云消息队列 ApsaraMQ
云消息队列 ApsaraMQ 是阿里云自主研发的消息队列服务系列产品的总称,旨在为开发者和企业的不同业务场景提供强大、可靠、低成本、高弹性且易于管理的消息服务。云消息队列 ApsaraMQ 全系列产品提供 Serverless 化的消息服务,按实际使用量付费,自适应弹性,跨可用区容灾,帮助客户降低使用和维护成本,专注业务创新。
消息系列课程直播回放.ApsaraMQ 产品家族.RocketMQ基础架构全新升级.Apache RocketMQ,构建云原生统一消息引擎.Apache RocketMQ 5.0 消息进阶:如何支撑复杂的业务消息场景?RocketMQ 5.0 架构解析:如何基于云原生架构支撑多元化场景.RocketMQ 在业务消息场景的优势详解.从互联网到云时代,Apache RocketMQ 是如何演进的?...
来自:
云产品
SLS数据入湖Kafka最佳实践
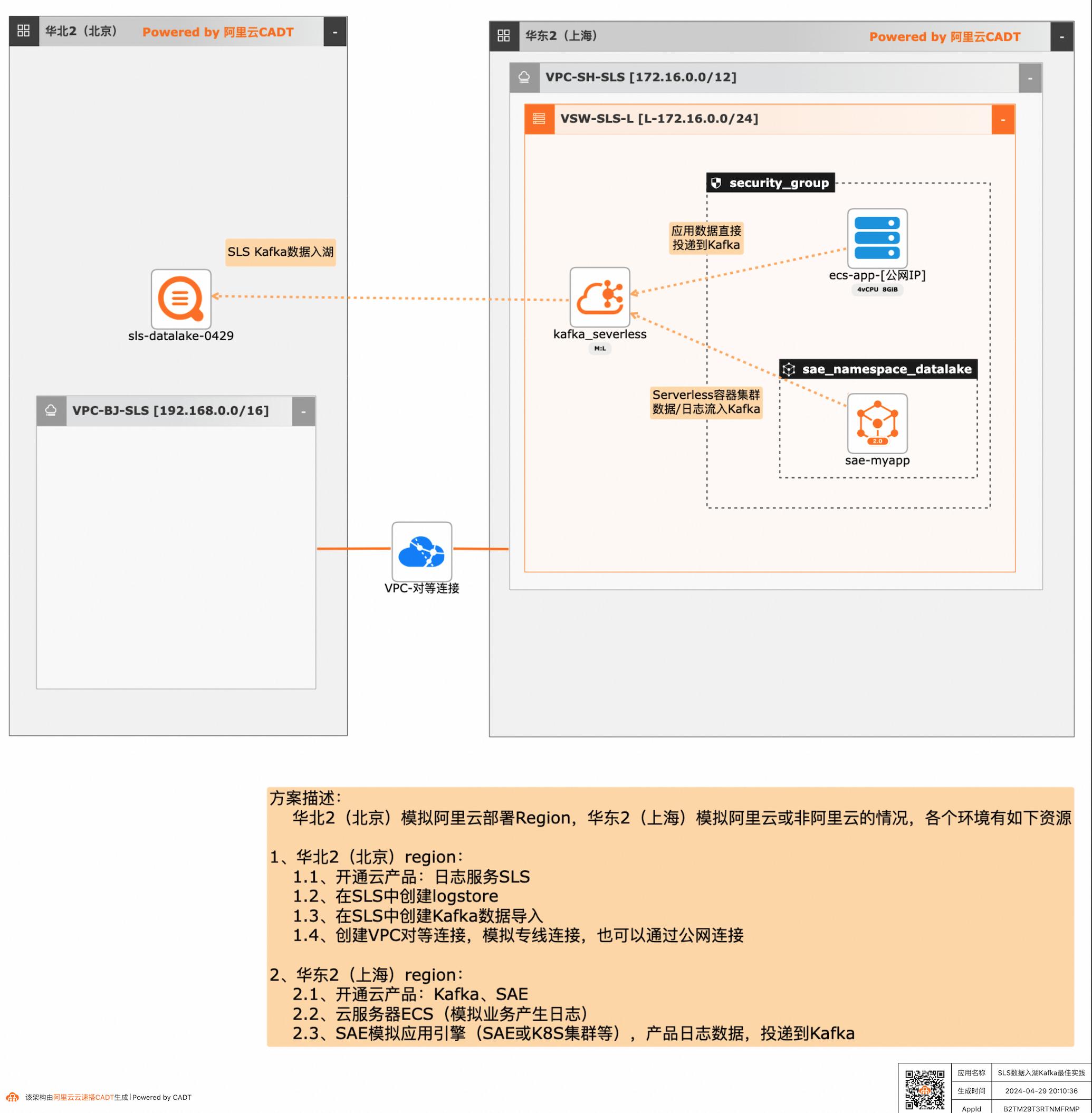
应用和数据分散在多云或混合云,在面对多云/混合云这样大的趋势下,数据无法进行统一的聚合、分析处理和导出等,本方案给出了在多云/混合云场景下,构建通过标准的Kafka协议和托管服务,SLS可以连接Kafka数据入湖导入,然后进行统一的海量数据的集中存储、智能转储、聚合分析查询等。
20240428 IIISLS数据入湖Kafka最佳实践 最佳实践概述 最佳实践概述 方案概述 应用和数据分散在多云或混合云,在面对多云/混合云这样大的趋势下,数据无法进行统 一的聚合、分析处理和导出等,本方案给出了在多云/混合云场景下,构建通过标准的 Kafka协议和托管服务,SLS可以连接Kafka数据入湖导入,然后进行统一的海量数据 ...
