对象存储 OSS
阿里云对象存储 OSS(Object Storage Service)是一款海量、安全、低成本、高可靠的云备份服务,提供最高可达 99.995 % 的服务可用性。多种存储类型供选择,全面优化存储成本。
立即购买免费试用快捷入口控制台文档APISDK产品定价常用工具05:03快速了解对象存储 OSS产品动态内容甄选新功能OSS 设置 TLS 版本功能发布2023.09.19新功能OSS 归档直读发布2023.06.30新功能OSS Bucket 存储冗余类型转换发布2023.06.28精选特惠"存"享优惠,新老用户同享2023.11.01最新活动Stable Diffusion 模型库,AIGC ...
来自:
云产品
限制企业仅使用已批准的云服务
客户使用资源目录集中管理云上账号,通过管控策略创建“只能使用批准的云服务”对应的Policy,实现企业在云上只能使用批准的云服务,从而规范用户使用云产品的行为。
产品解决方案文档与社区权益中心定价云市场合作伙伴支持与服务了解阿里云备案控制台限制企业仅使用已批准的云服务方案介绍方案优势应用场景方案部署方案权益限制企业仅使用已批准的云服务客户使用资源目录集中管理云上账号,通过管控策略创建“只能使用批准的云服务”...,则此策略对Root资源夹下的所有子资源夹及成员生效...
来自:
解决方案
数据集成 Data Integration
阿里云数据集成 Data Integration是跨异构数据、低成本、弹性扩展的数据采集同步平台,为DataX的商业版,支持ETL,支持50+数据源跨网络离线(全量/增量)同步。
快速把MySQL数据库内所有表一并上传至MaxCompute,极大减少您初始化上云的配置、迁移成本.Oracle整库迁移.快速把Oracle数据库内所有表一并上传至MaxCompute,极大减少您初始化上云的配置、迁移成本.其他类型整库迁移.支持PostgreSQL、SQL Server、DRDS、PolarDB、AnalyticDB for PostgreSQL、HybridDB for MySQL、Analytic...
来自:
云产品
基于Elasticsearch的订单检索加速最佳实践
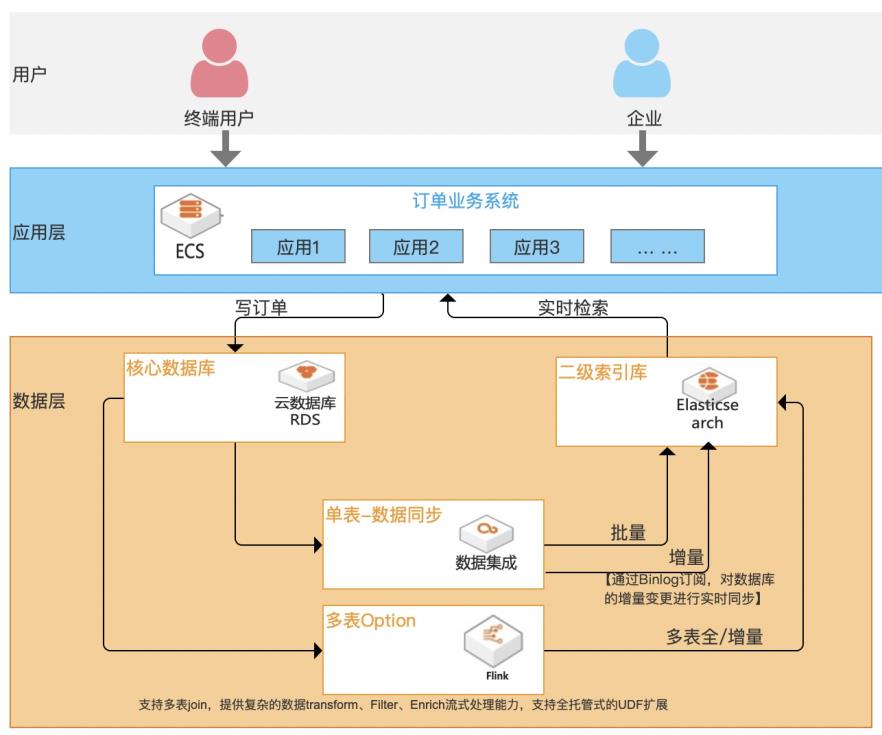
随着企业信息化程度越来越高,核心业务数据存储在传统关系型数据库中不可避免地会遇到一个问题:单表记录不断增多,数据检索速度会变慢,尤其是对中文的模糊查询(建立普通索引完全不起作用)。虽然数据库自身在不断完善,但效果有限且没办法灵活扩展,复杂场景无法应对。 本方案基于阿里云Elasticsearch作为二级索引库,数据集成产品提供Binlog实时订阅,实时解析、增量数据实时更新及二级索引库之间进行数据实时同步,为数据库提供“能力增益”, 不仅能从根本解决主库抗压问题,提升稳定性;同时支持高效率、高性能、高弹性、低成本、多复杂场景的检索加速服务。
步骤11 回到 rds的 dms界面中,对表 trading_order插入数据,再到 Elasticsearch中查看数 据。(dms登录方式本可查看文档章节 2.4创建 rds订单表”。在上图 dms中使用 insert into语句插入一条数据到 trading_order表中:insert into trading_order(order_amount,source_type,consignee_ada,order_type,company,consignee_...
