通过ES兼容接口方式使用Kibana访问SLS数据
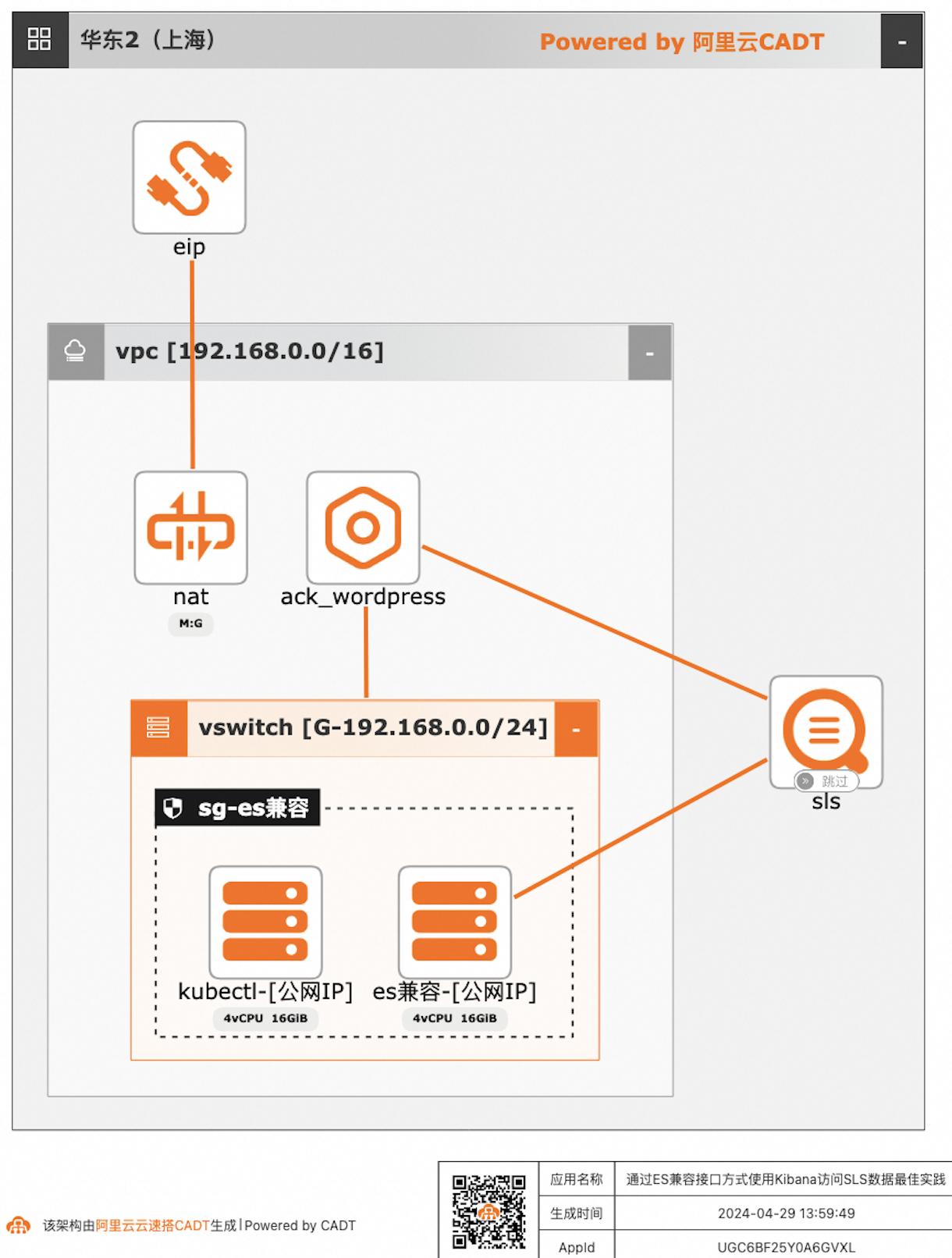
自建ELK日志系统的客户迁移到阿里云日志服务SLS后,对SLS查询分析语法不太熟悉的客户,可以继续沿用原有的查询分析习惯,在不改变使用方式习惯的情况下,通过Elasticsearch兼容接口的方式使用Kibana访问SLS。
遇到这类问题请先去控制台人工进行资 源清理后,在CADT中再次释放资源即可。步骤3 打开需要释放的应用,点击画布下方的资源清单。步骤4 点击释放全部资源。文档版本:20240418 42基于MSE云原生网关同城多活最佳实践 释放环境 步骤5 确认后,需要点击确定按钮。步骤6 需要用户再次确认,点击确定后,如果是主账号会触发风控...
向量检索服务 Milvus 版
阿里云向量检索服务Milvus版是一款云原生开源向量检索引擎,为用户提供多模态检索服务和高效稳定的向量数据检索能力,与云计算等产品集成对接,为AI应用场景的数据工程提供便利。
数据安全系统数据安全:管控服务通过HTTPS化确保了请求访问链路的安全,同时对产品服务数据实施多备份存储策略,以增强数据传输和存储的安全性。通过这些措施,管控服务不仅确保了数据在传输过程中的安全,还通过多备份策略保障了数据的持久性和可靠性,为用户提供了一个全面、可靠的安全保障体系。业务数据安全:阿里云...