RocketMQ性能压测快速方案
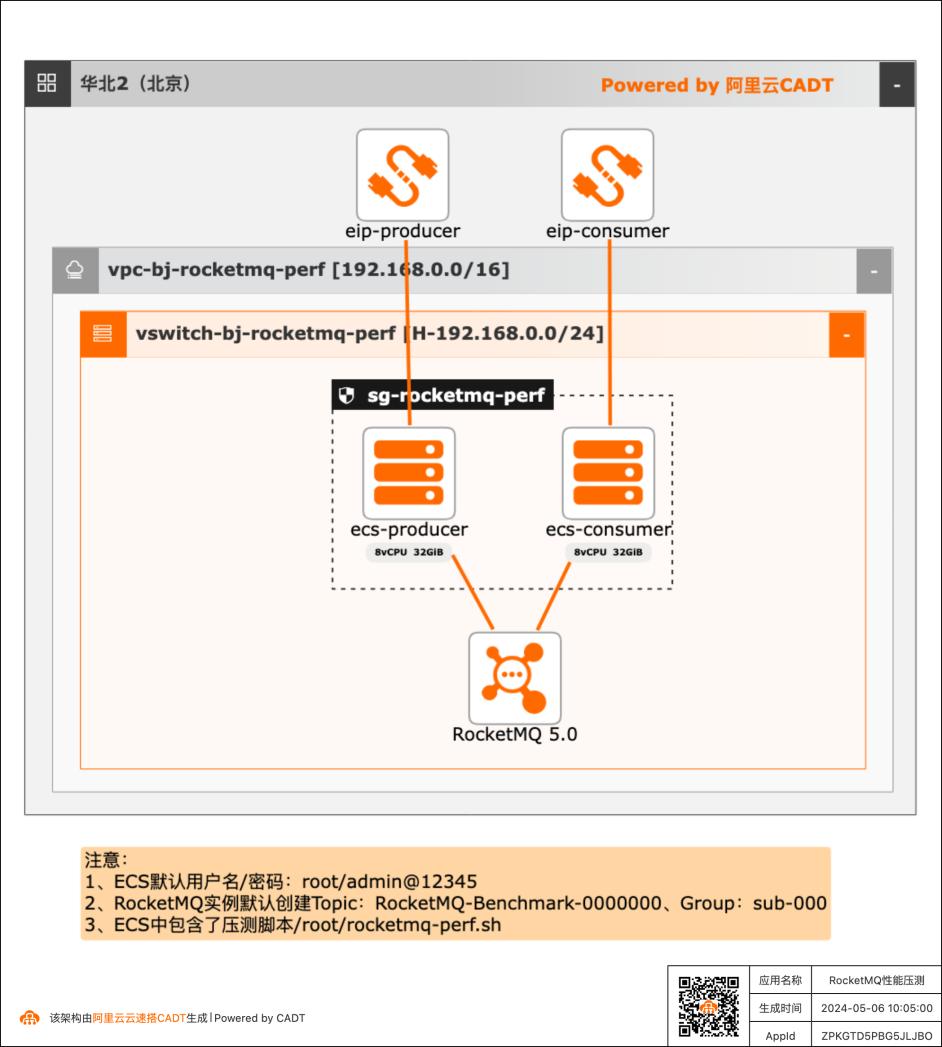
在客户对产品性能存疑或者给客户进行POC验证时可以用本实践来快速完成性能测试。
云消息队列RocketMQ版:是阿里云基于ApacheRocketMQ构建的低延迟、高 并发、高可用、高可靠的分布式“消息、事件、流”统一处理平台,面向互联网分布 式应用场景提供微服务异步解耦、流式数据处理、事件驱动处理等核心能力。文档版本:20240506 6RocketMQ性能压测快速方案 前置条件 前置条件 在进行本文操作之前,您需要...
