- 相关产品:
- 遗传分析解读解决方案 智慧交通解决方案 智能语音点餐机解决方案
企业级云灾备与数据管理
云备份 Cloud Backup 为企业数据安全提供了全方位的云灾备、冷热数据统一管理能力,全面覆盖公共云、混合云以及本地 IDC 生产环境,帮助用户减少因自然灾害、系统故障、运维事故、勒索病毒等造成的数据丢失而带来的业务影响。
云备份 Cloud Backup 为企业数据安全提供了全方位的云灾备、冷热数据统一管理能力,全面覆盖公共云、混合云以及本地 IDC 生产环境,帮助用户减少因自然灾害、系统故障、运维事故、勒索病毒等造成的数据丢失而带来的业务影响。企业级云灾备与数据管理 云备份 Cloud Backup 为企业数据安全提供了全方位的云灾备、冷热数据统一...
来自:
技术解决方案
多媒体数据存储与分发
多媒体数据存储与分发解决方案融合对象存储 OSS、内容分发 CDN 、智能媒体管理 IMM 等产品能力,解决客户多媒体数据存储、处理、加速、分发等业务问题,进而实现低成本、高稳定性的业务目标。本技术解决方案以搭建一个多媒体数据存储与分发服务为例,搭建一个多媒体数据存储与分发服务。
在线部署 适用客户 需要满足多终端、高清晰度内容分发需求 需要同时满足直播视频合规存储和高并发访问需求 方案优势 为什么选择多媒体数据存储与分发解决方案 高可靠、高可用设计 采用多重冗余架构设计,将每个对象冗余存放在多个设备上,用高可用架构设计,消除单点故障,服务可用性最高可达99.995%。安全、智能的存储系统...
来自:
技术解决方案
10 分钟构建 AI 客服并应用到网站、钉钉或微信中
为了提升用户体验和增强业务竞争力,越来越多的企业会构建 AI 助手,以便全天候(7x24)回应客户咨询。在阿里云上,只需 10 分钟即可构建一个 AI 助手,并发布到网站、钉钉或微信公众号中。
在阿里云上,只需 10 分钟即可构建一个 AI 助手,并发布到网站、钉钉或微信公众号中。10 分钟构建 AI 客服并应用到网站、钉钉或微信中 为了提升用户体验和增强业务竞争力,越来越多的企业会构建 AI 助手,以便全天候(7x24)回应客户咨询。在阿里云上,只需 10 分钟即可构建一个 AI 助手,并发布到网站、钉钉或微信公众号中...
来自:
技术解决方案
网站文本内容安全检测
社交媒体平台、电子商务网站、新闻门户和博客等平台都会有大量的用户生成内容(UGC),可能会存在色情、暴力、惊悚、敏感、禁限、辱骂等风险内容。本方案通过内容安全API的形式,提供直播场景的文本检测能力。响应时间短,支持类型多,可从频次、上下文、内容重复等多维度判断风险行为。
社交媒体平台、电子商务网站、新闻门户和博客等平台都会有大量的用户生成内容(UGC),可能会存在色情、暴力、惊悚、敏感、禁限、辱骂等风险内容。本方案通过内容安全API的形式,提供直播场景的文本检测能力。响应时间短,支持类型多,可从频次、上下文、内容重复等多维度判断风险行为。网站文本内容安全检测 社交媒体平台...
来自:
技术解决方案
从海量到价值,泛时序数据一站式分析与洞察
泛时序数据广泛存在于车联网、工业物联网、金融交易、股票分析等业务场景。随着业务增长带来的数据量激增,如何高效地获取和分析这些数据成为业务洞察和决策的关键挑战,Lindorm作为阿里云自研的云原生多模数据库,具备低成本存储、弹性高可用的能力,提供一站式的分析与洞察。
在线部署 适用客户 有车联网、金融、日志等海量数据处理场景 寻求“宽表+搜索+分析”大数据组合方案的一站式替代 方案优势 为什么选择 Lindorm 使用Lindorm对泛时序数据进行一站式的处理分析,不仅在开发效率和成本效益上超越传统自建方式,更在性能优化和运维便捷性上提供卓越表现。预处理效率高 支持接收实时数据,进行流...