来自:
云产品
可观测链路 OpenTelemetry版结合日志服务SLS关联分析最佳实践
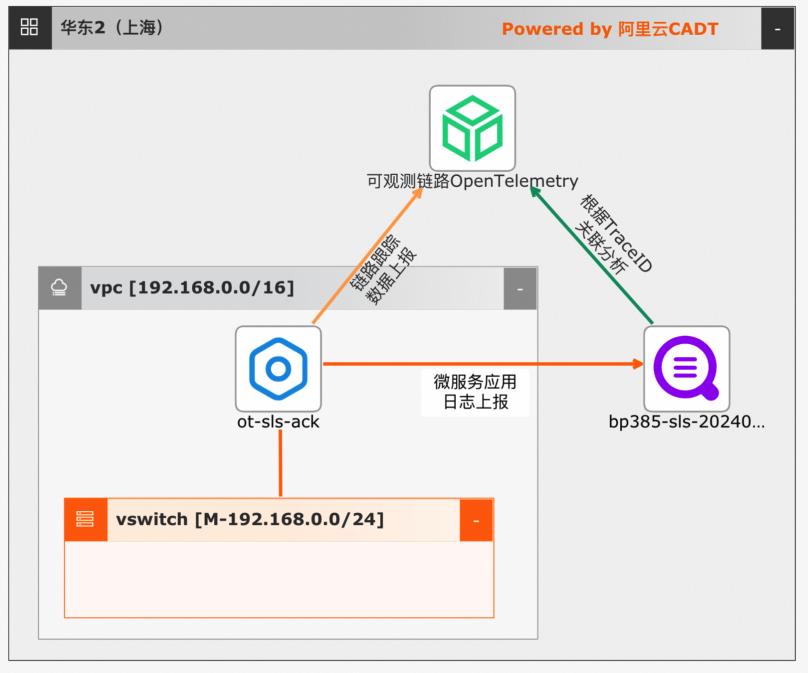
可观测链路 OpenTelemetry 版为分布式应用的开发者提供了完整的调用链路还原、调用请求量统计、链路拓扑、应用依赖分析等工具,可以帮助开发者快速分析和诊断分布式应用架构下的性能瓶颈,当应用出现业务异常问题时,您可以在可观测链路 OpenTelemetry 版控制台关联查看日志进行分析,精准定位业务异常。
遇到这类问题请先去控制台人工进行资 源清理后,在 CADT中再次释放资源即可。步骤1 打开需要释放的应用,点击画布下方的资源清单。点击释放全部资源。步骤2 确认后,需要点击确定按钮。步骤3 需要用户再次确认,点击确定后,如果是主账号会触发风控(手机校验等),请按照提 示进行操作。文档版本:20240428 22 可观测链路 ...
阿里云日志服务SLS多云统一日志方案之腾讯云日志采集最佳实践
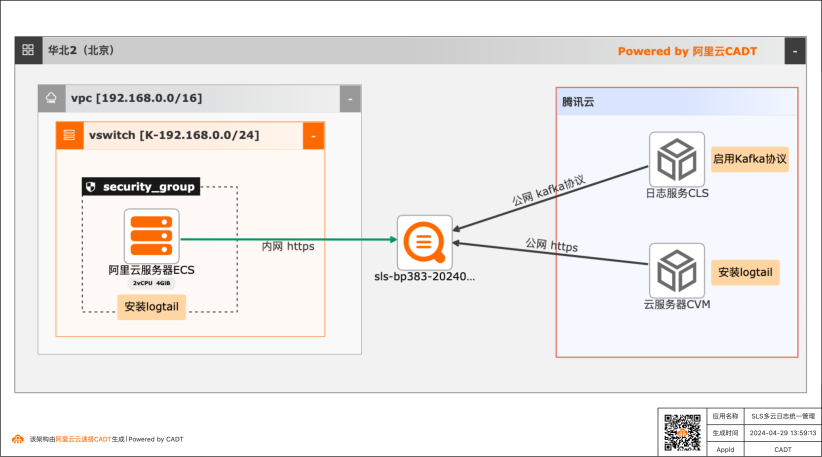
使用日志服务SLS统一采集、存储、查询和分析阿里云、腾讯云等不同云厂商上的业务日志、系统日志和云产品日志,实现在一个平台上管理多云架构下的所有日志。
阿里云 SLS多云日志统一管理方案-腾讯云日志采集 最佳实践 业务架构 场景描述 使用日志服务 SLS统一采集、存储、查询和分析 阿里云、腾讯云等不同云厂商上的业务日志、系 统日志和云产品日志,实现在一个平台上管理多 云架构下的所有日志。产品列表 方案适用的场景和优势 阿里云 多云:使用多云架构的用户都需要有一个统一...
