Function Compute构建高弹性大数据采集系统
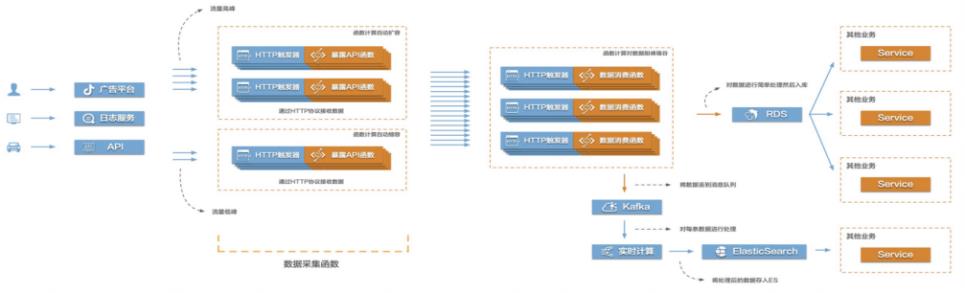
当前互联网很多场景都存在需要将大量的数据信息采集起来然后传输到后端的各类系统服务中,对数据进行处理、分析,形成业务闭环。比如游戏行业中的游戏发行、游戏运营,产互行业中的数字营销,物联网、车联网行业中的硬件、车辆信息上报等等。这些场景普遍存在数据采集量大、数据传输需要稳定且吞吐量大的特点,给整个数据采集传输系统带来很大的挑战。在这个场景中,有三个关键的环节,数据采集、数据传输、数据处理。该最佳实践主要涉
编写 template.yml 步骤1 新建一个目录 fc,在该目录下创建一个名为 template.yml的 YAML文件,该文件主要 描述要创建的函数的各项配置,就是将函数计算控制台上配置的那些配置信息以 YAML格式写在文件里。mkdir fc cd fc touch template.yml 步骤2 首先,我们导出 dataCollector服务的 yml模板,然后在其基础上增加 ...
本地数据中心基于SMB/NFS协议访问对象存储最佳实践
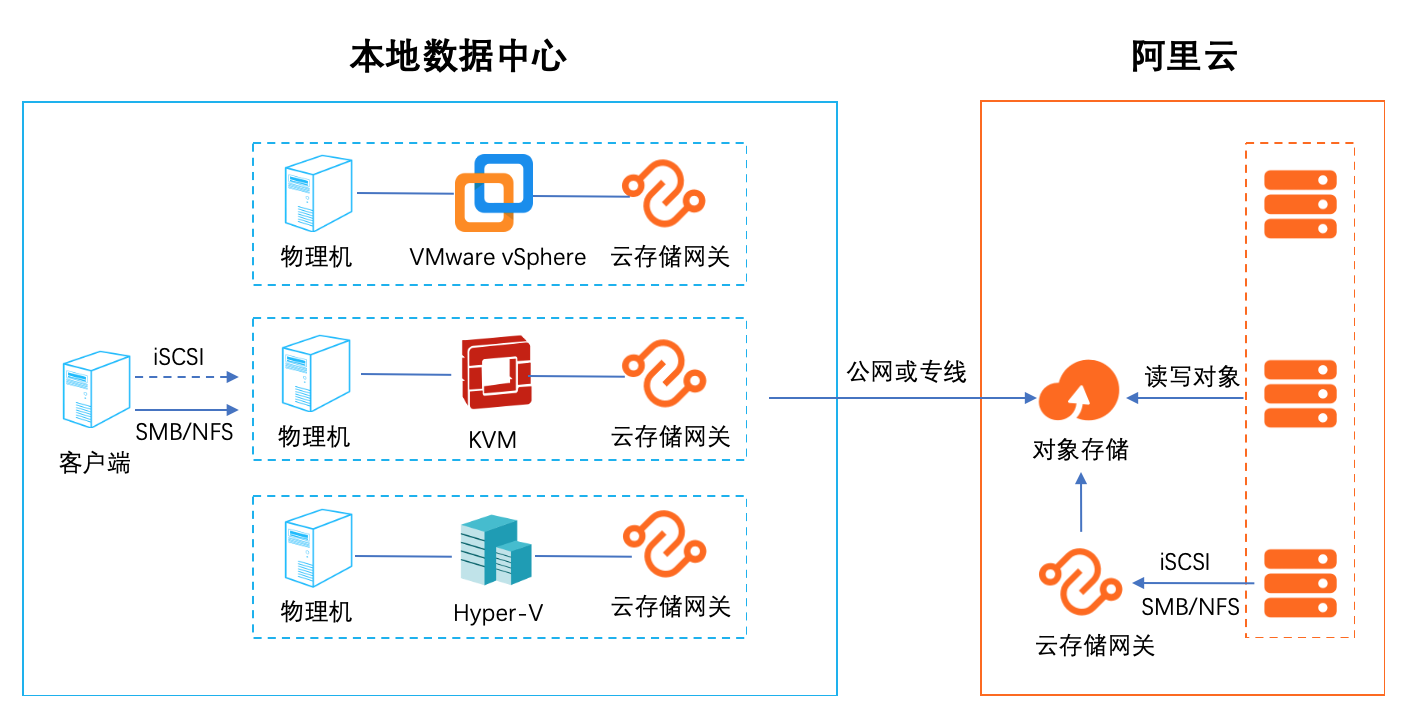
1. 云存储扩容和迁移 集成智能缓存算法,自动识别冷热数据,将热数据保留在本地缓存,保证数据访问体验,无感知的将海量云存储数据接入本地数据中心,拓展存储空间。同时在云端 保留全量数据(冷+热)保证数据的一致性 2.云容灾 随着云计算的普及,越来越多的用户把自己的业务放到了云上。但是随着业务的发展,如何提高业务的可靠性和连续性,跨云容灾是一个比较热门的话题。借助云存 储网关对虚拟化的全面支持,可以轻松应对各种第三方云厂商对接阿里云的数据容灾。 3. 多地数据共享和分发 通过多个异地部署的文件网关实例,对接同一个阿里云OSS Bucket,可以实现快速的异地文件共享和分发,非常适合多个分支机构之间互相同步和共享数据。 4. 适配传统应用 有很多用户在云上的业务是新老业务的结合,老业务是从数据中心迁移过来的使用的是标准的存储协议,例如: NFS/SMB/iSCSI。新的应用往往采用比较新的技 术,支持对象访问的协议。如何沟通两种业务之间的数据是一个比较麻烦的事情,云存储网关正好起到一个桥梁的作用,可以便捷的沟通新旧业务,进行数据交换。 5. 替代 ossfs 和 ossftp ossfs 和 ossftp 都是基于文件协议的开源工具,用户可以通过它们直接上传文件到OSS。但是这两个开源文件都不建议在生产环境使用(POSIX 兼容度低),同时挂 载在用户的客户端需要额外的配置和缓存资源,对于多个客户端的情况安装配置繁琐。通过文件网关的服务可以完美替代 ossfs 和 ossftp。通过创建文件网关,用 户只需要执行简单的挂载(NFS)和映射(Windows SMB)就可以像使用本地文件系统一样使用 OSS。
云存储网关以对象存储 OSS为后 端存储,为云上和云下应用提供业界标准的文件 服务(NFS和 SMB)和块存储服务(iSCSI)。解决问题 1.云存储扩容和迁移:热数据本地缓存,海量 云存储接入本地数据中心。2.多个数据中心快速实现异地文件共享和分 发。3.以标准的存储协议 NFS/SMB/iSCSI兼容客 户老业务,同时支持新的对象存储...
