基于函数计算FC实现阿里云Kafka消息轻量级ETL处理
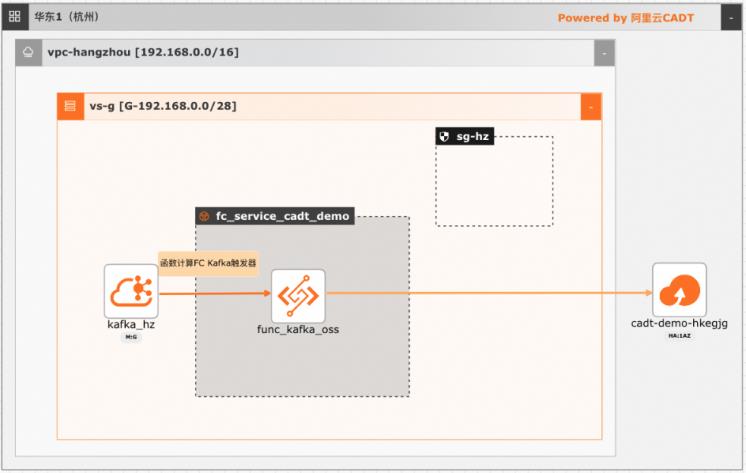
在大数据ETL场景,Kafka是数据的流转中心,Kafka中的数据一般是原始数据,可能存在多种数据混杂的情况,需要进一步做数据清洗后才能进行下一步的处理或者保存。利用函数计算FC,可以快速高效的搭建数据处理链路,用户只需要关注数据处理的逻辑,数据的触发,弹性伸缩,运维监控等阿里云函数计算都已经做了集成,函数计算FC也支持多种下游,OSS/数据库/消息队列/ES等都可以自定义的对接
(这里有异步调用和同步调用两种方式,为了能快速消费消 息,这里选择异步调用,并且两种调用方式的正文负载大小不同,同步调用为 32MB,异步调用为 128KB)触发器启用状态:勾选 批量推送:默认关闭。(可以选择开启,然后可以设置批量推送的条数,批量推送 间隔,根据需求选择是否批量推送)推送格式:RawData(也可以...
通过ES兼容接口方式使用Kibana访问SLS数据
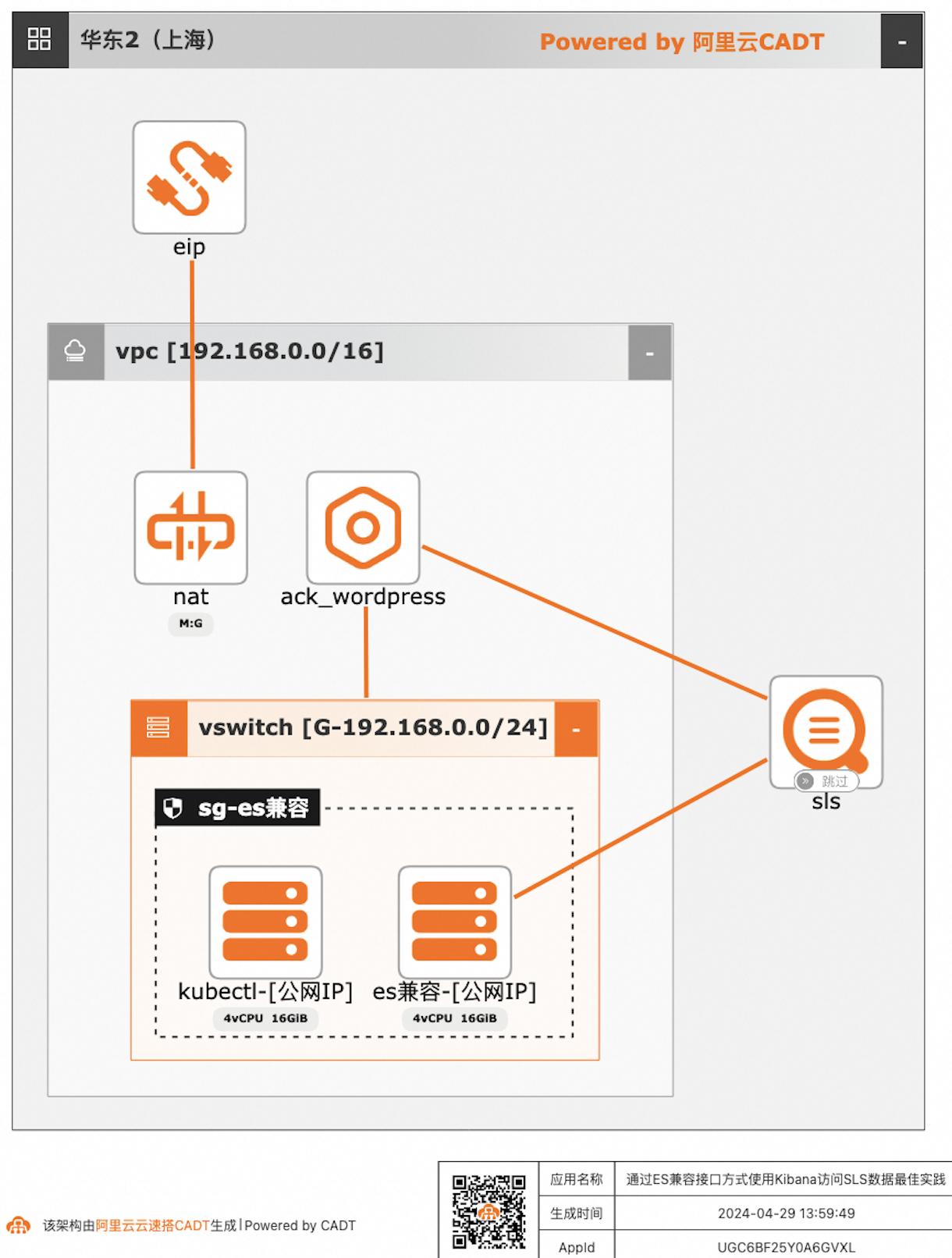
自建ELK日志系统的客户迁移到阿里云日志服务SLS后,对SLS查询分析语法不太熟悉的客户,可以继续沿用原有的查询分析习惯,在不改变使用方式习惯的情况下,通过Elasticsearch兼容接口的方式使用Kibana访问SLS。
通过ES兼容接口方式使用Kibana访问SLS数据最佳实践 业务架构 场景描述 日志服务SLS提供Elasticsearch兼容接口,支 持客户将日志采集到日志服务后,仍可以继续沿 用Elasticsearch的查询方案,即通过使用 Kibana访问日志服务的Elasticsearch兼容接 口,实现查询SLS数据。应用场景 自建ELK日志系统的客户迁移到阿里云日志服 务...
