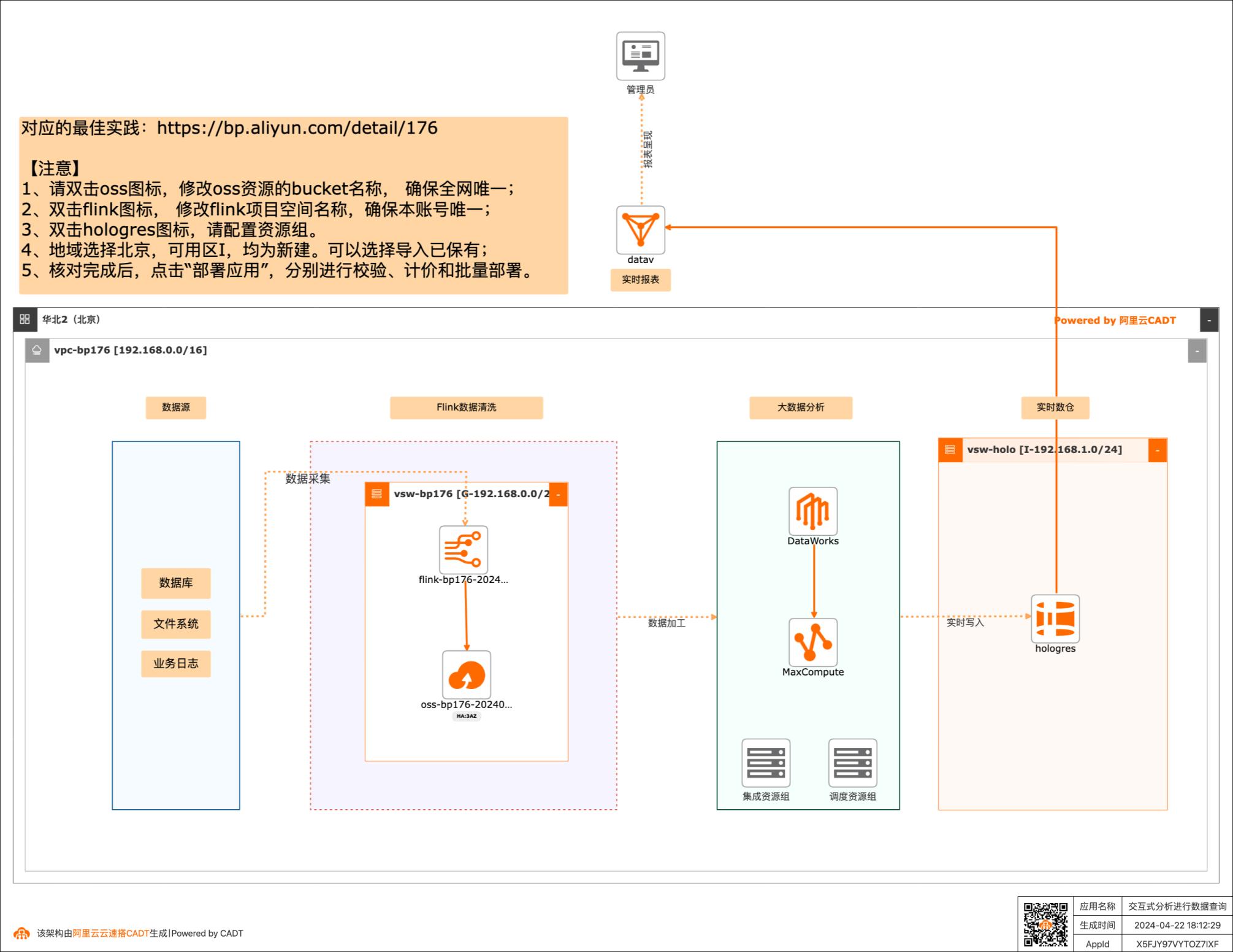
场景描述:随着收集数据的方式不断丰富,企业信息化 程度越来越高,企业掌握的数据量呈TB、 PB或EB级别增长。同时,数据中台的快 速推进,使数据应用主要为数据支撑、用户 画像、实时圈人及广告精准投放等核心业务 服务。高可靠和低延时地数据服务成为企业 数字化转型的关键。 Hologres致力于低成本和高性能地大规模 计算型存储和强大的查询能力,为您提供海 量数据的实时数据仓库解决方案和实时交 互式查询服务。 解决问题 1.加速查询MaxCompute数据 2.快速搭建实时数据仓库 3.无缝对接主流BI工具 产品列表 MaxCompute Hologres 实时计算Flink 专有网络VPC DataWorks DataV
Flink半托管(基于EMR):如果您的公司或团队希望在业务开发的基础上,对整 个集群资源有完全的掌控力,并且熟悉Yarn或阿里云E-MapReduce服务,推 荐您使用Flink半托管(基于EMR)产品。Blink独享集群(原产品线):如果您已经购买阿里云实时计算Blink独享集群,可以考虑继续使用Blink独享集群(原产品线)产品。...
