基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测实践 业务架构 ...lib,用于指定数据在进行序列化及反序列化时所使用的类名,如 org.apache.hive.hcatalog.data.JsonSerDe 6.serde_properties,当storage_handler被设置时,该属性将用于给storagehandler 指定相关属性;否则该属性将用于给serialization_lib指定相关属性。
大数据近实时数据投递MaxCompute
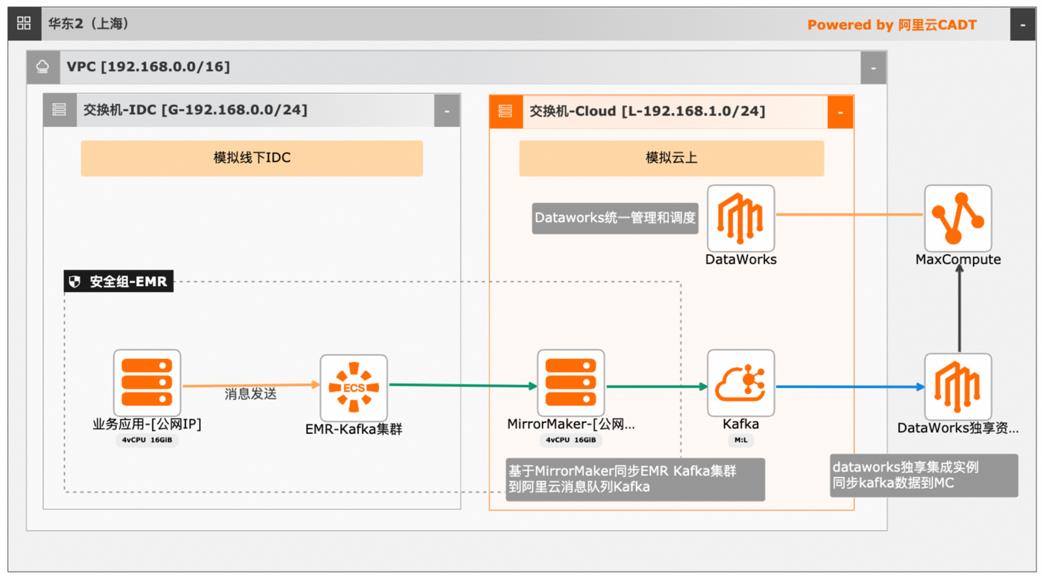
本文介绍离线大数据场景使MaxCompute构建云 上近实时数仓,打通云下数据上云链路,解决数据复杂类型支持和动态分区问题,满足高级数据处理需求的最佳实践。 l混合云环境下,现有业务系统零改造,打通数据上云链路。 l使用UDF实现复杂数据类型转换和数据动态分区。 l使用DataWorks配置周期调度业务流程,数据自动入仓。 l借助MaxCompute优化计算引擎,实现降本增效。 产品列表 云服务器ECS 专有网络VPC 访问控制RAM 数据总线DataHub E-MapReduceEMR DataWorks 大数据计算服务MaxCompute
在本实践中,使用 Java程序模拟输 出包含三种数据结构:map、list、struct的信息,并经过序列化后投递至 Kafka集 群。数据信息示例:为简化操作流程,本实践已经预打包好了数据信息发生及投递的程序包。下载数据信息发生及投递程序包。yum install-y git git clone ...
通过PAI-灵骏分布式训练和部署Llama 2模型
以 Meta 最新开源的大语言模型 Llama2 为例,通过PAI-灵骏完成了大语言模型的高效分布式训练、三阶段指令微调、模型离线推理验证以及在线服务部署等完整的开发链路。
LM引擎支持了数据并行、算子拆分、流水并行、序列并行、Flashattention等技术,保障模型效果且大幅提升大模型训练分布式效率相关产品智算服务 PAI-灵骏交互式建模 PAI-DSW机器学习 PAI-DLC模型在线服务 PAI-EAS对象存储 OSS文件存储 NAS在线咨询方案优势企业级应用基于软硬件一体优化技术,构建高性能异构算力底座,提供AI...
