通义灵码助力函数计算FC实现函数编写

现在社会软件开发的复杂性不断增加,服务器配置和运维管理更复杂、开发效率变低。函数计算FC采用无服务器计算模式,用户只需要关注业务逻辑的实现,无需关心底层的服务器配置和运维管理,从而大大降低了运维成本和复杂性,而且具有弹性伸缩、快速部署、按需使用按量付费的特点。通义灵码是阿里云出品的一款基于通义大模型的智能编码辅助工具,可以帮助开发者快速编写高质量的代码,为开发者提供了强大的编程辅助功能。两者的结合让开发者可以更高效地编写函数代码,简化部署流程,提高开发效率。
填写函数名称 运行环境选择这里以python3.10为例,也可以选择自己平时使用的编程语言,目前,通义灵码支持Java、Python、Go、C#、C/C++、JavaScript、TypeScript、PHP、Ruby、Rust、Scala、Kotlin等多种主流编程语言。 使用示例代码hello,world!示例 配置环境变量,完成函数创建。 加入环境变量,使用JSON格式...
云消息队列 Confluent 版
云消息队列 Confluent 版是阿里云与 Apache Kafka 项目创始团队所创立的 Confluent 公司合作,基于 Apache Kafka 核心能力提供的企业级全托管消息队列服务,旨在为企业提供集成消息流式处理与大数据系统的一站式解决方案。
快速使用云消息队列 Confluent 版.云消息队列 Confluent 版所有文档.云消息队列 Confluent 版计费说明.阿里云与 Confluent 专家技术交流.云消息队列 Confluent 版正式发布!云消息队列 Confluent 版正式发布!查看全部产品.云消息队列 Confluent 版是阿里云与 Apache Kafka 项目创始团队所创立的 Confluent 公司合作,基于...
来自:
云产品
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
Databricks Runtime版本 Databricks Runtime的版本信息,版本号与 Databricks 官方保持一致,包含 Scala和 Spark的版本。版本详情 请参见 Databricks Runtime版本说明。Python版本 默认版本为 Python3 付费类型 目前支持的付费类型为包年包月和按量付费 可用区 可用区为在同一地域下的不同物理区域,可用区之间内 网互通。...
云原生数据湖分析DLA
阿里云云原生数据湖分析是新一代大数据解决方案,采取计算与存储完全分离的架构,支持对象存储(OSS)、RDS(MySQL等)、NoSQL(MongoDB等)数据源的消息实时归档建仓,提供Presto和Spark引擎,满足在线交互式查询、流处理、批处理、机器学习等诉求。内置大量优化+弹性,比开源自建集群最高降低50%+的成本,最快可1分钟级拉起300个计算节点,快速满足业务资源要求。
用资源包抵扣数据湖分析所有按量付费实例(Presto和Spark引擎实例)消费,使用期间按量付费实例灵活升降配,不用考虑升配后剩余预付费时长的差价,资源包不使用不抵扣,相比包年包月和按量付费更灵活易用,性价比高.支持数据湖分析Presto和Spark引擎实例,适用于查询频率高、查询数据量较大的场景。按CPU和内存规格进行收费...