云原生应用迁云解决方案
云原生应用迁云解决方案可将数百个服务以云原生的方式平滑迁移上云,相比普通的整体迁云方案,本方案平滑迁移复杂但是对业务影响小。阿里云容器服务以可靠稳定的IaaS平台为底座,将用户未容器化应用、容器化应用、K8s应用平滑地迁移到容器服务ACK上,保证用户业务可靠性、稳定性、安全性和灵活性。
待所有的应用迁移完成后,可以将线下数据库通过DTS同步到线上数据库.借助阿里云EDAS(企业级分布式应用服务)为企业级应用提供一站式的应用托管服务,支持阿里自研的HSF(高性能服务框架)、Dubbo以及SpringCloud等分布式应用框架。可实现0代码侵入即可完成Dubbo、SpringCloud应用上云,有效降低运维成本,支持多种高级特性...
来自:
解决方案
阿里云最佳实践离线大数据workshop

本最佳实践,首先搭建一个简化的电商 demo 系统,然后为此 demo 系统构建一套离 线大数据分析系统。 实践目标 1. 学习搭建一个离线大数据分析系统,学习从数据采集到数据存储和业务分析的业 务流程。 2. 整个离线大数据分析系统全部基于阿里云产品进行搭建,学习掌运用各个服务组 件及各个组件之间如何联动。 背景知识要求 熟练掌握 SQL 语法 对大数据体系系统知识有一定的了解
MaxCompute向用户提供了完善的数据导入方 案以及多种经典的分布式计算模型,能够更快速的解决用户海量数据计算问题,有 效 降 低 企 业 成 本,并 保 障 数 据 安 全。详 见:https://help.aliyun.com/product/27797.html Dataworks:DataWorks基于MaxCompute/EMR/MC-Hologres等大数据计算引 文档版本:20210802(发布...
来自:
最佳实践
相关产品:云服务器ECS,云数据库RDS MySQL 版,对象存储 OSS,日志服务(SLS),大数据计算服务 MaxCompute,DataV数据可视化,数据总线,Quick BI,云速搭
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
将订正后的转储文件导入到 RDS for MySQL实例中中,我们在 Databricks数 据洞察集群的 Hive元数据库中导入了客户 Hive元数据库的转储文件,创建了一系列 的数据表并插入了数据。在本实践方案中,Hive版本从客户 IDC的 1.2.2变更为阿里云 Databrickes数据洞察 集群的 2.3.5,但是 Databricks 数据洞察集群 Hive 元数据库中的...
