Oracle RAC 12C云上部署
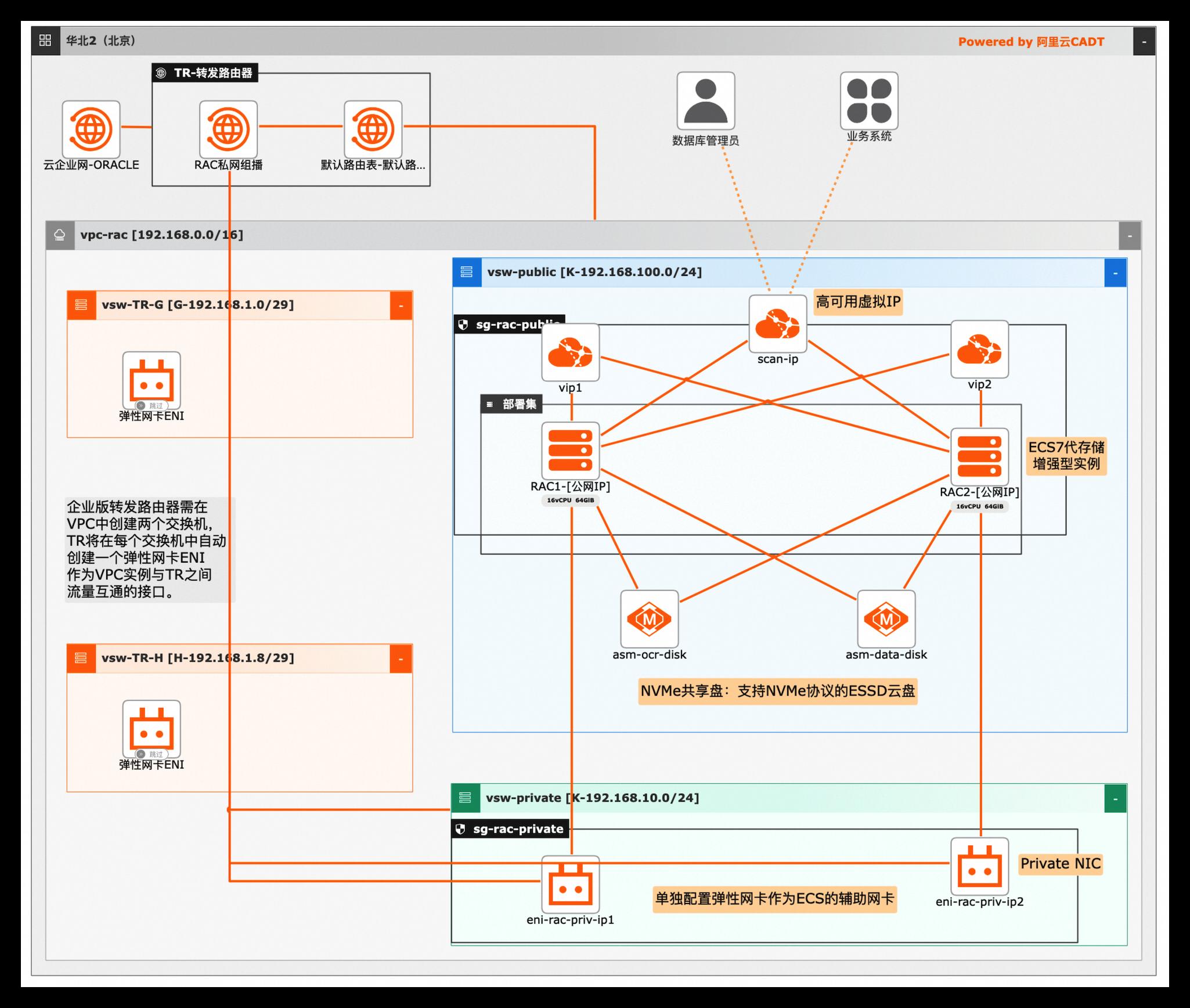
Oracle RAC架构迁移上云,提供高并发,高吞吐,高安全等特性,适用于金融,电力,电信,制造业等传统客户的核心交易系统。
云企业网CEN:云企业网(CloudEnterpriseNetwork,简称CEN)是阿里云提 供的一款能够快速构建混合云和分布式业务系统的全球网络服务,为用户提供优 质、高效、稳定的网络传输环境,帮助用户打造一张具有企业级规模和通信能力 的云上网络。适用于集团企业、全球网络等场景。 转发路由器TR(TransitRouter):提供连接...
