通义灵码助力函数计算FC实现函数编写

现在社会软件开发的复杂性不断增加,服务器配置和运维管理更复杂、开发效率变低。函数计算FC采用无服务器计算模式,用户只需要关注业务逻辑的实现,无需关心底层的服务器配置和运维管理,从而大大降低了运维成本和复杂性,而且具有弹性伸缩、快速部署、按需使用按量付费的特点。通义灵码是阿里云出品的一款基于通义大模型的智能编码辅助工具,可以帮助开发者快速编写高质量的代码,为开发者提供了强大的编程辅助功能。两者的结合让开发者可以更高效地编写函数代码,简化部署流程,提高开发效率。
函数计算FC采用 无服务器计算模式,用户只需要关注业务逻辑的实现,无需关心底层的服务器配置和运维管理,从而大大 降低了运维成本和复杂性,而且具有弹性伸缩、快速部署、按需使用按量付费的特点。通义灵码是阿里云 出品的一款基于通义大模型的智能编码辅助工具,可以帮助开发者快速编写高质量的代码,为开发者提供 了强大...
基于Flink+ClickHouse构建实时游戏数据分析
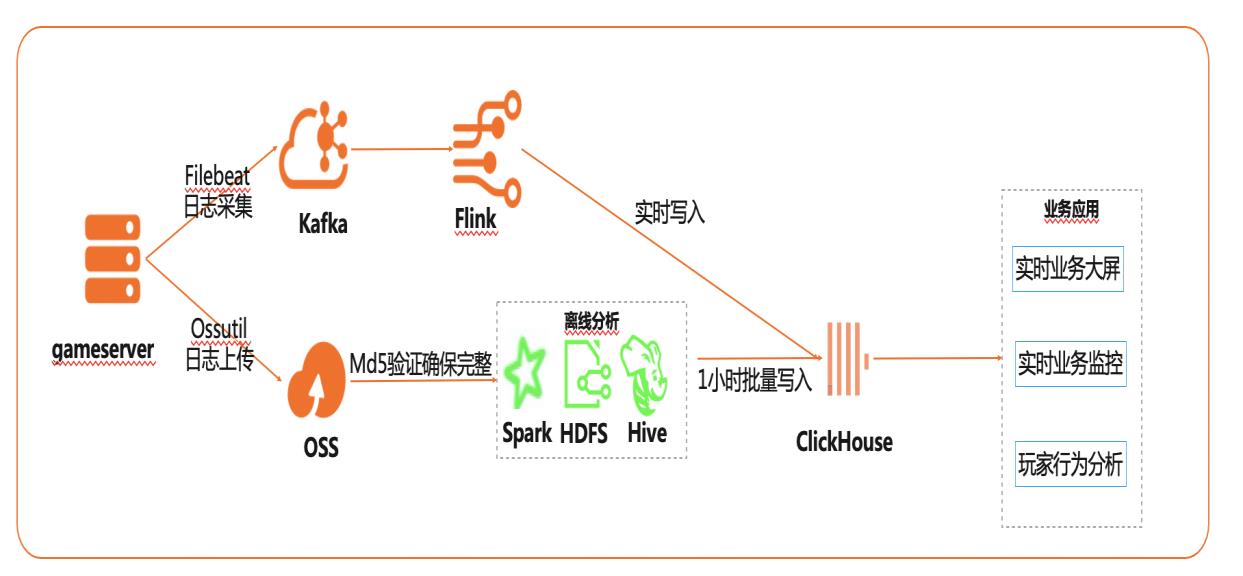
在互联网、游戏行业中,常常需要对用户行为日志进行分析,通过数据挖掘,来更好地支持业务运营,比如用户轨迹,热力图,登录行为分析,实时业务大屏等。当业务数据量达到千亿规模时,常常导致分析不实时,平均响应时间长达10分钟,影响业务的正常运营和发展。 本实践介绍如何快速收集海量用户行为数据,实现秒级响应的实时用户行为分析,并通过实时流计算Flink/Blink、云数据库ClickHouse等技术进行深入挖掘和分析,得到用户特征和画像,实现个性化系统推荐服务。 通过云数据库ClickHouse替换原有Presto数仓,对比开源Presto性能提升20倍。 利用云数据库ClickHouse极致分析性能,千亿级数据分析从10分钟缩短到30秒。 云数据库ClickHouse批量写入效率高,支持业务高峰每小时230亿的用户数据写入。 云数据库ClickHouse开箱即用,免运维,全球多Region部署,快速支持新游戏开服。 Flink+ClickHouse+QuickBI
ClickHouse对数据采用有序存储的方式,其核心思想是充分利用了磁盘批量顺序读写 的性能要远远高于随机读写的特征,并且结合 LSM tree的设计进一步进行优化,使得 写性能达到最优(可达到 200MB/S)。Presto,支持 SQL 并提供了一个标准数据库的语法特性,但其不是一个通常意义上的 关系数据库,而是定位在数据仓库和数据分析...
