基于Flink+ClickHouse构建实时游戏数据分析
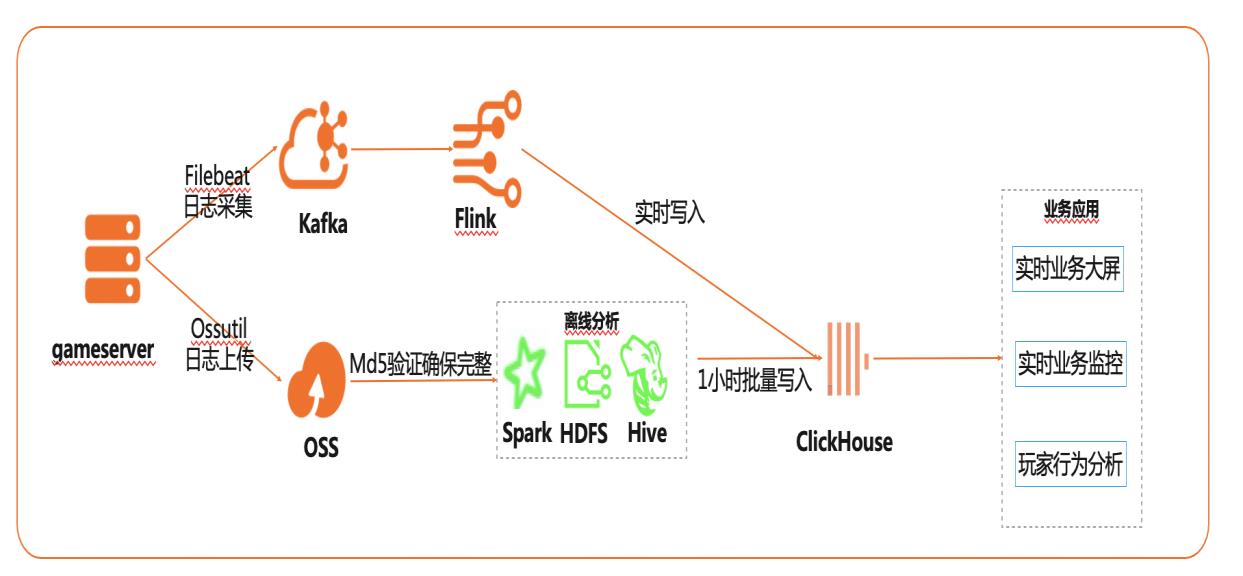
在互联网、游戏行业中,常常需要对用户行为日志进行分析,通过数据挖掘,来更好地支持业务运营,比如用户轨迹,热力图,登录行为分析,实时业务大屏等。当业务数据量达到千亿规模时,常常导致分析不实时,平均响应时间长达10分钟,影响业务的正常运营和发展。 本实践介绍如何快速收集海量用户行为数据,实现秒级响应的实时用户行为分析,并通过实时流计算Flink/Blink、云数据库ClickHouse等技术进行深入挖掘和分析,得到用户特征和画像,实现个性化系统推荐服务。 通过云数据库ClickHouse替换原有Presto数仓,对比开源Presto性能提升20倍。 利用云数据库ClickHouse极致分析性能,千亿级数据分析从10分钟缩短到30秒。 云数据库ClickHouse批量写入效率高,支持业务高峰每小时230亿的用户数据写入。 云数据库ClickHouse开箱即用,免运维,全球多Region部署,快速支持新游戏开服。 Flink+ClickHouse+QuickBI
结论:云数据库 ClickHouse更加适合海量数据分析型业务、大宽表聚合查询分析、数 据 Hash对齐 Join场景、实时日志分析场景等等 文档版本:20201224 6 基于 Flink+ClickHouse构建实时游戏数据分析 架构设计 2.架构设计 2.1.架构图 本实践主要以流处理为主线,搭建实验环境,构建在线用户行为分析平台:2.2.核心模块 游戏服...
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。
} }],"Version":"1"}互联网电商行业离线大数据分析 6.附录B-T表示table_properties,用于配置默认的Table的FileFormat/RowFormat,为map 数据类型,包含如下配置项(可以在odpscmd中执行helpexternalproject查看帮助信 息):1.storage_handler用于指定存储时storedby所使用的handler,如 org.apache.hadoop.hive.hbase....