移动开发平台 mPaaS
阿里云移动开发平台 mPaaS提供App开发、测试、运营及运维等云到端的一站式解决方案,帮助企业快速构建高质量的移动应用,阿里云快速开发平台提升企业产品生态发展。
A:客户端开发包含前端框架与 UI 组件、H5 容器和离线包、设备标识、社交分享、扫一扫、统一存储、定位等。查看详情Q:如何提高移动应用的安全性?A:移动应用安全加固(Mobile Security Armor,简称 MSA)为移动应用(下文简称 App)提供稳定、简单、有效的安全保护,提高 App 的整体安全水平,力保应用不被逆向破解。查看...
来自:
云产品
基于SLS实现统一告警最佳实践
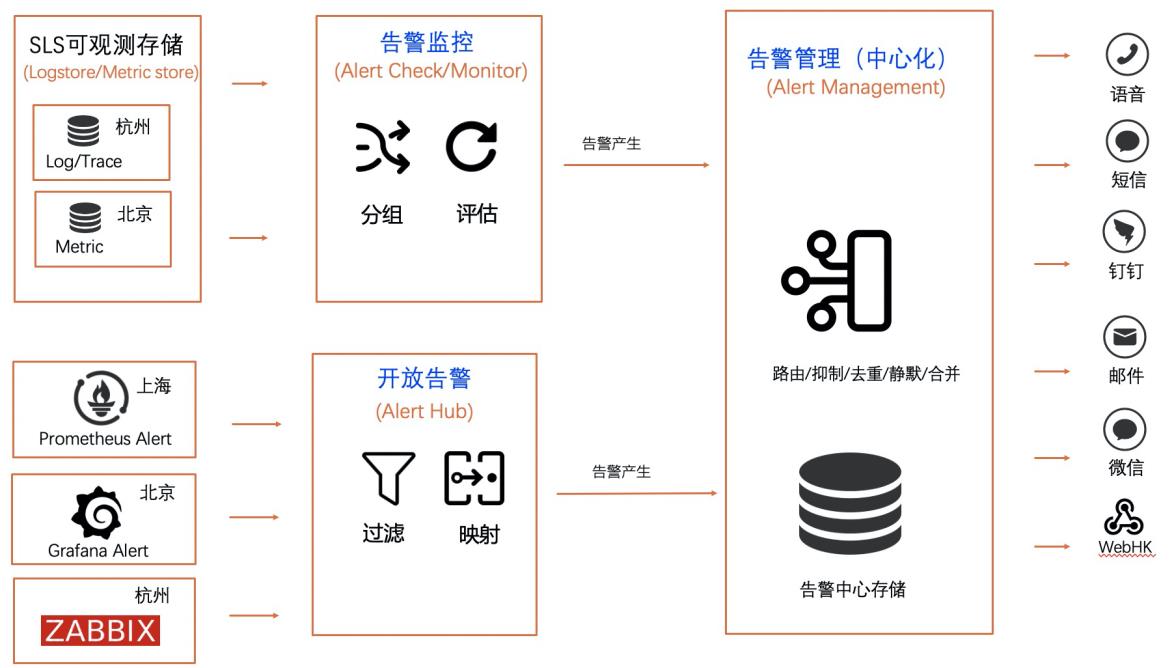
告警对于企业的开发运维,安全运维,业务运维有着至关重要的作用。然而很多企业在告警运维方面存在着重复建设、监控质量差、告警风暴、触达不人性化、无法闭环等问题。 针对企业在告警管理方面存在的痛点问题,SLS告警提供了一站式云上告警管理方案,具有弹性易用、稳定可靠、功能持续升级、成本更低、噪音更少等优势。企业可以将现有的监控方案系统无缝接入到SLS告警平台,实现在SLS上一站式管理告警。
基于 SLS实现统一告警 最佳实践 业务架构 场景描述 告警监控对于一个企业有着至关重要的作 用,然而很多企业在告警运维方面存在着重 复建设、监控质量差、告警风暴、触达不人 性化、无法闭环等问题。SLS告警提供了一站式云上告警管理方案,能够有效的解决企业在使用告警中的痛点。本文以通过自定义告警、Prometheus 告 警、...
