大数据近实时数据投递MaxCompute
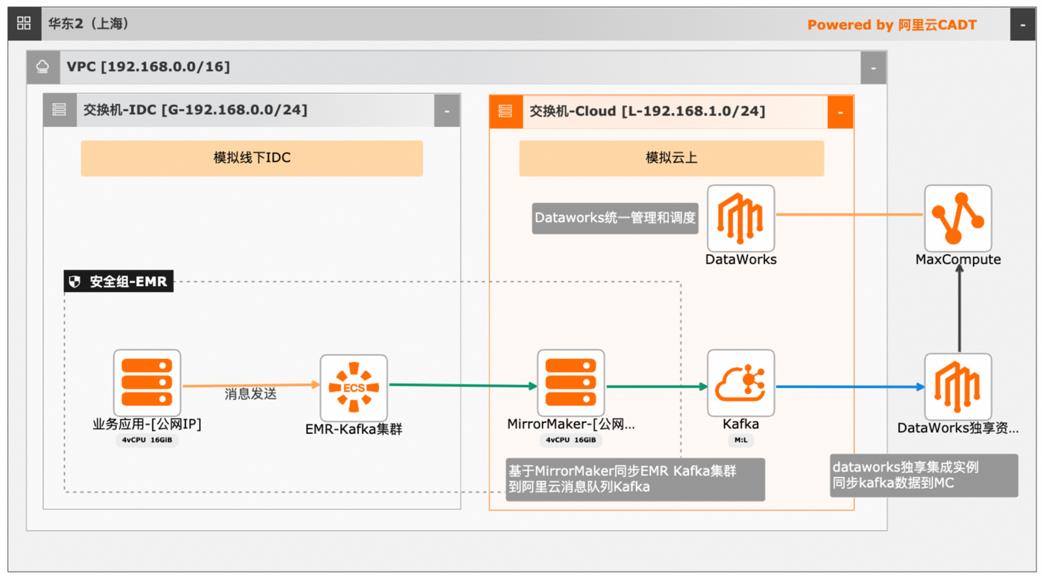
本文介绍离线大数据场景使MaxCompute构建云 上近实时数仓,打通云下数据上云链路,解决数据复杂类型支持和动态分区问题,满足高级数据处理需求的最佳实践。 l混合云环境下,现有业务系统零改造,打通数据上云链路。 l使用UDF实现复杂数据类型转换和数据动态分区。 l使用DataWorks配置周期调度业务流程,数据自动入仓。 l借助MaxCompute优化计算引擎,实现降本增效。 产品列表 云服务器ECS 专有网络VPC 访问控制RAM 数据总线DataHub E-MapReduceEMR DataWorks 大数据计算服务MaxCompute
在本实践中,使用 Java程序模拟输 出包含三种数据结构:map、list、struct的信息,并经过序列化后投递至 Kafka集 群。数据信息示例:为简化操作流程,本实践已经预打包好了数据信息发生及投递的程序包。下载数据信息发生及投递程序包。yum install-y git git clone ...