Function Compute构建高弹性大数据采集系统
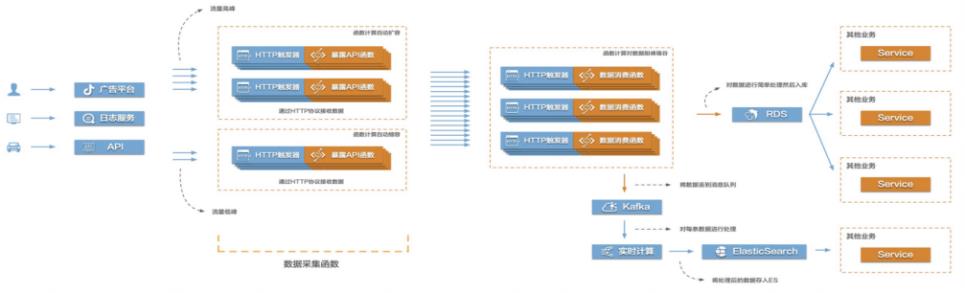
当前互联网很多场景都存在需要将大量的数据信息采集起来然后传输到后端的各类系统服务中,对数据进行处理、分析,形成业务闭环。比如游戏行业中的游戏发行、游戏运营,产互行业中的数字营销,物联网、车联网行业中的硬件、车辆信息上报等等。这些场景普遍存在数据采集量大、数据传输需要稳定且吞吐量大的特点,给整个数据采集传输系统带来很大的挑战。在这个场景中,有三个关键的环节,数据采集、数据传输、数据处理。该最佳实践主要涉
Function Compute构建高弹性大数据采集系统 最佳实践 业务架构 场景描述 当前互联网很多场景都存在需要将大量的数据 信息采集起来然后传输到后端的各类系统服务 中,对数据进行处理、分析,形成业务闭环。比 如游戏行业中的游戏发行、游戏运营,产互行业 中的数字营销,物联网、车联网行业中的硬件、车辆信息上报等等。这些...
EMR本地盘实例大规模数据集测试
场景描述 阿里云为了满足大数据场景下的存储需求,在云 上推出了本地盘D1机型,这个系列提供了本地 盘而非云盘作为存储,提高了磁盘的吞吐能力, 发挥Hadoop的就近计算优势。阿里云EMR 产品针对本地盘机型,推出了一整套的自动化运 维方案,帮助用户方便可靠地使用本地盘机型, 不需要关注整个运维过程同时数据的高可靠和 服务的高可用。 解决问题 1.云盘多份冗余数据导致成本高 2.磁盘吞吐量不高 3.节点的高可靠分布问题 4.本地盘与节点的故障监控问题 5.数据迁移时自动决策问题 6.自动故障节点迁移与数据平衡问题 产品列表 EMR(E-MapReduce) 本地盘 VPC
应用范围 需要使用阿里云 EMR+本地盘进行大数据业务前进行性能测试的用户 线下自建大数据集群用户需要迁移到阿里云云上 EMR+本地盘进行大数据分析性 能对比测试的用户 名词解释 VPC:Virtual Private Cloud,简称 VPC。基于阿里云创建的自定义私有网络,不 同的专有网络之间二层逻辑隔离,可以在自己创建的专有网络内创建和...