基于SpringCloud应用玩转MSE实践
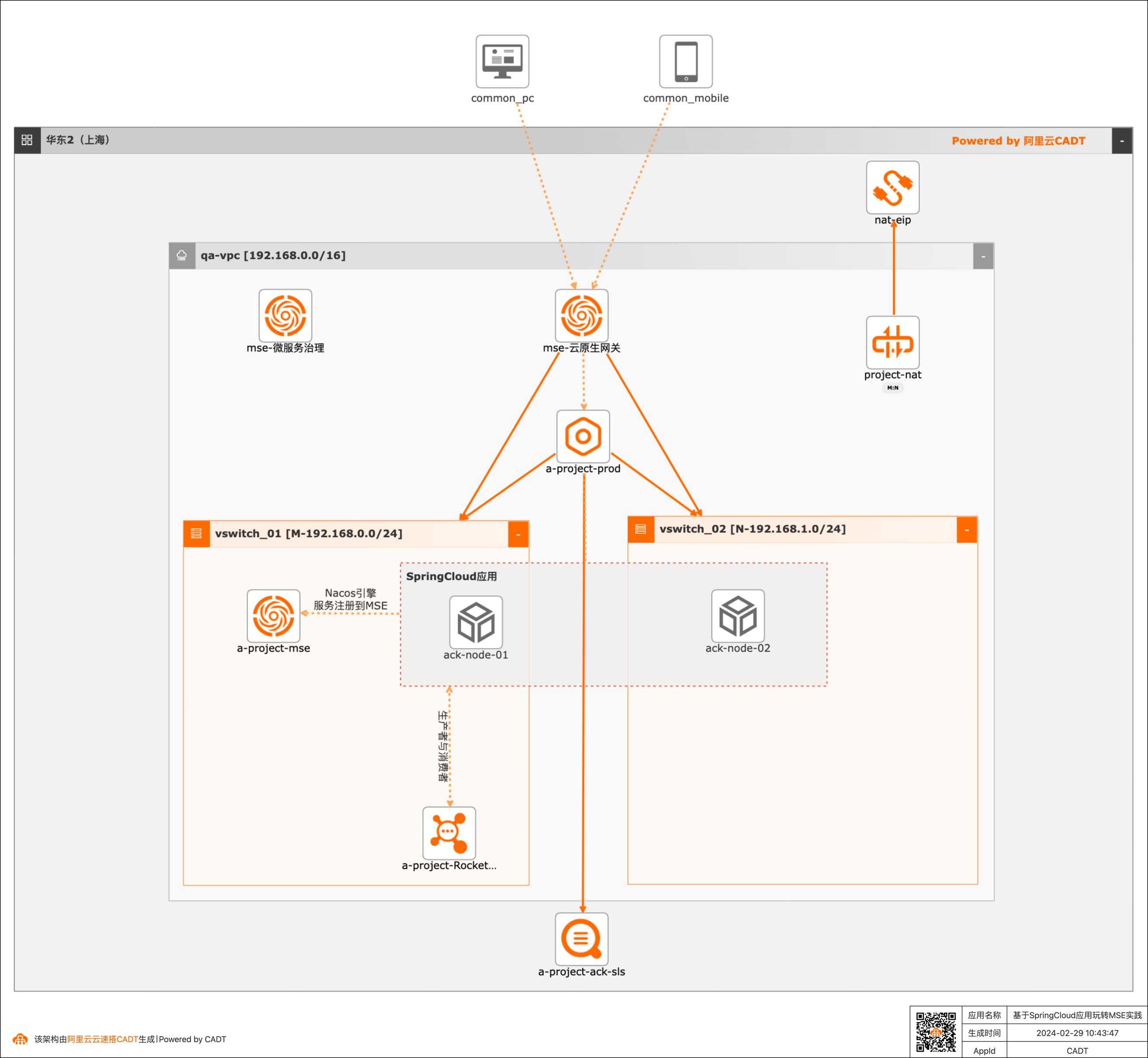
随着业务不断创新,大型的单个应用和服务会被拆分为数个甚至数十个微服务,微服务架构已经被广泛应用。 微服务的好处在于快速迭代,如何在迭代过程中保障线上流量不受损。依赖开源产品缺少无运维工具,常常需要投入较大的运维人力和成本。 本实践提供基于云原生应用产品提供微服务注册配置中心、微服务治理和云原生网关等一系列高性能和高可用的企业级云服务能力。
但实际情况是如下图所示:请求到达第一跳应用后(mseconsumer或mseconsumer-gray),第一跳的应 用会随机通过restapi调用下游应用,mseprovider或mseprovider-gray发送的消息也会随机投递到 mseconsumer或mseconsumer-gray,无法实现预期中的流量隔离的效果。原因是在没有开使用微服务治 理的情况下,单纯依赖网关的流量...
云消息队列 Kafka 版
云消息队列 Kafka 版是阿里云基于Apache Kafka构建的大数据消息中间件,广泛用于日志收集和分析、数据处理等场景。可提供全托管服务,用户无需部署运维,更专业、更可靠、更安全。
随着业务的快速发展,大搜车遇到了消息量大幅增加、异地消息同步等一系列的问题,需要更稳定可靠的商业版Kafka产品,减少运维工作量,利用云消息队列Kafka对接大数据生态,即开即用,快速扩容,可靠性更高.大搜车:云上多地域高可用消息系统的构建.云消息队列 Kafka 版 V3 系列 Serverless 实例正式发布!云消息队列 Kafka ...