RocketMQ性能压测快速方案
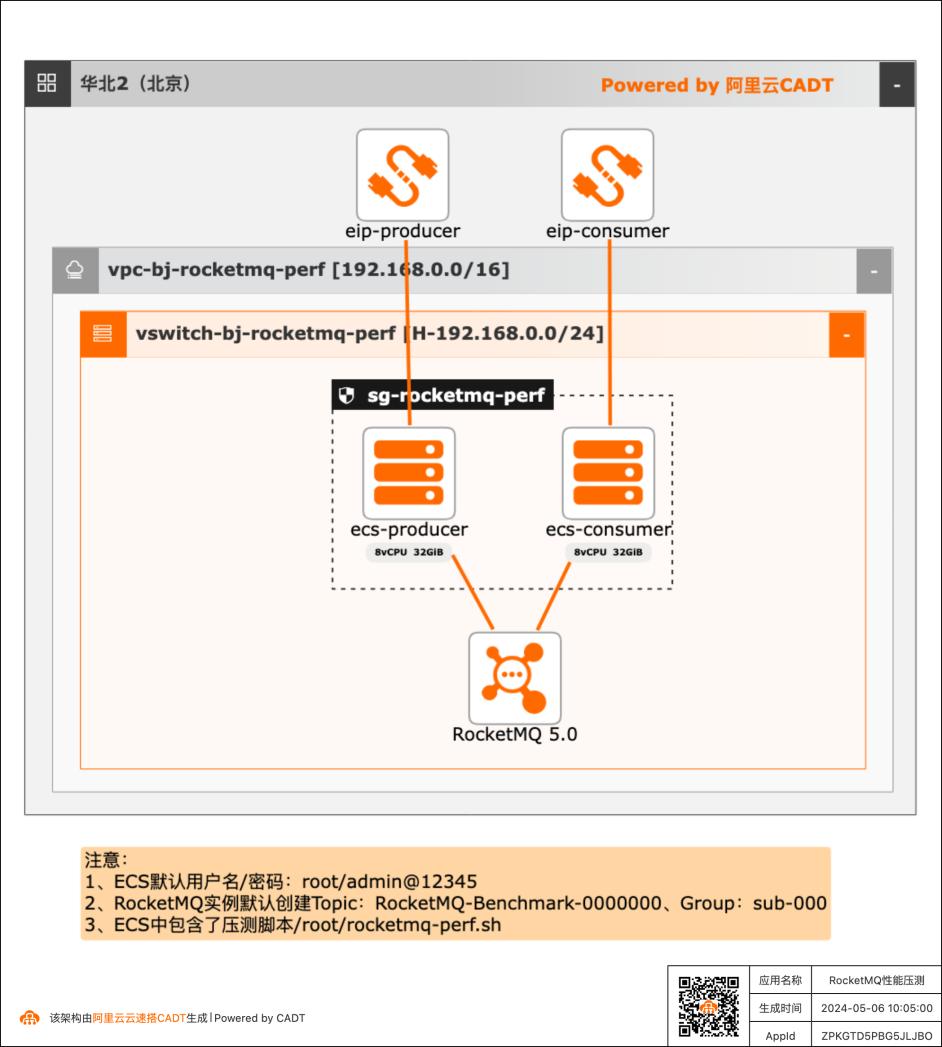
在客户对产品性能存疑或者给客户进行POC验证时可以用本实践来快速完成性能测试。
这里需要注意,如果通过CADT创建的VPC、vswitch中人工通过其他方式添加了资 源,如通过控制台或者API等购买了ECS,释放时因为这些非CADT部署的资源会 依赖VSW和VPC,会出现释放失败。遇到这类问题请先去控制台人工进行资源清理 后,在CADT中再次释放资源即可。步骤1 打开需要释放的应用 步骤2 打开资源清单,点击释放全部...
MSE云原生网关解析body内容进行路由转发
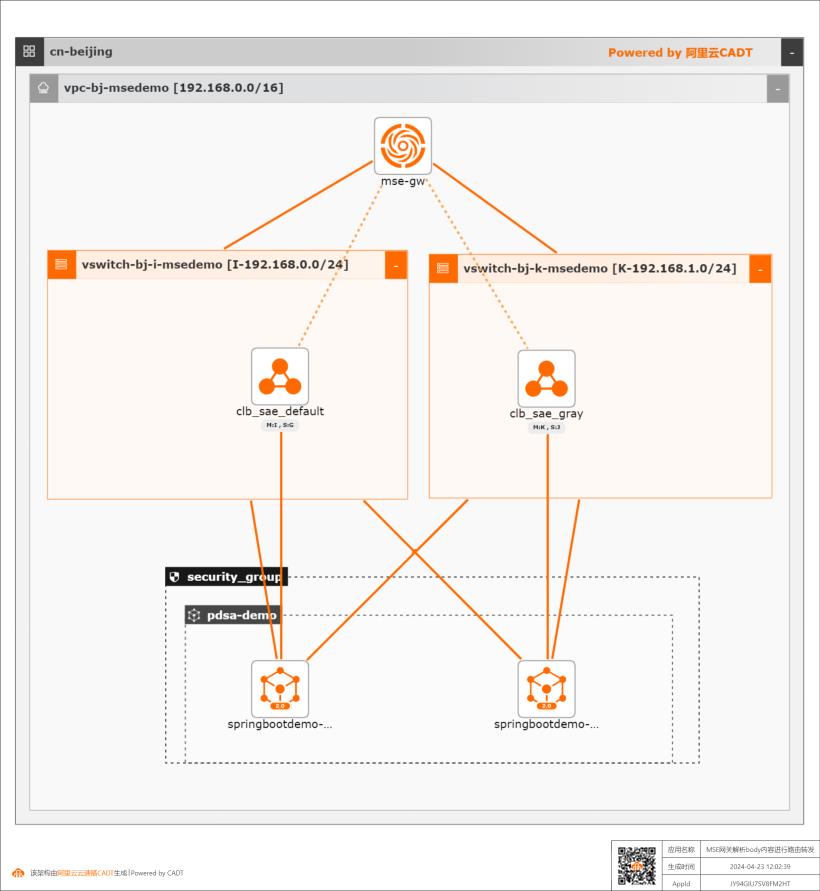
MSE云原生网关中通过自定义插件transformer解析body内容,并用以路由转发规则判断
这里需要注意,如果通过 CADT创建的 VPC、VSwitch中人工通过其他方式添加了资 源,如通过控制台或者 API等购买了 ECS,释放时因为这些非 CADT部署的资源会 依赖 VSwitch和 VPC,会出现释放失败。遇到这类问题请先去控制台人工进行资源清 理后,在 CADT中再次释放资源即可。步骤1 打开需要释放的应用 步骤2 打开资源清单,...
