基于弹性供应组构建大数据分析集群
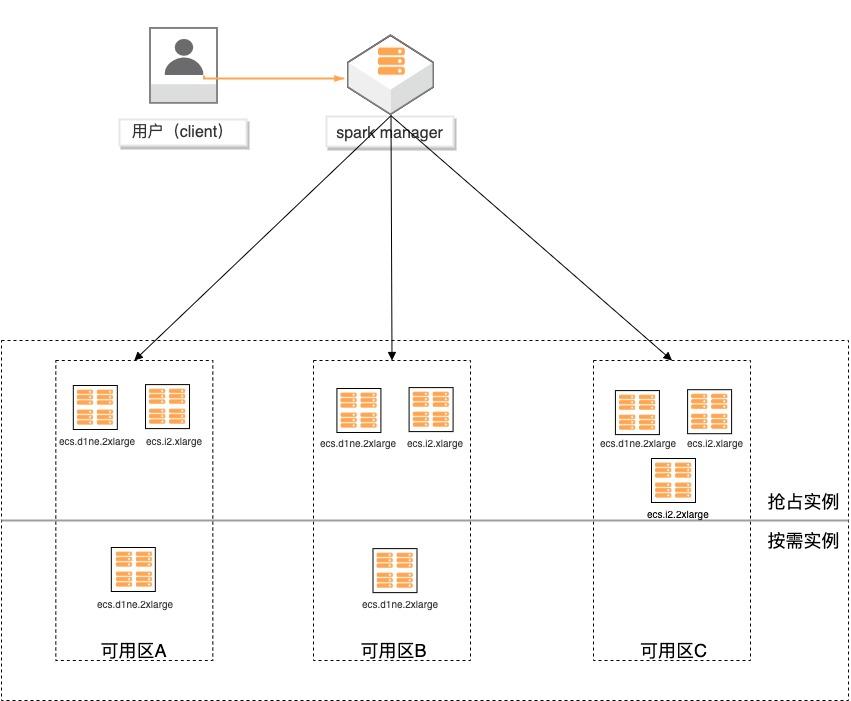
场景描述 基于弹性供应组(APG)搭建spark计算集 群,提供一键开启跨售卖方式、跨可用区、 跨实例规格的计算集群交付模式的实践。 方案优势 1.超低成本:跨售卖方式提供计算实 例,按秒计费,可全部使用spot实例 交付,最高可省90%成本。 2.稳定可靠:跨可用域、跨实例规格, 降低spot被集体释放的风险;自动托 管,分钟级巡检,动态保证集群的算 力。 3.快速交付:单次可在5分钟内交付 2000个实例。 4.多策略组合:可分别指定spot和按量 实例的交付策略,以及差额补足的策 略,包括成本最低、打散和折中。 解决问题 1.大规模计算集群成本高。 2.创建ECS实例方式单一,无法跨计费 方式、可用区及规格等核心参数。 3.当可用区资源紧张,无法自动保证基于 spot类型的稳定算力。 产品列表 专有网络VPC 云服务器ECS
文档版本:20200619 3 基于弹性供应组构建大数据集群分析 方案背景 方案背景 场景需求 随着大数据的兴起,越来越多的客户会尝试通过云服务器搭建自己的大数据分析平台,如 Hadoop、Spark等。但是用户通过种单例或批量创建 ECS,方式均缺乏灵活性,无法跨越计费方式、可用区及规格族等核心参数的限制,同时无法避免资源不足...
