在线教育流量洪峰
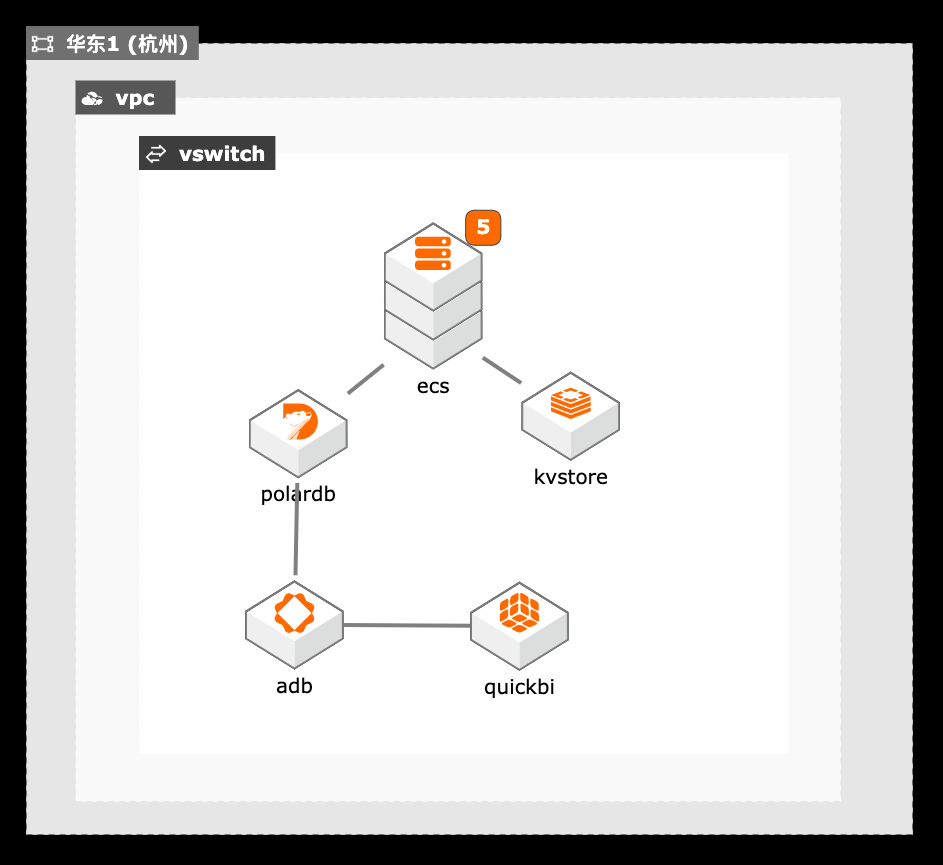
1. 通过Tair缓存的性能增强型解决高并发读的性能问题,通过持久内存型解决大并发写性能及数据可靠性问题。 2. PolarDB作为主数据库保存业务的交易数据,通过弹性能力和并发SQL解决性能瓶颈。 3. ADB+QuickBI提供的数据仓库方案通过分时弹性能力和实时业务展现能力。
根据阿里云数据库团队测试结果,可参考如下对比:文档版本:20210120 17 在线教育流量洪峰最佳实践 大流量缓存方案 3.3.场景二:持久内存缓存 本节将采用压测工具 YCSB来对 Tair进行性能压测,对于 YCSB压测描述请参考:https://github.com/brianfrankcooper/YCSB/wiki/Core-Workloads YCSB的压测中,根据 workload的不同,...
