SLS数据入湖Kafka最佳实践
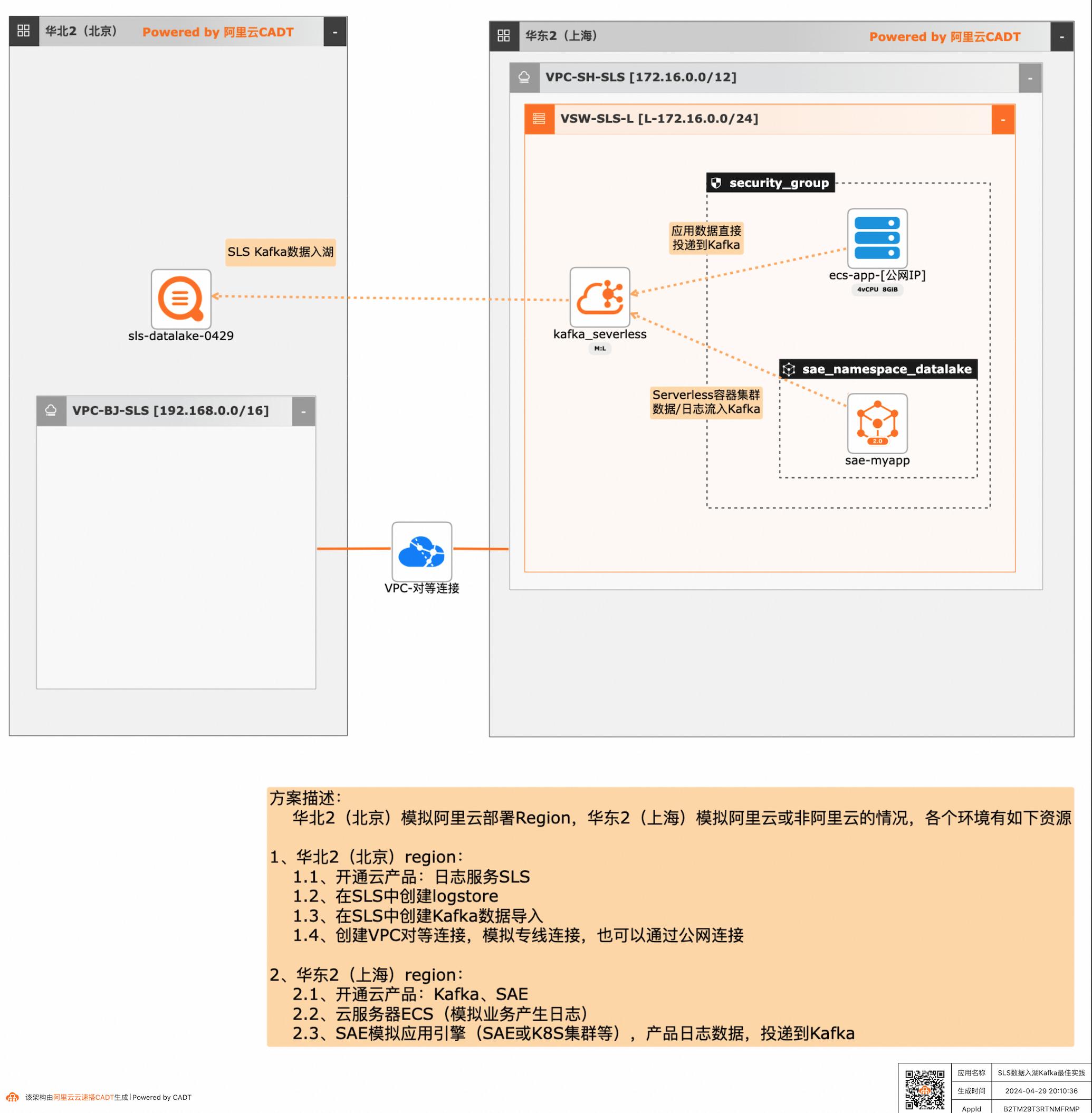
应用和数据分散在多云或混合云,在面对多云/混合云这样大的趋势下,数据无法进行统一的聚合、分析处理和导出等,本方案给出了在多云/混合云场景下,构建通过标准的Kafka协议和托管服务,SLS可以连接Kafka数据入湖导入,然后进行统一的海量数据的集中存储、智能转储、聚合分析查询等。
添加北京region的SLS白名单的方法:文档版本:20240428 16SLS数据入湖Kafka最佳实践 场景验证 点击【添加白名单分组】,填写【分组名称】,添加【组内白名单】,多个白名单用英文逗号隔开:59.110.6.146,39.105.19.110,47.93.61.189,182.92.187.76。SLS白名单的查 询,详见:...
容器场景下的应用性能监控、调用链拓扑、内存剖析
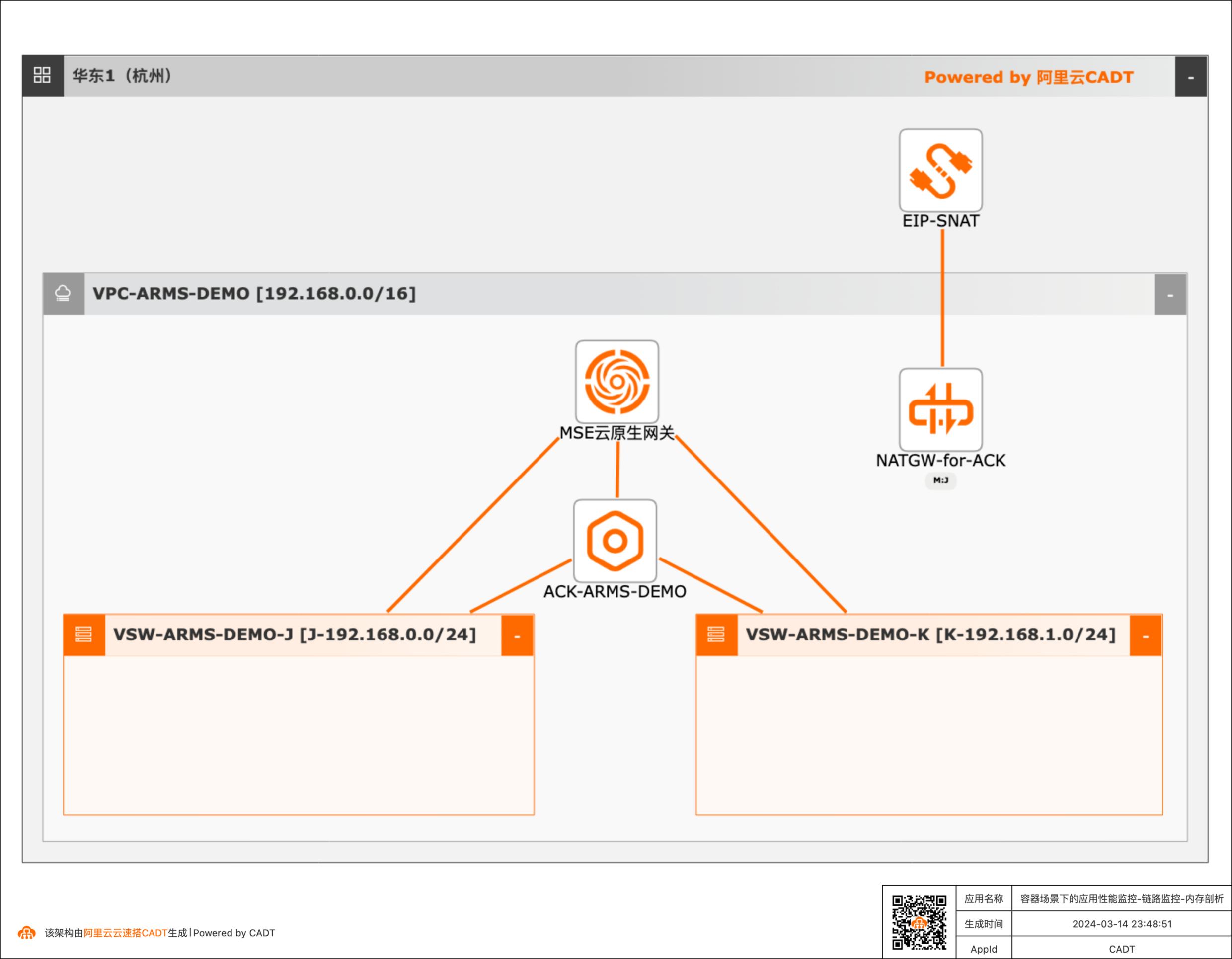
场景描述 随着云原生及微服务技术的普及,越来越多的系统已经通过云原生和微服务技术实现企业的降本增效,同时因微服务及云原生的复杂性给系统运维带来非常大的挑战,云原生应用监控arms通过全链路应用监控,从端到端及代码级别的链路下钻能力、CPU、内存持续剖析及诊断能力,帮助客户降低系统故障定位难度,此demo,您将体验arms的链路监控、内存剖析等能力 应用场景 微服务+容器场景下链路调用拓扑,调用链可以显示出服务之间的调用顺序和层次关系,帮助开发人员理解和追踪代码的执行流程 在分布式系统中,一个请求往往需要通过多个服务来完成。当出现问题时,如请求超时、错误或异常,很难快速定位问题所在。 解决问题 调用链可以帮助运维人员解决以下问题: · 故障排查:当请求失败或出现错误时,调用链可以显示整个请求的路径和每个服务的执行情况,从而帮助运维人员快速定位问题所在。 · 性能优化:通过调用链,运维人员可以了解请求在系统中的执行时间和瓶颈所在,从而进行优化。 · 系统监测:调用链可以提供实时的系统监测和分析,帮助运维人员了解系统的健康状况和资源利用情况。
该demo的内存申请速度为60M/min,CPU使用量大约为30s/min,选择一个5分钟 的可以查看聚合分析相关效果:文档版本:20240329 39容器场景下的应用性能监控、调用链拓扑、内存剖析 场景验证 通过持续剖析,我们可以看到在这个5分钟时间段内的快照分析,最后一段代码我们 可以看到CPUPressure.runBusiness方法,通过我们刚刚的...
SAE-ACK应用双跑最佳实践
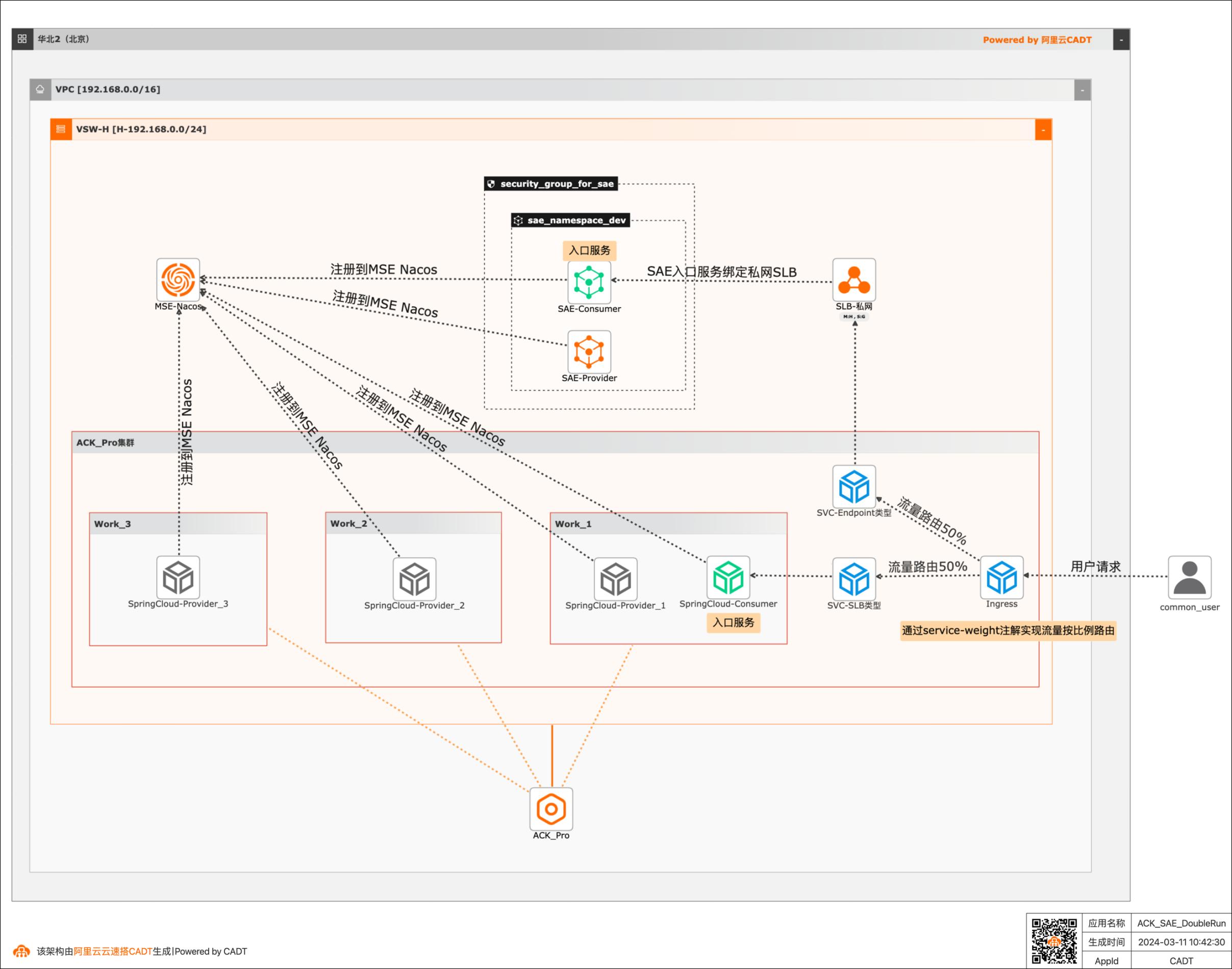
场景描述 实现ACK、SAE中部署的应用在东西向和南北向互通,实现SAE-ACK应用双跑。 应用场景 该最佳实践应用于两类场景: l 因为SAE支持更丰富自动扩缩指标(比如QPS,RT,TCP连接数等),所以将相对稳态的应用部署在ACK中,将相对弹性波动大的应用部署在SAE,借助SAE更强大的自动扩缩应对流量洪峰。 l 将K8s架构迁移到Serverless架构时,需要平滑过渡,所以该最佳实践中的双跑架构可以有效帮用户平滑的完成迁移。
实例类型:该方法使用私网SLB。 计费类型:按使用流量计费。 IP版本:ipv4。步骤6 双击SAE,查看配置信息。文档版本:20240311 5SAE-ACK应用双跑 场景验证 因为Serverless应用引擎SAE是一款Serverless技术机构的计算产品,所以没有IaaS的概念,没有资源规格的概念,在CADT中拖入的直接就是一个一个的应用(服务),...