来自:
云产品
基于Flink+ClickHouse构建实时游戏数据分析
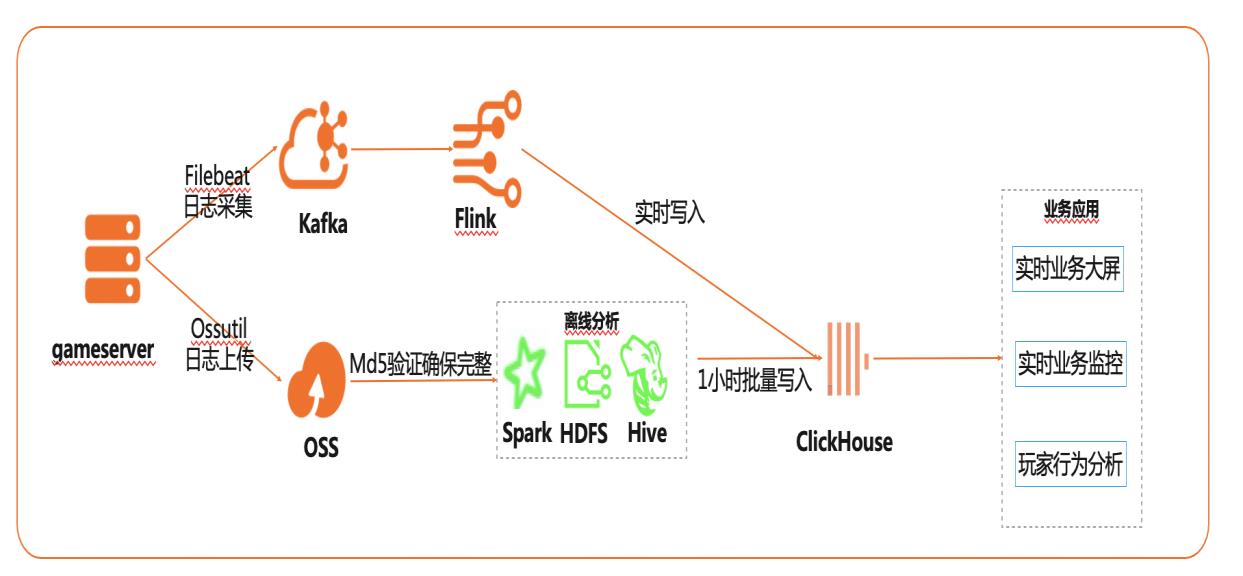
在互联网、游戏行业中,常常需要对用户行为日志进行分析,通过数据挖掘,来更好地支持业务运营,比如用户轨迹,热力图,登录行为分析,实时业务大屏等。当业务数据量达到千亿规模时,常常导致分析不实时,平均响应时间长达10分钟,影响业务的正常运营和发展。 本实践介绍如何快速收集海量用户行为数据,实现秒级响应的实时用户行为分析,并通过实时流计算Flink/Blink、云数据库ClickHouse等技术进行深入挖掘和分析,得到用户特征和画像,实现个性化系统推荐服务。 通过云数据库ClickHouse替换原有Presto数仓,对比开源Presto性能提升20倍。 利用云数据库ClickHouse极致分析性能,千亿级数据分析从10分钟缩短到30秒。 云数据库ClickHouse批量写入效率高,支持业务高峰每小时230亿的用户数据写入。 云数据库ClickHouse开箱即用,免运维,全球多Region部署,快速支持新游戏开服。 Flink+ClickHouse+QuickBI
clickhouse-jdbc 官网上也提供了 scala版的代码演示,详情请查看:https://help.aliyun.com/document_detail/175749.html 7.2. Flink-Connector-ClickHouse 除了可以使用 Flink原生的 JDBC connector以外,还可使用 flink-connector-clickhouse 文档版本:20201224 62 基于 Flink+ClickHouse构建实时游戏数据分析 数据导入 ...
实时计算Flink版
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,具备实时应用的作业开发、数据调试、运行与监控、自动调优、智能诊断等全生命周期能力。内核引擎100%兼容Apache Flink,2倍性能提升,拥有FlinkCDC、动态CEP等企业级增值功能,内置丰富上下游连接器,助力企业构建高效、稳定和强大的实时数据应用。
一站式开发管理平台,包括SQL/Java/Scala/Python\\u00A0语言.支持主流\\u00A0Flink\\u00A0版本,包括多版本作业代码比较和回滚.内置统一元数据管理,并可无缝对接外部元数据系统.内置多个领域函数库,并可按需自定义函数.提供20多个Flink\\u00A0SQL常见通用场景的模版.支持线上采样和模拟测试数据管理.基于Session集群实现...
