游戏数据运营融合分析
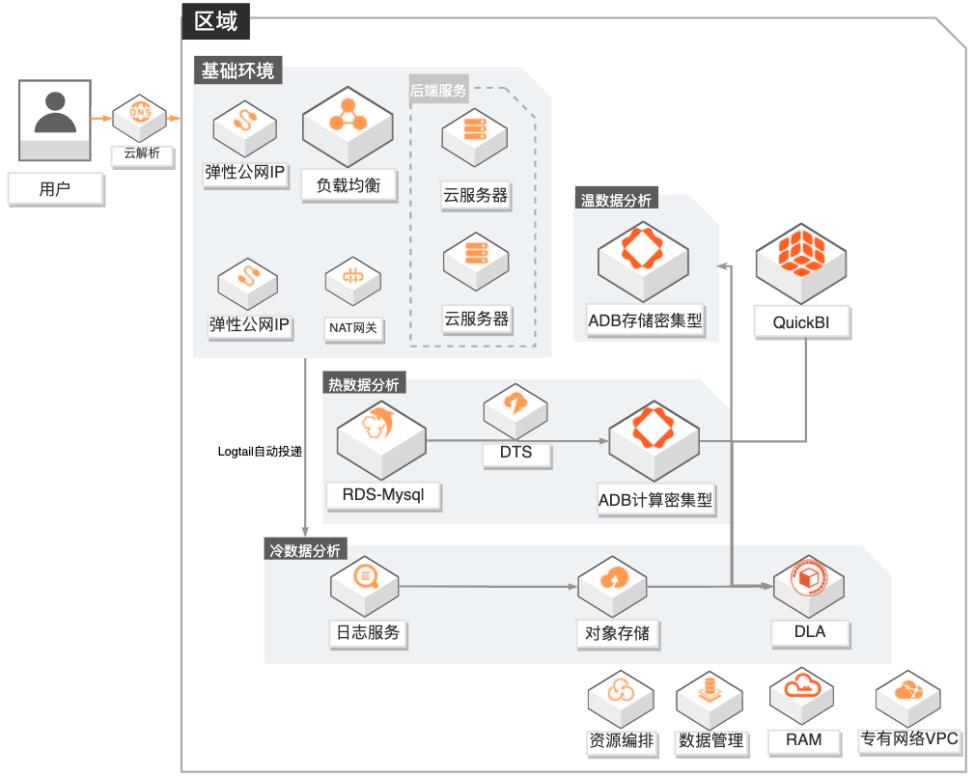
场景描述 1.游戏行业有结构化和非结构化数据融合分 析需求的客户。 2.游戏行业有数据实时分析需求的客户,无法 接受T+1延迟。 3.对数据成本有一定诉求的客户,希望物尽其 用尽量优化成本。 4.其他行业有类似需求的客户。 方案优势/解决问题 1.秒级实时分析:依托ADB计算密集型实例, 秒级监控DAU等数据,为广告投放效果提 供有力的在线决策支撑。 2.高效数据融合分析:打通结构化和非结构化 数据,支撑产品体验分析;广告买量投放效 果实时(分钟级)分析,渠道的评估更准确。 3.低成本:DLA融合冷数据分析+ADB存储密 集型温数据分析+ADB计算密集型热数据分 析,在满足各种分析场景需求的同时,有效 地降低的客户的总体使用成本。 4.学习成本低:DLA和ADB兼容标准SQL语 法,无需额外学习其他技术。 产品列表 专有网络VPC、负载均衡SLB、NAT网关、弹性公网IP 云服务器ECS、日志服务SLS、对象存储OSS 数据库RDSMySQL、数据传输服务DTS、数据管理DMS 分析型数据库MySQL版ADS 数据湖分析DLA、QuickBI
文档版本:20210224 101 游戏数据运营融合分析 数据分析及展示 步骤2 创建 quickBI数据集,对近一个小时每分钟活跃用户数进行分析。文档版本:20210224 102 游戏数据运营融合分析 数据分析及展示 文档版本:20210224 103 游戏数据运营融合分析 数据分析及展示 步骤3 新建仪表板,展现分析结果。文档版本:20210224 104 游戏...