EMR集群安全认证和授权管理
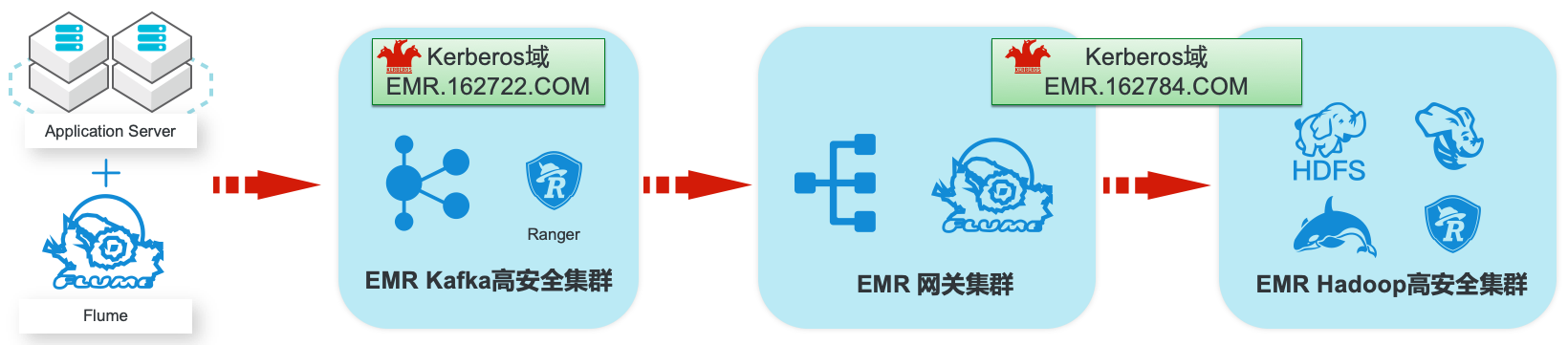
场景描述 阿里云EMR服务Kafka和Hadoop安全集群使 用Kerberos进行用户安全认证,通过Apache Ranger服务进行访问授权管理。本最佳实践中以 Apache Web服务器日志为例,演示基于Kafka 和Hadoop的生态组件构建日志大数据仓库,并 介绍在整个数据流程中,如何通过Kerberos和 Ranger进行认证和授权的相关配置。 解决问题 1.创建基于Kerberos的EMR Kafka和 Hadoop集群。 2.EMR服务的Kafka和Hadoop集群中 Kerberos相关配置和使用方法。 3.Ranger中添加Kafka、HDFS、Hive和 Hbase服务和访问策略。 4.Flume中和Kafka、HDFS相关的安全配 置。 产品列表:E-MapReduce、专有网络VPC、云服务器ECS、云数据库RDS版
详见:https://web.mit.edu/kerberos/krb5-1.4/krb5-1.4.1/doc/krb5- admin/domain_realm.html [capaths]为了执行直接(非分层)跨领域身份验证,需要一个数据库来构造领域 之间的 身份 验 证路径,本节用于定 义该 数 据库。详见:https://web.mit.edu/kerberos/krb5-1.4/krb5-1.4.1/doc/krb5-admin/capaths.html 文档版本...
Exchange Server云上部署最佳实践
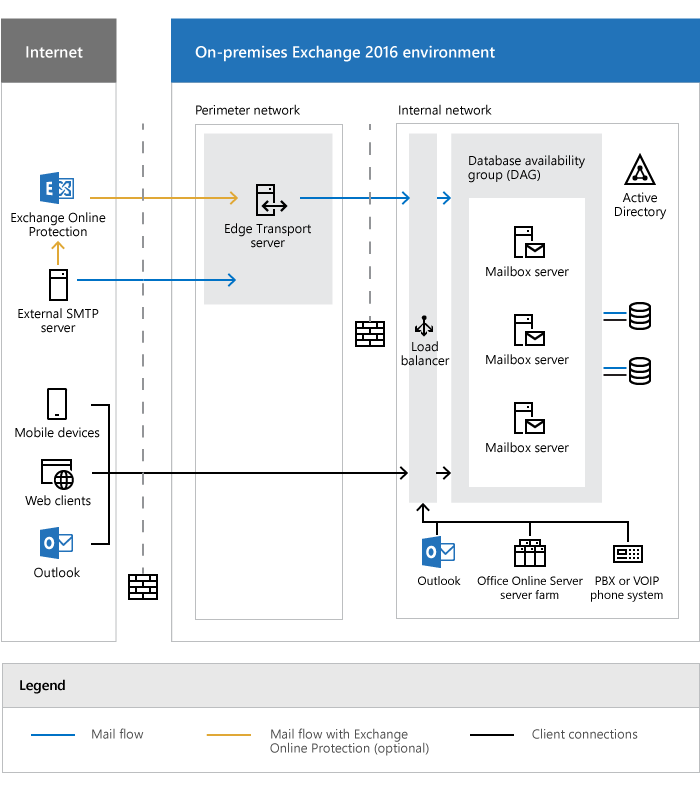
阿里云提供基础设施服务,能够以高可用、高容错且经济实惠的方式将Exchange Server部署在云上。通过在 阿里云上部署,可以获得Exchange Server的功能以及阿里云天然灵活性和安全性。
步骤2 选择新建>官方模版库新建 进入接官方模板库。步骤3 通过搜索找到“Exchange_on_Aliyun”模版,选择基于应用新建。步骤4 在架构编辑界面,根据架构部署提示,双击 ECS实例,设置其登录密码。文档版本:20220119 6 Exchange Server云上部署最佳实践 资源环境部署 步骤5 点击保存,设定应用名称后点击确认。步骤6 应用...