音视频行业单线静态公网接入最佳实践
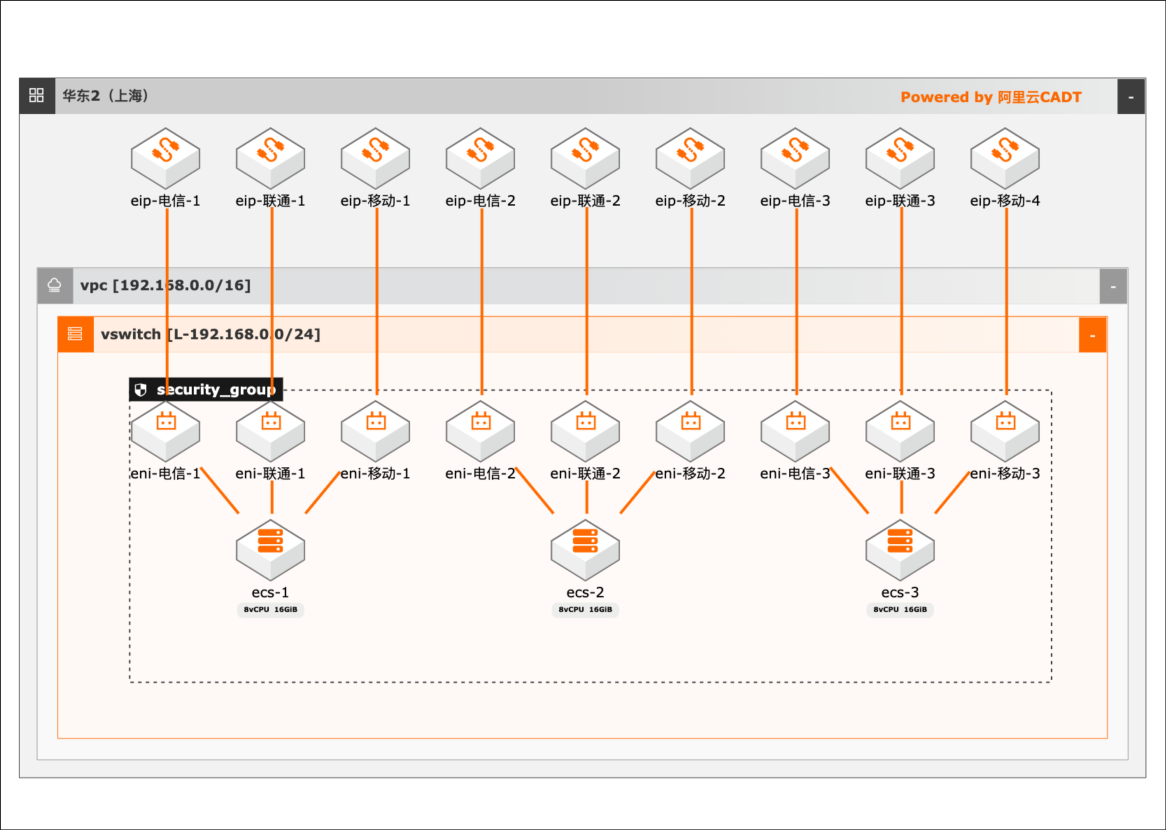
在音视频、下载领域,部分客户出于某些特定的原因需要使用单线EIP,考虑到单线EIP相较于多线BPG EIP存在单点故障的风险,因此会在一个节点上同时绑定多个运营商的单线EIP,通过设置内部的路由调度策略实现链路的高可靠。当用户有下载请求时,会首先通过调度策略调度到与用户相同运营商对外服务的IP地址。
目前,EIP 支持绑定到专有网络类型的云服务器 ECS(Elastic Compute Service)实例、专有网络类型的私网传统型负载均衡 CLB(Classic Load Balancer)实例、私网类型的应用型负载均衡 ALB(Application Load Balancer)、专有网络类型的辅助弹性网卡、NAT网关和高可用虚拟 IP上。详见 ...
CDH迁移升级CDP最佳实践
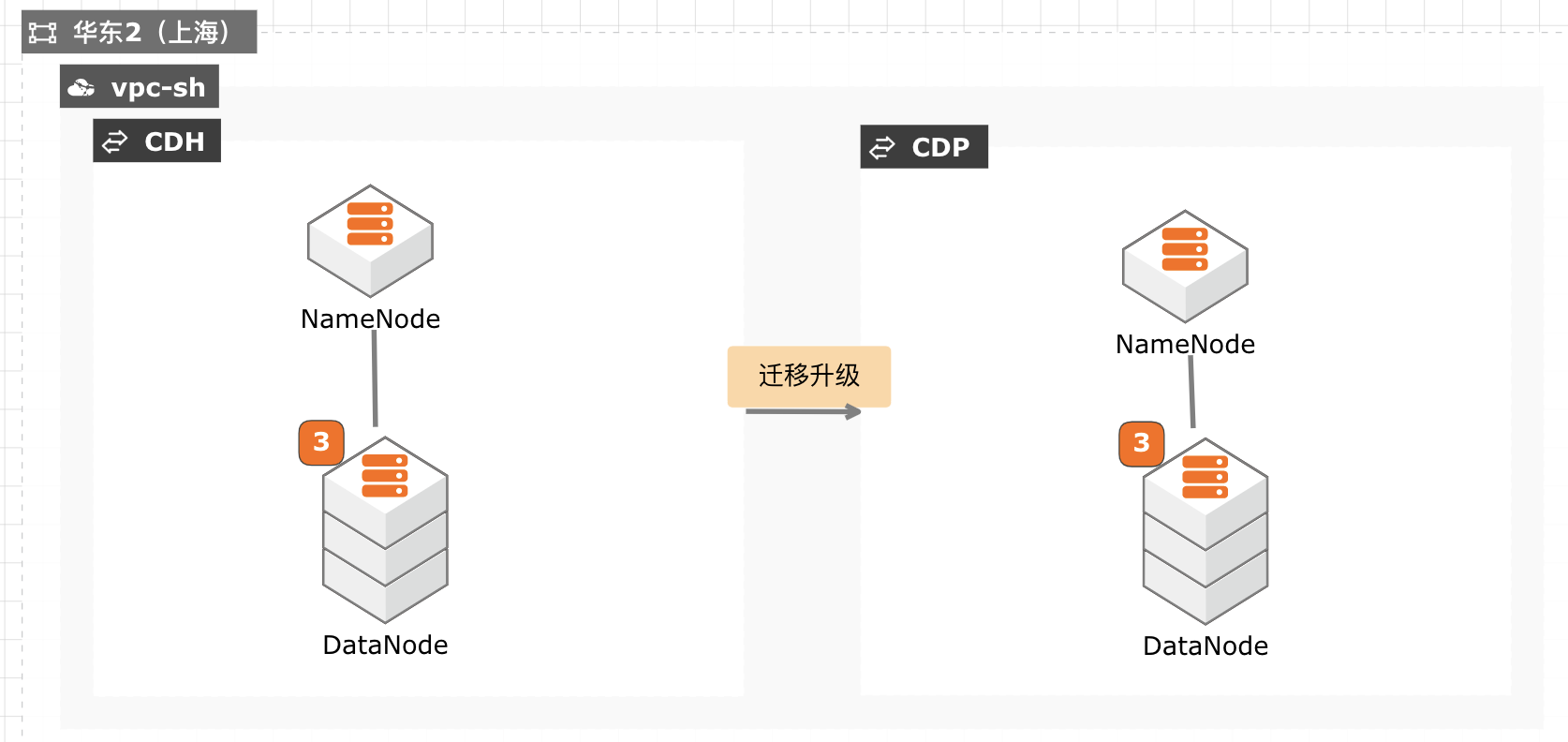
当前 CDH 免费版停止下载,终止服务,针对需要企业版服务能力并且CDH 升级过程对业务影响较小的客户,通过安装新的 CDP 集群,将现有数据拷贝至新集群,然后将新集群切换为生产集群,升级过程没有数据丢失风险,停机时间较短,适合大部分互联网客户升级使用。
1.收集 3个节点的私网 IP地址和对应的主机名,如下所示(请根据您环境的实际 IP 地址进行修改):192.168.10.205 master 192.168.10.207 slave1 文档版本:20211029 9 CDH迁移升级 CDP最佳实践 基础环境搭建 192.168.10.208 slave2 192.168.10.206 slave3 2.通过 SSH远程登录 master节点所在的 ECS实例,通过 vim编辑器将...