来自:
技术解决方案
SLS数据入湖Kafka最佳实践
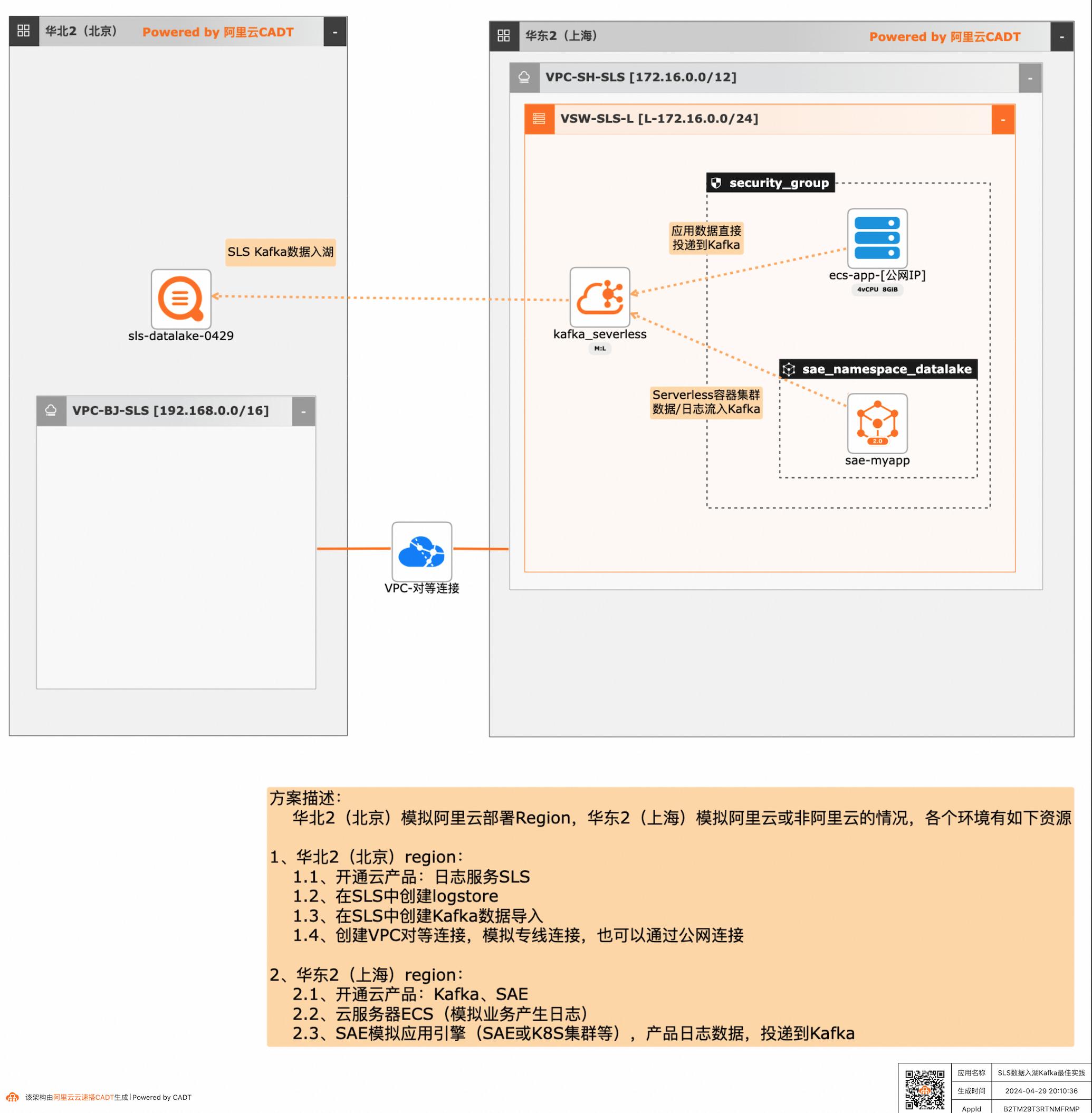
应用和数据分散在多云或混合云,在面对多云/混合云这样大的趋势下,数据无法进行统一的聚合、分析处理和导出等,本方案给出了在多云/混合云场景下,构建通过标准的Kafka协议和托管服务,SLS可以连接Kafka数据入湖导入,然后进行统一的海量数据的集中存储、智能转储、聚合分析查询等。
SLS 数据入湖 Kafka 最佳实践 业务架构 场景描述 应用和数据分散在多云或混合云,在面对多云/混合云这样大的趋势下,数据无法进行统一的 聚合、分析处理和导出等,本方案给出了在多 云/混合云场景下,构建通过标准的Kafka协议 和托管服务,SLS可以连接Kafka数据入湖导 入,然后进行统一的海量数据的集中存储、智 能转储、...
