云上成本优化workshop
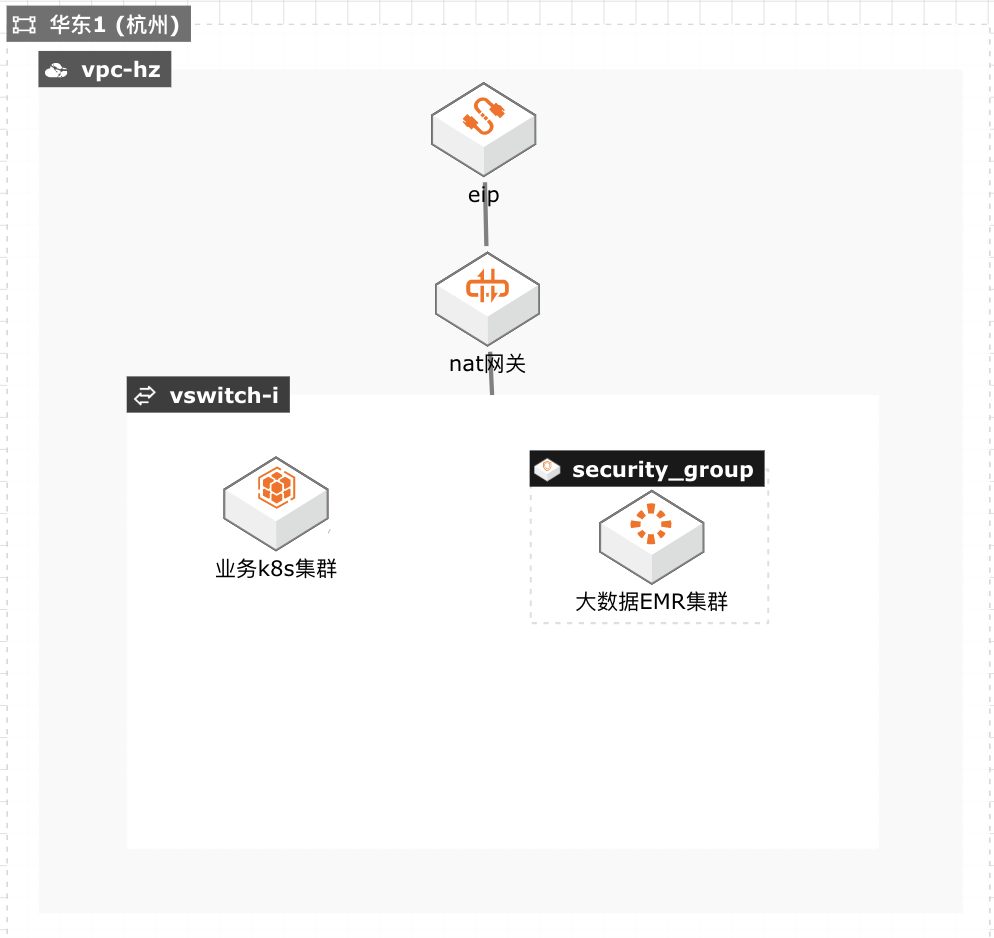
某金融科技公司,它主要提供信贷,理财,电商等 服务,目前已经拥有千万级注册用户。该公司在将 在线业务系统和大数据业务从自建 IDC 机房迁移 到阿里云后,今年大数据集群经历过多次因为资 源不足导致弹性扩容失败的故障,运维负责人非 常苦恼。由于该公司从事互联网金融的借贷业务, 白天的催收非常依赖晚上大数据计算的结果,若 因为资源不足导致计算结果失败则意味着白天催 收业务员无事可做,会对公司业务造成严重影响。 后来,通过阿里云解决方案架构师建议的方案,将 大数据集群迁移到资源较充足的可用区以及配置 弹性伸缩多规格 ECS 选型增加交付成功率等方 法,目前已阶段性的解决因资源不足导致弹性扩 容失败的问题,但该方案在 Spot 计算资源不足 时,启用大量按量收费算力,带来了较高的成本, 并且抢占式实例和按量付费实例都不保证资源 100%交付,还是存在交付失败的可能性,特别是 在双 11 期间由于其他客户的资源需求上升带来 的资源挤兑客观上存在,就进一步增加了弹性扩 容失败的风险,从而影响业务正常运行。
业务应用 客户的业务系统,在微服务化改造之后,将其大部分业务系统以服务的形式,跑在本 地 IDC的 K8S集群上面,但是由于本地 IDC单一,存在扩展性差,容器容灾难,K8S 管理复杂等问题。在本案例里,采用 serverless版本的 Kubernetes来模拟业务应用的运行平台,这种 类型的托管服务,无需创建和管理 K8s里面的 Master和 ...
来自:
最佳实践
相关产品:云服务器ECS,负载均衡 SLB,弹性公网IP,容器服务 ACK,日志服务(SLS),NAT网关,函数计算,E-MapReduce,云数据库PolarDB,弹性容器实例 ECI,存储容量单位包,预留实例券,Hologres
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。
基于集群学 专有网络VPC 习PAI封装出多种贴近业务场景的算法服务,满足 交换机vswitch 更多的业务需求。 数据糊DLF 3.MaxCompute云原生的弹性资源和EMR集群资源 云原生大数据计算服务MaxCompute 形成互补,两套体系之间进行资源的削峰填谷,不 大数据开发治理平台DataWorks 仅减少作业排队,且降低整体成本。...