开源Flink迁移实时计算Flink全托管版最佳实践
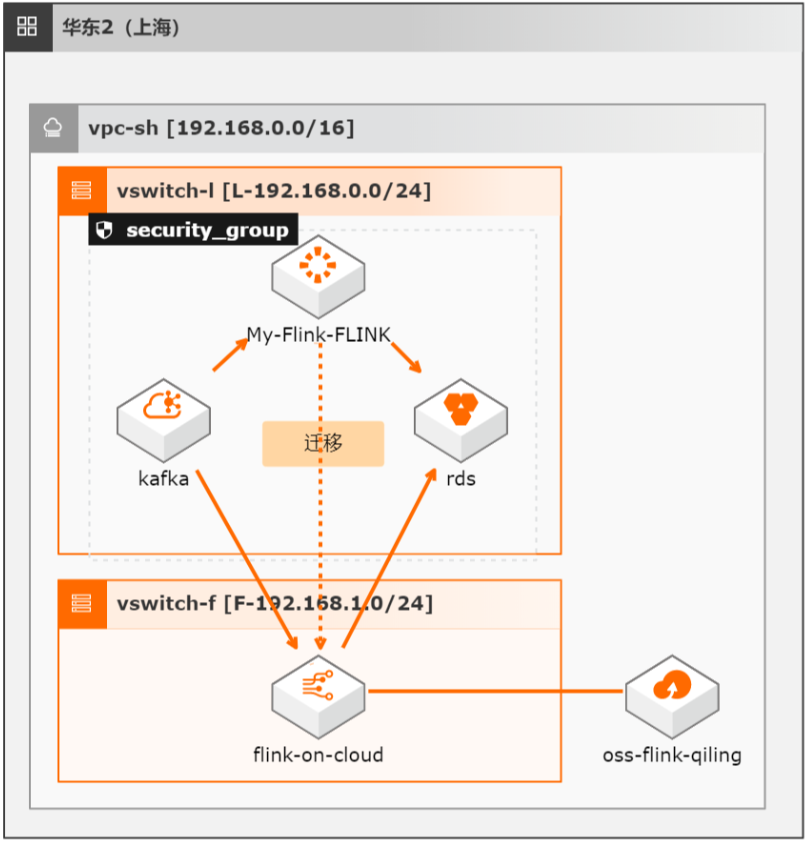
本方案介绍如何将自建开源Flink集群的流式任务(包含Datastream、Table/SQL、PyFlink任务)迁移至阿里云实时计算全托管版。
比如聚合任务按小时、天维度计算的聚合值,清洗任务加工的按天分区表等,在数据对比时就可以根据对应的时间周期来进对比,比如小时周期的任务实际已完整处理多个小时数据 后,就可以对比处理过的小时数 据,而天维度的聚合值,一般就需要等待新任务处理完完整的一天数 据后才能对比。2、数据规模 中小数据规模:建议进行全量...