来自:
云产品
SLS多云日志采集、处理及分析
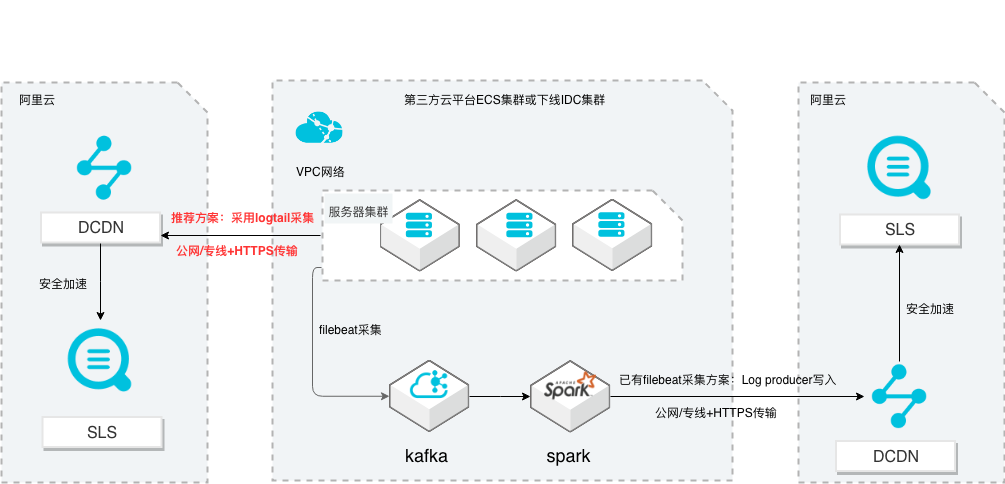
场景描述 从第三方云平台或线下IDC服务器上采集 日志写入到阿里云日志服务,通过日志服务 进行数据分析,帮助提升运维、运营效率, 建立DT 时代海量日志处理能力。 针对未使用其他日志采集服务的用户,推荐 在他云或线下服务器安装logtail采集并使用 Https安全传输;针对已使用其他日志采集 工具并且已有日志服务需要继续服务的情 况,可以通过Log producer SDK写入日志 服务。 解决问题 1.第三方云平台或线下IDC客户需要使用 阿里云日志服务生态的用户。 2.第三方云平台或线下IDC服务器已有完 整日志采集、处理及分析的用户。 产品列表 E-MapReduce 专有网络VPC 云服务器ECS 日志服务LOG DCDN
由于本实践仅有一台云服务器,因此机器组配置里使用了 IP地址作为机器组标识,在 VPC等自定义网络环境或者有多台服务器需要进行弹性伸缩的场景下,建议使 用用户自定义标识作为机器组标识 2.