自建Hive数仓迁移到阿里云EMR
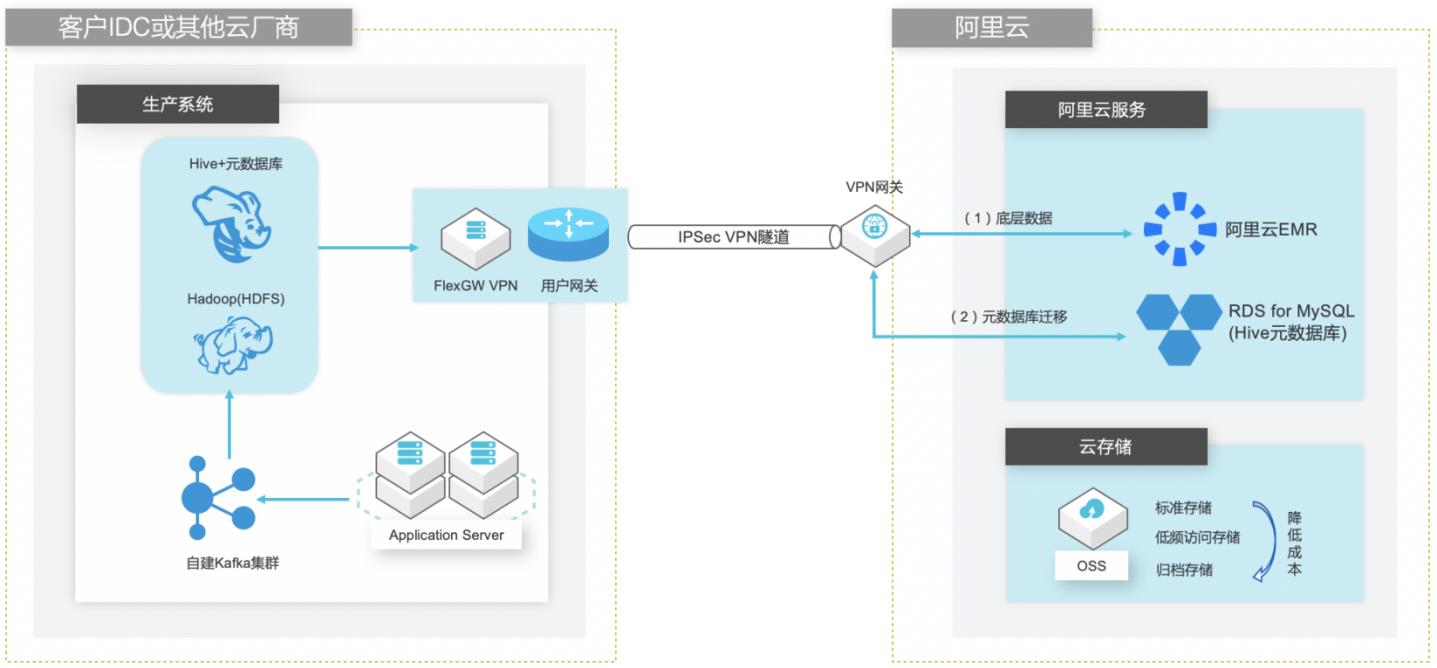
场景描述 客户在IDC或者公有云环境自建Hadoop集群构 建数据仓库和分析系统,购买阿里云EMR集群之 后,涉及到将数据仓库和Hive元数据的数据库迁 移上云。目前主流Hive数据仓库迁移场景为1.x 版本迁移到阿里云EMR(Hive2.x版本),涉及到 数据订正更新步骤。 解决的问题 Hive数据仓库的数据迁移方案 Hive元数据库的迁移方案 Hive跨版本迁移后的数据订正 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
敬海、游士 审阅人 子关、期会、游圣 文档变更记录 版本编号 日期 作者 审核人 说明 V1.0 2019-12-20 云魁 子关、期会、游圣 创建 V1.1 2019-12-25 筱晖 云魁 文档优化 V1.2 2020-01-09 云魁、子关 子关 增加附录 使用 CADT创 V1.3 2021-07-21 游士 建资源,更新部 分命令 文档版本:20210721 I 自建Hive数据仓库跨版本迁移...
