Function Compute构建高弹性大数据采集系统
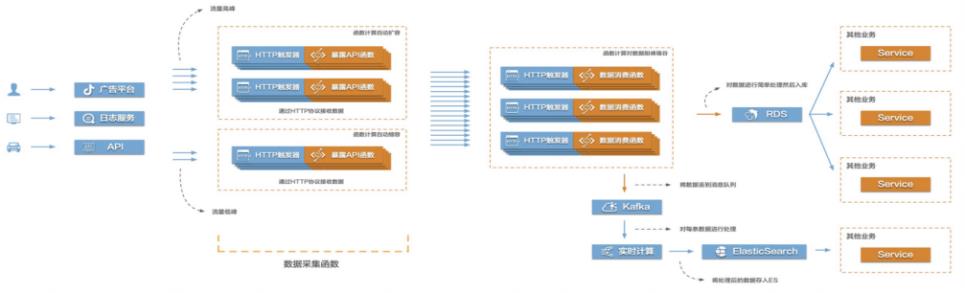
当前互联网很多场景都存在需要将大量的数据信息采集起来然后传输到后端的各类系统服务中,对数据进行处理、分析,形成业务闭环。比如游戏行业中的游戏发行、游戏运营,产互行业中的数字营销,物联网、车联网行业中的硬件、车辆信息上报等等。这些场景普遍存在数据采集量大、数据传输需要稳定且吞吐量大的特点,给整个数据采集传输系统带来很大的挑战。在这个场景中,有三个关键的环节,数据采集、数据传输、数据处理。该最佳实践主要涉
下游服务 下游服务包含从 Kafka里取数据进行实时流处理的实时计算 Flink,数据处理完后 将数据推给 ES 存储,另外还有在第二个函数中对数据简单处理后直接存入数据 库。部署架构 文档版本:20210806(发布日期)3 Function Compute构建高弹性大数据采集系统 前置条件 前置条件 为了顺利完成本实践,您需要提前完成以下准备...
开源Flink迁移实时计算Flink全托管版最佳实践
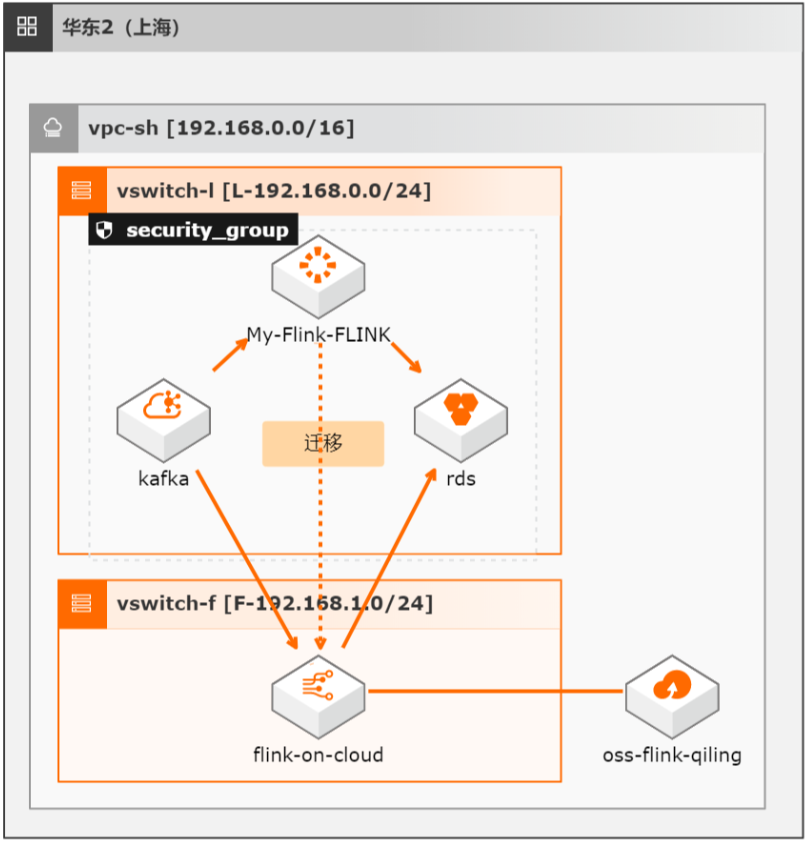
本方案介绍如何将自建开源Flink集群的流式任务(包含Datastream、Table/SQL、PyFlink任务)迁移至阿里云实时计算全托管版。
文档版本:20211222 14 开源 Flink迁移实时计算Flink全托管版 基础环境搭建 步骤4 待作业成功运行后,在 kafka中查询消息,可见测试数据已成功生成。文档版本:20211222 15 开源 Flink迁移实时计算Flink全托管版 作业迁移 2.作业迁移 原始集群计算说明:Flink 中的计算逻辑为:统计每 5分钟窗口内订单的订单总量和订单总...
- 产品推荐
- 这些文档可能帮助您