容器跨可用区高可用
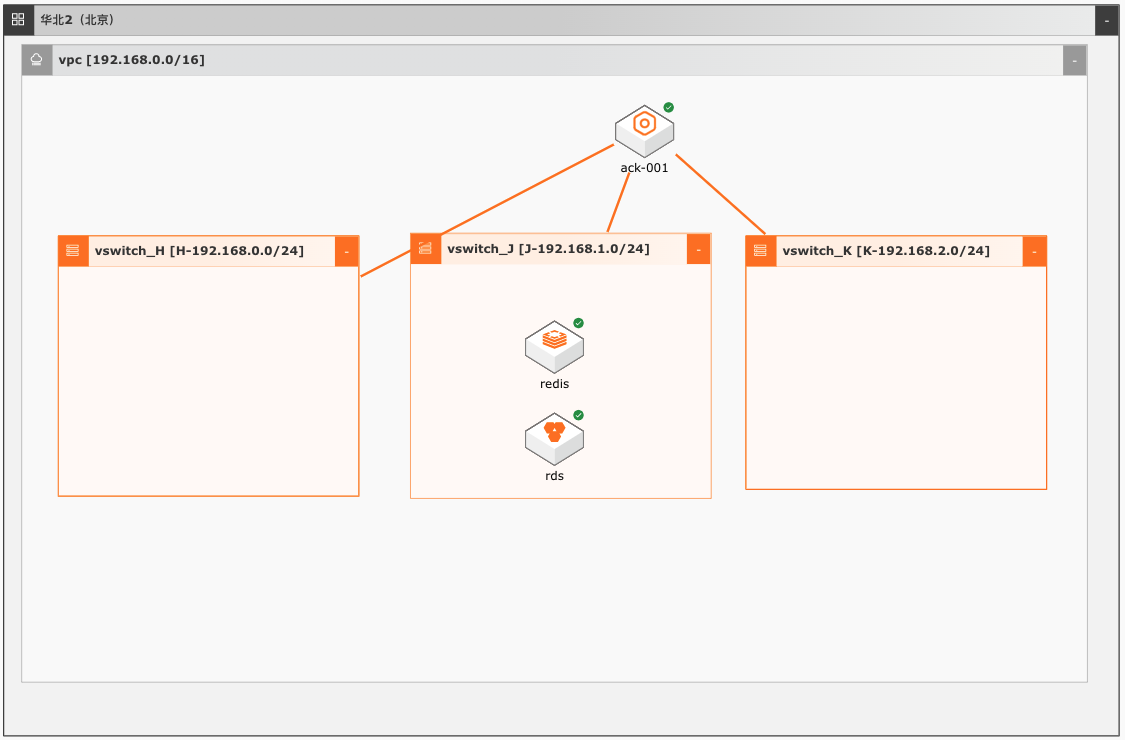
场景描述 本实践适合使用容器服务ACK结合阿里云上的 其他产品构建跨可用区高可用应用的场景。在一 开始创建容器服务ACK的时候就把容器集群建 成多个可用区的架构,某可用区挂掉后,不影响 应用和集群的高可用。容器服务ACK通常配合 高可用SLB,RDS,Redis等产品,实现跨可用 区高可用。 解决问题 1.利用容器服务ACK搭建跨可用区高可用 的应用 2.容器服务ACK结合SLB,RDS,REDIS构 建高可用应用 产品列表 容器服务ACK RDSforMysql版 云数据库Redis版 文件存储NAS
解决问题 利用容器服务 ACK搭建跨可用区高可用 产品列表 的应用 容器服务 ACK 容器服务 ACK结合 SLB,RDS,REDIS构 RDS for Mysql版 建高可用应用 云数据库 Redis 版 文件存储 NAS 云速搭 CADT 最佳实践频道 阿里云最佳实践分享群 云服务器 ECS(产品名称)文档模板(手册名称)/文档版本信息 阿里云 企业上云实践 容器跨...
高性能数据库ECS测试及选型
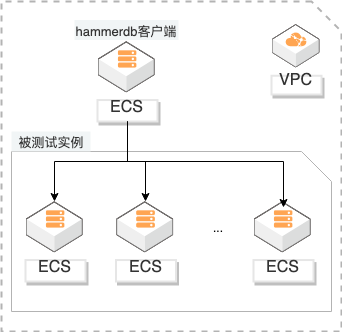
概述 客户自建高性能数据库(如电商大促)在做ECS选型时,对磁盘的IO、网络的吞吐都有很大要求,为了跟接近真实业务场景,使用HammerDB选定真实业务模型测试其TPM。通过对比TPM对比ECS性价比进行选型。同时使用FIO测试磁盘性能作为参考。 适用场景 自建数据库性能测试 磁盘性能测试 ECS选型建议 技术架构 本实践方案基于如下图所示的技术架构和主要流程编写操作步骤: 方案优势 基于标准的TPC-C测试,接近真实业务场景。 提供多规格实例测试,快速选择最优性价比实例。
解决问题 自建数据库性能测试 磁盘性能测试 产品列表 ECS选型建议 专用网络 VPC 云服务器 ECS HammerDB FIO 阿里云最佳实践技术分享群 最佳实践频道 云服务器 ECS(产品名称)文档模板(手册名称)/文档版本信息 阿里云 高性能数据库 ECS测试及选型 最佳实践 文档版本:20201104 文档版本:20150122(发布日期)II 高性能...