互联网电商行业离线大数据分析

电商网站销售数据通过大数据分析后将业务指标数据在大屏幕上展示,如销售指标、客户指标、销售排名、订单地区分布等。大屏上销售数据可视化动态展示,效果震撼,触控大屏支持用户自助查询数据,极大地增强数据的可读性。
magento 自定义名称:业务出 基于模版新建 弹性公网EIP 口EIP 默认配置 自动绑定到ECS 默认公共云版本 基于模版新建 DataV 默认配置 新用户可以选择使用互联网电商行业离线大数据分析 搭建电商网站Demo 版 API网关 数据发布网关 默认配置 基于模版新建 付费基础版 基于模版新建 DataWorks独享资 源,2个 独享数据服务资源:...
计算机软件著作权登记
全新支持APP/小程序全程在线电子化登记,无纸化线上极速办理,助力APP便捷上架,最快3个工作日拿证。在线填写,系统纠错,全流程可视化,申请进度实时掌控,阿里云开启知识产权一站式专业服务。
阿里云计算机软件著作权登记,全新支持APP/小程序全程在线电子化登记,无纸化线上极速办理,助力APP便捷上架,最快3个工作日拿证。在线填写,系统纠错,全流程可视化,申请进度实时掌控,阿里云开启知识产权一站式专业服务。
服务优化新策略:AI大模型助力客户对话分析
在数字化时代,企业面临着海量客户对话数据的处理挑战,迫切需要从这些数据中提取有价值的洞察以提升服务质量和客户体验。本方案旨在介绍如何部署AI大模型实现对客户对话的自动化分析,精准识别客户意图、评估服务互动质量,实现数据驱动决策。
在数字化时代,企业面临着海量客户对话数据的处理挑战,迫切需要从这些数据中提取有价值的洞察以提升服务质量和客户体验。本方案旨在介绍如何部署AI大模型实现对客户对话的自动化分析,精准识别客户意图、评估服务互动质量,实现数据驱动决策。服务优化新策略:AI大模型助力客户对话分析 在数字化时代,企业面临着海量客户...
来自:
技术解决方案
大模型服务平台百炼
阿里云百炼是企业级大模型开发平台,助力企业轻松打造最优落地效果的AI应用,深度聚焦于人工智能与机器学习的前沿技术,它不仅提供了丰富的多模态模型调用服务,还简化了在线模型训练与部署流程,让开发者能够轻松驾驭大模型,加速创新应用的开发,推动AI技术在各行业的广泛应用。
产品解决方案文档与社区权益中心定价云市场合作伙伴支持与服务了解阿里云AI 助理备案控制台大模型服务平台百炼产品概述产品功能选型与定价入门与试用技术解决方案相关资源开发者活动控制台文档联系我们立即购买阿里云百炼 通义大模型企业级服务平台,助力企业轻松打造最优落地效果的AI应用立即开通立即咨询开放兼容实现多端...
来自:
云产品
1分钟部署幻兽帕鲁游戏服务器
近期幻兽帕鲁、雾锁王国等游戏备受追捧,其对计算资源与带宽有较高的要求。为确保游戏过程的流畅度与优质体验,玩家需要配备性能好、稳定可靠的游戏服务器。本方案为广大的玩家群体提供专属联机服务器,一键购买部署,轻松开启游戏。
云服务器 ECS 计算巢服务 专有网络VPC 应用场景 技术解决方案的广泛应用场景 幻兽帕鲁游戏 玩家可以在广阔的世界中收集神奇的生物“帕鲁”,派他们进行战斗、建造、做农活,工业生产。可以与好友联机游戏,在游戏里分工合作,共同建设属于自己的家园,一起组队冒险。雾锁王国游戏 游戏背景设定在一个基于体素构筑的辽阔大陆...
来自:
技术解决方案
部署Nginx并通过Ingress暴露和监控服务
在阿里云容器服务(后简称ACK)集群中通过YAML文件快速部署一个Nginx应用并通过Nginx Ingress暴露和监控服务,结合使用ACK、日志服务、专有网络搭建业务部署运维方案,具有集群快速创建、应用高效部署和业务运维简单的优势,适用于新兴互联网行业,转型的传统金融、物流等多行业。
在阿里云容器服务(后简称ACK)集群中通过YAML文件快速部署一个Nginx应用并通过Nginx Ingress暴露和监控服务,结合使用ACK、日志服务、专有网络搭建业务部署运维方案,具有集群快速创建、应用高效部署和业务运维简单的优势,适用于新兴互联网行业,转型的传统金融、物流等多行业。部署Nginx并通过Ingress暴露和监控服务 在...
来自:
技术解决方案
PAI部署多形态的Stable Diffusion WebUI服务
PAI Stable Diffusion WebUI 解决方案为企业提供云上快速部署定制化的文生图应用。提供了方便、高效的模型部署产品,并支持根据实际需求,配置不同的服务版本及服务参数。具有分钟级部署上线,方便快捷、开箱即用,多版本部署方案,参数可定制化调整的优势。
提供了方便、高效的模型部署产品,并支持根据实际需求,配置不同的服务版本及服务参数。具有分钟级部署上线,方便快捷、开箱即用,多版本部署方案,参数可定制化调整的优势。PAI部署多形态的Stable Diffusion WebUI服务 PAI Stable Diffusion WebUI 解决方案为企业提供云上快速部署定制化的文生图应用。提供了方便、高效的...
来自:
技术解决方案
- 产品推荐
- 这些文档可能帮助您