容器多云统一监控日志
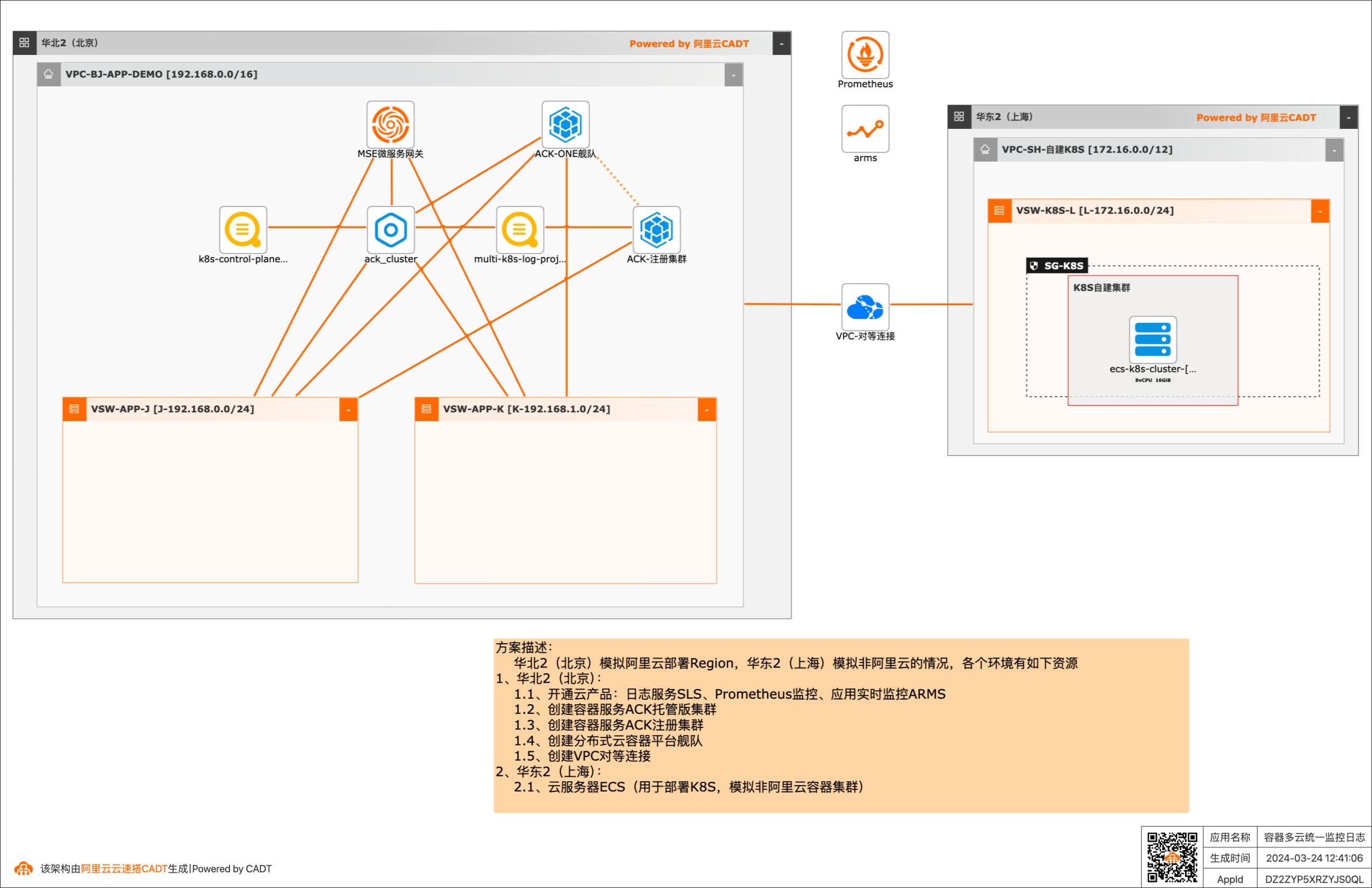
多云、混合云成为常态,Forrester 报告中指出,未来 89% 的企业至少使用两个云,74% 的企业至少使用三个甚至更多公有云,在面对多云/混合云这样大的趋势下,Gartner报告指出,安全、运维复杂性、财务复杂性是多云架构的主要挑战,本方案给出了在多云/混合云场景下,构建基于容器环境下的统一管理、统一监控和统一日志方案,解决多云、混合云场景下,运维复杂性问题。 应用场景 客户在阿里云以外的其他云服务商(AWS、Azure、GCP、TencentCloud、HuaweiCloud等)或者IDC基于容器(Kubernetes)运行业务系统,希望构建容器场景下的统一监控日志系统,方便做不同大屏和问题分析定位。 解决问题 •构建容器多云统一监控和日志系统,在一个平台可以看到不同环境系统的运行情况。
日志服务SLS:是云原生观测与分析平台,为Log、Metric、Trace等数据提供 大规模、低成本、实时的平台化服务,日志服务一站式提供数据采集、加工、查 询与分析、可视化、告警、消费与投递等功能,全面提升您在研发、运维、运营、安全等场景的数字化能力。文档版本:20240322 2容器多云统一监控日志 最佳实践概述 应用...
自建数据库迁移到云数据库
本方案介绍如何将网站的自建数据库迁移至云数据库 RDS,解决您随着业务增长可能会面临的数据库运维难题。数据库采用高可用架构,支持跨可用区容灾,给业务带来数据安全、可用性、性能和成本方面收益。方案提供了快速体验教程,模拟了数据库迁移所需的工作,帮助您快速上手。
产品解决方案文档与社区权益中心定价云市场合作伙伴支持与服务了解阿里云备案控制台方案导读背景RDS 解决的问题如何迁移到 RDS迁移前后对比优惠购买自建数据库迁移到云数据库本方案介绍如何将网站的自建数据库迁移至云数据库 RDS,解决您随着业务增长可能会面临的数据库运维难题。数据库采用高可用架构,支持跨可用区容灾,...