基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步
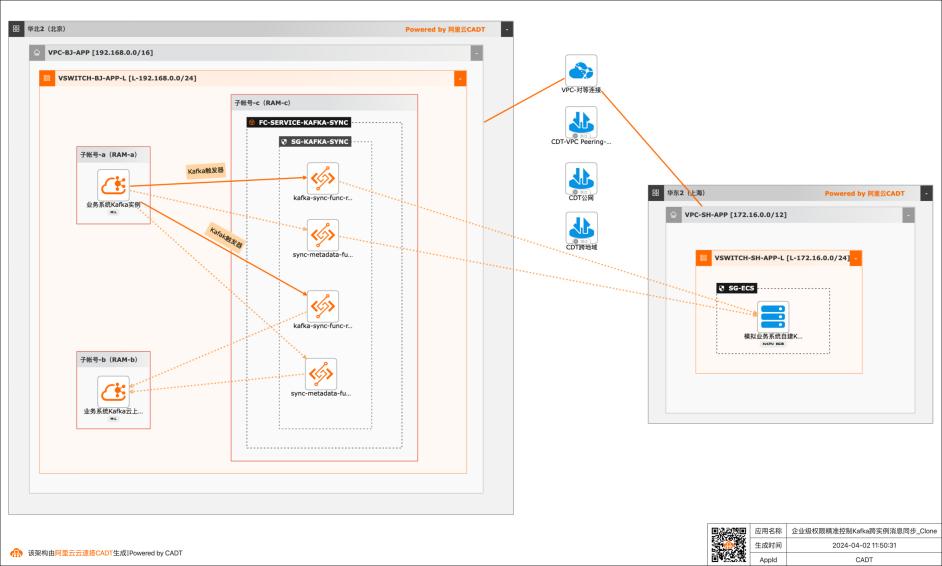
应用场景 在大数据场景,企业的Kafka实例可能存在多种情况,比如使用阿里云Kafka服务,可能是自建开源Kafka,或者是其他云上的云Kafka。不同的业务使用不同类型的Kafka实例,在这个前提下Kafka实例之间可能会需要消息同步的情况: 同帐号容灾场景:比如Kafka实例都是阿里云Kafka,但是Kafka实例会有主备之分,需要将主Kafka实例的消息实时同步到备Kafka。 跨帐号或异地容灾:这类场景比如主Kafka是阿里云Kafka,备Kafka是IDC开源自建Kafka,或者是其他云上的Kafka。 不同业务之间消息同步:因为现在的业务通常不会是信息孤岛,都需要消息互通,所以可能是A业务的Kafka实例消息需要同步到B业务的Kafka实例,并且这两个Kafka实例归属不同的RAM角色,有自己独自的权限控制。 解决问题 解决使用开源组件做消息同步的高成本问题。 解决使用开源组件做消息同步的并发性能、稳定性问题。 解决使用开源组件做消息同步的可靠性问题(重试机制,容错机制,死信队列等)。 大幅提升构建消息同步架构的效率,降低构建复杂度问题。
(这里有异步调用和同步调用两种方式,为了能快速消费消 息,这里选择异步调用,并且两种调用方式的正文负载大小不同,同步调用为32MB,异步调用为128KB) 触发器启用状态:勾选 批量推送:默认关闭。(可以选择开启,然后可以设置批量推送的条数,批量推送 间隔,根据需求选择是否批量推送) 推送格式:RawData(也...