EMR集群安全认证和授权管理
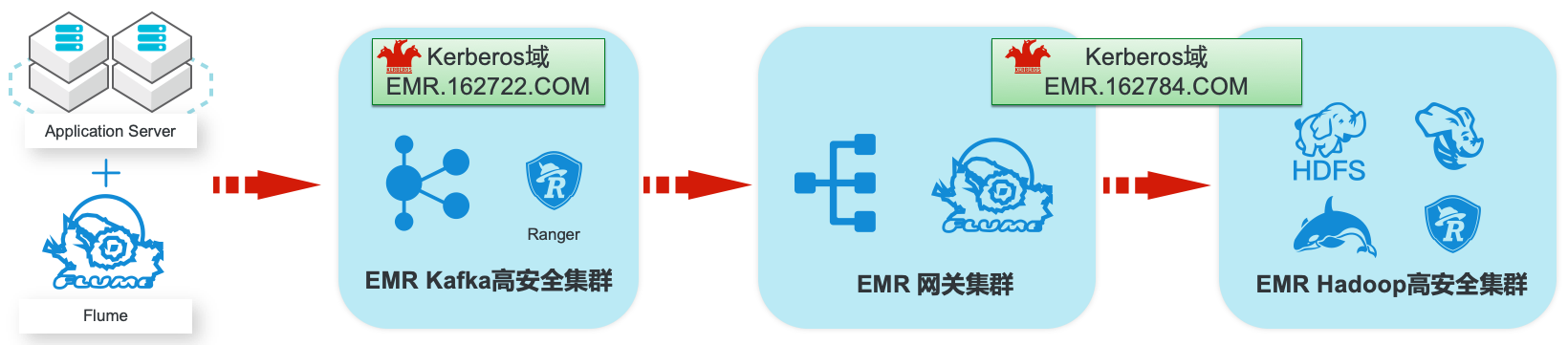
场景描述 阿里云EMR服务Kafka和Hadoop安全集群使 用Kerberos进行用户安全认证,通过Apache Ranger服务进行访问授权管理。本最佳实践中以 Apache Web服务器日志为例,演示基于Kafka 和Hadoop的生态组件构建日志大数据仓库,并 介绍在整个数据流程中,如何通过Kerberos和 Ranger进行认证和授权的相关配置。 解决问题 1.创建基于Kerberos的EMR Kafka和 Hadoop集群。 2.EMR服务的Kafka和Hadoop集群中 Kerberos相关配置和使用方法。 3.Ranger中添加Kafka、HDFS、Hive和 Hbase服务和访问策略。 4.Flume中和Kafka、HDFS相关的安全配 置。 产品列表:E-MapReduce、专有网络VPC、云服务器ECS、云数据库RDS版
文档版本:20200330 12 EMR集群安全认证和授权管理 EMR Kafka安全集群 2.EMR Kafka安全集群 本最佳实践中,将首先创建云上虚拟网络 VPC,后续所有云上资源都将规划在该 VPC 中,例如 RDS数据库、日志发生器、EMR Kafka集群、EMR Hadoop集群和 EMR网 关集群等。2.1.创建专有网络 VPC 步骤1 登录专有网络控制台,地域:华东 1...
基于Flink的资讯场景实时数仓
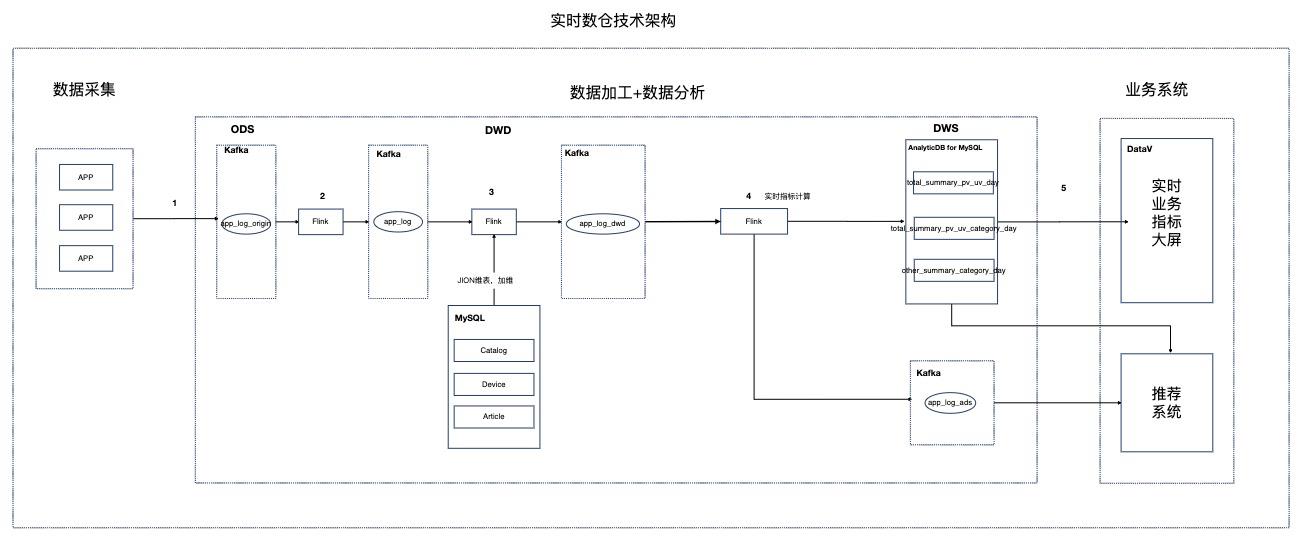
场景描述 本实践针对资讯聚合类业务场景,Step by Step介绍 如何搭建实时数仓。 解决问题 1.如何搭建实时数仓。 2.通过实时计算Flink实现实时ETL和数据流。 3.通过实时计算Flink实现实时数据分析。 4.通过实时计算Flink实现事件触发。 产品列表 实时计算 专有网络VPC 云数据库RDSMySQL版 分析型数据库MySQL版 消息队列Kafka 对象存储OSS NAT网关 DataV数据可视化
专有网络 VPC 云数据库 RDS MySQL版 分析型数据库 MySQL版 解决问题 消息队列 Kafka 对象存储 OSS 1.如何搭建实时数仓。NAT网关 2.通过实时计算 Flink实现实时 ETL和数据流。DataV数据可视化 3.通过实时计算 Flink实现实时数据分析。4.通过实时计算 Flink实现事件触发。最佳实践频道 阿里云最佳实践分享群 云服务器 ECS...
