基于MSE云原生网关同城多活
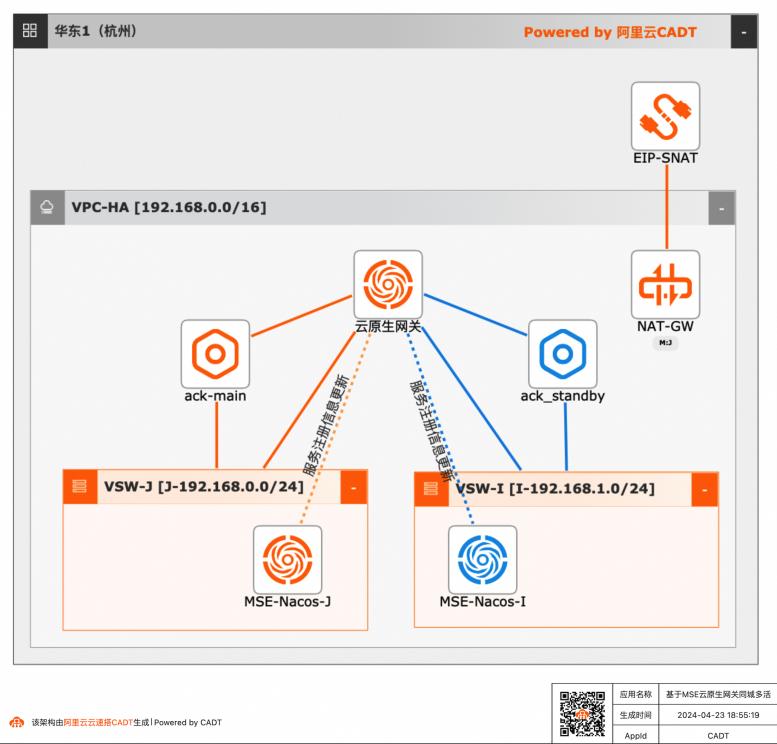
借助云原生微服务MSE网关,MSE配置注册中心的同城容灾多活微服务应用。构建一个经典的微服务场景,实现同城容灾的步骤,体现云原生相关产品在用户上云,高可用同城容灾多活场景下的能力。
那这时分配给机房 1的流量会自动的从 50%降到 10%,分配给机 房 2的流量会自动的从 50%提升到 90%。文档版本:20240423 V 基于MSE云原生网关同城多活最佳实践 最佳实践概述●流量的精细化管控:每个集群一套注册中心,应用启动的时候只向本可用区的注册 中心注册。这样可以保证微服务调用在可用区内闭环。微服务调用可用区...
企业级云灾备与数据管理
本方案以备份 ECS 文件为例,介绍如何部署一个简单的云灾备环境,以满足常见的数据保护需求。
相关产品云备份 Cloud Backup云服务器 ECS在线咨询方案优势本地机房和公共云混合架构,统一灾备平台无论客户数据是在本地还是公共云,都可以使用云备份进行统一灾备和管理,减少运维投入。冷热数据分层,策略化备份或归档上云使用云备份对客户本地 IDC 热数据如数据库和正在编辑使用的文件,进行策略化备份上云,需要长期...
来自:
解决方案
金融分布式架构SOFAStack
阿里云金融分布式架构SOFAStack为金融用户提供全栈式的基础架构能力,是集项目管理、微服务开发、发布部署、监控运维、容灾高可用等全栈式解决方案,助力客户应用轻松转型分布式架构,保证风险安全的同时帮助业务需求敏捷迭代,支撑金融业务创新,开发人员学习成本最多可降低92%、应用开发效率可最多提升80%、运维人力成本最多可节省90%
基于蚂蚁金服中台战略及架构的最佳实践,将企业级公共能力进行抽象,形成以客户服务、运营服务、分布式架构为基础的业务中台体系,实现开放、可扩展、组件化、分布式的业务架构,支持业务快速、高效、低成本创新,满足互联网场景化快速多变的业务发展需求.将企业级公共能力进行抽象,形成各大能力中心,并沉淀到业务中台,...