来自:
解决方案
云上成本优化workshop
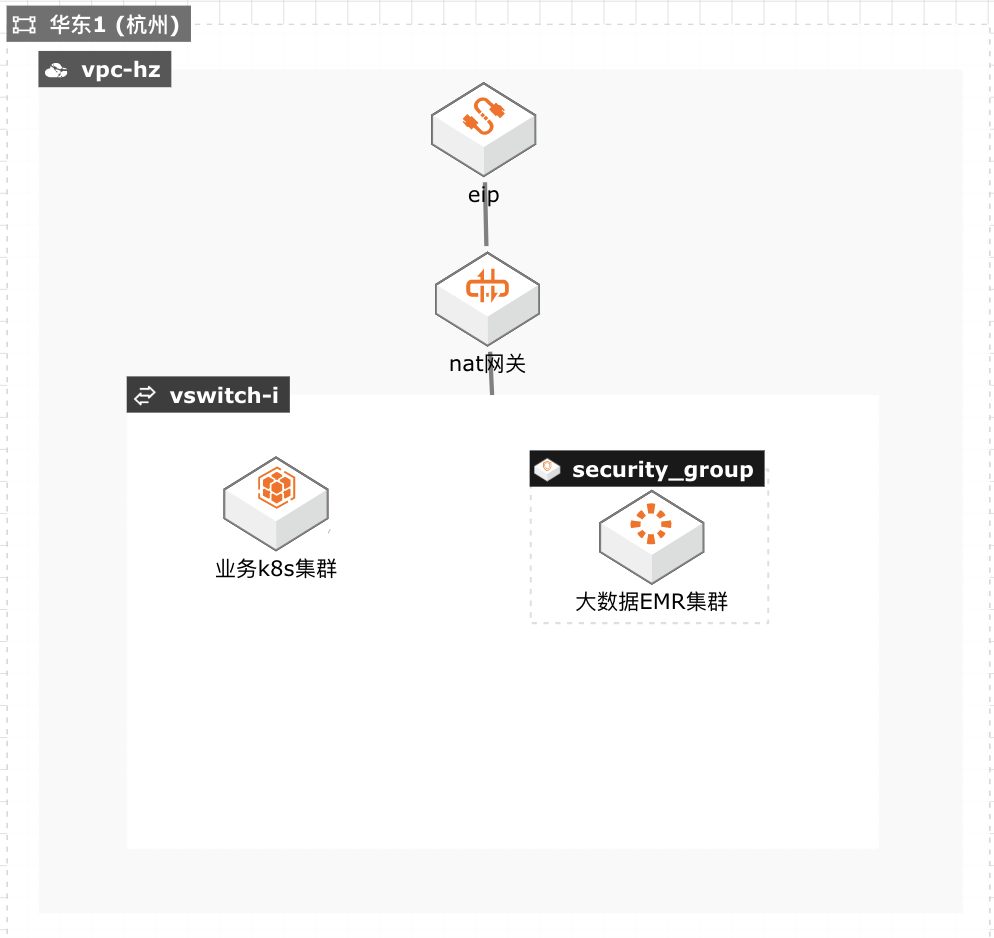
某金融科技公司,它主要提供信贷,理财,电商等 服务,目前已经拥有千万级注册用户。该公司在将 在线业务系统和大数据业务从自建 IDC 机房迁移 到阿里云后,今年大数据集群经历过多次因为资 源不足导致弹性扩容失败的故障,运维负责人非 常苦恼。由于该公司从事互联网金融的借贷业务, 白天的催收非常依赖晚上大数据计算的结果,若 因为资源不足导致计算结果失败则意味着白天催 收业务员无事可做,会对公司业务造成严重影响。 后来,通过阿里云解决方案架构师建议的方案,将 大数据集群迁移到资源较充足的可用区以及配置 弹性伸缩多规格 ECS 选型增加交付成功率等方 法,目前已阶段性的解决因资源不足导致弹性扩 容失败的问题,但该方案在 Spot 计算资源不足 时,启用大量按量收费算力,带来了较高的成本, 并且抢占式实例和按量付费实例都不保证资源 100%交付,还是存在交付失败的可能性,特别是 在双 11 期间由于其他客户的资源需求上升带来 的资源挤兑客观上存在,就进一步增加了弹性扩 容失败的风险,从而影响业务正常运行。
账单是一种时间序列的数据,而日志服务的主要功能就是对时间序列数据的采集、存储和分析,实现与账单数据的 无缝对接,减少了账单分析人员 80%的人力投入。注意:开通成本管家导入一般 3个小时之后可见。开通后的新增账单数据会在每天上 午 11点开始自动导入。步骤1 登录成本管家。...
