运筹帷幄,快捷搭建企业经营数据大屏
随着数字化建设推进,如何从复杂的业务数据的中洞察趋势、辅助决策,成为了企业现代化管理的一项关键挑战。阿里云DataV数据可视化平台提供一站式企业经营数据大屏建设方案,提供监控大屏、PC看板、移动端看板等覆盖全端的经营数据实时监控与分析决策能力。
随着数字化建设推进,如何从复杂的业务数据的中洞察趋势、辅助决策,成为了企业现代化管理的一项关键挑战。阿里云DataV数据可视化平台提供一站式企业经营数据大屏建设方案,提供监控大屏、PC看板、移动端看板等覆盖全端的经营数据实时监控与分析决策能力。运筹帷幄,快捷搭建企业经营数据大屏 随着数字化建设推进,如何从...
来自:
技术解决方案
企业云上网络架构规划
企业云上网络架构规划方案能够为企业提供面向业务的网络架构,确保业务的可靠性,并保持架构的可扩展性和可持续性,以满足未来企业业务增长所需的资源扩容和架构升级。
企业云上网络架构规划方案能够为企业提供面向业务的网络架构,确保业务的可靠性,并保持架构的可扩展性和可持续性,以满足未来企业业务增长所需的资源扩容和架构升级。企业云上网络架构规划 企业云上网络架构规划方案能够为企业提供面向业务的网络架构,确保业务的可靠性,并保持架构的可扩展性和可持续性,以满足未来企业...
来自:
技术解决方案
高效构建企业门户网站
本方案为您介绍如何使用云效将项目代码部署到云服务器ECS,快速完成一个企业门户网站的开发和部署。
本方案为您介绍如何使用云效将项目代码部署到云服务器ECS,快速完成一个企业门户网站的开发和部署。高效构建企业门户网站 本方案为您介绍如何使用云效将项目代码部署到云服务器ECS,快速完成一个企业门户网站的开发和部署。在线部署 适用客户 企业数字化转型 搭建并维护企业网站 方案优势 为什么要搭建门户网站 对于企业而...
来自:
技术解决方案
企业上云框架 Landing Zone
基于大量企业的上云实践验证,帮助企业规划云上资源结构、访问控制、网络架构、安全合规体系,搭建可管理、可扩展的云环境。企业客户可以在此基础上缩短上云周期,将原有的业务平顺上云并快速开展新业务。
在线部署 适用客户 需要快速构建云环境的企业 追求云治理效率的企业 面临多领域决策挑战的企业 方案优势 为什么选择企业上云框架 Landing Zone 云上环境的顶层设计 充分考虑企业长期发展需求,满足复杂企业组织和业务规模化上云的需求。加速业务规模化上云效率 基于可拓展和自动化的设计,可以降低业务规模化上云后管理难度...
来自:
技术解决方案
云防火墙企业多账号统一管理
为了解决多账号资源安全管控和降低安全运维成本,云防火墙结合资源目录服务,为用户提供了多账号统一管理方案。只需开启多账号统一管理,用户即可在云防火墙控制台集中保护多个账号的资源安全,大幅提升安全运维效率和降低采购成本。
架构与部署 云防火墙企业多账号统一管理 本方案通过将多个阿里云账号加入同一个资源目录,建立云上企业业务组织关系。用户可以指派购买了云防火墙的阿里云账号为委派管理员账号,并建立云防火墙多账号体系。方案部署完成后,用户可以通过云防火墙控制台统一管理多个账号的云资源,防护多账号下的云资源的安全性。立即部署 ...
来自:
技术解决方案
高效构建安全合规的企业新账号
通过账号工厂解决方案能够高效构建安全合规的新账号。在本方案中会介绍如何利用开源的IaC工具(Terraform)来快速创建安全合规的新账号。通过此方案可以统一企业内不同账号内的基线,灵活适配不同企业对账号初始化的个性需求。
通过此方案可以统一企业内不同账号内的基线,灵活适配不同企业对账号初始化的个性需求。高效构建安全合规的企业新账号 通过账号工厂解决方案能够高效构建安全合规的新账号。在本方案中会介绍如何利用开源的IaC工具(Terraform)来快速创建安全合规的新账号。通过此方案可以统一企业内不同账号内的基线,灵活适配不同企业对...
