MSE云原生网关解析body内容进行路由转发
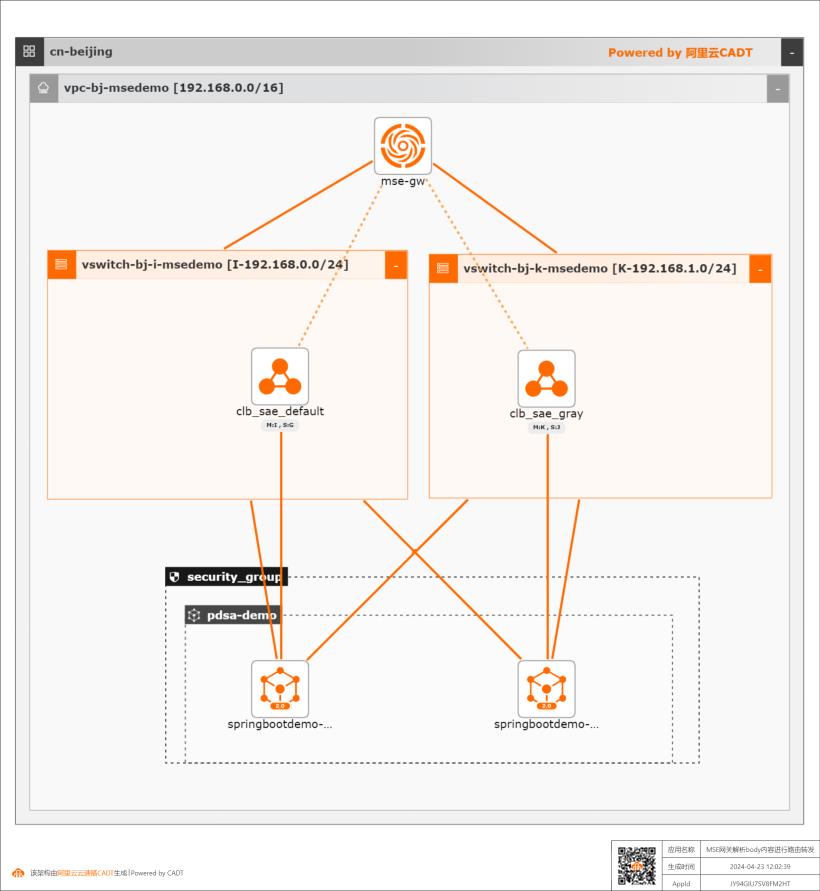
MSE云原生网关中通过自定义插件transformer解析body内容,并用以路由转发规则判断
文档版本:20240426 10 MSE云原生网关解析 body内容进行路由转发 方案验证 步骤3 单击 transformer自定义插件打开插件的配置界面,在插件配置的右上角点击【编辑】链接 更新插件 YAML 在 YAML编辑窗口中输入以下内容(注意缩进):reqRules:operate:map headers:fromKey:userId toKey:version mapSource:body 该脚本的含义...
自建Hadoop迁移到阿里云EMR
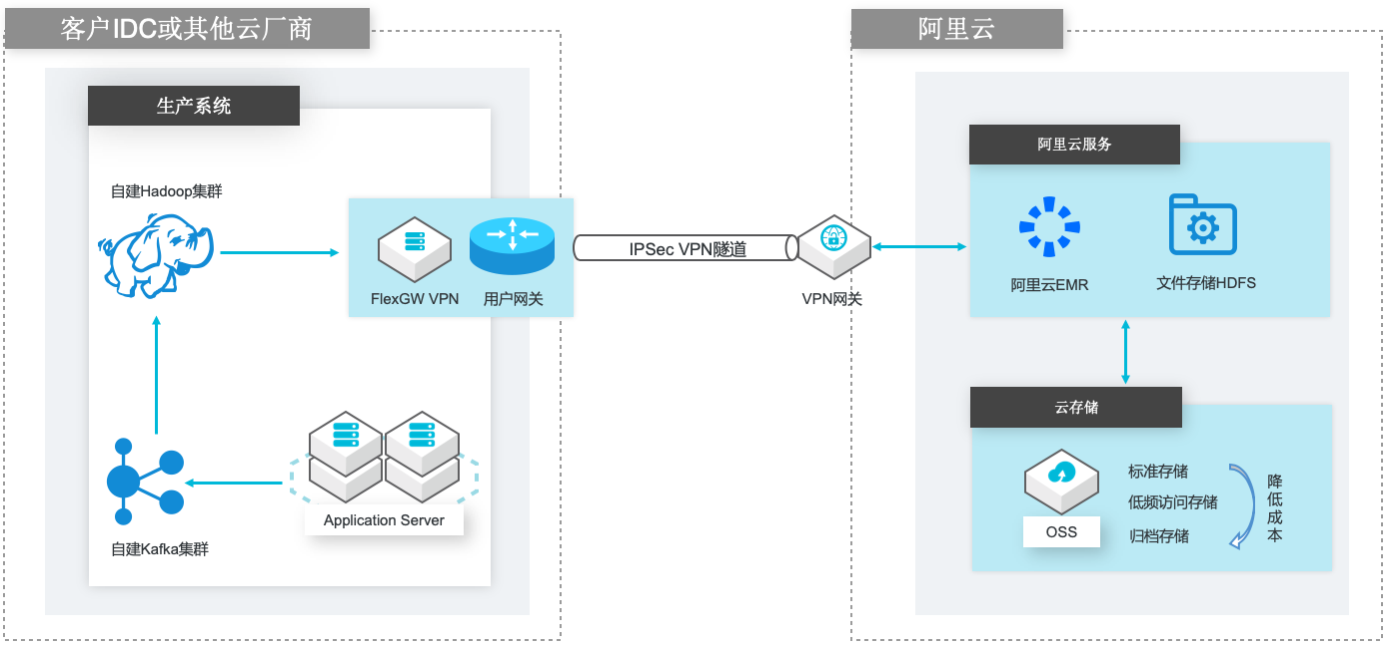
场景描述 场景1:自建Hadoop集群数据(HDFS)迁移到 阿里云EMR集群的HDFS文件系统; 场景2:自建Hadoop集群数据(HDFS)迁移到 计算存储分离架构的阿里云EMR集群,以OSS 和JindoFS作为EMR集群的后端存储。 解决的问题 客户自建Hadoop迁移到阿里云EMR集群的 技术方案; 基于IPSecVPN隧道构建安全和低成本数据 传输链路 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
yum install-y java java-1.8.0-openjdk-devel.x86_64 ssh slave1"yum install-y java java-1.8.0-openjdk-devel.x86_64"ssh