利用低成本链路完成业务数据迁移上云
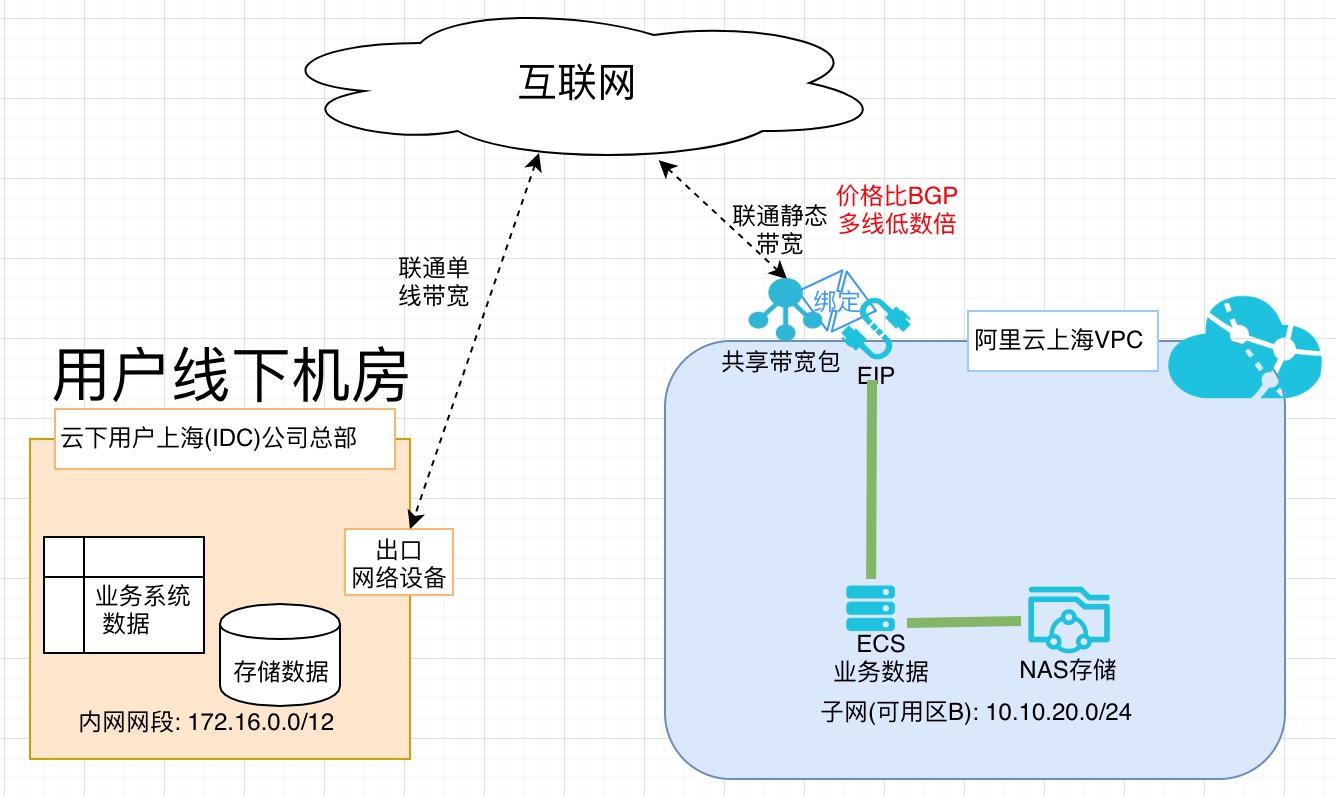
场景描述 随着云计算被越来越多的客户所接受,除业务系 统上云外,很多客户已经把业务数据搬迁上云。 业务数据量一般都比较大,迁移上云需要大量的 网络带宽,BGP费用比较高。阿里云对用户开 放所需地域购买静态单线共享带宽包的权限(移 动/联通/电信均可),可用为迁移数据有效降低 成本。 解决问题 1.业务数据上云网络成本高 产品列表 专有网络VPC 云服务器ECS 网络存储NAS 共享带宽包
业务数据上云网络成本高 产品列表 专有网络VPC 云服务器ECS 网络存储NAS 共享带宽包 文档版本:20191010(发布日期)云服务器ECS(产品名称)文档模板(手册名称)/文档版本信息 阿里云 利用低成本链路 完成业务数据迁移上云 最佳实践 文档版本:20150122(发布日期)2 利用低成本链路完成业务数据迁移上云 ...