来自:
云产品
云数据库 SelectDB 版
阿里云数据库 SelectDB 是现代化实时数据仓库 SelectDB 在阿里云上的全托管服务,内核基于业界领先的开源分析型数据库 Apache Doris 研发,由阿里云和飞轮科技联合打造。阿里云数据库 SelectDB 聚焦于满足企业级大数据分析需求,广泛应用于实时报表分析、即席多维分析、日志检索分析、数据联邦与查询加速等场景,致力于为客户提供极致性能、简单易用的数据分析服务。
相关产品云数据库 SelectDB 版本产品对象存储 OSS开源大数据平台 E-MapReduce在线咨询阿里云数据库 SelectDB 版重磅发布,邀测火热进行中阿里云数据库 SelectDB 版已于 8 月 20 日正式上线,用户可以在阿里云上便捷地使用 SelectDB 数仓服务,以满足海量数据极速实时、融合统.查看详情阿里云数据库 SelectDB 版内核 Apache ...
来自:
云产品
AHAS多活容灾MSHA
多活容灾MSHA是在阿里电商业务环境演进出来的多活容灾商业化产品,是应用高可用服务AHAS的核心模块,为客户提供容灾架构建设能力。横向支持容灾架构的上线、运维、演练、切流,升级到下线。纵向支持业务流量的全链路管理,从流量接入到服务化调用再到异步化消息,最终完成数据落库。
具备接入层、服务层、消息层、数据层等自上而下的业务组件资源容灾管理能力,统一管理维护.基于接入层流量切换,以及RPC、MQ、定时任务调度流量的流量切换能力,保障业务的分钟级恢复能力.基于MSHA SDK的切面能力,请求封闭在一个逻辑区域,避免跨机房的RT延迟,减少故障场景的决策时间,加速故障恢复.数据一致性保障.通过...
来自:
云产品
大数据workshop

大数据workshop
tail-f nohup.out 文档版本:20210628(发布日期)32 阿里云最佳实践大数据 WorkShop 最佳实践项目实践 步骤7 查询 datahub中是否已有消息,可见消息已正常投递到 datahub,观察到数据量在增 加。文档版本:20210628(发布日期)33 阿里云最佳实践大数据 WorkShop 最佳实践项目实践 3.2.4.业务数据同步 步骤1 进入 DTS...
来自:
最佳实践
相关产品:块存储,云服务器ECS,云数据库RDS MySQL 版,对象存储 OSS,弹性公网IP,数据传输,DataWorks,大数据计算服务 MaxCompute,DataV数据可视化,实时计算,数据总线,Quick BI,Hologres
金融专属大数据workshop

实践目标 学习搭建一个实时数据仓库,掌握数据采集、存储、计算、输出、展示等整个业务流程。 整个实时数据仓库系统全部基于阿里云产品进行架构搭建,用户可以掌握并学会运用各个服务组件及各个组件之间如何联动。 理解阿里云原生实时离线一体数仓解决方案架构以及掌握交付落地的实践使用方法。 前置知识要求 熟练掌握SQL语法 对大数据体系系统知识有一定的了解
tail-fnohup.out 文档版本:20210803(发布日期)29阿里云最佳实践金融大数据WorkShop 最佳实践项目实践 步骤4 查询datahub中是否已有消息,可见消息已正常投递到datahub,观察到数据量在增 加。(说明:刚开始实时流量曲线可能会没有生成)文档版本:20210803(发布日期)30阿里云最佳实践金融大数据WorkShop 最佳实践项目...
来自:
最佳实践
相关产品:块存储,云服务器ECS,云数据库RDS MySQL 版,对象存储 OSS,弹性公网IP,数据传输,DataWorks,大数据计算服务 MaxCompute,DataV数据可视化,实时计算,数据总线,Quick BI,Hologres
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
步骤7 运行 flume agent 文档版本:20201020 22 基于 Dataworks的大数据一站式开发及数据治理 日志采集 执行以下命令后台运行 flume agent:nohup flume-ng agent-name a1-conf$FLUME_HOME/conf-conf-file$FLUME_HOME/conf/flume-conf.properties-Dflume.root.logger=INFO,console&2>&1&步骤8 查询 kafka中是否已有消息,...
数据湖-在线学习场景数据分析

场景描述 本场景以在线教育中一个答题闯关类的应用为 例,使用WebServer来模拟演示这类日志数据 的分析处理。通过Nginx和Pythonflask搭建 WebServer,模拟应用中的关键页面,比如登 录、课程内容等,之后构造若干用户使用的模拟 日志数据,投递到数据湖进行分析后获取应用 PV、UV、课程内容访问排行、平均得分等等。 解决问题 基于数据湖(EMR+OSS)搭建大数据平台。 EMR和OSS使用和配置。 数据统一存储到OSS。 产品列表 E-MapReduce 对象存储OSS 云服务器ECS 访问控制RAM 专有网络VPC
数据湖-在线学习场景数据分析 最佳实践 场景描述 业务架构 本场景以在线教育中一个答题闯关类的应用为例,使用WebServer来模拟演示这类日志数据的分析 处理。通过Nginx和Python flask搭建Web Server,模拟应用中的关键页面,比如登录、课程 内容等,之后构造若干用户使用的模拟日志数据,投递到数据湖进行分析后获取应用PV...