来自:
解决方案
基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步
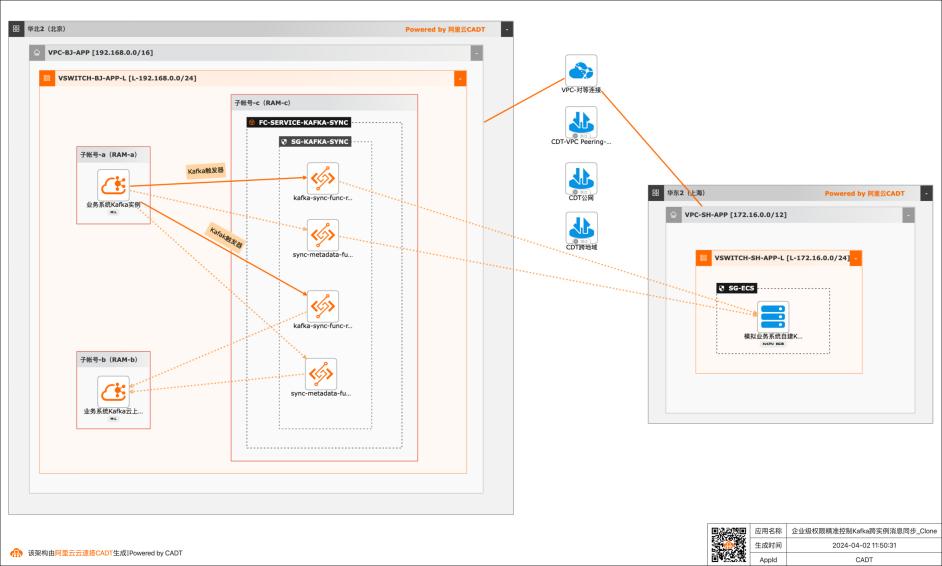
应用场景 在大数据场景,企业的Kafka实例可能存在多种情况,比如使用阿里云Kafka服务,可能是自建开源Kafka,或者是其他云上的云Kafka。不同的业务使用不同类型的Kafka实例,在这个前提下Kafka实例之间可能会需要消息同步的情况: 同帐号容灾场景:比如Kafka实例都是阿里云Kafka,但是Kafka实例会有主备之分,需要将主Kafka实例的消息实时同步到备Kafka。 跨帐号或异地容灾:这类场景比如主Kafka是阿里云Kafka,备Kafka是IDC开源自建Kafka,或者是其他云上的Kafka。 不同业务之间消息同步:因为现在的业务通常不会是信息孤岛,都需要消息互通,所以可能是A业务的Kafka实例消息需要同步到B业务的Kafka实例,并且这两个Kafka实例归属不同的RAM角色,有自己独自的权限控制。 解决问题 解决使用开源组件做消息同步的高成本问题。 解决使用开源组件做消息同步的并发性能、稳定性问题。 解决使用开源组件做消息同步的可靠性问题(重试机制,容错机制,死信队列等)。 大幅提升构建消息同步架构的效率,降低构建复杂度问题。
kafka-message-sync.py:同步消息的示例代码 metadata_cloud_kafka_to_idc_kafka.py:阿里云Kafka向自建IDCKafka同步元数 据的示例代码。 metadata_cloud_kafka_to_cloud_kafka.py:阿里云Kafka向阿里云Kafka同步元数 据的示例代码。以上三份Python代码在文档后续内容中会替换到函数计算的函数中。文档版本:...
