自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
通过下面命令将 master、slave1、slave2 和 slave3 这 4 个节点上的公钥文件/root/.ssh/id_rsa.pub内容拷贝到 master节点的/root/.ssh/authorized_keys文 件中。cat/root/.ssh/id_rsa.pub>>/root/.ssh/authorized_keys 文档版本:20210425 8 自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 基础环境搭建 ssh ...
OpenLake大数据&AI一体化解决方案
本方案是基于开放可控数据湖仓构建的大数据/搜索/AI一体化解决方案。通过元数据管理平台DLF管理结构化和半/非结构化数据,提供湖仓数据表和文件的安全访问及IO加速。支持多引擎对接和平权协同计算,通过DataWorks统一开发,并保障大规模任务调度。
通过元数据管理平台DLF管理结构化和半/非结构化数据,提供湖仓数据表和文件的安全访问及IO加速。支持多引擎对接和平权协同计算,通过DataWorks统一开发,并保障大规模任务调度。OpenLake大数据&AI一体化解决方案 本方案是基于开放可控数据湖仓构建的大数据/搜索/AI一体化解决方案。通过元数据管理平台DLF管理结构化和半/非...
来自:
技术解决方案
基于函数计算实现直播流录制-存储-通知
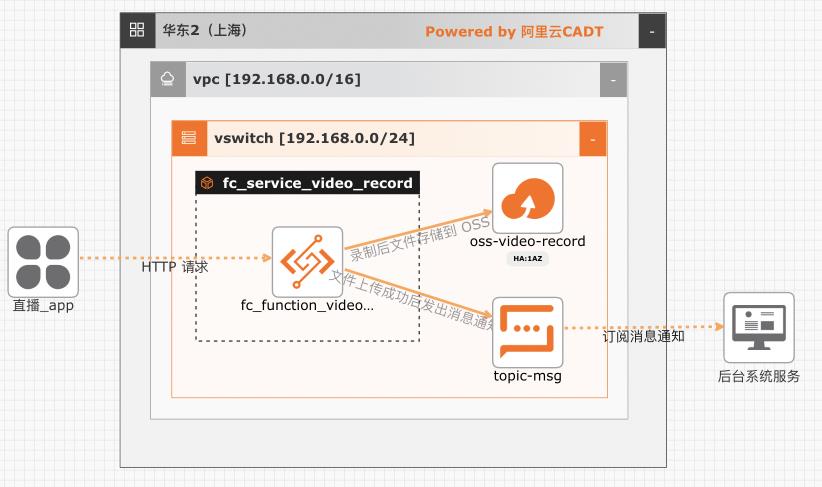
在互娱、教育、电商等行业都会有直播相关的业务,大部分场合都需要对直播相关的业务做安全审核,或者对直播的课程进行录制和转码。该方案实现了一种完全按需拉起、按量弹性、按实际使用付费的录制方案。基于本方案还可以扩展实现直播流截帧、自动化安全审核等能力
通过 Git获取示例代码和文件 使用Git Clone命令,从 Git仓库下载示例代码和文件。git clone https://best-practice:Abcd123456@codeup.aliyun.com/best- practice/bp/374.git 下载成功后,会看到名为 374的文件夹,里面包含 1个 ZIP文件。ZIP 文件就是实现录制功能的代码源文件,后面会替换到函数计算的函数中。文档版本:...