基于函数计算FC实现物联网音视频处理
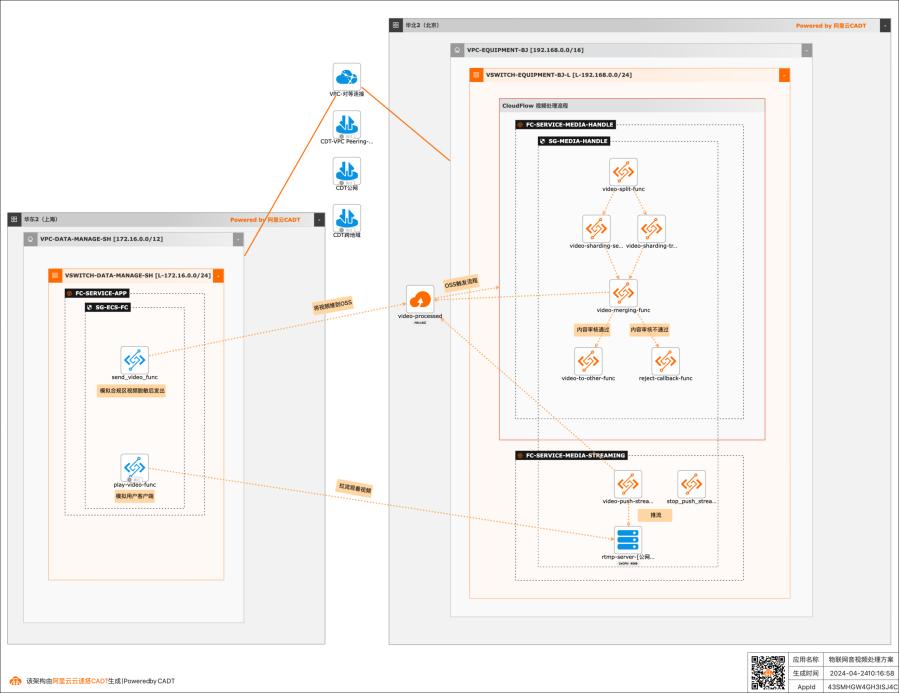
在物联网场景中,智能设备会产生大量的非结构化数据,并且采集量和频率都很高。比如各类摄像头(家用摄像头、车载摄像头、工业监控摄像头等)采集的数据。企业需要对这些非结构化数据做快速的分析和处理,然后应用到下游业务中,所以需要一套高并发、低成本、自动化的方案。该最佳实践就适用于这类场景。
应用场景 在物联网场景中,智能设备会产生大量的非结构化数 据,并且采集量和频率都很高。比如各类摄像头(家 用摄像头、车载摄像头、工业监控摄像头等)采集的 数据。企业需要对这些非结构化数据做快速的分析和 处理,然后应用到下游业务中,所以需要一套高并发、低成本、自动化的方案。该最佳实践就适用于这类场 景。解决...
基于函数计算FC镜像部署Stable Diffusion大模型
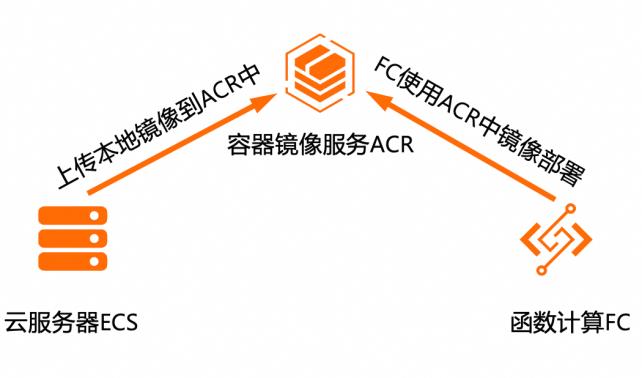
在现代AI应用中, Stable Diffusion等模型因其强大的功能而受到关注。然而,这些模型对计算资源的高需求和复杂的运维管理成为部署时的挑战。基于函数计算FC的无服务器计算模式为这类模型的部署提供了全新的解决方案。用户只需关注模型的部署和调用逻辑,而无需关心底层的服务器配置、资源分配和扩展性等问题。函数计算FC能够自动处理函数的执行环境,包括冷启动、弹性伸缩等,确保模型能够在大规模的请求下稳定运行。
然而,这些模型对计算资 源的高需求和复杂的运维管理成为部署时的挑战。基于函数计算 FC的无服务器计算模式为这类模型的 部署提供了全新的解决方案。用户只需关注模型的 部署和调用逻辑,而无需关心底层的服务器配置、资源分配和扩展性等问题。函数计算 FC能够自动处 理函数的执行环境,包括冷启动、弹性伸缩等,确 保模型...
