大数据近实时数据投递MaxCompute
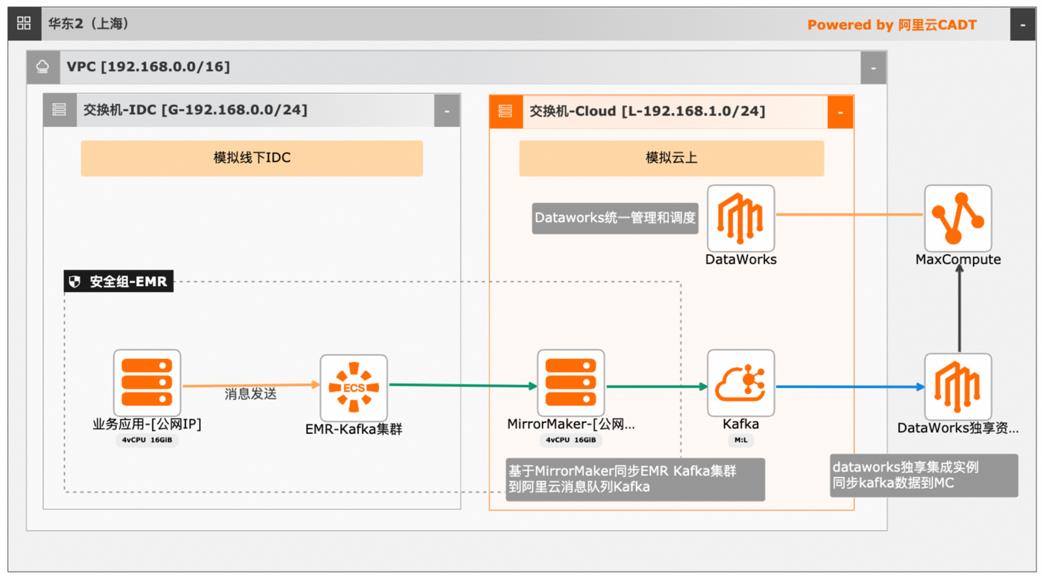
本文介绍离线大数据场景使MaxCompute构建云 上近实时数仓,打通云下数据上云链路,解决数据复杂类型支持和动态分区问题,满足高级数据处理需求的最佳实践。 l混合云环境下,现有业务系统零改造,打通数据上云链路。 l使用UDF实现复杂数据类型转换和数据动态分区。 l使用DataWorks配置周期调度业务流程,数据自动入仓。 l借助MaxCompute优化计算引擎,实现降本增效。 产品列表 云服务器ECS 专有网络VPC 访问控制RAM 数据总线DataHub E-MapReduceEMR DataWorks 大数据计算服务MaxCompute
kafka-console-consumer.sh-bootstrap-server core-1-1:9092-topic message-from-beginning-max-messages 10 文档版本:20240419 15 大数据近实时数据投递 MaxCompute 4.EMR Kafka数据拉取至消息队列 Kafka 在本实践中,云上环境使用独立 ECS部署 MirrorMaker服务同步 EMR Kafka集群 数据至云上阿里云消息队列 Kafka,再...
云呼叫中心
阿里云呼叫中心(Cloud Call Center)是阿里云推出的企业级智能联络中心类产品,为客户提供灵活的坐席扩展能力、高性能的分布式服务以及丰富的OpenAPI能力,搭配智能排队路由、可视化IVR以及阿里云智能客服产品体系,轻松搭建智能化的联络中心服务。
了解更多信息,请添加钉钉:cccsupport2.云联络中心(原云呼叫中心).无需繁琐部署,无需技术支持,一键创建智能呼叫中心,一键发布上线.自由接入智能化模块,支撑大并发多样性业务,提升管理效能.采用自助式图形界面,非技术用户也可以轻松设计IVR流程.多种方式集成,灵活集成第三方系统,实现来电弹屏,交互式IVR.更多产品...