容器场景下的应用性能监控、调用链拓扑、内存剖析
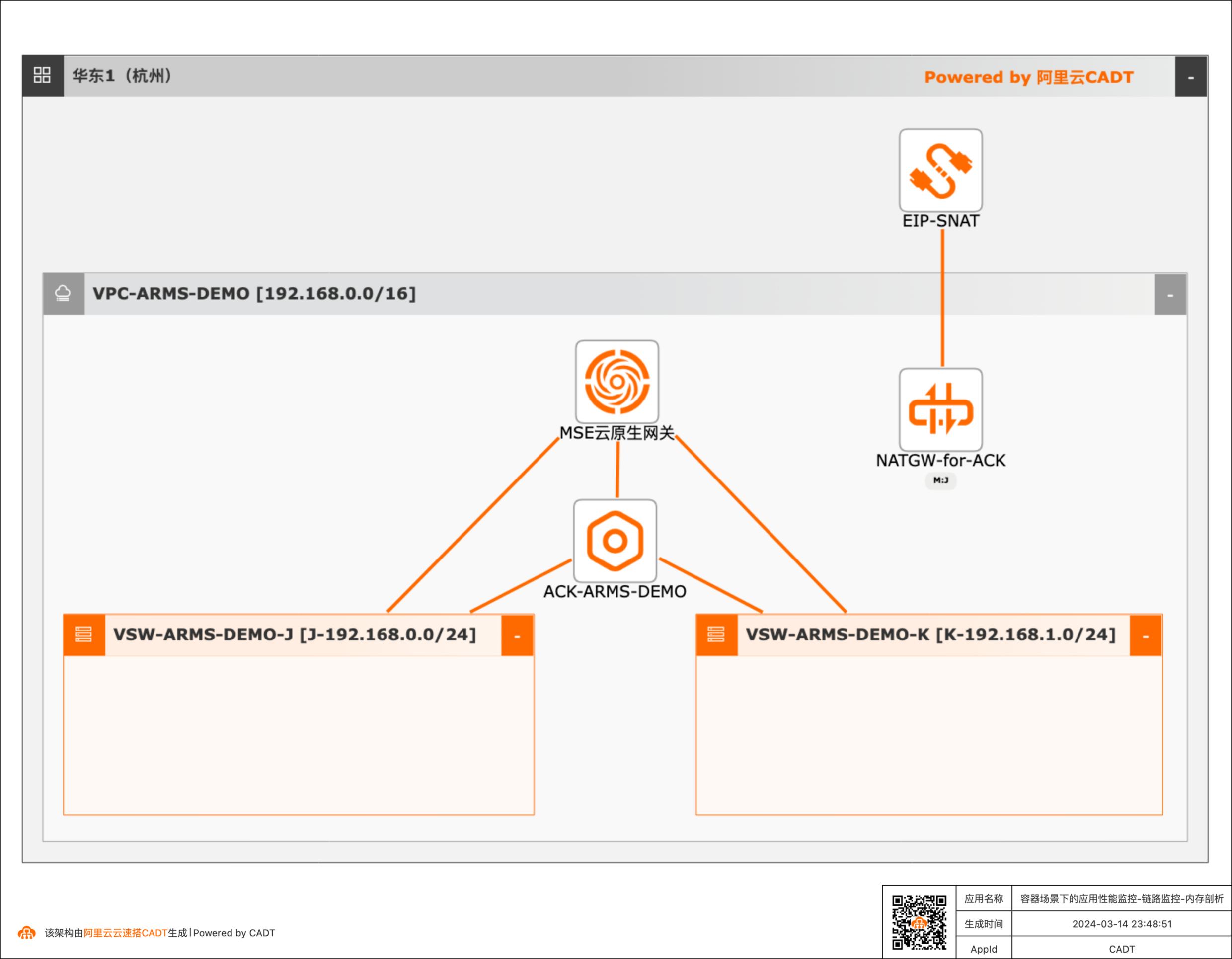
场景描述 随着云原生及微服务技术的普及,越来越多的系统已经通过云原生和微服务技术实现企业的降本增效,同时因微服务及云原生的复杂性给系统运维带来非常大的挑战,云原生应用监控arms通过全链路应用监控,从端到端及代码级别的链路下钻能力、CPU、内存持续剖析及诊断能力,帮助客户降低系统故障定位难度,此demo,您将体验arms的链路监控、内存剖析等能力 应用场景 微服务+容器场景下链路调用拓扑,调用链可以显示出服务之间的调用顺序和层次关系,帮助开发人员理解和追踪代码的执行流程 在分布式系统中,一个请求往往需要通过多个服务来完成。当出现问题时,如请求超时、错误或异常,很难快速定位问题所在。 解决问题 调用链可以帮助运维人员解决以下问题: · 故障排查:当请求失败或出现错误时,调用链可以显示整个请求的路径和每个服务的执行情况,从而帮助运维人员快速定位问题所在。 · 性能优化:通过调用链,运维人员可以了解请求在系统中的执行时间和瓶颈所在,从而进行优化。 · 系统监测:调用链可以提供实时的系统监测和分析,帮助运维人员了解系统的健康状况和资源利用情况。
容器场景下的应用性能监控、调用链拓扑、内存剖析 最佳实践 场景描述 业务架构 随着云原生及微服务技术的普及,越来越多的系 统已经通过云原生和微服务技术实现企业的降 本增效,同时因微服务及云原生的复杂性给系统 运维带来非常大的挑战,云原生应用监控arms 通过全链路应用监控,从端到端及代码级别的链 路下钻能力、CPU...
基于OSS Object FC实现非结构化文件实时处理最佳实践
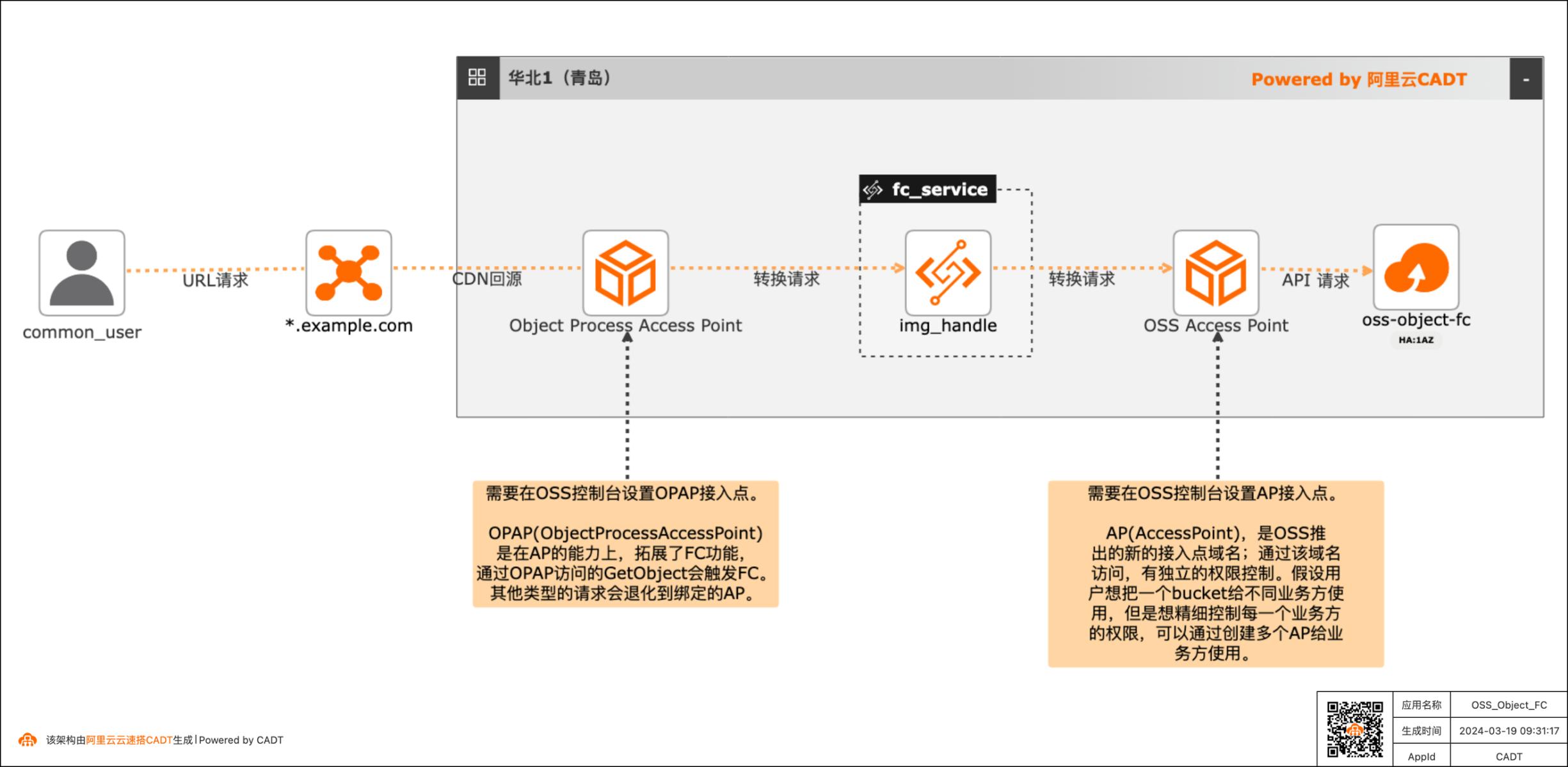