AK防泄漏
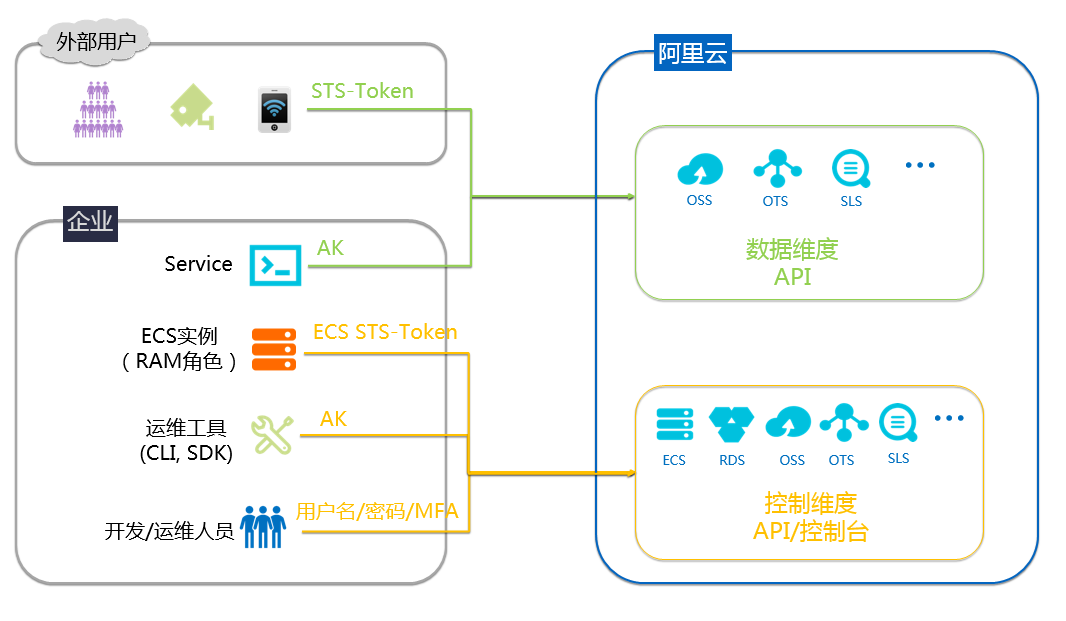
场景描述 用户名密码是开发运维人员访问阿里云控制台 的凭据,AK是软件程序访问阿里云资源的凭据。 如果AK被泄露,那么会造成非常严重的后果, 比如资源被释放导致业务不可用、大量服务器被 创建用来挖矿,等等。采用合适的方式来使用、 保护AK,是每一个云客户都必须关注的问题。 解决问题 1.避免AK被泄露 2.改进已经错误使用AK的方法 产品列表 访问控制RAM 云服务器ECS 操作审计Action Trail 云安全中心
您可以登录阿里云控制台,并前往实名认证页 面(https://account.console.aliyun.com/v2/#/authc/home)查看是否已经完成实名 认证。阿里云账户余额大于 100 元。您可以登录阿里云控制台,并前往账户总览页面(https://expense.console.aliyun.com/#/account/home)查看账户余额。为了便于演示,本文中涉及资源开通时,均...
企业办公安全访问一体化
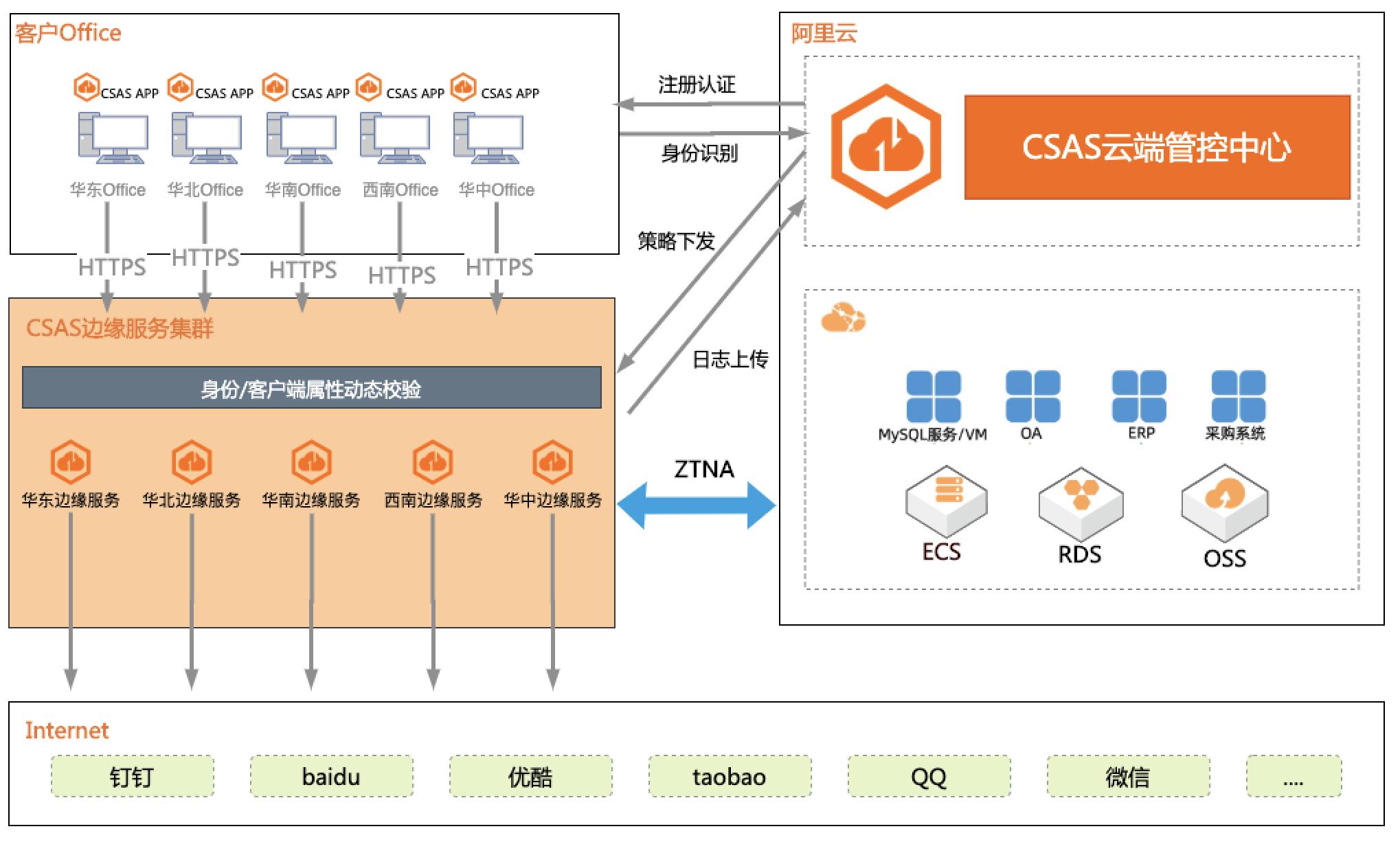
本场景模拟企业办公环境,基于 CSAS 服务构 建企业办公安全一体化方案,将“安全 + 网络” 能力无缝融合,实现了对云下办公终端安全的统 一管理,企业无需在投资复杂且昂贵的传统硬件 安全设备,即可快速构建安全、可靠、低成本的 办公安全防护体系。 1. 企业办公环境访问互联网的安全管理 2. 企业办公环境访问内网服务的安全管理 3. 企业办公网络、安全一体化管理
您可以登录阿里云控制台,并前往实名认证 页面(https://account.console.aliyun.com/v2/#/authc/home)查看是否已经完成 实名认证。 阿里云账户余额大于100元。您可以登录阿里云控制台,并前往账户总览页面(https://expense.console.aliyun.com/#/account/home)查看账户余额。 开通以下服务:ᅳ CSAS:详情请参见...