slave2"yum install-y java java-1.8.0-openjdk-devel.x86_64"ssh slave3"yum install-y java java-1.8.0-openjdk-devel.x86_64"步骤5 下载并解压缩 Hadoop 2.10.1文件包。1.下载软件包,下面两...
SLS多云日志采集、处理及分析
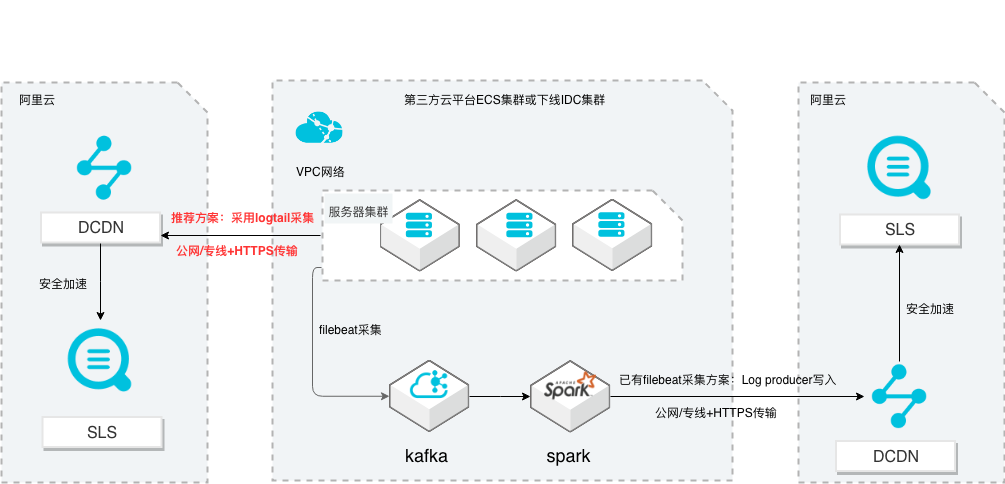
场景描述 从第三方云平台或线下IDC服务器上采集 日志写入到阿里云日志服务,通过日志服务 进行数据分析,帮助提升运维、运营效率, 建立DT 时代海量日志处理能力。 针对未使用其他日志采集服务的用户,推荐 在他云或线下服务器安装logtail采集并使用 Https安全传输;针对已使用其他日志采集 工具并且已有日志服务需要继续服务的情 况,可以通过Log producer SDK写入日志 服务。 解决问题 1.第三方云平台或线下IDC客户需要使用 阿里云日志服务生态的用户。 2.第三方云平台或线下IDC服务器已有完 整日志采集、处理及分析的用户。 产品列表 E-MapReduce 专有网络VPC 云服务器ECS 日志服务LOG DCDN
步骤6 开始读取 RDD 数据集,并通过 map 函数把读取的 JavaRDD>中的 Payload(即 kafka中的消息)提取转化为 JavaRDD,并通过 collect函数把 RDD数据转化为 List。步骤7 创建 producer,使用多线程对 List中的数据进行处理,写入日志服务(这里数据写入 文档版本:20211203 61 SLS多云日志采集、处理及分析 编写 Spark作业...
