可观测链路 OpenTelemetry版结合日志服务SLS关联分析最佳实践
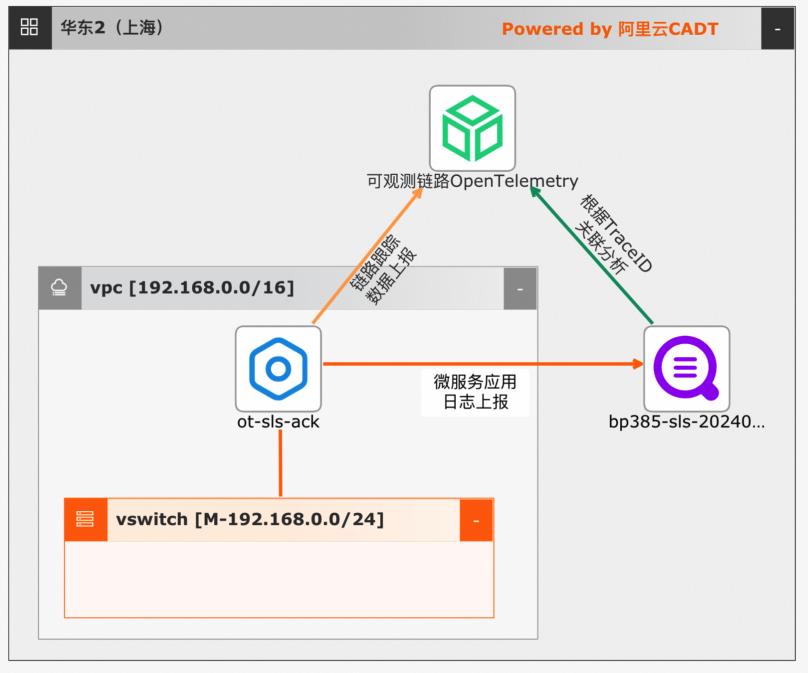
可观测链路 OpenTelemetry 版为分布式应用的开发者提供了完整的调用链路还原、调用请求量统计、链路拓扑、应用依赖分析等工具,可以帮助开发者快速分析和诊断分布式应用架构下的性能瓶颈,当应用出现业务异常问题时,您可以在可观测链路 OpenTelemetry 版控制台关联查看日志进行分析,精准定位业务异常。
可观测链路 OpenTelemetry 版结合日志服务 SLS关联分析 最佳实践 场景描述 业务架构 可观测链路 OpenTelemetry 版为分布式应用的 开发者提供了完整的调用链路还原、调用请求量 统计、链路拓扑、应用依赖分析等工具,可以帮 助开发者快速分析和诊断分布式应用架构下的 性能瓶颈,当应用出现业务异常问题时,您可以 在可观测...
SLS数据入湖Kafka最佳实践
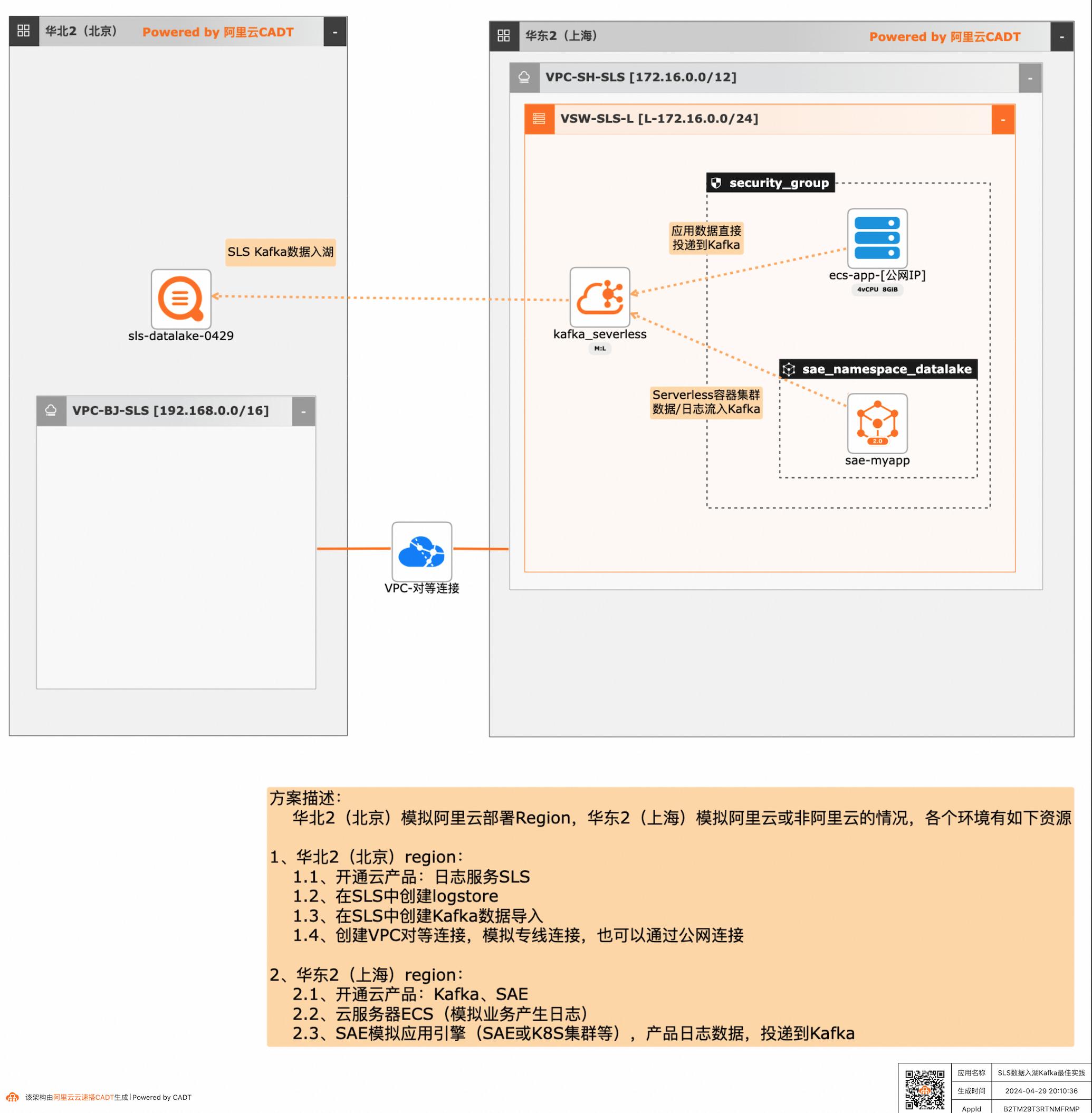
应用和数据分散在多云或混合云,在面对多云/混合云这样大的趋势下,数据无法进行统一的聚合、分析处理和导出等,本方案给出了在多云/混合云场景下,构建通过标准的Kafka协议和托管服务,SLS可以连接Kafka数据入湖导入,然后进行统一的海量数据的集中存储、智能转储、聚合分析查询等。