异地双活场景下的数据双向同步
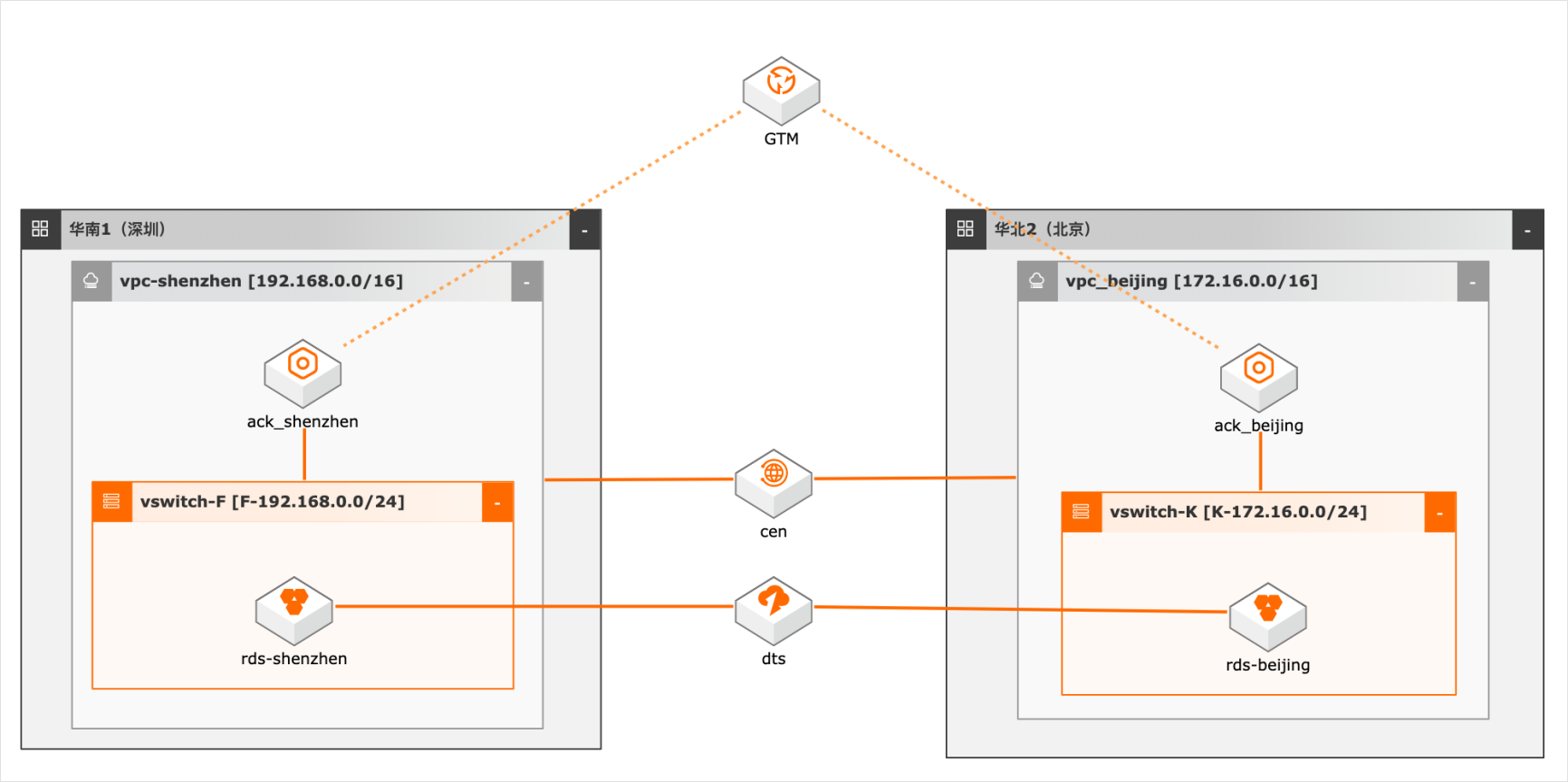
概述 随着客户业务规模的扩大,对系统高可用性要求越来越高,越来越多用户采用异地双活/多活架构,多活架构往往涉及业务侧做单元化改造,本方案仅模拟用户已做单元化改造后的数据双向同步,数据库采用双主架构,本地写本地读,同时又保证双库的数据一致性,为业务增加可用性和灵活性。 适用场景 数据库双向同步 数据库全局ID不冲突 双活架构的数据库建设问题 技术架构 本实践方案基于如下图所示的技术架构和主要流程编写操作步骤: 方案优势 DTS双向同步,采用独立模块避免数据同步占用系统资源。 奇偶ID涉及,避免数据冲突。 DTS多种处理冲突的方式供业务选择。 安全:原生的多租户系统,以项目进行隔离,所有计算任务在安全沙箱中运行。
对系统高可用性要求越 数据库双向同步 来越高,越来越多用户采用异地双活/多活架构,多 数据库全局 ID不冲突 活架构往往涉及业务侧做单元化改造,本方案仅模 双活架构的数据库建设问题 拟用户已做单元化改造后的数据双向同步,数据库 采用双主架构,本地写本地读,同时又保证双库的数 据一致性,为业务增加可用性和灵活性。...
