数据安全解决方案
数据是企业的核心资产,如何保护企业的云上数据,是每个企业管理者都应当重视的课题。在云平台提供更为安全便捷的数据保护能力的同时,阿里云根据自身多年的经验积累,结合大量云上客户的最佳实践,提供了一套完整的数据安全解决方案,帮助企业提升云上数据风险防御能力,实现企业核心及敏感数据安全可控。
数据安全生命周期过程域.DSMM模型中将数据安全过程维度分为数据全生命周期安全和数据通用安全两个过程,并将数据全生命周期划分为:数据采集安全、数据传输安全、数据存储安全、数据处理安全、数据交换安全、数据销毁安全六个阶段。数据生命周期安全共包含30个过程域,为企业保护数据提供了可落地的参考.安全能力“云、管、...
来自:
解决方案
数据同步服务
数据同步 MSS,源于阿里云移动开发平台。移动数据同步 MSS,通过一个安全的数据通道 TCP+SSL,及时、准确、有序地将服务器端的业务数据,主动的同步(SYNC)到客户端 App。提供增量、可靠的消息触达能力,将聊天消息按发送方的发送顺序,有序推送至指定用户。可以动态地将配置信息进行全设备推送,保证在线 APP 可实时接收推送数据。
移动数据同步 MSS,通过一个安全的数据通道 TCP+SSL,及时、准确、有序地将服务器端的业务数据,主动的同步(SYNC)到客户端 App.全线降价,mPaaS 助力打造超级 App!点击查看.mPaaS 全线降价!点击查看.查看产品文档,快速上手.频道页banner.产品详情页二级页面锚点导航.唐家哲,靖鑫,也树.mPaaS 小程序.智能投放 MCDP.解决...
来自:
云产品
数据安全中心
敏感数据保护(Sensitive Data Discovery and Protection),在满足等保v2.0“安全审计”、等保v3.0及“个人信息保护”的合规要求的基础上,为客户提供敏感数据识别、分级分类、数据安全审计、数据脱敏、智能异常检测等数据安全能力,形成一体化的数据安全解决方案。
数据安全中心 Data Security Center 为客户提供敏感数据自动识别、分级分类、大数据安全审计与数据脱敏等数据安全能力,形成一体化的云上全域数据防泄漏与安全解决方案,在帮助客户实现等保 2.0 二级有关“安全审计”与三级有关“个人信息保护”的合规要求的同时,并满足《数据安全法》中提出的有关要求.数据检测与响应DDR...
来自:
云产品
大数据近实时数据投递MaxCompute
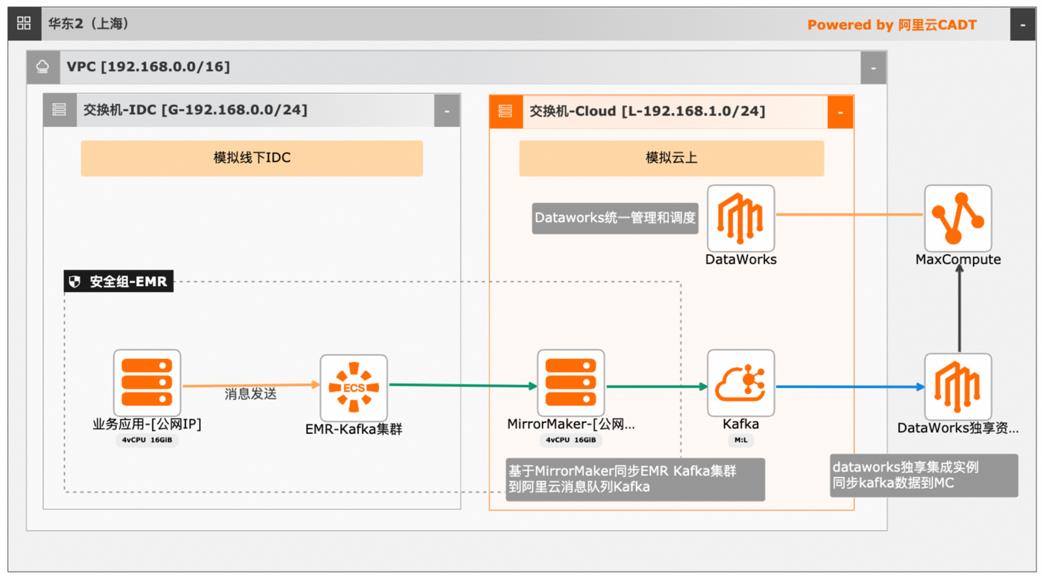
本文介绍离线大数据场景使MaxCompute构建云 上近实时数仓,打通云下数据上云链路,解决数据复杂类型支持和动态分区问题,满足高级数据处理需求的最佳实践。 l混合云环境下,现有业务系统零改造,打通数据上云链路。 l使用UDF实现复杂数据类型转换和数据动态分区。 l使用DataWorks配置周期调度业务流程,数据自动入仓。 l借助MaxCompute优化计算引擎,实现降本增效。 产品列表 云服务器ECS 专有网络VPC 访问控制RAM 数据总线DataHub E-MapReduceEMR DataWorks 大数据计算服务MaxCompute
大数据近实时数据投递 MaxCompute 最佳实践 业务架构 最佳实践 解决问题 场景描述 混合云环境下,现有业务系统零改造,打通数据 本文介绍离线大数据场景使用 MaxCompute构建云 上云链路。上近实时数仓,打通云下数据上云链路,解决数据复 使用 UDF实现复杂数据类型转换和数据动态分 杂类型支持和动态分区问题,满足高级数据...