基于函数计算FC实现阿里云Kafka消息内容控制MongoDB DML操作
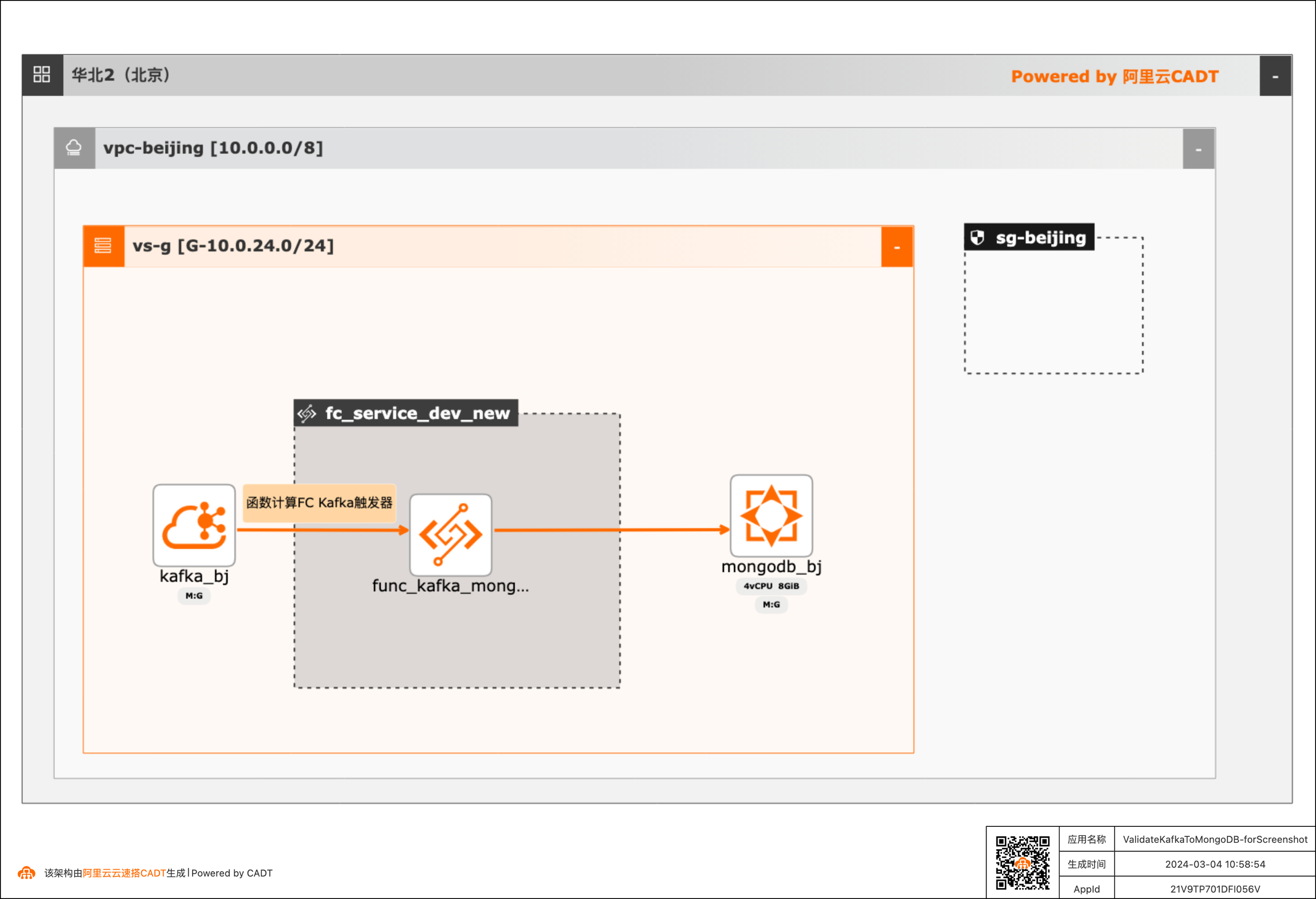
在大数据ETL场景,将Kafka中的消息流转到其他下游服务是很常见的场景,除了常规的消息流转外,很多场景还需要基于消息体内容做判断,然后决定下游服务做何种操作。 该方案实现了通过Kafka中消息Key的内容来判断应该对MongoDB做增、删、改的哪种DML操作。 当Kafka收到消息后,会自动触发函数计算中的函数,接收到消息,对消息内容做判断,然后再操作MongoDB。用户可以对提供的默认函数代码做修改,来满足更复杂的逻辑。 整体方案通过CADT可以一键拉起依赖的产品,并完成了大多数的配置,用户只需要到函数计算和MongoDB控制台做少量配置即可。
l 云消息队列 Kafka 版:云消息队列 Kafka 版是阿里云提供的分布式、高吞吐、可扩展的消 息队列服务。云消息队列 Kafka 版广泛用于日志收集、监控数据聚合、流式数据处理、在 线和离线分析等大数据领域,已成为大数据生态中不可或缺的部分。l 云数据库 MongoDB 版(ApsaraDB for MongoDB):完全兼容 MongoDB 协议,基于...