DTS数据同步集成MaxCompute数仓
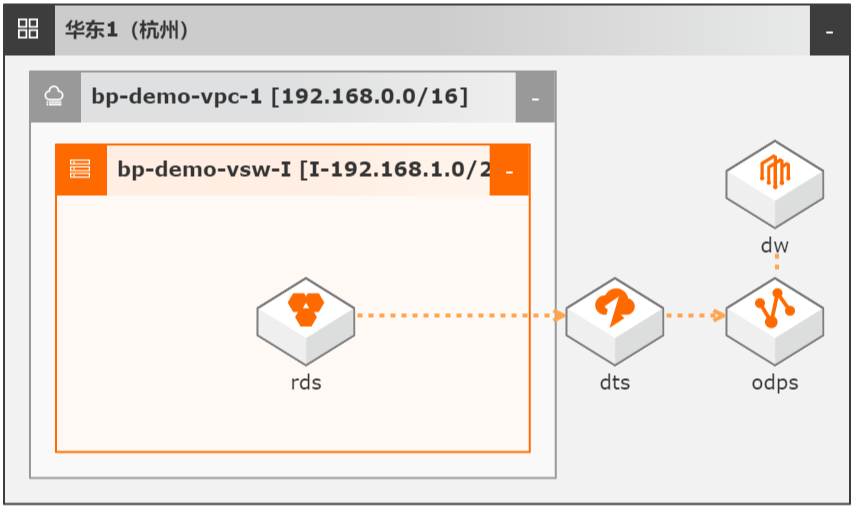
场景描述 本文Step by Step介绍了通过数据传输服务 DTS实现从云数据库RDS到MaxCompute的 数据同步集成,并介绍如何使用DTS和 MaxCompute数仓联合实现数据ETL幂等和数 据生命周期快速回溯。 解决问题 1.实现大数据实时同步集成。 2.实现数据ETL幂等。 3.实现数据生命周期快速回溯。 产品列表 MaxCompute 数据传输服务DTS DataWorks 云数据库RDS MySQL 版
数据抽取不幂等或容错率低,如凌晨 0:00启动的 ETL任务因为各种原因(数据库 HA切换、网络抖动或 MAXC写入失败等)失败后,再次抽取无法获取 0:00时的数 据状态。2.针对不规范设计表,如没有 create_time/update_time的历史遗留表,传统 ETL需 全量抽取。3.实时性差,抽取数据+重试任务往往需要 1-3小时。另外数据库的数据...
基于Flink+ClickHouse构建实时游戏数据分析
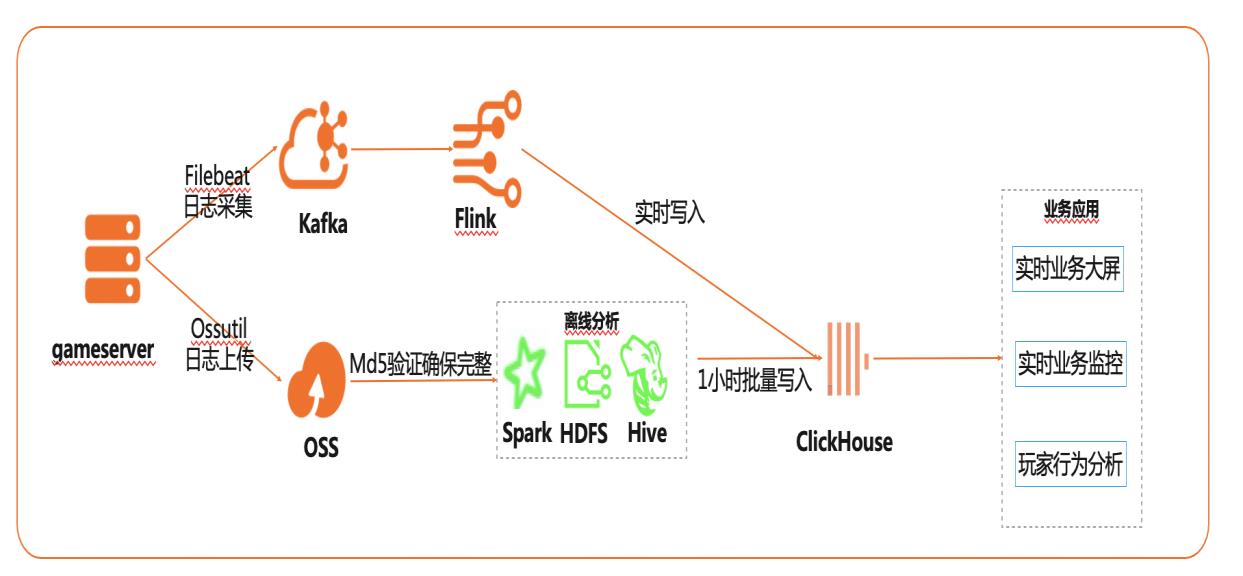
在互联网、游戏行业中,常常需要对用户行为日志进行分析,通过数据挖掘,来更好地支持业务运营,比如用户轨迹,热力图,登录行为分析,实时业务大屏等。当业务数据量达到千亿规模时,常常导致分析不实时,平均响应时间长达10分钟,影响业务的正常运营和发展。 本实践介绍如何快速收集海量用户行为数据,实现秒级响应的实时用户行为分析,并通过实时流计算Flink/Blink、云数据库ClickHouse等技术进行深入挖掘和分析,得到用户特征和画像,实现个性化系统推荐服务。 通过云数据库ClickHouse替换原有Presto数仓,对比开源Presto性能提升20倍。 利用云数据库ClickHouse极致分析性能,千亿级数据分析从10分钟缩短到30秒。 云数据库ClickHouse批量写入效率高,支持业务高峰每小时230亿的用户数据写入。 云数据库ClickHouse开箱即用,免运维,全球多Region部署,快速支持新游戏开服。 Flink+ClickHouse+QuickBI
步骤3 查看数据集,在数据集页面,单击用户行为分析名称,进入数据集编辑页面。文档版本:20201224 68 基于 Flink+ClickHouse构建实时游戏数据分析 数据可视化 步骤4 单击刷新预览,可以看到数据集的信息。8.1.4.可视化仪表板 步骤1 新建仪表板。文档版本:20201224 69 基于 Flink+ClickHouse构建实时游戏数据分析 数据可视...