企业办公安全访问一体化
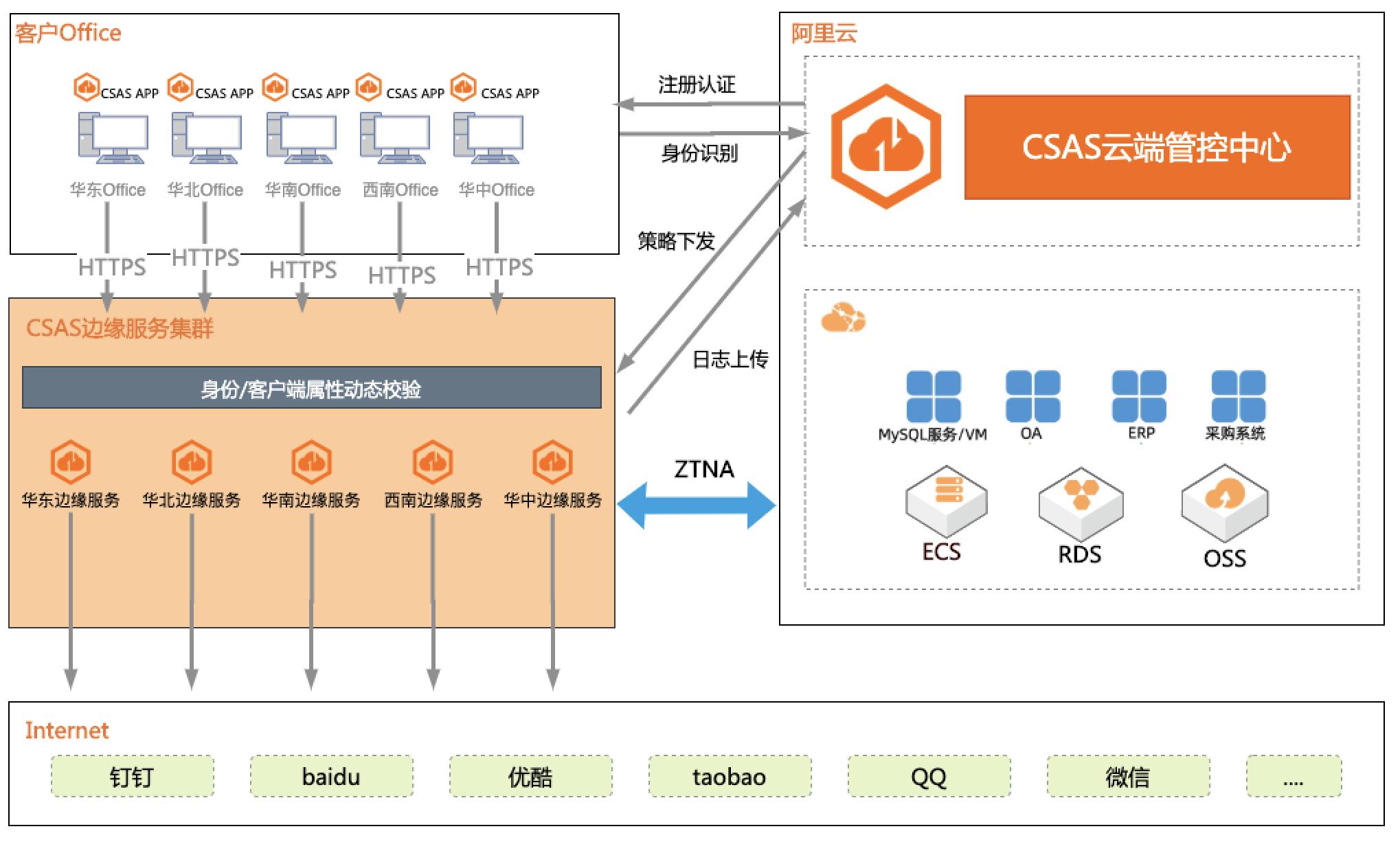
本场景模拟企业办公环境,基于 CSAS 服务构 建企业办公安全一体化方案,将“安全 + 网络” 能力无缝融合,实现了对云下办公终端安全的统 一管理,企业无需在投资复杂且昂贵的传统硬件 安全设备,即可快速构建安全、可靠、低成本的 办公安全防护体系。 1. 企业办公环境访问互联网的安全管理 2. 企业办公环境访问内网服务的安全管理 3. 企业办公网络、安全一体化管理
企业办公安全访问一体化最佳实践 业务架构 场景描述 本场景模拟企业办公环境,基于CSAS服务构建 企业办公安全一体化方案,将“安全+网络”能力 无缝融合,实现了对云下办公终端安全的统一管 理,企业无需在投资复杂且昂贵的传统硬件安全 设备,即可快速构建安全、可靠、低成本的办公 安全防护体系。解决问题 1.企业办公环境...