来自:
云产品
新零售商超基于Serverless服务化改造
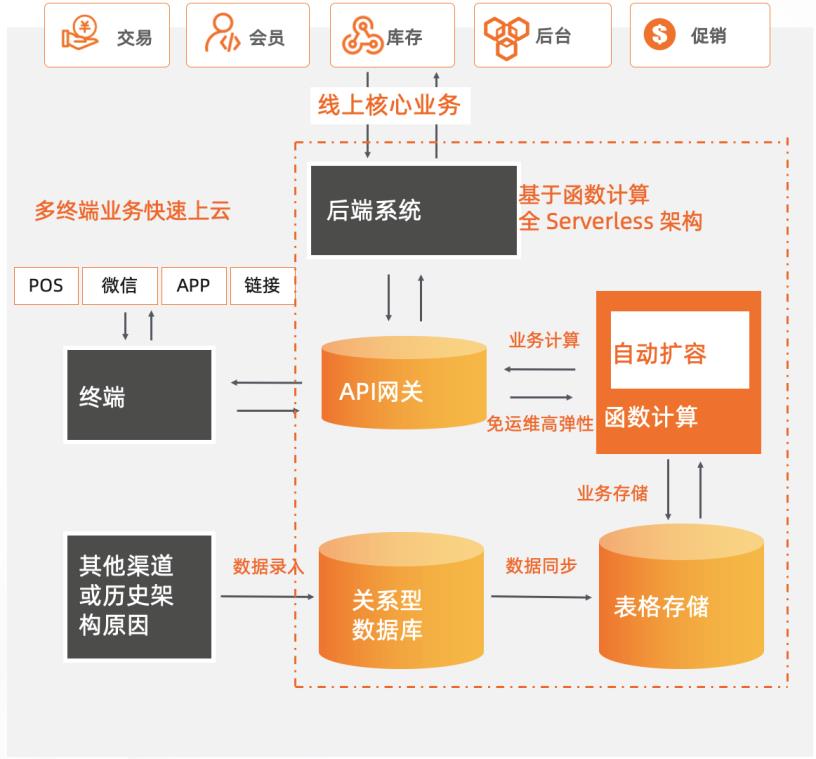
某零售商超行业龙头企业,主要业务涵盖购物中心、大卖场、综合超市、标准超市、精品超市、便利店、无人值守智慧商店等零售业态,涉及全渠道零售、仓储物流、餐饮、消费服务、数据服务、金融业务、跨境贸易等领域。为了持续支持业务高速且稳定地发展,其在快速上云后,将核心业务改造为全Serverless架构的中台模式,采用函数计算 + API网关 + 表格存储OTS 作为计算网络存储核心,弹性支撑日常和大促峰谷所需资源,轻松支撑618/双11/双12大促。 核心价值 l 全 Serverless 架构:FC + API 网关 + OTS Serverless 解决方案。 l 弹性高可用:毫秒级弹性扩容、充足的资源池水位、跨可用区高可用。 l 敏捷开发免运维:函数式极简编程可专注于业务创新,无采购和部署成本、提供监控报警等完备的可观测能力。
是阿里巴巴经济体核心基础设施之一,提供稳定与极致的数据服 务。详见:https://www.aliyun.com/product/ots DTS:支持关系型数据库、NoSQL、大数据(OLAP)等数据源,集数据迁移、订阅 及实时同步功能于一体,能够解决公共云、混合云场景下,远距离、毫秒级异步数 据传输难题。其底层基础设施采用阿里双 11异地多活架构,为...
阿里云云盒
阿里云云盒(Alibaba Cloud CloudBox)是一种可在客户数据中心进行部署公共云产品,让客户能够在本地扩展和运行原生的阿里云云产品服务,可以满足企业数据本地留存和处理、低延时等业务场景需求。同时,云盒还可以与阿里云公共云进行互通和扩展,使客户能够在本地弹性、灵活地使用公共云的产品和服务。
提供本地部署软硬一体的全托管云服务,用户无需自行运维,即可享受和公共云一致的稳定体验.解决因带宽、成本、数据量、时间等因素无法将数据传输到公共云处理的场景.本地数据处理.解决和本地设备、应用程序近实时交互的场景需求.低延时云服务.解决因监管、合规、数据物理隔离的需求,需要将数据部署在园区、机房、或地区内...
