自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 业务架构 场景描述 客户在 IDC或者公有云环境自建 Hadoop集群 构建数据仓库和分析系统,购买阿里云 Databricks数据洞察集群之后,涉及到数仓数 据和元数据的迁移以及 Hive版本的订正更新。方案优势 1.全托管 Spark集群免运维,节省人力成 本。2.Databricks数据洞察...
Function Compute构建高弹性大数据采集系统
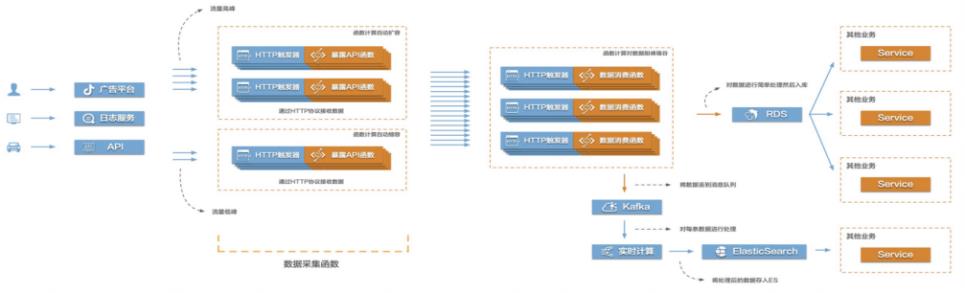
当前互联网很多场景都存在需要将大量的数据信息采集起来然后传输到后端的各类系统服务中,对数据进行处理、分析,形成业务闭环。比如游戏行业中的游戏发行、游戏运营,产互行业中的数字营销,物联网、车联网行业中的硬件、车辆信息上报等等。这些场景普遍存在数据采集量大、数据传输需要稳定且吞吐量大的特点,给整个数据采集传输系统带来很大的挑战。在这个场景中,有三个关键的环节,数据采集、数据传输、数据处理。该最佳实践主要涉
创建数据采集函数#process custom request headers pass try:request_body_size=int(environ.get('CONTENT_LENGTH',0))except(ValueError):request_body_size=0#接收回传的数据,对传入的数据做 json处理 request_body=environ['wsgi.input'].read(request_body_size)request_body_str=urllib.parse.unquote(request_body....
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。
相关命令可 以下载后浏览:gitclonehttps:/best-practice:Abcd123456@codeup.aliyun.com/best-practice/bp/199.git 使用场景 针对分析师如何利用MaxComputeIn-databaseML 能力,通过湖仓一体架构对海量OSS 非结构化、半结构化数据做数据分析和机器学习模型构建、训练和应用。业务架构基于湖仓一体架构使用MaxCompute对OSS湖...
智能数据建设与治理Dataphin
Dataphin遵循阿里巴巴集团多年实战沉淀的大数据建设OneData体系(OneModel、OneID、OneService),集产品、技术、方法论于一体,一站式地为您提供集数据引入、规范定义、智能建模研发、数据萃取、数据资产管理、数据服务等的全链路智能数据构建及管理服务。助您打造属于自己的标准统一、资产化、服务化和闭环自优化的智能数据体系,驱动创新。
基于Dataphin的数据管理能力,数据量庞大的地产企业做了数据治理的工作,进行数据采集,构建数据模型,进行多维数据分析,比如描述性分析、预测性分析、诊断性分析,而它们之间是一步一步进阶的。数据中台大幅度降低了数据运营成本与决策时间成本,提高了速度和准确性.集成超过50个数据源涉及的数据,地产、物业、营销、...
来自:
云产品
多媒体数据存储与分发
以搭建一个多媒体数据存储与分发服务为例,搭建一个多媒体数据存储与分发服务。
产品解决方案文档与社区权益中心定价云市场合作伙伴支持与服务了解阿里云备案控制台多媒体数据存储与分发方案介绍方案优势应用场景方案部署方案权益多媒体数据存储与分发视频、图文类多媒体数据量快速增长,内容不断丰富,多媒体数据存储与分发解决方案融合对象存储 OSS、内容分发 CDN、智能媒体管理 IMM 等产品能力,解决...