云Clickhouse冷热数据分层存储
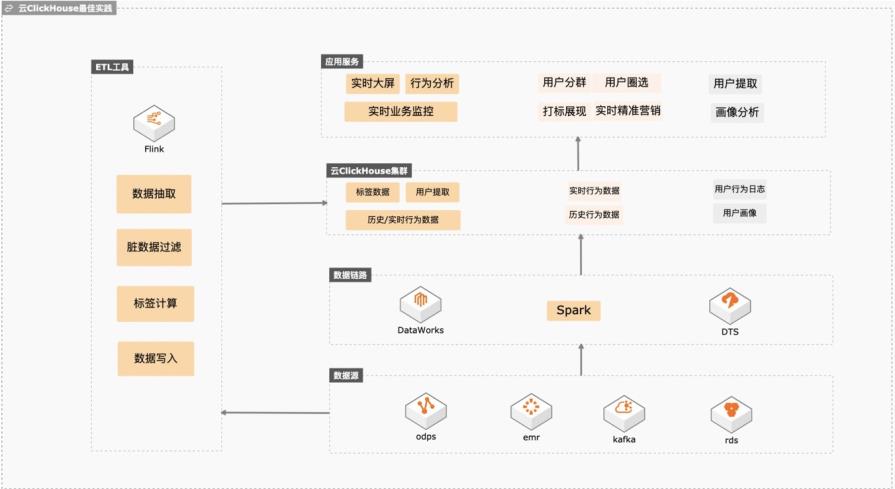
基于云ClickHouse可以给电商、游戏、互联网以及其他行业提供高性能、高稳定性、低维护成本、高性价比的实时数据分析、精准营销、业务运营、业务分析、业务预警、业务营销、数仓加速等场景化方案,本实践会向客户提供数据库低维护成本、数据库链路构建、冷热分层存储、快熟分析等操作实践。 解决问题 1. 维护成本低不用建设维护体系,稳定性高,数据倾斜自动均衡。 2. 完善的数据同步链路,可以平滑将业务库、大数据、日志服务的数据同步到Clickhouse,降低研发成本。 3. 平滑升级版本,业务中断小。 冷热分层后透明读取,帮客户节约整体数据存储成本。
您可以登录阿里云控制台,并前往实名认证 页面(https://account.console.aliyun.com/v2/#/authc/home)查看是否已经完成 实名认证。阿里云账户余额大于 500元。您可以登录阿里云控制台,并前往账户总览页面(https://expense.console.aliyun.com/#/account/home)查看账户余额。付费方式:为了便于演示默认按量付费 有问题...
高性能数据库ECS测试及选型
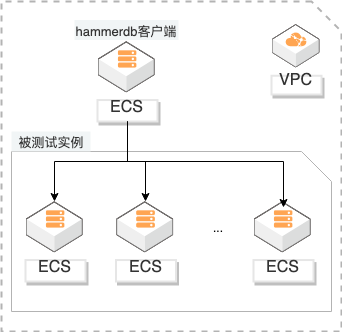
概述 客户自建高性能数据库(如电商大促)在做ECS选型时,对磁盘的IO、网络的吞吐都有很大要求,为了跟接近真实业务场景,使用HammerDB选定真实业务模型测试其TPM。通过对比TPM对比ECS性价比进行选型。同时使用FIO测试磁盘性能作为参考。 适用场景 自建数据库性能测试 磁盘性能测试 ECS选型建议 技术架构 本实践方案基于如下图所示的技术架构和主要流程编写操作步骤: 方案优势 基于标准的TPC-C测试,接近真实业务场景。 提供多规格实例测试,快速选择最优性价比实例。
高性能数据库 ECS测试及选型 最佳实践 场景描述 业务架构 客户自建高性能数据库(如电商大促)在做 ECS选 型时,对磁盘的 IO、网络的吞吐都有很大要求,为 了跟接近真实业务场景,使用 HammerDB选定真 实业务模型测试其 TPM。通过对比 TPM对比 ECS 性价比进行选型。同时使用 FIO测试磁盘性能作为 参考。解决问题 自建数据库...
基于Elasticsearch的订单检索加速最佳实践
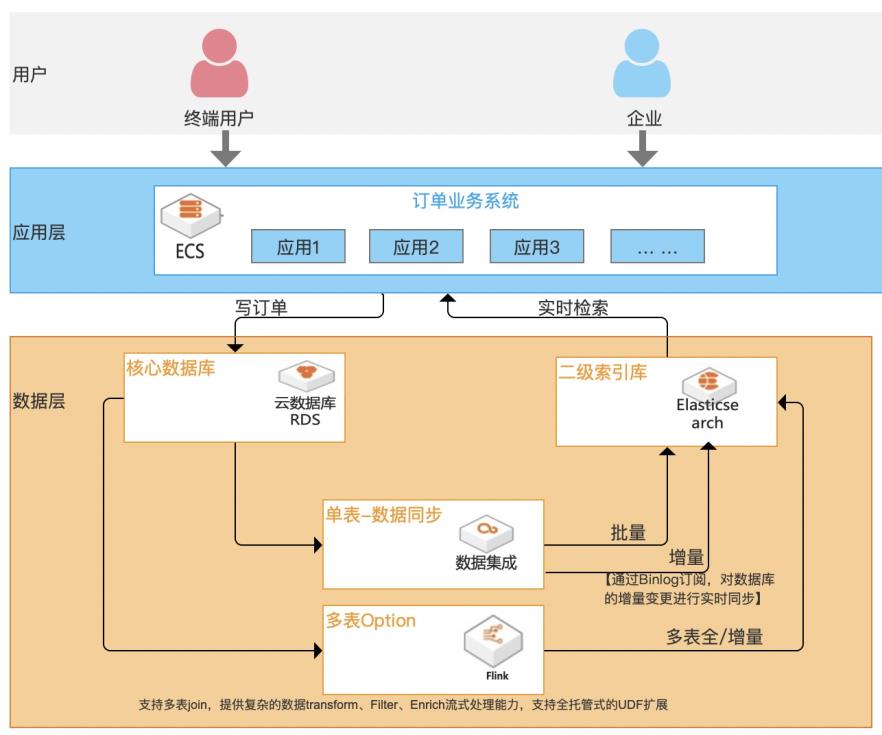
随着企业信息化程度越来越高,核心业务数据存储在传统关系型数据库中不可避免地会遇到一个问题:单表记录不断增多,数据检索速度会变慢,尤其是对中文的模糊查询(建立普通索引完全不起作用)。虽然数据库自身在不断完善,但效果有限且没办法灵活扩展,复杂场景无法应对。 本方案基于阿里云Elasticsearch作为二级索引库,数据集成产品提供Binlog实时订阅,实时解析、增量数据实时更新及二级索引库之间进行数据实时同步,为数据库提供“能力增益”, 不仅能从根本解决主库抗压问题,提升稳定性;同时支持高效率、高性能、高弹性、低成本、多复杂场景的检索加速服务。
本实践基于阿里云 Elasticsearch作为 二级索引库,数据集成产品提供 Binlog实 时订阅,实时解析、增量数据实时更新及二 级索引库之间的数据实时同步,为数据库提 供“能力增益”,不仅能从根本解决主库抗 压问题,提升稳定性;同时支持高效率、高 性能、高弹性、低成本、多复杂场景的检索 加速服务。解决问题 产品列表 1.单...