日志服务SLS:是云原生观测与分析平台,为Log、Metric、Trace等数据提 供大规模、低成本、实时的平台化服务,日志服务一站式提供数据采集、加工、查询与分析、可视化、告警、消费与投递等功能,全面提升您在研发、运维、运营、安全等场景的数字化能力。 云消息队列Kafka版:是阿里云基于ApacheKafka构建的高吞吐量、...
移动开发平台 mPaaS
阿里云移动开发平台 mPaaS提供App开发、测试、运营及运维等云到端的一站式解决方案,帮助企业快速构建高质量的移动应用,阿里云快速开发平台提升企业产品生态发展。
查看更多登录mPaaS控制台,体验更多功能产品选型mPaaS订阅基础套餐mPaaS资源包移动应用安全加固3个月免费试用,立即开通 入门与试用快速上手01创建应用1iOS2Android3Harmony02下载配置1应用元数据服务地址03本地开发1IDE 插件04发布1版本发布2灰度发布05运营1Crash 报告2行为分析3性能分析4消息推送06修复1热修复技术解决...
来自:
云产品
容器场景下的应用性能监控、调用链拓扑、内存剖析
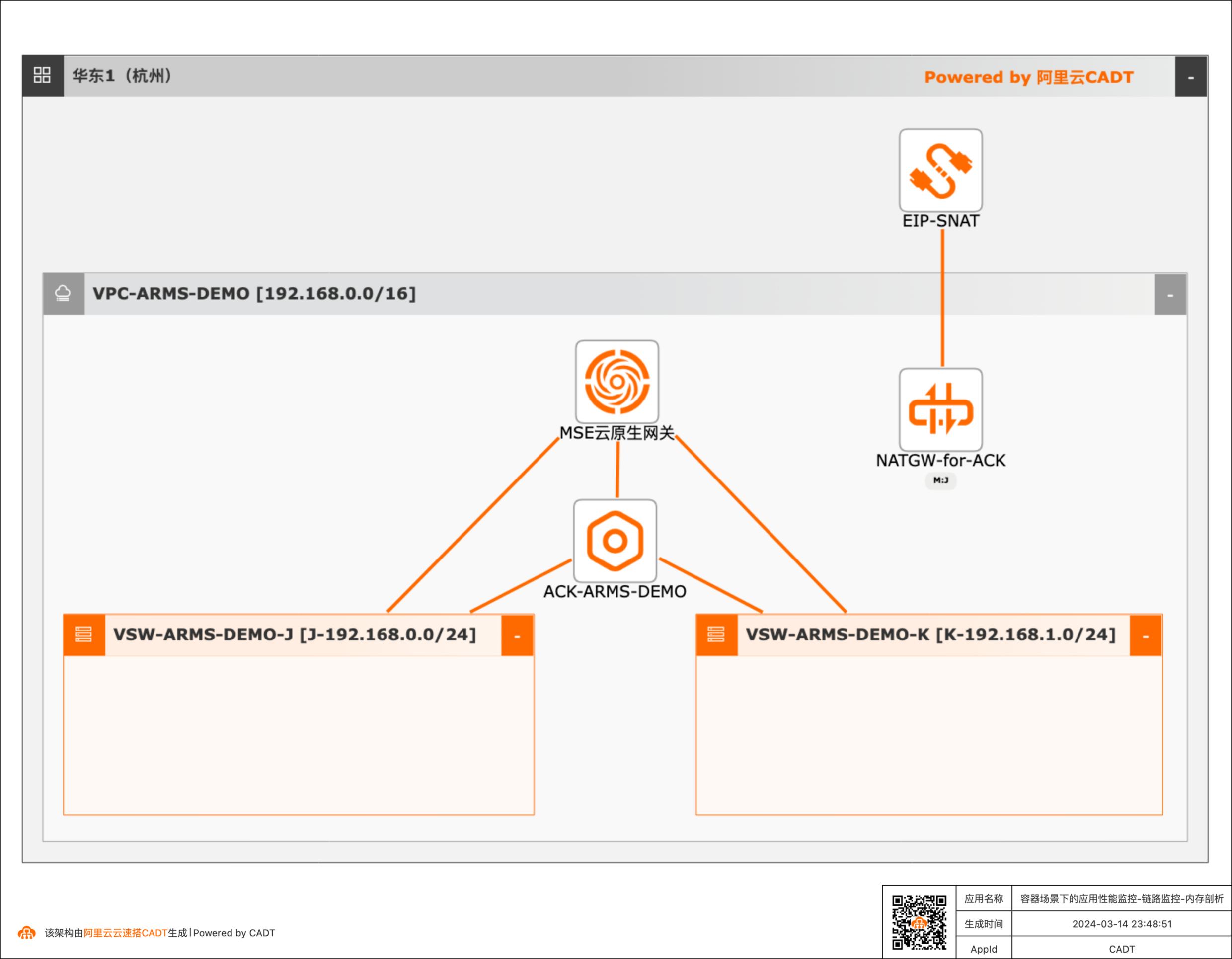
场景描述 随着云原生及微服务技术的普及,越来越多的系统已经通过云原生和微服务技术实现企业的降本增效,同时因微服务及云原生的复杂性给系统运维带来非常大的挑战,云原生应用监控arms通过全链路应用监控,从端到端及代码级别的链路下钻能力、CPU、内存持续剖析及诊断能力,帮助客户降低系统故障定位难度,此demo,您将体验arms的链路监控、内存剖析等能力 应用场景 微服务+容器场景下链路调用拓扑,调用链可以显示出服务之间的调用顺序和层次关系,帮助开发人员理解和追踪代码的执行流程 在分布式系统中,一个请求往往需要通过多个服务来完成。