基于函数计算FC实现阿里云Kafka消息内容控制MongoDB DML操作
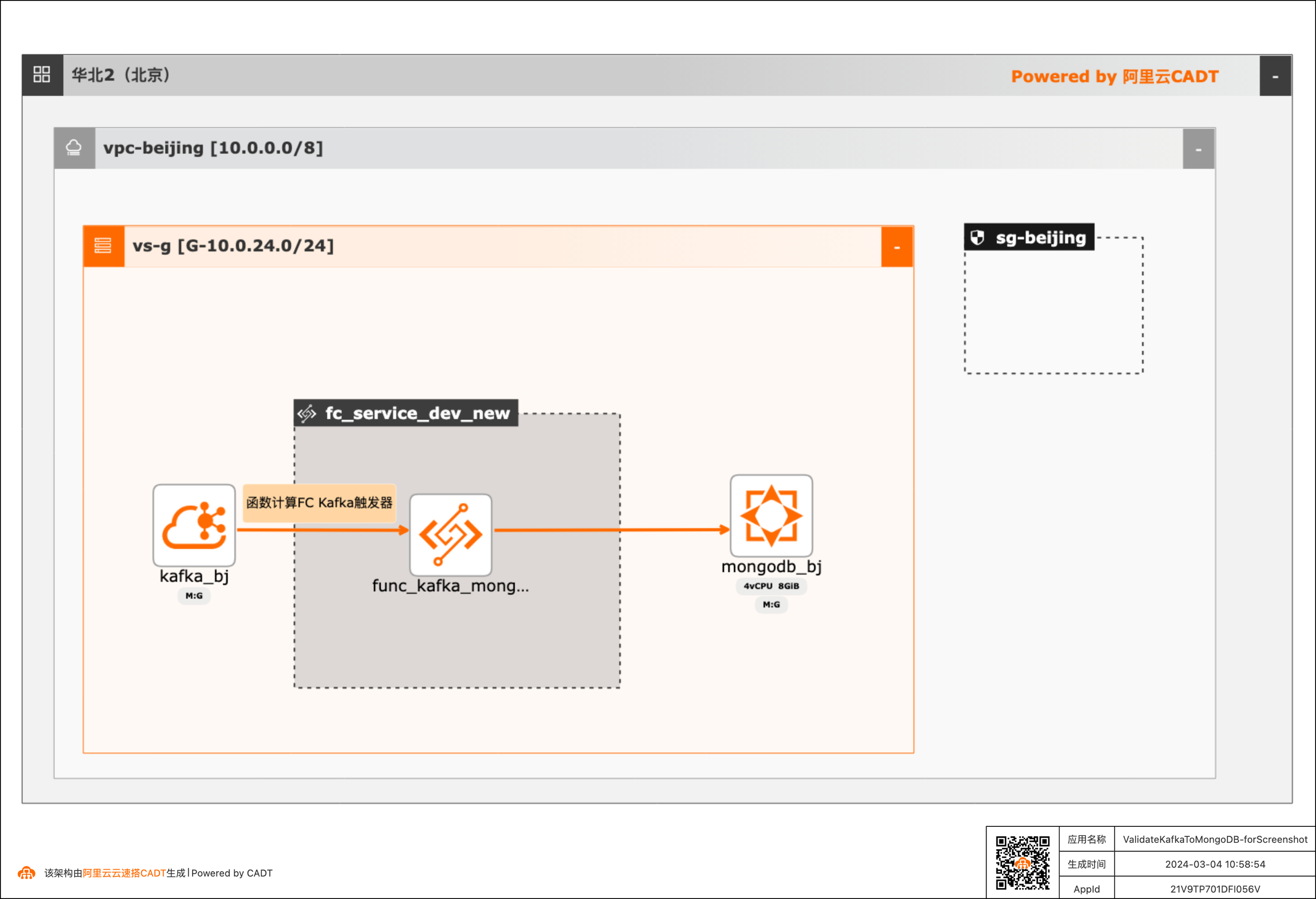
在大数据ETL场景,将Kafka中的消息流转到其他下游服务是很常见的场景,除了常规的消息流转外,很多场景还需要基于消息体内容做判断,然后决定下游服务做何种操作。 该方案实现了通过Kafka中消息Key的内容来判断应该对MongoDB做增、删、改的哪种DML操作。 当Kafka收到消息后,会自动触发函数计算中的函数,接收到消息,对消息内容做判断,然后再操作MongoDB。用户可以对提供的默认函数代码做修改,来满足更复杂的逻辑。 整体方案通过CADT可以一键拉起依赖的产品,并完成了大多数的配置,用户只需要到函数计算和MongoDB控制台做少量配置即可。
{"message_value":message_value}} mongodb_collection.update_one(update_condition,new_values)#如果要更新多条,可以使用 update_many 方法#mongodb_collection.update_many(update_condition,new_values)elif message_key='delete':delete_condition={"topic":topic} mongodb_collection.delete_one(delete_condition)#...