来自:
最佳实践
相关产品:云服务器ECS,负载均衡 SLB,弹性公网IP,容器服务 ACK,日志服务(SLS),NAT网关,函数计算,E-MapReduce,云数据库PolarDB,弹性容器实例 ECI,存储容量单位包,预留实例券,Hologres
人工智能-自然语言处理-多语言分词
将连续的自然语言文本,切分成具有语义合理性和完整性的词汇序列,同时保持对数据、模型的不断迭代更新,目前支持简体中文、英文、泰文及越南语。
支持文本实体抽取、文本分类等NLP定制化算法能力,用户无需拥有丰富的算法背景,仅需标注或上传适量文档数据,即可通过平台快速创建算法模型并使用.NLP自学习平台.基于电商行业的大量语料研发,对消费者历史评价和新增评价的商品维度属性自动解析,将文本转化为结构化属性字段,高效甄别正负面评价,同时根据情感强烈程度...
来自:
云产品
阿里云时序时空数据库TSDB
时序时空数据库 ( Time Series and Spatial-Temporal Database , 简称 TSDB) 是一种集时序数据高效读写,压缩存储,实时计算能力为一体的数据库服务,可广泛应用于物联网和互联网领域,实现对设备及业务服务的实时监控,实时预测告警。
通过Kafka 订阅业务和机器指标数据,经过Flink 进行业务规则的实时计算,最终将原始指标数据和实时计算结果存储到TSDB,业务监控系统依赖TSDB 进行实时的任意维度时序聚合计算并进行可视化数据展现和告警.推荐搭配使用.TSDB 帮助我们解决了指标数据存储的问题,其表现出的优越性能,零运维成本,数据永久存储,专门的技术...
来自:
云产品
人工智能-自然语言处理-信息抽取
抽取文本中具有特定意义的实体,当前已支持合同领域的文本信息抽取。如需更多实体类型的定制化抽取,请使用NLP自学习平台。
支持文本实体抽取、文本分类等NLP定制化算法能力,用户无需拥有丰富的算法背景,仅需标注或上传适量文档数据,即可通过平台快速创建算法模型并使用.NLP自学习平台.基于电商行业的大量语料研发,对消费者历史评价和新增评价的商品维度属性自动解析,将文本转化为结构化属性字段,高效甄别正负面评价,同时根据情感强烈程度...
来自:
云产品
医学NLP
对医学领域文本内容进行分析,识别文本中的医学术语及属性。目前支持16种核心医学实体、6种医学属性的抽取。 医疗大数据是医疗前沿重要的发展方向,大数据与医疗结合,不仅会提升临床诊疗效果,还会对保险、药品研发等多个医疗健康领域产生深远影响。 但医疗大数据面临严重的质量问题,主要体现在数据统一性、完整度、准确性三个方面。因此,要想将大数据与医疗深度结合,底层数据和上层应用能力都必不可少。
更多产品与服务.NLP定制化算法能力,仅需标注或上传适量文档数据,即可快速创建算法模型并使用.NLP自学习平台.基于电商行业语料,对消费者评价自动解析将文本转化高效甄别正负面评价.商品评价解析.将连续的自然语言文本,切分成具有语义合理性和完整性的词汇序列.将文本中特定类型的事物名称或符号识别出来.更多产品与服务....
来自:
云产品
云数据库HBase
阿里云云数据库 HBase 版(ApsaraDB for HBase)是基于 Hadoop 且100%兼容HBase协议的高性能、可弹性伸缩、面向列的分布式数据库,轻松支持PB级大数据存储,满足千万级QPS高吞吐随机读写场景。
同时支持结构化和非结构化数据,毫秒级响应时延.HBase内置原生openTSDB,支持时序数据高效低成本处理,适合物联网、监控、金融K线等多个应用场景.内置原生openTSDB,使用体验100%兼容开源,基于HBase分布 式,可伸缩时间序列数据库.原生openTSDB,低成本浮点数据处理.存储计算分离,支持高性能并发写入,单节点数十万QPS.PB...
来自:
云产品
人工智能-自然语言处理-文本分类
按照给定类目体系对输入文本进行自动分类,当前已支持新闻资讯领域和电商领域的文本分类。如需更多类目体系的定制化,请使用NLP自学习平台。
将连续的自然语言文本,切分成具有语义合理性和完整性的词汇序列,同时保持对数据、模型的不断迭代更新,目前支持简体中文、英文及泰文.命名实体服务可以帮助您快速识别文本中的实体,进而挖掘各实体间的关系,目前主要针对电商领域,识别品牌、产品、型号等,同时也包括一些通用领域实体如人名、地名、机构名、时间日期等....