当出现问题时,如请求超时、错误或异常,很难快速定位问题所在。 解决问题 调用链可以帮助运维人员解决以下问题: · 故障排查:当请求失败或出现错误时,调用链可以显示整个请求的路径和每个服务的执行情况,从而帮助运维人员快速定位问题所在。 · 性能优化:通过调用链,运维人员可以了解请求在系统中的执行时间和瓶颈所在,从而进行优化。 · 系统监测:调用链可以提供实时的系统监测和分析,帮助运维人员了解系统的健康状况和资源利用情况。
容器场景下的应用性能监控、调用链拓扑、内存剖析 最佳实践 场景描述 业务架构 随着云原生及微服务技术的普及,越来越多的系 统已经通过云原生和微服务技术实现企业的降 本增效,同时因微服务及云原生的复杂性给系统 运维带来非常大的挑战,云原生应用监控arms 通过全链路应用监控,从端到端及代码级别的链 路下钻能力、CPU...
基于SpringCloud应用玩转MSE实践
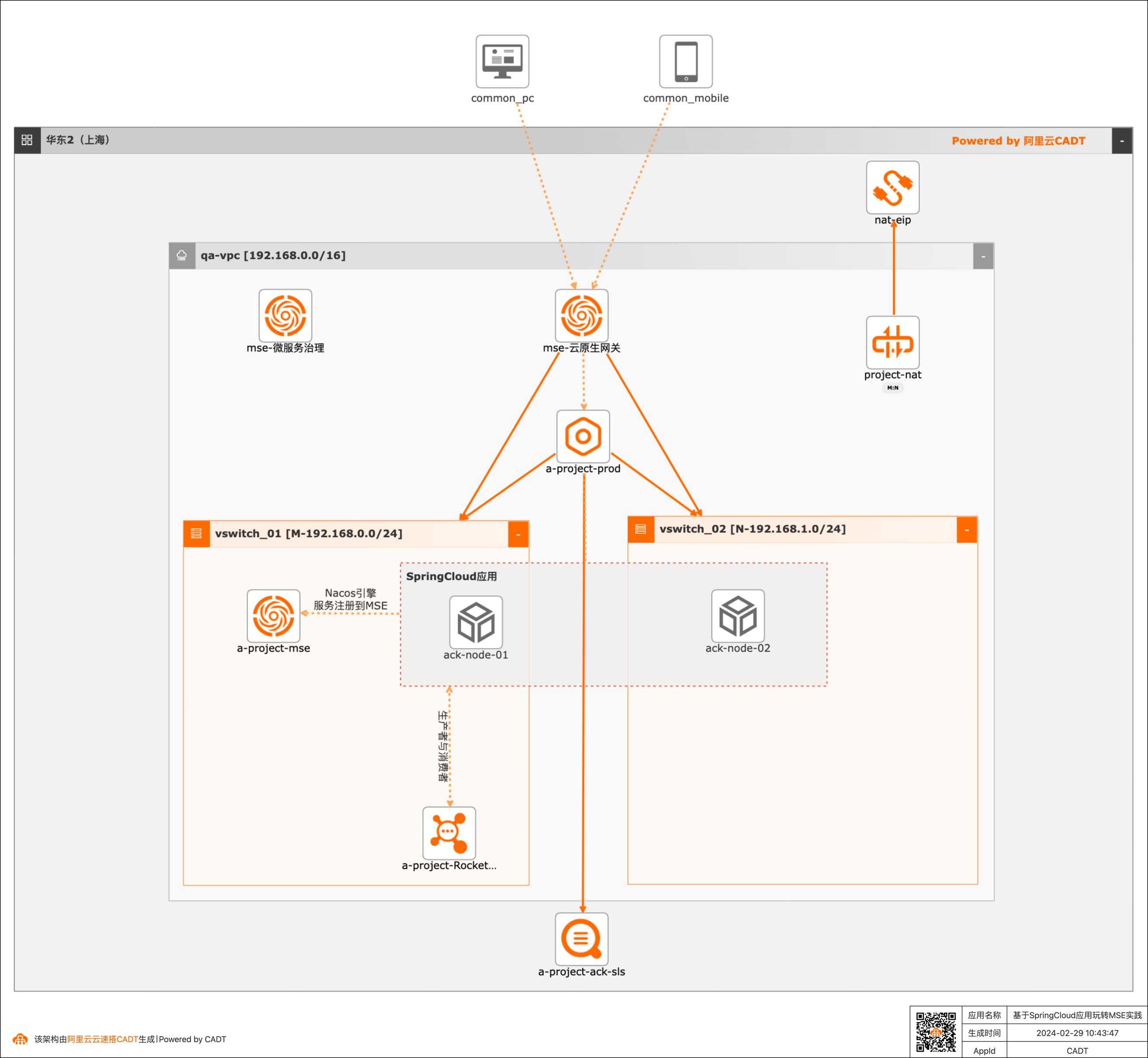
随着业务不断创新,大型的单个应用和服务会被拆分为数个甚至数十个微服务,微服务架构已经被广泛应用。 微服务的好处在于快速迭代,如何在迭代过程中保障线上流量不受损。依赖开源产品缺少无运维工具,常常需要投入较大的运维人力和成本。 本实践提供基于云原生应用产品提供微服务注册配置中心、微服务治理和云原生网关等一系列高性能和高可用的企业级云服务能力。