数据总线Datahub
数据总线(DataHub)服务是阿里云提供的流式数据(Streaming Data)服务,它提供流式数据的发布(Publish)和订阅(Subscribe)的功能,拥有高吞吐量、高稳定性、低成本等特点,与阿里云大数据生态系统完美打通,让您可以轻松构建基于流式数据的分析和应用。
数据总线(DataHub)服务是阿里云提供的流式数据(Streaming Data)服务,它提供流式数据的发布(Publish)和订阅(Subscribe)的功能,让您可以轻松构建基于流式数据的分析和应用.孙慧颖,靖鑫,也树.MySQL低至1折起,前往限时优惠活动!1元体验简单易用的MySQL数据仓库,毫秒级海量数据多维分析!MySQL数据库+Quick BI数据可视化...
来自:
云产品
音视频终端 SDK
音视频终端 SDK集成了阿里云视频直播和视频点播业务中拍摄、编辑、上传、推流和播放的核心能力,同时融合视频特效、音频特效等音视频AI能力,为用户提供一体化SDK,支持多终端接入,搭配产品级Demo,支持用户根据业务需求快速集成所需
音视频终端 SDK 音视频终端 SDK(MediaBox SDKs)集成了直播推流、视频播放、短视频创作、美颜特效、音频特效等核心能力,为用户提供一体化 SDK,支持移动端、PC 端、Web 端等多终端接入,搭配开源 UI 组件和产品级 Demo,支持用户根据业务需求集成所需 SDK 以及采用低代码方式快速搭建所需应用。音视频终端智能方案,多种...
来自:
云产品