基于函数计算实现直播流录制-存储-通知
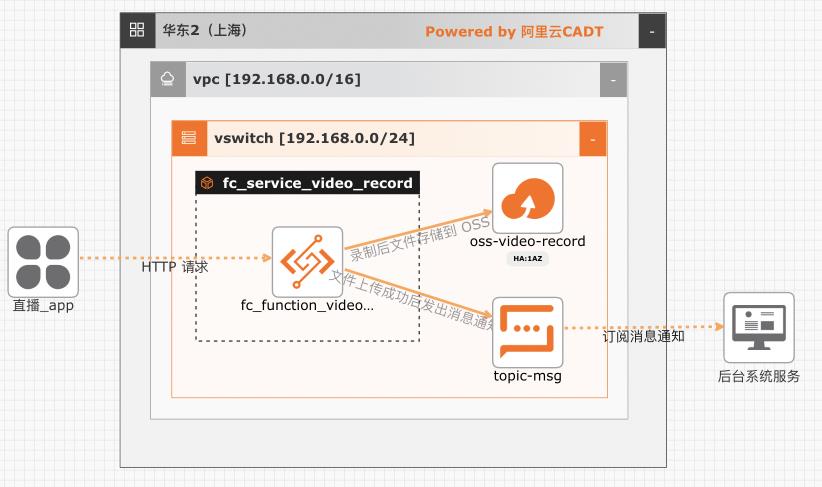
在互娱、教育、电商等行业都会有直播相关的业务,大部分场合都需要对直播相关的业务做安全审核,或者对直播的课程进行录制和转码。该方案实现了一种完全按需拉起、按量弹性、按实际使用付费的录制方案。基于本方案还可以扩展实现直播流截帧、自动化安全审核等能力
云速搭 CADT(Cloud Architect Design Tools):是一款为上云应用提供自助式云架构管 理的产品,显著地降低应用云上管理的难度和时间成本。本产品提供丰富的预制应用架构 模板,同时也支持自助拖拽方式定义应用云上架构;支持较多阿里云服务的配置和管理。用户可以方便的对云上架构方案的成本、部署、运维、回收进行全生命...
基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步
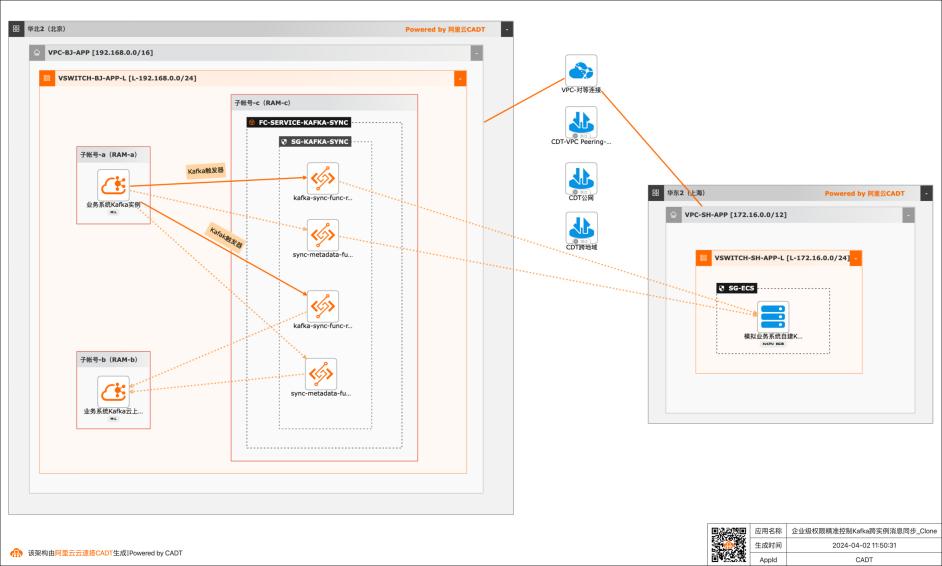
应用场景 在大数据场景,企业的Kafka实例可能存在多种情况,比如使用阿里云Kafka服务,可能是自建开源Kafka,或者是其他云上的云Kafka。不同的业务使用不同类型的Kafka实例,在这个前提下Kafka实例之间可能会需要消息同步的情况: 同帐号容灾场景:比如Kafka实例都是阿里云Kafka,但是Kafka实例会有主备之分,需要将主Kafka实例的消息实时同步到备Kafka。 跨帐号或异地容灾:这类场景比如主Kafka是阿里云Kafka,备Kafka是IDC开源自建Kafka,或者是其他云上的Kafka。 不同业务之间消息同步:因为现在的业务通常不会是信息孤岛,都需要消息互通,所以可能是A业务的Kafka实例消息需要同步到B业务的Kafka实例,并且这两个Kafka实例归属不同的RAM角色,有自己独自的权限控制。 解决问题 解决使用开源组件做消息同步的高成本问题。 解决使用开源组件做消息同步的并发性能、稳定性问题。 解决使用开源组件做消息同步的可靠性问题(重试机制,容错机制,死信队列等)。 大幅提升构建消息同步架构的效率,降低构建复杂度问题。
基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步最佳实践 场景描述 业务架构 基于阿里云函数计算FC实现同帐号阿里云Kafka实 例之间消息、元数据同步,跨帐号阿里云Kafka实例 之间消息、元数据同步,阿里云Kafka实例和IDC 自建Kafka(其他云Kafka)之间消息、元数据同步。应用场景 在大数据场景,企业的Kafka实例...