基于OSS Object FC实现非结构化文件实时处理最佳实践
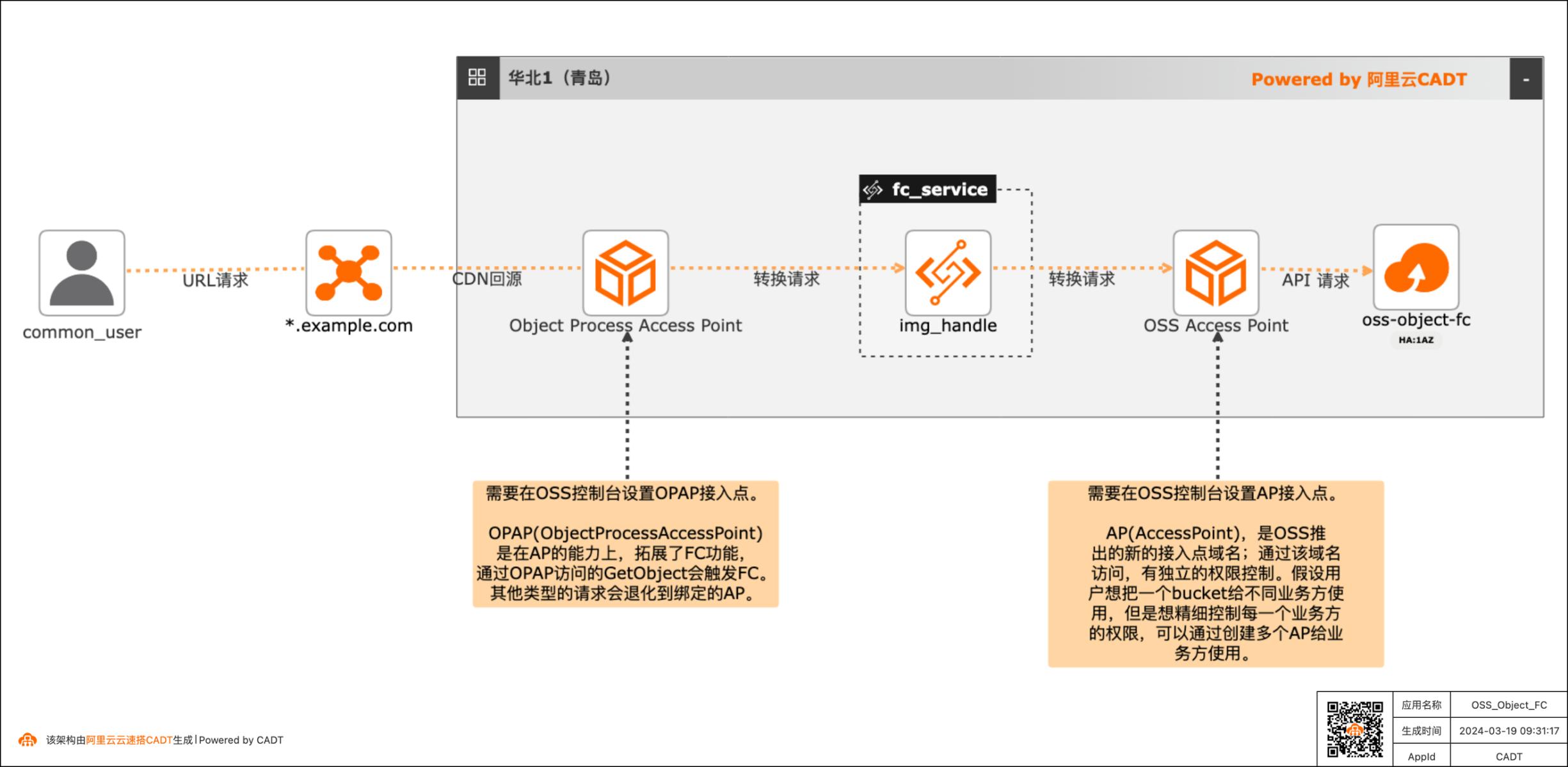
现在绝大多数客户都有很多非结构化的数据存在OSS中,以图片,视频,音频居多。举一个图片处理的场景,现在各种终端种类繁多,不同的终端对图片的格式、分辨率要求也不同,所以一张图片往往会有很多张衍生图,那如果所有的衍生图都存在OSS中,那存储的成本会增加,所以就可以通过OSS Object FC的方案,在不同的终端请求时,对OSS中的原图基于终端的要求做实时处理,然后响应返回,这样OSS中只需要存储原图即可。音视频也有类似的场景。
通过Git获取示例代码和文件 步骤1 使用GitClone命令,从Git仓库下载示例代码和文件。gitclonehttps:/best-practice:Abcd123456@codeup.aliyun.com/best-practice/bp/366.git 步骤2 下载成功后,会看到名为366的文件夹,里面包含4个文件。 oss-object-fc-original-img.png:方案中使用到的图片样例。 img_resize.py:...
基于函数计算FC实现阿里云Kafka消息轻量级ETL处理
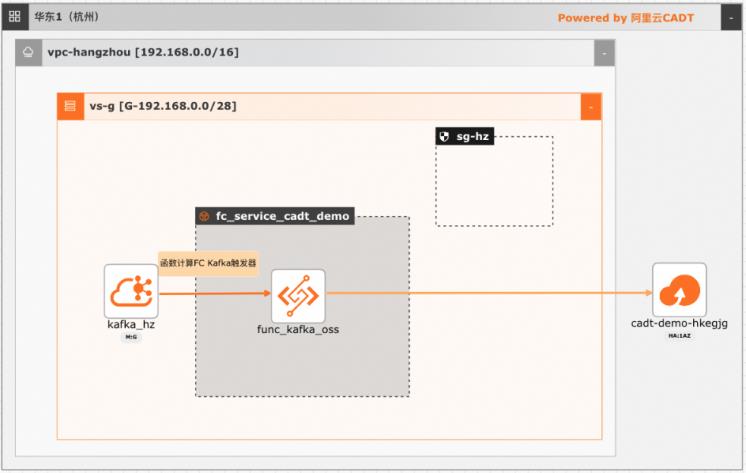
在大数据ETL场景,Kafka是数据的流转中心,Kafka中的数据一般是原始数据,可能存在多种数据混杂的情况,需要进一步做数据清洗后才能进行下一步的处理或者保存。利用函数计算FC,可以快速高效的搭建数据处理链路,用户只需要关注数据处理的逻辑,数据的触发,弹性伸缩,运维监控等阿里云函数计算都已经做了集成,函数计算FC也支持多种下游,OSS/数据库/消息队列/ES等都可以自定义的对接
可以看到对应的文件,代码中文件存储的名字按照时间生成。点击下载,可以在本地查看文件内容 文档版本:20240408 25 基于函数计算 FC实现阿里云 Kafka消息轻量级 ETL处理 场景验证 本次下载本地数据如下,符合预期,输入 3条数据,包含“error”关键字的被过滤,留下2条数据 如果结果不符合预期,可以开启函数计算日志,在...