来自:
云产品
人工智能-自然语言处理-情感分析
又称倾向性分析,或意见挖掘,它是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。利用情感分析能力,可以针对带有主观描述的自然语言文本,自动判断该文本的情感正负倾向并给出相应的结果。支持英语,泰语,越南语,印尼语。
将连续的自然语言文本,切分成具有语义合理性和完整性的词汇序列,同时保持对数据、模型的不断迭代更新,目前支持简体中文、英文及泰文.命名实体服务可以帮助您快速识别文本中的实体,进而挖掘各实体间的关系,目前主要针对电商领域,识别品牌、产品、型号等,同时也包括一些通用领域实体如人名、地名、机构名、时间日期等....
来自:
云产品
人工智能-自然语言处理-词性标注
通过词性标注服务,用户可以快速的为每一个词附上对应的词性,结合分词服务,可以快速进行更深层次的文本挖掘处理,无需担心新词发现、歧义消除等问题。
将连续的自然语言文本,切分成具有语义合理性和完整性的词汇序列,同时保持对数据、模型的不断迭代更新,目前支持简体中文、英文及泰文.命名实体服务可以帮助您快速识别文本中的实体,进而挖掘各实体间的关系,目前主要针对电商领域,识别品牌、产品、型号等,同时也包括一些通用领域实体如人名、地名、机构名、时间日期等....
来自:
云产品
人工智能-自然语言处理-中心词识别
多语言中心词(目前支持中文及英文)基于海量数据,使用电商标题中心词以及类目进行训练,通过给每个词计算一个相关性分数来衡量每个词与句子的相关性程度,进而识别并提取出句子的中心词。适用于提取电商搜索query、标题及其他类似短文本(一般小于25个词)的中心词。
将连续的自然语言文本,切分成具有语义合理性和完整性的词汇序列,同时保持对数据、模型的不断迭代更新,目前支持简体中文、英文及泰文.命名实体服务可以帮助您快速识别文本中的实体,进而挖掘各实体间的关系,目前主要针对电商领域,识别品牌、产品、型号等,同时也包括一些通用领域实体如人名、地名、机构名、时间日期等....
来自:
云产品
人工智能-自然语言处理-命名实体
我们为您提供的命名实体服务,可以帮助您快速识别文本中的实体,进而挖掘各实体间的关系,是进行深度文本挖掘,知识库构建等常用自然语言处理领域里的必备工具。目前主要针对电商领域,识别品牌、产品、型号等,同时也包括一些通用领域实体如人名、地名、机构名、时间日期等。
将连续的自然语言文本,切分成具有语义合理性和完整性的词汇序列,同时保持对数据、模型的不断迭代更新,目前支持简体中文、英文及泰文.又称倾向性分析,或意见挖掘,它是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。利用情感分析能力,可以针对带有主观描述的自然语言文本,自动判断该文本的情感正负...