CDH迁移升级CDP最佳实践
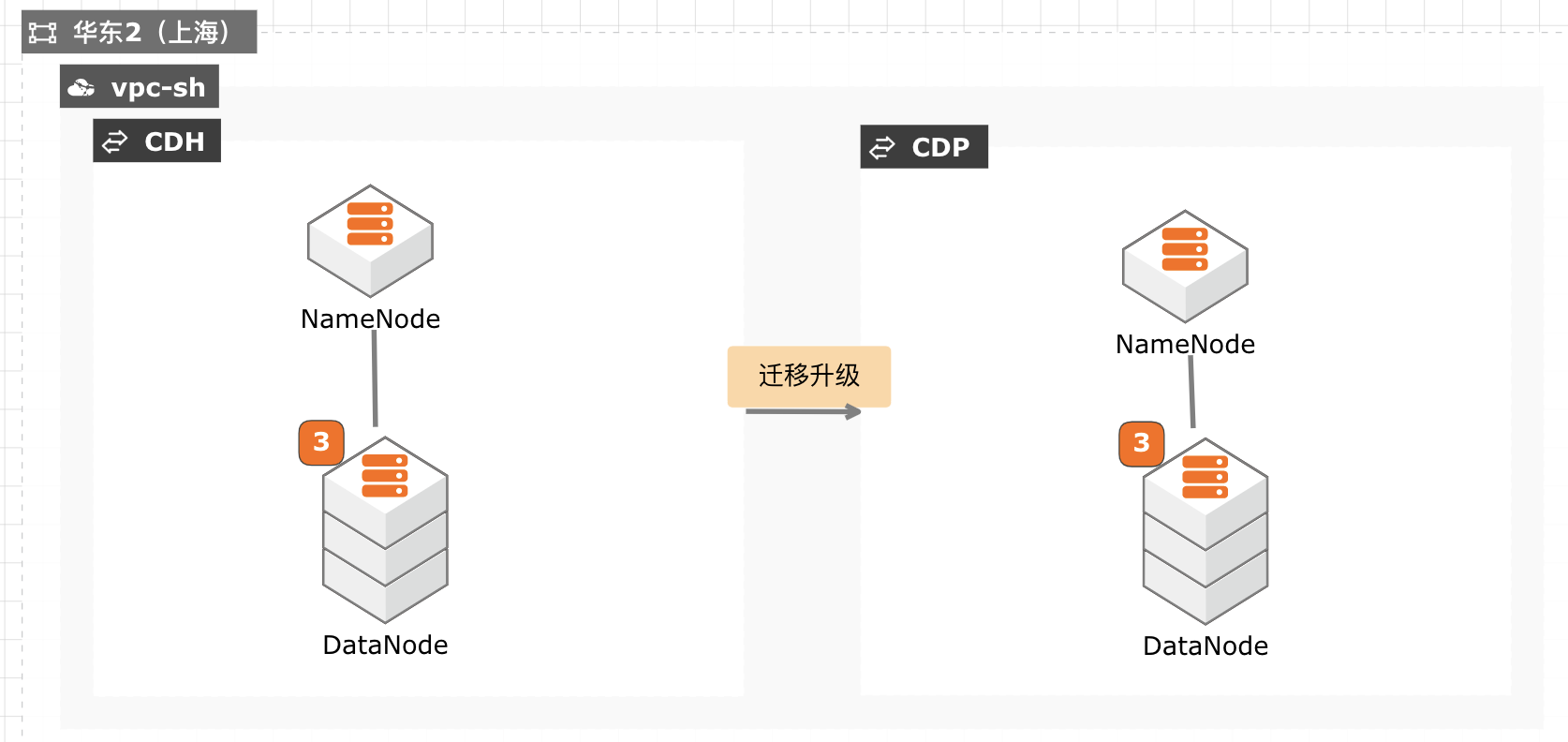
当前 CDH 免费版停止下载,终止服务,针对需要企业版服务能力并且CDH 升级过程对业务影响较小的客户,通过安装新的 CDP 集群,将现有数据拷贝至新集群,然后将新集群切换为生产集群,升级过程没有数据丢失风险,停机时间较短,适合大部分互联网客户升级使用。
ssh slave1 mkdir/usr/java/jdk1.8.0_301 scp-r cdh/jdk1.8.0_301/*root@slave1:/usr/java/jdk1.8.0_301 ssh slave2 mkdir/usr/java/jdk1.8.0_301 scp-r cdh/jdk1.8.0_301/*root@slave2:/usr/java/jdk1.8.0_301 ssh slave3 mkdir/usr/java/jdk1.8.0_301 scp-r cdh/jdk1.8.0_301/*root@slave3:/usr/java/jdk1.8.0_301 给与/...