通过ES兼容接口方式使用Kibana访问SLS数据
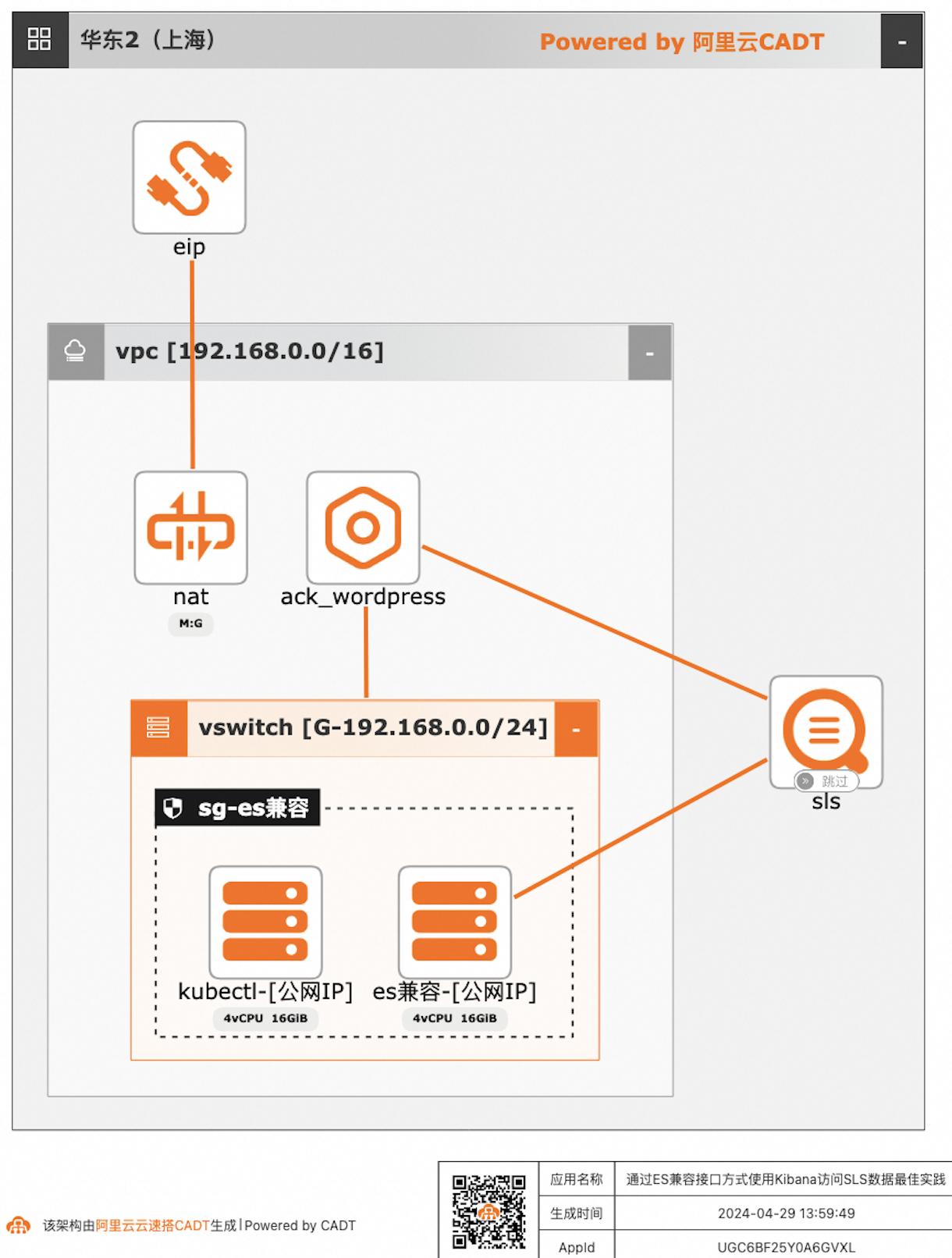
自建ELK日志系统的客户迁移到阿里云日志服务SLS后,对SLS查询分析语法不太熟悉的客户,可以继续沿用原有的查询分析习惯,在不改变使用方式习惯的情况下,通过Elasticsearch兼容接口的方式使用Kibana访问SLS。
通过Git下载示例代码 步骤1 使用GitClone命令,从Git仓库下载示例代码和文件。gitclonehttps:/best-practice:Abcd123456@codeup.aliyun.com/best-practice/bp/373.git 步骤2 打开es兼容.txt文件后,可以看到有3部分内容。1、定时触发访问Wordpress应用的python脚本 2、Logtail采集配置 3、ES兼容配置信息 文档版本:...