异地双活场景下的数据双向同步
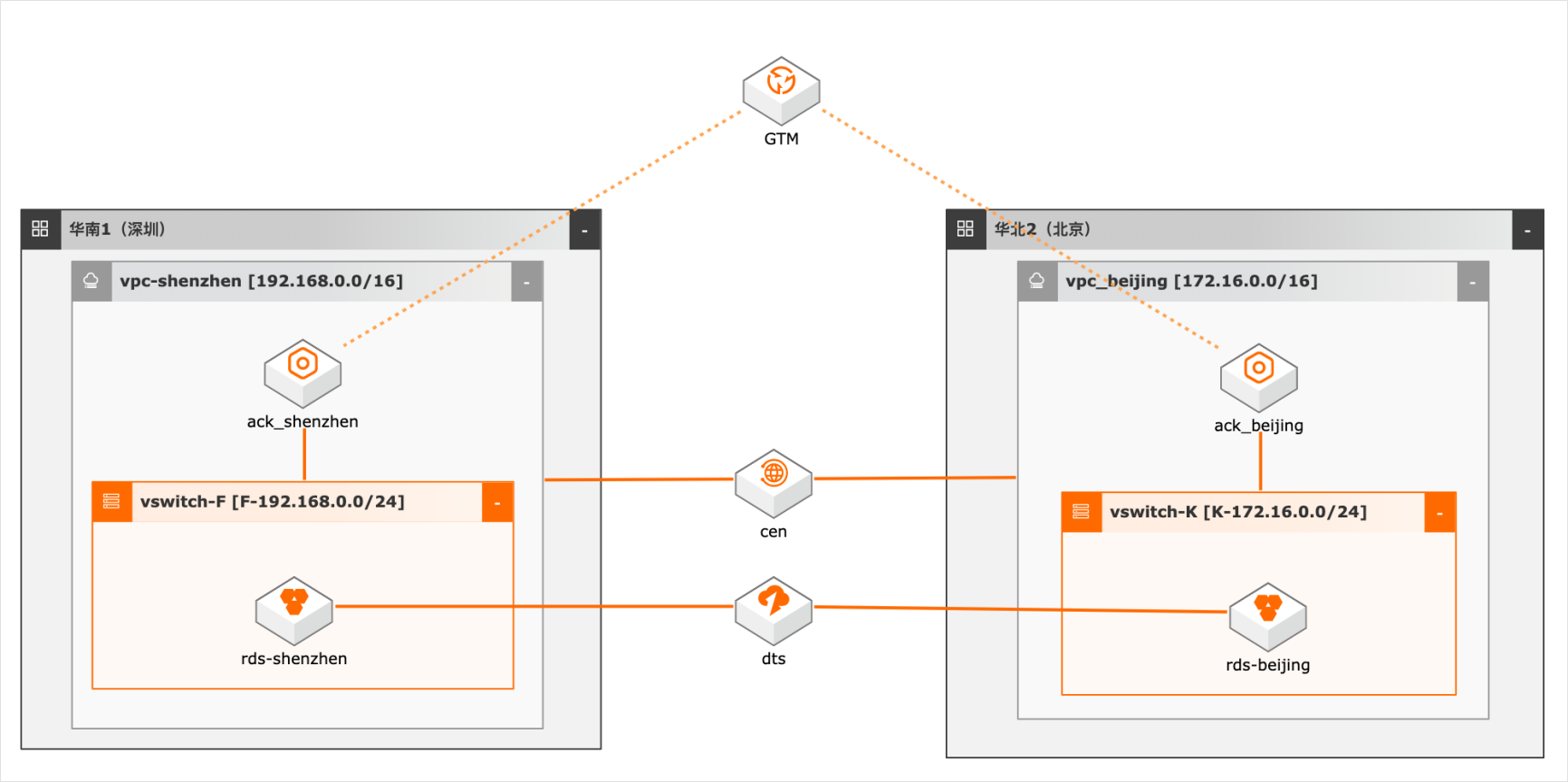
概述 随着客户业务规模的扩大,对系统高可用性要求越来越高,越来越多用户采用异地双活/多活架构,多活架构往往涉及业务侧做单元化改造,本方案仅模拟用户已做单元化改造后的数据双向同步,数据库采用双主架构,本地写本地读,同时又保证双库的数据一致性,为业务增加可用性和灵活性。 适用场景 数据库双向同步 数据库全局ID不冲突 双活架构的数据库建设问题 技术架构 本实践方案基于如下图所示的技术架构和主要流程编写操作步骤: 方案优势 DTS双向同步,采用独立模块避免数据同步占用系统资源。 奇偶ID涉及,避免数据冲突。 DTS多种处理冲突的方式供业务选择。 安全:原生的多租户系统,以项目进行隔离,所有计算任务在安全沙箱中运行。
随着客户业务规模的扩大,对系统高可用性要求越 数据库双向同步 来越高,越来越多用户采用异地双活/多活架构,多 数据库全局 ID不冲突 活架构往往涉及业务侧做单元化改造,本方案仅模 双活架构的数据库建设问题 拟用户已做单元化改造后的数据双向同步,数据库 采用双主架构,本地写本地读,同时又保证双库的数 据一致性,为...