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 业务架构 场景描述 客户在 IDC或者公有云环境自建 Hadoop集群 构建数据仓库和分析系统,购买阿里云 Databricks数据洞察集群之后,涉及到数仓数 据和元数据的迁移以及 Hive版本的订正更新。方案优势 1.全托管 Spark集群免运维,节省人力成 本。2.Databricks数据洞察...
DTS数据同步集成MaxCompute数仓
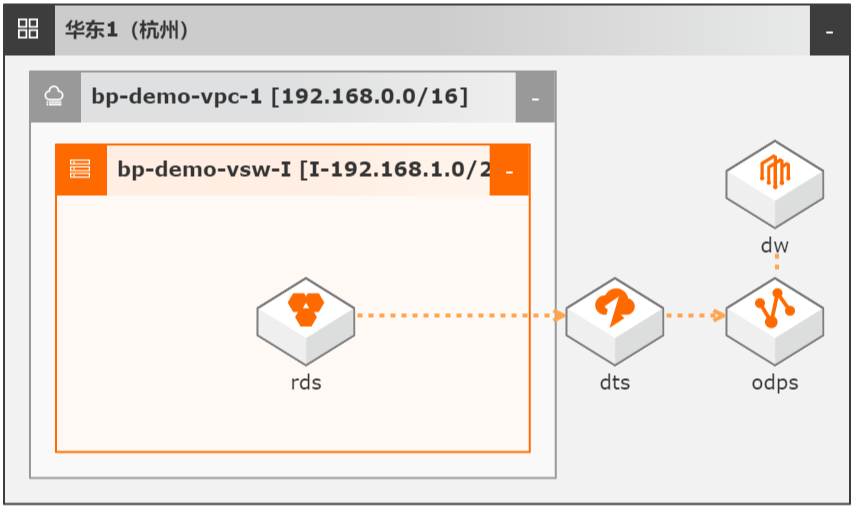
场景描述 本文Step by Step介绍了通过数据传输服务 DTS实现从云数据库RDS到MaxCompute的 数据同步集成,并介绍如何使用DTS和 MaxCompute数仓联合实现数据ETL幂等和数 据生命周期快速回溯。 解决问题 1.实现大数据实时同步集成。 2.实现数据ETL幂等。 3.实现数据生命周期快速回溯。 产品列表 MaxCompute 数据传输服务DTS DataWorks 云数据库RDS MySQL 版
数据抽取不幂等或容错率低,如凌晨 0:00启动的 ETL任务因为各种原因(数据库 HA切换、网络抖动或 MAXC写入失败等)失败后,再次抽取无法获取 0:00时的数 据状态。2.针对不规范设计表,如没有 create_time/update_time的历史遗留表,传统 ETL需 全量抽取。3.实时性差,抽取数据+重试任务往往需要 1-3小时。另外数据库的数据...
数据湖-在线学习场景数据分析

场景描述 本场景以在线教育中一个答题闯关类的应用为 例,使用WebServer来模拟演示这类日志数据 的分析处理。通过Nginx和Pythonflask搭建 WebServer,模拟应用中的关键页面,比如登 录、课程内容等,之后构造若干用户使用的模拟 日志数据,投递到数据湖进行分析后获取应用 PV、UV、课程内容访问排行、平均得分等等。 解决问题 基于数据湖(EMR+OSS)搭建大数据平台。 EMR和OSS使用和配置。 数据统一存储到OSS。 产品列表 E-MapReduce 对象存储OSS 云服务器ECS 访问控制RAM 专有网络VPC
通过Nginx和Pythonflask搭建WebServer,模拟应用中的关 键页面,比如登录、课程内容等,之后构造若干用户使用的模拟日志数据,投递到数 据湖进行分析后获取应用PV、UV、课程内容访问排行、平均得分等等。方案优势 支持超过10亿条元数据规模的数据管理,同时支持高可靠和高可用。 支持元数据实时备份和重建集群快速恢复...