通过ES兼容接口方式使用Kibana访问SLS数据
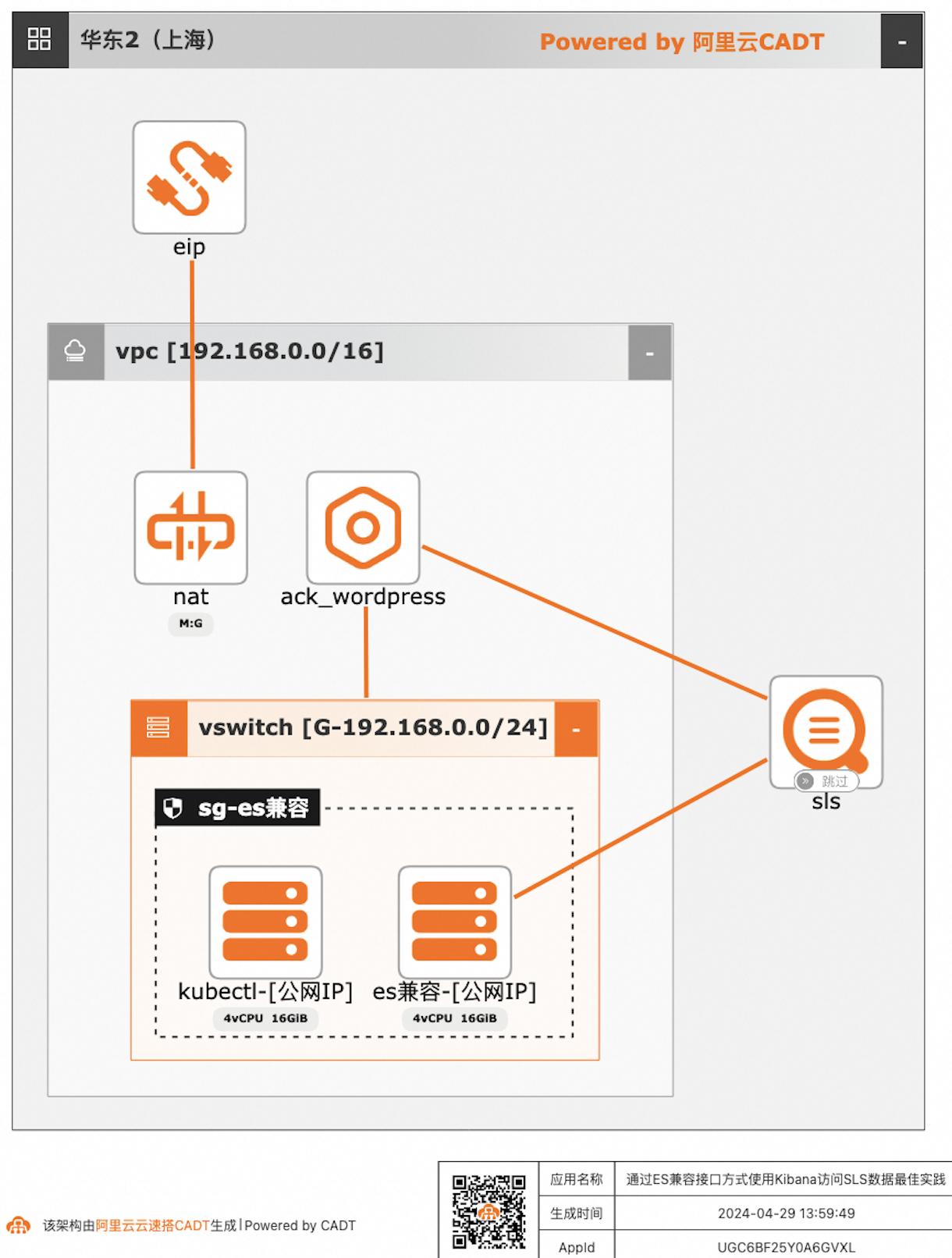
自建ELK日志系统的客户迁移到阿里云日志服务SLS后,对SLS查询分析语法不太熟悉的客户,可以继续沿用原有的查询分析习惯,在不改变使用方式习惯的情况下,通过Elasticsearch兼容接口的方式使用Kibana访问SLS。
步骤6 点击复制公网访问的集群凭证,并粘贴至$HOME/.kube路径下的config文件中 查找$HOME目录在哪的命令:echo$HOME 如果$HOME目录下没有.kube路径和config文件需要手动创建 创建路径:mkdir.kube 创建文件:vim.kub/config 然后输入复制的配置信息并保存:步骤7 验证集群连通性 kubectlgetnamespace 文档版本:20240418 21...