应用计价成功后,CADT会实时生成一个应用架构成本分析报告,可以单击查看报告。文档版本:20240229基于SpringCloud应用玩转MSE 如果确认价格符合预期,可以单击下一步:确认订单。步骤8 确认订单阶段会列出架构中所有的产品及其价格,需要用户确认无误后勾选接受《云 速搭服务条款》,此时下一步:支付并创建才会高亮,可以...
Kafka性能压测快速方案
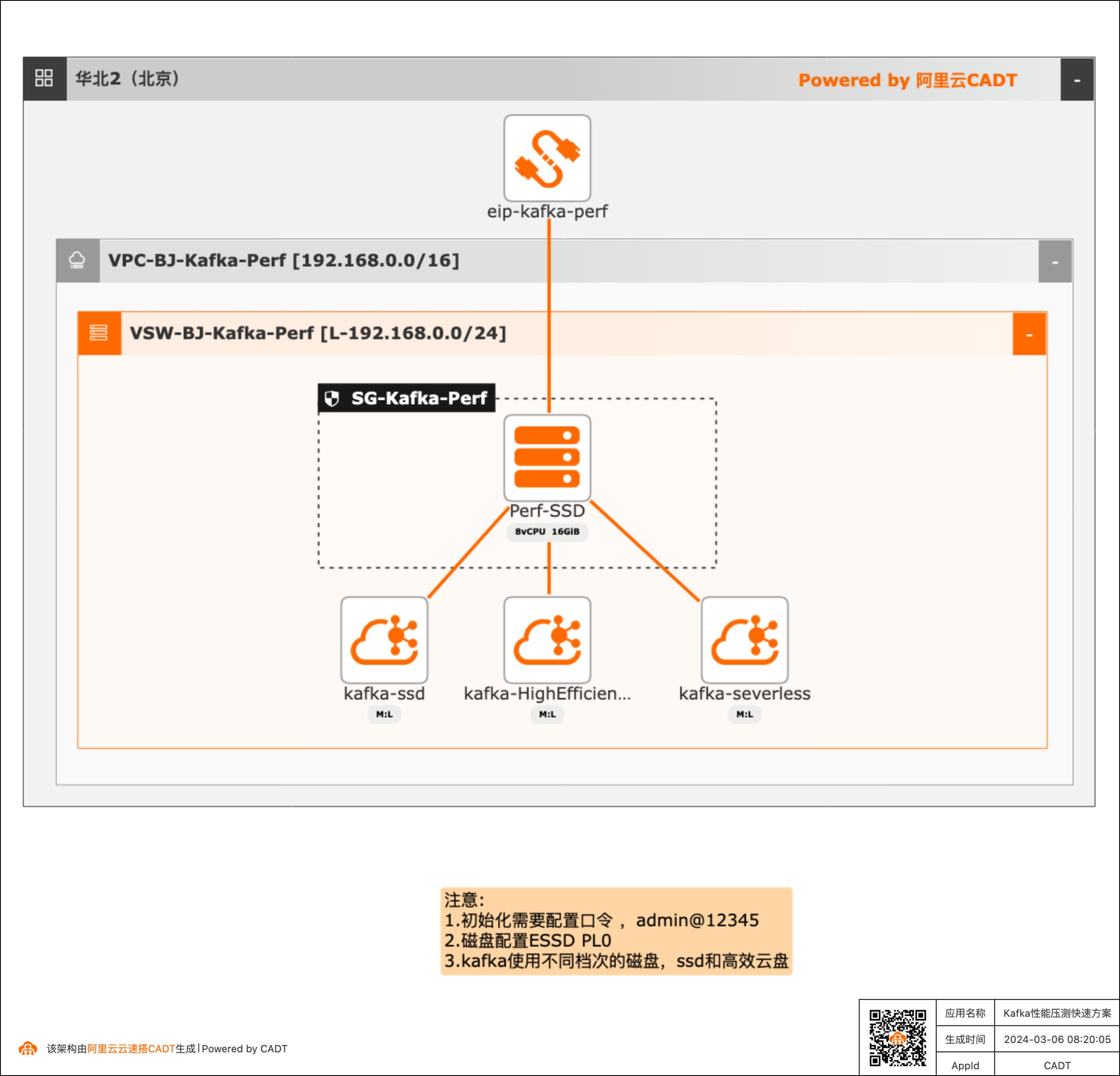
产品性能基线测试场景需要对产品进行性能测试得到详细的压测数据,本方案可以快速构建测试的客户端(kafka官方的压测客户端)和不同的Kafka服务端( SSD云盘版、高效云盘、Serverless版三种实例),方便客户进行POC完成性能验证。
应用计价成功后,CADT会实时生成一个应用架构成本分析报告,可以单击查看报告。文档版本:20240229 17Kafka性能压测快速方案 部署基础环境 步骤14如果确认价格符合预期,可以单击下一步:确认订单。确认订单阶段会列出架构中所有的产品及其价格,需要用户确认无误后勾选接受《云 速搭服务条款》,此时下一步:支付并创建才...
大模型RAG对话系统部署
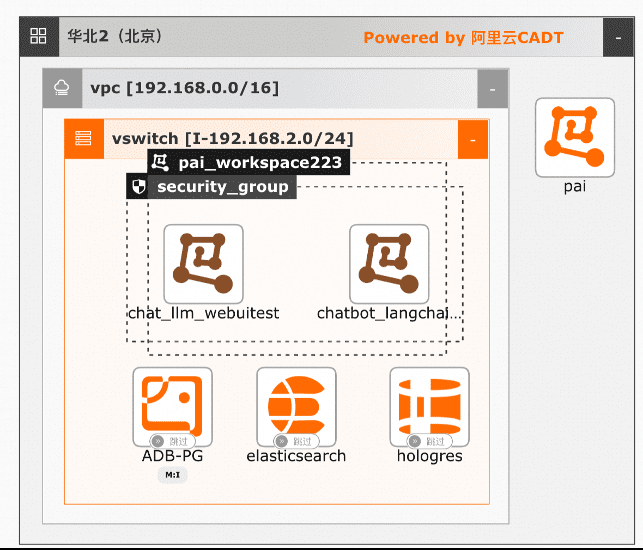
大模型RAG对话系统最佳实践,旨在指引AI开发人员如何有效地结合LLM大语言模型的推理能力和外部知识库检索增强技术,从而显著提升对话系统的性能,使其能更加灵活地返回用户查询的内容。适用于问答、摘要生成和其他依赖外部知识的自然语言处理任务。通过该实践,您可以掌握构建一个大模型RAG对话系统的完整开发链路。