SLS数据入湖Kafka最佳实践
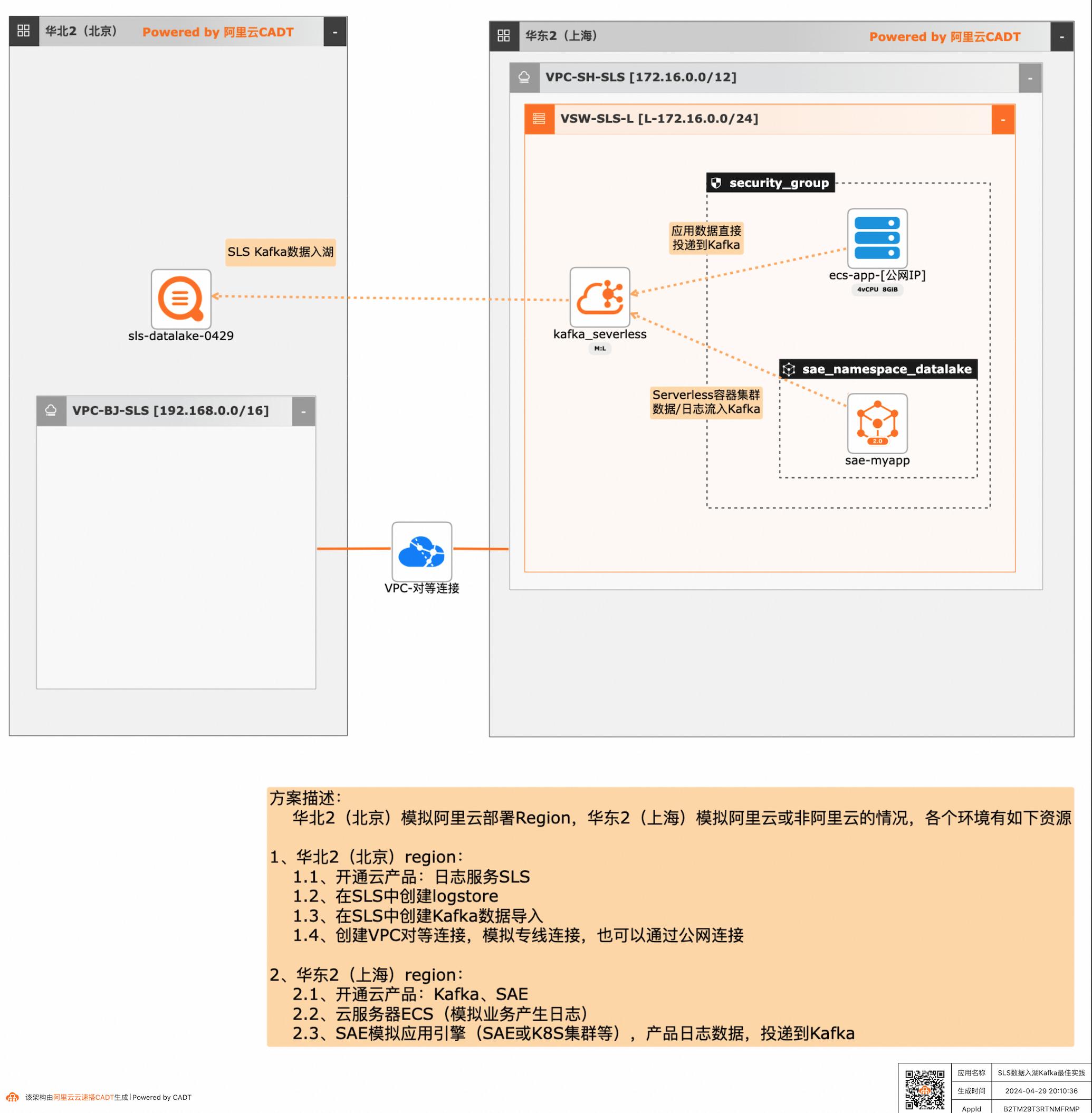
应用和数据分散在多云或混合云,在面对多云/混合云这样大的趋势下,数据无法进行统一的聚合、分析处理和导出等,本方案给出了在多云/混合云场景下,构建通过标准的Kafka协议和托管服务,SLS可以连接Kafka数据入湖导入,然后进行统一的海量数据的集中存储、智能转储、聚合分析查询等。
云消息队列Kafka版:是阿里云基于ApacheKafka构建的高吞吐量、高可扩 展性的分布式消息队列服务,广泛用于日志收集、监控数据聚合、流式数据处 理、在线和离线分析等场景,是大数据生态中不可或缺的产品之一,阿里云提 供全托管服务,用户无需部署运维,更专业、更可靠、更安全. Serverless应用引擎SAE...