电商网站数据埋点及分析
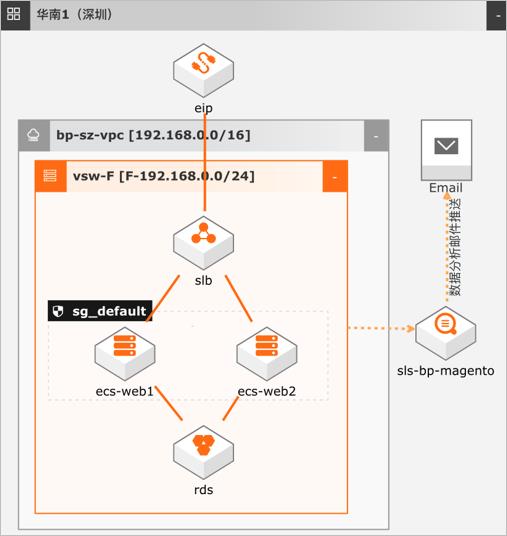
场景描述 数据埋点是数据产品经理、数据运营以及数据分 析师,基于业务需求(例如:CPC点击付费广 告中统计每一个广告位的点击次数),产品需求 (例如:推荐系统中推荐商品的曝光次数以及点 击的人数)对用户行为的每一个事件对应的位置 进行开发埋点,并通过SDK上报埋点的数据结 果,记录数据汇总后进行分析,推动产品优化或 指导运营。 解决问题 1.电商网站广告位效果统计分析 2.电网网站推荐商品曝光、点击、购买等行为统 计分析 3.电商网站用户分布分析 4.电商网站页面热点图分析等 产品列表 日志服务SLS Dataworks 云服务器ECS 云数据库RDS版 负载均衡SLB 专有网络VPC
文档版本:20220127 XXVI 电商网站数据埋点及分析 电商网站数据分析 步骤3 设置通知类型(可选邮件和钉钉机器人,本例使用邮件),输入收件人的主题名称提交。步骤4 提交成功后,每天 11点会收到已订阅数据图表。邮件示例如下:文档版本:20220127 XXVII 电商网站数据埋点及分析 附加说明 附加说明 如果您已经完成了本实践...
互联网电商行业离线大数据分析

电商网站销售数据通过大数据分析后将业务指标数据在大屏幕上展示,如销售指标、客户指标、销售排名、订单地区分布等。大屏上销售数据可视化动态展示,效果震撼,触控大屏支持用户自助查询数据,极大地增强数据的可读性。
一键释放云资源.64互联网电商行业离线大数据分析 最佳实践概述 最佳实践概述 概述 本实践介绍了使用阿里云MaxCompute、数据库(RDS)、DataWorks等产品实现电商网 站离线数据分析,分析后的业务指标数据实时在大屏展示。本实践以完整的实践Demo为例,提供从电商网站搭建,数据从RDS同步到MaxCompute、再到DataWorks进行数据...