混合云数据库统一管理
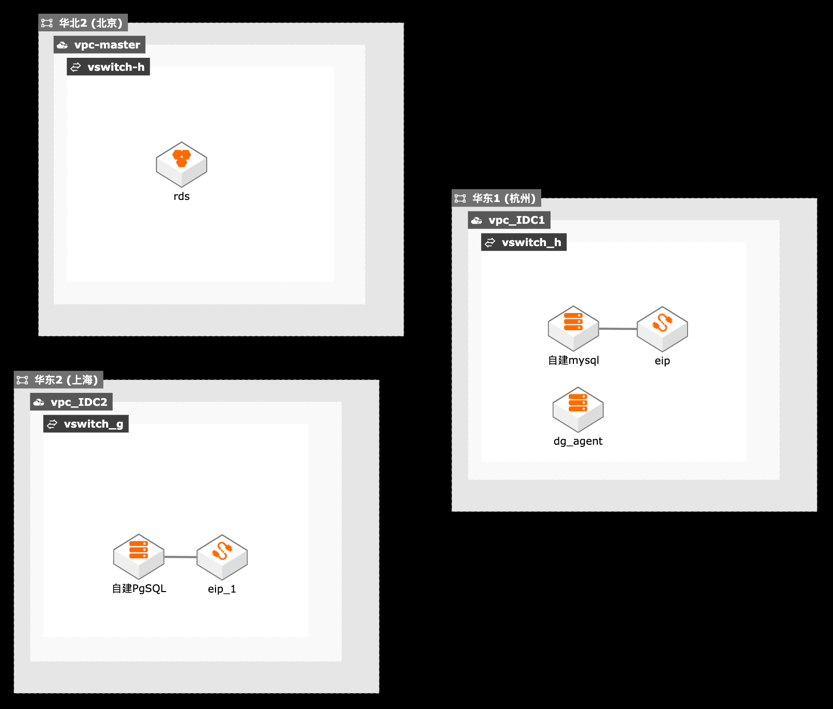
本最佳实践描述在混合云场景下,用户利用数据库网关将IDC自建数据库和云上RDS实例统一管理。通过DMS管理云上RDS实例和IDC自建数据库,并通过DTS实现IDC数据库和云上RDS的数据同步, DBS将数据备份到云上
您可以登录阿里云控制台,并前往实名认证页 面(https://account.console.aliyun.com/v2/#/authc/home)查看是否已经完成实名 认证。阿里云账户余额大于 100 元。您可以登录阿里云控制台,并前往账户总览页面(https://expense.console.aliyun.com/#/account/home)查看账户余额。文档版本:20201224(发布日期)2 混合云...
企业上云workshop
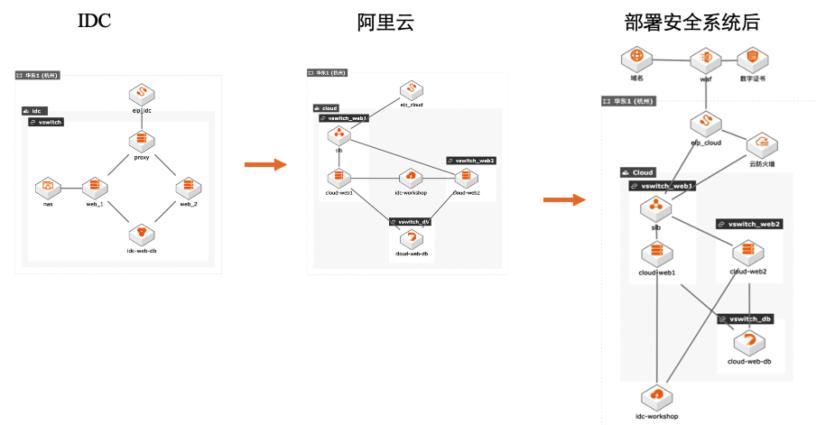
本文模拟了如下场景: 1. 线下 IDC 环境中部署了一个业务系统,业务是利用 wordpress 系统提供网站服务。 2. 本文详细介绍了如何将以上线下系统搬迁到云上, 包括如何在云上构建以上业务系统,如何迁移线下 系统到云上,如何割接。 3. 最后介绍了迁移上云后,如何部署安全系统。 解决问题 IDC 业务系统搬迁上云 云上构建业务系统 部署安全系统
获取数据库实 例地址获取的为准。mysql-h rm-bpxxxxxxxxxxxxxxxxa.mysql.rds.aliyuncs.com -uapproot -p 步骤4 检查数据库 binlog设置。show global variables like"log_bin;如 binlog未开启,需要开启。set global log_bin=on;文档版本:20210617 59 企业上云 workshop-IDC业务迁移上云 数据库迁移 步骤5 检查 binlog格式...
来自:
最佳实践
相关产品:专有网络 VPC,云服务器ECS,云数据库RDS MySQL 版,对象存储 OSS,负载均衡 SLB,弹性公网IP,文件存储NAS,云数据库PolarDB,Web应用防火墙,云防火墙,SSL证书,云速搭
云上IT治理workshop
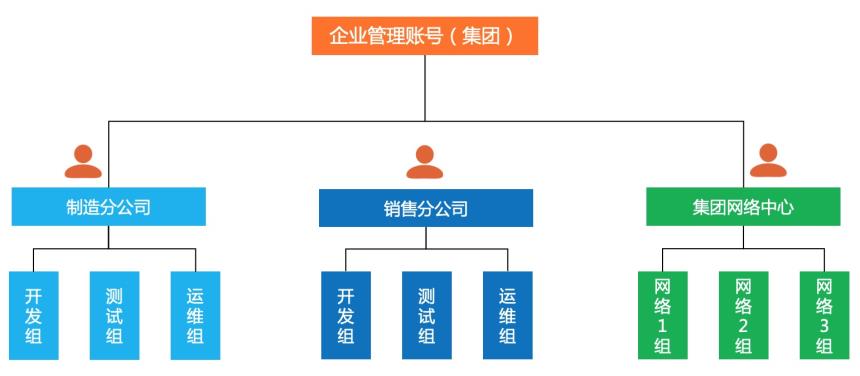
假设您负责假设您负责一家集团公司的IT 基础设施,集团 旗下有多个分公司(如制造分公司和销售分公 司),各分公司有独立的开发、测试以及运维团 队。现在选择阿里云作为合作伙伴,拟达到以下 业务目标: 1. 各个分公司拥有独立的账号,可以购买云资 源,由集团账号统一付费。 2. 集团对各个分公司的账号以及权限拥有管理 权限。 3. 网络资源由独立的平台账号统一规划和创 建,分配给各个公司使用。 4. 集团对分公司账号具有配置管理和操作审计 权限。 5. 各分公司内部独立管理账号权限以及资源。
步骤3 设置共享单元名称为“轿车生产线网络”,将为轿车生产线规划的生产环境和测试环境 的虚拟交换机添加到共享资源。注意:选中虚拟交换机后,要单击添加。文档版本:20210909(发布日期)30 云上 IT治理 Workshop 部署共享服务 步骤4 输入轿车生产线成员账号的 UID,并单击添加,最后单击确定。注意:填写完 UID后,要...