云速搭构建大规模云手机压测集群
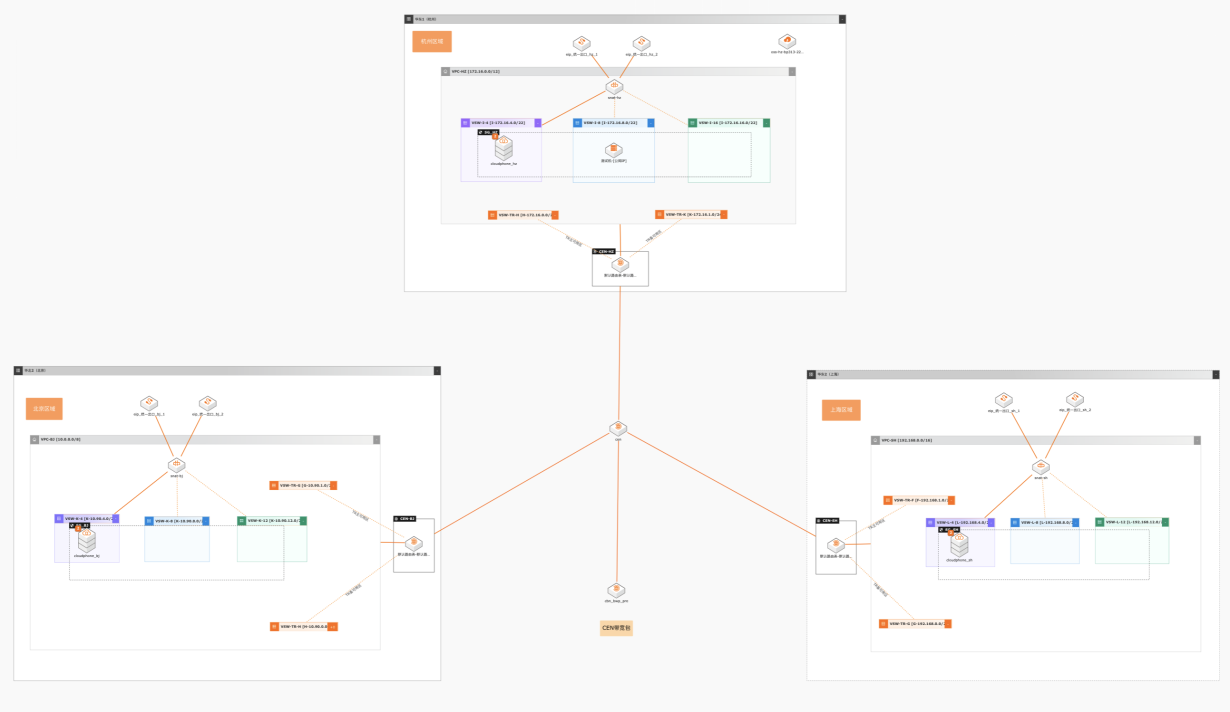
在互联网游戏行业新游发行前、金融行业的基金或券商APP在大版本更新前,均需要将APP部署到大规模测试环境中进行压测,确保大规模并发场景下对APP本身可靠性和后台业务系统的稳定性及资源准备情况做好验证。 本实践设计一个游戏压测场景,在阿里云的多地域快速部署共一万台云手机,每台云手机之间网络可互通,每台云手机通过阿里云提供的NAT网关可访问互联网。
用户基于电脑、平板等终端,以串流的方式,远程实时操控,实现安卓应用云 端运行,可以广泛应用于移动办公,游戏以及广告营销等场景。详见:https://www.aliyun.com/product/ecs/cloudphone 云服务器 ECS:云服务器 ECS(Elastic Compute Service)是一种简单高效、处 理能力可弹性伸缩的计算服务。帮助您构建更稳定、安全...
混合云存储构建VMware虚拟化平台
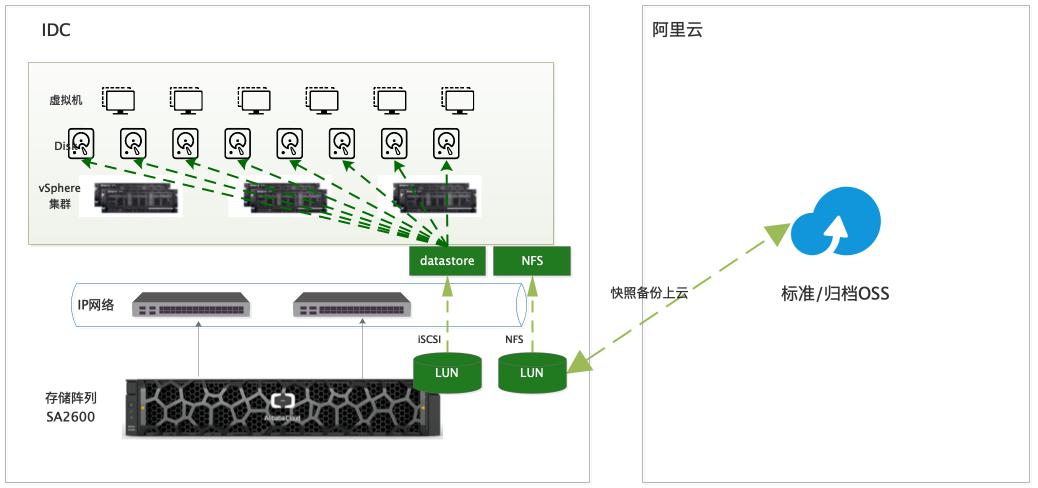
场景描述 本文以混合云存储阵列SA2600系统为例,介绍如 何在混合云存储环境下部署VMware虚拟化平台, 以及混合云环境下虚拟机的部署、扩容、云备份等功 能演示。 解决问题 1.如何使用混合云存储部署VMware虚拟化平台。 2.存储阵列在混合云环境下的使用,比如虚拟机部 署、扩容、云备份等。 产品列表 1.混合云存储阵列 2.对象存储OSS
文档版本:20191223 27 混合云存储构建VMware虚拟化平台 存储阵列系统初始化配置 池菜单 池菜单位于左侧的菜单栏,从上到下是第二个图标,将鼠标悬停至该图标,即可显示 子菜单:池、按池划分的卷、内部存储器、外部存储器、按池划分的MDisk、系统迁 移。卷菜单 卷菜单位于左侧的菜单栏,从上到下是第三个图标,将鼠标移动...