电商网站业务安全
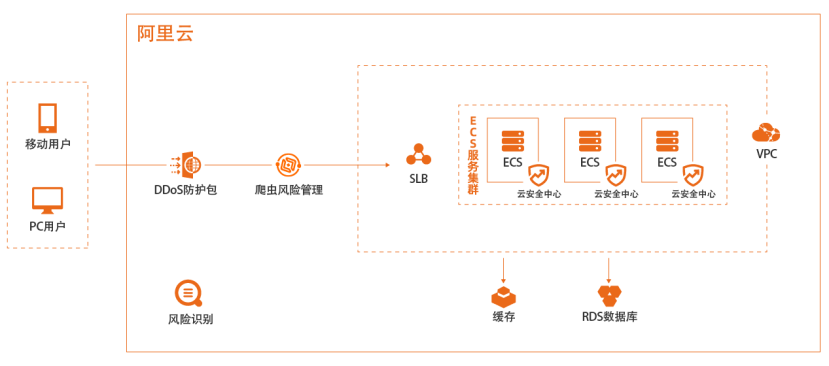
场景描述 业务运营活动是电商行业开展业务必不可少的 手段,但大流量带来的系统可用性、优惠券带来 的“薅羊毛”等问题屡见不鲜,都会影响到运营 效果、甚至出现负面影响。阿里云基于集团电商 业务多年的运营经验,为云上客户提供完整的电 商网站运营期间的防护方案。 解决问题 1.保障业务运维活动系统稳定运行 2.防止“薅羊毛” 3.运营优惠给到真实的客户 产品列表 爬虫风险管理 风险识别 DDoS防护包
文档版本:20210806 17 企业上云实践 电商网站业务安全最佳实践|搭建电商网站 DEMO 步骤2 在 Default Category(ID:2)页面,将 Category Name设置为 bookCate,并单击 Save。创建 Sources 步骤1 在左侧导航栏选择 STORES>All Stores。文档版本:20210806 18 企业上云实践 电商网站业务安全最佳实践|搭建电商网站 DEMO 步骤2 ...
数据湖-在线学习场景数据分析

场景描述 本场景以在线教育中一个答题闯关类的应用为 例,使用WebServer来模拟演示这类日志数据 的分析处理。通过Nginx和Pythonflask搭建 WebServer,模拟应用中的关键页面,比如登 录、课程内容等,之后构造若干用户使用的模拟 日志数据,投递到数据湖进行分析后获取应用 PV、UV、课程内容访问排行、平均得分等等。 解决问题 基于数据湖(EMR+OSS)搭建大数据平台。 EMR和OSS使用和配置。 数据统一存储到OSS。 产品列表 E-MapReduce 对象存储OSS 云服务器ECS 访问控制RAM 专有网络VPC
通过Nginx和Pythonflask搭建WebServer,模拟应用中的关 键页面,比如登录、课程内容等,之后构造若干用户使用的模拟日志数据,投递到数 据湖进行分析后获取应用PV、UV、课程内容访问排行、平均得分等等。方案优势 支持超过10亿条元数据规模的数据管理,同时支持高可靠和高可用。 支持元数据实时备份和重建集群快速恢复...
Databricks数据洞察
阿里云Databricks数据洞察是基于Apache Spark的全托管数据分析平台, 内核采用更高效、稳定的商业版Databricks Runtime和Delta Lake。可满足数据分析师、数据工程师和数据科学家在大数据场景下对数据湖分析、实时数仓、离线数仓、BI数据分析、AI机器学习等需求
Databricks 数据洞察.Databricks数据洞察是基于Apache Spark的全托管数据分析平台,内核采用更高效稳定的商业版Databricks Runtime和Delta Lake,满足用户对数据湖分析、实时数仓、离线数仓、BI数据分析、AI机器学习等场景需求。因产品服务策略调整,本产品将于2023年10月23日停止全面支持,并将于2024年4月23日停止服务....
来自:
云产品
Spark on ECI大数据分析

场景描述 方案优势 1.计算引擎弹性扩缩容,兼顾资源弹性与计 算资源成本优化。 2.计算与存储分离架构,结合阿里云原生云 存储产品,海量数据湖优势。 3.Kubernetes原生的调度性能优势,提升在 大规模分析作业时的分析性能优势分。 4.集群资源隔离和按需分配。 解决问题 1.计算资源弹性能力不足,计算资源成本管 控能力欠缺. 2.集群资源调度能力和隔离能力不足。 3.计算与存储无法分离,大数据量分析时出 现数据存储资源瓶颈。 4.Spark submit方式提交分析作业参数支持 有限等缺点。 产品列表 容器服务Kubernetes版(ACK) 弹性容器实例(ECI) 文件存储HDFS 对象存储OSS 专有网络VPC 容器镜像服务ACR
Spark on Kubernetes解决方案的用户 对 Spark大数据分析平台计算资源成本控制考虑的用户 需要有灵活可扩展计算平台资源弹性及管控的用户 名词解释 文件存储 HDFS:阿里云文件存储 HDFS是面向阿里云 ECS实例及容器服务等计 算资源的文件存储服务,允许用户像在 Hadoop分布式文件系统中管理和访问数 据,无需对数据分析应用做...