来自:
云产品
媒体处理MPS
阿里云媒体处理(ApsaraVideo for Media Processing,原MTS)是一种多媒体数据处理服务。它以经济、弹性和高可扩展的转换方法,将多媒体数据转码成适合在全平台播放的格式。并基于海量数据深度学习,对媒体的内容、文字、语音、场景多模态分析,实现智能审核、内容理解、智能编辑。
集成消息队列和通知.对象存储OSS.消息服务MNS.推荐搭配使用.更稳定,更流畅的点播体验.丰富的视频功能,给用户较好的观看体验,助您快速构建自己的教学平台!满足教师分享课程视频的需求,实现对教育资源的统一管理.高可靠的云存储服务和灵活定制的防盗链、链接鉴权功能双重保障资源安全.视频版权保护.支持在输出的视频上...
来自:
云产品
自建Hadoop迁移到阿里云EMR
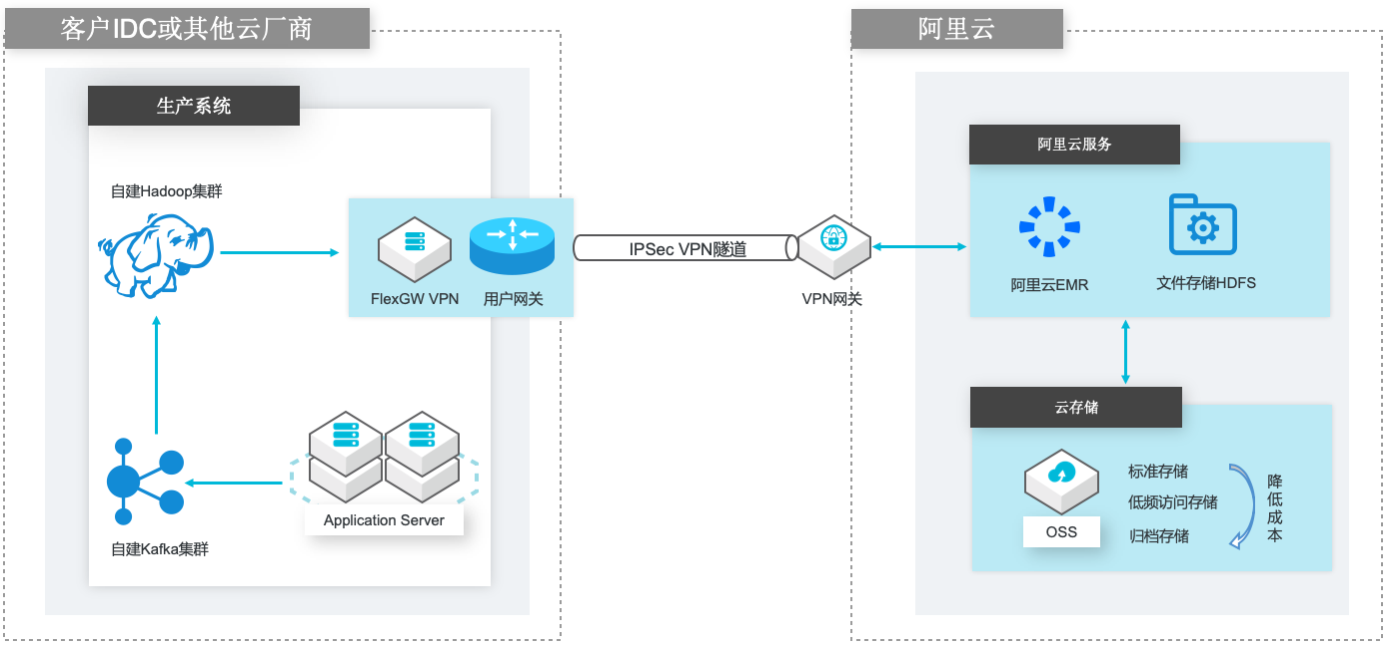
场景描述 场景1:自建Hadoop集群数据(HDFS)迁移到 阿里云EMR集群的HDFS文件系统; 场景2:自建Hadoop集群数据(HDFS)迁移到 计算存储分离架构的阿里云EMR集群,以OSS 和JindoFS作为EMR集群的后端存储。 解决的问题 客户自建Hadoop迁移到阿里云EMR集群的 技术方案; 基于IPSecVPN隧道构建安全和低成本数据 传输链路 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
在 Kafka队列的 ECS上启动一个 Consumer(消费者)进程,用于查看队列中收 到的日志消息。首先通过 SSH登录到后台,然后执行如下命令(下面两行为同一 条命令,在第一行末尾有换行符“\”):/opt/kafka/bin/kafka-console-consumer.sh-bootstrap-server \ Kafka所在 ECS的 VPC IP地址:9092-topic log-generator-topic 文档...