来自:
解决方案
Spark on ECI大数据分析

场景描述 方案优势 1.计算引擎弹性扩缩容,兼顾资源弹性与计 算资源成本优化。 2.计算与存储分离架构,结合阿里云原生云 存储产品,海量数据湖优势。 3.Kubernetes原生的调度性能优势,提升在 大规模分析作业时的分析性能优势分。 4.集群资源隔离和按需分配。 解决问题 1.计算资源弹性能力不足,计算资源成本管 控能力欠缺. 2.集群资源调度能力和隔离能力不足。 3.计算与存储无法分离,大数据量分析时出 现数据存储资源瓶颈。 4.Spark submit方式提交分析作业参数支持 有限等缺点。 产品列表 容器服务Kubernetes版(ACK) 弹性容器实例(ECI) 文件存储HDFS 对象存储OSS 专有网络VPC 容器镜像服务ACR
对 Spark大数据分析平台计算资源成本控制考虑的用户 需要有灵活可扩展计算平台资源弹性及管控的用户 名词解释 文件存储 HDFS:阿里云文件存储 HDFS是面向阿里云 ECS实例及容器服务等计 算资源的文件存储服务,允许用户像在 Hadoop分布式文件系统中管理和访问数 据,无需对数据分析应用做任何修改,即可使用具备无限容量及...
数据传输解决方案
数据传输解决方案支持关系型数据库、NoSQL、大数据(OLAP)等数据源间的数据传输。 它是一种集数据迁移、数据订阅及数据实时同步于一体的数据传输服务。数据传输致力于在公共云、混合云场景下,解决远距离、毫秒级异步数据传输难题。
从RDS向后端数据汇总,获得全局业务的实时统计、BI报表和分析.数据传输DTS.云数据库MySQL.云服务器ECS.其业务系统的数据变化,以订阅消息的方式,快速向下游分发.数据传输DTS.云数据库MySQL.借助DTS异构数据库迁移的能力,银泰百货实施了去O上云.数据传输DTS.云数据库PolarDB-X.云数据库MySQL.UC浏览器实现了异地多活的架构...
来自:
解决方案
数据湖-在线学习场景数据分析

场景描述 本场景以在线教育中一个答题闯关类的应用为 例,使用WebServer来模拟演示这类日志数据 的分析处理。通过Nginx和Pythonflask搭建 WebServer,模拟应用中的关键页面,比如登 录、课程内容等,之后构造若干用户使用的模拟 日志数据,投递到数据湖进行分析后获取应用 PV、UV、课程内容访问排行、平均得分等等。 解决问题 基于数据湖(EMR+OSS)搭建大数据平台。 EMR和OSS使用和配置。 数据统一存储到OSS。 产品列表 E-MapReduce 对象存储OSS 云服务器ECS 访问控制RAM 专有网络VPC
通过Nginx和Pythonflask搭建WebServer,模拟应用中的关 键页面,比如登录、课程内容等,之后构造若干用户使用的模拟日志数据,投递到数 据湖进行分析后获取应用PV、UV、课程内容访问排行、平均得分等等。方案优势 支持超过10亿条元数据规模的数据管理,同时支持高可靠和高可用。 支持元数据实时备份和重建集群快速恢复...
Databricks数据洞察
阿里云Databricks数据洞察是基于Apache Spark的全托管数据分析平台, 内核采用更高效、稳定的商业版Databricks Runtime和Delta Lake。可满足数据分析师、数据工程师和数据科学家在大数据场景下对数据湖分析、实时数仓、离线数仓、BI数据分析、AI机器学习等需求
满足高性能、高稳定性、可弹性的计算需求.Databricks Delta Lake为数据湖分析提供了ACID事务能力,轻松处理包含数十亿文件的PB级表的元数据信息,实现了批流一体的数据处理方式.同时满足数据科学家、数据工程师以及业务分析师的计算需求,提供交互式的协同分析工作平台.计算存储分离,减少数据冗余,实现多引擎间的数据共享...