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
在 PB 级别 的数据集上可以支持亚秒级别的处理延时,赋能用户标准实时数据处理流程和行 业解决方案;支持 Datastream API 作业开发,提供了批流统一的 Flink SQL,简 化 BI 场景下的开发;可与用户已使用的大数据组件无缝对接,更多增值特性助力 企业实时化转型。详情请查看 ...
Spark on ECI大数据分析

场景描述 方案优势 1.计算引擎弹性扩缩容,兼顾资源弹性与计 算资源成本优化。 2.计算与存储分离架构,结合阿里云原生云 存储产品,海量数据湖优势。 3.Kubernetes原生的调度性能优势,提升在 大规模分析作业时的分析性能优势分。 4.集群资源隔离和按需分配。 解决问题 1.计算资源弹性能力不足,计算资源成本管 控能力欠缺. 2.集群资源调度能力和隔离能力不足。 3.计算与存储无法分离,大数据量分析时出 现数据存储资源瓶颈。 4.Spark submit方式提交分析作业参数支持 有限等缺点。 产品列表 容器服务Kubernetes版(ACK) 弹性容器实例(ECI) 文件存储HDFS 对象存储OSS 专有网络VPC 容器镜像服务ACR
应用范围 需要使用 Spark on Kubernetes解决方案的用户 对 Spark大数据分析平台计算资源成本控制考虑的用户 需要有灵活可扩展计算平台资源弹性及管控的用户 名词解释 文件存储 HDFS:阿里云文件存储 HDFS是面向阿里云 ECS实例及容器服务等计 算资源的文件存储服务,允许用户像在 Hadoop分布式文件系统中管理和访问数 据,...
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。
登录OSS并上传测试数据集.25 3.2.在EMR创建外部表.27 3.3.通过MC查询EMR的Hive数据表.29 3.4.数据预处理.30 3.5.创建预测模型.35 3.6.使用模型做预测.36 4.一键释放云资源.39 5.附录A.42 5.1.MaxCompute和DLF属于同一个账号,需要自定义授权.42 5.2.MaxCompute和DLF属于不同账号.47 6.附录B.49基于湖仓一体架构使用...
基于弹性供应组构建大数据分析集群
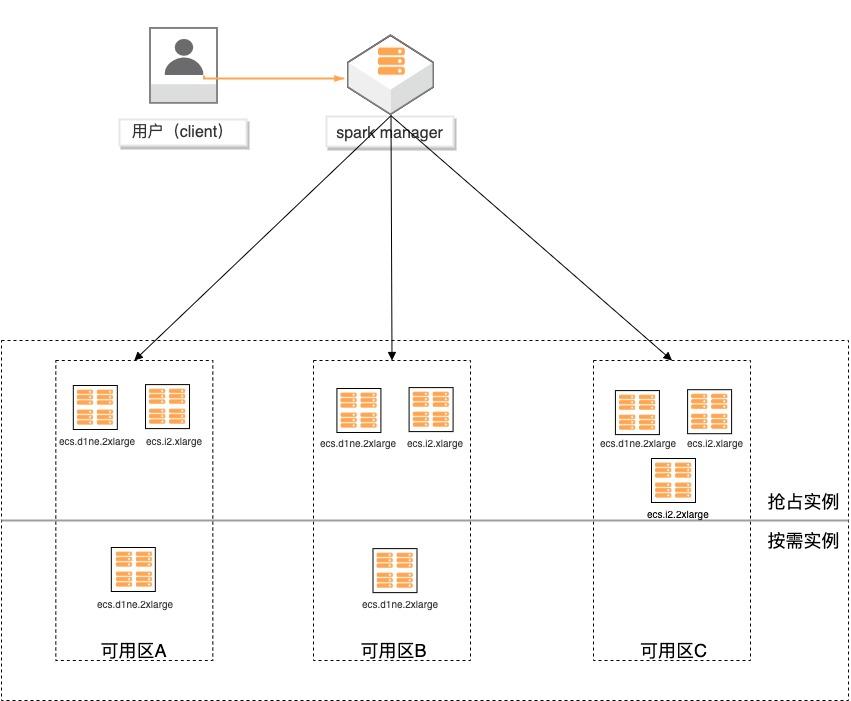
场景描述 基于弹性供应组(APG)搭建spark计算集 群,提供一键开启跨售卖方式、跨可用区、 跨实例规格的计算集群交付模式的实践。 方案优势 1.超低成本:跨售卖方式提供计算实 例,按秒计费,可全部使用spot实例 交付,最高可省90%成本。 2.稳定可靠:跨可用域、跨实例规格, 降低spot被集体释放的风险;自动托 管,分钟级巡检,动态保证集群的算 力。 3.快速交付:单次可在5分钟内交付 2000个实例。 4.多策略组合:可分别指定spot和按量 实例的交付策略,以及差额补足的策 略,包括成本最低、打散和折中。 解决问题 1.大规模计算集群成本高。 2.创建ECS实例方式单一,无法跨计费 方式、可用区及规格等核心参数。 3.当可用区资源紧张,无法自动保证基于 spot类型的稳定算力。 产品列表 专有网络VPC 云服务器ECS
基于弹性供应组构建大数据分析集群最佳实践 业务架构 场景描述 基于弹性供应组(APG)搭建 spark计算集 群,提供一键开启跨售卖方式、跨可用区、跨实例规格的计算集群交付模式的实践。方案优势 1.超低成本:跨售卖方式提供计算实 例,按秒计费,可全部使用 spot实例 交付,最高可省 90%成本。2.稳定可靠:跨可用域、跨实例...