云Clickhouse冷热数据分层存储
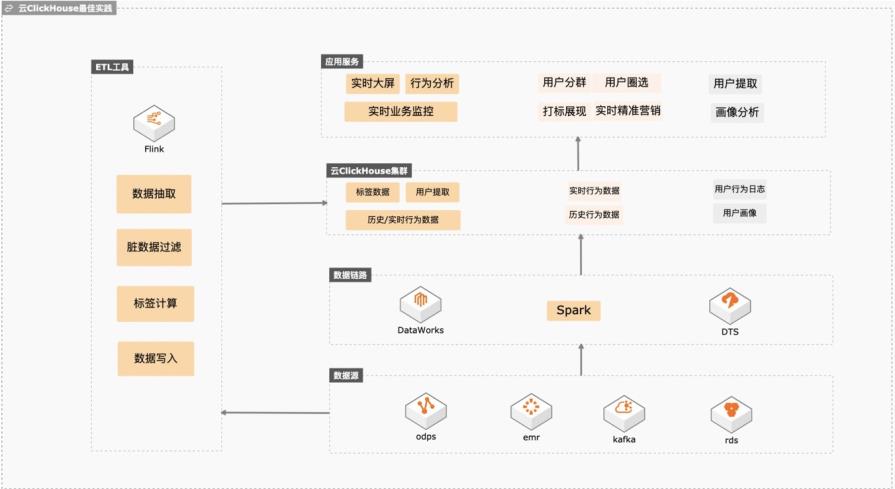
基于云ClickHouse可以给电商、游戏、互联网以及其他行业提供高性能、高稳定性、低维护成本、高性价比的实时数据分析、精准营销、业务运营、业务分析、业务预警、业务营销、数仓加速等场景化方案,本实践会向客户提供数据库低维护成本、数据库链路构建、冷热分层存储、快熟分析等操作实践。 解决问题 1. 维护成本低不用建设维护体系,稳定性高,数据倾斜自动均衡。 2. 完善的数据同步链路,可以平滑将业务库、大数据、日志服务的数据同步到Clickhouse,降低研发成本。 3. 平滑升级版本,业务中断小。 冷热分层后透明读取,帮客户节约整体数据存储成本。
云数据库 ClickHouse 冷热数据分层存储是一种更具性价比的单实例多类型并存的数 据存储方式,提供热数据存储和冷数据存储两种方式,以及不同数据存储介质之间的 转存策略。热数据指的是实时性查询要求高、访问频次较高的数据,采用 ESSD或高 效云盘存储,满足高性能访问的需求。冷数据指的是查询频度相对较低、访问频次较 ...
云原生数据仓库AnalyticDB MySQL数据仓库
阿里云云原生数据仓库AnalyticDB MySQL版(简称AnalyticDB)是融合数据库、大数据技术于一体的云原生企业级数据仓库平台。云原生数据仓库AnalyticDB MySQL版支持数据实时写入和同步更新、实时计算和实时服务,可用于构建企业级报表系统、数据仓库和数据服务引擎。
冷热数据设置.可以随时修改表和分区的冷热属性,系统自动进行数据搬迁.冷热数据切换.支持将计算资源分组隔离,让重要、稳定计算任务不受临时和异常任务影响,保证业务稳定运行.按照计算任务的重要程度或业务范围,建立多个资源组,配置计算资源量,将重要任务分配到各个资源组,资源相互隔离,互不影响,稳定运行.重要任务...