大模型RAG对话系统部署
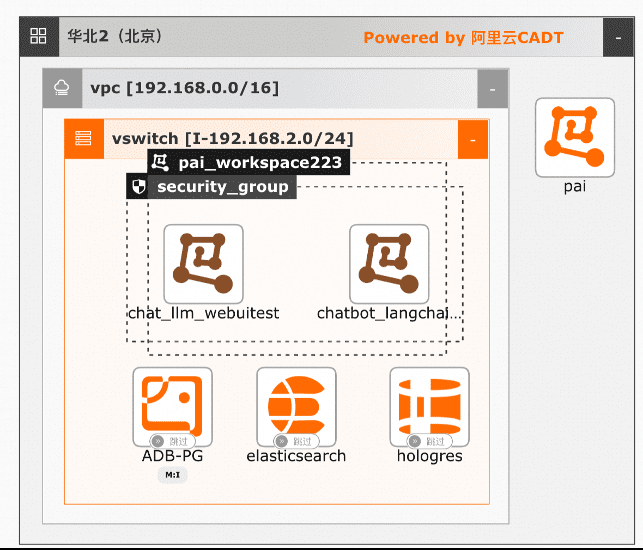
大模型RAG对话系统最佳实践,旨在指引AI开发人员如何有效地结合LLM大语言模型的推理能力和外部知识库检索增强技术,从而显著提升对话系统的性能,使其能更加灵活地返回用户查询的内容。适用于问答、摘要生成和其他依赖外部知识的自然语言处理任务。通过该实践,您可以掌握构建一个大模型RAG对话系统的完整开发链路。
但在某些语料稀缺的垂直 领域,或要求准确匹配的场景,向量数据库召回方法可能不如传统的稀疏检索召回方 法。稀疏检索召回方法通过计算用户查询与知识文档的关键词重叠度来进行检索,因 此更为简单和高效。PAI提供了 BM25等关键词检索召回算法来完成稀疏检索召回操 作,可以在页面中选择是否使用关键词检索召回。步骤10 ...
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测实践 业务架构 场景描述 数据湖和数据仓库是当前大数据技术条件下构建分布式系 统的两种数据架构设计取向,数据湖偏向灵活性,数据仓 库侧重成本、性能、安全、治理等企业级特性。但是数据 湖和数据仓库的边界正在慢慢模糊,数据湖自身的治理能 力、数据仓库延伸到外部...
向量检索服务
向量检索服务基于阿里云自研的向量引擎 Proxima 内核,提供具备水平拓展、全托管、云原生的高效向量检索服务。向量检索服务将强大的向量管理、查询等能力,通过简洁易用的 SDK/API 接口透出,方便在大模型知识库搭建、多模态AI搜索等多种应用场景上集成。
图像搜索以深度学习和机器视觉为核心,提取图片内容特征、建立图像搜索引擎。用户通过输入图片,用以图搜图的方式可快速在图片库中检索到与输入图片相似的图片集合。可广泛应用于拍照购物、商品推荐、版权保护等场景.创建 API-KEY.通过控制台管理 API-KEY.创建试用 Cluster.通过控制台创建 Clsuter.创建 Collection.在 ...
来自:
云产品
CDH迁移升级CDP最佳实践
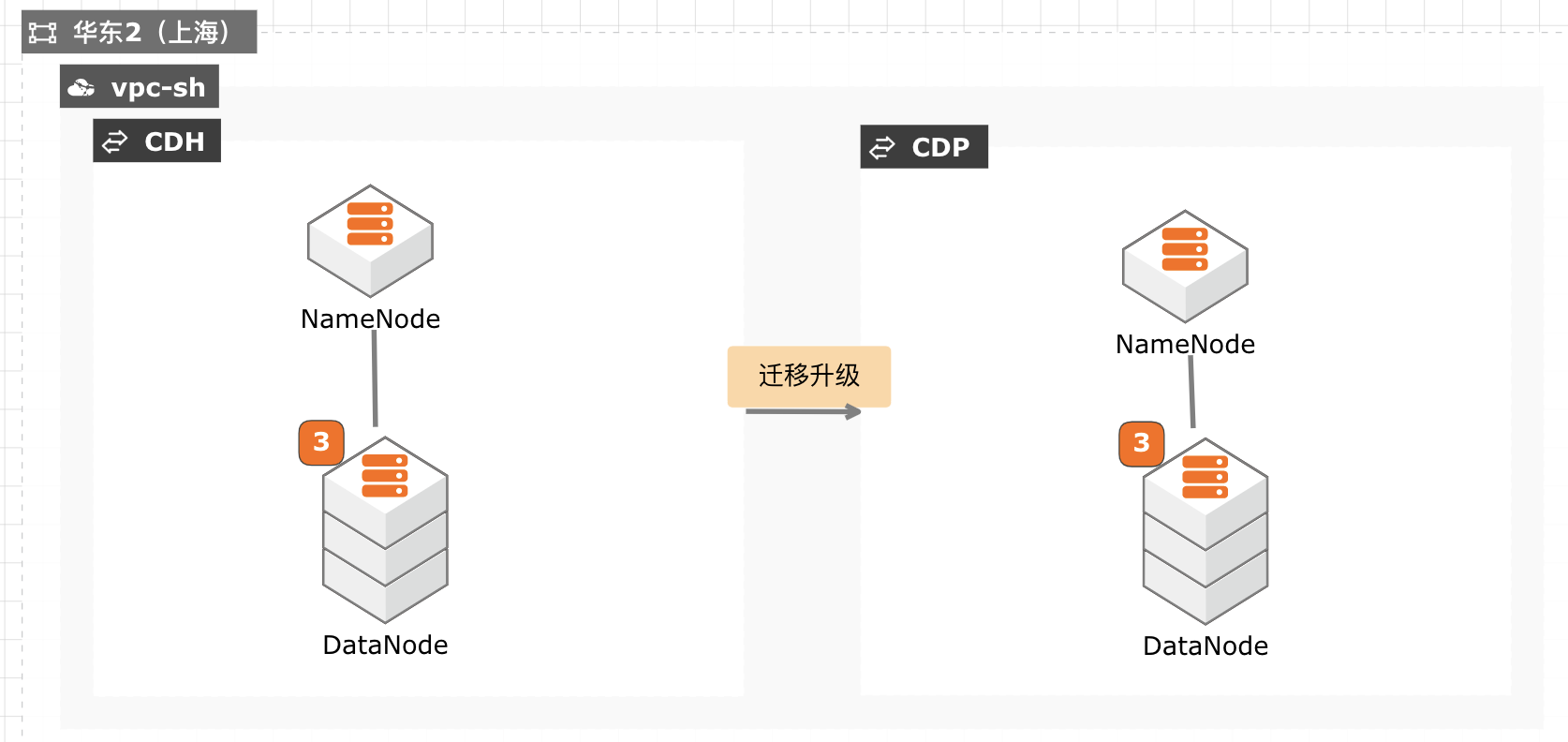
当前 CDH 免费版停止下载,终止服务,针对需要企业版服务能力并且CDH 升级过程对业务影响较小的客户,通过安装新的 CDP 集群,将现有数据拷贝至新集群,然后将新集群切换为生产集群,升级过程没有数据丢失风险,停机时间较短,适合大部分互联网客户升级使用。
如果“root.default”不是预期的默认 队列,则有两种可能的方法:使用setDefaultQueue 策略更 改“root.default”,然 后 应 用 defaultQueue。使用自定义策略并将策略字符串设 置为目标队列。3.3.4.调度程序迁移的限制 将 Fair Scheduler 配置转换为 Capacity Scheduler 配置有一些硬性限制,因为这两个 调度程序并不等效...