大数据近实时数据投递MaxCompute
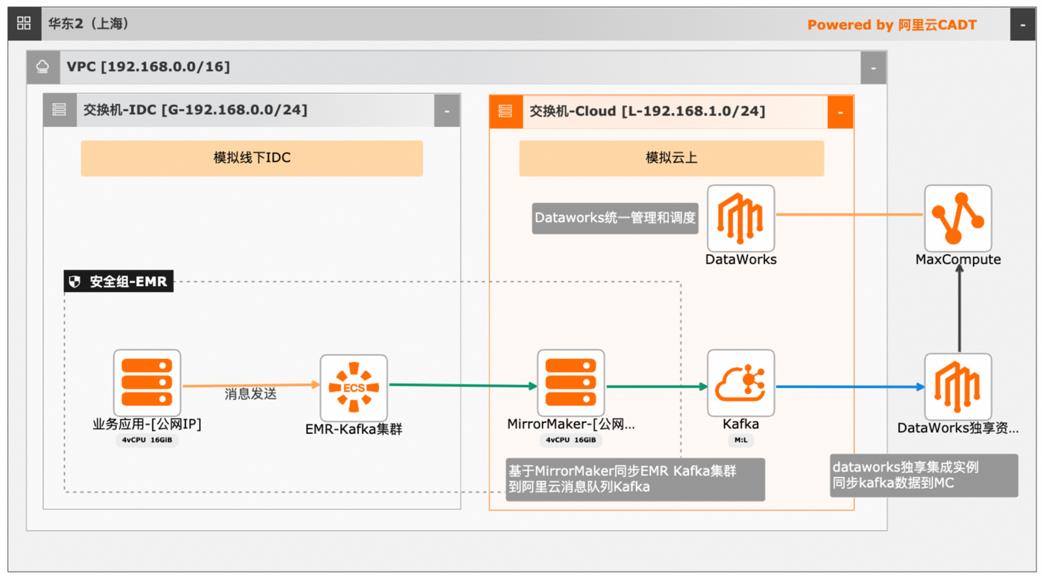
本文介绍离线大数据场景使MaxCompute构建云 上近实时数仓,打通云下数据上云链路,解决数据复杂类型支持和动态分区问题,满足高级数据处理需求的最佳实践。 l混合云环境下,现有业务系统零改造,打通数据上云链路。 l使用UDF实现复杂数据类型转换和数据动态分区。 l使用DataWorks配置周期调度业务流程,数据自动入仓。 l借助MaxCompute优化计算引擎,实现降本增效。 产品列表 云服务器ECS 专有网络VPC 访问控制RAM 数据总线DataHub E-MapReduceEMR DataWorks 大数据计算服务MaxCompute
MaxCompute 2.0版本升级后,Java UDF支持的数据类型从原来的 BIGINT、STRING、DOUBLE、BOOLEAN扩展了更多的新数据类型,同时还扩展支持了 ARRAY、MAP、STRUCT以及 Writable等复杂类型。文档版本:20240419 36 大数据近实时数据投递 MaxCompute 本例中,示例的复杂数据类型都已经得到支持。我们先将来自 Kafka的数据信息拉 ...
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。
附录B-T表示table_properties,用于配置默认的Table的FileFormat/RowFormat,为map 数据类型,包含如下配置项(可以在odpscmd中执行helpexternalproject查看帮助信 息):1.storage_handler用于指定存储时storedby所使用的handler,如 org.apache.hadoop.hive.hbase.HBaseStorageHandler,设置后忽略除 serde_properties外的...
分布式任务调度 SchedulerX
SchedulerX 是阿里巴巴自研的基于 Akka 架构的分布式任务调度平台(兼容开源 XXL-JOB/ElasticJob/K8s Job/Spring Schedule),支持 Cron 定时、一次性任务、任务编排、分布式数据处理,具有高可用、可视化、可运维、低延时等能力。
提供单机、广播、Map、MapReduce 和分片等多种分布式编程模型,简单几行代码即可通过您自己的机器自建分布式引擎,进行大数据跑批.全面的监控指标,丰富及时的报警方式,便于运维人员快速定位和解决线上问题.典型应用场景.最新变更公告>>.最新变更公告>>.SchedulerX 是阿里巴巴自研的分布式任务调度平台(兼容开源 XXL-JOB/...