大数据近实时数据投递MaxCompute
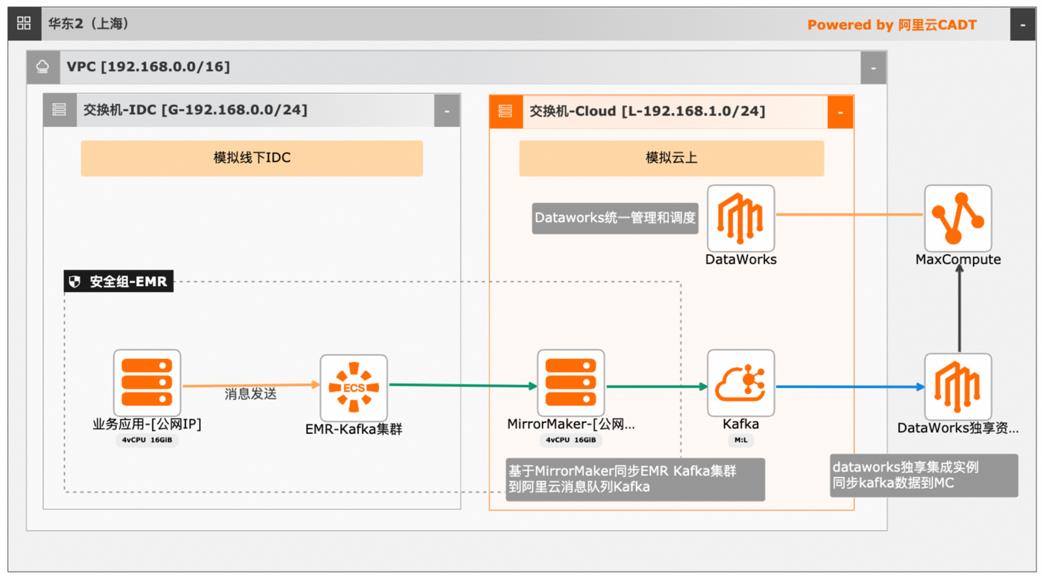
本文介绍离线大数据场景使MaxCompute构建云 上近实时数仓,打通云下数据上云链路,解决数据复杂类型支持和动态分区问题,满足高级数据处理需求的最佳实践。 l混合云环境下,现有业务系统零改造,打通数据上云链路。 l使用UDF实现复杂数据类型转换和数据动态分区。 l使用DataWorks配置周期调度业务流程,数据自动入仓。 l借助MaxCompute优化计算引擎,实现降本增效。 产品列表 云服务器ECS 专有网络VPC 访问控制RAM 数据总线DataHub E-MapReduceEMR DataWorks 大数据计算服务MaxCompute
为 Dataworks独享集成实例配置网络 通过 CADT架构图跳转到 Dataworks独享实例页面 点击网络配置 文档版本:20240419 28 大数据近实时数据投递 MaxCompute 选择网络信息,选择 Kafka实例所在的 VPC,VSW以及安全组。5.4.配置 Kafka数据源 进入数据集成页面 新增数据源 文档版本:20240419 29 大数据近实时数据投递 ...
数据迁移上云
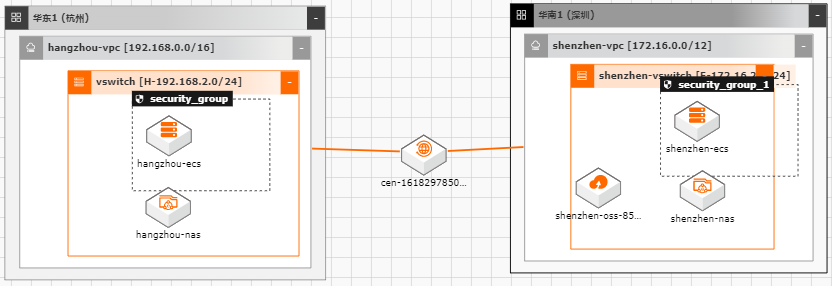
随着越来越多的企业选择将业务系统上云,各种类型的数据如何便捷、平滑的迁移上 云,成了用户上云较为关注的点;业务上云后,因为业务或者其他方面调整等因素, 也存在如跨区域,跨账号等数据迁移的场景。针对以上需求,阿里云上提供了较为丰 富的工具(如ossimport)、服务(在线迁移服务),旨在能够帮助客户便捷进行数据迁 移。 本文通过云架构设计工具CADT来快速创建云上基础资源,并以杭州区域来模拟线 下IDC(或友商),深圳区域模拟阿里云云上资源。通过云上的工具命令、服务来提 供常见数据迁移场景的最佳实践。
云企业网可帮助您在不同地域 VPC间,VPC与本地数据中心间搭建私网通信通道,通过自动路由分发及学习,提高网络 的快速收敛和跨网络通信的质量和安全性,实现全网资源的互通,帮助您打造一 文档版本:20201013 II 数据迁移上云最佳实践 前言 张 具 有 企 业 级 规 模 和 通 信 能 力 的 互 联 网 络。详见:...