影视数据分发汇集与传输加速
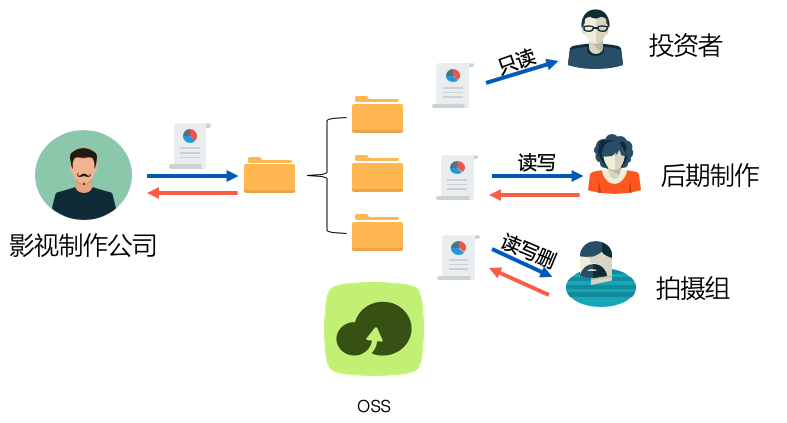
场景描述 使用阿里云对象存储服务OSS及OSSBrowser 工具,实现影视数据多用户多地域分发、汇集, 以及传输加速的最佳实践。 解决问题 1.跨地域、多角色、分权限文件上传、下载。 2.基于OSS及其客户端实现Serverless文件 分发服务(可替换传统FTP服务)。 3.OSS文件传输全球加速。 产品列表 lOSS lRAM
影视数据分发汇集与传输加速 场景描述 业务架构 使用阿里云对象存储服务 OSS及 OSSBrowser 工具,实现影视数据多用户多地域分发、汇集,以及传输加速的最佳实践。解决问题 1.跨地域、多角色、分权限文件上传、下载。2.基于 OSS及其客户端实现 Serverless文件 分发服务(可替换传统 FTP服务)。3.OSS文件传输全球加速。产品...
物联网平台
物联网平台提供全托管的企业级实例服务,具有低成本、高可靠、高性能、高安全的优势,无需自建物联网基础设施即可接入各种主流协议设备,管理运维亿级规模设备,存储备份和处理分析EB量级的设备数据,帮助企业快速实现设备数据和应用数据的融合,实现设备智能化升级。
阿里云物联网平台上线了国内3大地域和海外5大地域,支撑光伏企业提升海外业务的稳定性、安全性并应对各国和地区对于数据的严格监管.全球8大服务区域支撑设备出海.阿里云物联网平台的SLA可达99.95%以上,支撑客户业务系统对光伏逆变器的配置进行实时大批量更新,通过灵活调度以达到最优发电效率,正常网络环境下消息延时低于...
来自:
云产品
云原生数据仓库AnalyticDB MySQL数据仓库
阿里云云原生数据仓库AnalyticDB MySQL版(简称AnalyticDB)是融合数据库、大数据技术于一体的云原生企业级数据仓库平台。云原生数据仓库AnalyticDB MySQL版支持数据实时写入和同步更新、实时计算和实时服务,可用于构建企业级报表系统、数据仓库和数据服务引擎。
边锋&AnalyticDB MySQL:打造一站式大数据分析平台.AnalyticDB MySQL带你学:基于Flink的高吞吐&精确一致性数据入湖.兰姆达 x AnayticDB 降本30%的数据湖最佳实践.一键实现穿衣自由|揭秘淘宝AI试衣间硬核技术:AnalyticDB向量在线召回.支持按小时设置计算资源弹性扩容规则,解决计算资源峰谷需求问题,降低计算资源成本....
来自:
云产品
云原生数据湖分析DLA
阿里云云原生数据湖分析是新一代大数据解决方案,采取计算与存储完全分离的架构,支持对象存储(OSS)、RDS(MySQL等)、NoSQL(MongoDB等)数据源的消息实时归档建仓,提供Presto和Spark引擎,满足在线交互式查询、流处理、批处理、机器学习等诉求。内置大量优化+弹性,比开源自建集群最高降低50%+的成本,最快可1分钟级拉起300个计算节点,快速满足业务资源要求。
兼容MySQL协议,无需ETL,可使用SQL直接分析OSS等数十种源数据,快速低成本开启大数据分析.云数据库RDS MySQL版.对象存储OSS.推荐搭配产品.Lakehouse实时入湖.异构数据实时分析,为数据驱动提速.直接使用生产库对海量数据分析,不仅会对线上业务产生影响,还可能出现超时,查询失败的现象;但自建数据仓库又需投入大量的软...