基于k8s多集群隔离环境下的devops实现
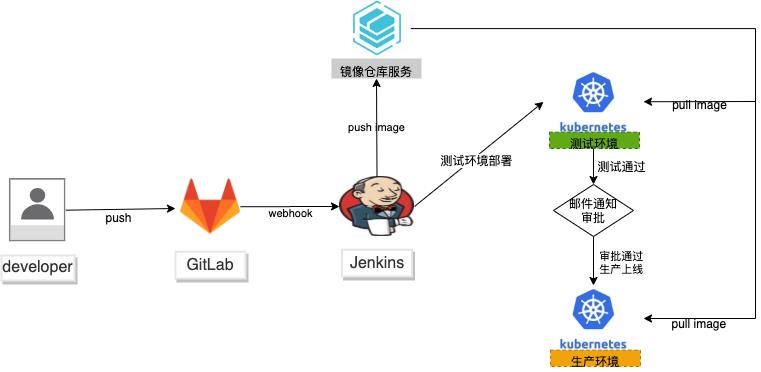
场景描述 DevOps是一组过程、方法与系统 的统称,并通过工具实现自动化部署, 确保部署任务的可重复性、减少部署出 错的可能性。随着微服务、中台架构的 兴起,devops重要性日益显著。 本方案使用两个独立的k8s集群: 用户已有的k8s模拟测试,ack集群模 拟生产环境,保证环境的高度隔离,互 不影响。通过gitlab+Jenkins的黄金组 合,实现容器应用的自动化构建和持续 部署,提高迭代效率。 解决问题 1.微服务应用的CI/CD。 2.测试和生产环境的高度隔离。 3.自动化的测试与部署。 4.现有CI对接ACK。 产品列表 专有网络VPC 容器服务ACK 容器镜像服务ACR 弹性公网IP 负载均衡SLB
基于 K8S多集群隔离环境下的 DevOps实现 最佳实践 业务架构 场景描述 DevOps 是一组过程、方法与系统的统 称,并通过工具实现自动化部署,确保部署任 务的可重复性、减少部署出错的可能性。随着 微服务、中台架构的兴起,devops重要性日 益显著。本方案使用两个独立的 k8s集群:用户已 有的 k8s模拟测试,ack集群模拟生产...
弹性计算OOS审批流程自动化运维
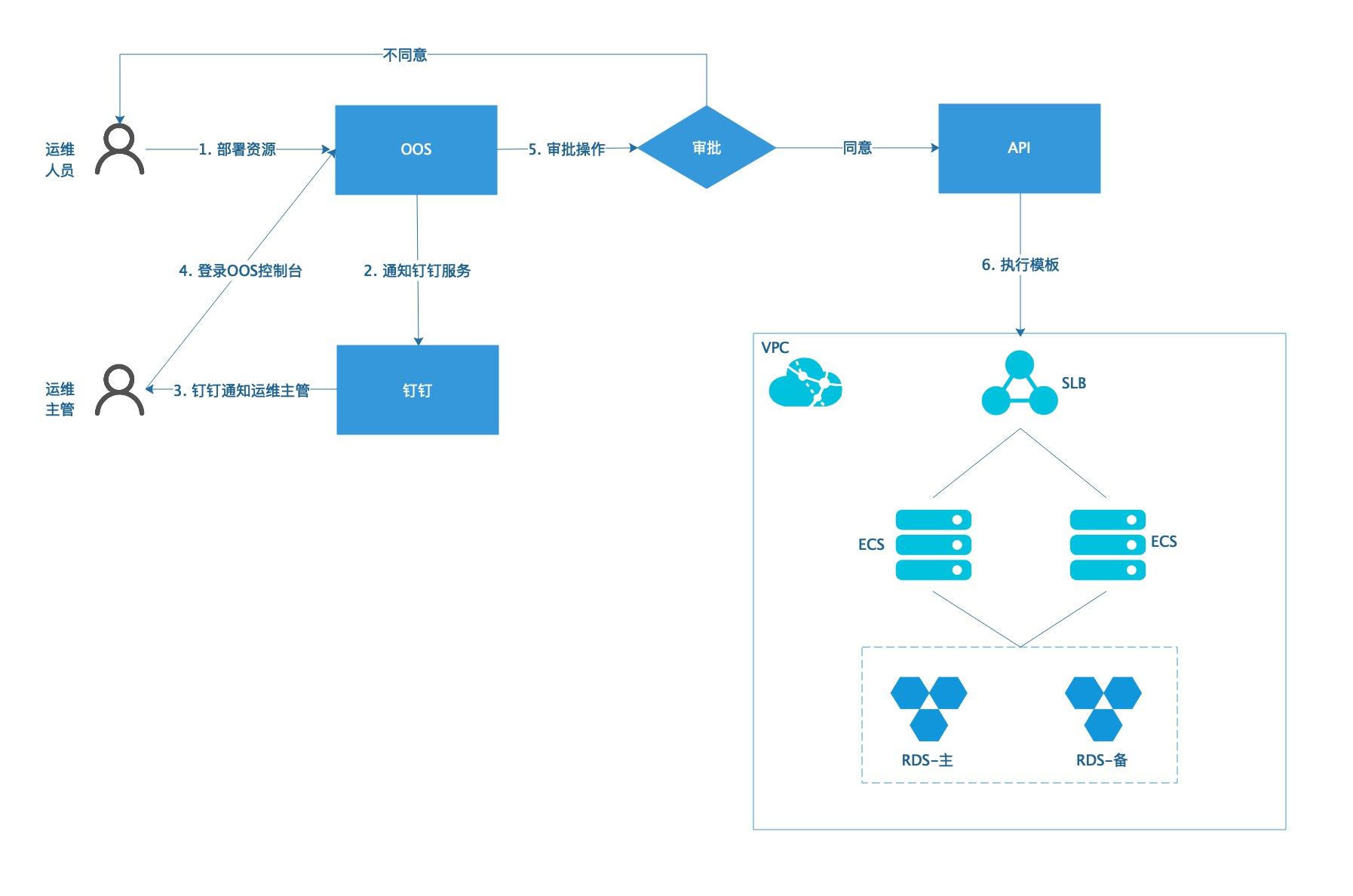
场景描述 本文以ECS、RDS、SLB搭建一个小型的WEB系 统为例,介绍如何利用OOS在运维常见的部署系统、 扩容系统、回收系统三个场景中添加审批流程,并以 钉钉通知到对应的审批人员。 解决问题 1.