来自:
技术解决方案
限制企业仅使用已批准的云服务
客户使用资源目录集中管理云上账号,通过管控策略创建“只能使用批准的云服务”对应的Policy,将Policy绑定到资源目录的Root资源夹,则此策略对Root资源夹下的所有子资源夹及成员生效。通过此能力,可以实现企业在云上只能使用批准的云服务,从而规范企业内部用户订购和使用云产品的行为。
通过此能力,可以实现企业在云上只能使用批准的云服务,从而规范企业内部用户订购和使用云产品的行为。限制企业仅使用已批准的云服务 客户使用资源目录集中管理云上账号,通过管控策略创建“只能使用批准的云服务”对应的Policy,将Policy绑定到资源目录的Root资源夹,则此策略对Root资源夹下的所有子资源夹及成员生效。...
来自:
技术解决方案
企业级云灾备与数据管理
云备份 Cloud Backup 为企业数据安全提供了全方位的云灾备、冷热数据统一管理能力,全面覆盖公共云、混合云以及本地 IDC 生产环境,帮助用户减少因自然灾害、系统故障、运维事故、勒索病毒等造成的数据丢失而带来的业务影响。
云备份 Cloud Backup 为企业数据安全提供了全方位的云灾备、冷热数据统一管理能力,全面覆盖公共云、混合云以及本地 IDC 生产环境,帮助用户减少因自然灾害、系统故障、运维事故、勒索病毒等造成的数据丢失而带来的业务影响。企业级云灾备与数据管理 云备份 Cloud Backup 为企业数据安全提供了全方位的云灾备、冷热数据统一...
来自:
技术解决方案
企业多账号配置统一合规审计
面向企业的各中心管理团队提供一种面向多账号的合规管理方案。从上而下的实施统一的合规基线并强制管理,可中心化的持续监测所有业务的合规状态。提升中心管理团队工作的可见性可控性,切实起到监管效力,规避潜在风险。
立即部署 55分钟 免费(资源目录、配置审计均为免费产品)资源管理 配置审计 云服务器 ECS 云企业网 Web应用防火墙 对象存储 应用场景 技术方案的广泛应用场景 高效实施企业内控基线 企业为保证经营活动的有序运行,保障IT服务的稳定性和合规性,通常会对IT服务制定相关管控措施,来进行监督和审计。法规及行业标准预检 ...
来自:
技术解决方案
企业多账号身份权限集中管理
本方案帮助企业实现身份权限集中管理,包括集中管理阿里云上的人员身份,一次性配置企业身份管理系统与阿里云的单点登录,和统一配置所有用户对企业成员账号的访问权限。能够降低企业在阿里云的身份权限配置成本,减少因身份权限分散无法统一管理导致的安全风险。
本方案帮助企业实现身份权限集中管理,包括集中管理阿里云上的人员身份,一次性配置企业身份管理系统与阿里云的单点登录,和统一配置所有用户对企业成员账号的访问权限。能够降低企业在阿里云的身份权限配置成本,减少因身份权限分散无法统一管理导致的安全风险。企业多账号身份权限集中管理 本方案帮助企业实现身份权限...
来自:
技术解决方案
高效安全:企业统一公网出口
本方案介绍了企业上云,通过NAT构建公网出口,帮助企业更加统一、安全地管理自己的云上公网访问能力,同时可以实现高效的运维管理和公网成本优化。
本方案介绍了企业上云,通过NAT构建公网出口,帮助企业更加统一、安全地管理自己的云上公网访问能力,同时可以实现高效的运维管理和公网成本优化。高效安全:企业统一公网出口 本方案介绍了企业上云,通过NAT构建公网出口,帮助企业更加统一、安全地管理自己的云上公网访问能力,同时可以实现高效的运维管理和公网成本优化...
