自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
Databricks Runtime版本 Databricks Runtime的版本信息,版本号与 Databricks 官方保持一致,包含 Scala和 Spark的版本。版本详情 请参见 Databricks Runtime版本说明。Python版本 默认版本为 Python3 付费类型 目前支持的付费类型为包年包月和按量付费 可用区 可用区为在同一地域下的不同物理区域,可用区之间内 网互通。...
云原生数据湖分析DLA
阿里云云原生数据湖分析是新一代大数据解决方案,采取计算与存储完全分离的架构,支持对象存储(OSS)、RDS(MySQL等)、NoSQL(MongoDB等)数据源的消息实时归档建仓,提供Presto和Spark引擎,满足在线交互式查询、流处理、批处理、机器学习等诉求。内置大量优化+弹性,比开源自建集群最高降低50%+的成本,最快可1分钟级拉起300个计算节点,快速满足业务资源要求。
适合大量数据清洗,Streaming,编写Java、Scala、Python等SQL难表达的场景.采用Serverless形态,支持Presto和Spark两种引擎,集群分钟级弹性扩缩容,相比线下部署机房成本更低.丰富的产品系列,全面覆盖多种场景需求.CU时资源包.采用按量付费+资源包的付费模式,适用于业务量波动较大且频繁场景。用资源包抵扣数据湖分析...
来自:
云产品
基于Flink+ClickHouse构建实时游戏数据分析
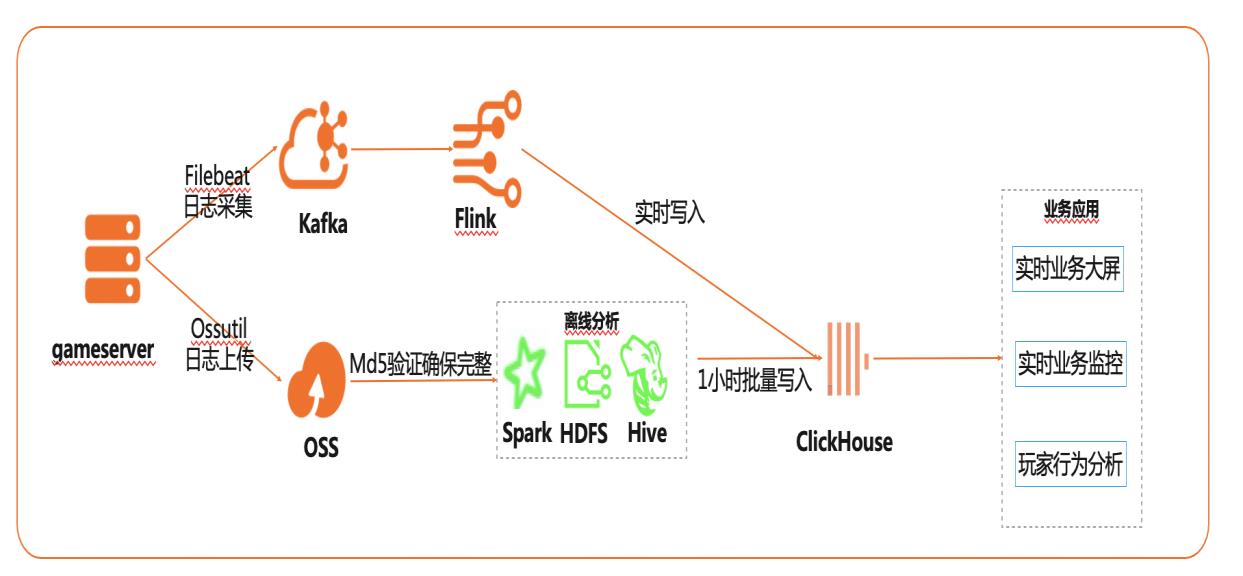
在互联网、游戏行业中,常常需要对用户行为日志进行分析,通过数据挖掘,来更好地支持业务运营,比如用户轨迹,热力图,登录行为分析,实时业务大屏等。当业务数据量达到千亿规模时,常常导致分析不实时,平均响应时间长达10分钟,影响业务的正常运营和发展。 本实践介绍如何快速收集海量用户行为数据,实现秒级响应的实时用户行为分析,并通过实时流计算Flink/Blink、云数据库ClickHouse等技术进行深入挖掘和分析,得到用户特征和画像,实现个性化系统推荐服务。 通过云数据库ClickHouse替换原有Presto数仓,对比开源Presto性能提升20倍。 利用云数据库ClickHouse极致分析性能,千亿级数据分析从10分钟缩短到30秒。 云数据库ClickHouse批量写入效率高,支持业务高峰每小时230亿的用户数据写入。 云数据库ClickHouse开箱即用,免运维,全球多Region部署,快速支持新游戏开服。 Flink+ClickHouse+QuickBI
clickhouse-jdbc 官网上也提供了 scala版的代码演示,详情请查看:https://help.aliyun.com/document_detail/175749.html 7.2. Flink-Connector-ClickHouse 除了可以使用 Flink原生的 JDBC connector以外,还可使用 flink-connector-clickhouse 文档版本:20201224 62 基于 Flink+ClickHouse构建实时游戏数据分析 数据导入 ...
- 产品推荐
- 这些文档可能帮助您