云消息队列 Confluent 版
云消息队列 Confluent 版是阿里云与 Apache Kafka 项目创始团队所创立的 Confluent 公司合作,基于 Apache Kafka 核心能力提供的企业级全托管消息队列服务,旨在为企业提供集成消息流式处理与大数据系统的一站式解决方案。
快速使用云消息队列 Confluent 版.云消息队列 Confluent 版所有文档.云消息队列 Confluent 版计费说明.阿里云与 Confluent 专家技术交流.Apache Kafka 全托管消息服务,大数据生态中不可或缺的消息产品,具备开箱即用、无缝迁移、安全可靠、免运维等特点.云消息队列 Kafka 版.阿里巴巴官方指定消息产品,成熟、稳定、先进的...
来自:
云产品
RocketMQ性能压测快速方案
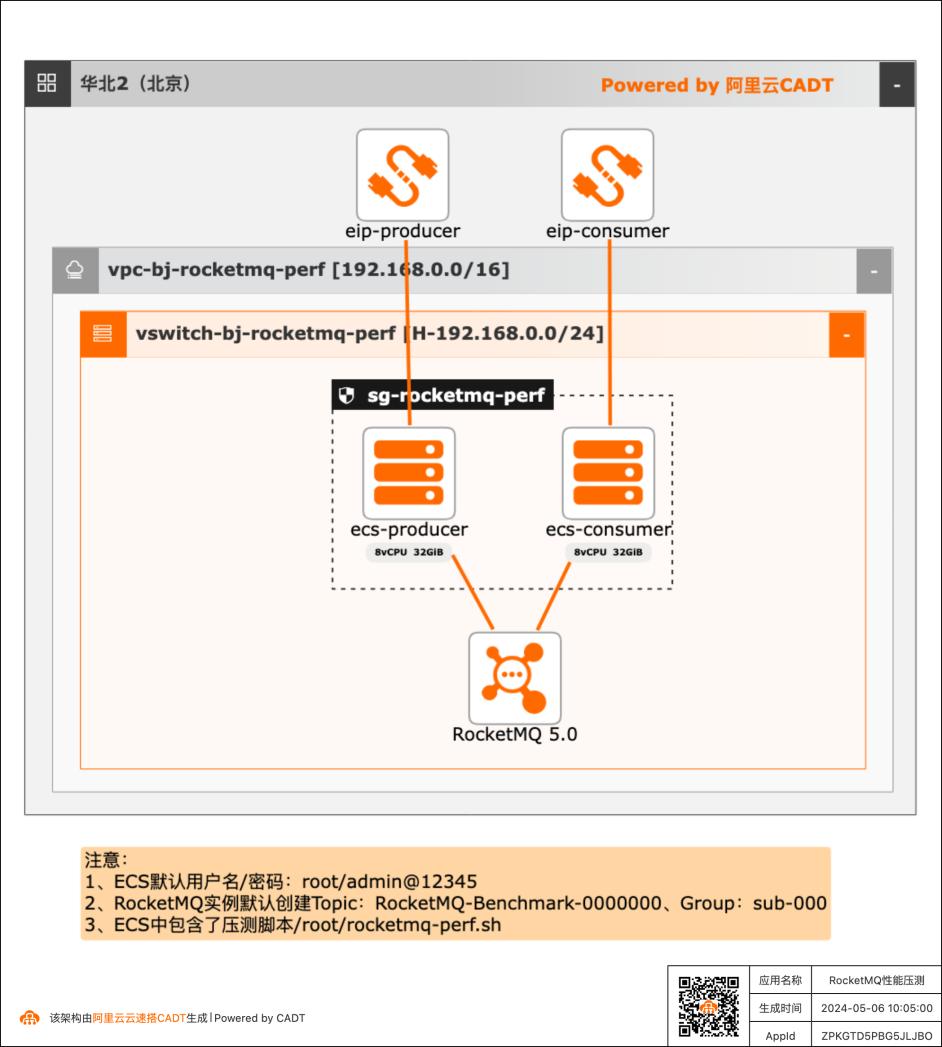
在客户对产品性能存疑或者给客户进行POC验证时可以用本实践来快速完成性能测试。
一键释放资源.29 文档版本:20240506 IIIRocketMQ性能压测快速方案 最佳实践概述 最佳实践概述 方案概述 消息队列RocketMQ5.0版提供多种消息收发实例规格,在创建实例时按照消息读写 TPS总和选择满足业务的规格大小,本实验进行性能压测,来验证实例的消息读写 TPS能力是否符合规格定义的TPS峰值大小。应用场景 借助CADT...