关于用户自定义标识 的配置,请查阅阿里云官网文档:https://help.aliyun.com/document_detail/28983.html 成功创建机器组,您可以...
通过ES兼容接口方式使用Kibana访问SLS数据
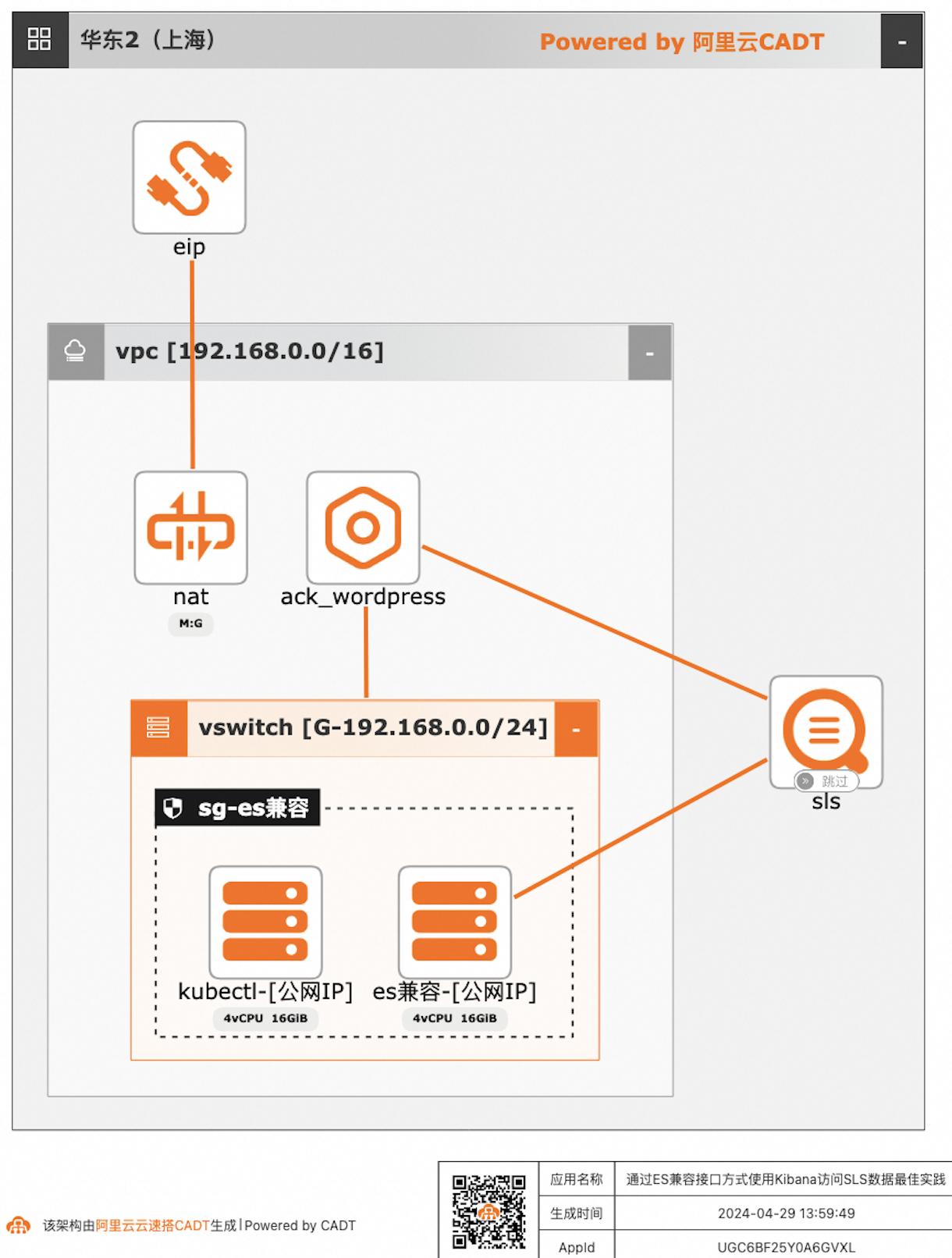
自建ELK日志系统的客户迁移到阿里云日志服务SLS后,对SLS查询分析语法不太熟悉的客户,可以继续沿用原有的查询分析习惯,在不改变使用方式习惯的情况下,通过Elasticsearch兼容接口的方式使用Kibana访问SLS。
解决问题 如何使用ACK部署Wordpress应用,并使 用SLS采集容器日志到SLS 最大程度保障Elasticsearch查询分析方 案迁移SLS的平滑度; 降低将日志引擎从Elasticsearch切换为 日志服务的使用难度;产品列表 专有网络VPC 云服务器ECS 容器服务Kubernetes版 日志服务SLS 阿里云交换机 最佳实践频道 最佳...