对接阿里云API,通过OOS模板执行运维 任务,实现了运维自动化与可视化。 2.运维操作集成了RAM访问控制权限管理, 无需担心操作安全,并可以快速增加审批流 程,提高运维安全与效率。 产品列表 1.运维编排OOS 2.访问控制RAM 3.云服务器ECS 4.RDSMySQL版 5.负载均衡SLB
弹性计算OOS审批流程自动化运维最佳实践 业务架构图 场景描述 本文以ECS、RDS、SLB搭建一个小型的WEB系 统为例,介绍如何利用OOS在运维常见的部署系统、扩容系统、回收系统三个场景中添加审批流程,并以 钉钉通知到对应的审批人员。解决问题 1.对接阿里云API,通过OOS模板执行运维 任务,实现了运维自动化与可视化。2.运维...
云上高并发系统改造
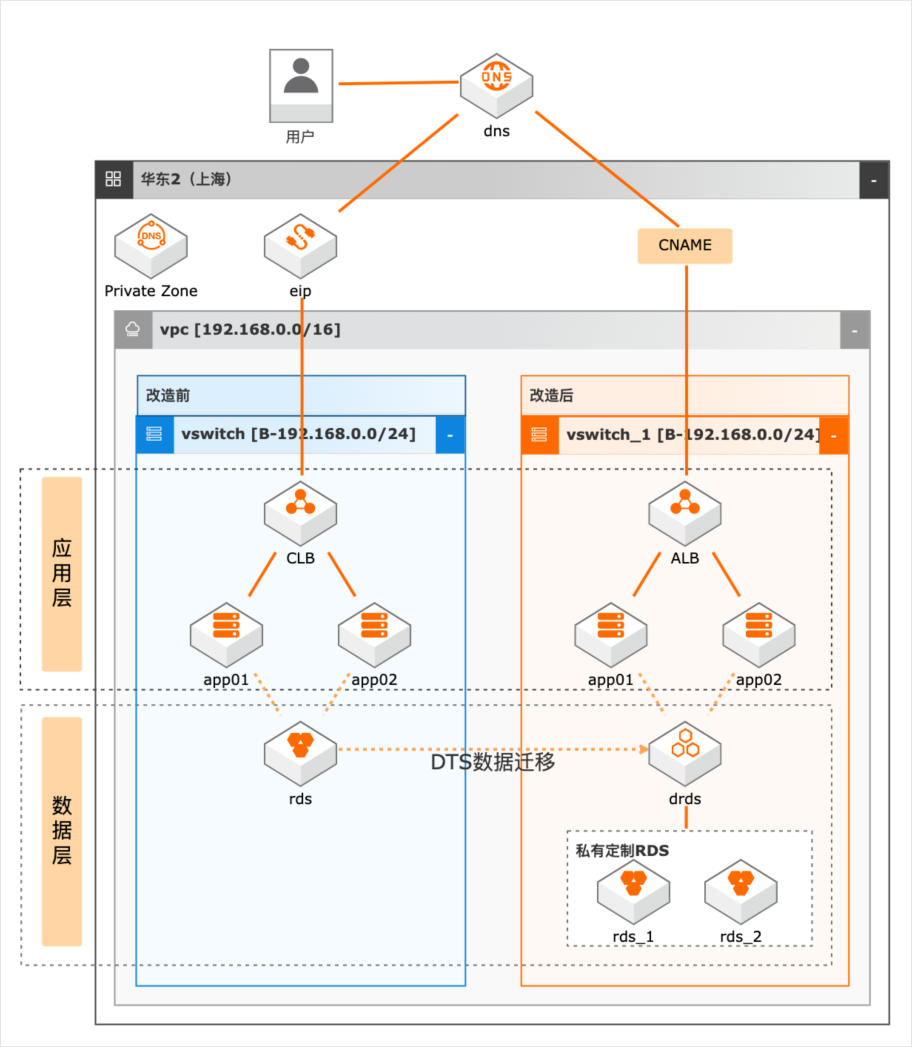
场景描述 随着业务的发展,系统并发压力越来越大,如何 进行系统改造以满足高并发场景的业务需求成 为了一个技术难题。本实践抽象于客户的实际场 景,提供高并发下系统改造的理论指导和部分实 操演示。主要适用于以下场景: 1.系统并发压力大,需要进行系统应用改造。 2.数据层并发压力大,需进行分库分表改造。 3.数据库数据量巨大,亟待分库分表解决查询 和写入瓶颈的场景。 方案优势/解决问题 1.在水平扩展阶段,我们除了通过SLB做负载 均衡外,我们可以通过SLB下挂nginx的方 式,增加负载均衡侧的可扩展性 2.在数据库拆分阶段,在做好数据规划后,我 们借助DTS进行数据迁移,通过DRDS将 RDS MySQL的数据拆分到多个分库和分 表中。 产品列表 专用网络VPC 负载均衡SLB 云服务器ECS 数据库RDSMySQL 数据传输服务DTS PrivateZone 分布式关系型数据库DRDS