容器场景下的应用性能监控、调用链拓扑、内存剖析
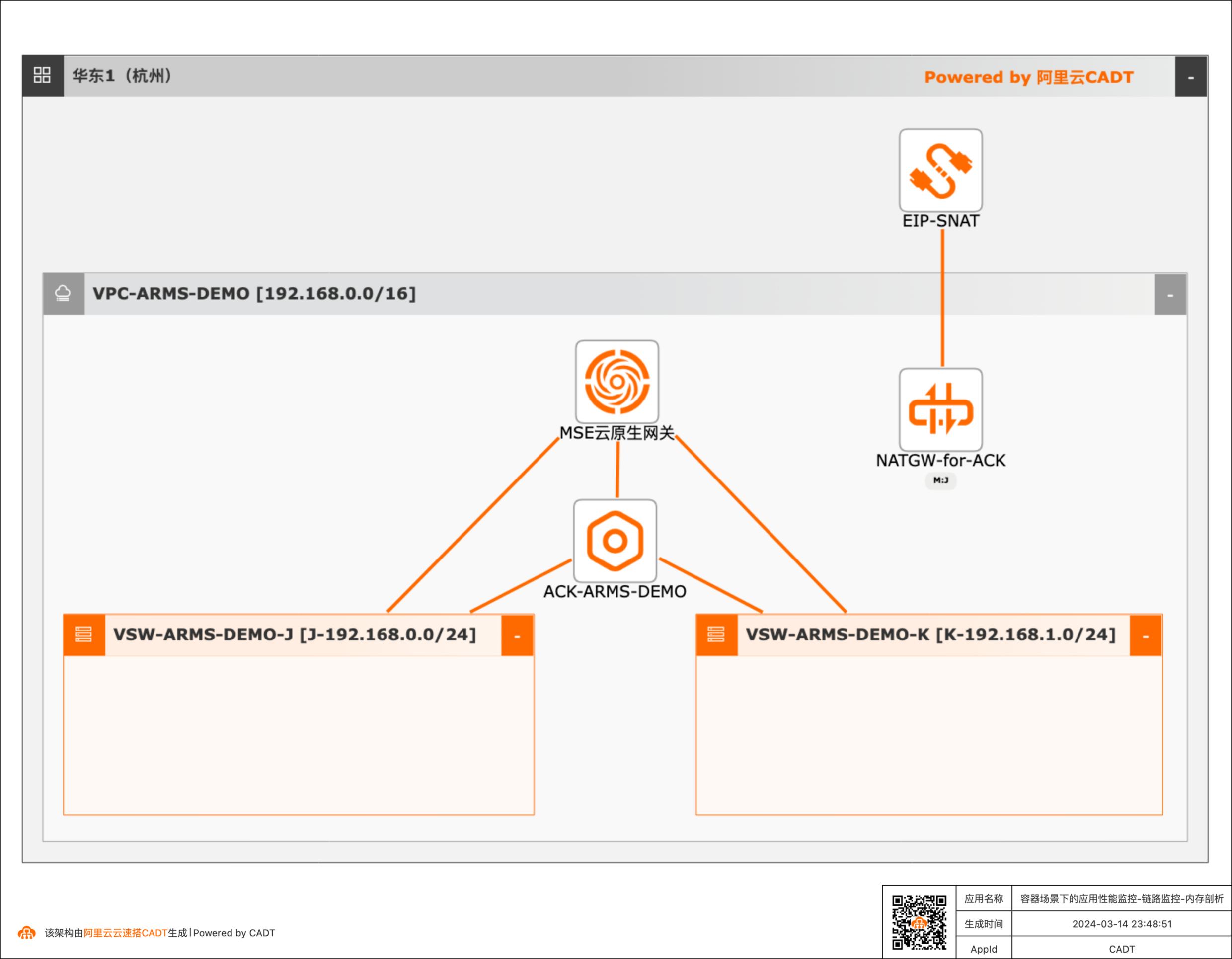
场景描述 随着云原生及微服务技术的普及,越来越多的系统已经通过云原生和微服务技术实现企业的降本增效,同时因微服务及云原生的复杂性给系统运维带来非常大的挑战,云原生应用监控arms通过全链路应用监控,从端到端及代码级别的链路下钻能力、CPU、内存持续剖析及诊断能力,帮助客户降低系统故障定位难度,此demo,您将体验arms的链路监控、内存剖析等能力 应用场景 微服务+容器场景下链路调用拓扑,调用链可以显示出服务之间的调用顺序和层次关系,帮助开发人员理解和追踪代码的执行流程 在分布式系统中,一个请求往往需要通过多个服务来完成。当出现问题时,如请求超时、错误或异常,很难快速定位问题所在。 解决问题 调用链可以帮助运维人员解决以下问题: · 故障排查:当请求失败或出现错误时,调用链可以显示整个请求的路径和每个服务的执行情况,从而帮助运维人员快速定位问题所在。 · 性能优化:通过调用链,运维人员可以了解请求在系统中的执行时间和瓶颈所在,从而进行优化。 · 系统监测:调用链可以提供实时的系统监测和分析,帮助运维人员了解系统的健康状况和资源利用情况。
容器场景下的应用性能监控、调用链拓扑、内存剖析 最佳实践 场景描述 业务架构 随着云原生及微服务技术的普及,越来越多的系 统已经通过云原生和微服务技术实现企业的降 本增效,同时因微服务及云原生的复杂性给系统 运维带来非常大的挑战,云原生应用监控arms 通过全链路应用监控,从端到端及代码级别的链 路下钻能力、CPU...