基于函数计算FC实现物联网音视频处理
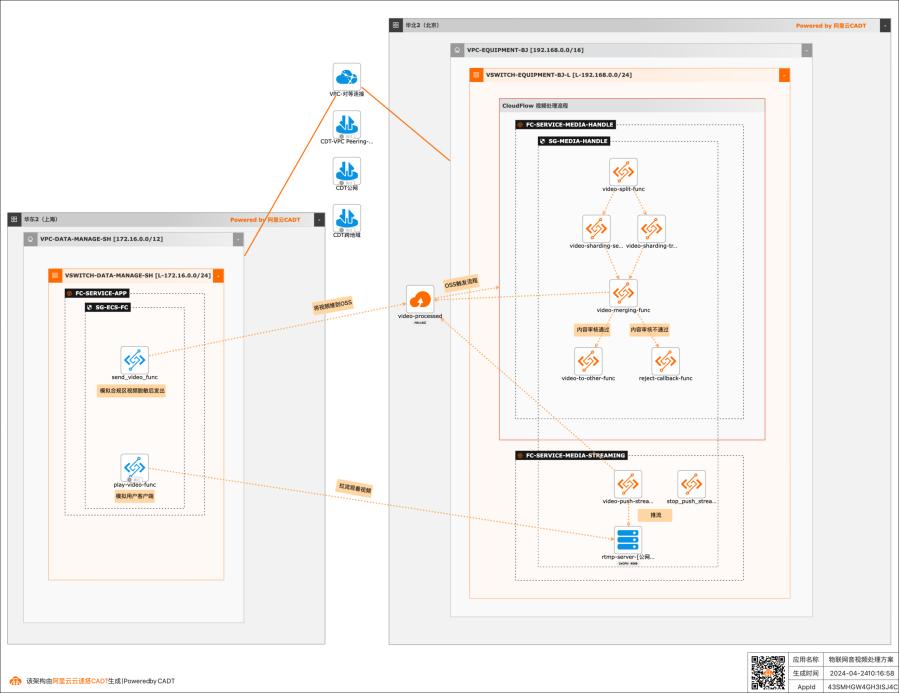
在物联网场景中,智能设备会产生大量的非结构化数据,并且采集量和频率都很高。比如各类摄像头(家用摄像头、车载摄像头、工业监控摄像头等)采集的数据。企业需要对这些非结构化数据做快速的分析和处理,然后应用到下游业务中,所以需要一套高并发、低成本、自动化的方案。该最佳实践就适用于这类场景。
通过Git下载示例代码 步骤1 使用GitClone命令,从Git仓库下载示例代码和文件。gitclonehttps:/best-practice:Abcd123456@codeup.aliyun.com/best-practice/bp/370.git 步骤2 下载成功后,会看到名为370的文件夹,里面包含2个文件夹,及若干视频文件和代 码文件,我们不需要关注videos文件夹里的视频文件,这是之后验证时...
基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步
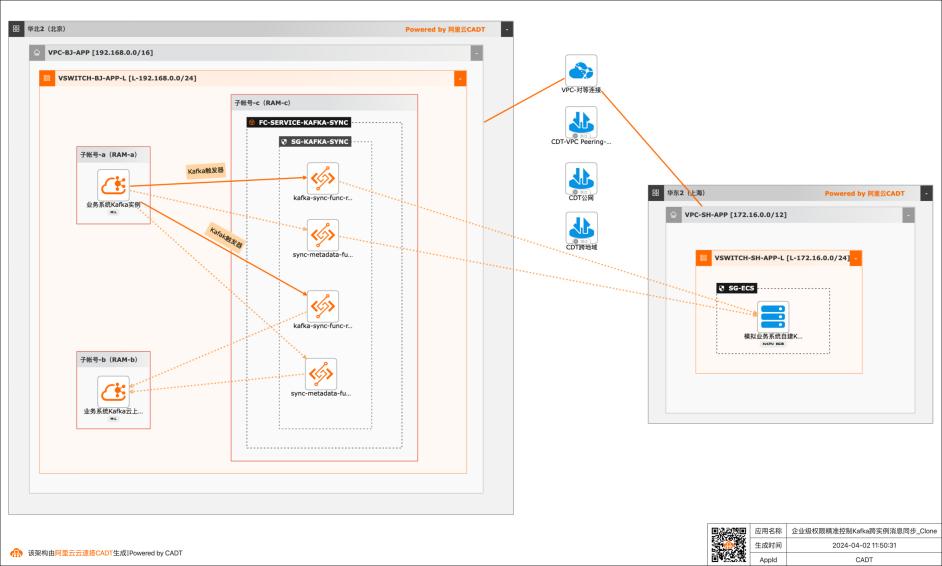
应用场景 在大数据场景,企业的Kafka实例可能存在多种情况,比如使用阿里云Kafka服务,可能是自建开源Kafka,或者是其他云上的云Kafka。不同的业务使用不同类型的Kafka实例,在这个前提下Kafka实例之间可能会需要消息同步的情况: 同帐号容灾场景:比如Kafka实例都是阿里云Kafka,但是Kafka实例会有主备之分,需要将主Kafka实例的消息实时同步到备Kafka。 跨帐号或异地容灾:这类场景比如主Kafka是阿里云Kafka,备Kafka是IDC开源自建Kafka,或者是其他云上的Kafka。 不同业务之间消息同步:因为现在的业务通常不会是信息孤岛,都需要消息互通,所以可能是A业务的Kafka实例消息需要同步到B业务的Kafka实例,并且这两个Kafka实例归属不同的RAM角色,有自己独自的权限控制。 解决问题 解决使用开源组件做消息同步的高成本问题。 解决使用开源组件做消息同步的并发性能、稳定性问题。 解决使用开源组件做消息同步的可靠性问题(重试机制,容错机制,死信队列等)。 大幅提升构建消息同步架构的效率,降低构建复杂度问题。
通过Git下载示例代码 步骤1 使用GitClone命令,从Git仓库下载示例代码和文件。gitclonehttps:/best-practice:Abcd123456@codeup.aliyun.com/best-practice/bp/369.git 步骤2 下载成功后,会看到名为369的文件夹,里面包含3个文件。 kafka-message-sync.py:同步消息的示例代码 metadata_cloud_kafka_to_idc_kafka.py:...