来自:
云产品
SLS多云日志采集、处理及分析
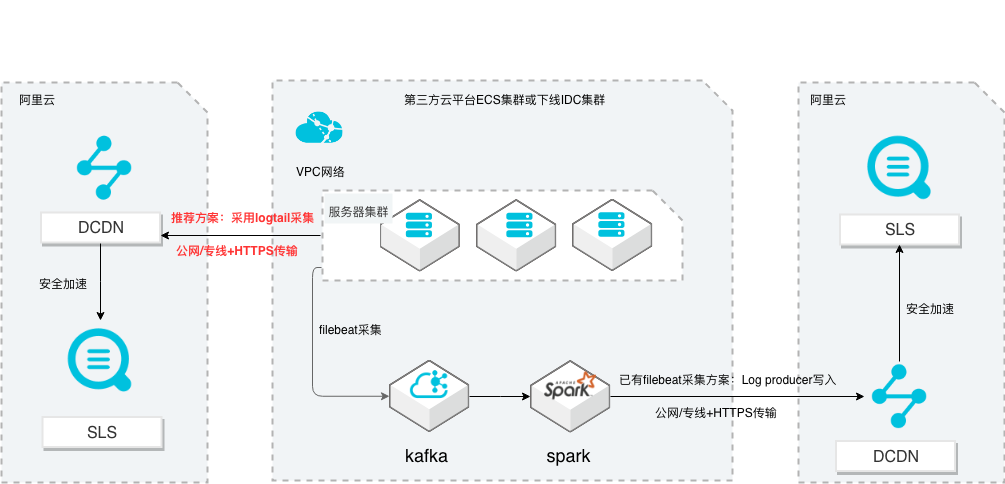
场景描述 从第三方云平台或线下IDC服务器上采集 日志写入到阿里云日志服务,通过日志服务 进行数据分析,帮助提升运维、运营效率, 建立DT 时代海量日志处理能力。 针对未使用其他日志采集服务的用户,推荐 在他云或线下服务器安装logtail采集并使用 Https安全传输;针对已使用其他日志采集 工具并且已有日志服务需要继续服务的情 况,可以通过Log producer SDK写入日志 服务。 解决问题 1.第三方云平台或线下IDC客户需要使用 阿里云日志服务生态的用户。 2.第三方云平台或线下IDC服务器已有完 整日志采集、处理及分析的用户。 产品列表 E-MapReduce 专有网络VPC 云服务器ECS 日志服务LOG DCDN
文档版本:20211203 70 SLS多云日志采集、处理及分析 日志服务器集群公网日志数据传递到日志服务 步骤8 日志服务机器组添加日志服务器 按照本节步骤 1到步骤 6再在杭州区域同一 VPC同一可用区下创建一台 ECS日志服 务器并添加到日志服务机器组。文档版本:20211203 71 SLS多云日志采集、处理及分析 日志服务器集群公网日志...
自建K8S集群迁移ACK弹性裸金属集群
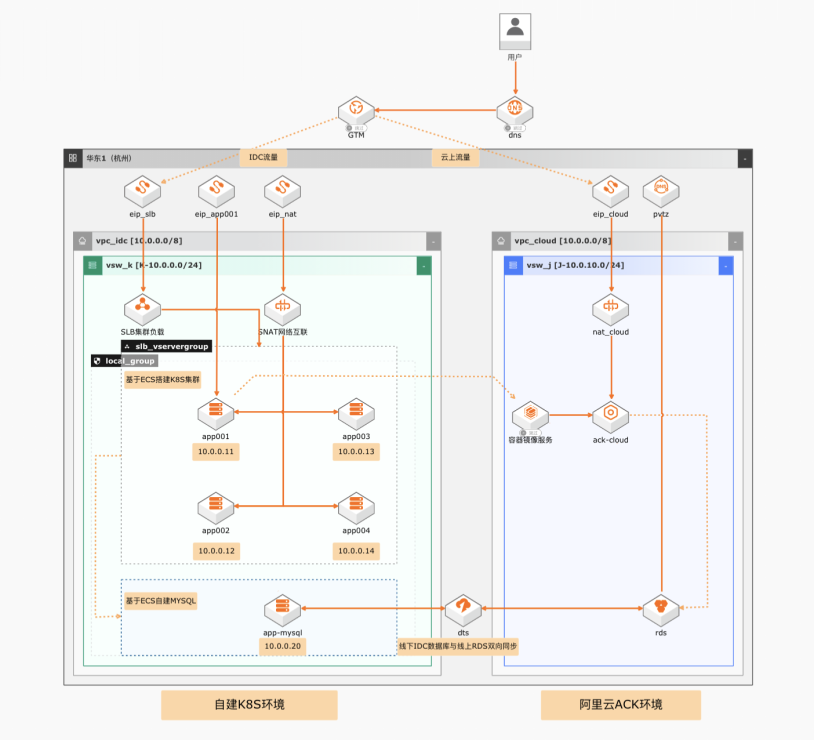
场景描述 在微服务化改造之后,企业在享受K8S带来应 用管理的便利的同时,存在硬件性能不足,本 地扩展性差,容器容灾难,K8S管理复杂等问 题。 解决问题 1.增强K8S扩展性:如何通过弹性裸金属服务 器的强劲硬件性能,实现云端资源急速扩 展,从容应对应用访问压力大的问题。 2.如何简化云端K8S运维:通过阿里云容器服 务(ACK)实现敏捷开发和部署落地,加速 企业业务迭代。 3.如何综合考虑迁移和容灾:如何整合云上和 云下容器资源实现遇到故障时可以通过健 康检查实现自动容灾。 4.如何不改应用上云:如何实现应用上云数据 库连接零修改。 5.数据库上云及回退:如何实现上云回退; 产品列表 ACK/ECS/SLB/NAT网关/弹性裸金属服务器/DTS/RDS MySQL
遇到线下 IDC机房过保或其他全量上云场景时可以通过修改全局流量管 理统一管理的访问策略实现一键上云,也可以通过对用户地理位置的甄别实现流 量/用户分批上云。不改应用:应用通过域名访问数据库,云上环境通过 PrivateZone实现数据库域名 解析 RDS域名,实现应用上云数据库连接零修改。云上云下并行场景下,数据库层面...