来自:
云产品
利用低成本链路完成业务数据迁移上云
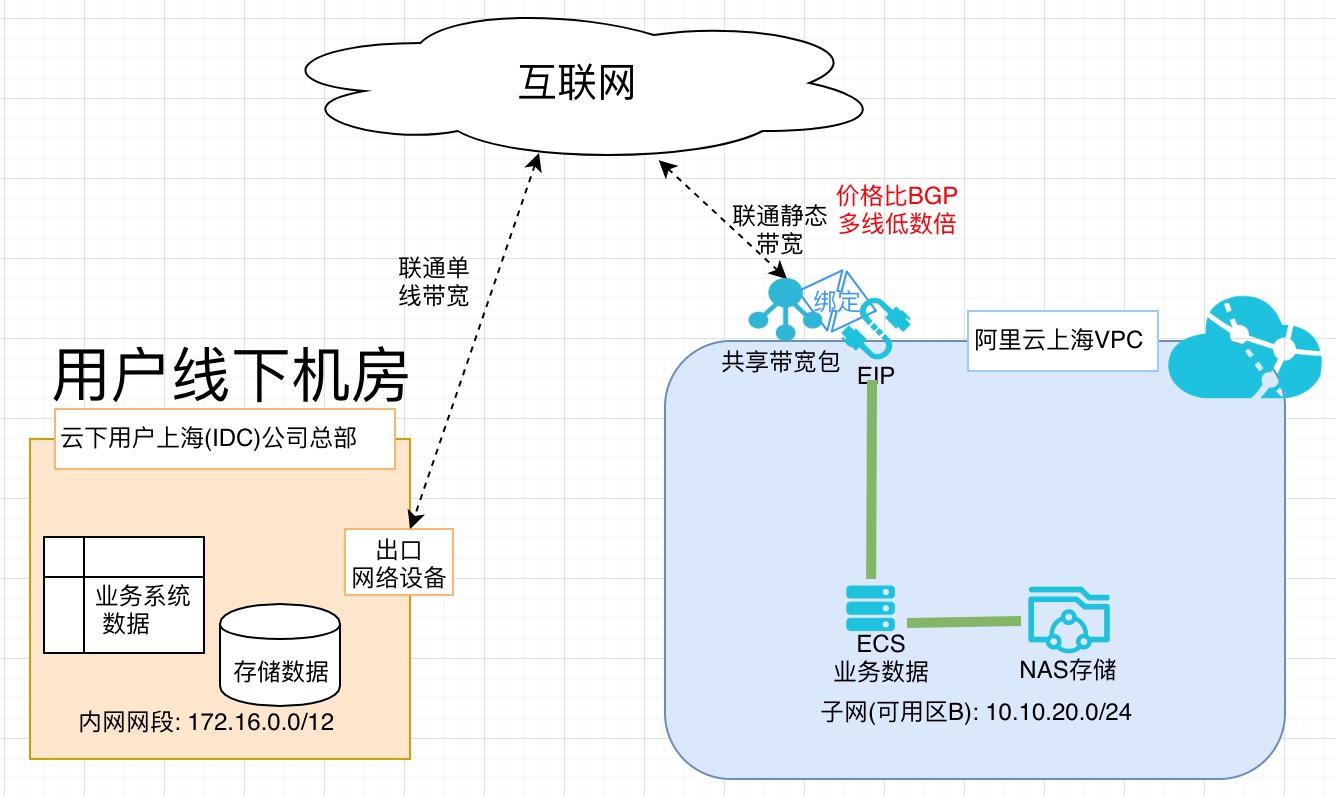
场景描述 随着云计算被越来越多的客户所接受,除业务系 统上云外,很多客户已经把业务数据搬迁上云。 业务数据量一般都比较大,迁移上云需要大量的 网络带宽,BGP费用比较高。阿里云对用户开 放所需地域购买静态单线共享带宽包的权限(移 动/联通/电信均可),可用为迁移数据有效降低 成本。 解决问题 1.业务数据上云网络成本高 产品列表 专有网络VPC 云服务器ECS 网络存储NAS 共享带宽包
利用低成本链路完成业务数据上云 最佳实践 部署架构图 场景描述 随着云计算被越来越多的客户所接受,除业务系 统上云外,很多客户已经把业务数据搬迁上云。业务数据量一般都比较大,迁移上云需要大量的 网络带宽,BGP费用比较高。阿里云对用户开 放所需地域购买静态单线共享带宽包的权限(移 动/联通/电信均可),可用为...