基于MyBase构建自主可控数据库和高弹性应用实践
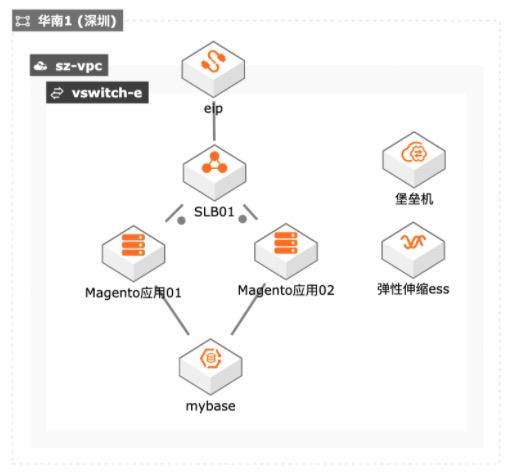
一些企业级客户上云前,会重点关心数据库是否自主可控,包括云资源独享、自主可运维、获取OS 权限等特点,同时又要兼顾数据库合规性、安全性和高性能的要求;并力求在业务弹性下合理利用云产品降低数据和应用成本,弹性地支持业务。本实践为此类用户提供相关实践参考。
云数据库专属集群为 客户独享云资源更加安全,用户既享受到云数据库服务的便捷灵活,又满足企业 对 数 据 库 合 规 性、安 全 性 和 高 性 能 的 要 求。详见:https://www.aliyun.com/product/apsaradb/cddc 堡垒机:集中管理资产权限,全程记录操作数据,实时还原运维场景,助力企业用 户构建云上统一、安全、高效运维...
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
Databricks 数据洞察与阿里云其它产品(Kafka、Redis、MongoDB、Elasticseach、RDS和 MaxCompute等)进行了深度整合,支持以这些产品作为 Spark计算引擎的输入源或者输出目的地。详 情 请 参 见:Databricks 数 据 洞 察 引 入 多 种 数 据 源(https://help.aliyun.com/document_detail/203265.html)文档版本:20210425 ...
小型互联网迁移阿里云
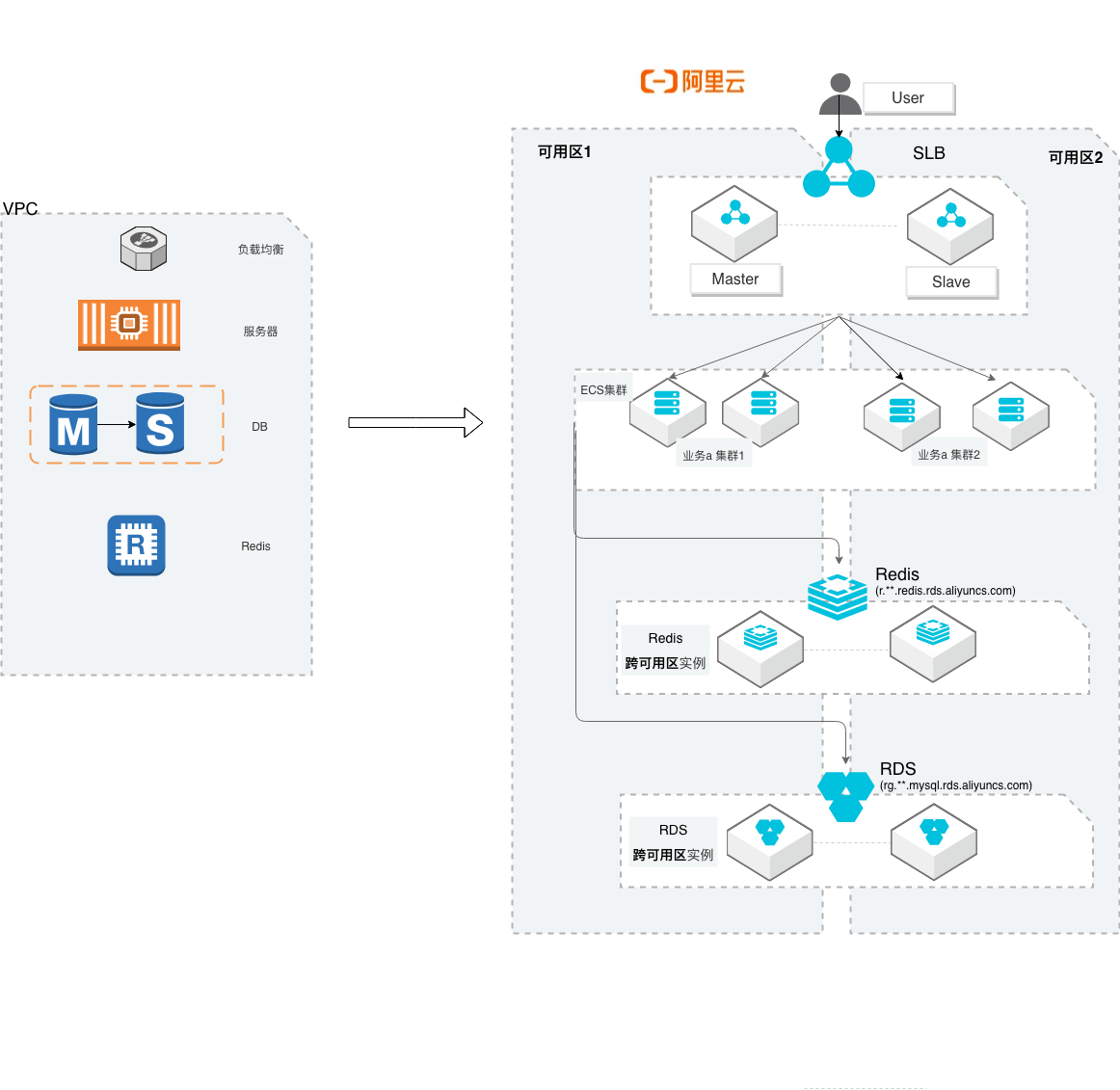