基于FC实现的Web端视频录制最佳实践
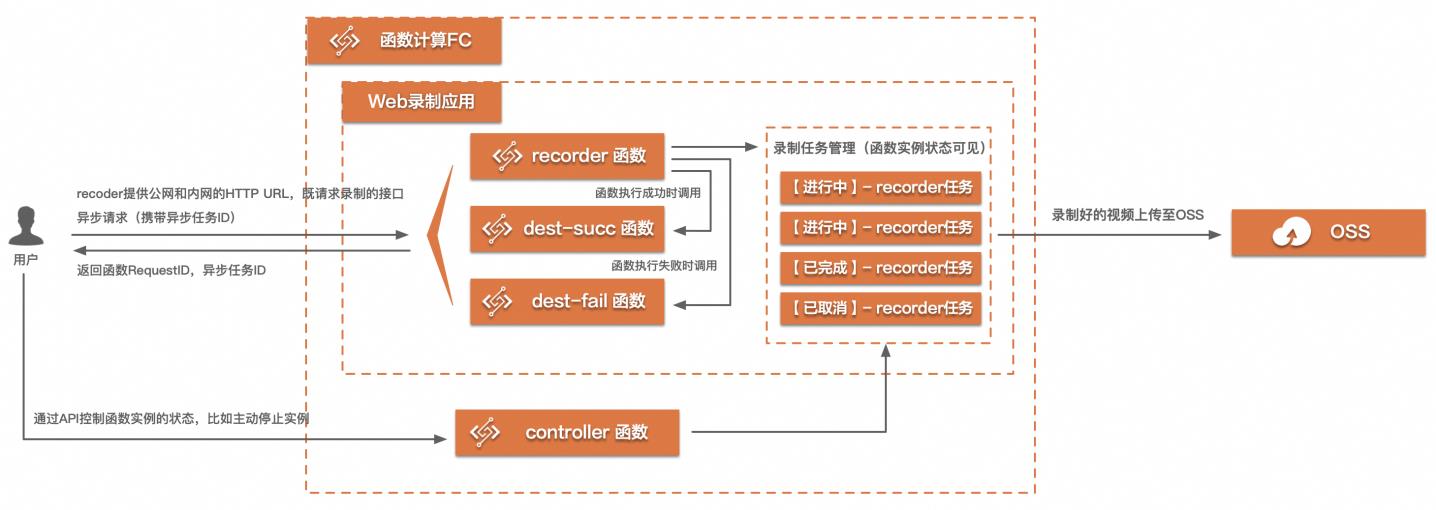
场景描述在很多互娱场景,在线教育领域会有直播视频录制的需求,但是往往一个页面上的内容是多种多样的,不止有直播流,可能还有白板,评论等其他元素,如果只是录直播流,那内容是不完整的,所以需要将整个屏幕的内容录制为视频。该最佳实践可以有效解决这个场景。
使用 RESTful API 可以在互联网任何位置存储和访问,容量和处理能力弹性扩 展,多种存储类型供选择全面优化存储成本。容器镜像服务 ACR(Alibaba Cloud Container Registry):是面向容器镜像、Helm Chart等符合 OCI标准的云原生制品安全托管及高效分发平台。ACR企业版支 持全球同步加速、大规模和大镜像分发加速、多代码源...
容器多云统一监控日志
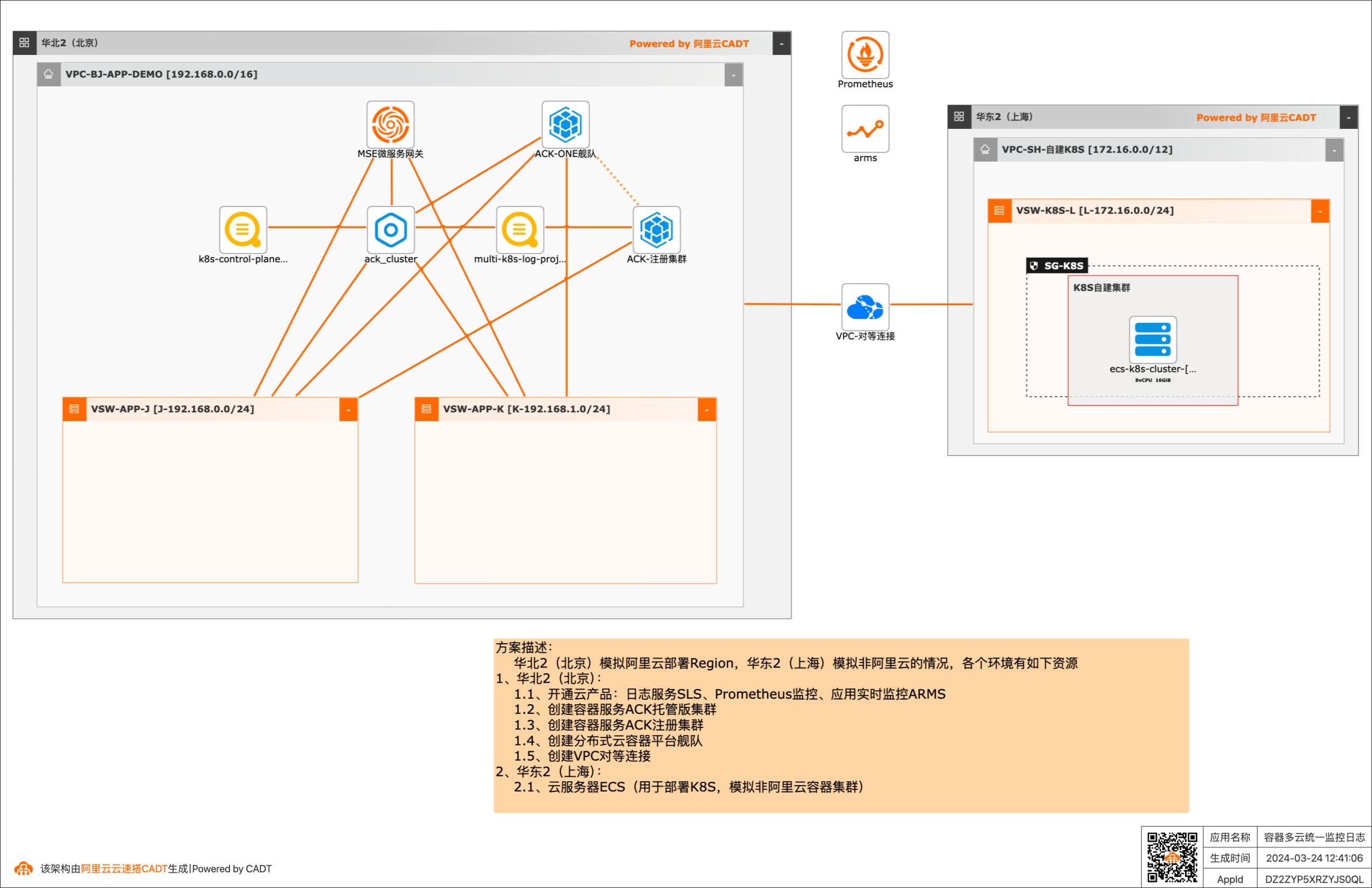
多云、混合云成为常态,Forrester 报告中指出,未来 89% 的企业至少使用两个云,74% 的企业至少使用三个甚至更多公有云,在面对多云/混合云这样大的趋势下,Gartner报告指出,安全、运维复杂性、财务复杂性是多云架构的主要挑战,本方案给出了在多云/混合云场景下,构建基于容器环境下的统一管理、统一监控和统一日志方案,解决多云、混合云场景下,运维复杂性问题。 