MSE网关使用JWT进行认证鉴权
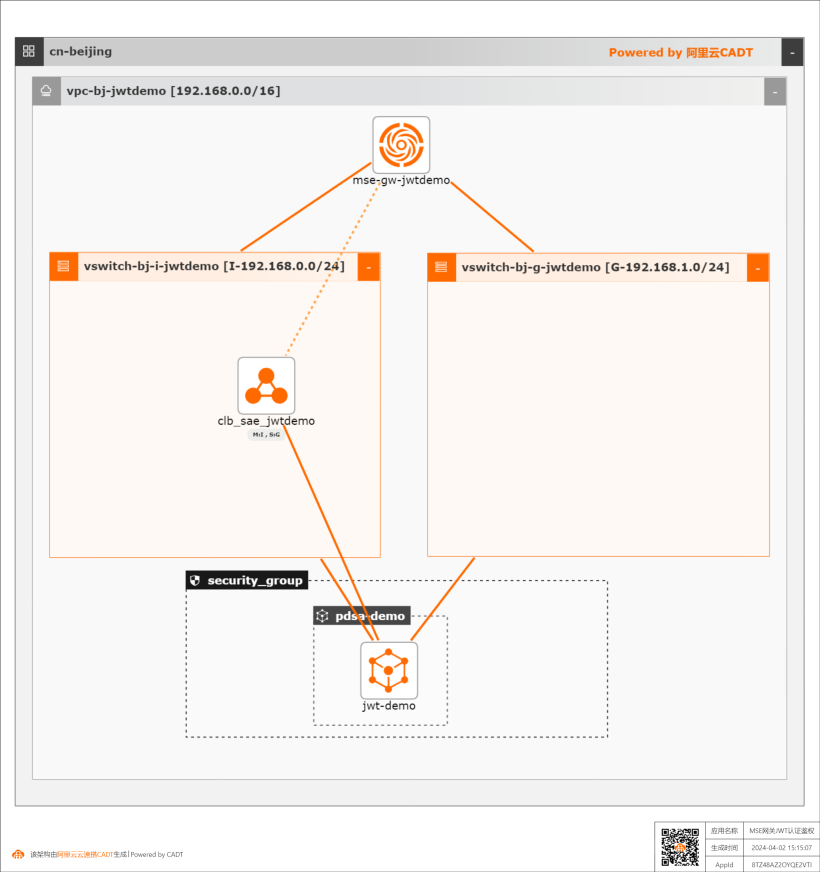
MSE网关中调用外部的认证鉴权服务,通过JWT的方式进行全局认证鉴权。 对网关有认证鉴权安全需求的场景,对于敏感的服务路由(可通过黑白名单方式配置)在网关层进行认证鉴权。
SAE能够让您免运维 IaaS和 K8s,秒级完 成从源代码、代码包、Docker镜像部署任意语言的在线应用(例如 Web、微服务、Job任务)到 SAE,并自动伸缩实例按使用量计费,开箱即用日志、监控、负载 均衡等配套能力。云速搭 CADT(Cloud Architect Design Tools):是一款为上云应用提供自助式云 架构管理的产品,显著地降低应用...
限制企业仅使用已批准的云服务
客户使用资源目录集中管理云上账号,通过管控策略创建“只能使用批准的云服务”对应的Policy,实现企业在云上只能使用批准的云服务,从而规范用户使用云产品的行为。
产品解决方案文档与社区权益中心定价云市场合作伙伴支持与服务了解阿里云备案控制台限制企业仅使用已批准的云服务方案介绍方案优势应用场景方案部署方案权益限制企业仅使用已批准的云服务客户使用资源目录集中管理云上账号,通过管控策略创建“只能使用批准的云服务”对应的Policy,将Policy绑定到资源目录的Root资源夹,则...
