- 相关产品:
- 知位-停车空间数字化解决方案 在家学解决方案 电子招投标平台解决方案
通过PAI-灵骏分布式训练和部署Llama 2模型
灵骏支持业界各类流行的开源大语言模型,包括Llama2系列、Bloom系列、Falcon系列、GLM/ChatGLM系列,以及领域大模型galactica等的高效训练和部署。本方案整体可用于企业样本标注、创意文本生成、智能对话助手、文本类创作辅助等场景。
智能方案推荐 定制化的模型拥有分析学习能力,结合实际需求,辅助给出个性化且高度定制化的方案推荐。游戏场景NPC对话 通过Llama2构建的游戏NPC对话模型,相较于固有模式,丰富度显著提升,对话更加自然。智能家居助手 智能家居助手有效提升住户的生活舒适度和满意度。实现智能场景触发和自动化控制。优惠购买 阿里云为你...
来自:
技术解决方案
Databricks数据洞察
阿里云Databricks数据洞察是基于Apache Spark的全托管数据分析平台, 内核采用更高效、稳定的商业版Databricks Runtime和Delta Lake。可满足数据分析师、数据工程师和数据科学家在大数据场景下对数据湖分析、实时数仓、离线数仓、BI数据分析、AI机器学习等需求
Databricks 数据洞察.Databricks数据洞察是基于Apache Spark的全托管数据分析平台,内核采用更高效稳定的商业版Databricks Runtime和Delta Lake,满足用户对数据湖分析、实时数仓、离线数仓、BI数据分析、AI机器学习等场景需求。因产品服务策略调整,本产品将于2023年10月23日停止全面支持,并将于2024年4月23日停止服务....
来自:
云产品
大数据近实时数据投递MaxCompute
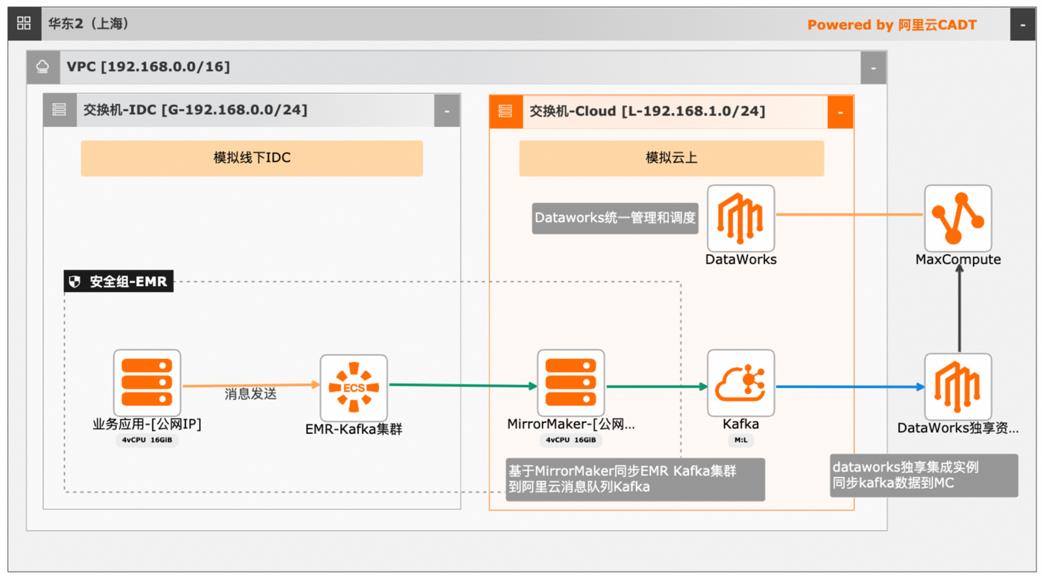
本文介绍离线大数据场景使MaxCompute构建云 上近实时数仓,打通云下数据上云链路,解决数据复杂类型支持和动态分区问题,满足高级数据处理需求的最佳实践。 l混合云环境下,现有业务系统零改造,打通数据上云链路。 l使用UDF实现复杂数据类型转换和数据动态分区。 l使用DataWorks配置周期调度业务流程,数据自动入仓。 l借助MaxCompute优化计算引擎,实现降本增效。 产品列表 云服务器ECS 专有网络VPC 访问控制RAM 数据总线DataHub E-MapReduceEMR DataWorks 大数据计算服务MaxCompute
MaxCompute已与数据集成、DataWorks、QuickBI、机器学习 PAI、ADB、推荐引擎、移动数据分析等大数据产 品打通,可快速集成使用,轻松应对各种大数据应用场景。本文以线下现有业务大数据离线数仓建设为背景,介绍如何在现有业务应用系统零 改造的前提下,从 Kafka集群切入,打通数据上云链路,解决数据复杂类型支持和 动态...