来自:
云产品
智能数据标注PAI-iTAG
智能数据标注PAI-iTAG是一款智能化数据标注平台,支持图像、文本、视频、音频等多种数据类型的标注以及多模态的混合标注。智能标注PAI-iTAG提供了丰富的标注内容组件和题目组件,可以直接使用平台预置的标注模板,也可以根据场景自定义模板进行数据标注。
为任务包进行打标、检查或验收,为模型训练做准备.导出标注结果数据.将结果创建为一个数据集,便于应用于模型训练.远低于自建外包团队的人力成本.标注员专业的技能培训和生产管理.专业标注团队.0事故数据安全运营记录.数据安全保密.标准化SAAS数据标注服务交付流程.全托管式项目管理.PAI-iTAG 提供专业、全托管的定制化标注...
来自:
云产品
数据安全中心
敏感数据保护(Sensitive Data Discovery and Protection),在满足等保v2.0“安全审计”、等保v3.0及“个人信息保护”的合规要求的基础上,为客户提供敏感数据识别、分级分类、数据安全审计、数据脱敏、智能异常检测等数据安全能力,形成一体化的数据安全解决方案。
从海量数据中自动发现并分析敏感数据使用情况,基于数据识别引擎,对其储存结构化数据(RDS)和非结构化数据(OSS、MaxCompute等)进行扫描、分类、分级,解决数据“盲点”,以此做进一步安全防护.隐藏资产自动发现.基于NLP的语义识别,准确发现敏感信息.自定义分级分类规则.重点解决的数据安全问题.数据安全中心.敏感数据...
来自:
云产品
异地双活场景下的数据双向同步
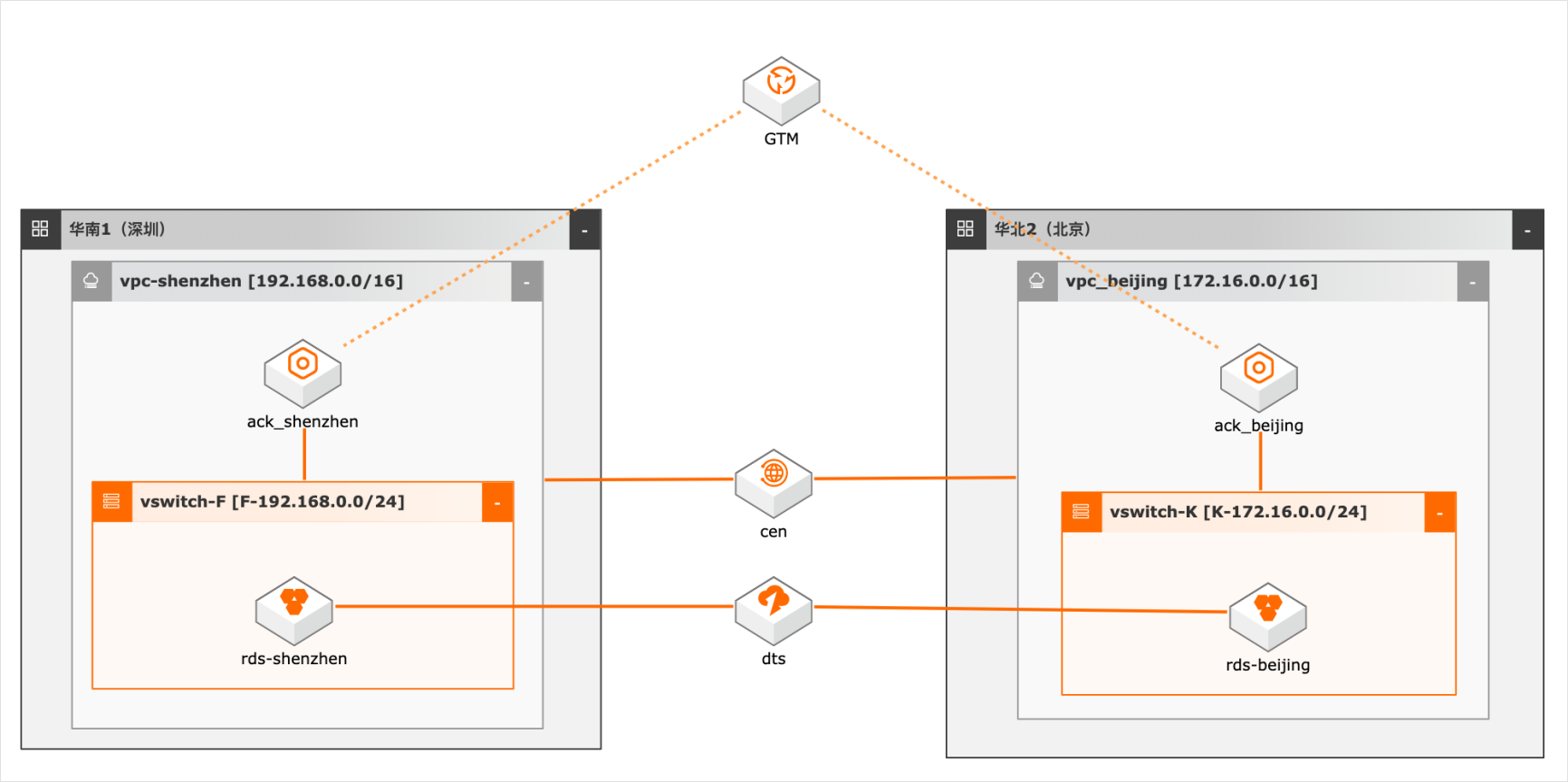