来自:
解决方案
RI和SCU全链路使用实践
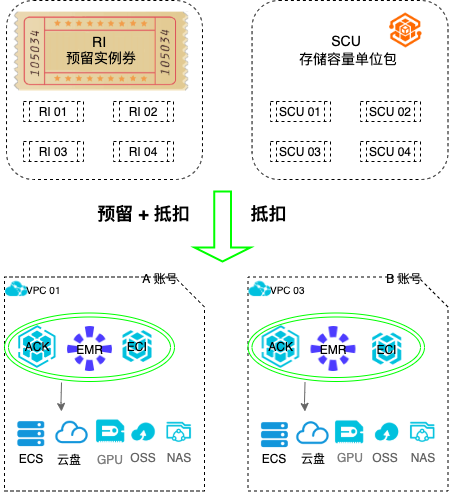
场景描述 随着云计算的不断发展,更多的企业会使用云计算,且会有越来 越多的企业和用户开始重视云上使用成本。 其中计算和存储是云资源使用的主要服务之一。采用预留实例券 业务架构(RI)和存储容量单位包(SCU)可以帮助客户灵活的节省成本。 本文提供全链路使用实践,帮助客户快速验证云上服务,更合理 的使用RI/SCU。借助覆盖率指标和智能推荐,有效管理云上资 源成本。 用户价值 使用RI 和SCU,可以灵活抵扣相关资源。随时创建释放, 稳态业务资源效率提高。 一份RI 可以抵扣ECS+ACK+EMR+ECI 等服务,跨服务高 度灵活,无需再分开购买。 SCU可以跨可用区抵扣某个地域下所有类型的按量付费云 盘,简化购买与管理复杂度。 RI+SCU 大幅降低按量场景的计算和存储成本。 产品列表 专有网络VPC、容器服务Kubernetes 版ACK 云服务器ECS、预留实例券RI、存储容量单位包SCU
相比于随 ECS预付费实例购买 云盘的模式,存储容量单位包与按量付费云盘的组合使用,兼具性价比与资源使 用的灵活性。详见:www.aliyun.com/product/scu 文档版本:20200608(发布日期)IV RI和SCU全链路使用实践 目录 目录 文档版本信息.I 法律声明.II 前言.III 目录.V 前置条件.1 1.实践概述.2 2.成本节省对比.6 2.1.业务...
混合云自有K8S弹性使用ECI
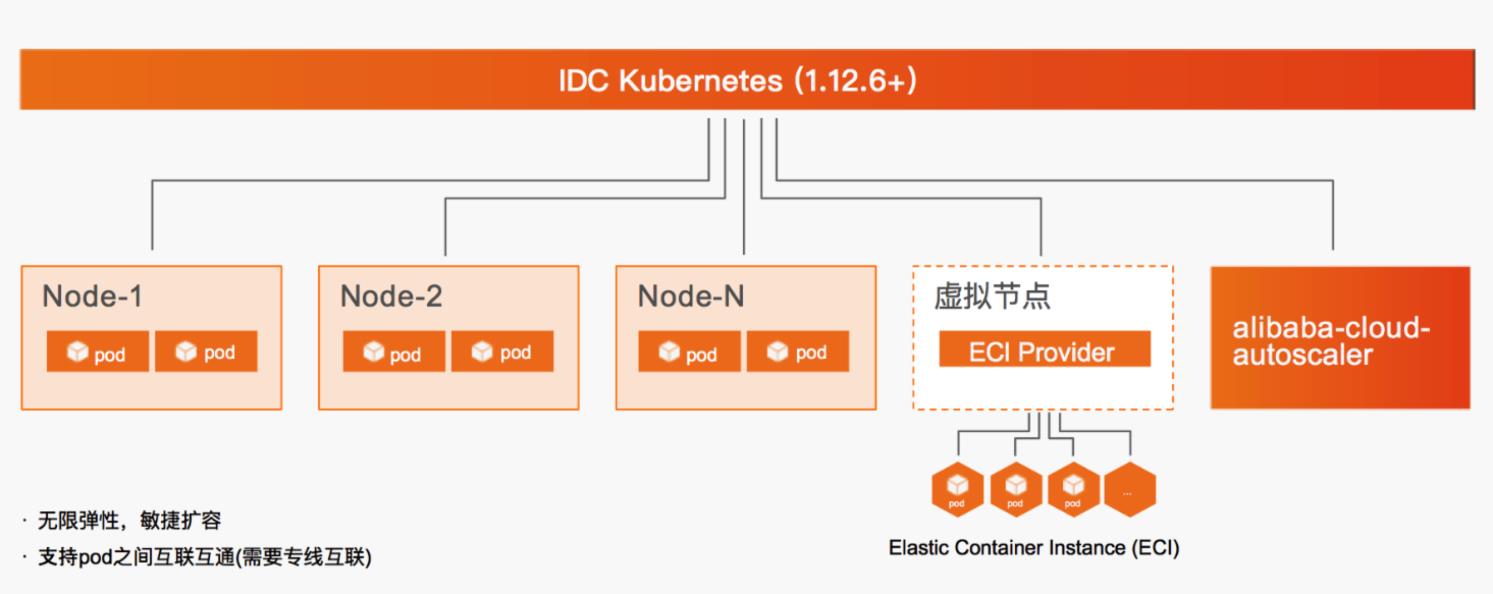
场景描述 本文介绍线下IDC与云端通过专线构建混合云架构,自有K8S利用虚拟节点弹性调用ECI承载业务高峰期资源需求的最佳实践。 解决问题 混合云环境下,自有K8S集群注册至ACK,实现云端纳管。纳管K8S集群部署Virtual Node,使集群具备ECI资源调度能力。在以上环境中部署Web及离线作业应用,并使用ECI资源作为弹性资源池满足业务波峰需求。 产品列表 云服务器ECS 云架构设计工具CADT 专有网络VPC 访问控制RAM 云企业网CEN 弹性容器实例ECI Nat网关NAT 容器镜像服务ACR 负载均衡SLB 容器服务Kubernetes版ACK 弹性公网IPEIP