Spark on ECI大数据分析

场景描述 方案优势 1.计算引擎弹性扩缩容,兼顾资源弹性与计 算资源成本优化。 2.计算与存储分离架构,结合阿里云原生云 存储产品,海量数据湖优势。 3.Kubernetes原生的调度性能优势,提升在 大规模分析作业时的分析性能优势分。 4.集群资源隔离和按需分配。 解决问题 1.计算资源弹性能力不足,计算资源成本管 控能力欠缺. 2.集群资源调度能力和隔离能力不足。 3.计算与存储无法分离,大数据量分析时出 现数据存储资源瓶颈。 4.Spark submit方式提交分析作业参数支持 有限等缺点。 产品列表 容器服务Kubernetes版(ACK) 弹性容器实例(ECI) 文件存储HDFS 对象存储OSS 专有网络VPC 容器镜像服务ACR
Spark on Kubernetes解决方案的用户 对 Spark大数据分析平台计算资源成本控制考虑的用户 需要有灵活可扩展计算平台资源弹性及管控的用户 名词解释 文件存储 HDFS:阿里云文件存储 HDFS是面向阿里云 ECS实例及容器服务等计 算资源的文件存储服务,允许用户像在 Hadoop分布式文件系统中管理和访问数 据,无需对数据分析应用做...
企业上云数据安全
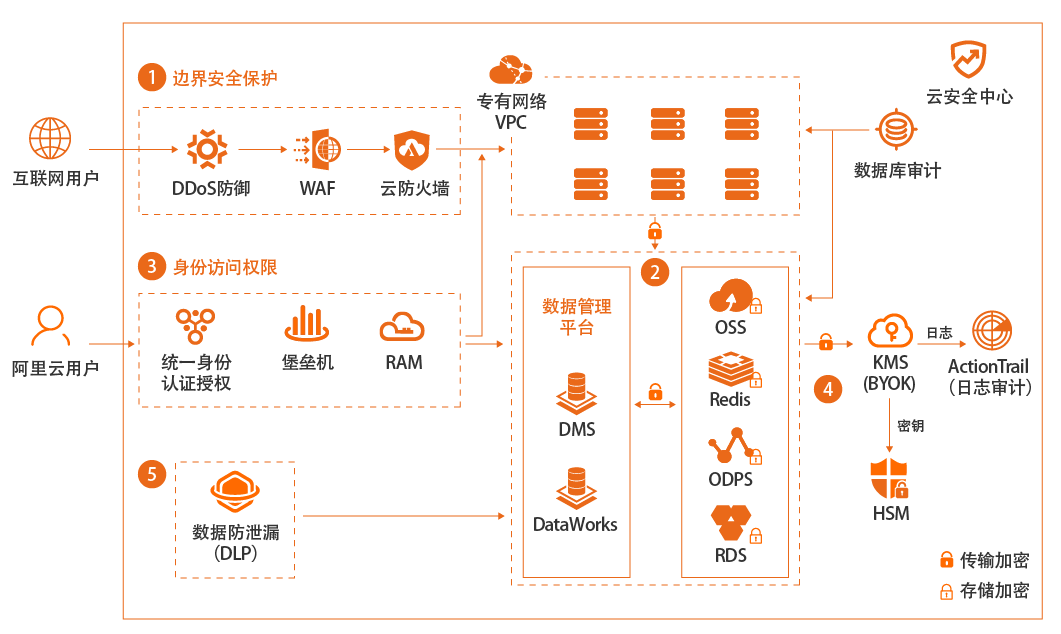
场景描述 企业是否选择上公共云,或者哪些系统或数据上 公共云,对数据安全的关心是重要因素之一。本 最佳实践重点在于介绍狭义的数据加密存储安 全范畴,即首先使用SDDP产品进行敏感数据发 现和分级分类,然后对高级别敏感数据进行按 需、不同类型的全链路加密存储。 解决问题 1.帮助客户发现敏感数据 2.对敏感数据进行分类、分级 3.对不同级别的数据如何选择加密方式 4.具体如何进行加密 产品列表 敏感数据识别SDDP 密钥管理服务KMS 云数据库RDS 对象存储OSS
本最佳实践重点在于介绍狭义的数据加密 存储安全范畴,即首先使用 SDDP产品进行敏 感数据发现和分级分类,然后对高级别敏感数 据进行按需、不同类型的全链路加密存储。解决问题 1.帮助客户发现敏感数据 2.对敏感数据进行分类、分级 3.对不同级别的数据如何选择加密方式 4.具体如何进行加密 产品列表 敏感数据识别 SDDP 密钥...
