基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步
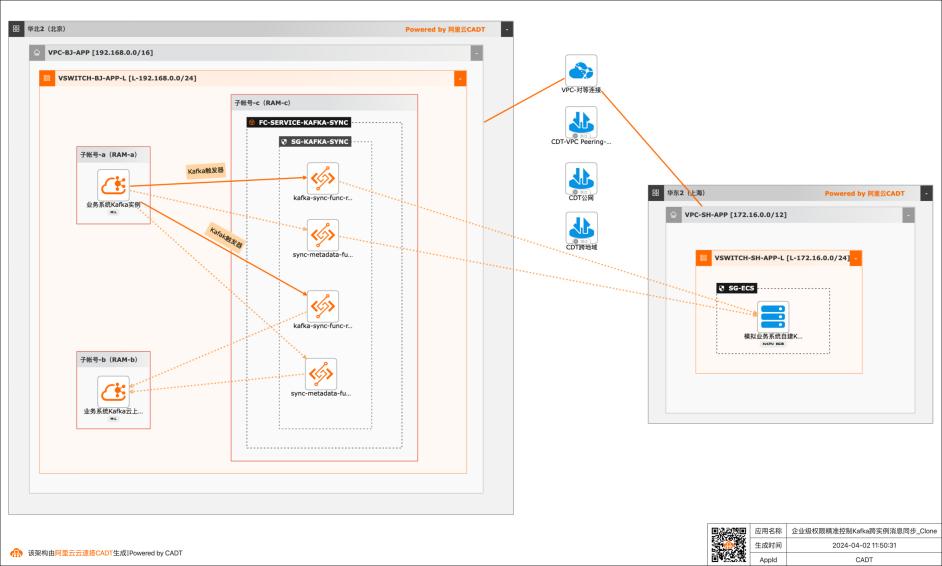
应用场景 在大数据场景,企业的Kafka实例可能存在多种情况,比如使用阿里云Kafka服务,可能是自建开源Kafka,或者是其他云上的云Kafka。不同的业务使用不同类型的Kafka实例,在这个前提下Kafka实例之间可能会需要消息同步的情况: 同帐号容灾场景:比如Kafka实例都是阿里云Kafka,但是Kafka实例会有主备之分,需要将主Kafka实例的消息实时同步到备Kafka。 跨帐号或异地容灾:这类场景比如主Kafka是阿里云Kafka,备Kafka是IDC开源自建Kafka,或者是其他云上的Kafka。 不同业务之间消息同步:因为现在的业务通常不会是信息孤岛,都需要消息互通,所以可能是A业务的Kafka实例消息需要同步到B业务的Kafka实例,并且这两个Kafka实例归属不同的RAM角色,有自己独自的权限控制。 解决问题 解决使用开源组件做消息同步的高成本问题。 解决使用开源组件做消息同步的并发性能、稳定性问题。 解决使用开源组件做消息同步的可靠性问题(重试机制,容错机制,死信队列等)。 大幅提升构建消息同步架构的效率,降低构建复杂度问题。
进入角色菜单,搜 索AliyunFcDefaultRole。文档版本:20240330 35基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步 场景验证 步骤2 点击AliyunFcDefaultRole进入详情页面,点击新增权限按钮。步骤3 授权范围选择整个云帐号,选择系统策略,依次搜索 AliyunOSSFullAccess AliyunFCFullAccess AliyunVPCFullAccess ...