Spark on ECI大数据分析

场景描述 方案优势 1.计算引擎弹性扩缩容,兼顾资源弹性与计 算资源成本优化。 2.计算与存储分离架构,结合阿里云原生云 存储产品,海量数据湖优势。 3.Kubernetes原生的调度性能优势,提升在 大规模分析作业时的分析性能优势分。 4.集群资源隔离和按需分配。 解决问题 1.计算资源弹性能力不足,计算资源成本管 控能力欠缺. 2.集群资源调度能力和隔离能力不足。 3.计算与存储无法分离,大数据量分析时出 现数据存储资源瓶颈。 4.Spark submit方式提交分析作业参数支持 有限等缺点。 产品列表 容器服务Kubernetes版(ACK) 弹性容器实例(ECI) 文件存储HDFS 对象存储OSS 专有网络VPC 容器镜像服务ACR
2.配置环境变量,添加 SPARK_HOME的相关路径(vim~/.bash_profile文件添加相 关环境变量以后并执行 source~/.bash_profile,使环境变量添加修改生效)。步骤3 编写 Dockerfile。在本地应用的 target目录下(与应用 jar包在同一个目录)编写 Dockerfile。文档版本:20200409 15 Spark on ECI大数据分析 应用开发 步骤4 构建...
自建Hadoop迁移MaxCompute
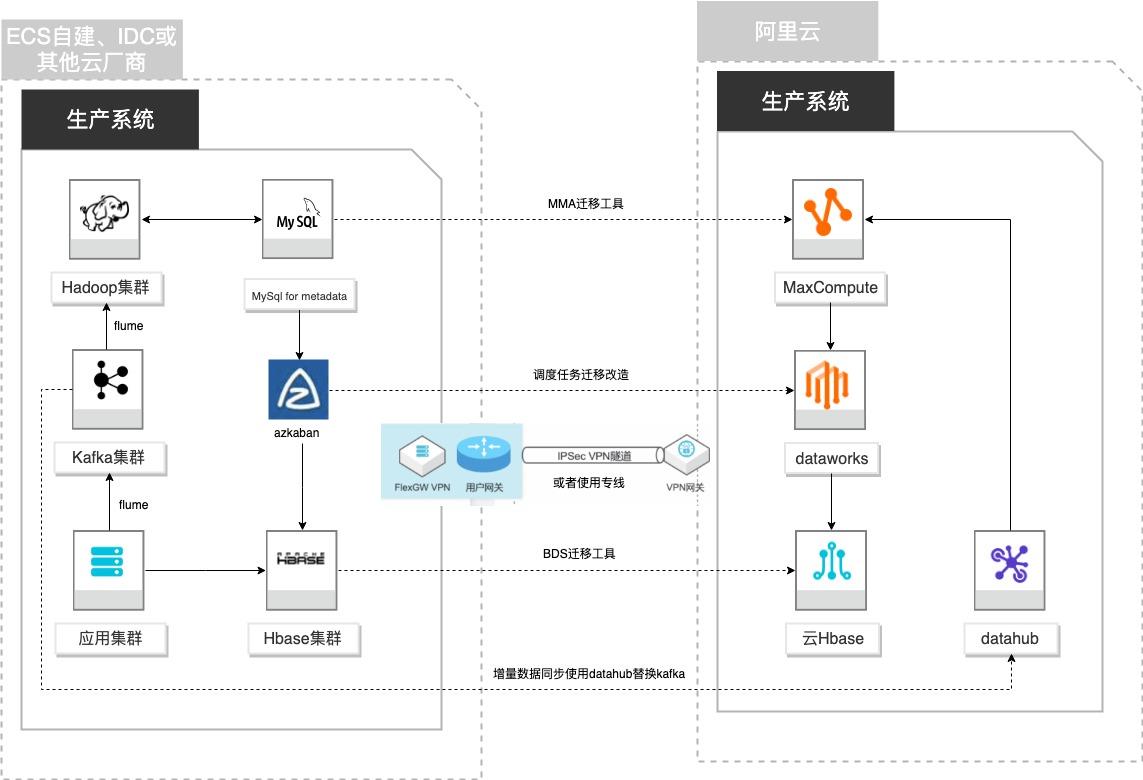
场景描述 客户基于ECS、IDC自建或在友商云平台自建了大数 据集群,为了降低企业大数据计算平台的成本,提高 大数据应用开发效率,更有效保障数据安全,把大数 据集群的数据、作业、调度任务以及业务数据库整体 迁移到MaxCompute和其他云产品。 解决的问题 自建Hadoop集群搬迁到MaxCompute 自建Hbase集群搬迁到云Hbase 自建Kafka或应用数据准实时同步到 MaxCompute 自建Azkaban任务迁移到Dataworks任务 产品列表 MaxCompute,Dataworks、云数据库Hbase版、Datahub、VPC,ECS。