Function Compute构建高弹性大数据采集系统
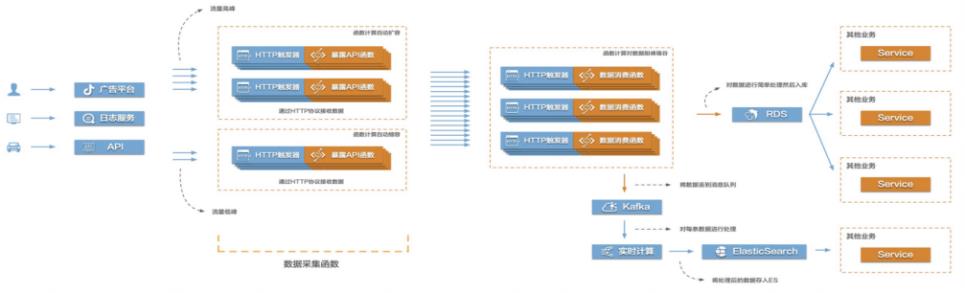
当前互联网很多场景都存在需要将大量的数据信息采集起来然后传输到后端的各类系统服务中,对数据进行处理、分析,形成业务闭环。比如游戏行业中的游戏发行、游戏运营,产互行业中的数字营销,物联网、车联网行业中的硬件、车辆信息上报等等。这些场景普遍存在数据采集量大、数据传输需要稳定且吞吐量大的特点,给整个数据采集传输系统带来很大的挑战。在这个场景中,有三个关键的环节,数据采集、数据传输、数据处理。该最佳实践主要涉
Function Compute构建高弹性大数据采集系统 最佳实践 业务架构 场景描述 当前互联网很多场景都存在需要将大量的数据 信息采集起来然后传输到后端的各类系统服务 中,对数据进行处理、分析,形成业务闭环。比 如游戏行业中的游戏发行、游戏运营,产互行业 中的数字营销,物联网、车联网行业中的硬件、车辆信息上报等等。这些...
云速搭部署 Elasticsearch 应用

本实践通过云速搭实现一个 DTS+Elasticsearch 的搜索引擎架构,构建一个快速分析和检索 业务数据的系统。
专有网络由逻辑网络设备(如虚拟路由器,虚拟交 换机)组成,可以通过专线/VPN等连接方式与传统数据中心组成一个按需定制的 网络环境,实现应用的平滑迁移上云。详见:https://www.aliyun.com/product/vpc 数据传输服务 DTS:Data Transmission Service,简称 DTS,是一种集数据迁移、数据订阅及数据实时同步于一体的数据...
云速搭部署 DTS 应用

通过云速搭实现 通过云速搭实现一个 DTS 和两个 RDS 实例的创建,并通过配置同步策略,将源 RDS数据库库中的数据同步到目标 RDS 数据库中。
其底层基础设施采用阿里双 11异地多活架构,为数千下游应用提供实时数据流,已在线上稳定运行 6年之久。详见:https://www.aliyun.com/product/dts。文档版本:20220104 3 云速搭部署DTS应用 云速搭架构设计入门 云速搭架构设计入门 方案架构 通过云速搭实现一个 DTS和两个 RDS实例的创建,并通过配置同步策略,将源 RDS ...