云原生应用迁云解决方案
云原生应用迁云解决方案可将数百个服务以云原生的方式平滑迁移上云,相比普通的整体迁云方案,本方案平滑迁移复杂但是对业务影响小。阿里云容器服务以可靠稳定的IaaS平台为底座,将用户未容器化应用、容器化应用、K8s应用平滑地迁移到容器服务ACK上,保证用户业务可靠性、稳定性、安全性和灵活性。
云服务器ECS.对象存储 OSS.日志服务 SLS.负载均衡 SLB.搞定复杂平滑迁移,对业务影响小,自研工具库提高迁云效率.极大保证用户业务的可靠性、稳定性、安全性和灵活性.分时间阶段、分业务角色,提供了企业容器化生命周期模型.应用进一步优化适配,提供更强大的扩展能力.本方案可将数百个服务以云原生的方式平滑迁移上云。ACK...
来自:
解决方案
企业级互联网架构解决方案
企业级互联网架构解决方案是在阿里巴巴电商业务环境沉淀下来的互联网中间件,其优秀的架构设计理念,以及大型分布式系统数据化运营能力,帮助企业用户快速构建大型分布式应用,支持业务需求快速创新,助力传统企业快速互联网+转型。
免费的容器架构可视化工具>.Nginx 外的另一选择,轻量级开源 Web 服务器>.压测环境的设计和搭建>.阿里巴巴中间件在 Serverless 技术领域的探索>.提升不止一点点,Dubbo 3.0 预览版详细解读>.建立共享业务服务中心.如“会员”、“商品”,自己掌握信息系统的主动权,可以快速迭代试错,满足业务变化的需求.零售云统一...
来自:
解决方案
云消息队列 RocketMQ 版
云消息队列 RocketMQ 版是基于 Apache RocketMQ 构建的分布式消息中间件,广泛用于异步解耦、削峰填谷等场景。可支撑千万级并发、万亿级数据洪峰,更稳定,更安全。
通过上、下游业务系统的松耦合设计,即便下游子系统(如物流、积分等)出现不可用甚至宕机,都不会影响到核心交易系统的正常运转.高可用松耦合架构设计.商场如战场,通过 RocketMQ 的异步化设计,可以灵活高效的适应因业务快速发展而带来的变化,如新增业务系统.灵活适应业务的快速增长.云消息队列 MQ.推荐搭配使用.诸如...