SAP S/4HANA上云最佳实践
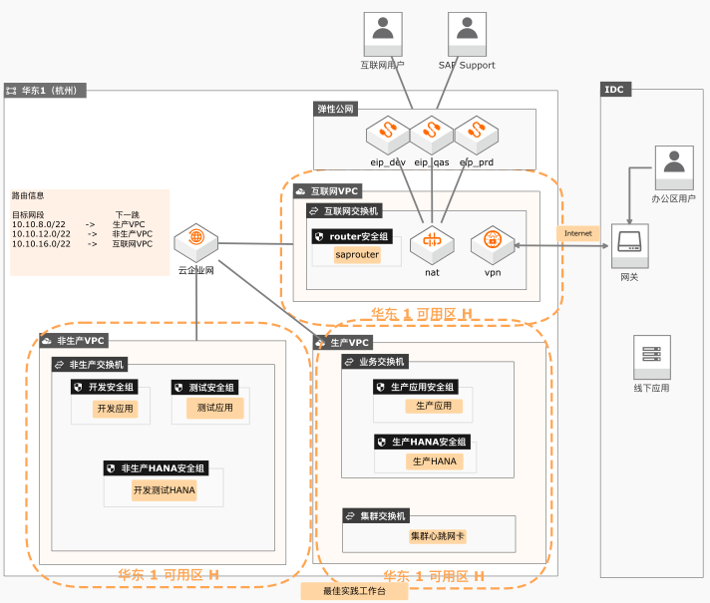
本实践以SAP S/4HANA上阿里云的场景为原型,阐述了如何通过CADT在阿里云上快速交付符合最佳实践的基础云架构。
其他适用的 SAP产品 SAP S/4HANA SAP Suite on HANA SAP BW/4HANA SAP NetWeaver on HANA 方案涵盖内容 1、云架构设计 2、云资源选型 3、CADT一键部署资源 4、CADT分阶段部署资源 产品列表 云服务器 ECS 专有网络 VPC 云网关 NAT 最佳实践频道 阿里云最佳实践技术分享群 弹性公网 EIP SAP S/4HANA上云最佳实践 文档版本信息...
云速搭部署智能接入网关SAG APP

本篇最佳实践通过CADT在华东2上海和美西弗吉尼亚创建跨地域的VPC,在VPC内部署ECS模拟办公系统应用。通过CADT购买SAG APP版并挂载到云连接网CCN,通过云企业网CEN将云上跨地域的VPC和云连接网CCN打通,实现内网互联互通。登录SAG客户端之后,就可以通过内网IP访问云上资源。
适用于中小数据中心、分支互联、移动办公、应用加速及混合云等场景。详见:https://www.aliyun.com/product/smartag 云服务器 ECS:云服务器 ECS(Elastic Compute Service)是一种简单高效、处 理能力可弹性伸缩的计算服务。帮助您构建更稳定、安全的应用,提升运维效率,降低 IT 成 本,使 您 更 专 注 于 核 心 业 务 创...
轻量级GPU部署云游戏最佳实践
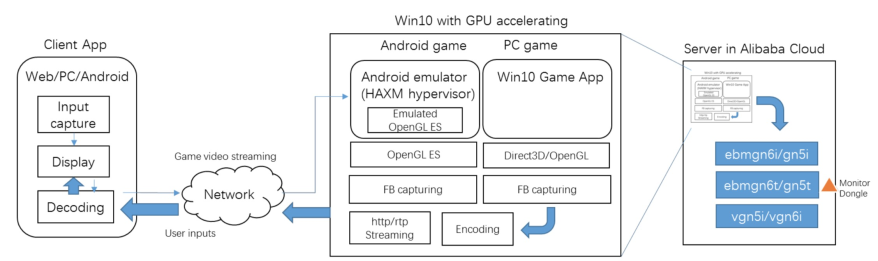
随着AI深度学习,视频处理,科学计算以及图形可视化等应用场景的普及,GPU的市场需求越来越大,但单颗物理GPU起步至超大规模弹性计算带来的计算能力过剩成本上升问题也越来越明显。轻量级GPU的诞生打破了传统直通模式的局限,可以提供比单颗物理GPU更细粒度的服务,从而让客户以更低成本、更高弹性开展业务。
且本地设备无要求 云游戏厂商对服务器核心诉求:ᅳ 重资产交给云厂并弹性管理 ᅳ 低成本带渲染能力的异构机型 随着 5G移动通信业务的快速展开,云游戏发展最大障碍的带宽和延时因素得以消除,基于云端计算的云游戏将迎来春天。基于轻量级 GPU,仅需要一颗物理 GPU几分之 一的计算能力即可流畅完成图形或视觉计算,提升系统...