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 业务架构 场景描述 客户在 IDC或者公有云环境自建 Hadoop集群 构建数据仓库和分析系统,购买阿里云 Databricks数据洞察集群之后,涉及到数仓数 据和元数据的迁移以及 Hive版本的订正更新。方案优势 1.全托管 Spark集群免运维,节省人力成 本。2.Databricks数据洞察...
异地双活场景下的数据双向同步
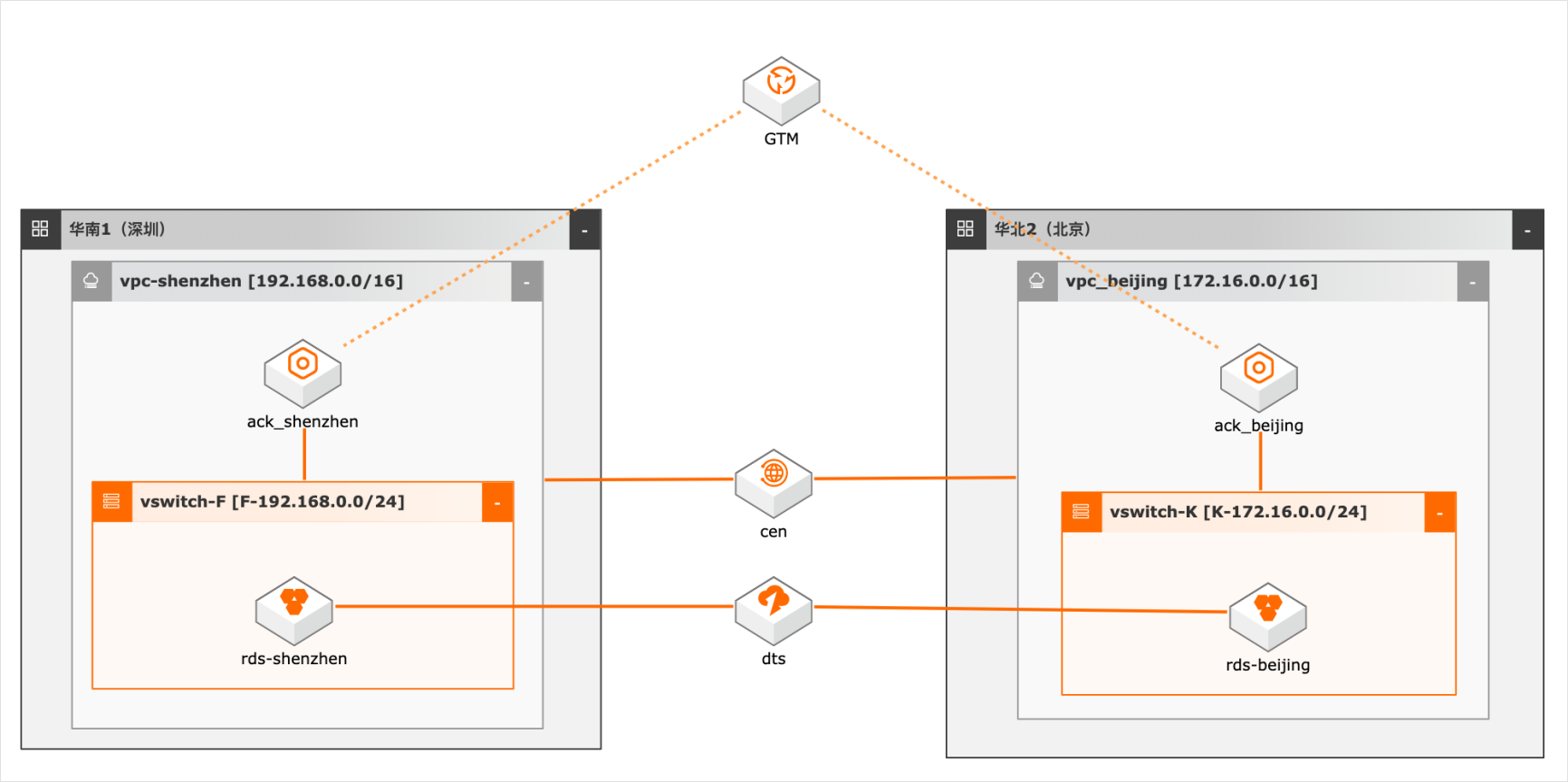
概述 随着客户业务规模的扩大,对系统高可用性要求越来越高,越来越多用户采用异地双活/多活架构,多活架构往往涉及业务侧做单元化改造,本方案仅模拟用户已做单元化改造后的数据双向同步,数据库采用双主架构,本地写本地读,同时又保证双库的数据一致性,为业务增加可用性和灵活性。 适用场景 数据库双向同步 数据库全局ID不冲突 双活架构的数据库建设问题 技术架构 本实践方案基于如下图所示的技术架构和主要流程编写操作步骤: 方案优势 DTS双向同步,采用独立模块避免数据同步占用系统资源。 奇偶ID涉及,避免数据冲突。 DTS多种处理冲突的方式供业务选择。 安全:原生的多租户系统,以项目进行隔离,所有计算任务在安全沙箱中运行。
随着客户业务规模的扩大,对系统高可用性要求越 数据库双向同步 来越高,越来越多用户采用异地双活/多活架构,多 数据库全局 ID不冲突 活架构往往涉及业务侧做单元化改造,本方案仅模 双活架构的数据库建设问题 拟用户已做单元化改造后的数据双向同步,数据库 采用双主架构,本地写本地读,同时又保证双库的数 据一致性,为...
利用低成本链路完成业务数据迁移上云
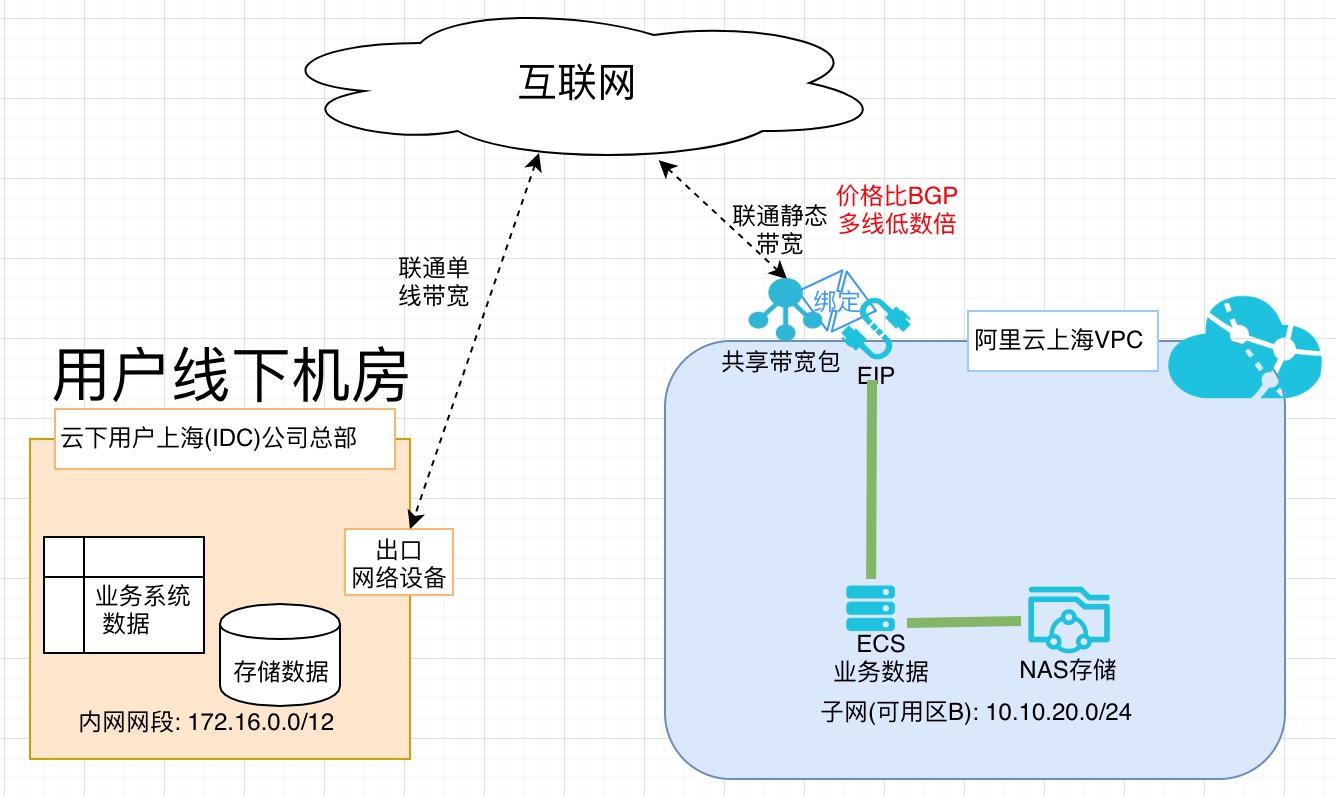