来自:
云产品
基于弹性计算的AI推理
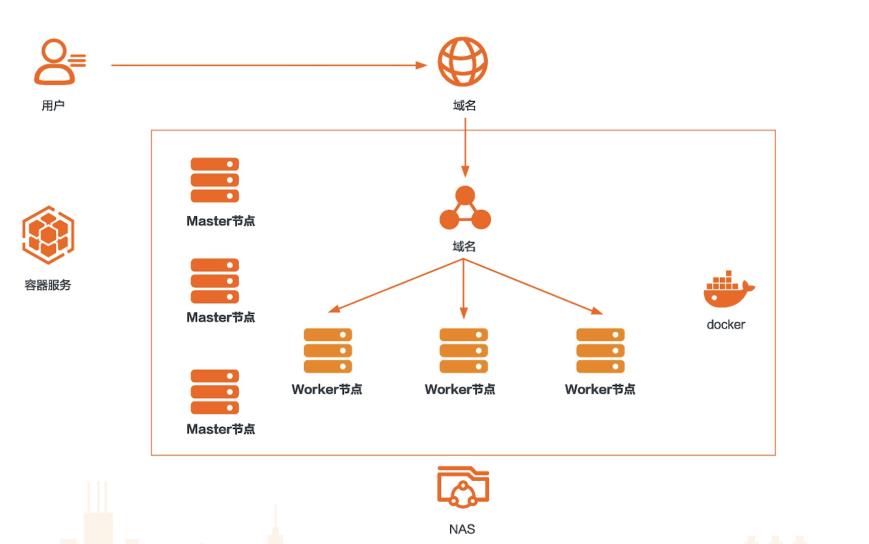
场景描述 本方案适用于使用GPU进行AI在线推理的场 景。在推理之前,模型已经训练完成。例如,刷脸 支付中,我们在刷脸的时候,就是推理的一个过 程。再比如图像分类,目标检测,语音识别,语 义分析等返回结果的过程。 解决问题 使用GPU云服务器搭建推理环境 使用容器服务Kubernetes版构建推理 环境 使用NAS存储模型数据 使用飞天AI加速推理工具加速推理 产品列表 GPU云服务器 容器服务Kubernetes版 NAS共享存储
ᅳ.meta文件是 MetaGraphDef序列化的二进制文件,保存了网络结构相关的数 据,包括 graph_def和 saver_def等。ᅳ.index文件为数据文件提供索引,存储的核心内容是以 tensor name为键以 BundleEntry为值的表格 entries,BundleEntry主要内容是权值的类型、形状、偏移、校验和等信息。ᅳ.data文件保存所有变量的值,即网络...
超级计算集群实现自然语言处理训练
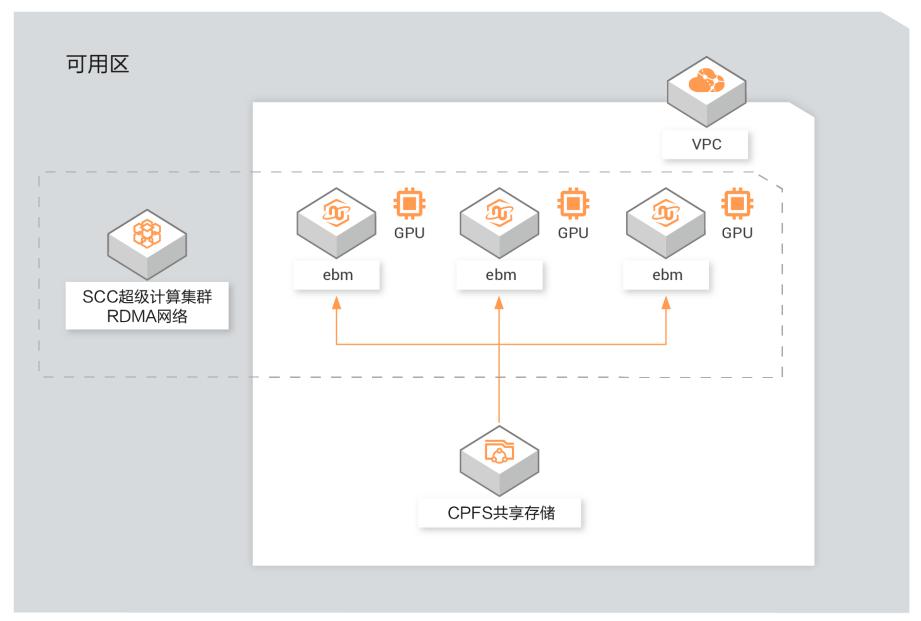
场景描述 本方案适用于自然语言训练场景,使用神龙 GPU云服务器(SCCGN6)+CPFS进行NLP的 训练,采用Bert模型。这里不使用容器,直接 使用裸机进行NLP的Bert训练,使用飞天AI加 速训练工具可以有效提升多机多卡的训练效率。 解决问题 使用神龙GPU云服务器搭建NLP训练环 境 使用SCC的RDMA网络 使用CPFS存储训练数据 使用飞天AI加速训练工具加速训练 产品列表 神龙GPU云服务器(SCCGN6) SCC超级计算集群 CPFS共享存储
–.meta文件是MetaGraphDef序列化的二进制文件,保存了网络结构相关的数 据,包括graph_def和saver_def等;–.index文件为数据文件提供索引,存储的核心内容是以tensorname为键以 BundleEntry为值的表格entries,BundleEntry主要内容是权值的类型、形状、偏移、校验和等信息。–.data文件保存所有变量的值,即网络权值。 ...
- 产品推荐
- 这些文档可能帮助您