Kafka迁移到 Datahub 步骤5 预览数据 文档版本:20210723 48 自建Hadoop迁移MaxCompute Azkaban定时任务迁移和改造 6.Azkaban定时任务迁移和改造 本实践方案中,自建 Hadoop集群的数据的流向如下所示:日志发生器→Kafka队列→HDFS文件系统→Azkaba任务 01执行→Hive表 apache_logs→Azkaba任务 99执行→Hbase表 job99_ip_...
Spring Cloud Netflix应用迁移EDAS
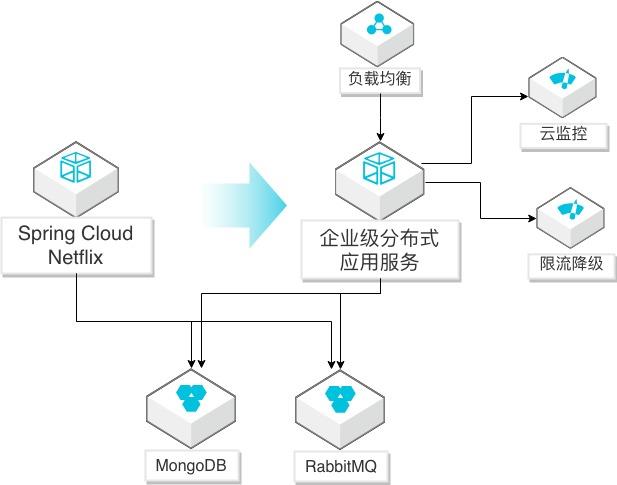
场景描述 Spring Cloud Netflix微服务应用迁移到EDAS 服务(SpringCloud Alibaba云版本)的方法, 迁移后充分利用阿里云监控、调用链、限流降级 等能力,优化应用生命周期管理。 解决问题 1.帮助自建SpringCloudNetflix微服务应用 通过简单修改迁移到阿里云企业级分布式 应用服务(EDAS)平台。 2.迁移到EDAS后,简化应用的运维,提升监 控、调用链探测、限流降级等管理能力,提 高对应用的全生命周期管理。 产品列表 企业级分布式应用服务(EDAS) 负载均衡(SLB) 专有网络(VPC) 云服务器(ECS)
2.4节介绍部署微服务应用依赖的 RabbitMQ消息队列。2.5节介绍部署微服务应用依赖的 MongoDB数据库。2.6节介绍修改应用启动成功线下微服务应用。2.2.构建 PiggyMetrics本地开发环境 步骤1 下载项目源码。git clone https://github.com/sqshq/piggymetrics.git 步骤2 自行安装 JAVA环境和 MAVEN编译环境。1.请自行完成下载 ...
云消息队列 Confluent 版
云消息队列 Confluent 版是阿里云与 Apache Kafka 项目创始团队所创立的 Confluent 公司合作,基于 Apache Kafka 核心能力提供的企业级全托管消息队列服务,旨在为企业提供集成消息流式处理与大数据系统的一站式解决方案。
快速使用云消息队列 Confluent 版.云消息队列 Confluent 版所有文档.云消息队列 Confluent 版计费说明.阿里云与 Confluent 专家技术交流.Apache Kafka 全托管消息服务,大数据生态中不可或缺的消息产品,具备开箱即用、无缝迁移、安全可靠、免运维等特点.云消息队列 Kafka 版.阿里巴巴官方指定消息产品,成熟、稳定、先进的...