自建Hadoop迁移到阿里云EMR
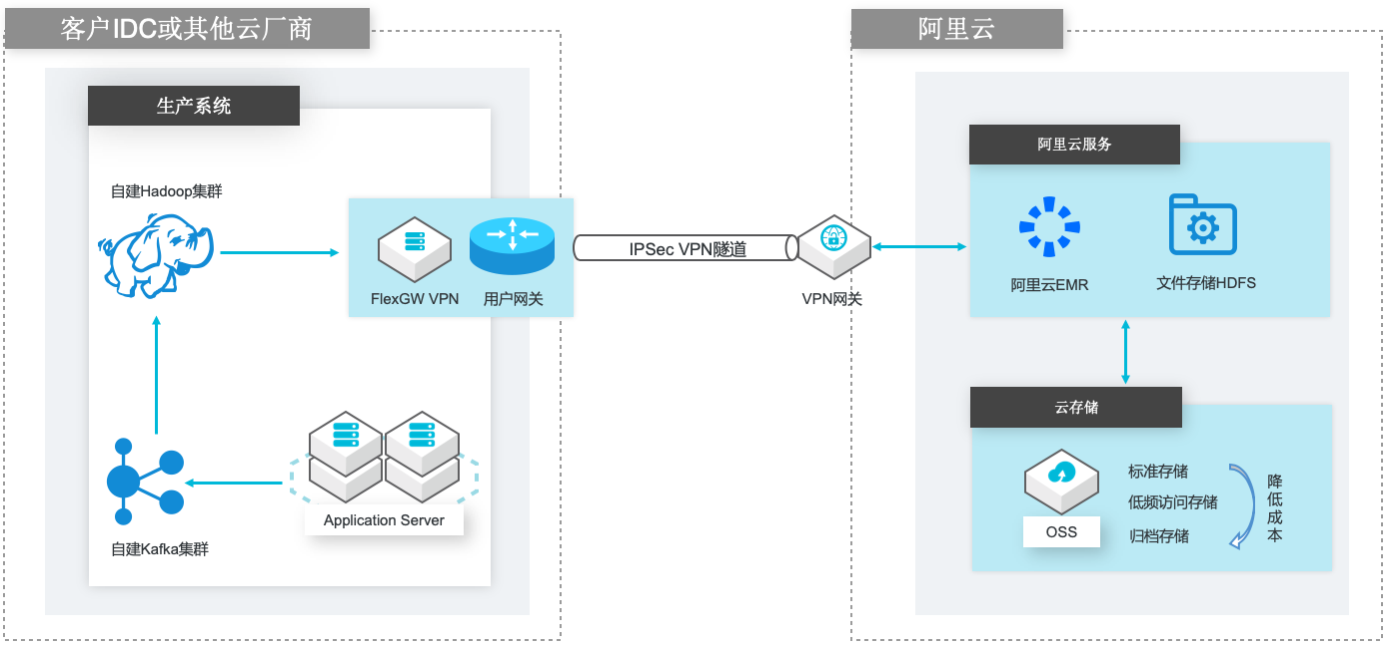
场景描述 场景1:自建Hadoop集群数据(HDFS)迁移到 阿里云EMR集群的HDFS文件系统; 场景2:自建Hadoop集群数据(HDFS)迁移到 计算存储分离架构的阿里云EMR集群,以OSS 和JindoFS作为EMR集群的后端存储。 解决的问题 客户自建Hadoop迁移到阿里云EMR集群的 技术方案; 基于IPSecVPN隧道构建安全和低成本数据 传输链路 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
yum install-y java java-1.8.0-openjdk-devel.x86_64 ssh slave1"yum install-y java java-1.8.0-openjdk-devel.x86_64"ssh slave2"yum install-y java java-1.8.0-openjdk-devel.x86_64"ssh slave3"yum install-y java java-1.8.0-openjdk-devel.x86_64"步骤5 下载并解压缩 Hadoop 2.10.1文件包。1.下载软件包,下面两...
- 产品推荐
- 这些文档可能帮助您