CDH迁移升级CDP最佳实践
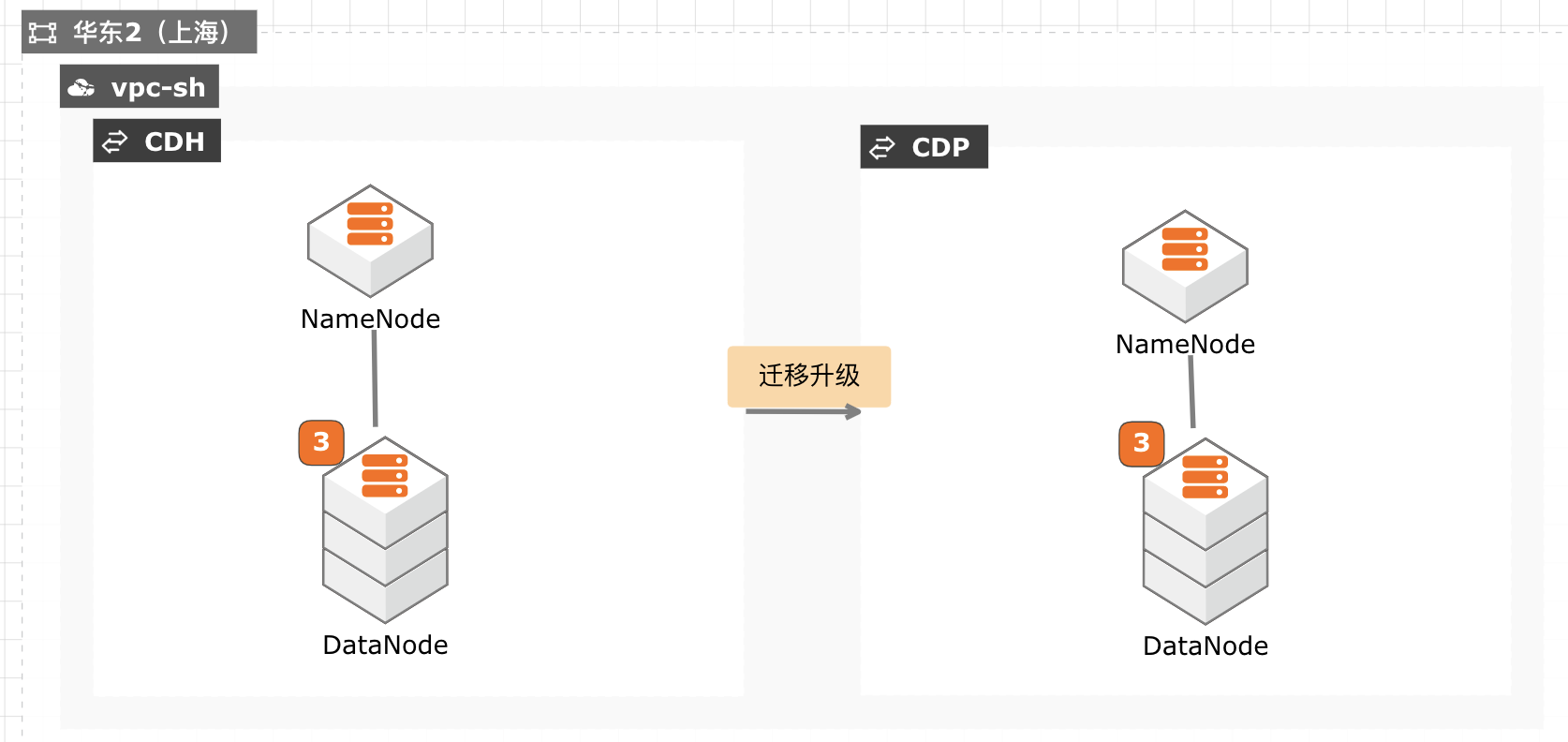
当前 CDH 免费版停止下载,终止服务,针对需要企业版服务能力并且CDH 升级过程对业务影响较小的客户,通过安装新的 CDP 集群,将现有数据拷贝至新集群,然后将新集群切换为生产集群,升级过程没有数据丢失风险,停机时间较短,适合大部分互联网客户升级使用。
除了 Navigator能够集成的那些数据源之外,Atlas还支持 NiFi和 Kafka元数 据。业务术语表:Atlas提供了一个 Web界面,用于创建和管理业务术语表,这些术 语可以帮助组织通过标准化来识别和使用数据。Data Profiling:“Data Catalog”提供自动数据标记功能,用于列出常见的数据类 型,也允许用户通过正则表达式标记其他数据...