多媒体数据存储与分发
以搭建一个多媒体数据存储与分发服务为例,搭建一个多媒体数据存储与分发服务。
产品解决方案文档与社区权益中心定价云市场合作伙伴支持与服务了解阿里云备案控制台多媒体数据存储与分发方案介绍方案优势应用场景方案部署方案权益多媒体数据存储与分发视频、图文类多媒体数据量快速增长,内容不断丰富,多媒体数据存储与分发解决方案融合对象存储 OSS、内容分发 CDN、智能媒体管理 IMM 等产品能力,解决...
来自:
解决方案
利用交互式分析(Hologres)进行数据查询
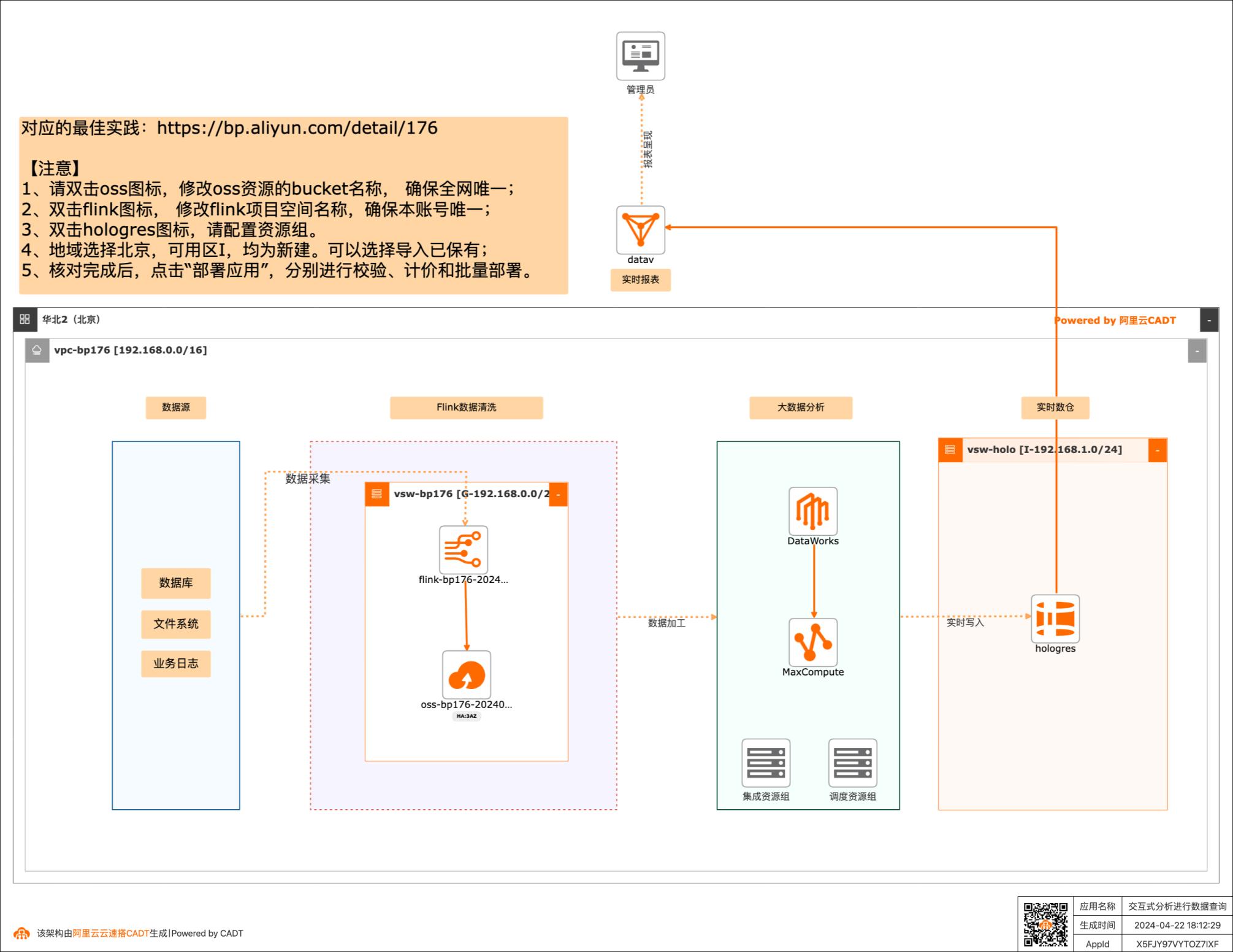
场景描述:随着收集数据的方式不断丰富,企业信息化 程度越来越高,企业掌握的数据量呈TB、 PB或EB级别增长。同时,数据中台的快 速推进,使数据应用主要为数据支撑、用户 画像、实时圈人及广告精准投放等核心业务 服务。高可靠和低延时地数据服务成为企业 数字化转型的关键。 Hologres致力于低成本和高性能地大规模 计算型存储和强大的查询能力,为您提供海 量数据的实时数据仓库解决方案和实时交 互式查询服务。 解决问题 1.加速查询MaxCompute数据 2.快速搭建实时数据仓库 3.无缝对接主流BI工具 产品列表 MaxCompute Hologres 实时计算Flink 专有网络VPC DataWorks DataV