云消息队列 Kafka 版
云消息队列 Kafka 版是阿里云基于Apache Kafka构建的大数据消息中间件,广泛用于日志收集和分析、数据处理等场景。可提供全托管服务,用户无需部署运维,更专业、更可靠、更安全。
可对接开源 Storm/Samza/Spark 以及 EMR、Blink、StreamCompute 等阿里云产品;实时计算 Flink版.云消息队列 MQ.应用实时监控服务 ARMS.推荐搭配使用.近年来KV存储(HBase)、搜索(ElasticSearch)、流式处理(Storm/Spark Streaming/Samza)、时序数据库(OpenTSDB)等专用系统应运而生,产生了同一份数据集需要被注入到...
来自:
云产品
云原生数据仓库AnalyticDB MySQL数据仓库
阿里云云原生数据仓库AnalyticDB MySQL版(简称AnalyticDB)是融合数据库、大数据技术于一体的云原生企业级数据仓库平台。云原生数据仓库AnalyticDB MySQL版支持数据实时写入和同步更新、实时计算和实时服务,可用于构建企业级报表系统、数据仓库和数据服务引擎。
支持数据库(RDS、PolarDB-X、PolarDB、Oracle、SQL Server等),大数据(Flink、Hadoop、EMR、MaxCompute)、OSS、日志数据(Kafka、SLS等)以及本地数据导入.支持多数据源接入.支持一键建仓,通过简单几步配置即可将RDS、PolarDB MySQL、或者日志服务中某个日志库中的数据快速同步到ADB集群中。支持将MySQL分库分表的数据...
来自:
云产品
云存储解决方案
云存储解决方案面向大数据存储、多媒体存储(视频存储)、视频监控、基因生命科学、数据迁移、自动驾驶、在线教育、混合云存储、数据迁移、数据容灾备份等多个行业用户的多元化场景,提供更安全稳定、更优化、无缝上云的智能数据存储服务,为企业上云、实现数字化转型奠定数据基础。
缺服务:相比阿里云 EMR 等,自建大数据集群,缺乏专家支持.难管理:数据分散在多个集群,缺乏数据的统一管理.海量弹性:计算存储分离,存储规模弹性扩容.生态开放:对 Hadoop 生态友好,且无缝对接阿里云各计算平台.高性价比:统一存储池,避免重复拷贝,多种类型冷热分层.更易管理:加密、授权、生命周期、跨区复制等统一...
来自:
解决方案
实时数仓Hologres
Hologres(原交互式分析)是一站式实时数据仓库引擎,支持海量数据实时写入、实时更新、实时分析,支持标准SQL(兼容PostgreSQL协议),支持PB级数据多维分析(OLAP)与自助分析(Ad Hoc),支持高并发低延迟的在线数据服务(Serving),与MaxCompute、Flink、DataWorks深度融合,提供离在线一体化全栈数仓解决方案。
某互联网服务公司原先通过Greenplum、EMR离线架构来搭建实时数仓,但数据更新时效性差,无法实时掌握业务动态。为实现全场景的用户增长需求,采用Flink+Hologres新一代实时数仓,基于业务日志数据构建实时大屏和数据中台系统,加速知识数据探索,促进业务快速发展.完美支撑营收额、订单量等指标实时报表查询,满足企业运营...
来自:
云产品
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
其优点是学习成本低,可以通过类 SQL语句快速 实现简单的 MapReduce统计,不必开发专门的 MapReduce应用,十分适合数据 仓库的统计分析。RDS:阿里云关系型数据库(Relational Database Service,简称 RDS)是一种 稳定可靠、可弹性伸缩的在线数据库服务。基于阿里云分布式文件系统和 SSD盘 高性能存储,RDS支持 MySQL、SQL...
- 产品推荐
- 这些文档可能帮助您