不仅提供云上开箱即用 的 Elasticsearch、Logstash、Kibana、Beats在内的 Elastic Stack生态组件,还 与 Elastic官方合作提供免费 X-Pack(白金版高级特性)商业插件,集成了安全、SQL、机器学习、告警、监控等高级特性,被广泛应用于实时日志分析处理、信息 检索、以及数据的多维查询和统计分析等场景。云原生数据仓库 ...
SLS多云日志采集、处理及分析
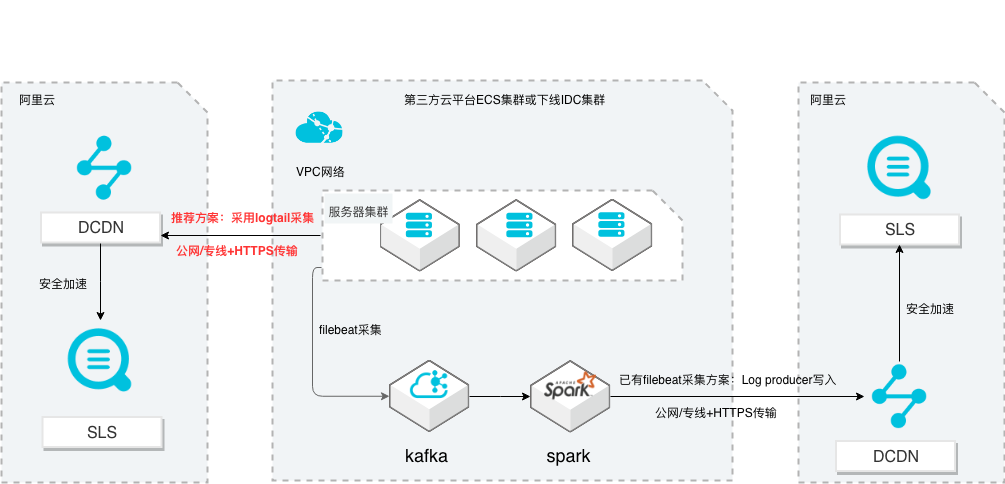
场景描述 从第三方云平台或线下IDC服务器上采集 日志写入到阿里云日志服务,通过日志服务 进行数据分析,帮助提升运维、运营效率, 建立DT 时代海量日志处理能力。 针对未使用其他日志采集服务的用户,推荐 在他云或线下服务器安装logtail采集并使用 Https安全传输;针对已使用其他日志采集 工具并且已有日志服务需要继续服务的情 况,可以通过Log producer SDK写入日志 服务。 解决问题 1.第三方云平台或线下IDC客户需要使用 阿里云日志服务生态的用户。 2.第三方云平台或线下IDC服务器已有完 整日志采集、处理及分析的用户。 产品列表 E-MapReduce 专有网络VPC 云服务器ECS 日志服务LOG DCDN
文档版本:20211203 24 SLS多云日志采集、处理及分析 Logtail日志采集处理分析 注意:查询分析设置的修改操作只会对新写入的数据生效,如果您需要提前对查询分 析设置的某些字段分析统计生效,请使用指定字段查询的自定义方式在日志写入到日 志库之前进行开启统计查询。步骤4 再次启动日志发生器和停止日志发生器。按云...