现在绝大多数客户都有很多非结构化的数据存在OSS中,以图片,视频,音频居多。举一个图片处理的场景,现在各种终端种类繁多,不同的终端对图片的格式、分辨率要求也不同,所以一张图片往往会有很多张衍生图,那如果所有的衍生图都存在OSS中,那存储的成本会增加,所以就可以通过OSS Object FC的方案,在不同的终端请求时,对OSS中的原图基于终端的要求做实时处理,然后响应返回,这样OSS中只需要存储原图即可。音视频也有类似的场景。
应用场景 现在绝大多数客户都有很多非结构化的数据存 在OSS中,以图片,视频,音频居多。举一个 产品列表 图片处理的场景,现在各种终端种类繁多,不同 专有网络VPC 的终端对图片的格式、分辨率要求也不同,所以 阿里云函数计算(FC)一张图片往往会有很多张衍生图,那如果所有的 阿里云对象存储(OSS)衍生图都存在...
MaxFrame
MaxFrame 是由阿里云自研的分布式计算框架,支持 Python 编程接口并可直接使用 MaxCompute 计算资源及数据接口,同时与 MaxCompute Notebook、镜像管理等功能共同构成了 MaxCompute 完整的 Python 开发生态。用户可以以更熟悉、高效的方式进行大规模数据处理、可视化数据分析及科学计算、ML/AI 开发等工作。
处理数据量大、处理逻辑复杂,需要基于 MaxCompute 海量数据及弹性计算资源及 MaxFrame 分布式能力进行大规模数据分析、处理及数据挖掘,提高开发效率.面向 Data+AI 开发,需要依赖第三方或自定义镜像完成数据开发、模型开发等整体流程.推荐搭配使用.海量数据处理、数据科学、机器学习、AI 开发.基于 MaxFrame 进行大规模...
来自:
云产品
基于函数计算FC实现阿里云Kafka消息内容控制MongoDB DML操作
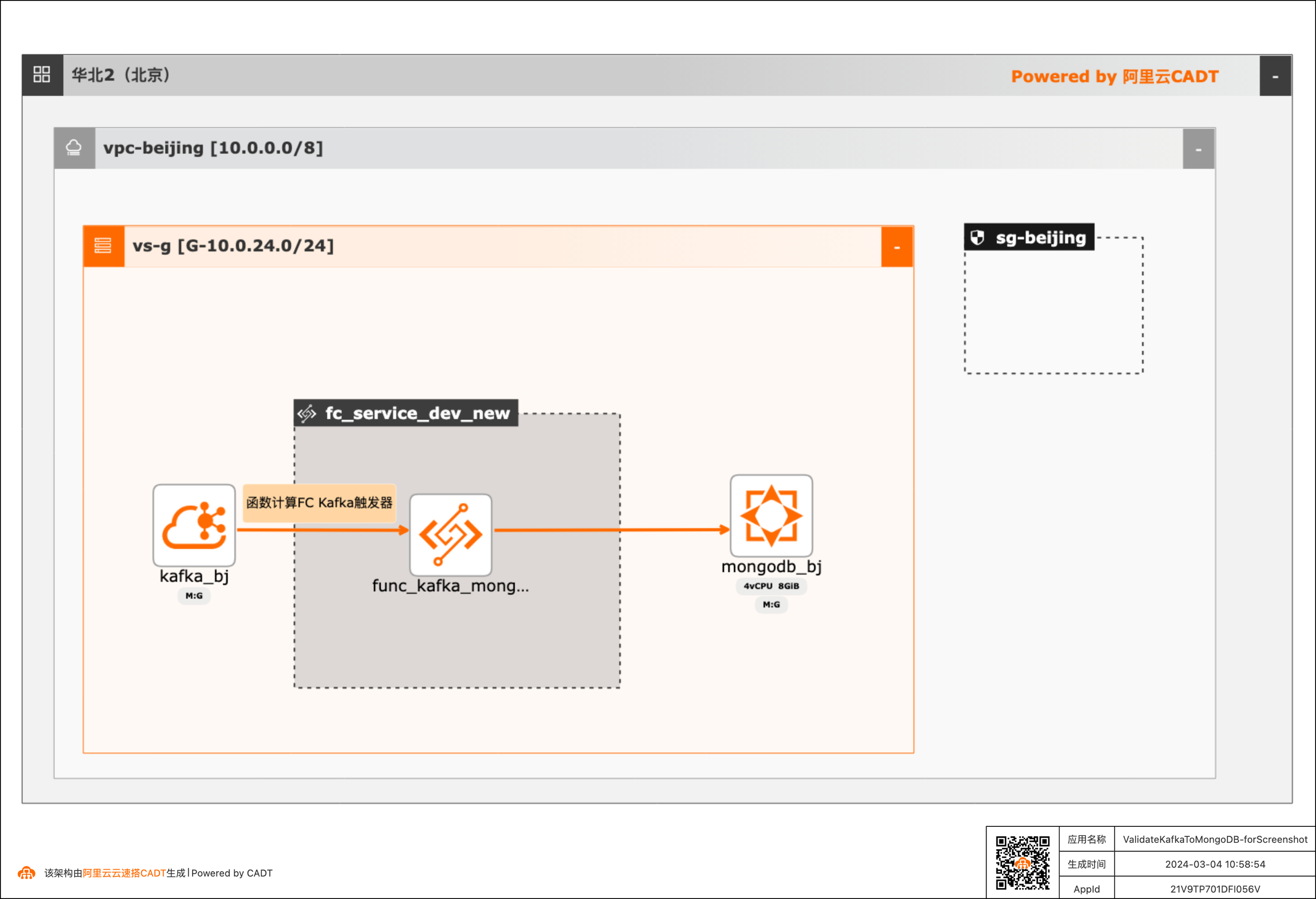