场景描述 随着云计算被越来越多的客户所接受,除业务系 统上云外,很多客户已经把业务数据搬迁上云。 业务数据量一般都比较大,迁移上云需要大量的 网络带宽,BGP费用比较高。阿里云对用户开 放所需地域购买静态单线共享带宽包的权限(移 动/联通/电信均可),可用为迁移数据有效降低 成本。 解决问题 1.业务数据上云网络成本高 产品列表 专有网络VPC 云服务器ECS 网络存储NAS 共享带宽包
利用低成本链路完成业务数据上云 最佳实践 部署架构图 场景描述 随着云计算被越来越多的客户所接受,除业务系 统上云外,很多客户已经把业务数据搬迁上云。业务数据量一般都比较大,迁移上云需要大量的 网络带宽,BGP费用比较高。阿里云对用户开 放所需地域购买静态单线共享带宽包的权限(移 动/联通/电信均可),可用为...
湖仓一体架构EMR元数据迁移DLF
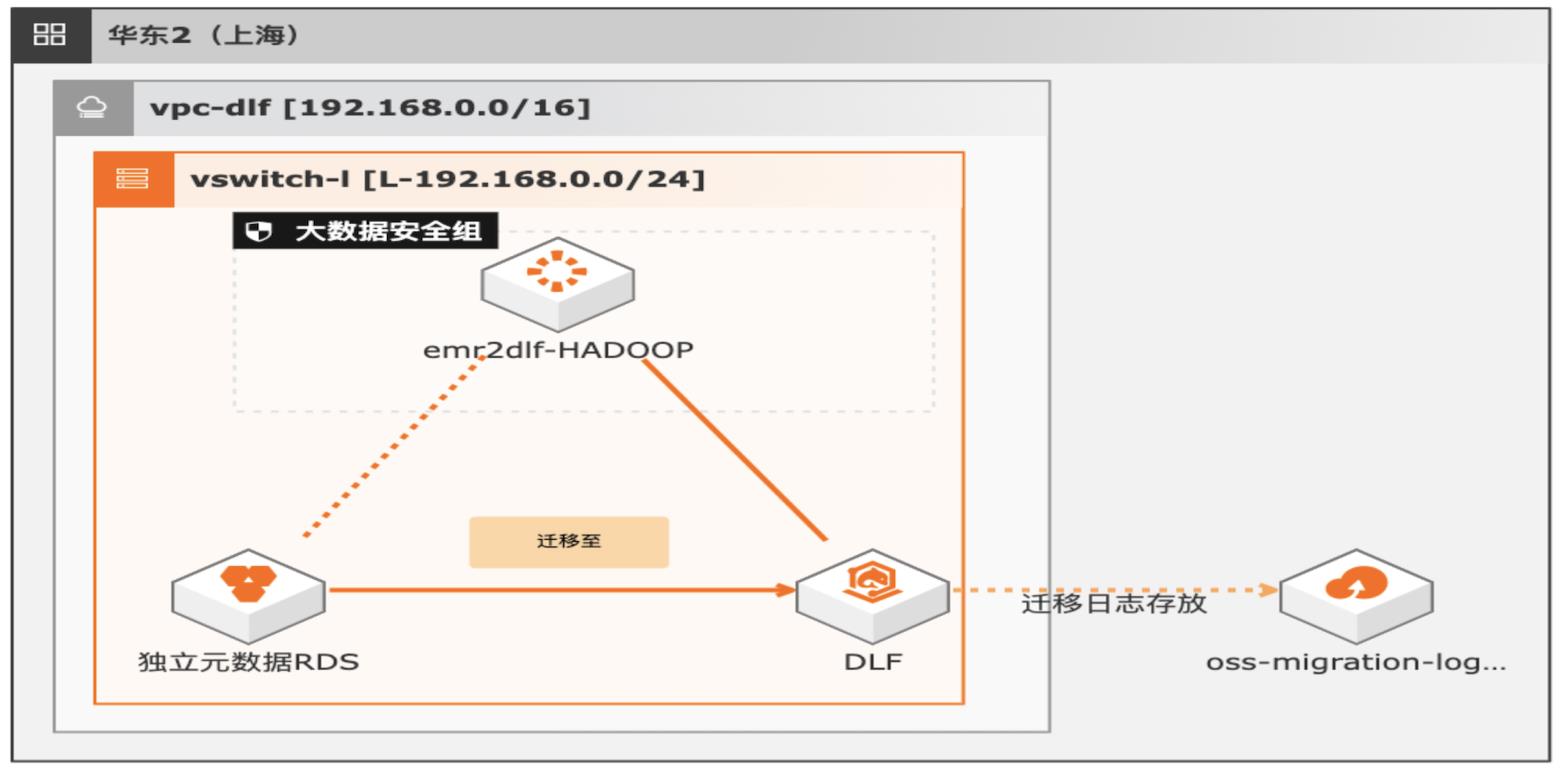
通过EMR+DLF数据湖方案,可以为企业提供数据湖内的统一的元数据管理,统一的权限管理,支持多源数据入湖以及一站式数据探索的能力。本方案支持已有EMR集群元数据库使用RDS或内置MySQL数据库迁移DLF,通过统一的元数据管理,多种数据源入湖,搭建高效的数据湖解决方案。
湖仓一体架构 EMR元数据迁移 DLF最佳实践 业务架构 场景描述 解决的问题 通过 EMR+DLF数据湖方案,可以为企业提供数据 EMR元数据迁移至 DLF 湖内的统一的元数据管理,统一的权限管理,支持多 元数据迁移验证 源数据入湖以及一站式数据探索的能力。本方案支 数据一致性校验 持已有 EMR集群元数据库使用 RDS或内置 MySQL ...