基于转发路由器构建企业级组网
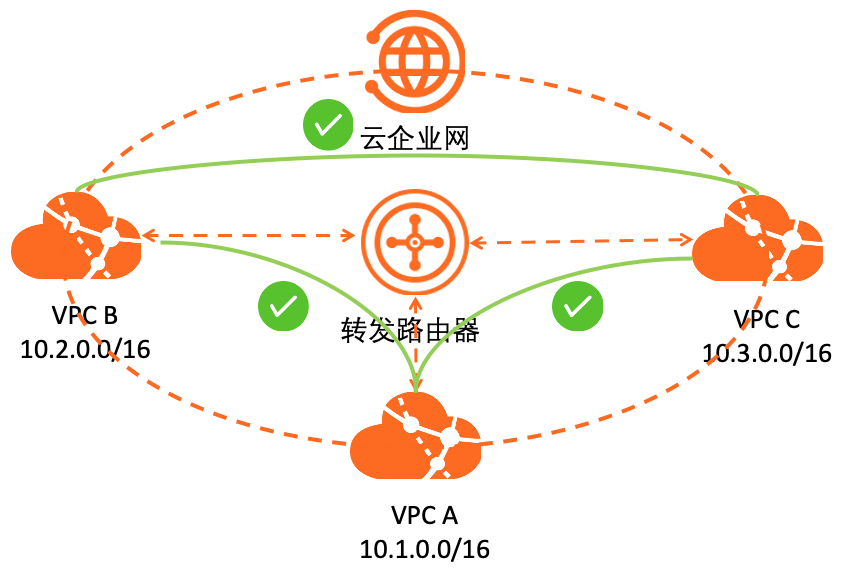
通过云企业网转发路由器 1. 实现灵活的互通、隔离、引流策略 2. VPC 间的内网互访流量经过三方安全设备管控(如Palo Alto) 3. 统一多 VPC 的互联网访问出口,提高业务安全性
您可以登录阿里云控制台,并前往实名认证页 面(https://account.console.aliyun.com/v2/#/authc/home)查看是否已经完成实名 认证。阿里云账户余额大于 100 元。您可以登录阿里云控制台,并前往账户总览页面(https://expense.console.aliyun.com/#/account/home)查看账户余额。新版云企业网 CEN公测工单申请通过 东西向...
基于DDH+MyBase降本合规
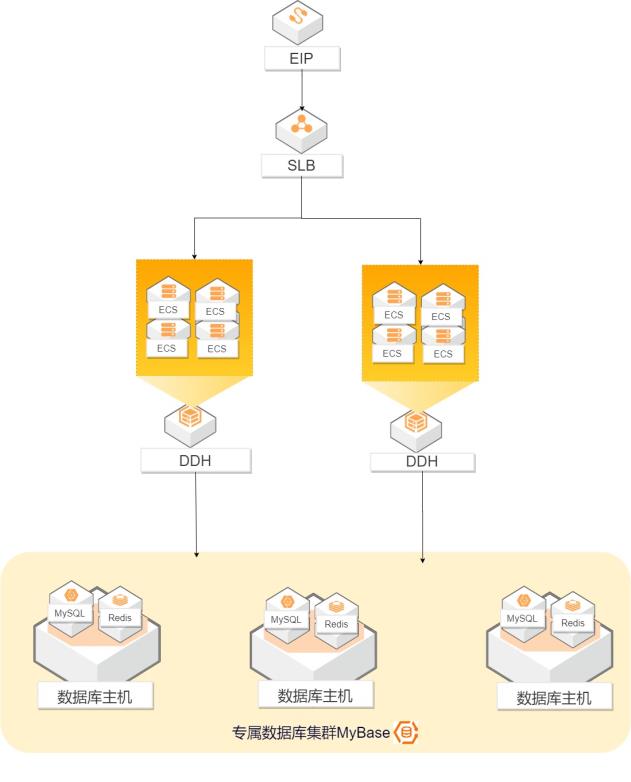
出版、金融、保险等传统行业一方面希望能借助云计算以更好地适应业务发展需求(政策上云),另一方面出于对降低单实例部署成本(CPU 超分超配)以及满足更严格合规和监管要求的考虑,希望能对云上资源有更多的自主控制权(监管合规)。从业务系统架构云上部署的角度,基于专有宿主机DDH 和云数据库专属集群MyBase 的解决方案,可以很好地满足这两方面的需求。 解决问题: 1. 国家政策上云趋势和需求 2. 更严格的云上安全合规要求 3. 对云上资源有更灵活的管控权 4. 有效降低企业上云的整体拥有成本(TCO) 方案优势: 1、单租户隔离 DDH和 MyBase都可以提供宿主机级别物理隔离,可以独占资源,可以开放更多接口 , 同时杜绝 多租户间 干扰 。 2、安全合规:在完备的隔离基础之上,开放更多数据库权限和 OS权限 。 3、资源灵活部署和调度 创建 ECS实例、从共享宿主机迁移 ECS实例至专有宿主机或在专有宿主机之间迁移 ECS实例时,若您不指定专有宿主机,系统将自动帮您选择专有宿主机部署实例。 针对于初始部署数据库实例时,提 供紧凑型和均衡型两种方式将数据库实例分不到不同的主机上。 4、超配 降本 DDH和 MyBase组合的方式可以实现资源自定义 CPU内存 配比以及CPU超分 ,可以降低单 ECS实例以及云数据库实例的部署成本。
内网访问外网 EIP(1M,按带宽计费)业务系统 操作系统 CentOS 7.6 64位-软件程序 WordPress 硬件配置:存储 40G 高效云盘(系统盘)安全组 sg-bptest 初始 root用户密码*网络 BP-VPC(MyBase-VSW)可用区/数量/实例 建议实例名和主机名一致,便于管 H/1/bp-test-1,2 名(主机名)理 自定义镜像 bptest-image-可用区 杭州,可用...