云速搭部署Flink应用

本水煎通过云速搭实现一个DataHub+Flink的实时流计算引擎架构,利用DataHub收集原始数据,推送到Flink进行基于流式数据的分析和应用。
更多信 息,详见:https://www.aliyun.com/product/bigdata/sc 数据总线 DataHub:是阿里云提供的流式数据(Streaming Data)服务,它提供流 式数据的发布(Publish)和订阅(Subscribe)的功能,让您可以轻松构建基于流式数 据的分析和应用。详见:https://www.aliyun.com/product/datahub 对象存储 OSS(Object Storage Service...
云速搭部署ADB应用最佳实践

本实践通过云速搭实现一个云原生数据仓库AnalyticDB MySQL版的产品实例。
专有网络由逻辑网络设备(如虚拟路由器,虚拟交 换机)组成,可以通过专线/VPN等连接方式与传统数据中心组成一个按需定制的 网络环境,实现应用的平滑迁移上云。详见:https://www.aliyun.com/product/vpc 云原生数据仓库 ADB:云原生数据仓库 AnalyticDB MySQL版是一种支持高并发 低延时查询的新一代云原生数据仓库,高度...
跨云迁移单写双读过渡架构
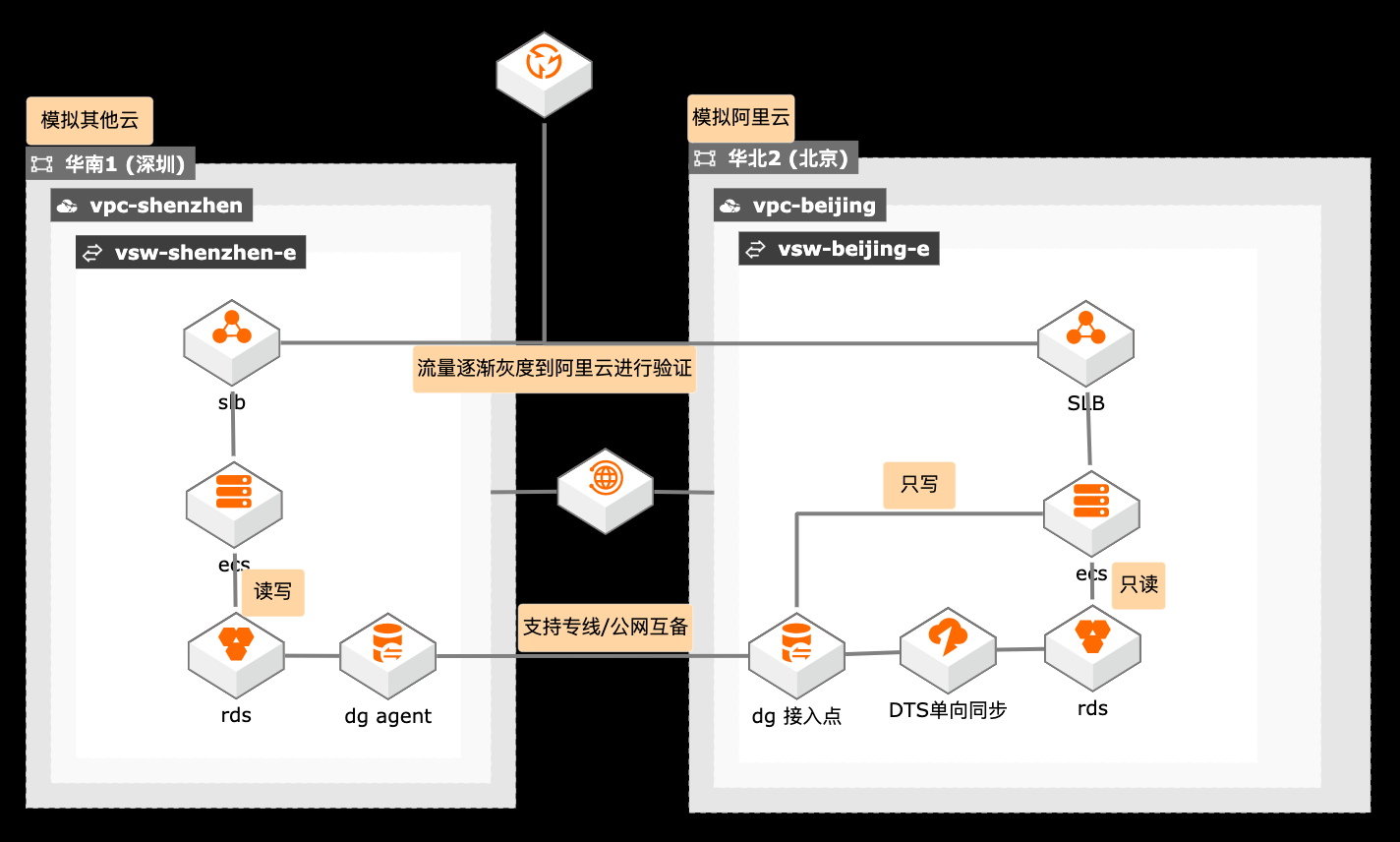
概述 在搬站场景下,涉及迁移跨度较长,在过渡阶段客户需要跨云访问,如何保障数据链路的高可用尤为关键,采用专线和公网双备的方案保障数据传输的高可用,也降低双专线的迁移成本。 适用场景 数据迁移链路的高可用 跨云迁移过渡期架构 读写分类架构设计 技术架构 本实践方案基于如下图所示的技术架构和主要流程编写操作步骤: 方案优势 在迁移时间持续较长的情况下,使用单写双读架构降低业务改造成本。 使用数据库网关做专线和公网互备。 流量逐渐灰度验证,保障迁移平滑过渡。 安全:原生的多租户系统,以项目进行隔离,所有计算任务在安全沙箱中运行。