场景描述 本方案主要适用于中小型互联网企业,从他云 迁移到阿里云的最佳实践。方案中会概述网络 规划、服务器、数据库、存储数据、Kafka和 镜像数据的迁移方案描述。同时在实践环节, 增加服务器和RDS的迁移操作演练和验证。 解决问题 提供服务器、数据库等关键环节的平滑迁移方 案 提供云上高可用架构参考 提供模拟简单的演练回归流程机制 产品列表 云服务器(ECS)、迁云工具(SMC)、数据库 (RDS)、数据库(Redis)、数据传输(DTS)、 负载均衡(SLB)、专有络(VPC)等
解决问题 提供服务器、数据库等关键环节的平滑迁移方案 提供云上高可用架构参考 提供模拟简单的演练回归流程机制 产品列表 云服务器(ECS)服务器迁移中心(SMC)数据库(RDS)数据库(Redis)阿里云最佳实践分享群 最佳实践频道 数据传输(DTS)负载均衡(SLB)专有网络(VPC)阿里云 业务上云实践 小型互联网迁移阿里云 ...
应用高可用服务AHAS
应用高可用服务AHAS是阿里云基于内部高可用架构最佳实践而打造的商业化产品,主要提供多活容灾MSHA、容灾演练CHAOS等能力,帮助用户全面提升业务稳定性。
自动识别Redis,Mysql,ZooKeeper等常用的 三方组件 和ECS、RDS、Redis、CDN、DNS、MQ、SLB、EIP、NAT、DDOS、WAF等云资源,同时可识别容器服务、Kubernetes环境中的node、Pod、service、container等资源,将其 拓扑关系 进行可视化展示.根据通用风险规则,定期进行基于架构拓扑中节点的 风险巡检,并将巡检结果可视化直观...