应用场景 客户在阿里云以外的其他云服务商(AWS、Azure、GCP、TencentCloud、HuaweiCloud等)或者IDC基于容器(Kubernetes)运行业务系统,希望构建容器场景下的统一监控日志系统,方便做不同大屏和问题分析定位。 解决问题 •构建容器多云统一监控和日志系统,在一个平台可以看到不同环境系统的运行情况。
分布式云容器平台ACKOne:是阿里云面向混合云、多集群、分布式计算、容 灾等场景推出的企业级云原生平台,ACKOne可以连接并管理您任何地域、任 何基础设施上的Kubernetes集群,并提供一致的管理和社区兼容的API,支持 对计算、网络、存储、安全、监控、日志、作业、应用、流量等进行统一运维管 控。 日志服务SLS:是云...
基于MSE云原生网关同城多活
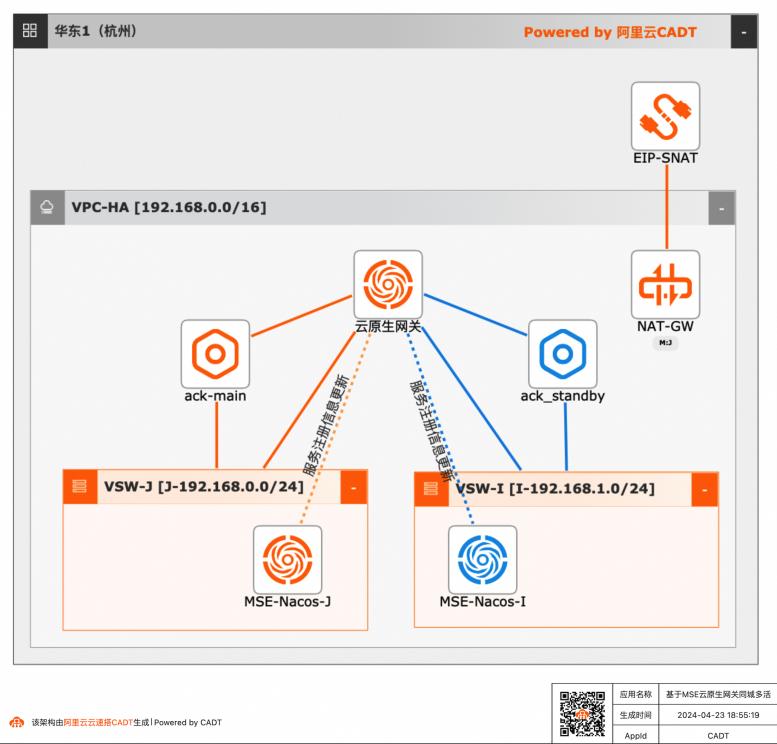
借助云原生微服务MSE网关,MSE配置注册中心的同城容灾多活微服务应用。构建一个经典的微服务场景,实现同城容灾的步骤,体现云原生相关产品在用户上云,高可用同城容灾多活场景下的能力。
通过 Git下载示例代码 步骤1 使用 Git Clone命令,从 Git仓库下载示例代码和文件。git clone https://best-practice:Abcd123456@codeup.aliyun.com/best-practice/bp/359.git 步骤2 下载成功后,会看到名为 359的文件夹,里面包含 2个文件。J-YAML:ack-main集群部署应用使用的 YAML模版 I-YAML:ack-standby集群部署应用...