来自:
技术解决方案
基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步
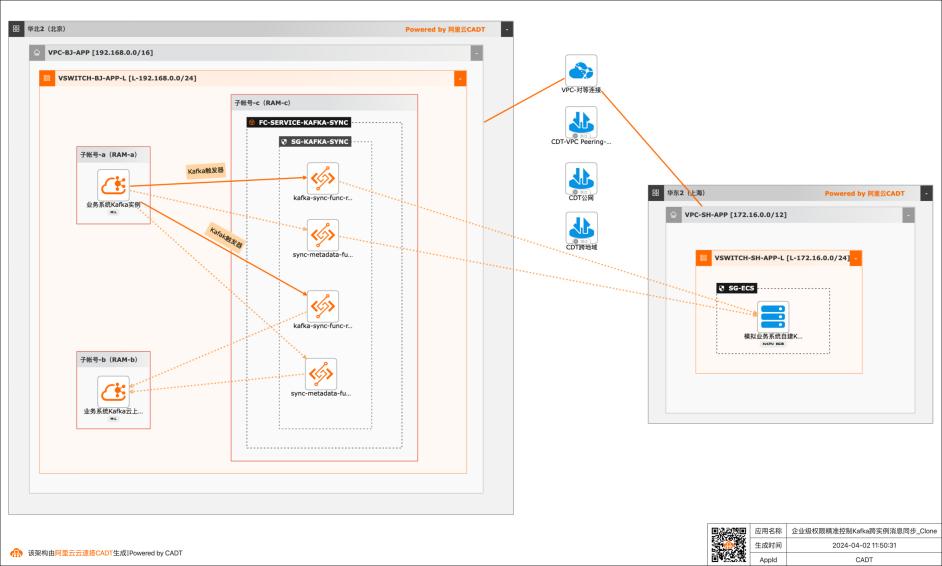
应用场景 在大数据场景,企业的Kafka实例可能存在多种情况,比如使用阿里云Kafka服务,可能是自建开源Kafka,或者是其他云上的云Kafka。不同的业务使用不同类型的Kafka实例,在这个前提下Kafka实例之间可能会需要消息同步的情况: 同帐号容灾场景:比如Kafka实例都是阿里云Kafka,但是Kafka实例会有主备之分,需要将主Kafka实例的消息实时同步到备Kafka。 跨帐号或异地容灾:这类场景比如主Kafka是阿里云Kafka,备Kafka是IDC开源自建Kafka,或者是其他云上的Kafka。 不同业务之间消息同步:因为现在的业务通常不会是信息孤岛,都需要消息互通,所以可能是A业务的Kafka实例消息需要同步到B业务的Kafka实例,并且这两个Kafka实例归属不同的RAM角色,有自己独自的权限控制。 解决问题 解决使用开源组件做消息同步的高成本问题。 解决使用开源组件做消息同步的并发性能、稳定性问题。 解决使用开源组件做消息同步的可靠性问题(重试机制,容错机制,死信队列等)。 大幅提升构建消息同步架构的效率,降低构建复杂度问题。
属性 内容 文档名称 基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步 文档编号 369 文档版本 V1.2 版本日期 2024-03-30 文档状态 外部发布 制作人 计缘 审阅人 游圣 变更记录 版本编号 日期 作者 审阅人 说明 V1.0 20240330 计缘 游圣 初始版本 V1.2 20240402 游圣、寰奕 更新CDT部署相关内容 文档版本:20240330...
企业上云workshop
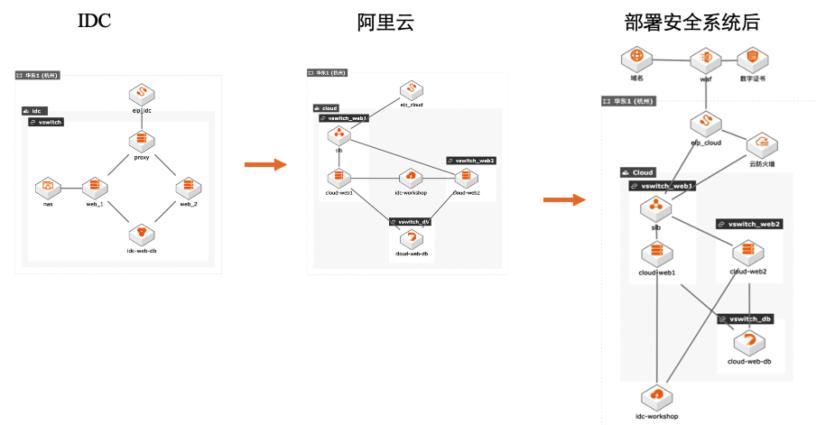
本文模拟了如下场景: 1. 线下 IDC 环境中部署了一个业务系统,业务是利用 wordpress 系统提供网站服务。 2. 本文详细介绍了如何将以上线下系统搬迁到云上, 包括如何在云上构建以上业务系统,如何迁移线下 系统到云上,如何割接。 3. 最后介绍了迁移上云后,如何部署安全系统。 解决问题 IDC 业务系统搬迁上云 云上构建业务系统 部署安全系统
企业上云 workshop-IDC业务迁移上云 部署架构图 场景描述 本文模拟了如下场景:1.线下 IDC环境中部署了一个业务系统,业务是利用 wordpress系统提供网站服务。2.本文详细介绍了如何将以上线下系统搬迁到云上,包括如何在云上构建以上业务系统,如何迁移线下 系统到云上,如何割接。3.最后介绍了迁移上云后,如何部署安全...
来自:
最佳实践
相关产品:专有网络 VPC,云服务器ECS,云数据库RDS MySQL 版,对象存储 OSS,负载均衡 SLB,弹性公网IP,文件存储NAS,云数据库PolarDB,Web应用防火墙,云防火墙,SSL证书,云速搭
- 产品推荐
- 这些文档可能帮助您