容器多云统一监控日志
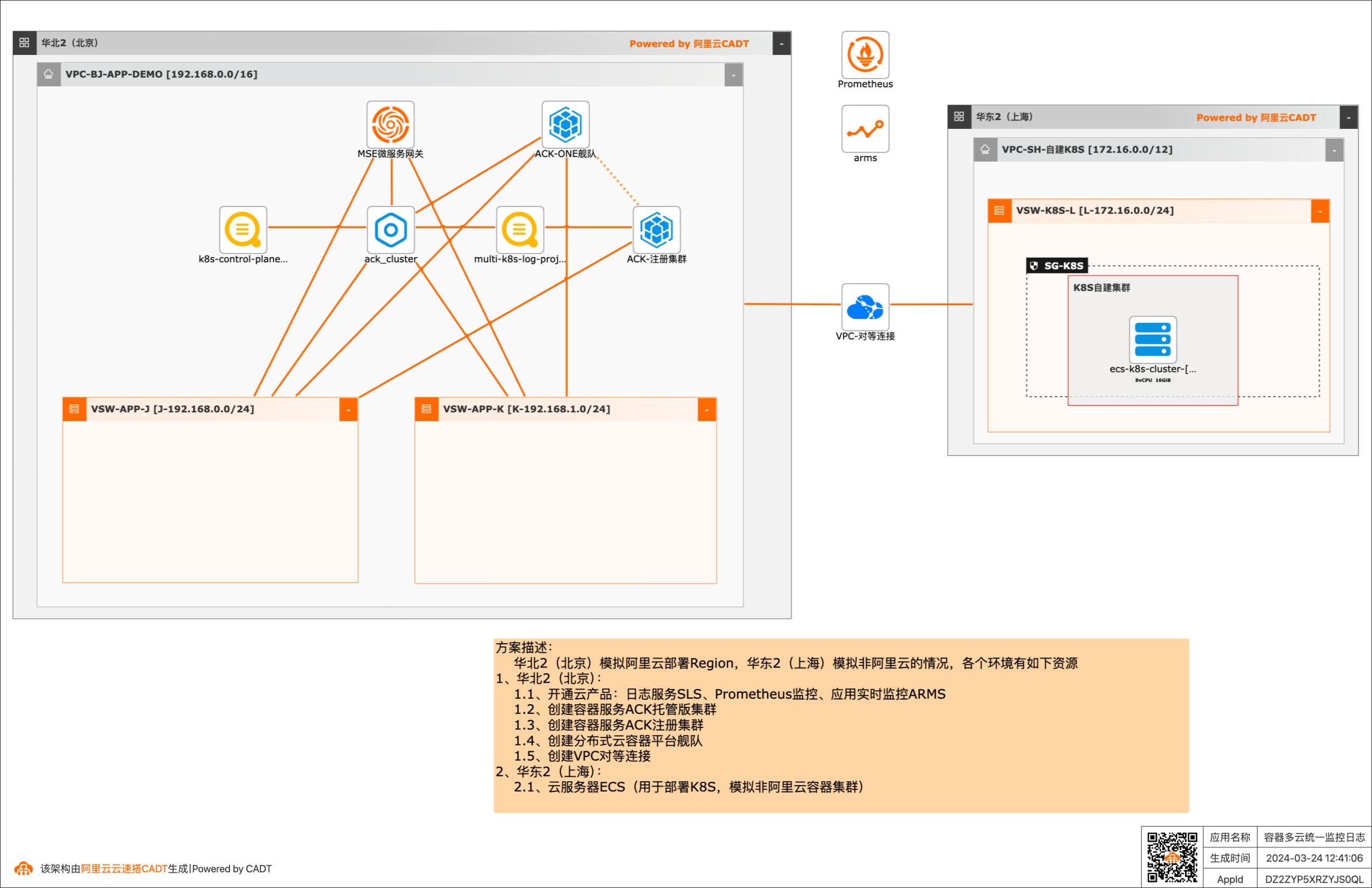
多云、混合云成为常态,Forrester 报告中指出,未来 89% 的企业至少使用两个云,74% 的企业至少使用三个甚至更多公有云,在面对多云/混合云这样大的趋势下,Gartner报告指出,安全、运维复杂性、财务复杂性是多云架构的主要挑战,本方案给出了在多云/混合云场景下,构建基于容器环境下的统一管理、统一监控和统一日志方案,解决多云、混合云场景下,运维复杂性问题。 应用场景 客户在阿里云以外的其他云服务商(AWS、Azure、GCP、TencentCloud、HuaweiCloud等)或者IDC基于容器(Kubernetes)运行业务系统,希望构建容器场景下的统一监控日志系统,方便做不同大屏和问题分析定位。 解决问题 •构建容器多云统一监控和日志系统,在一个平台可以看到不同环境系统的运行情况。
这里需要注意,如果通过CADT创建的VPC、vswitch中人工通过其他方式添加了资 源,如通过控制台或者API等购买了ECS,释放时因为这些非CADT部署的资源会 依赖VSW和VPC,会出现释放失败。遇到这类问题请先去控制台人工进行资源清理 后,在CADT中再次释放资源即可。步骤1 对等连接路由策略释放,其中 步骤2 打开需要释放的应用 ...