DTS数据同步集成MaxCompute数仓
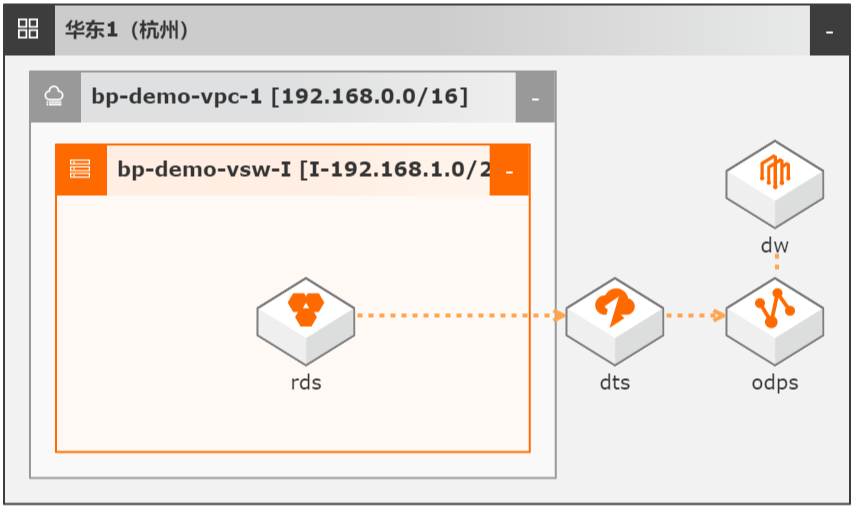
场景描述 本文Step by Step介绍了通过数据传输服务 DTS实现从云数据库RDS到MaxCompute的 数据同步集成,并介绍如何使用DTS和 MaxCompute数仓联合实现数据ETL幂等和数 据生命周期快速回溯。 解决问题 1.实现大数据实时同步集成。 2.实现数据ETL幂等。 3.实现数据生命周期快速回溯。 产品列表 MaxCompute 数据传输服务DTS DataWorks 云数据库RDS MySQL 版
DTS数据同步集成 MaxCompute数仓 最佳实践 业务架构 场景描述 本文 Step by Step 介绍了通过数据传输服务 DTS实现从云数据库 RDS到 MaxCompute的 数据同步集成,并介绍如何使用 DTS 和 MaxCompute数仓联合实现数据 ETL幂等和数 据生命周期快速回溯。解决问题 1.实现大数据实时同步集成。2.实现数据 ETL幂等。3.实现数据生命...
Databricks数据洞察
阿里云Databricks数据洞察是基于Apache Spark的全托管数据分析平台, 内核采用更高效、稳定的商业版Databricks Runtime和Delta Lake。可满足数据分析师、数据工程师和数据科学家在大数据场景下对数据湖分析、实时数仓、离线数仓、BI数据分析、AI机器学习等需求
Databricks 数据洞察.Databricks数据洞察是基于Apache Spark的全托管数据分析平台,内核采用更高效稳定的商业版Databricks Runtime和Delta Lake,满足用户对数据湖分析、实时数仓、离线数仓、BI数据分析、AI机器学习等场景需求。因产品服务策略调整,本产品将于2023年10月23日停止全面支持,并将于2024年4月23日停止服务....