在线教育流量洪峰
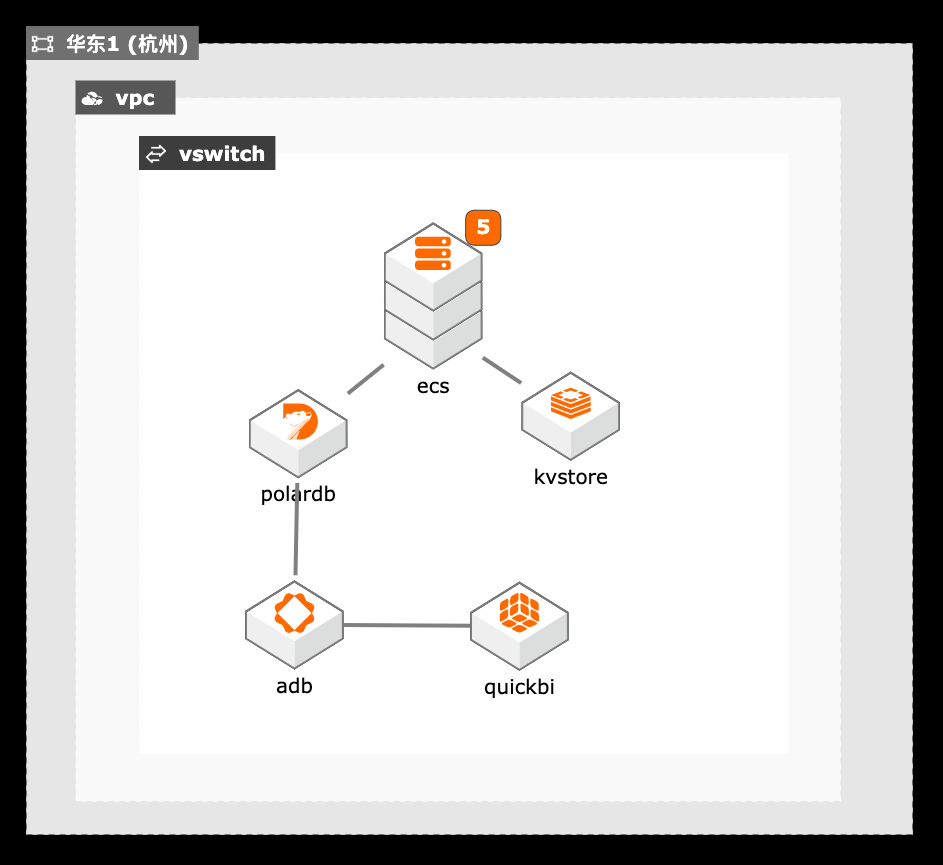
1. 通过Tair缓存的性能增强型解决高并发读的性能问题,通过持久内存型解决大并发写性能及数据可靠性问题。 2. PolarDB作为主数据库保存业务的交易数据,通过弹性能力和并发SQL解决性能瓶颈。 3. ADB+QuickBI提供的数据仓库方案通过分时弹性能力和实时业务展现能力。
在 ECS控制台,将创建的 5台 ECS实例分别改名为 redis-master,redis-slave,redis-client,mysql,mysql-client,具体功能请参考下表:ECS名 安装系统 功能 Redis-master 安装 Redis 5 作为 Redis master节点 Redis-slave 安装 Redis 5 作为 Redis slave节点 Redis-client 安装 Redis 6、YCSB 作为 Redis 压测客户端,包括 ...
SpringCloud应用托管到ACK服务
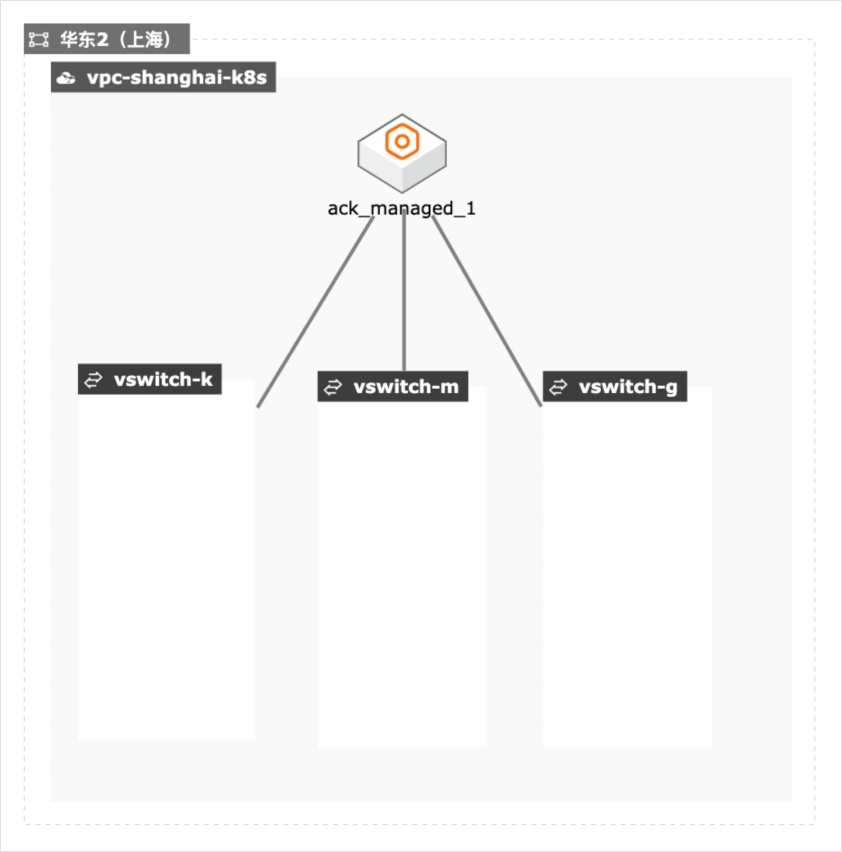
场景描述 本实践适用于将SpringCloud应用托管到 ACK服务的场景中,创建容器服务ACK后, 利用Helm一键部署SpringCloud应用,将 SpringCloud应用托管到容器服务ACK。 解决问题 1.将SpringCloud应用托管到容器服务 ACK 产品列表 容器服务ACK 云服务器ECS
说明:您可以登录阿里云控制台,并前往实人认证页面(https://account.console.aliyun.com/v2/#/authc/home),查看是否已经完成实名 认证。阿里云账户余额大于 100元。说明:您可以登录阿里云控制台,并前往账户总览页面(https://expense.console.aliyun.com/#/account/home),查看当前账户余额。阿里云账号下已开通以下...