企业上云workshop
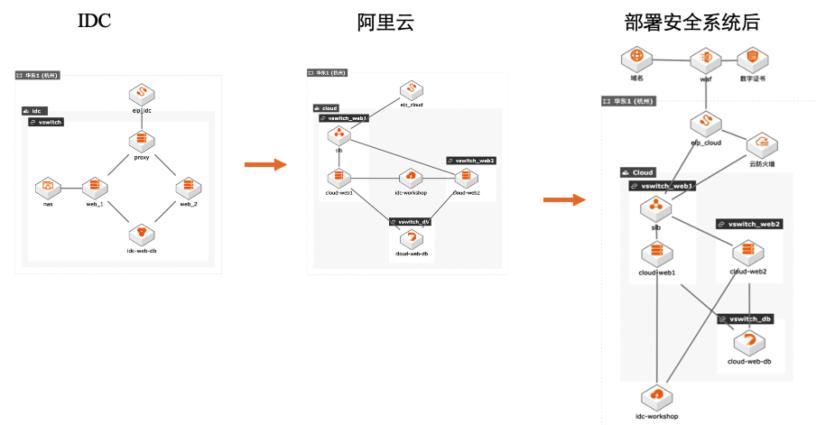
本文模拟了如下场景: 1. 线下 IDC 环境中部署了一个业务系统,业务是利用 wordpress 系统提供网站服务。 2. 本文详细介绍了如何将以上线下系统搬迁到云上, 包括如何在云上构建以上业务系统,如何迁移线下 系统到云上,如何割接。 3. 最后介绍了迁移上云后,如何部署安全系统。 解决问题 IDC 业务系统搬迁上云 云上构建业务系统 部署安全系统
本文以免费试用版本为例,介绍云防火墙的使用方法。文档版本:20200127 118 部署云防火墙 企业上云 workshop-IDC业务迁移上云 步骤4 首次使用云防火墙时,需要完成服务授权,授权云防火墙访问其他云产品资源。在云 资源访问授权页面,单击同意授权。成功开通服务。返回到云防火墙控制台概览页,您可以在页面右上角看到当前...
来自:
最佳实践
相关产品:专有网络 VPC,云服务器ECS,云数据库RDS MySQL 版,对象存储 OSS,负载均衡 SLB,弹性公网IP,文件存储NAS,云数据库PolarDB,Web应用防火墙,云防火墙,SSL证书,云速搭
利用交互式分析(Hologres)进行数据查询
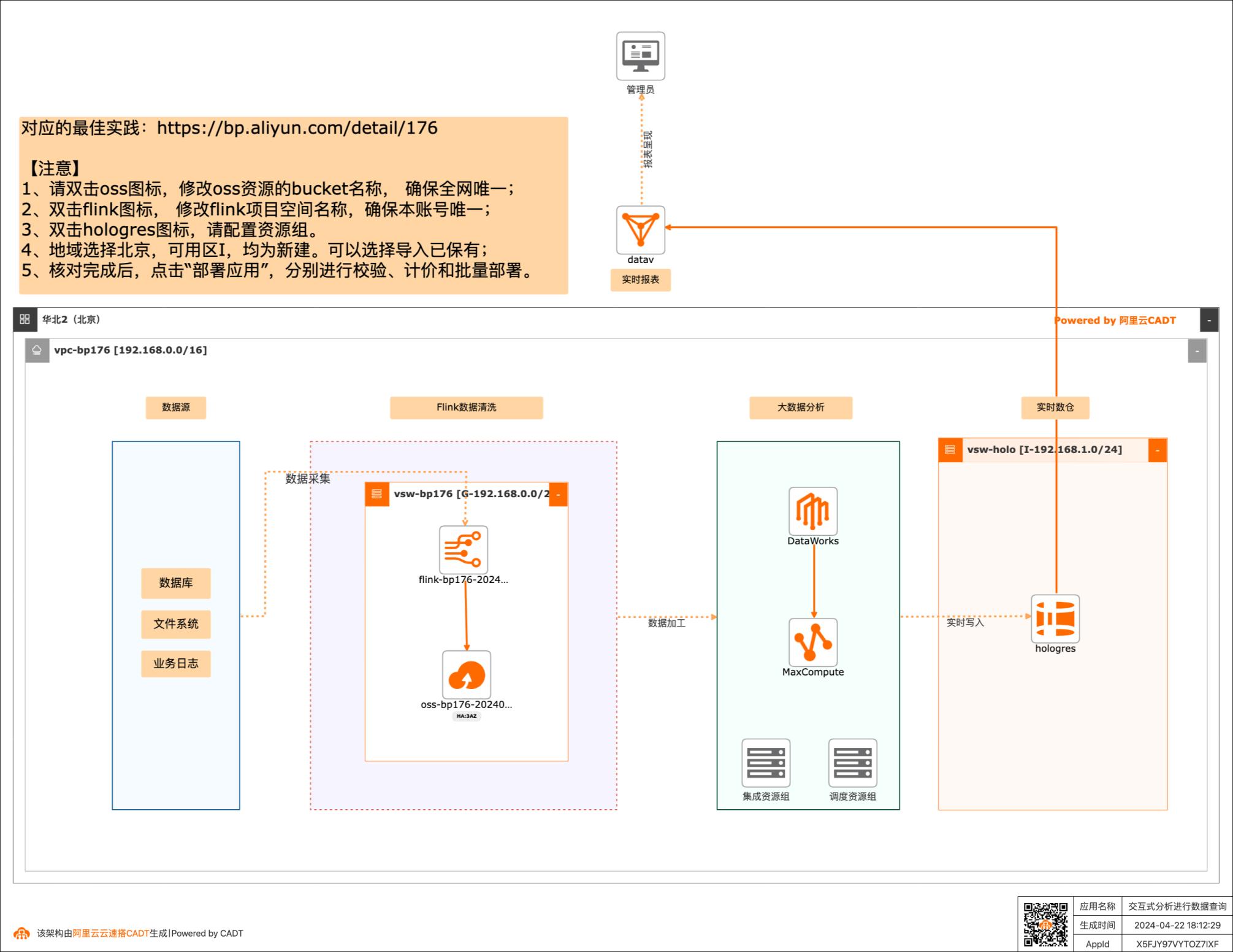
场景描述:随着收集数据的方式不断丰富,企业信息化 程度越来越高,企业掌握的数据量呈TB、 PB或EB级别增长。同时,数据中台的快 速推进,使数据应用主要为数据支撑、用户 画像、实时圈人及广告精准投放等核心业务 服务。高可靠和低延时地数据服务成为企业 数字化转型的关键。 Hologres致力于低成本和高性能地大规模 计算型存储和强大的查询能力,为您提供海 量数据的实时数据仓库解决方案和实时交 互式查询服务。 解决问题 1.加速查询MaxCompute数据 2.快速搭建实时数据仓库 3.无缝对接主流BI工具 产品列表 MaxCompute Hologres 实时计算Flink 专有网络VPC DataWorks DataV
同时,数 据中台的快速推进,使数据应用主要为数据支撑、用户画 像、实时圈人及广告精准投放等核心业务服务。高可靠和 低延时地数据服务成为企业数字化转型的关键。Hologres致力于低成本和高性能地大规模计算型存储和 强大的查询能力,为您提供海量数据的实时数据仓库解决 方案和实时交互式查询服务。解决问题 1.加速查询...