Kafka性能压测快速方案
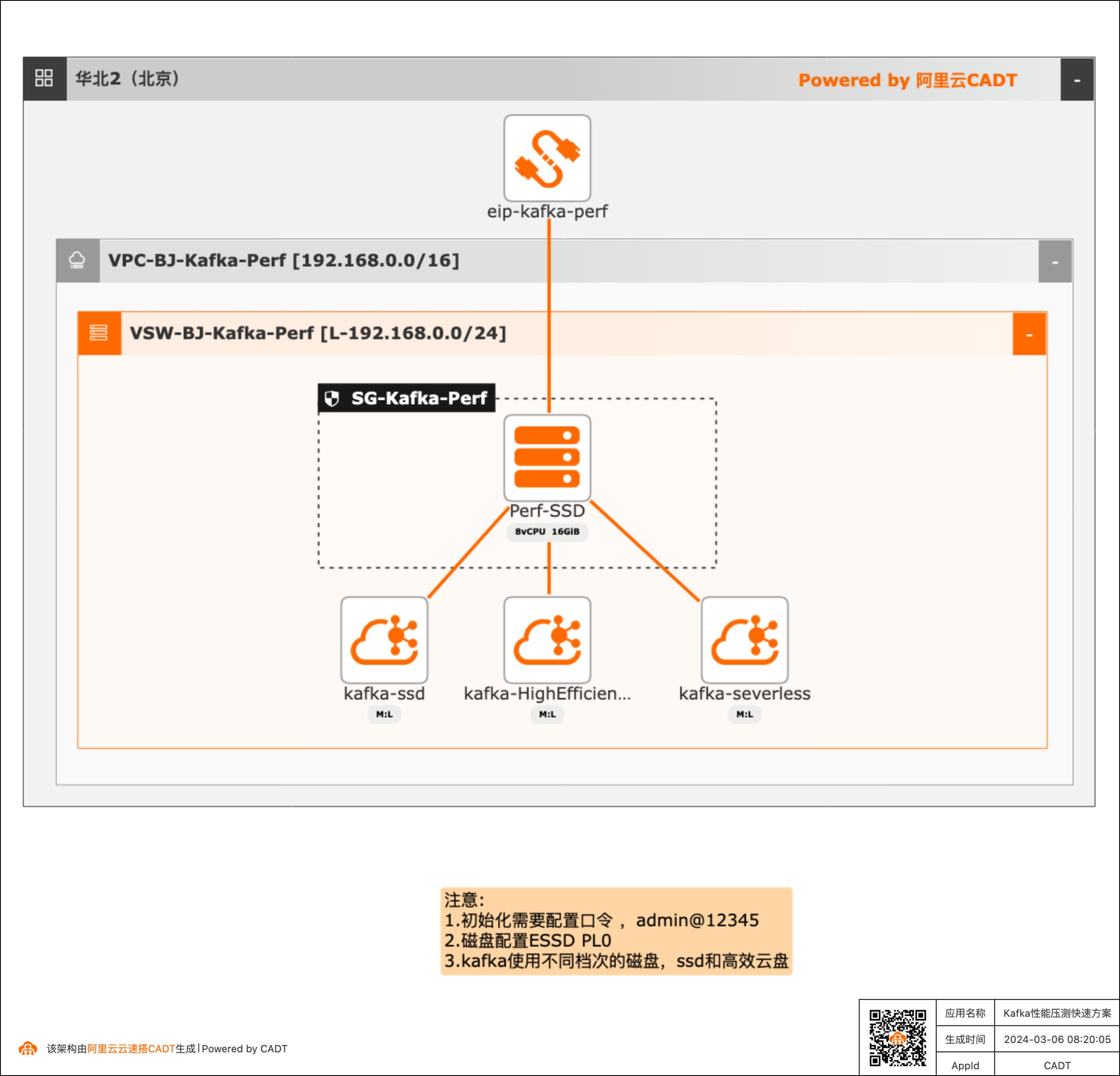
产品性能基线测试场景需要对产品进行性能测试得到详细的压测数据,本方案可以快速构建测试的客户端(kafka官方的压测客户端)和不同的Kafka服务端( SSD云盘版、高效云盘、Serverless版三种实例),方便客户进行POC完成性能验证。
实例版本(创建时指定规格)可以提 供与开源Kafka完全兼容的接口和能力。 消息队列Kafkaserverless 云托管的kafka服务Serverless版本(按照预留量+实际流量进行计费)文档版本:20240229 6基于MSE云原生网关同城多活最佳实践 前置条件 前置条件 在进行本文操作之前,您需要完成以下准备工作: 注册阿里云账号,并完成...