本实践与阿里云 ACK官方使 用的版本对齐,安装 Docker CE 19.03.5,K8S 1.16.10版本。以 node1为例,node2、node3、node4节点上都按以下步骤操作。操作步骤 步骤1 调整相关系统服务。1.禁用防火墙。systemctl stop firewalld&systemctl disable firewalld 2.确认 SELinux状态为关闭状态。sestatus 如 SELinux未关闭,使用...
混合云使用Ali-Perseus
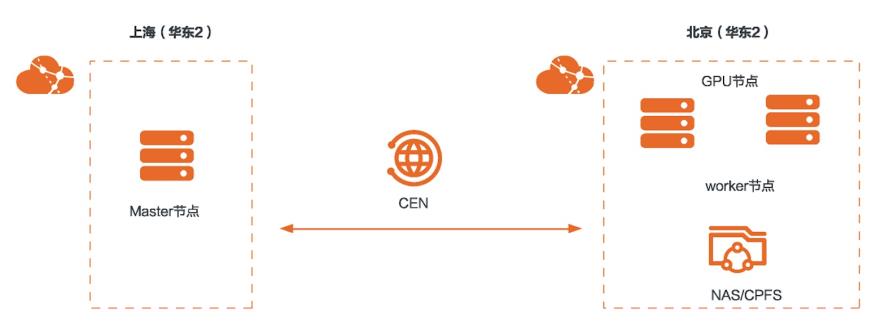
场景描述 本文介绍了混合云场景中,自建 Kubernetes服务,线下集群+云上弹性扩 展阿里云GPU服务实例+飞天AI加速工 具,并采用阿里云CPFS存储,运行AI训 练+AI推理作业的操作步骤。 解决问题 1.利用云企业网打通两个地域的VPC, 自建Kubernetes集群 2.使用飞天AI加速工具运行训练和推理 作业 3.使用CPFS存储共享数据 产品列表 云企业网CEN GPU云服务器 并行文件存储CPFS 文件存储NAS
混合云使用飞天 AI加速工具 最佳实践 场景描述 部署架构 本文介绍了混合云场景中,自建 Kubernetes服务,线下集群+云上弹性扩 展阿里云 GPU服务实例+飞天 AI加速工 具,并采用阿里云 CPFS存储,运行 AI训 练+AI推理作业的操作步骤。解决问题 1.利用云企业网打通两个地域的 VPC,自建 Kubernetes集群 阿里云最佳实践分享群 ...
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测实践 业务架构 场景描述 数据湖和数据仓库是当前大数据技术条件下构建分布式系 统的两种数据架构设计取向,数据湖偏向灵活性,数据仓 库侧重成本、性能、安全、治理等企业级特性。但是数据 湖和数据仓库的边界正在慢慢模糊,数据湖自身的治理能 力、数据仓库延伸到外部...
- 产品推荐
- 这些文档可能帮助您