数据湖-在线学习场景数据分析

场景描述 本场景以在线教育中一个答题闯关类的应用为 例,使用WebServer来模拟演示这类日志数据 的分析处理。通过Nginx和Pythonflask搭建 WebServer,模拟应用中的关键页面,比如登 录、课程内容等,之后构造若干用户使用的模拟 日志数据,投递到数据湖进行分析后获取应用 PV、UV、课程内容访问排行、平均得分等等。 解决问题 基于数据湖(EMR+OSS)搭建大数据平台。 EMR和OSS使用和配置。 数据统一存储到OSS。 产品列表 E-MapReduce 对象存储OSS 云服务器ECS 访问控制RAM 专有网络VPC
附录-TPCDS 本章使用hive-testbench对jindofs和OSS分别进行性能测试,并进行对比,测试方 法参考《EMR本地盘实例大规模数据集测试最佳实践》:https://www.aliyun.com/acts/best-practice/preview?&id=52141 本次测试集群配置:节点 配置 数量 Master 16C/64G/80GBESSD 1 Core 16C/64G/80GBESSD*4 6 存储 OSS标准型 NA 4.1....
微服务引擎的线上流量治理
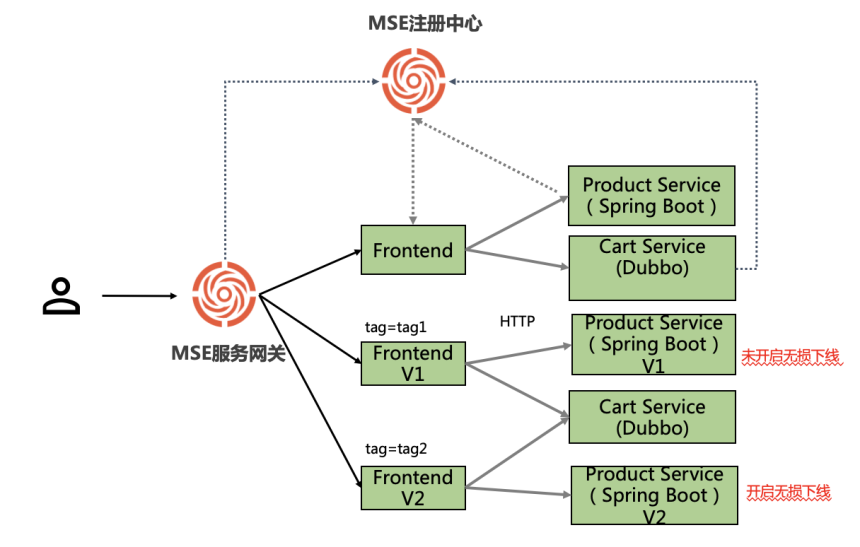
随着业务不断创新,微服务架构及数字化转型不断落地,在这个过程中,大量企业采用了开源的组件构建了微服务,比如有开源微服务全家桶之称的Spring Cloud体系或Apache Dubbo等,微服务的好处之一,在于快速迭代,如何在迭代过程中保障线上流量不受损? 开源产品无运维工具,常常需要投入较大的运维人力和成本。 本实践将重点介绍如何快速集成主流开源微服务框架,实现业务零改造,解决开源框架在生产落地过程中的痛点,例如无损上下线、标签路由等,并通过托管微服务开源组件(API网关、注册中心、配置中心等)的服务,提供白屏化监控告警、容灾、宕机重启、扩缩容等能力,帮助企业释放业务无关的运维成本,聚焦业务本身的运维和发展。 方案优势 快速集成:通过JavaAgent技术实现Sping Cloud和Dubbo框架可以实现业务零改造接入。 免运维:托管微服务依赖开源中间件的服务,提供白屏化监控告警、容灾、宕机重启、扩缩容等能力,帮助我们客户释放业务无关的运维成本,聚焦自身业务本身的运维和发展。 开源增强:提供开源框架在生产落地过程中的痛点,例如应用无损上下线/金丝雀发布/南北+东西流量打通等,帮助客户的业务提高自身SLA和降低自研成本。
微服务引擎的线上流量治理 最佳实践 业务架构 背景描述 随着业务不断创新,微服务架构及数字化转型不 断落地,在这个过程中,大量企业采用了开源的 组件构建了微服务,比如有开源微服务全家桶之 称的 Spring Cloud体系或 Apache Dubbo等,微服务的好处之一,在于快速迭代,如何在迭代 过程中保障线上流量不受损?...