云消息队列 MQTT 版
云消息队列 MQTT 版是专为移动互联网(MI)、物联网(IoT)领域设计的消息产品,覆盖直播互动、金融支付、智能餐饮、即时聊天、移动 Apps、智能设备、车联网等多种应用场景;通过对 MQTT、WebSocket 等协议的全面支持,连接端云之间的双向通信,实现 C2C、C2B、B2C 等业务场景之间的消息通信,可支撑千万级设备与消息并发。
可支撑千万级设备在线连接,百万级消息并发,万亿级消息流转,毫秒级消息推送;分布式理念进行设计,无单点瓶颈,各组件之间均可以无限水平扩展,确保容量可弹性伸缩,并对用户透明.支持设备级权限控制,支持临时 Token 服务以及 SSL/TLS 传输加密通信,确保用户数据安全可靠.可以支持云消息队列 MQTT 版和云消息队列 ...
来自:
云产品
云消息队列 Kafka 版
云消息队列 Kafka 版是阿里云基于Apache Kafka构建的大数据消息中间件,广泛用于日志收集和分析、数据处理等场景。可提供全托管服务,用户无需部署运维,更专业、更可靠、更安全。
骑士卡:基于 Kafka 搭建消息中心,上亿消息推送轻松完成.开源自建 Kafka 运维投入大,在大规模场景下稳定性无法保障,开源 bug 没有解决,同时 SLA 无法保障。而阿里云云消息队列 Kafka 对产品内核进行全方位优化,解决开源产品长期以来的痛点,免运维、低成本、更稳定、大数据领域优选数据通道.小麦助教:通过阿里云原生...
来自:
云产品
云消息队列 RabbitMQ 版
云消息队列 RabbitMQ 版是阿里云打造的云消息服务,广泛用于海量队列分发、分布式定时任务等场景。支持 AMQP 协议,开箱即用,轻松实现快速上云,更专业、更可靠、更安全。
商业版提供强大的监控告警能力,有丰富的 Prometheus 指标,包括实例、Vhost、Exchange、Queue 维度查看的消息速率、消息堆积量、当前连接数、Channel 数、每个接口的请求 QPS 等.云消息队列 RabbitMQ 版.支持所有版本和语言开源客户端.Erlang 语言实现的,排查问题困难;\ 高可用的部署模式是非集群横向可扩展的架构,有...
来自:
云产品
云消息队列 ApsaraMQ
云消息队列 ApsaraMQ 是阿里云自主研发的消息队列服务系列产品的总称,旨在为开发者和企业的不同业务场景提供强大、可靠、低成本、高弹性且易于管理的消息服务。云消息队列 ApsaraMQ 全系列产品提供 Serverless 化的消息服务,按实际使用量付费,自适应弹性,跨可用区容灾,帮助客户降低使用和维护成本,专注业务创新。
RocketMQ系列课:5.0新版本消息收发原理解析.RocketMQ系列课:5.0新版本可观测能力详解.RocketMQ系列课:5.0新版本弹性运维系列.RocketMQ系列课:生产实战监控告警.查看更多商品.ApsaraMQ 产品选型.云消息队列 RocketMQ 版是阿里云基于 Apache RocketMQ 构建的低延迟、高并发、高可用、高可靠、高弹性的分布式“消息、事件...
来自:
云产品
云消息队列 RocketMQ 版
云消息队列 RocketMQ 版是基于 Apache RocketMQ 构建的分布式消息中间件,广泛用于异步解耦、削峰填谷等场景。可支撑千万级并发、万亿级数据洪峰,更稳定,更安全。
云消息队列 RocketMQ 版 Serverless 系列资源包重磅上线!存储空间无法自由弹性伸缩,空间不足会导致清理数据;多副本存储成本高.基于集群水位规划机器:·需要预留水位,且缩容复杂;受扩容速度限制,无法支持突发流量弹性.手工命令行操作运维,成本高,风险大;缺少配套可观测监控体系.自行运维保障,需要资深技术人员...