来自:
云产品
ACK集群神龙资源错峰利用
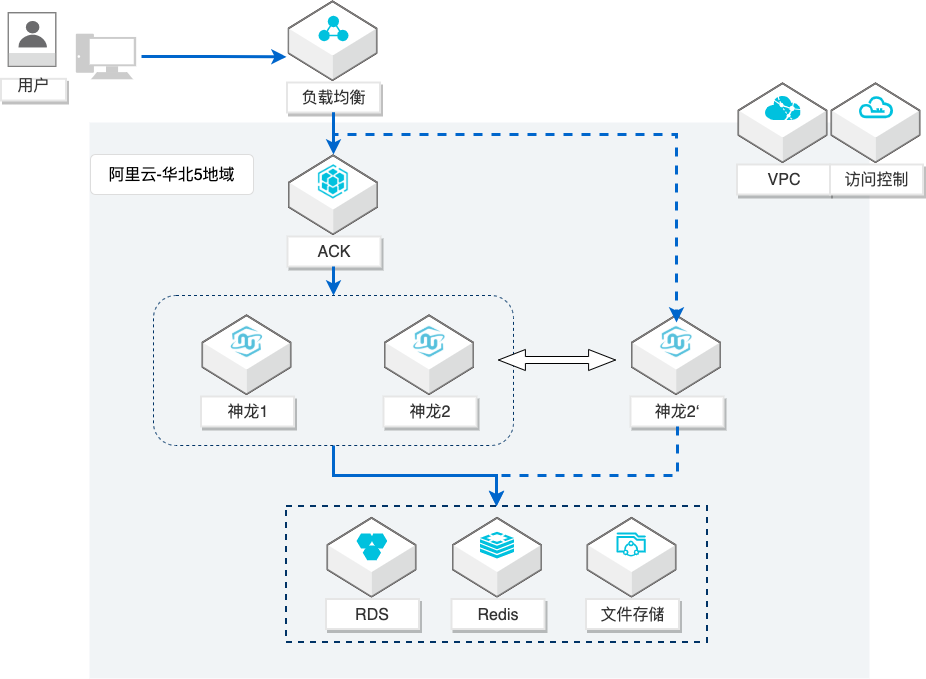
场景描述 使用ACK构建容器集群环境,神龙资源为 集群节点资源部署应用。在主业务低谷 期,通过将部分神龙节点从容器集群中移 除,更换镜像切换操作系统及应用环境, 使得这部分神龙实例资源服务于其他业 务。在主业务高峰期前将神龙资源重新加 入ACK集群。从而达到错峰利用神龙资源 的目的,以便充分利用神龙资源,降低资 源成本。 解决问题 1.基于ACK及神龙资源构建容器集群环 境,典型部署应用。 2.ACK内挂载NAS存储。 3.ACK集群神龙实例节点移除和重新加入 集群。 产品列表 弹性裸金属服务器EBM 容器服务ACK 专有网络VPC 弹性公网IPEIP 负载均衡SLB 云数据库RDS MySQL版 云数据库Redis版 文件存储NAS 访问控制RAM 日志服务SLS 云监控CloudMonitor 运维编排OOS
步骤27 此时,已经可以看到缓存数据写入云数据库 redis版中,表示 redis工作正常。文档版本:20220509 35 ACK集群神龙资源错峰利用 配置应用 2.6.发布测试 步骤1 重新登录 wordpress站点,新建文章,测试站点是否正常工作。步骤2 发布测试文章。文档版本:20220509 36 ACK集群神龙资源错峰利用 配置应用 步骤3 查看文章已...
虚拟桌面架构的高性能体验云上部署
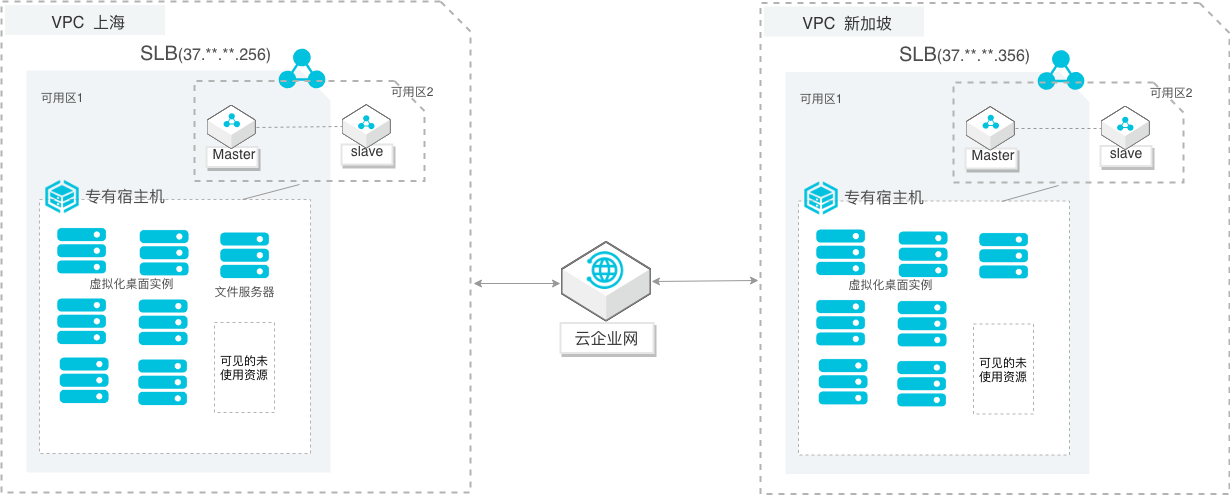
场景描述 针对自建虚拟化桌面架构迁移阿里云,以及有虚拟化桌面 架构需求上云。包括但不限于: 1.有许可证合规要求,利用自带license快速上云的客户。 2.对数据安全较高要求,需要快速构建虚拟化桌面的客 户。 解决问题 利用云上灵活性和规模化优势,构建云上更加高效、高性 能体验的服务,为客户解决: 1.客户VDI部署的需求,能够更及时的得到满足。 2.解决硬件资源限制,根据业务规模化部署并集中管 控。 3.利用公共云的网络、计算、备份容灾方案、安全防护 等,提供高可靠、高性能、高体验的远程桌面服务。 产品列表 VPC(专有网络) SLB(负载均衡) CEN(云企业网) 专有宿主机 OpenAPI