云原生数据湖分析DLA
阿里云云原生数据湖分析是新一代大数据解决方案,采取计算与存储完全分离的架构,支持对象存储(OSS)、RDS(MySQL等)、NoSQL(MongoDB等)数据源的消息实时归档建仓,提供Presto和Spark引擎,满足在线交互式查询、流处理、批处理、机器学习等诉求。内置大量优化+弹性,比开源自建集群最高降低50%+的成本,最快可1分钟级拉起300个计算节点,快速满足业务资源要求。
数据湖分析采用Serverless形态,无基础设施和管理成本,互联网直接访问,开箱即用,按需付费,不需要长期持有分析成本,升级期间对业务影响小,产品迭代敏捷快速.Presto引擎.Presto引擎是数据湖分析基于Presto打造的交互式分析引擎,接入MySQL协议,可使用任何兼容MySQL协议的工具来进行数据分析,适合Adhoc查询、BI分析、...
来自:
云产品
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
scp/etc/profile slave1:/etc/scp/etc/profile slave2:/etc/scp/etc/profile slave3:/etc/步骤7 下载本实践方案中需要的 Hadoop配置文件,已经预先进行了配置,只需更改少量内 容即可使用。1.下载配置文件包并解压缩。cd~wget ...
SLS多云日志采集、处理及分析
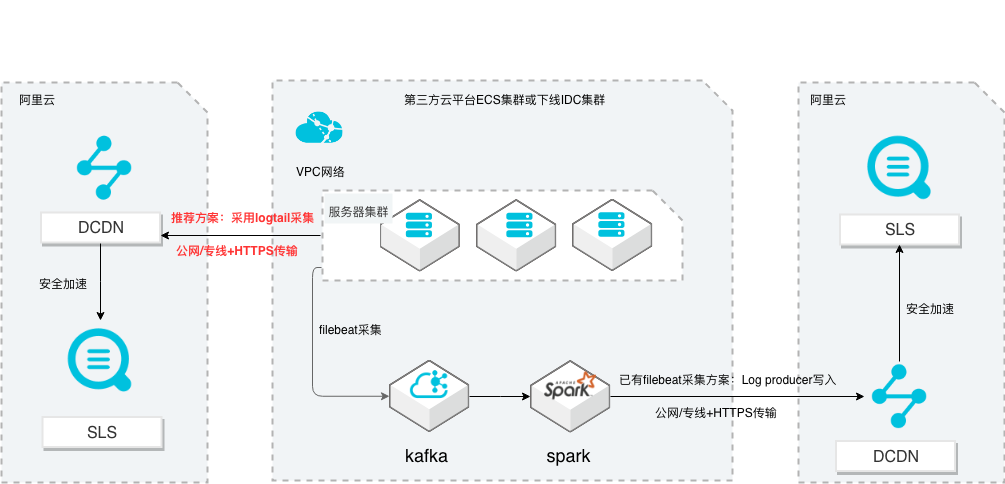
场景描述 从第三方云平台或线下IDC服务器上采集 日志写入到阿里云日志服务,通过日志服务 进行数据分析,帮助提升运维、运营效率, 建立DT 时代海量日志处理能力。 针对未使用其他日志采集服务的用户,推荐 在他云或线下服务器安装logtail采集并使用 Https安全传输;针对已使用其他日志采集 工具并且已有日志服务需要继续服务的情 况,可以通过Log producer SDK写入日志 服务。 解决问题 1.第三方云平台或线下IDC客户需要使用 阿里云日志服务生态的用户。 2.第三方云平台或线下IDC服务器已有完 整日志采集、处理及分析的用户。 产品列表 E-MapReduce 专有网络VPC 云服务器ECS 日志服务LOG DCDN
针对已使用其他日志采 集工具并且已有日志服务需要继续服务的 情况,可以通过 Log producer SDK写入日 产品列表 志服务。E-MapReduce 专有网络 VPC 解决问题 云服务器 ECS 日志服务 SLS 1.第三方云平台或线下 IDC客户需要使用 DCDN 阿里云日志服务进行日志采集、处理和 Kafka 分析 2.第三方云平台或线下 IDC服务器已有完 整...
实时计算Flink版
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,具备实时应用的作业开发、数据调试、运行与监控、自动调优、智能诊断等全生命周期能力。内核引擎100%兼容Apache Flink,2倍性能提升,拥有FlinkCDC、动态CEP等企业级增值功能,内置丰富上下游连接器,助力企业构建高效、稳定和强大的实时数据应用。
一站式开发管理平台,包括SQL/Java/Scala/Python\\u00A0语言.支持主流\\u00A0Flink\\u00A0版本,包括多版本作业代码比较和回滚.内置统一元数据管理,并可无缝对接外部元数据系统.内置多个领域函数库,并可按需自定义函数.提供20多个Flink\\u00A0SQL常见通用场景的模版.支持线上采样和模拟测试数据管理.基于Session集群实现...
来自:
云产品
- 产品推荐
- 这些文档可能帮助您