基于函数计算FC实现阿里云Kafka消息内容控制MongoDB DML操作
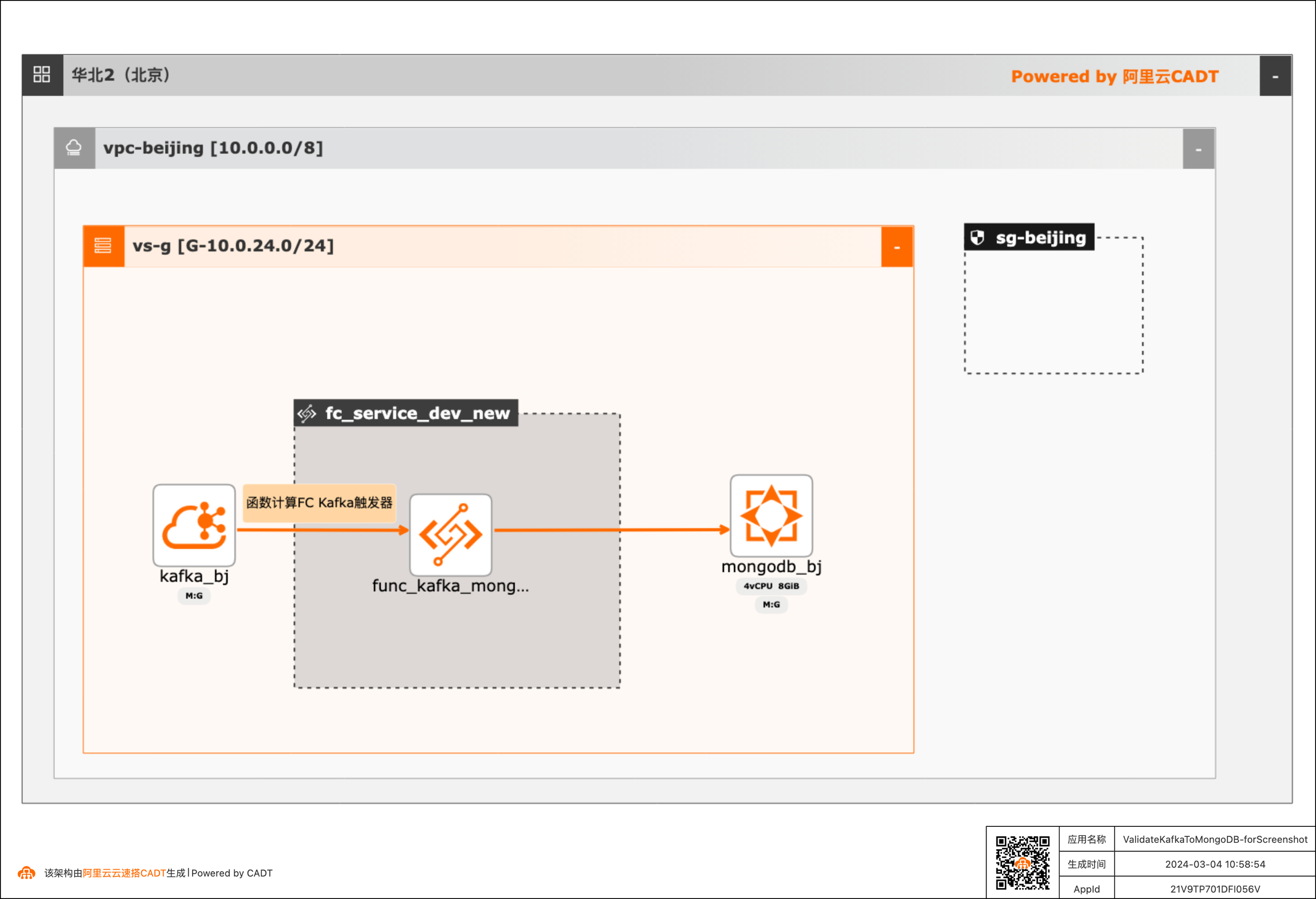
在大数据ETL场景,将Kafka中的消息流转到其他下游服务是很常见的场景,除了常规的消息流转外,很多场景还需要基于消息体内容做判断,然后决定下游服务做何种操作。 该方案实现了通过Kafka中消息Key的内容来判断应该对MongoDB做增、删、改的哪种DML操作。 当Kafka收到消息后,会自动触发函数计算中的函数,接收到消息,对消息内容做判断,然后再操作MongoDB。用户可以对提供的默认函数代码做修改,来满足更复杂的逻辑。 整体方案通过CADT可以一键拉起依赖的产品,并完成了大多数的配置,用户只需要到函数计算和MongoDB控制台做少量配置即可。
u 分区数:默认 12 个分区,通常建议分区数是 12 的倍数,减少数据倾斜风险。u 存储引擎:阿里云 Kafka 架构,有云存储和 Local 存储。(详细对比参见文档:https://help.aliyun.com/zh/apsaramq-for-kafka/cloud-message-queue-for- kafka/product-overview/comparison-between-storage-engines )u 消息类型:普通消息。...
- 产品推荐
- 这些文档可能帮助您