云Clickhouse冷热数据分层存储
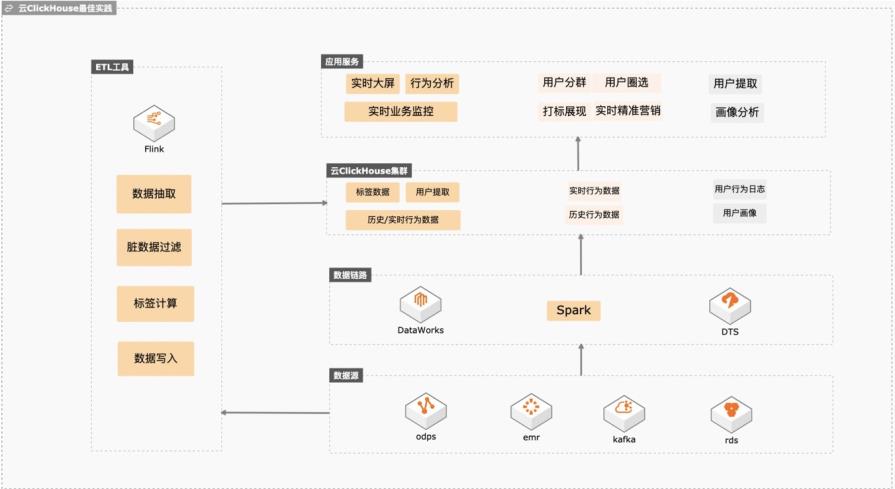
基于云ClickHouse可以给电商、游戏、互联网以及其他行业提供高性能、高稳定性、低维护成本、高性价比的实时数据分析、精准营销、业务运营、业务分析、业务预警、业务营销、数仓加速等场景化方案,本实践会向客户提供数据库低维护成本、数据库链路构建、冷热分层存储、快熟分析等操作实践。 解决问题 1. 维护成本低不用建设维护体系,稳定性高,数据倾斜自动均衡。 2. 完善的数据同步链路,可以平滑将业务库、大数据、日志服务的数据同步到Clickhouse,降低研发成本。 3. 平滑升级版本,业务中断小。 冷热分层后透明读取,帮客户节约整体数据存储成本。
云 ClickHouse冷热数据分层存储最佳实践 技术架构 场景描述 基于云 ClickHouse可以给电商、游戏、互联网以及其他行业提供高性能、高稳定 性、低维护成本、高性价比的实时数据分 析、精准营销、业务运营、业务分析、业 务预警、业务营销、数仓加速等场景化方 案,本实践会向客户提供数据库低维护成 本、数据库链路构建、冷热...
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
深度融合 Databricks数据洞察与阿里云其它产品(例如,OSS、MongoDB、Elasticseach、RDS和 MaxCompute等)进行了深度整合,支持以这些产品作为 Spark计算引 擎的输入源或者输出目的地。文档版本:20210425 VI 自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 前置条件 前置条件 为了顺利完成本实践,您需要提前...
开源Flink迁移实时计算Flink全托管版最佳实践
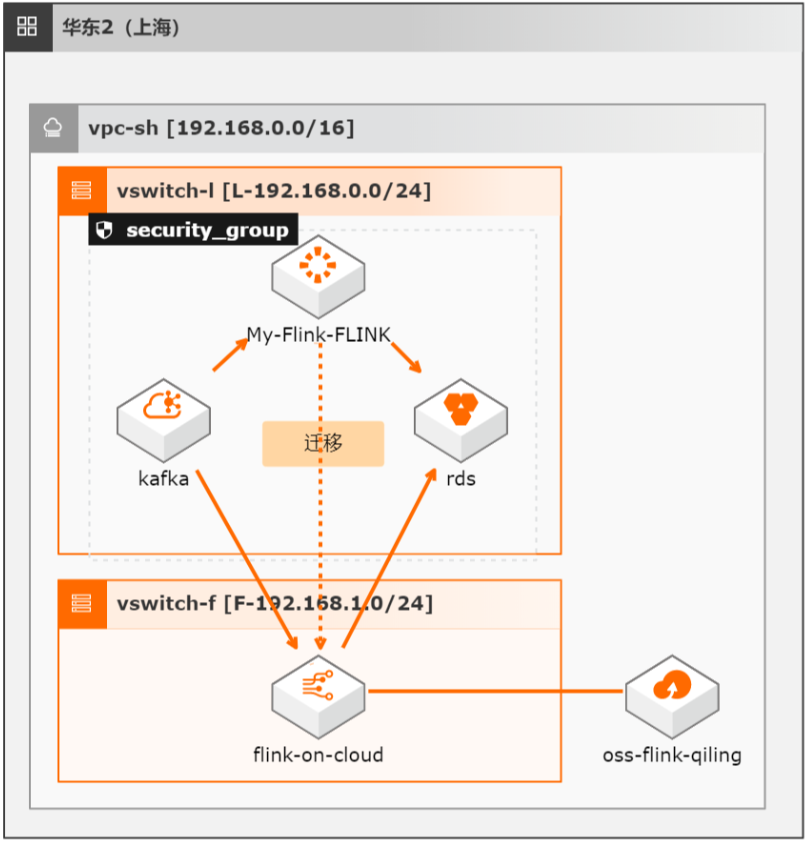
本方案介绍如何将自建开源Flink集群的流式任务(包含Datastream、Table/SQL、PyFlink任务)迁移至阿里云实时计算全托管版。
业务迁移 业务迁移是整个过程的最后一步,按照建议的步骤,在验证完成数据正确性和业务 稳定性后,进行最终的迁移工作,将新任务使用的备用结果表替换原有任务的结果 表提供给业务方使用,并将原有生产链路停止下线,整个迁移工作就圆满结束了。3.4.迁移 FAQ 1.跨版本迁移时需要注意什么?ᅳ 建议参考迁移目标版本的 ...