云上高并发系统改造
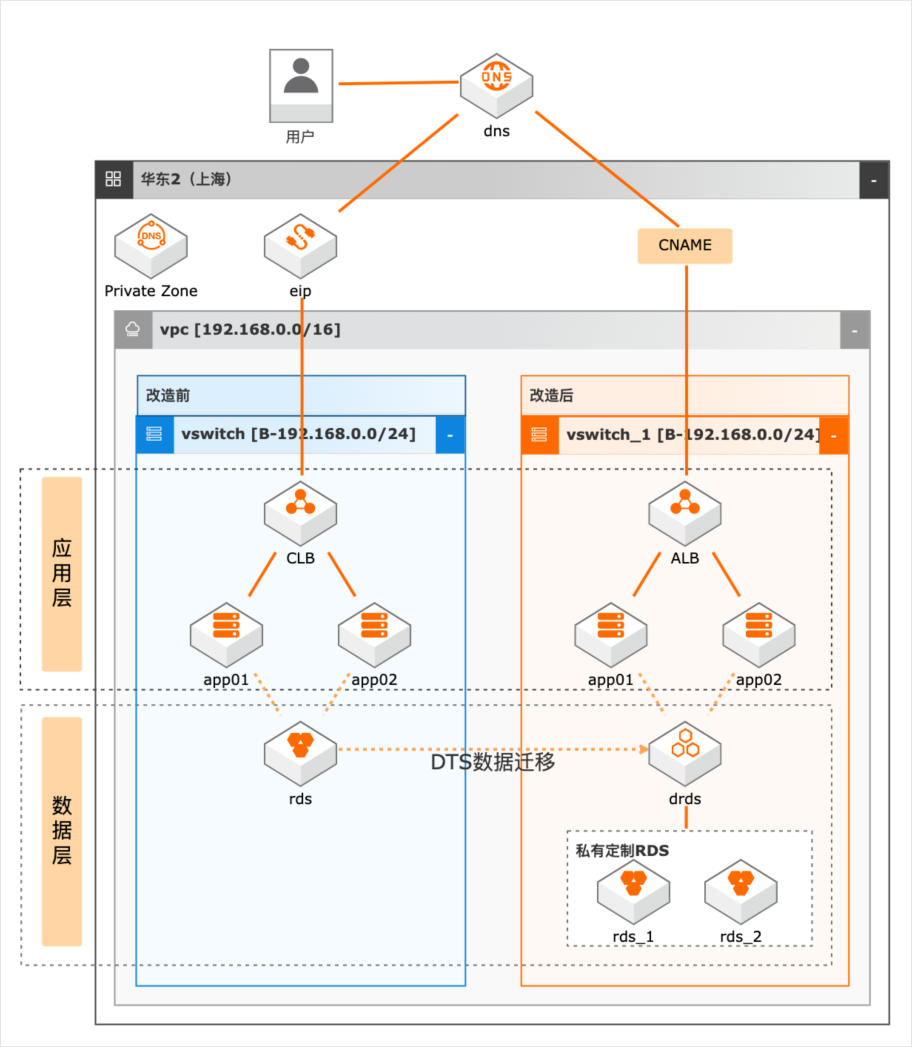
场景描述 随着业务的发展,系统并发压力越来越大,如何 进行系统改造以满足高并发场景的业务需求成 为了一个技术难题。本实践抽象于客户的实际场 景,提供高并发下系统改造的理论指导和部分实 操演示。主要适用于以下场景: 1.系统并发压力大,需要进行系统应用改造。 2.数据层并发压力大,需进行分库分表改造。 3.数据库数据量巨大,亟待分库分表解决查询 和写入瓶颈的场景。 方案优势/解决问题 1.在水平扩展阶段,我们除了通过SLB做负载 均衡外,我们可以通过SLB下挂nginx的方 式,增加负载均衡侧的可扩展性 2.在数据库拆分阶段,在做好数据规划后,我 们借助DTS进行数据迁移,通过DRDS将 RDS MySQL的数据拆分到多个分库和分 表中。 产品列表 专用网络VPC 负载均衡SLB 云服务器ECS 数据库RDSMySQL 数据传输服务DTS PrivateZone 分布式关系型数据库DRDS
所以,解决问题的 前提是要搞清楚我们今天面临的业务量有多大,增长走势是什么样的,而且解决高 并发的过程,一定是一个循序渐进逐步的过程。本着以上原则整个系统的进化可以参考下图(图片来自云栖社区):整个系统进化分为三个阶段:x轴,水平扩展阶段,通过负载均衡服务器不断地横向扩充应用服务器,水平 扩展最重要的...
- 产品推荐
- 这些文档可能帮助您