概述 随着客户业务规模的扩大,对系统高可用性要求越来越高,越来越多用户采用异地双活/多活架构,多活架构往往涉及业务侧做单元化改造,本方案仅模拟用户已做单元化改造后的数据双向同步,数据库采用双主架构,本地写本地读,同时又保证双库的数据一致性,为业务增加可用性和灵活性。 适用场景 数据库双向同步 数据库全局ID不冲突 双活架构的数据库建设问题 技术架构 本实践方案基于如下图所示的技术架构和主要流程编写操作步骤: 方案优势 DTS双向同步,采用独立模块避免数据同步占用系统资源。 奇偶ID涉及,避免数据冲突。 DTS多种处理冲突的方式供业务选择。 安全:原生的多租户系统,以项目进行隔离,所有计算任务在安全沙箱中运行。
随着客户业务规模的扩大,对系统高可用性要求越 数据库双向同步 来越高,越来越多用户采用异地双活/多活架构,多 数据库全局 ID不冲突 活架构往往涉及业务侧做单元化改造,本方案仅模 双活架构的数据库建设问题 拟用户已做单元化改造后的数据双向同步,数据库 采用双主架构,本地写本地读,同时又保证双库的数 据一致性,为...
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
基于 DataWorks的大数据一站式开发及数据治理 最佳实践 业务架构 场景描述 解决问题 本实践基于 Dataworks做大数据一站式开发,包含 日志采集、处理及分析 数据实时采集到 kafka 通过实时计算对数据进行 日志使用 Flink实时写入 HDFS ETL写入 HDFS,使用 Hive进行数据分析。通过 日志数据实时 ETL Dataworks进行数据治理,...