它底层的数据流基础设施为阿里双 11异地多 活基础架构,为数千下游应用提供实时数据流,已在线上稳定运行 6年之久。您 可以使用数据传输轻松构建安全、可扩展、高可用的数据架构。详见:https://www.aliyun.com/product/dts 云企业网:阿里云致力于为用户提供优质、高效、稳定的网络传输环境,云企业网(Cloud Enterprise ...
基于Flink的资讯场景实时数仓
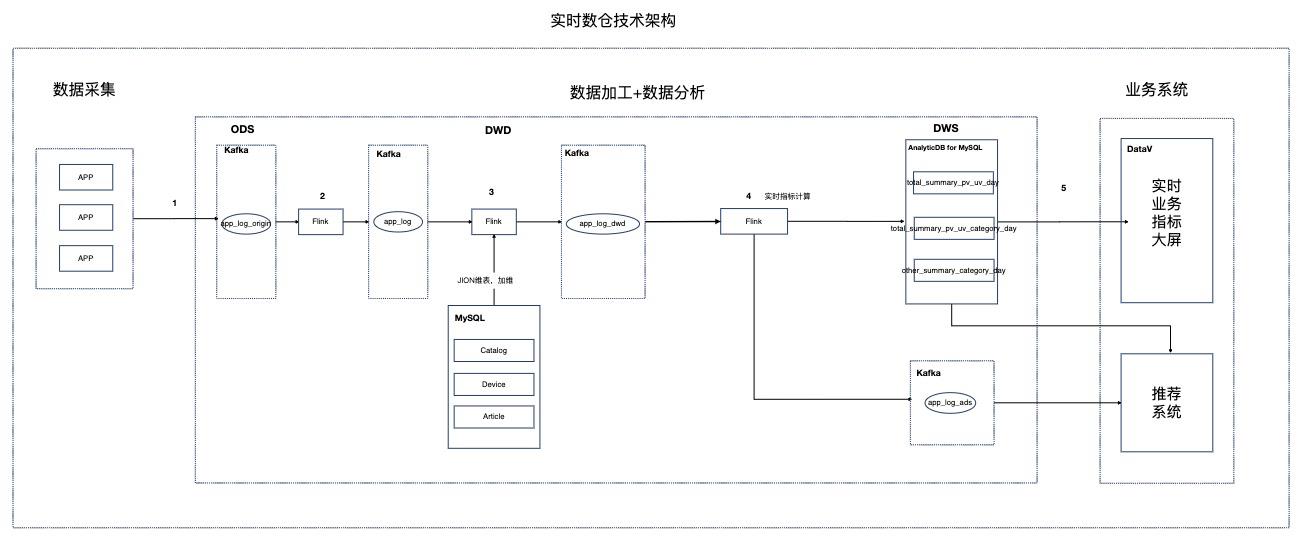
场景描述 本实践针对资讯聚合类业务场景,Step by Step介绍 如何搭建实时数仓。 解决问题 1.如何搭建实时数仓。 2.通过实时计算Flink实现实时ETL和数据流。 3.通过实时计算Flink实现实时数据分析。 4.通过实时计算Flink实现事件触发。 产品列表 实时计算 专有网络VPC 云数据库RDSMySQL版 分析型数据库MySQL版 消息队列Kafka 对象存储OSS NAT网关 DataV数据可视化
3.数据加工:消息队列收到的原始数据,往往存在格式不齐或内容不全,需要经过数 据清洗(ETL)之后,才能更好的被下游业务使用。而整个 ETL过程,是实时数 仓架构设计上非常重要的一环,该环节要做到延时小,成本低,可扩展性好,业务 指标计算准确。在系统选型上,推荐使用实时计算 Flink对数据进行处理,因为 Flink具有...
函数计算FC
阿里云函数计算(Function Compute)是一个事件驱动的全托管计算服务。通过函数计算,您无需管理服务器等基础设施,只需编写代码并上传。函数计算会为您准备好计算资源,以弹性、可靠的方式运行您的代码。更棒的是,您只需要为代码实际运行消耗的资源付费,代码未运行则不产生费用。
网络数据源调整公告 查看详情 2021-05-06 功能优化 函数计算WebIDE工具下线通知 查看详情 2021-06-25 新功能/规格 阿里云函数计算-资源套餐包(预付费)上线和包年包月(预付费)下线公告 查看详情 2021-07-31 其他 经典网络环境下的机器分批下线通知 查看详情 2021-12-12 新功能/规格 函数计算资源包支持申请 ICP 备案服务...