已经开通了如下服务:云服务器(ECS)服务-负载均衡(SLB)服务-云数据库(RDS)服务-云数据库(Redis)服务-专有网络(VPC)服务 提前根据业务发展情况,规划资源。1 企业上云实践 虚拟桌面架构的高性能体验云上部署|演示环境说明 演示环境说明 本示例基础架构图:产品或服务 本文示例 备注 VPC-1 名称:VPC_SH 华东 2...
云数据库专属集群MyBase
云数据库专属集群MyBase是阿里云专为企业级用户定制优化的解决方案。支持MySQL、PostgreSQL、SQL Server、Redis和MongoDB数据库。具有云资源独享、支持资源超分配,自主可运维、开放权限等特点。MyBase不仅能保障客户独享云资源更加安全、享受到云数据库服务的便捷灵活,同时还满足企业对数据库合规性、安全性和高性能的要求。
查看详情 云数据库 Redis 版 高可靠双机热备架构及可无缝扩展的集群架构,满足高读写性能场景及容量需弹性变配的业务需求。查看详情 云数据库 MongoDB 版 云数据库 MongoDB 版支持 ReplicaSet 和 Sharding 两种部署架构,具备安全审计,时间点备份等多项企业能力。在互联网、物联网、游戏、金融等领域被广泛采用。查看详情 ...
来自:
云产品
智能商业分析 Quick BI
瓴羊智能商业分析 Quick BI 是阿里云用户臻选的数据可视化工具,大幅提升数据分析和报表开发效率,一站式满足企业各种场景的数据分析和决策的诉求。
产品功能个人版高级版专业版数据分析仪表板支持支持支持即席分析不支持不支持支持模板市场支持查看所有模块支持查看所有模块,应用已购模块支持查看及应用所有模块电子表格不支持单独购买支持数据大屏不支持单独购买赠送基础容量,可按需增购智能小Q(智能搭建)不支持单独购买单独购买数据应用企业门户不支持支持支持订阅...
来自:
云产品
云数据库 RDS MySQL版
阿里云云数据库RDS MySQL是一种稳定可靠、可弹性伸缩的在线MySQL数据库服务, 提供了高可用、高可靠、高安全、易运维等一站式的数据库解决方案,帮助您免除MySQL运维的烦恼。
相关产品云数据库 RDS MySQL 版本产品数据传输服务 DTS云数据库 Redis 版云服务器 ECS专有网络 VPC一键部署基于 RDS MySQL 实现单机网站架构云化本最佳实践介绍了如何基于 RDS MySQL 把单机系统进行初步云化。很多用户在开始使用云时,会把云(服务器)简单地当成普通物理服务器来使用,比如把应用系统、数据库和文件等都...