云原生数据湖分析DLA
阿里云云原生数据湖分析是新一代大数据解决方案,采取计算与存储完全分离的架构,支持对象存储(OSS)、RDS(MySQL等)、NoSQL(MongoDB等)数据源的消息实时归档建仓,提供Presto和Spark引擎,满足在线交互式查询、流处理、批处理、机器学习等诉求。内置大量优化+弹性,比开源自建集群最高降低50%+的成本,最快可1分钟级拉起300个计算节点,快速满足业务资源要求。
拥有优越弹性,支持元数据发现,支持多源一键数据实时入湖分析等功能,直接使用SQL即可分析OSS等数十种源数据.多项企业级能力,涵盖各类业务需求.GUI工具丰富.支持Microstrategy、MySQL Workbench、DBeaver等多种MySQL GUI管理工具.多种可视化工具支持.与QuickBI、Tableau、DataV等BI工具集成度高、兼容性好.兼容标准SQL....
来自:
云产品
企业构建统一CMDB数据源
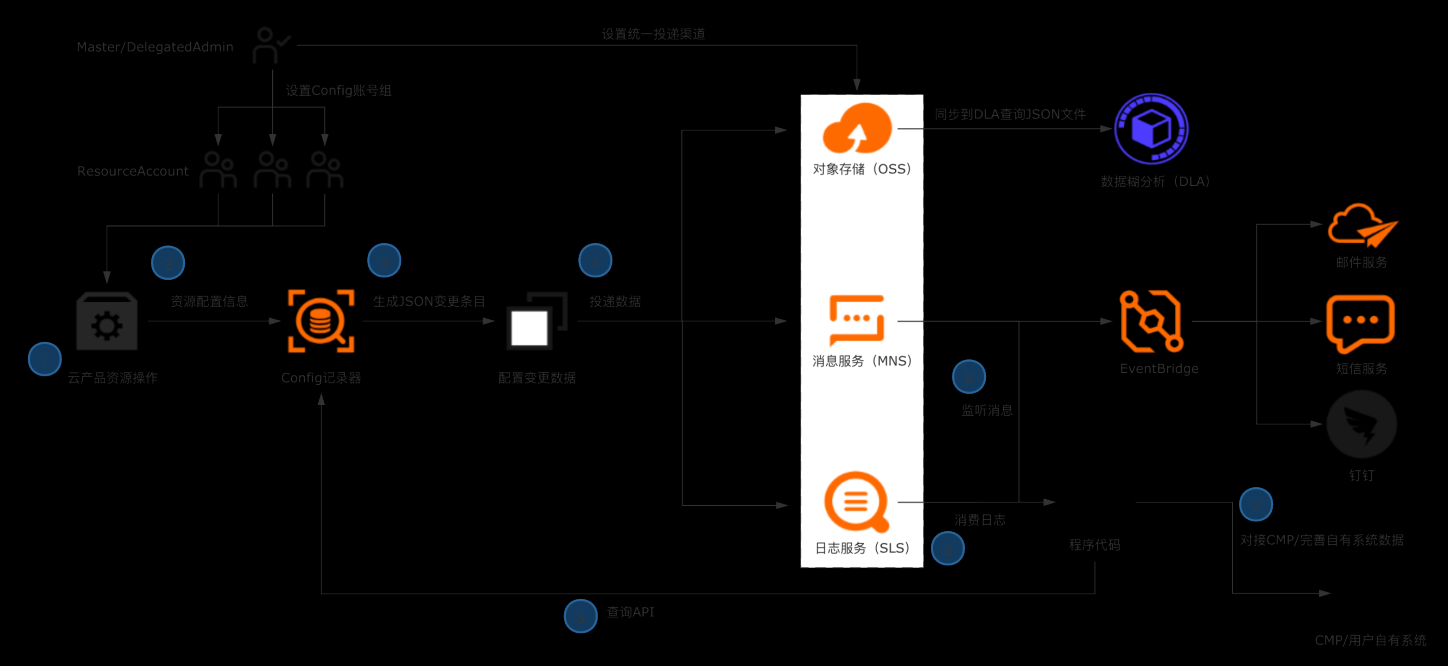
典型场景 l 企业/ISV构建多云CMDB平台,对接数十款产品的API,拉取、清洗、格式化、存储配置数据是复杂且高成本的工作。 l 企业日常的资源管理,需依赖资源配置历史、资源关系数据进行故障溯源和影响评估。 解决方案 l 企业管理账号设置Config配置数据投递,将所有账号的资源配置快照和历史归集到统一地址留存。 l 使用OSS做长期归档,使用SLS做实时分析和监听。获取全量资源数据并及时感知云上资源的变更。 l 将数据集成到自有CMDB平台 客户价值 l 基于配置审计简单便捷的持续收集云上资源配置数据,在自建CMDB过程中节省大量人力和时间成本。 l 跨账号统一收集数据,实现中心化的资源配置管理。 l 实现资源配置数据的持续收集和监听,及时感知云上资源的增删改,洞察异常变更。