利用低成本链路完成业务数据迁移上云
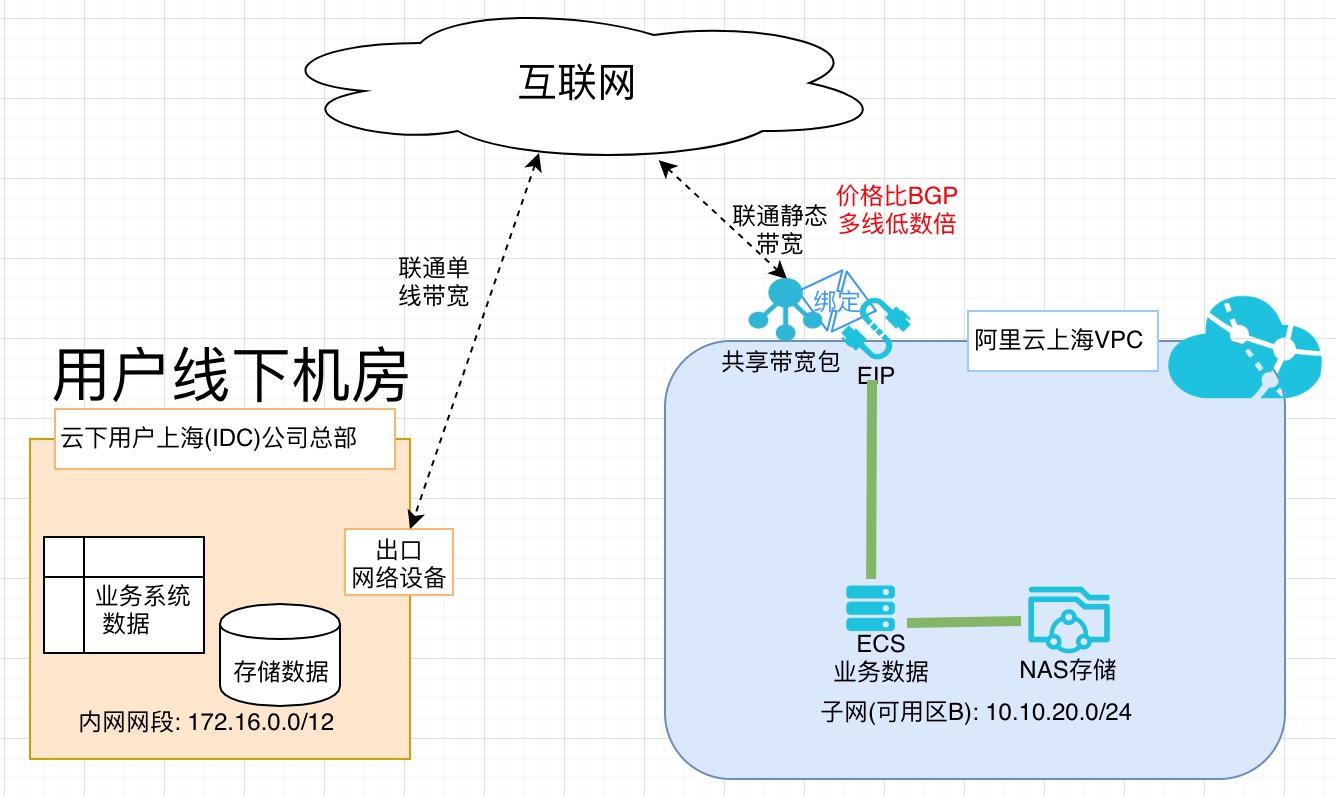
场景描述 随着云计算被越来越多的客户所接受,除业务系 统上云外,很多客户已经把业务数据搬迁上云。 业务数据量一般都比较大,迁移上云需要大量的 网络带宽,BGP费用比较高。阿里云对用户开 放所需地域购买静态单线共享带宽包的权限(移 动/联通/电信均可),可用为迁移数据有效降低 成本。 解决问题 1.业务数据上云网络成本高 产品列表 专有网络VPC 云服务器ECS 网络存储NAS 共享带宽包
阿里云对用户开 放所需地域购买静态单线共享带宽包的权限(移 动/联通/电信均可),可用为迁移数据有效降低 成本。解决问题 1.业务数据上云网络成本高 产品列表 专有网络VPC 云服务器ECS 网络存储NAS 共享带宽包 文档版本:20191010(发布日期)云服务器ECS(产品名称)文档模板(手册名称)/文档版本信息 阿里...
云速搭部署 NAS 文件系统

本实践通过云速搭构建一个 NAS,并将 NAS 文件系统挂载到 ECS 的目录上。
专有网络由逻辑网络设备(如虚拟路由器,虚拟 交换机)组成,可以通过专线/VPN等连接方式与传统数据中心组成一个按需定 制 的 网 络 环 境,实 现 应 用 的 平 滑 迁 移 上 云。详 见:https://www.aliyun.com/product/vpc 云服务器 ECS:云服务器 ECS(Elastic Compute Service)是一种简单高效、处理能力可弹性伸缩的计算...
云速搭部署 ALB 实现负载分发

本实践通过云速搭构建一个基于 http(s)的负载均衡业务架构,实现终端浏览器发起http(s)请求后,经过 ALB 监听配置的转发规则,分别负载分担到后端 ECS 服务器、CLB 和 ACK 集群。
专有网络由逻辑网络设备(如虚拟路由器,虚拟 交换机)组成,可以通过专线/VPN等连接方式与传统数据中心组成一个按需定 制 的 网 络 环 境,实 现 应 用 的 平 滑 迁 移 上 云。详 见:https://www.aliyun.com/product/vpc 云服务器 ECS:云服务器 ECS(Elastic Compute Service)是一种简单高效、处理能力可弹性伸缩的计算...
云速搭部署 EIP 实现共享带宽/流量包管理

本实践通过云速搭设计、部署一个“ECS+EIP+共享带宽”架构,多个 EIP 可以使用共享带宽的资源。
专有网络由逻辑网络设备(如虚拟路由器,虚拟交 换机)组成,可以通过专线/VPN等连接方式与传统数据中心组成一个按需定制的 网络环境,实现应用的平滑迁移上云。详见:https://www.aliyun.com/product/vpc 弹性公网 IP:弹性公网 IP是独立的公网 IP资源,可与阿里云专有网络 VPC类型 的云服务器 ECS、NAT网关、ENI网卡、私...
云速搭部署SLS实现日志采集处理分析

通过云速搭部署ECS+SLS,在ECS上安装logtail收集Nginx应用日志写入SLS。通过日志生成器模拟Nginx日志生成,并通过SLS进行日志分析。
专有网络由逻辑网络设备(如虚拟路由器,虚拟 交换机)组成,可以通过专线/VPN等连接方式与传统数据中心组成一个按需定 制 的 网 络 环 境,实 现 应 用 的 平 滑 迁 移 上 云。详 见:https://www.aliyun.com/product/vpc 云服务器 ECS:云服务器 ECS(Elastic Compute Service)是一种简单高效、处理能力可弹性伸缩的计算...