来自:
云产品
本地数据中心基于SMB/NFS协议访问对象存储最佳实践
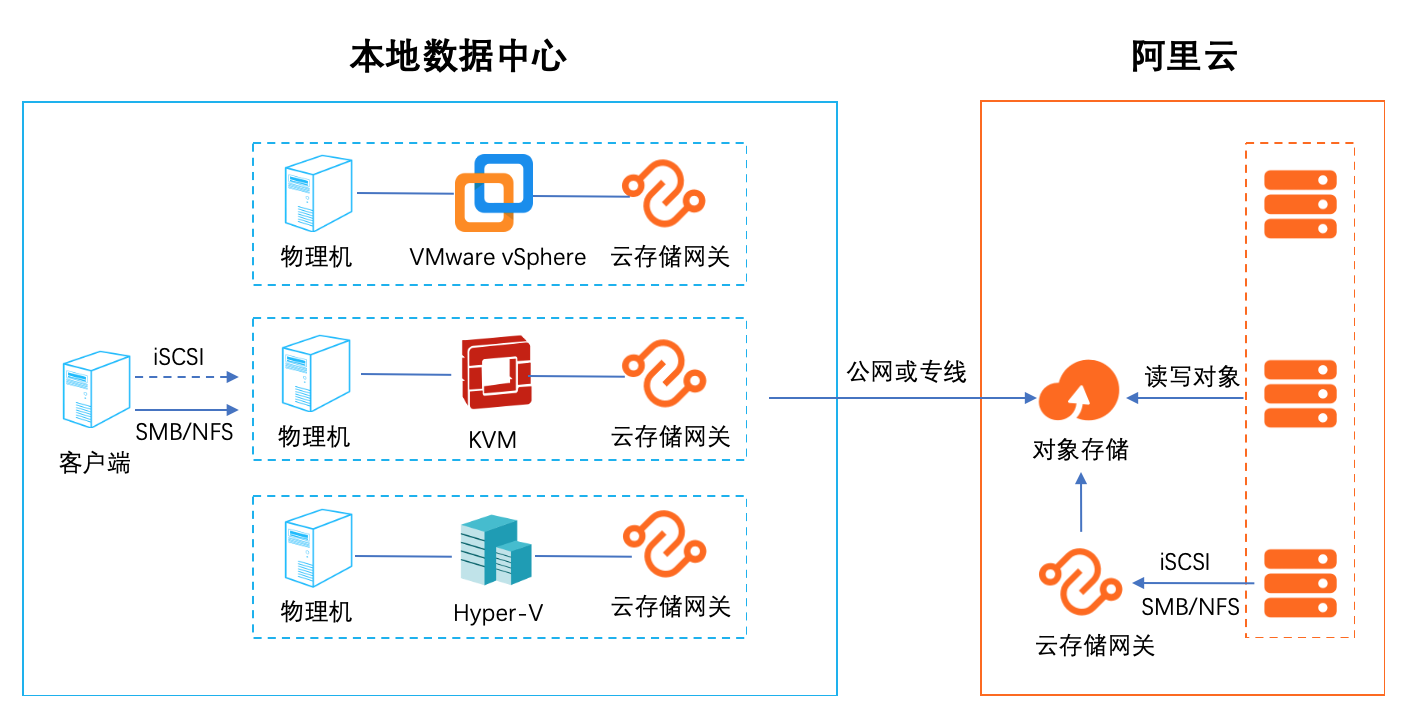
1. 云存储扩容和迁移 集成智能缓存算法,自动识别冷热数据,将热数据保留在本地缓存,保证数据访问体验,无感知的将海量云存储数据接入本地数据中心,拓展存储空间。同时在云端 保留全量数据(冷+热)保证数据的一致性 2.云容灾 随着云计算的普及,越来越多的用户把自己的业务放到了云上。但是随着业务的发展,如何提高业务的可靠性和连续性,跨云容灾是一个比较热门的话题。借助云存 储网关对虚拟化的全面支持,可以轻松应对各种第三方云厂商对接阿里云的数据容灾。 3. 多地数据共享和分发 通过多个异地部署的文件网关实例,对接同一个阿里云OSS Bucket,可以实现快速的异地文件共享和分发,非常适合多个分支机构之间互相同步和共享数据。 4. 适配传统应用 有很多用户在云上的业务是新老业务的结合,老业务是从数据中心迁移过来的使用的是标准的存储协议,例如: NFS/SMB/iSCSI。新的应用往往采用比较新的技 术,支持对象访问的协议。如何沟通两种业务之间的数据是一个比较麻烦的事情,云存储网关正好起到一个桥梁的作用,可以便捷的沟通新旧业务,进行数据交换。 5. 替代 ossfs 和 ossftp ossfs 和 ossftp 都是基于文件协议的开源工具,用户可以通过它们直接上传文件到OSS。但是这两个开源文件都不建议在生产环境使用(POSIX 兼容度低),同时挂 载在用户的客户端需要额外的配置和缓存资源,对于多个客户端的情况安装配置繁琐。通过文件网关的服务可以完美替代 ossfs 和 ossftp。通过创建文件网关,用 户只需要执行简单的挂载(NFS)和映射(Windows SMB)就可以像使用本地文件系统一样使用 OSS。
本地数据中心基于 SMB/NFS协议访问对象存储 最佳实践 业务架构 场景描述 本地数据中心在本地存储有限的情况下可以基 于云存储网关搭建一个海量文件系统的文件存 储服务,实现多个数据中心互相之间高效的同步 和共享数据。云存储网关以对象存储 OSS为后 端存储,为云上和云下应用提供业界标准的文件 服务(NFS和 SMB)和块...