互联网电商行业离线大数据分析

电商网站销售数据通过大数据分析后将业务指标数据在大屏幕上展示,如销售指标、客户指标、销售排名、订单地区分布等。大屏上销售数据可视化动态展示,效果震撼,触控大屏支持用户自助查询数据,极大地增强数据的可读性。
互联网电商行业离线大数据分析 最佳实践 业务架构 场景描述 本实践介绍了使用阿里云MaxCompute、数据库(RDS)、DataWorks等产品实现电商网站离线数据分 析,分析后的业务指标数据实时在大屏展示。通过完整 的实践Demo为例,提供从电商网站搭建,数据从RDS 同步到MaxCompute、再到DataWorks进行数据分析,最后在大屏上展示...
利用交互式分析(Hologres)进行数据查询
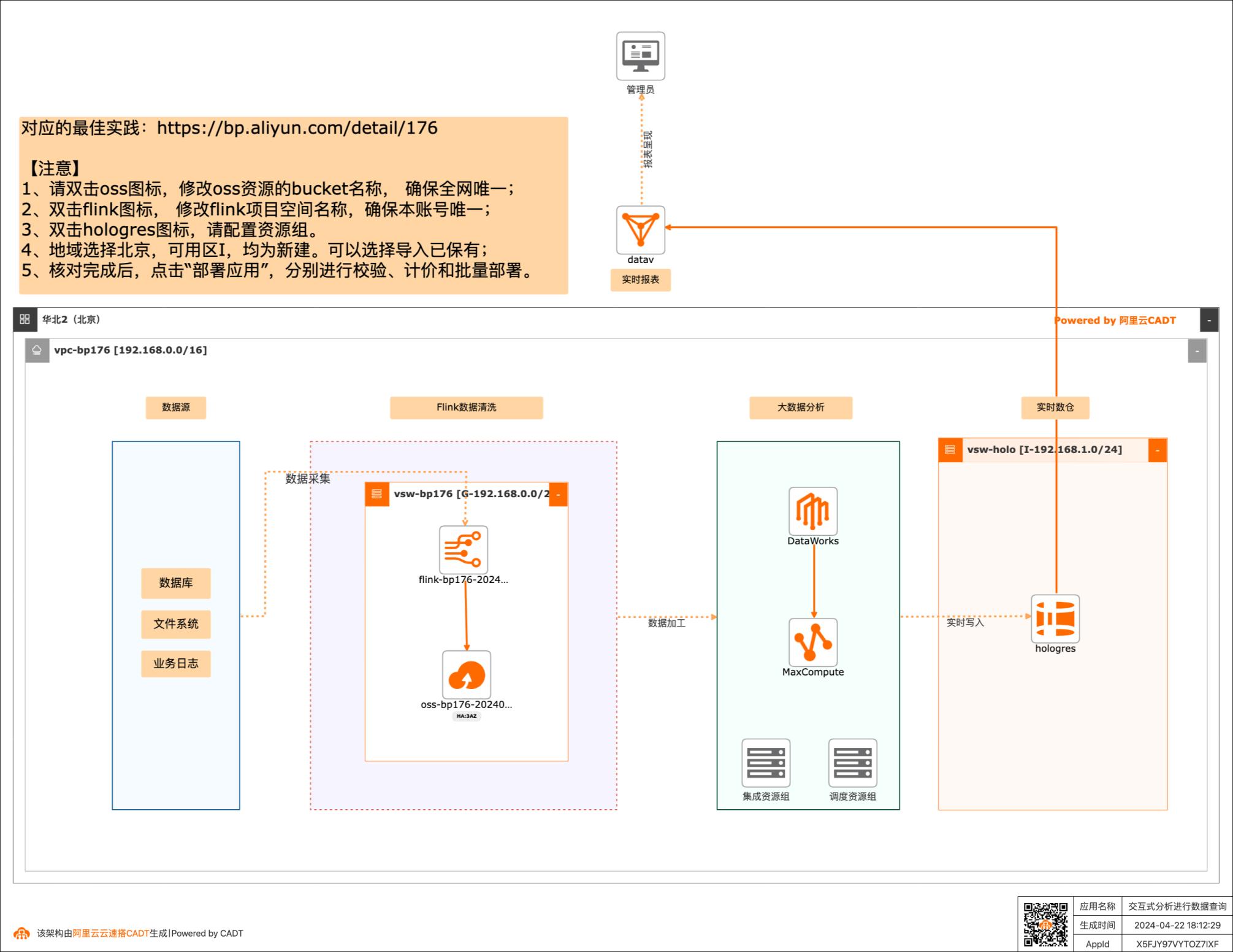
场景描述:随着收集数据的方式不断丰富,企业信息化 程度越来越高,企业掌握的数据量呈TB、 PB或EB级别增长。同时,数据中台的快 速推进,使数据应用主要为数据支撑、用户 画像、实时圈人及广告精准投放等核心业务 服务。高可靠和低延时地数据服务成为企业 数字化转型的关键。 Hologres致力于低成本和高性能地大规模 计算型存储和强大的查询能力,为您提供海 量数据的实时数据仓库解决方案和实时交 互式查询服务。 解决问题 1.加速查询MaxCompute数据 2.快速搭建实时数据仓库 3.无缝对接主流BI工具 产品列表 MaxCompute Hologres 实时计算Flink 专有网络VPC DataWorks DataV
应用计价成功后,CADT会实时生成一个应用架构成本分析报告,可以单击查看报 告。步骤8 同意并勾选《云速搭服务条款》,单击下一步:支付并创建。因为有包月服务,再点 击确认包月的datav服务。步骤9 部署预计5分钟~10分钟左右,部署成功后,如下图所示:2.3.创建子用户 步骤1 登录RAM访问控制管理控制台。...