基于Flink的资讯场景实时数仓
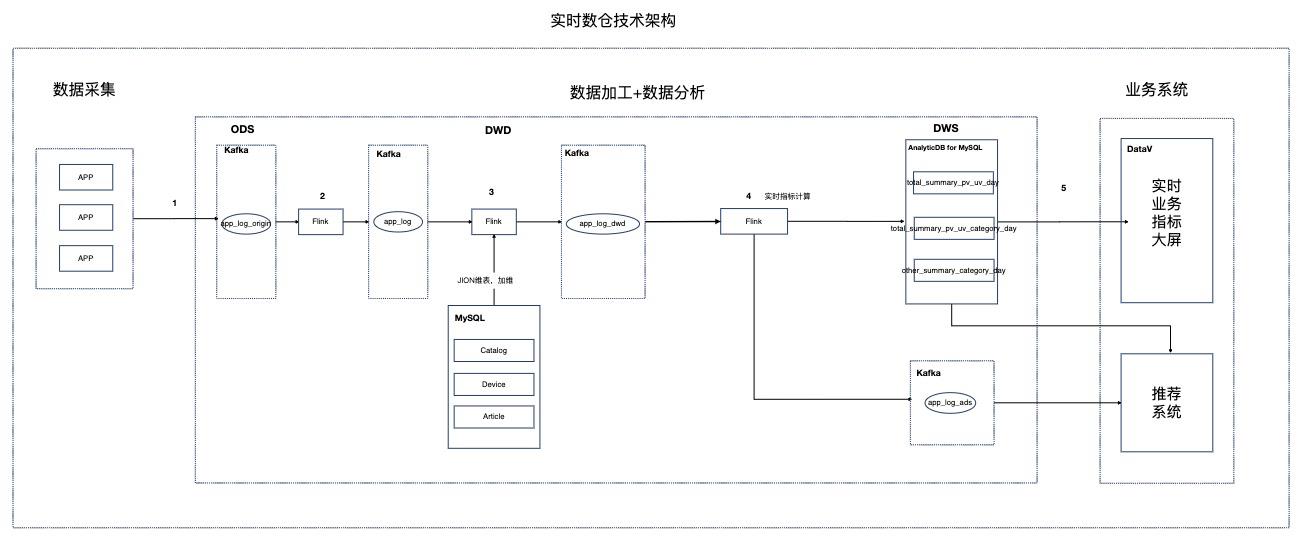
场景描述 本实践针对资讯聚合类业务场景,Step by Step介绍 如何搭建实时数仓。 解决问题 1.如何搭建实时数仓。 2.通过实时计算Flink实现实时ETL和数据流。 3.通过实时计算Flink实现实时数据分析。 4.通过实时计算Flink实现事件触发。 产品列表 实时计算 专有网络VPC 云数据库RDSMySQL版 分析型数据库MySQL版 消息队列Kafka 对象存储OSS NAT网关 DataV数据可视化
IP2Region.java 通过 NAT 网 关 配 置 SNAT 访 问 公 网 服 务 http://whois.pconline.com.cn/ipJson.jsp?json=true&ip={ip}获取地理位置信息。本方式 仅演示外网访问和自定义函数 UDX,不适合生产环境使用。public class IP2Region extends TableFunction>{ private String urlPrefix=...
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。
基于湖仓一体架构使用MaxCompute对OSS湖数据...1)project_name:为MC的项目名称,本示例为2.1步骤2创建的“dlf_mc001”access_id&access_key:创建2.1创建的RAM用户对应的AK信息 2)end_point:本例是华东2上海外网Endpoint:http://service.cn-shanghai.maxcompute.aliyun.com/api MaxCompute在各地域部署的访问端点:请参考...
- 产品推荐
- 这些文档可能帮助您