同时,数 据中台的快速推进,使数据应用主要为数据支撑、用户画 像、实时圈人及广告精准投放等核心业务服务。高可靠和 低延时地数据服务成为企业数字化转型的关键。Hologres致力于低成本和高性能地大规模计算型存储和 强大的查询能力,为您提供海量数据的实时数据仓库解决 方案和实时交互式查询服务。解决问题 1.加速查询...
大数据近实时数据投递MaxCompute
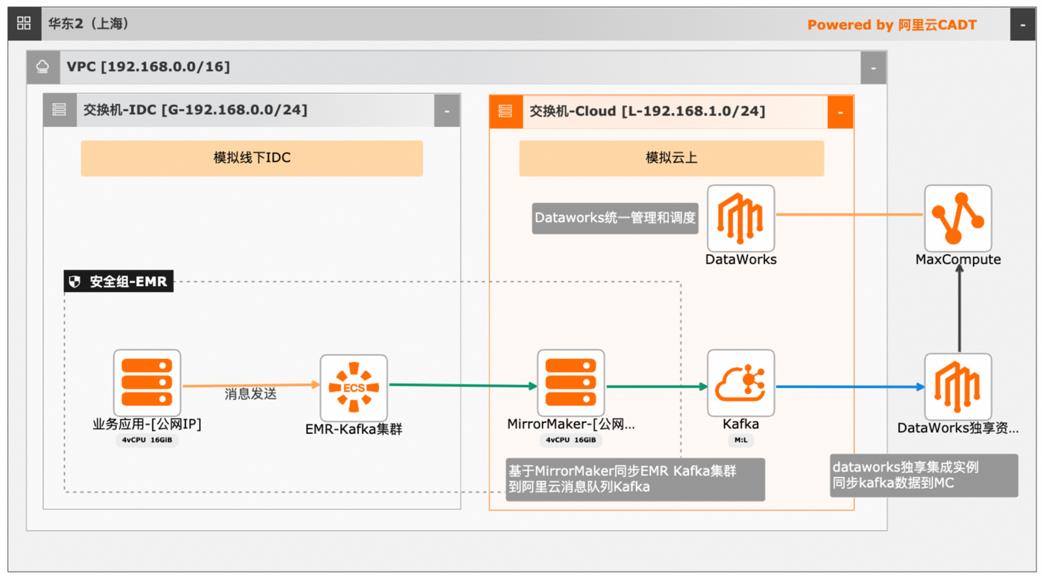
本文介绍离线大数据场景使MaxCompute构建云 上近实时数仓,打通云下数据上云链路,解决数据复杂类型支持和动态分区问题,满足高级数据处理需求的最佳实践。 l混合云环境下,现有业务系统零改造,打通数据上云链路。 l使用UDF实现复杂数据类型转换和数据动态分区。 l使用DataWorks配置周期调度业务流程,数据自动入仓。 l借助MaxCompute优化计算引擎,实现降本增效。 产品列表 云服务器ECS 专有网络VPC 访问控制RAM 数据总线DataHub E-MapReduceEMR DataWorks 大数据计算服务MaxCompute
上近实时数仓,打通云下数据上云链路,解决数据复 使用 UDF实现复杂数据类型转换和数据动态分 杂类型支持和动态分区问题,满足高级数据处理需求 区。的最佳实践。使用 DataWorks配置周期调度业务流程,数据自 产品列表 动入仓。借助 MaxCompute优化计算引擎,实现降本增 云服务器 ECS 效。云消息队列 Kafka 最佳实践频道 ...