基于Flink+ClickHouse构建实时游戏数据分析
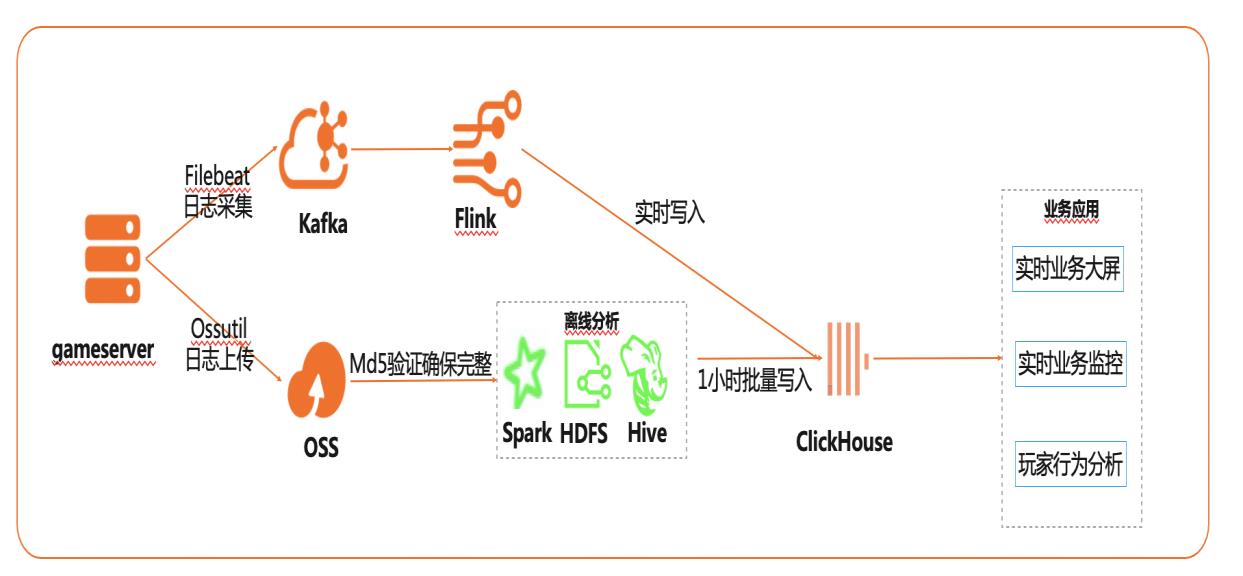
在互联网、游戏行业中,常常需要对用户行为日志进行分析,通过数据挖掘,来更好地支持业务运营,比如用户轨迹,热力图,登录行为分析,实时业务大屏等。当业务数据量达到千亿规模时,常常导致分析不实时,平均响应时间长达10分钟,影响业务的正常运营和发展。 本实践介绍如何快速收集海量用户行为数据,实现秒级响应的实时用户行为分析,并通过实时流计算Flink/Blink、云数据库ClickHouse等技术进行深入挖掘和分析,得到用户特征和画像,实现个性化系统推荐服务。 通过云数据库ClickHouse替换原有Presto数仓,对比开源Presto性能提升20倍。 利用云数据库ClickHouse极致分析性能,千亿级数据分析从10分钟缩短到30秒。 云数据库ClickHouse批量写入效率高,支持业务高峰每小时230亿的用户数据写入。 云数据库ClickHouse开箱即用,免运维,全球多Region部署,快速支持新游戏开服。 Flink+ClickHouse+QuickBI
文档版本:20201224 17 基于 Flink+ClickHouse构建实时游戏数据分析 基础环境部署 步骤6 部署完成后,可查看部署报告,方便以后运维工作,如下图所示,截取于自动生成的 部署报告的部分内容。文档版本:20201224 18 基于 Flink+ClickHouse构建实时游戏数据分析 基础环境部署 控制台确认资源创建情况 步骤1 登录阿里云管理...