来自:
云产品
云数据库 Tair(兼容 Redis)
阿里云数据库Tair(兼容Redis®)能够应对开源Redis难以覆盖的场景,并提供稳定的高性能、低时延服务,包括多线程处理能力、多种存储介质等更多企业级服务,广泛应用于缓存、内存存储场景。
同城容灾:云数据库 Tair 支持双机房的同城容灾架构,主备机房数据通过专门的复制通道同步,当主机房出现电力或网络问题时,备实例升级为主实例,保障服务可用。全球多活:云数据库 Tair 支持异地多个站点同时对外提供服务,提供跨域复制的能力,快速实现数据异地灾备和多活。查看《安全白皮书》客户案例云数据库 Tair 提供...
来自:
云产品
全域采集与增长分析 产品概述
阿里云全域采集与增长分析(QuickTracking)通过行为采集分析、私域标签画像、性能体验监控、隐私采集授权管理等数据采集与洞察服务,提供基于大数据计算的流量统计分析能力,助力企业营销增长第一公里。
为保证移动端用户的个人隐私,本产品提供了多种功能辅助开发者合规采集用户隐私数据,以及在网络传输、数据存储和产品访问方面提供了更全面的数据安全合规策略。采集合规预初始化:可以在用户同意隐私协议后,再初始化Quick Tracking SDK,不会造成SDK工作异常或者数据丢失。设备ID采集可关闭:Quick Tracking默认采集...
来自:
云产品
全域采集与增长分析 产品功能
阿里云全域采集与增长分析(QuickTracking)提供采集管理、行为分析、用户画像、性能体验监测和隐私合规管理几大功能,帮助企业快速构建全渠道用户行为采集和分析体系。
产品解决方案文档与社区权益中心定价云市场合作伙伴支持与服务了解阿里云AI 助理备案控制台全域采集与增长分析产品概述产品功能选型与定价相关资源控制台文档联系我们立即购买产品功能助力企业实现全域数据采集、一站式增长分析和性能体验提升。立即购买管理控制台全域采集与增长分析产品功能数据采集埋点管理埋点管理包含...
来自:
云产品
- 产品推荐
- 这些文档可能帮助您