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 业务架构 场景描述 客户在 IDC或者公有云环境自建 Hadoop集群 构建数据仓库和分析系统,购买阿里云 Databricks数据洞察集群之后,涉及到数仓数 据和元数据的迁移以及 Hive版本的订正更新。方案优势 1.全托管 Spark集群免运维,节省人力成 本。2.Databricks数据洞察...
跨链数据连接服务解决方案
利用蚂蚁区块链领先技术实现的跨链数据连接服务 Open Data Access Trusted Service(ODATS)。通过制定标准化的区块链UDAG全栈跨链协议,保证跨链交易的安全性、可扩展性及可靠性,打破区块链数据孤岛,实现同构及异构链之间的可信互通,助力企业之间可信协作,促进产业生态可信融合。
为作品内容生产机构或内容运营企业提供集原创登记、版权监测、电子数据采集与公证、司法维权诉讼为一体的一站式线上版权保护解决方案.区块链版权保护.企业和机构可以更合规的使用和管理用户身份信息及数据授权,而身份信息的真实性得到了极大的保障.分布式身份服务.超过30个专利的自研跨链技术,通过区块链跨链协议栈,提供...
来自:
解决方案
湖仓一体架构EMR元数据迁移DLF
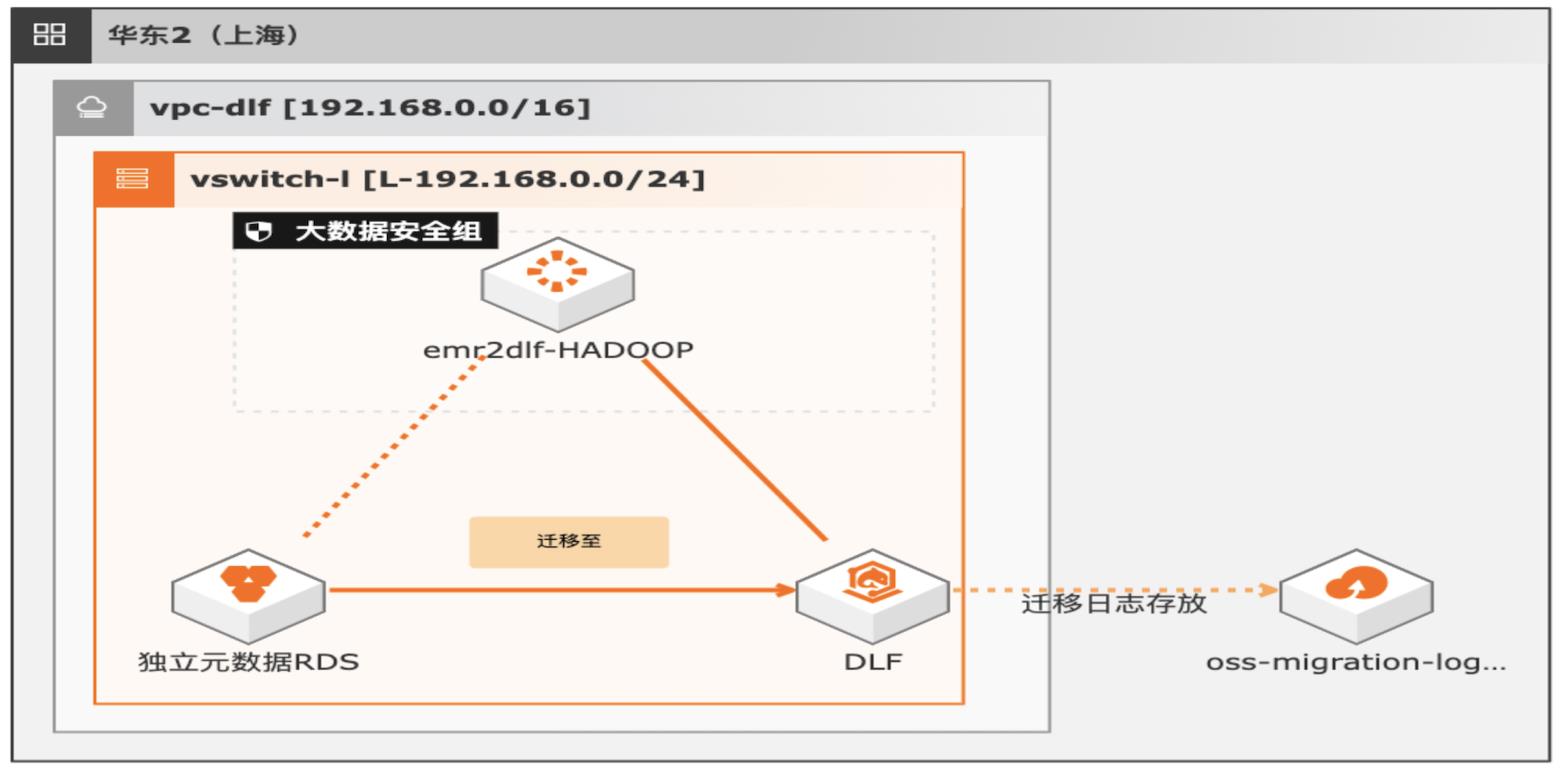
通过EMR+DLF数据湖方案,可以为企业提供数据湖内的统一的元数据管理,统一的权限管理,支持多源数据入湖以及一站式数据探索的能力。本方案支持已有EMR集群元数据库使用RDS或内置MySQL数据库迁移DLF,通过统一的元数据管理,多种数据源入湖,搭建高效的数据湖解决方案。
湖仓一体架构 EMR元数据迁移 DLF最佳实践 业务架构 场景描述 解决的问题 通过 EMR+DLF数据湖方案,可以为企业提供数据 EMR元数据迁移至 DLF 湖内的统一的元数据管理,统一的权限管理,支持多 元数据迁移验证 源数据入湖以及一站式数据探索的能力。本方案支 数据一致性校验 持已有 EMR集群元数据库使用 RDS或内置 MySQL ...