基于云速搭CADT快速构建药物筛选批量计算环境-serverless版
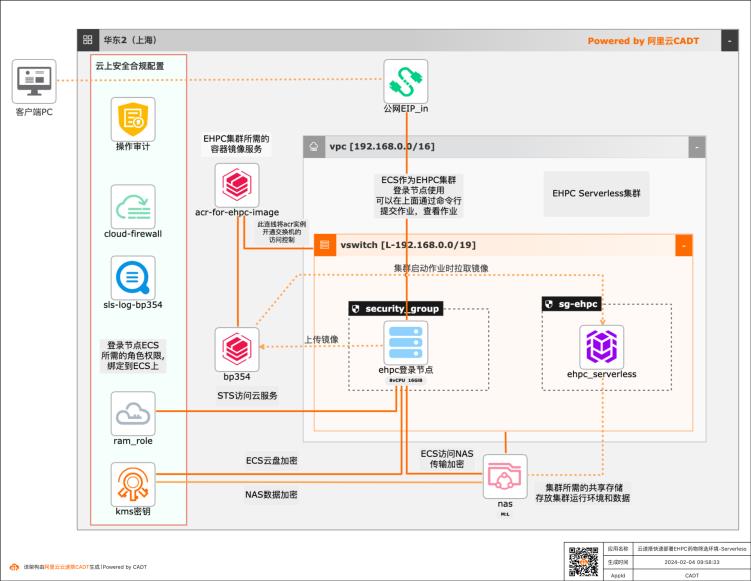
本方案基于云速搭 CADT提供一个快速构建云上Serverless版HPC批量计算环境的模板,针对生物制药领域的药物筛选场景,提供开箱即用的整套解决方案工具包,整个云上环境仅需1个小时即可完成自动化部署搭建。
产品列表 最佳实践频道 阿里云最佳实践分享群 弹性高性能计算 E-HPC Serverless版 文件存储 NAS 云速搭 CADT 容器镜像服务 ACR NAT网关 云服务器 ECS 钉钉扫描二维码或搜索钉群号 31852400入群 基于云速搭 CADT快速部署 药物筛选批量计算环境 Serverless版 文档版本:20240204(发布日期)基于云速搭 CADT部署药物筛选批量...
容器服务 Kubernetes 版 ACK
阿里云容器服务Kubernetes版ACK(容器服务Kubernetes版,简称ACK)支持企业级K8s容器化应用的全生命周期管理,提供高性能可伸缩的容器应用管理能力,助力企业高效运行云端K8s容器化应用。
相关产品容器服务 ACK文件存储 NAS块存储云数据库 Redis 版性能测试 PTS云速搭 CADT一键部署ACK 实现 GPU 成本优化利用 ACK 部署 GPU 集群之后,出于成本优化的考虑,对于集群中 GPU 利用率不高的应用,比如推理的应用,建议利用阿里云 cGPU 技术将一定数量的应用跑到一块 GPU 卡上,以提高利用率。对于 GPU 利用率比较高的...