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
基于 DataWorks的大数据一站式开发及数据治理 最佳实践 业务架构 场景描述 解决问题 本实践基于 Dataworks做大数据一站式开发,包含 日志采集、处理及分析 数据实时采集到 kafka 通过实时计算对数据进行 日志使用 Flink实时写入 HDFS ETL写入 HDFS,使用 Hive进行数据分析。通过 日志数据实时 ETL Dataworks进行数据治理,...
EMR本地盘实例大规模数据集测试
场景描述 阿里云为了满足大数据场景下的存储需求,在云 上推出了本地盘D1机型,这个系列提供了本地 盘而非云盘作为存储,提高了磁盘的吞吐能力, 发挥Hadoop的就近计算优势。阿里云EMR 产品针对本地盘机型,推出了一整套的自动化运 维方案,帮助用户方便可靠地使用本地盘机型, 不需要关注整个运维过程同时数据的高可靠和 服务的高可用。 解决问题 1.云盘多份冗余数据导致成本高 2.磁盘吞吐量不高 3.节点的高可靠分布问题 4.本地盘与节点的故障监控问题 5.数据迁移时自动决策问题 6.自动故障节点迁移与数据平衡问题 产品列表 EMR(E-MapReduce) 本地盘 VPC
Hue(Hadoop User Experience)是一个开源的 Apache Hadoop UI 系统,最早是由 Cloudera.Desktop演化而来,由 Cloudera贡献给开源社区,它是基于 Python Web 框架 Django实现的,通过使用 Hue可以在浏览器的 Web控制上与 Hadoop集群来进 行交互分析来处理数据,例如操作 HDFS上的数据,管理和查询 Hive数据库的数据 等等。...
企业上云数据安全
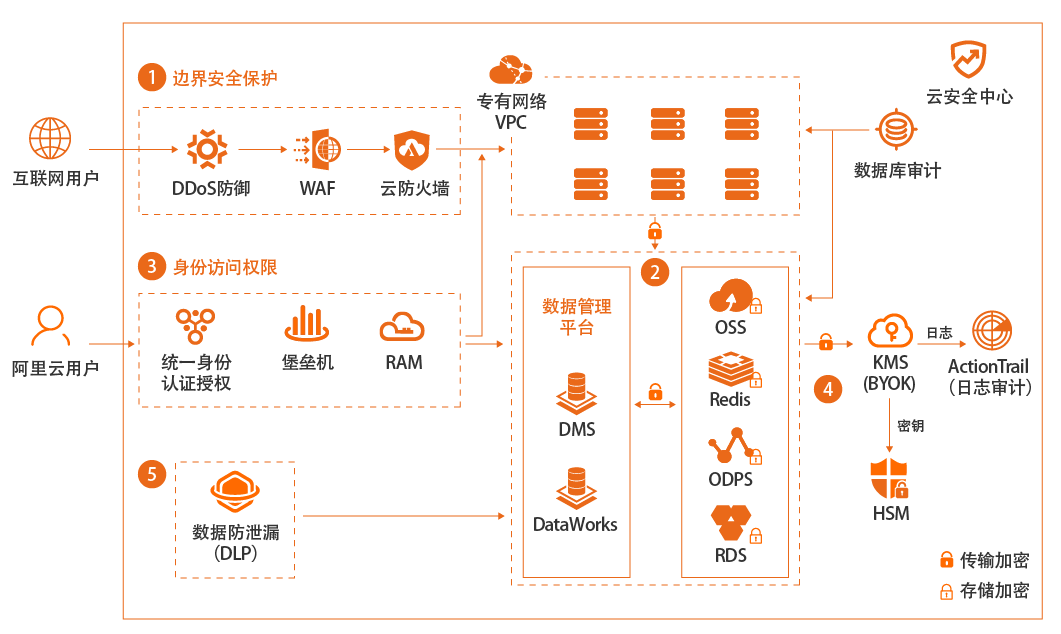
场景描述 企业是否选择上公共云,或者哪些系统或数据上 公共云,对数据安全的关心是重要因素之一。本 最佳实践重点在于介绍狭义的数据加密存储安 全范畴,即首先使用SDDP产品进行敏感数据发 现和分级分类,然后对高级别敏感数据进行按 需、不同类型的全链路加密存储。 解决问题 1.帮助客户发现敏感数据 2.对敏感数据进行分类、分级 3.对不同级别的数据如何选择加密方式 4.具体如何进行加密 产品列表 敏感数据识别SDDP 密钥管理服务KMS 云数据库RDS 对象存储OSS
本最佳实践重点在于介绍狭义的数据加密 存储安全范畴,即首先使用 SDDP产品进行敏 感数据发现和分级分类,然后对高级别敏感数 据进行按需、不同类型的全链路加密存储。解决问题 1.帮助客户发现敏感数据 2.对敏感数据进行分类、分级 3.对不同级别的数据如何选择加密方式 4.具体如何进行加密 产品列表 敏感数据识别 SDDP 密钥...