来自:
云产品
无影云电脑镜像升级包
在无影云电脑镜像升级包下载页面,下载对应镜像升级包,安装并升级为ASP协议的无影云电脑
游戏公司为了快速抢占市场,需要快速的开发出新产品吸引玩家,云数据库Redis版能减少系统开发复杂度,业务爆发时可轻松弹性扩容,满足高性能业务要求.满足游戏分服类应用的分服、滚服弹性扩展需求;数据持久化能力可减轻业务的数据库引擎负担,降低开发复杂度.解决游戏分服类应用一天多次的开服需求,根据备份文件可直接...
来自:
云产品
互联网业务全球化互通组网
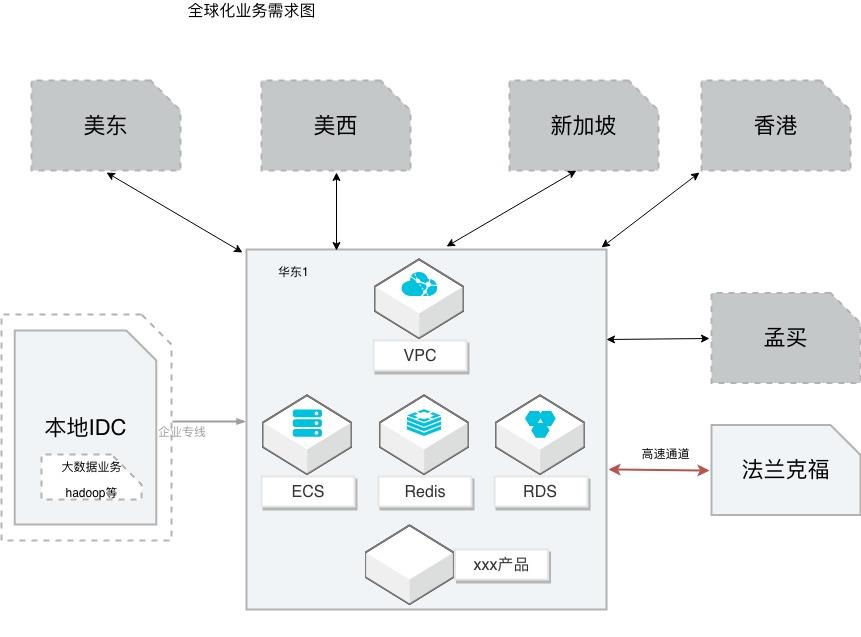
场景描述 本方案适用从事全球化业务的客户,希望借助全球 互通的网络,实现多地域的互通。 同时在全球互联的网络下,搭建应用多地部署。如果 业务中涉及到高速通道,提供高速通道迁移云企业网 的操作演练;涉及到跨账号多VPC下的数据迁移和 同步,本方案提供详细的操作步骤,帮助客户快速完 成演练。 解决问题 借助云企业网解决网络互通 高速通道到云企业网的平滑迁移 RDS的数据互通,特别是跨账号多VPC的数据同步 应用的快速部署 产品列表 云企业网(CEN)、云服务器(ECS)、数据库(RDS)、 数据库(Redis)、数据传输(DTS)、负载均衡(SLB) 块存储、专有网络(VPC)
(https://home.console.aliyun.com)文档版本:20191217 17 互联网业务全球化互通组网最佳实践 模拟应用国内部署 步骤2 通过产品与服务导航,定位到云数据库 Redis版,单击进入云数据库 Redis版管理 控制台。步骤3 在顶部导航栏,选择地域为华南 1(深圳),并单击右侧的创建实例。步骤4 选择按量付费模式,参考下表,配置...
数据管理与服务
数据管理与服务作为阿里云产品六大版块之一,面向不同业务场景,阿里云提供数据存储、分析、应用等全链路能力,满足企业客户全方位的数据处理需求,实现计算和存储分离、资源解耦、数据移动减化,用以满足行业快速发展的需求和趋势,利用数据重塑其业务。
云数据库 Redis 版.云数据库 MongoDB 版.云原生数据仓库 AnalyticDB PostgreSQL 版.数据传输服务 DTS.数据库备份 DBS.云原生内存数据库 Tair.云数据库专属集群 MyBase.云数据库 ClickHouse 版.数据库自治服务 DAS.云原生大数据计算服务 MaxCompute.大数据开发治理平台 DataWorks.实时数仓 Hologres.实时计算 Flink 版.检索...
来自:
云产品
- 产品推荐
- 这些文档可能帮助您