云速搭CADT部署VMware服务
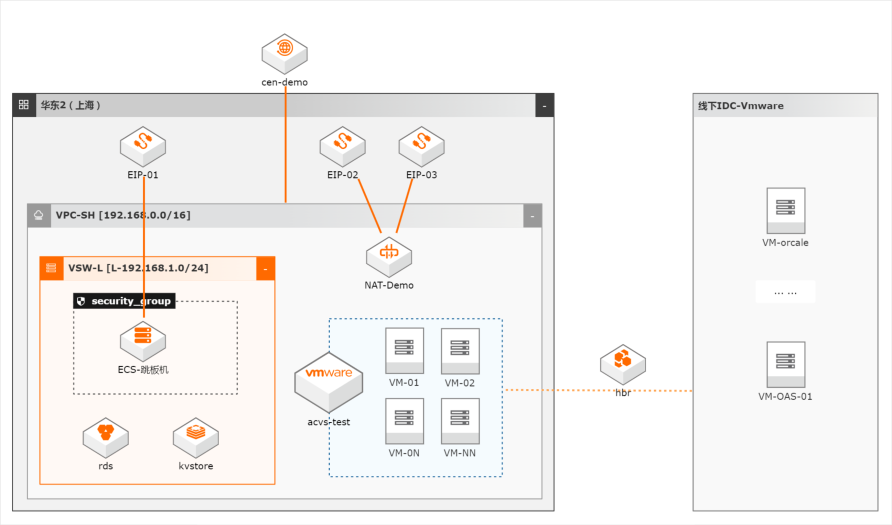
本方案适用客户云下使用VMware环境,在云上希望继续使用VMware环境,包括业务维护和扩容等,不希望改变云上使用环境。
文档版本:20220520 6 云速搭CADT部署VMware服务 业务规划 用于构建专有网络 VPC与专属 VMware 环境之间以及本地数 据中心间搭建私网通信通道,实 现全网资源的互通。同地域无需付费,跨地域需预付 费购买带宽包。名称:NAT-Demo 本次示例通过 CADT新建,支 支付方式:按量付费 持架构图导入公网 NAT网关。NAT网关 网关类型...
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测实践 业务架构 场景描述 数据湖和数据仓库是当前大数据技术条件下构建分布式系 统的两种数据架构设计取向,数据湖偏向灵活性,数据仓 库侧重成本、性能、安全、治理等企业级特性。但是数据 湖和数据仓库的边界正在慢慢模糊,数据湖自身的治理能 力、数据仓库延伸到外部...
弹性计算OOS审批流程自动化运维
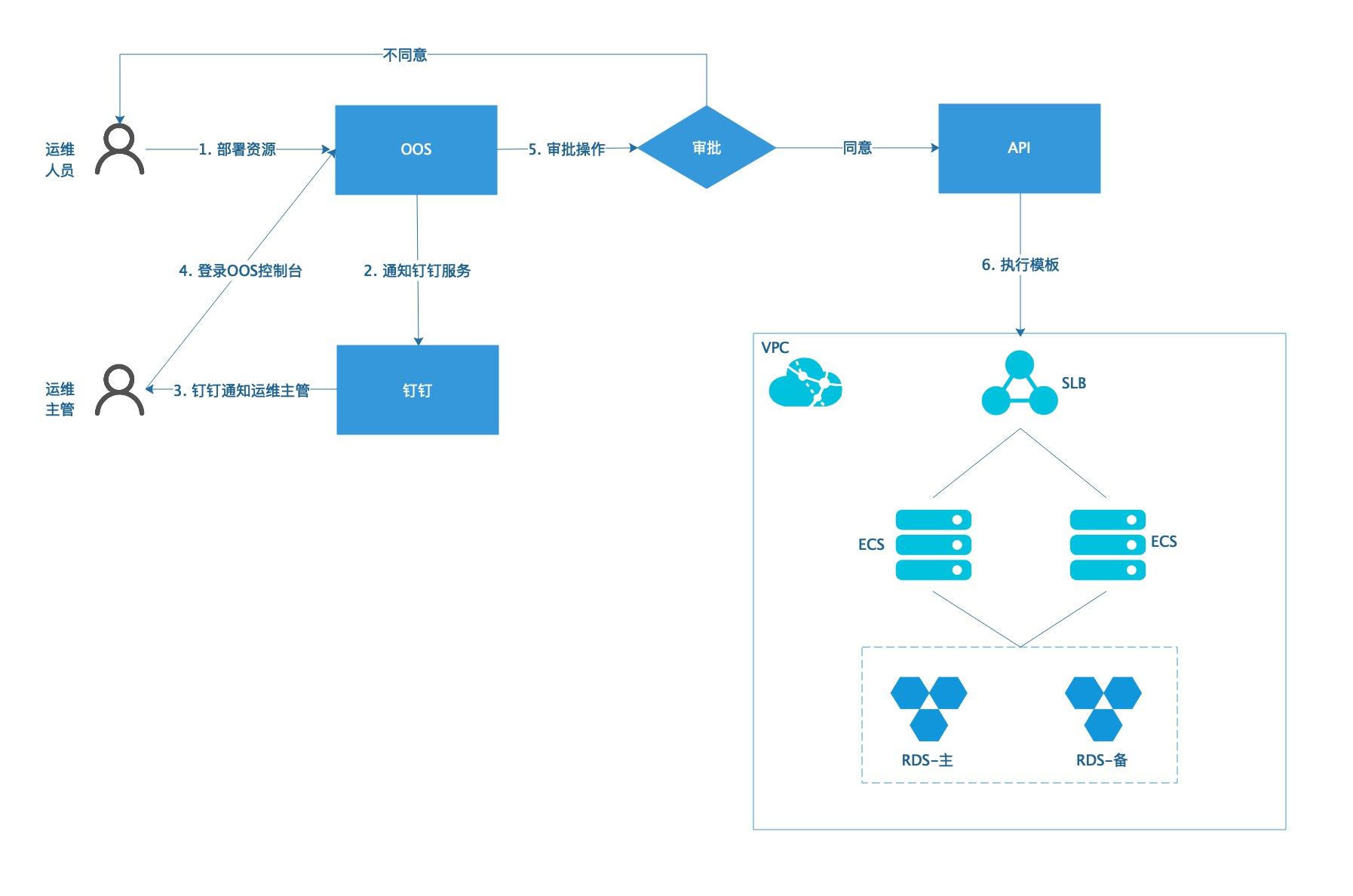
场景描述 本文以ECS、RDS、SLB搭建一个小型的WEB系 统为例,介绍如何利用OOS在运维常见的部署系统、 扩容系统、回收系统三个场景中添加审批流程,并以 钉钉通知到对应的审批人员。 解决问题 1.