来自:
云产品
MaxCompute湖仓一体方案
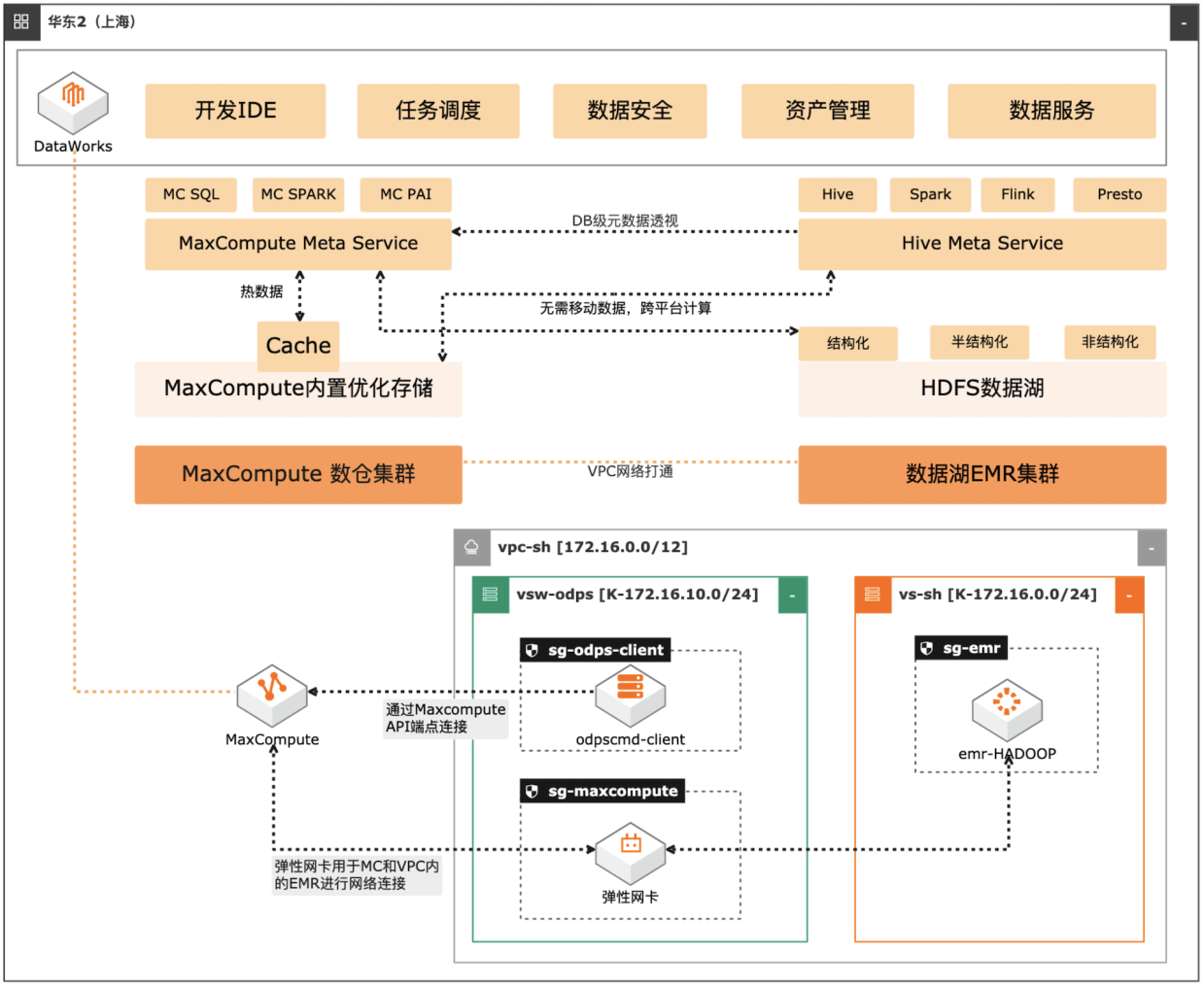
场景描述 自建数据湖与云数仓的融合解决方案,将 MaxCompute与自建的Hive集群做数据打 通,通过存储共享,元数据镜像等方式,解 决传统模式下的存储冗余,计算资源弹性能 力弱的痛点。可大幅度增强系统的资源弹 性,解决业务高峰期计算资源不足的问题。 方案优势 1.业务无侵入性:现有业务无需改造。 2.性能优化:MaxCompute在SQL上做 了大量优化与能力沉淀,可提高SQL 运行性能,降低计算成本。 3.灵活管理:元数据实时同步,无需额外 管理数据同步任务。 4.资源弹性:利用MaxCompute计算池 弹性进行海量数据计算。 解决问题 1.增强业务高峰期的资源弹性。 2.优化自建数据湖的数据治理能力。 3.减少跨平台数据处理的存储冗余。 产品列表 专有网络VPC 云服务器ECS 访问控制RAM 运维编排OOS MaxCompute(原ODPS) 云企业网CEN
2.MaxCompute端创建外部项目,镜像 Hive元数据,可以直接访问 Hive元数据服 务,并将元数据信息映射到 MaxCompute的外部项目(External Project)中 操作流程 1.资源创建:使用阿里云速搭 CADT一键完成业务部署图中的云资源创建,部分暂 时不支持 CADT拉起的资源,需要手动在控制台创建和配置,如 DataWorks工作 空间。2....
- 产品推荐
- 这些文档可能帮助您