来自:
云产品
跨链数据连接服务解决方案
利用蚂蚁区块链领先技术实现的跨链数据连接服务 Open Data Access Trusted Service(ODATS)。通过制定标准化的区块链UDAG全栈跨链协议,保证跨链交易的安全性、可扩展性及可靠性,打破区块链数据孤岛,实现同构及异构链之间的可信互通,助力企业之间可信协作,促进产业生态可信融合。
大规模商用的溯源营销服务平台,利用区块链和物联网技术,解决了溯源信息的真实性问题.区块链溯源服务.高效、司法可信、轻量便捷的电子合同存证解决方案,保证合同真实不可篡改、具备司法效力、提高维权效率.为作品内容生产机构或内容运营企业提供集原创登记、版权监测、电子数据采集与公证、司法维权诉讼为一体的一站式...
来自:
解决方案
数据管理DMS
数据管理DMS是基于阿里巴巴集团十余年的数据库服务平台的云版本,提供免安装、免运维、即开即用、多种数据库类型与多种环境统一的web数据库管理终端;可以为企业用户快速复制搭建与阿里集团同等安全、高效、规范的数据库DevOps研发流程解决方案。
更多产品与服务.SQL Server是发行最早的商用数据库产品之一,支持复杂的SQL查询,性能优秀,对基于Windows平台.NET架构的应用程序具有完美的支持.云数据库RDS SQL Server 版.高可靠双机热备架构及可无缝扩展的集群架构,满足高读写性能场景及容量需弹性变配的业务需求.云数据库 Redis 版.云数据库MongoDB版支持ReplicaSet和...
来自:
云产品
数据集成 Data Integration
阿里云数据集成 Data Integration是跨异构数据、低成本、弹性扩展的数据采集同步平台,为DataX的商业版,支持ETL,支持50+数据源跨网络离线(全量/增量)同步。
数据集成支持在数据抽取过程中进行简单的ETL数据转换操作(如日期解析、数据过滤等),导入到大数据处理中心,利用大数据引擎强大的计算能力可以再进行更复杂的数据转换操作.支持阿里云经典网络、专有网络(VPC)环境下的数据同步以及本地IDC网络环境下的数据集成.数据集成(Data Integration)比DataX更加高效、安全,且...
来自:
云产品
数据传输服务DTS
阿里云数据传输服务集数据迁移、订阅及实时同步功能于一体,能够解决公共云、混合云场景下,远距离、毫秒级异步数据传输难题,支持关系型数据库、NoSQL、大数据(OLAP)等数据源,其底层基础设施采用阿里双11异地多活架构,为数千下游应用提供实时数据流,已在线上稳定运行7年之久。
提供数据迁移、数据同步、数据订阅链路的数十个实时性能指标和监控视图,直观监控各条链路的健康状况,辅助用户进行故障诊断.查看同步链路状态和性能>.闭环的报警监控管理.可灵活配置任务延迟、任务状态等监控指标,对链路实时监控报警,并在故障消除后通知用户,实现监控、报警的闭环管理.大幅度降低运维成本.丰富的性能...
来自:
云产品
数据安全中心
敏感数据保护(Sensitive Data Discovery and Protection),在满足等保v2.0“安全审计”、等保v3.0及“个人信息保护”的合规要求的基础上,为客户提供敏感数据识别、分级分类、数据安全审计、数据脱敏、智能异常检测等数据安全能力,形成一体化的数据安全解决方案。
数据安全中心 Data Security Center 为客户提供敏感数据自动识别、分级分类、大数据安全审计与数据脱敏等数据安全能力,形成一体化的云上全域数据防泄漏与安全解决方案,在帮助客户实现等保 2.0 二级有关“安全审计”与三级有关“个人信息保护”的合规要求的同时,并满足《数据安全法》中提出的有关要求.数据安全中心(敏感...
来自:
云产品
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
需要有灵活可扩展的计算平台、弹性可伸缩集群资源及灵活管控的用户 名词解释 Databricks数据洞察:是基于 Apache Spark的全托管大数据分析平台,产品内核 引擎使用 Databricks Runtime,并针对阿里云平台进行优化,使用 Notebook交互 式数据分析,Python库便捷安装,使用 Delta表存储比其他使用 Spark查询性能 有 5-10倍的...
- 产品推荐
- 这些文档可能帮助您