尽可能避免跨库查询:关联查询的数据尽量分散到同一个分片中,跨库查询对系 统性能损耗很大。避免跨分表联表查询的方式有:a)剥离出高频访问的表,与核心表 1:1关系的,进行反范式设计,将核心表加 宽 b)如果与核心表是 N:1关系的,将高频访问字段冗余到核心表中 c)低频访问数据,业务功能设计上,避免一页展示大而全,...
Spring Cloud Netflix应用迁移EDAS
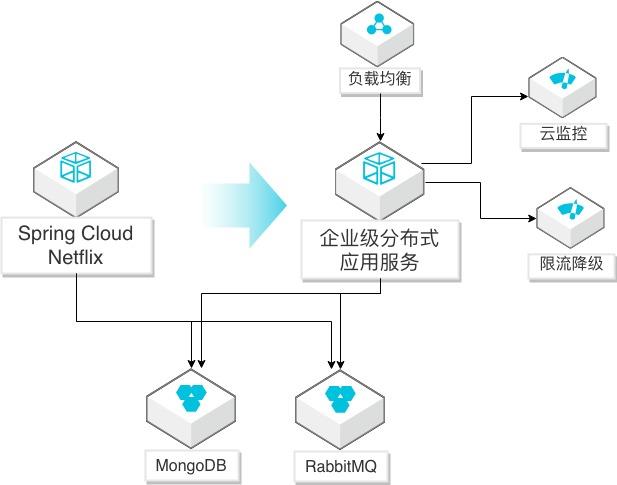
场景描述 Spring Cloud Netflix微服务应用迁移到EDAS 服务(SpringCloud Alibaba云版本)的方法, 迁移后充分利用阿里云监控、调用链、限流降级 等能力,优化应用生命周期管理。 解决问题 1.帮助自建SpringCloudNetflix微服务应用 通过简单修改迁移到阿里云企业级分布式 应用服务(EDAS)平台。 2.迁移到EDAS后,简化应用的运维,提升监 控、调用链探测、限流降级等管理能力,提 高对应用的全生命周期管理。 产品列表 企业级分布式应用服务(EDAS) 负载均衡(SLB) 专有网络(VPC) 云服务器(ECS)
3.EDAS 服务治理界面提供了一个统一的服务治理控制台,目前仅支持清晰的查询 发布和消费服务详情,更多功能在开发中。4.EDAS 提供了动态扩缩容功能,可以根据流量高峰和低谷实时的为您的应用扩容 和缩容。5.EDAS提供了高级监控功能,除了基本的机器信息查询之后,还支持查询微服务调 用链信息,系统调用拓扑图,慢 SQL查询...
- 产品推荐
- 这些文档可能帮助您