在大数据ETL场景,将Kafka中的消息流转到其他下游服务是很常见的场景,除了常规的消息流转外,很多场景还需要基于消息体内容做判断,然后决定下游服务做何种操作。 该方案实现了通过Kafka中消息Key的内容来判断应该对MongoDB做增、删、改的哪种DML操作。 当Kafka收到消息后,会自动触发函数计算中的函数,接收到消息,对消息内容做判断,然后再操作MongoDB。用户可以对提供的默认函数代码做修改,来满足更复杂的逻辑。 整体方案通过CADT可以一键拉起依赖的产品,并完成了大多数的配置,用户只需要到函数计算和MongoDB控制台做少量配置即可。
u 分区数:默认 12 个分区,通常建议分区数是 12 的倍数,减少数据倾斜风险。u 存储引擎:阿里云 Kafka 架构,有云存储和 Local 存储。(详细对比参见文档:https://help.aliyun.com/zh/apsaramq-for-kafka/cloud-message-queue-for- kafka/product-overview/comparison-between-storage-engines )u 消息类型:普通消息。...
基于SpringCloud应用玩转MSE实践
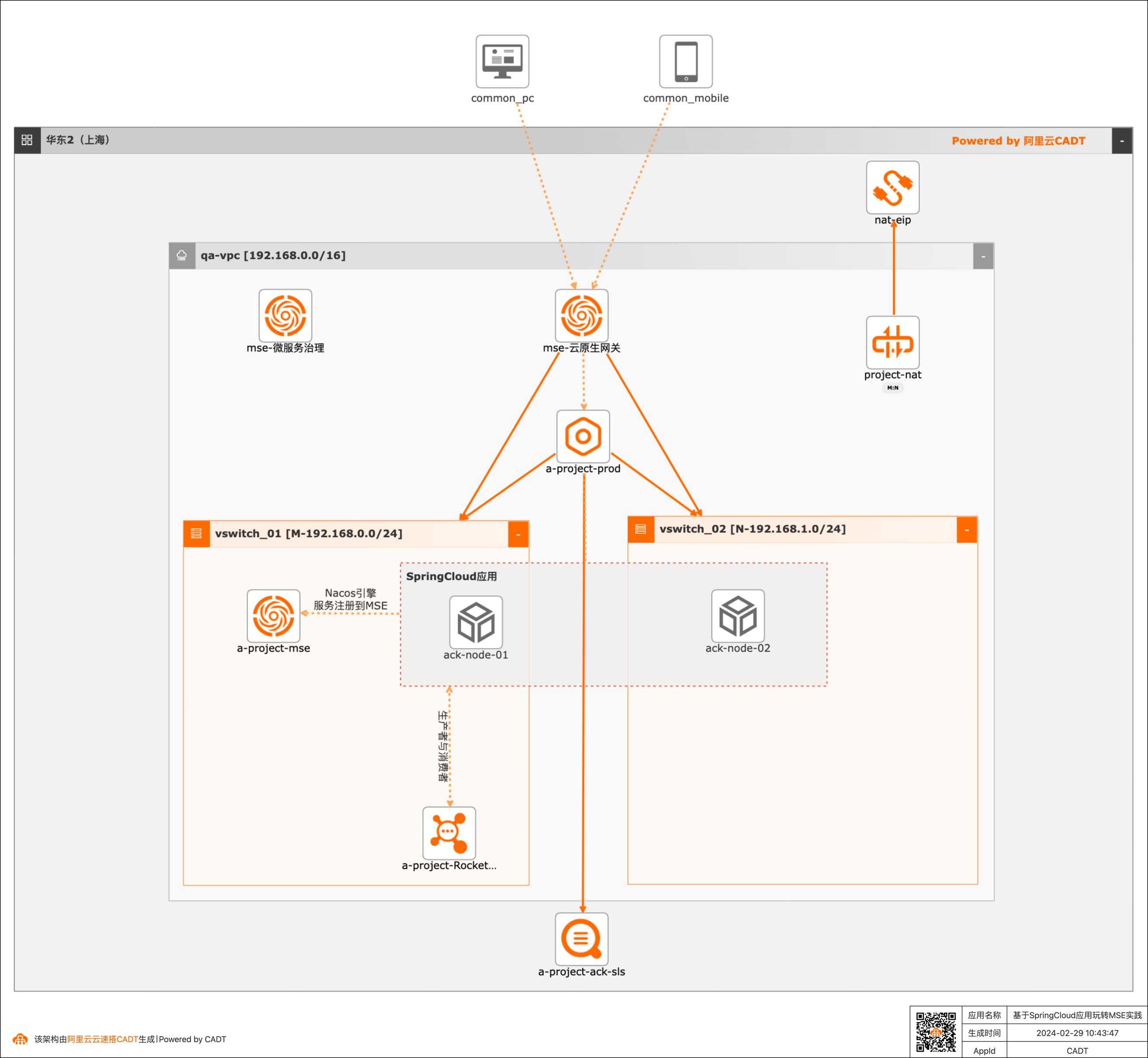
随着业务不断创新,大型的单个应用和服务会被拆分为数个甚至数十个微服务,微服务架构已经被广泛应用。 微服务的好处在于快速迭代,如何在迭代过程中保障线上流量不受损。依赖开源产品缺少无运维工具,常常需要投入较大的运维人力和成本。 本实践提供基于云原生应用产品提供微服务注册配置中心、微服务治理和云原生网关等一系列高性能和高可用的企业级云服务能力。