大数据近实时数据投递MaxCompute
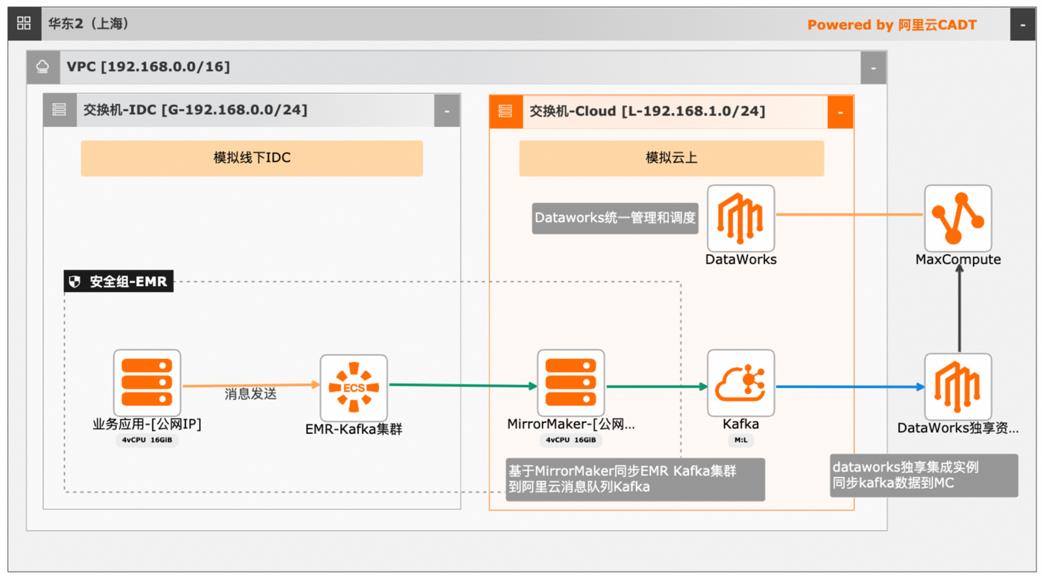
本文介绍离线大数据场景使MaxCompute构建云 上近实时数仓,打通云下数据上云链路,解决数据复杂类型支持和动态分区问题,满足高级数据处理需求的最佳实践。 l混合云环境下,现有业务系统零改造,打通数据上云链路。 l使用UDF实现复杂数据类型转换和数据动态分区。 l使用DataWorks配置周期调度业务流程,数据自动入仓。 l借助MaxCompute优化计算引擎,实现降本增效。 产品列表 云服务器ECS 专有网络VPC 访问控制RAM 数据总线DataHub E-MapReduceEMR DataWorks 大数据计算服务MaxCompute
使用 DataWorks配置周期调度业务流程,数据自 产品列表 动入仓。借助 MaxCompute优化计算引擎,实现降本增 云服务器 ECS 效。云消息队列 Kafka 最佳实践频道 阿里云最佳实践分享群 E-MapReduce EMR DataWorks 大数据计算服务 MaxCompute 云速搭 CADT 文档模板(手册名称)/Error!Use the Home tab to apply 云服务器 ECS...
DTS数据同步集成MaxCompute数仓
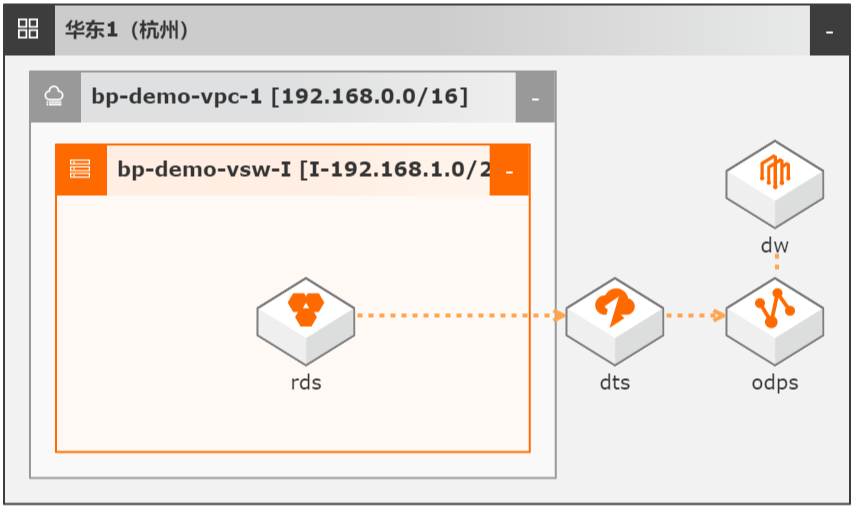
场景描述 本文Step by Step介绍了通过数据传输服务 DTS实现从云数据库RDS到MaxCompute的 数据同步集成,并介绍如何使用DTS和 MaxCompute数仓联合实现数据ETL幂等和数 据生命周期快速回溯。 解决问题 1.实现大数据实时同步集成。 2.实现数据ETL幂等。 3.实现数据生命周期快速回溯。 产品列表 MaxCompute 数据传输服务DTS DataWorks 云数据库RDS MySQL 版
基于阿里云创建的自定义私有网络,不 同的专有网络之间二层逻辑隔离,可以在自己创建的专有网络内创建和管理云产 品实例,比如 ECS、负载均衡、RDS等。在创建前,您需要结合具体业务,规划 VPC和交换机的数量及网段等。更多信息,请参见:https://www.aliyun.com/product/vpc 文档版本:20220126(发布日期)III DTS数据同步...
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
文档版本:20210425 30 自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 Hive数据迁移 Hive元数据中的表、分区等信息均带有 Location信息,以 DFSnameservices作为前例 如截图中的 hdfs:/master:9000/。使用下面命令可以查询转储文件中的 Location信 息:grep-i 'hdfs' hive_databases.sql 步骤3 订正转储文件中的 ...
- 产品推荐
- 这些文档可能帮助您