获取ECS网络信息 本章节,我们以ECS资源的网络配置数据为例,使用 python脚本模拟将资源配置数 据导入企业自有系统。用到了配置审计的 API,在使用前需要导入阿里云 SDK 核心库:aliyun-python-sdk-core:在多账号情况下,列出主账号下指定账号 组的所有资源数据:在多账号情况下,查询指定资源的详细数据 注意:上述两个...
DTS数据同步集成MaxCompute数仓
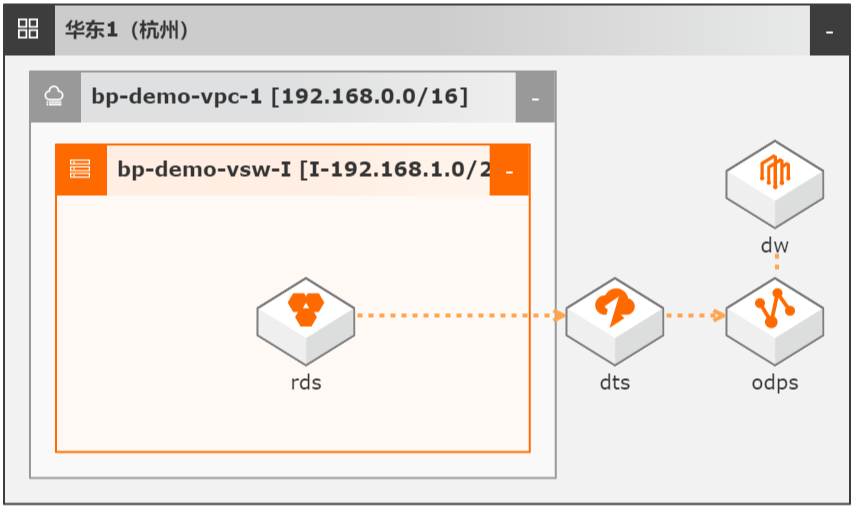
场景描述 本文Step by Step介绍了通过数据传输服务 DTS实现从云数据库RDS到MaxCompute的 数据同步集成,并介绍如何使用DTS和 MaxCompute数仓联合实现数据ETL幂等和数 据生命周期快速回溯。 解决问题 1.实现大数据实时同步集成。 2.实现数据ETL幂等。 3.实现数据生命周期快速回溯。 产品列表 MaxCompute 数据传输服务DTS DataWorks 云数据库RDS MySQL 版
数据抽取不幂等或容错率低,如凌晨 0:00启动的 ETL任务因为各种原因(数据库 HA切换、网络抖动或 MAXC写入失败等)失败后,再次抽取无法获取 0:00时的数 据状态。2.针对不规范设计表,如没有 create_time/update_time的历史遗留表,传统 ETL需 全量抽取。3.实时性差,抽取数据+重试任务往往需要 1-3小时。另外数据库的数据...
- 产品推荐
- 这些文档可能帮助您