Spark on ECI大数据分析

场景描述 方案优势 1.计算引擎弹性扩缩容,兼顾资源弹性与计 算资源成本优化。 2.计算与存储分离架构,结合阿里云原生云 存储产品,海量数据湖优势。 3.Kubernetes原生的调度性能优势,提升在 大规模分析作业时的分析性能优势分。 4.集群资源隔离和按需分配。 解决问题 1.计算资源弹性能力不足,计算资源成本管 控能力欠缺. 2.集群资源调度能力和隔离能力不足。 3.计算与存储无法分离,大数据量分析时出 现数据存储资源瓶颈。 4.Spark submit方式提交分析作业参数支持 有限等缺点。 产品列表 容器服务Kubernetes版(ACK) 弹性容器实例(ECI) 文件存储HDFS 对象存储OSS 专有网络VPC 容器镜像服务ACR
Spark on Kubernetes解决方案的用户 对 Spark大数据分析平台计算资源成本控制考虑的用户 需要有灵活可扩展计算平台资源弹性及管控的用户 名词解释 文件存储 HDFS:阿里云文件存储 HDFS是面向阿里云 ECS实例及容器服务等计 算资源的文件存储服务,允许用户像在 Hadoop分布式文件系统中管理和访问数 据,无需对数据分析应用做...
自建Hadoop迁移MaxCompute
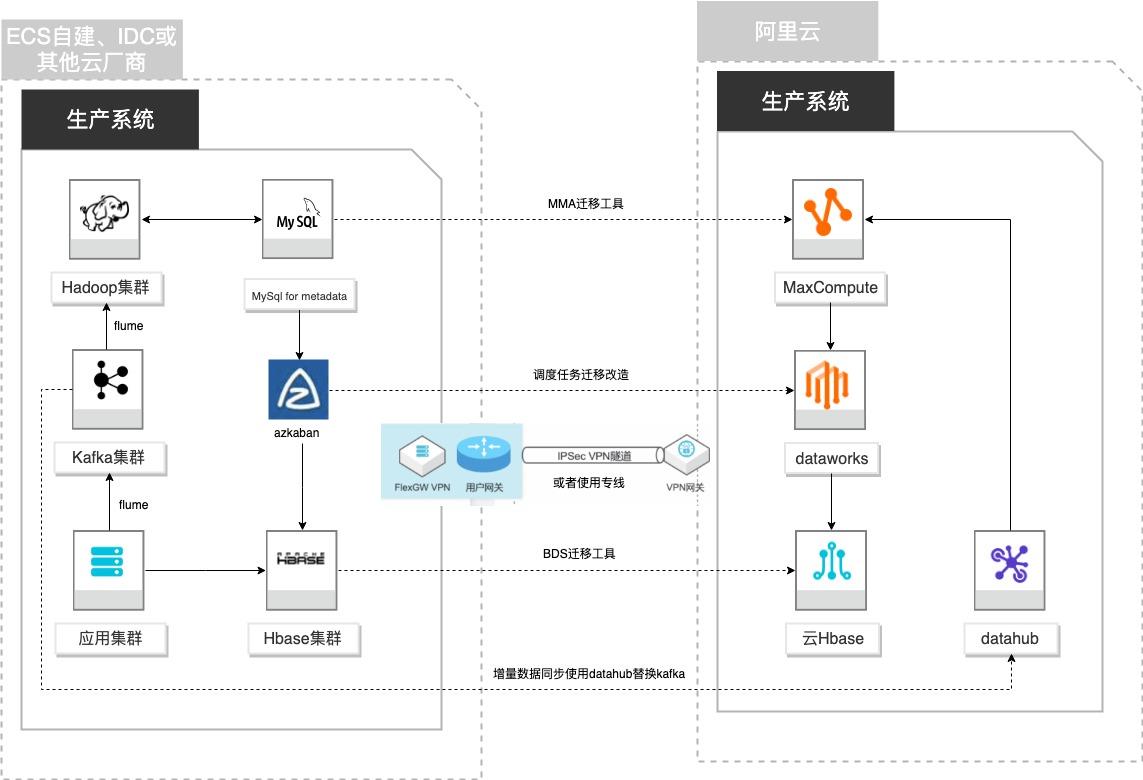
场景描述 客户基于ECS、IDC自建或在友商云平台自建了大数 据集群,为了降低企业大数据计算平台的成本,提高 大数据应用开发效率,更有效保障数据安全,把大数 据集群的数据、作业、调度任务以及业务数据库整体 迁移到MaxCompute和其他云产品。 解决的问题 自建Hadoop集群搬迁到MaxCompute 自建Hbase集群搬迁到云Hbase 自建Kafka或应用数据准实时同步到 MaxCompute 自建Azkaban任务迁移到Dataworks任务 产品列表 MaxCompute,Dataworks、云数据库Hbase版、Datahub、VPC,ECS。
VPN网关 VPN网关是一款基于 Internet的网络连接服务,通过加密通道的方式实现企业数 据中心、企业办公网络或 Internet终端与阿里云专有网络(VPC)安全可靠的连 接。VPN 网关提供 IPSec-VPN 连接和 SSL-VPN 连接。详情请查看 https://www.aliyun.com/product/vpn IPSec VPN 基于路由的 IPSec-VPN,不仅可以更方便的配置和...
- 产品推荐
- 这些文档可能帮助您