基于云拨测的网站用户体验监测最佳实践
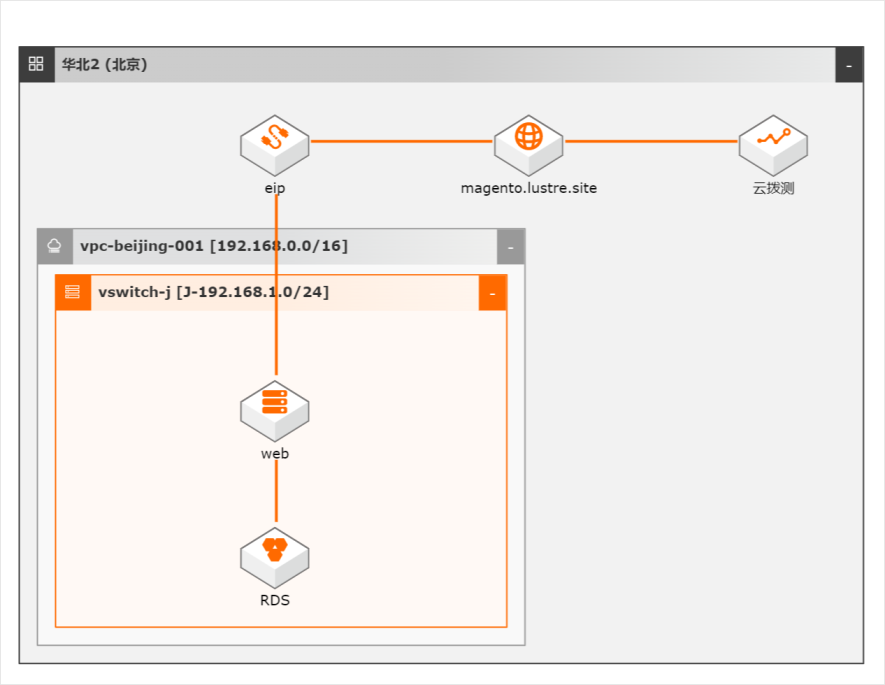
网站作为电商行业开展业务的核心场景,不同区域、不同运营商、不同的终端用户,给网站体验带来了巨大的一致性挑战。打开卡顿、缓慢,甚至无响应,都会影响到运营效果、甚至出现负面影响。阿里云基于多年业务经验,为云上客户提供完整的电商网站运营期间的用户体验监测方案。
文档版本:20220322 3 基于云拨测的网站用户体验监测 通过 CADT部署环境 步骤4 在部署前需要进行以下设置:1.双击 ECS,设置登录密码:2.双击 ECS和 RDS之间的连线,设置 RDS数据库账号和密码。3.目前 CADT暂时不支持开通、购买云拨测(正紧急开发中),您可以通过以下链接 选择对应套餐:试用版:云拨测提供免费试用版、后...
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 业务架构 场景描述 客户在 IDC或者公有云环境自建 Hadoop集群 构建数据仓库和分析系统,购买阿里云 Databricks数据洞察集群之后,涉及到数仓数 据和元数据的迁移以及 Hive版本的订正更新。方案优势 1.全托管 Spark集群免运维,节省人力成 本。2.Databricks数据洞察...
EMR本地盘实例大规模数据集测试
场景描述 阿里云为了满足大数据场景下的存储需求,在云 上推出了本地盘D1机型,这个系列提供了本地 盘而非云盘作为存储,提高了磁盘的吞吐能力, 发挥Hadoop的就近计算优势。阿里云EMR 产品针对本地盘机型,推出了一整套的自动化运 维方案,帮助用户方便可靠地使用本地盘机型, 不需要关注整个运维过程同时数据的高可靠和 服务的高可用。 解决问题 1.云盘多份冗余数据导致成本高 2.磁盘吞吐量不高 3.节点的高可靠分布问题 4.本地盘与节点的故障监控问题 5.数据迁移时自动决策问题 6.自动故障节点迁移与数据平衡问题 产品列表 EMR(E-MapReduce) 本地盘 VPC
首先进入 hive-testbench目录下执行如 下脚本并加载测试数据 参数说明:数据集规模参数单位为 GB,1000表示生成的数据量为 1TB/tpcdata/tpcds 为表数据生成的目录,目录不存在就自动生成,如果不指定目录,数 据目录就默认生成到/tmp/tpcds目录下 cd hive-testbench#如果已在此目录无需执行#tpcds数据表生成的目录,...
- 产品推荐
- 这些文档可能帮助您