此次方案涉及到云产品费用12.47元/时(不含流量型产品,数据参考20240229官网 数据)步骤9 等待分钟级后,查看应用状态为“部署成功”部署时长与产品有关系,本次方案涉及到ACK等云产品,预计部署10分钟左右。文档版本:20240229基于SpringCloud应用玩转MSE 步骤10部署完成后,可查看部署报告,方便以后运维工作,如下图所...
云上数据集成解决方案
云上数据集成解决方案提供可跨异构数据存储系统、可靠、安全、低成本、可弹性扩展的数据传输交互服务,有效帮助您解 决云环境、个人站点环境下异构数据存储系统的数据互通难题,让您数据不再成为孤岛!助您实现大数据分析和实时商务智能。
助您实现大数据分析和实时商务智能.云上数据集成解决方案.支持MaxCompute、AnalyticDB for PostgreSQL和Hologres等大数据计算引擎及其他数据源.详细了解>.支持的数据源.查看如何配置数据集成的数据源.详细了解>.如何进行增量数据同步.详细了解>.数据增量同步.数据集成整库迁移介绍.详细了解>.数据集成提供一套抽象化的数据...
来自:
解决方案
云原生数据仓库AnalyticDB MySQL数据仓库
阿里云云原生数据仓库AnalyticDB MySQL版(简称AnalyticDB)是融合数据库、大数据技术于一体的云原生企业级数据仓库平台。云原生数据仓库AnalyticDB MySQL版支持数据实时写入和同步更新、实时计算和实时服务,可用于构建企业级报表系统、数据仓库和数据服务引擎。
一份数据同时支持离线处理和在线分析,解决数据一致性和时效性问题...边锋&AnalyticDB MySQL:打造一站式大数据分析平台.AnalyticDB MySQL带你学:基于Flink的高吞吐&精确一致性数据入湖.兰姆达 x AnayticDB 降本30%的数据湖最佳实践.一键实现穿衣自由|揭秘淘宝AI试衣间硬核技术:AnalyticDB向量在线召回.更多应用场景请查看.
来自:
云产品
- 产品推荐
- 这些文档可能帮助您