大数据系统基准性能测试最佳实践
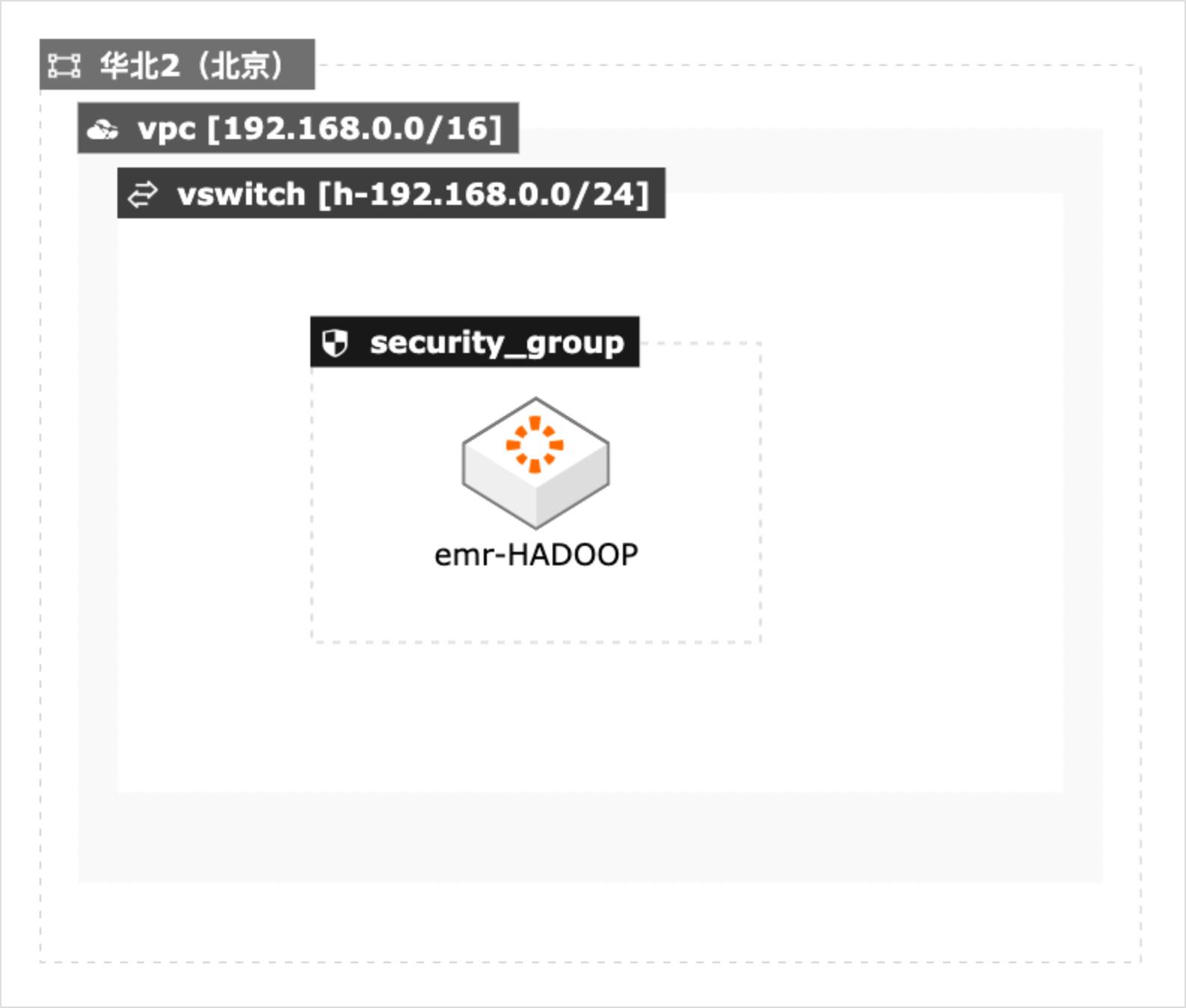
本方案适用于在阿里云上进行大数据基准性能测试的场景,包括 Teragen和Terasort测试,TestDFSIO测试。本文采用CADT工具结合阿里云的E-MapReduce服务快速构建测试集群,并提供了Teragen和Terasort测试,TestDFSIO测试的测试脚本,便于迅速开展测试。
EMR的 SmartData组件是 EMR Jindo引 擎的主要存储部分,为 EMR各个计算引擎提供统一的存储优化、缓存优化、计算 缓存加速优化和多个存储功能扩展。详见 https://help.aliyun.com/document_detail/28068.html 云架构设计工具 CADT:是一款为上云应用提供自助式云架构管理的产品,显著 地降低应用云上管理的难度和时间成本。...
多账号下企业分账
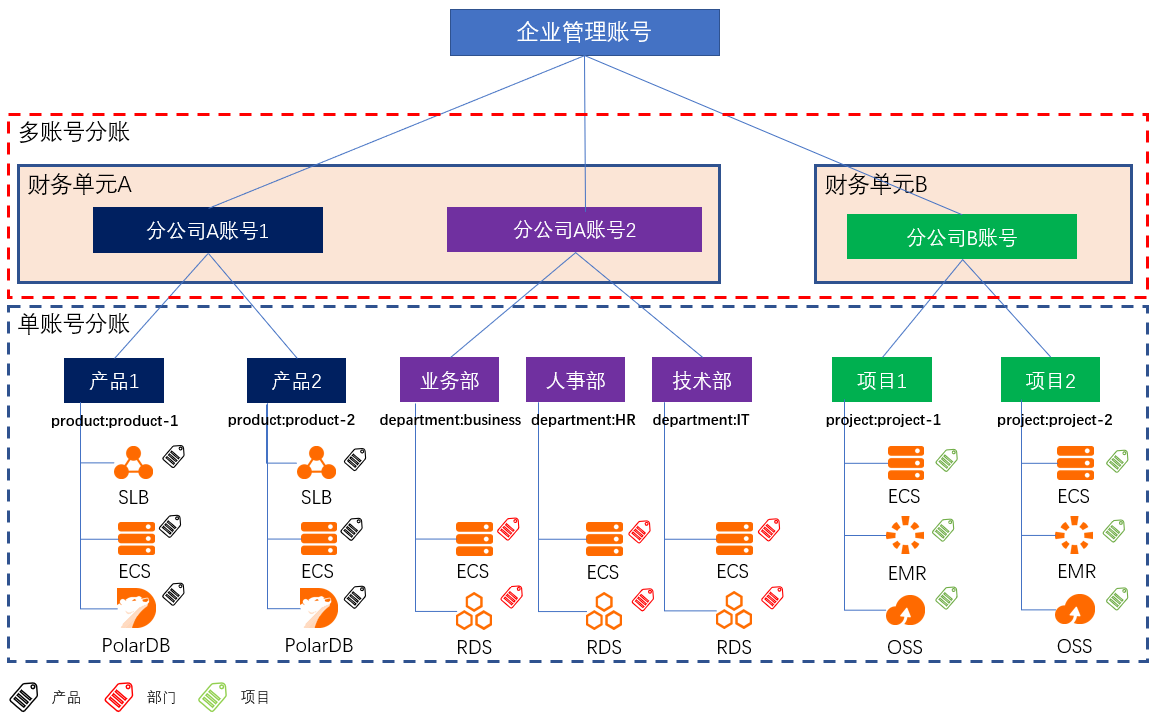
场景描述 财务分账,是根据企业的成本中心,将云上资源的成本划分到给各个项目组/业务部门;助力企业快速梳理云上成本结构,搭建复杂组织架构下的成本关系,便捷地进行财务和云上成本的管理。 大型企业或集团公司,由于组织架构复杂,业务复杂等原因,通常拥有多个阿里云账号来管理规模庞大的云上资源。针对云上资源,如何建立有效的分账方案,是财务关注的重要问题。 解决问题 解决CIO/CTO最关心的云上IT治理,IT成本核算等问题。 弄清楚企业内各部门成本及云上IT成本结构。 让CIO/CTO准确地掌握云上资源成本情况,清楚业务与成本的关系。 让采购/运维轻松搞定每月的IT成本汇报。
使 用 CADT模板中的步骤通过模板创建架构图。步骤2 保留架构图中分公司 A账号 1所需的资源,删除其他资源。步骤3 通过模板创建的架构图,ECS中的登录密码未包含在模板中,在部署应用前需要手工 输入。双击架构图中的 ECS实例,滚动到密码部分,填入管理员密码。文档版本:20210128 22 多账号下企业分账最佳实践 搭建模拟...
- 产品推荐
- 这些文档可能帮助您