来自:
云产品
Function Compute构建高弹性大数据采集系统
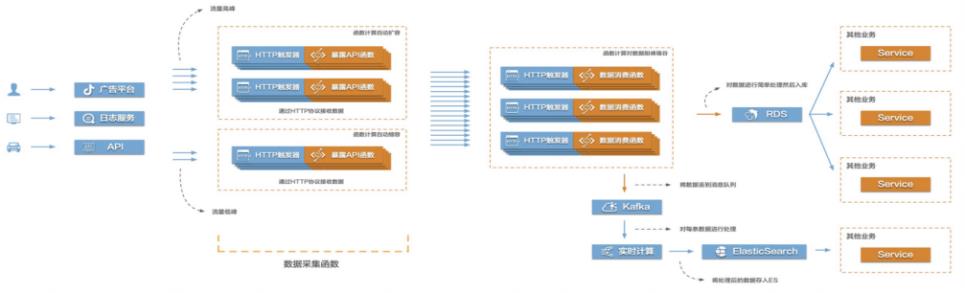
当前互联网很多场景都存在需要将大量的数据信息采集起来然后传输到后端的各类系统服务中,对数据进行处理、分析,形成业务闭环。比如游戏行业中的游戏发行、游戏运营,产互行业中的数字营销,物联网、车联网行业中的硬件、车辆信息上报等等。这些场景普遍存在数据采集量大、数据传输需要稳定且吞吐量大的特点,给整个数据采集传输系统带来很大的挑战。在这个场景中,有三个关键的环节,数据采集、数据传输、数据处理。该最佳实践主要涉
那么接下来,我们接受如何测试这个接口的性能。这里我们采用 PTS工具,来压测这个接口。这里仅展示压测的方法。之前,我们已经在 CADT的模板中,购买了 PTS压测包。步骤1 登录 PTS的控制台。(https://common-buy.aliyun.com)步骤2 从左侧导航栏选择创建场景>创建 PTS场景,在创建 PTS场景页面,完成以下配 置:填写场景...
开源Flink迁移实时计算Flink全托管版最佳实践
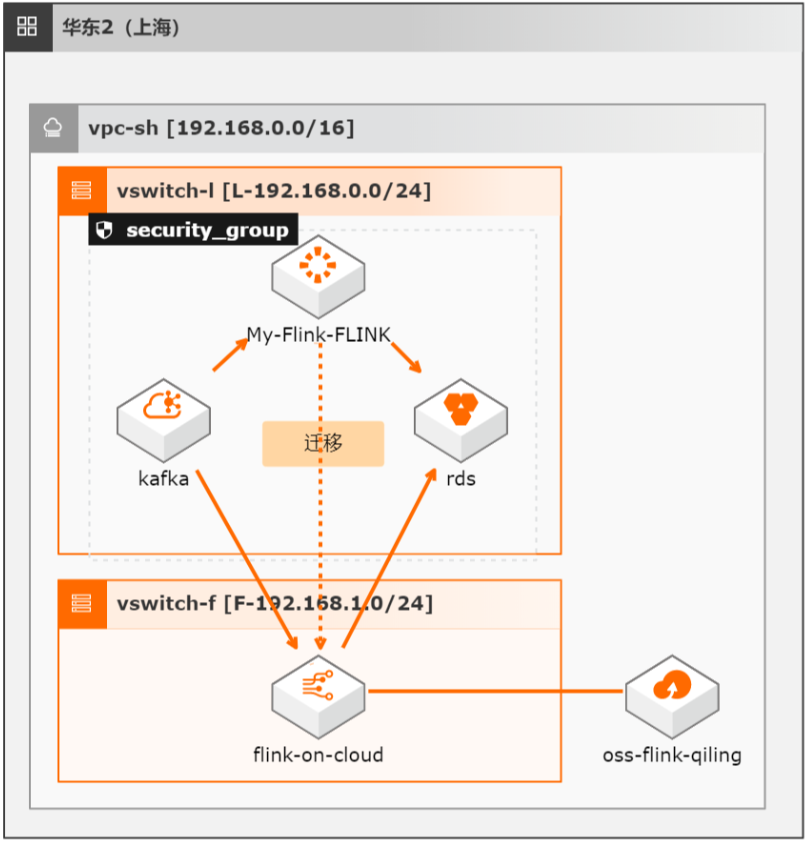
本方案介绍如何将自建开源Flink集群的流式任务(包含Datastream、Table/SQL、PyFlink任务)迁移至阿里云实时计算全托管版。
文档版本:20211222 12 开源 Flink迁移实时计算Flink全托管版 基础环境搭建 步骤2 在 Flink SQL中添加以下作业,注意修改 properties.bootstrap.servers为前面创建 的 kafka的接入点。CREATE TEMPORARY TABLE data_in(id VARCHAR,order_value FLOAT)WITH('connector'='datagen','rows-per-second'='100','fields.id.length'...
- 产品推荐
- 这些文档可能帮助您