云速搭部署SLS实现日志采集处理分析

通过云速搭部署ECS+SLS,在ECS上安装logtail收集Nginx应用日志写入SLS。通过日志生成器模拟Nginx日志生成,并通过SLS进行日志分析。
文档版本:20211203 30 云速搭部署 SLS实现日志采集处理分析 Logtail日志采集处理分析 注意:查询分析设置的修改操作只会对新写入的数据生效,如果您需要提前对查询分 析设置的某些字段分析统计生效,请使用指定字段查询的自定义方式在日志写入到日 志库之前进行开启统计查询。步骤4 再次启动日志发生器和停止日志发生器。...
E-MapReduce Serverless StarRocks 版
E-MapReduce Serverless StarRocks版简称EMR StarRocks,是阿里云提供的全托管服务,内核100%兼容StarRocks,性能比传统OLAP引擎提升3-10倍,助力企业高效构建湖仓分析、高并发查询及实时分析等大数据应用。
对集群概览、计算、存储及查询、导入等提供诊断分析报告,以优化集群到更加的健康状态.全托管分析平台.可视化的 StarRocks 实例管理控制台,使得实例的整体运维和管理更方便.易用的数据查询分析.支持可视化 SQL Editor 编辑器,随时进行查询分析。提供丰富的元数据的查询能力,支持用户安全及权限管理,导入任务管理.支持慢...
来自:
云产品
基于SLS实现统一告警最佳实践
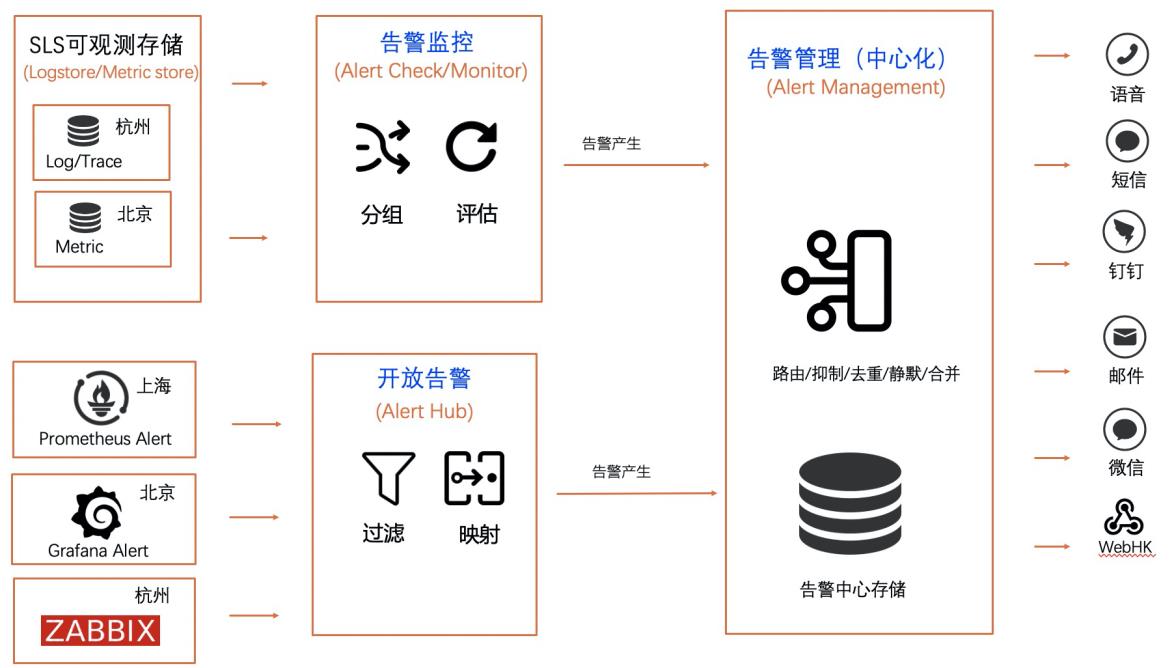
告警对于企业的开发运维,安全运维,业务运维有着至关重要的作用。然而很多企业在告警运维方面存在着重复建设、监控质量差、告警风暴、触达不人性化、无法闭环等问题。 针对企业在告警管理方面存在的痛点问题,SLS告警提供了一站式云上告警管理方案,具有弹性易用、稳定可靠、功能持续升级、成本更低、噪音更少等优势。企业可以将现有的监控方案系统无缝接入到SLS告警平台,实现在SLS上一站式管理告警。
基于 SLS实现统一告警 最佳实践 业务架构 场景描述 告警监控对于一个企业有着至关重要的作 用,然而很多企业在告警运维方面存在着重 复建设、监控质量差、告警风暴、触达不人 性化、无法闭环等问题。SLS告警提供了一站式云上告警管理方案,能够有效的解决企业在使用告警中的痛点。本文以通过自定义告警、Prometheus 告 警、...
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
其优点是学习成本低,可以通过类 SQL语句快速 实现简单的 MapReduce统计,不必开发专门的 MapReduce应用,十分适合数据 仓库的统计分析。RDS:阿里云关系型数据库(Relational Database Service,简称 RDS)是一种 稳定可靠、可弹性伸缩的在线数据库服务。基于阿里云分布式文件系统和 SSD盘 高性能存储,RDS支持 MySQL、SQL...
- 产品推荐
- 这些文档可能帮助您