来自:
云产品
SLS多云日志采集、处理及分析
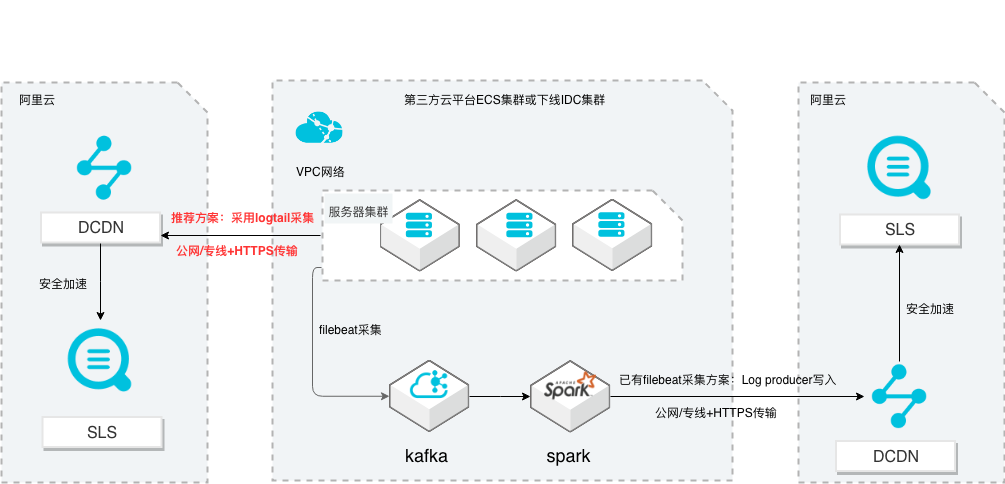
场景描述 从第三方云平台或线下IDC服务器上采集 日志写入到阿里云日志服务,通过日志服务 进行数据分析,帮助提升运维、运营效率, 建立DT 时代海量日志处理能力。 针对未使用其他日志采集服务的用户,推荐 在他云或线下服务器安装logtail采集并使用 Https安全传输;针对已使用其他日志采集 工具并且已有日志服务需要继续服务的情 况,可以通过Log producer SDK写入日志 服务。 解决问题 1.第三方云平台或线下IDC客户需要使用 阿里云日志服务生态的用户。 2.第三方云平台或线下IDC服务器已有完 整日志采集、处理及分析的用户。 产品列表 E-MapReduce 专有网络VPC 云服务器ECS 日志服务LOG DCDN
这些组件一起工作来读取文 件(tail file)并将事件数据发送到您指定的输出。启动 Filebeat时,它会启动一个或多个查找器,查看您为日志文件指定的本地路径。对于 prospector 所在的每个日志文件,prospector 启动 harvester。每个 harvester 都会为新内容读取单个日志文件,并将新日志数据发送到 libbeat,后者将聚合事件...
EMR集群安全认证和授权管理
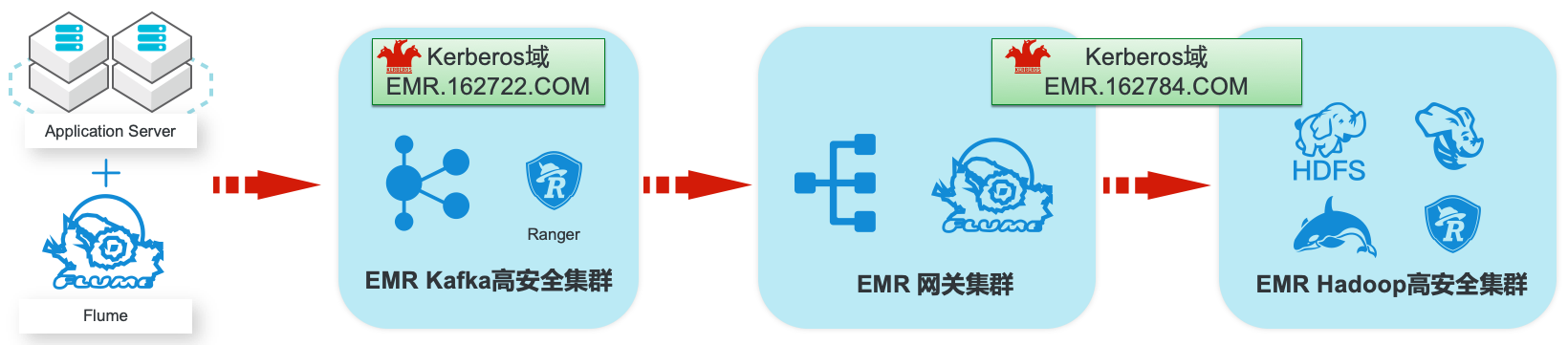
场景描述 阿里云EMR服务Kafka和Hadoop安全集群使 用Kerberos进行用户安全认证,通过Apache Ranger服务进行访问授权管理。本最佳实践中以 Apache Web服务器日志为例,演示基于Kafka 和Hadoop的生态组件构建日志大数据仓库,并 介绍在整个数据流程中,如何通过Kerberos和 Ranger进行认证和授权的相关配置。 解决问题 1.创建基于Kerberos的EMR Kafka和 Hadoop集群。 2.EMR服务的Kafka和Hadoop集群中 Kerberos相关配置和使用方法。 3.Ranger中添加Kafka、HDFS、Hive和 Hbase服务和访问策略。 4.Flume中和Kafka、HDFS相关的安全配 置。 产品列表:E-MapReduce、专有网络VPC、云服务器ECS、云数据库RDS版
步骤2 将 Kafka集群的 emr-header-1的/etc/hosts内容拷贝到 emr_loggen的/etc/hosts文 件中,下面红色字体为 Kafka集群的 emr-header-1节点的 VPC IP地址。ssh root@10.17.105.171"cat/etc/hosts">>/etc/hosts 步骤3 通过以下命令生成一个 Flume的配置文件。cd/opt/bigdata/flume/job_test cp flume-kafka.conf flume-emr-...
互联网电商行业离线大数据分析

电商网站销售数据通过大数据分析后将业务指标数据在大屏幕上展示,如销售指标、客户指标、销售排名、订单地区分布等。大屏上销售数据可视化动态展示,效果震撼,触控大屏支持用户自助查询数据,极大地增强数据的可读性。
大数据开发治理平台DataWorks:基于阿里云ODPS/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。作为阿里巴巴数据中台的建设者,互联网电商行业离线大数据分析 最佳实践概述 DataWorks从2009年起不断沉淀阿里巴巴大数据建设方法论,同时与数万名政务/金融/零售/互联网/...
- 产品推荐
- 这些文档可能帮助您