对接阿里云API,通过OOS模板执行运维 任务,实现了运维自动化与可视化。 2.运维操作集成了RAM访问控制权限管理, 无需担心操作安全,并可以快速增加审批流 程,提高运维安全与效率。 产品列表 1.运维编排OOS 2.访问控制RAM 3.云服务器ECS 4.RDSMySQL版 5.负载均衡SLB
用户组规划 用户组 权限 有无审批权限 oos-admin OOS所有权限 有 oos-dev OOS模板编辑、模板执行权限 无 注意:用户在实际环境中可以将模板编辑与执行分为两个用户组分别授权给不同 的用户使用,以实现更加精细的权限管理。这里为了演示便捷,将两个用户组合 为一个。 用户规划 用户 用户组 test-001 oos-admin test-...
地址标准化
地址标准化(Address Purification)是依托阿里云海量的地址语料库,及超强的NLP算法实力所沉淀出的高性能、高准确率、功能覆盖最全的标准地址算法服务。可为企业、政府机关及开发者提供地址数据清洗。地址标准化通过地址解析、补全、匹配等赋能业务的上层应用。
地址标准化(Address Purification)是一站式闭环地址数据处理和服务平台产品,依托阿里云海量的地址语料库,针对各行业业务系统所登记的地址数据,进行纠错、补全、归一、结构化、标签化等NLP处理清洗,实现地址库的标准化,并向上提供地址智能填写、地址搜索/联想、地址正/逆编码、地址围栏等地址服务.更多产品与服务....
来自:
云产品
- 产品推荐
- 这些文档可能帮助您