来自:
云产品
CDH迁移升级CDP最佳实践
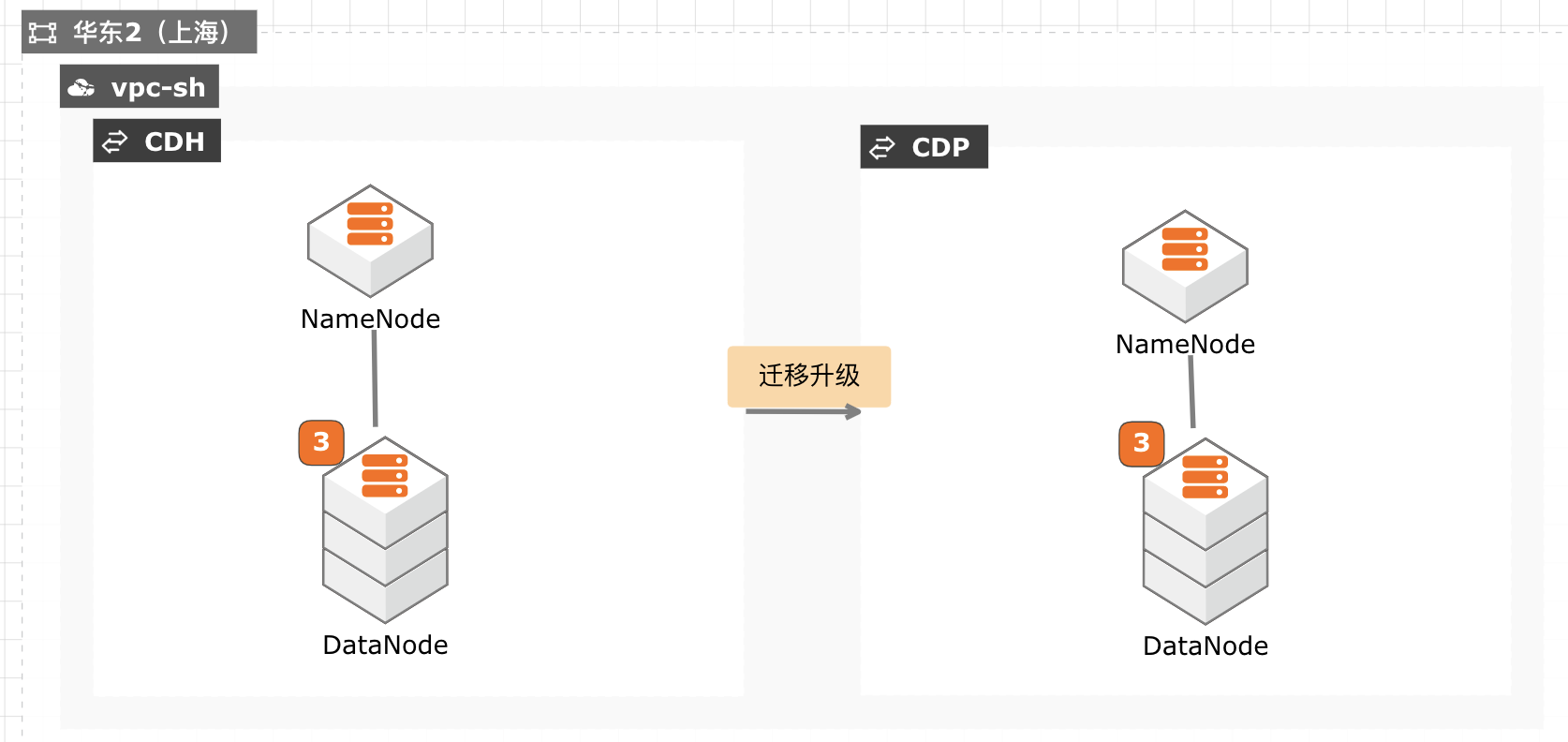
当前 CDH 免费版停止下载,终止服务,针对需要企业版服务能力并且CDH 升级过程对业务影响较小的客户,通过安装新的 CDP 集群,将现有数据拷贝至新集群,然后将新集群切换为生产集群,升级过程没有数据丢失风险,停机时间较短,适合大部分互联网客户升级使用。
chmod+x/usr/java/jdk1.8.0_301/bin/java ssh slave1 chmod+x/usr/java/jdk1.8.0_301/bin/java ssh slave2 chmod+x/usr/java/jdk1.8.0_301/bin/java ssh slave3 chmod+x/usr/java/jdk1.8.0_301/bin/java 进入主机菜单配置 JDK所在目录。配置所有主机的 JAVA主目录为/usr/java/jdk1.8.0_301。文档版本:20211029 28 CDH迁移...
- 产品推荐
- 这些文档可能帮助您