企业上云数据安全
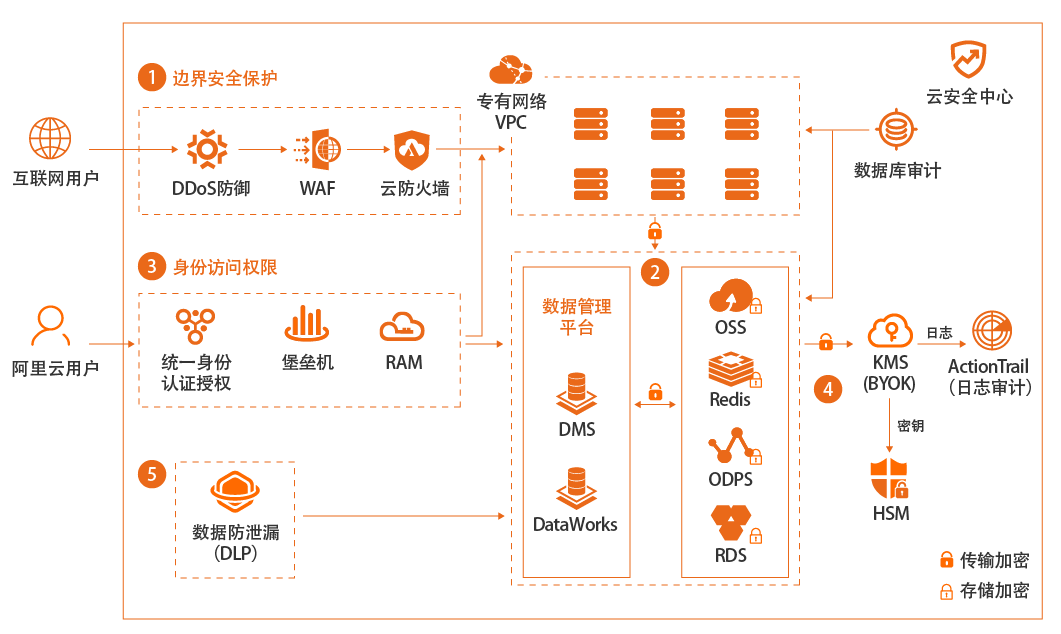
场景描述 企业是否选择上公共云,或者哪些系统或数据上 公共云,对数据安全的关心是重要因素之一。本 最佳实践重点在于介绍狭义的数据加密存储安 全范畴,即首先使用SDDP产品进行敏感数据发 现和分级分类,然后对高级别敏感数据进行按 需、不同类型的全链路加密存储。 解决问题 1.帮助客户发现敏感数据 2.对敏感数据进行分类、分级 3.对不同级别的数据如何选择加密方式 4.具体如何进行加密 产品列表 敏感数据识别SDDP 密钥管理服务KMS 云数据库RDS 对象存储OSS
流程如下图:对于客户端加密方式,分为用户自己管理密钥加密(CSE-C)和 KMS 托管密钥(CSE-KMS)加密两种,如下图所示:文档版本:20210809 28 企业上云数据安全 OSS数据加密 使用客户端加密,可以使用客户端加密 SDK,在本地进行数据加密,并将加密后的数 据上传到 OSS。在这种场景下,用户需要管理加密过程以及加密密钥...
数据传输服务DTS
阿里云数据传输服务集数据迁移、订阅及实时同步功能于一体,能够解决公共云、混合云场景下,远距离、毫秒级异步数据传输难题,支持关系型数据库、NoSQL、大数据(OLAP)等数据源,其底层基础设施采用阿里双11异地多活架构,为数千下游应用提供实时数据流,已在线上稳定运行7年之久。
云数据库 MongoDB 版支持副本集和分片集群两种部署架构,具备分钟级弹性扩缩容、快速备份恢复、安全审计和智能诊断等多项企业级能力。在互联网、物联网、游戏、金融等领域被广泛采用。云数据库 MongoDB 版.云原生数据库 PolarDB 是阿里云自研产品,在存储计算分离架构下,利用了软硬件结合的优势,为用户提供秒级弹性、高...
来自:
云产品
- 产品推荐
- 这些文档可能帮助您