Hyper-V on 弹性裸金属最佳实践
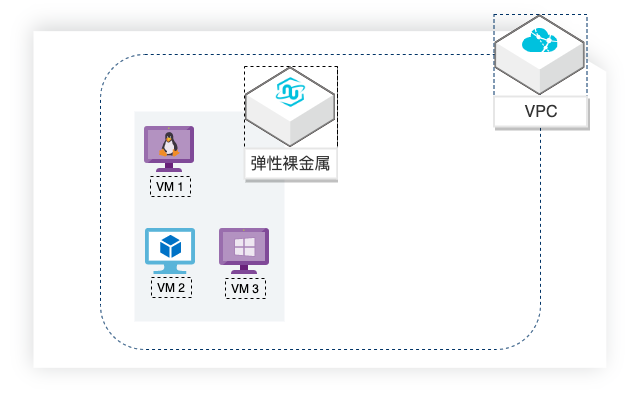
场景描述 本方案适用于基于弹性裸金属服务器(神龙)自 建Microsoft Hyper-V环境的场景。 解决问题 l使用神龙自建+Microsoft Hyper-V虚拟 化环境环境。 l创建LinuxHyper-VVM。 lHyper-VVM访问外部网络。 l外部网络访问Hyper-VVM上的服务。 产品列表 l神龙GPU云服务器(ecs.ebmg5s) l专有网络VPC
本文示例虚拟化系统网络结构:VM1 EBM实例 Internal-switch 10.1.1.0/24 NAT网关 10.1.1.1 网卡 192.168.0.0/16 公网 IP 文档版本:20220512 1 Hyper-V on弹性裸金属 前置条件 前置条件 在进行本文操作之前,您需要完成以下准备工作:拥有阿里云实名认证账号。您可以登录阿里云控制台,并前往实名认证...
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
说明:模拟的日志文件如下 {"clientTime":1596102120822,"consumeTime":1596214681374,"env":"production","l evel":"info","product":"XXXX","registerTime":1596153578322,"serverTime":1596214 681284} 步骤3 安装 java1.8 1.Flume需要 java1.8运行环境,所以先要安装 java1.8。在 centos上可以通过 yum 快捷的安装 java...
自建K8S迁移镜像、应用至阿里云ACK最佳实践

云原生技术K8S以其易管控,自动化操作,自修复等特点充分满足了企业的需求,越来越多的企业都加入容器化这个队伍中。但随着技术的更新迭代,自建的K8S相关的容器镜像服务、集群管理、稳定性保障也让企业IT人员感觉到压力,所以上云成了一些企业的选择,将底层的IAAS基础设施和K8S的基础PASS能力交给阿里云来管理,企业本身抽出更多精力聚焦业务的创新。针对以上需求通过使用image-syncer、velero来介绍如何平滑、便捷的迁移自建的K8S镜像和应用至阿里云容器镜像服务和ACK。 针对以上需求场景通过使用image-syncer、velero来介绍如何平滑、便捷的迁移自建的K8S镜像和应用至阿里云容器镜像服务和ACK;本文通过使用河源的ECS自建K8S集群和Harbor镜像仓库来模拟IDC环境
②资源过滤器:过滤出要同步的资源,包括资源的名称(由项目名+仓库名组成,如 示例中 test-ack/nginx,支持通配符,例如要同步整个项目中镜像,可以填写 test-ack/*)、tag、标签、类型等;③目的 Registry:下拉框中选择步骤 1中创建的远端仓库(toali);④目的 Namspace:acr中对应的 namespace。触发复制迁移 稍等几...
基于Flink+ClickHouse构建实时游戏数据分析
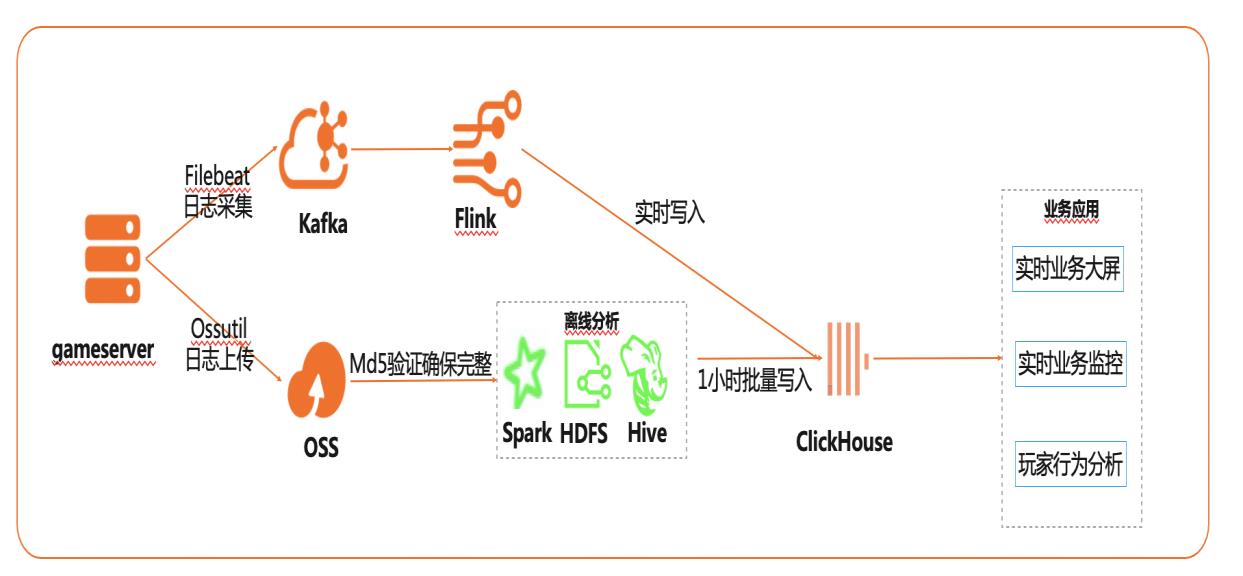
在互联网、游戏行业中,常常需要对用户行为日志进行分析,通过数据挖掘,来更好地支持业务运营,比如用户轨迹,热力图,登录行为分析,实时业务大屏等。当业务数据量达到千亿规模时,常常导致分析不实时,平均响应时间长达10分钟,影响业务的正常运营和发展。 本实践介绍如何快速收集海量用户行为数据,实现秒级响应的实时用户行为分析,并通过实时流计算Flink/Blink、云数据库ClickHouse等技术进行深入挖掘和分析,得到用户特征和画像,实现个性化系统推荐服务。 通过云数据库ClickHouse替换原有Presto数仓,对比开源Presto性能提升20倍。 利用云数据库ClickHouse极致分析性能,千亿级数据分析从10分钟缩短到30秒。 云数据库ClickHouse批量写入效率高,支持业务高峰每小时230亿的用户数据写入。 云数据库ClickHouse开箱即用,免运维,全球多Region部署,快速支持新游戏开服。 Flink+ClickHouse+QuickBI
基于 Flink+ClickHouse构建实时游戏数据分析 最佳实践 业务架构 背景描述 在互联网、游戏行业中,常常需要对用户行 为日志进行分析,通过数据挖掘,来更好地 支持业务运营,比如用户轨迹,热力图,登 录行为分析,实时业务大屏等。当业务数据 量达到千亿规模时,常常导致分析不实时,平均响应时间长达 10分钟,影响业务的正...
- 产品推荐
- 这些文档可能帮助您