来自:
云产品
云消息队列 ApsaraMQ
云消息队列 ApsaraMQ 是阿里云自主研发的消息队列服务系列产品的总称,旨在为开发者和企业的不同业务场景提供强大、可靠、低成本、高弹性且易于管理的消息服务。云消息队列 ApsaraMQ 全系列产品提供 Serverless 化的消息服务,按实际使用量付费,自适应弹性,跨可用区容灾,帮助客户降低使用和维护成本,专注业务创新。
云消息队列 RabbitMQ 版是一款兼容 AMQP 0-9-1 协议,解决开源稳定性痛点的消息队列产品,同时具备按量后付费的售卖模式开箱即用、无需评估容量等优势.云消息队列 RabbitMQ 版.移动互联网、物联网、互动直播原生支持,万物互联,端与云双向通信,支撑千万级设备同时在线.云消息队列 MQTT 版.消息服务是一款易集成、高并发、...
来自:
云产品
云消息队列 RabbitMQ 版
云消息队列 RabbitMQ 版是阿里云打造的云消息服务,广泛用于海量队列分发、分布式定时任务等场景。支持 AMQP 协议,开箱即用,轻松实现快速上云,更专业、更可靠、更安全。
并且云消息队列 RabbitmQ 版的百万队列能力让您无需担心因为业务规模上升而引起Queue数量过多导致的稳定性问题.相较于开源 RabbitMQ,云消息队列 RabbitMQ 版能支持的队列的数量具有明显的数量级的优势,不再成为业务发展的瓶颈,不用担心队列过多引起的稳定性问题,保证核心链路的稳定运转.灵活适应业务的快速增长.云消息...
来自:
云产品
云消息队列 MQTT 版
云消息队列 MQTT 版是专为移动互联网(MI)、物联网(IoT)领域设计的消息产品,覆盖直播互动、金融支付、智能餐饮、即时聊天、移动 Apps、智能设备、车联网等多种应用场景;通过对 MQTT、WebSocket 等协议的全面支持,连接端云之间的双向通信,实现 C2C、C2B、B2C 等业务场景之间的消息通信,可支撑千万级设备与消息并发。
云消息队列 MQTT 版产品介绍.下载 Demo,快速体验微消息队列 MQTT.Demo 下载.云消息队列 MQTT 入门与开发指南.常见问题答疑.兼容任何支持 MQTT 3.1.1 协议的 SDK,支持 Websocket 协议,覆盖绝大多数移动端开发平台及语言(JAVA、.NET、C++、PHP、iOS、Android、JavaScript、nodeJS、Go 等).可支撑千万级设备在线连接,...
来自:
云产品
云消息队列 Kafka 版
云消息队列 Kafka 版是阿里云基于Apache Kafka构建的大数据消息中间件,广泛用于日志收集和分析、数据处理等场景。可提供全托管服务,用户无需部署运维,更专业、更可靠、更安全。
云消息队列 Kafka 版是阿里云基于 Apache Kafka 构建的高吞吐量、高可扩展性的分布式消息队列服务,广泛用于日志收集、监控数据聚合、流式数据处理、在线和离线分析等场景,是大数据生态中不可或缺的产品之一,阿里云提供全托管服务,用户无需部署运维,更专业、更可靠、更安全.查看产品文档.购买云消息队列 Confluent 版....
来自:
云产品
云消息队列 RocketMQ 版
云消息队列 RocketMQ 版是基于 Apache RocketMQ 构建的分布式消息中间件,广泛用于异步解耦、削峰填谷等场景。可支撑千万级并发、万亿级数据洪峰,更稳定,更安全。
云消息队列 RocketMQ 版 Serverless 系列资源包重磅上线!存储空间无法自由弹性伸缩,空间不足会导致清理数据;多副本存储成本高.基于集群水位规划机器:·需要预留水位,且缩容复杂;受扩容速度限制,无法支持突发流量弹性.手工命令行操作运维,成本高,风险大;缺少配套可观测监控体系.自行运维保障,需要资深技术人员...
来自:
云产品
- 产品推荐
- 这些文档可能帮助您