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 业务架构 场景描述 客户在 IDC或者公有云环境自建 Hadoop集群 构建数据仓库和分析系统,购买阿里云 Databricks数据洞察集群之后,涉及到数仓数 据和元数据的迁移以及 Hive版本的订正更新。方案优势 1.全托管 Spark集群免运维,节省人力成 本。2.Databricks数据洞察...
基于函数计算FC实现阿里云Kafka消息轻量级ETL处理
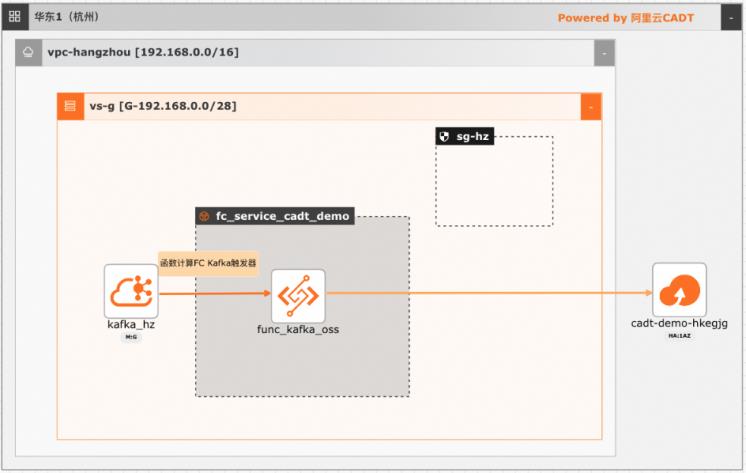
在大数据ETL场景,Kafka是数据的流转中心,Kafka中的数据一般是原始数据,可能存在多种数据混杂的情况,需要进一步做数据清洗后才能进行下一步的处理或者保存。利用函数计算FC,可以快速高效的搭建数据处理链路,用户只需要关注数据处理的逻辑,数据的触发,弹性伸缩,运维监控等阿里云函数计算都已经做了集成,函数计算FC也支持多种下游,OSS/数据库/消息队列/ES等都可以自定义的对接
对象存储 OSS:对象存储 OSS 是一款具有行业领先的安全、稳定、高性价比、高性能的 云存储服务,可以帮助各行业的客户在互联网应用、大数据分析、机器学习、数据归档等 各种使用场景存储任意数量的数据,以及进行任意位置的访问,同时通过丰富的数据处理 能力更便捷地使用数据。云速搭 CADT(Cloud Architect Design Tools...
数据安全中心
敏感数据保护(Sensitive Data Discovery and Protection),在满足等保v2.0“安全审计”、等保v3.0及“个人信息保护”的合规要求的基础上,为客户提供敏感数据识别、分级分类、数据安全审计、数据脱敏、智能异常检测等数据安全能力,形成一体化的数据安全解决方案。
无需安装agent,运用大数据和机器学习能力,对敏感数据和高风险活动进行有效识别和监控,并提供修复方案。同时也提供多种数据脱敏算法,有效防止数据泄漏.重点解决的数据安全问题.构建各生命周期的敏感识别能力.全量审计数据库、OSS等大数据.针对敏感数据提供脱敏能力.找“内鬼”,控异常权限使用.敏感数据发现与分类分级....
来自:
云产品
数据管理与服务
数据管理与服务作为阿里云产品六大版块之一,面向不同业务场景,阿里云提供数据存储、分析、应用等全链路能力,满足企业客户全方位的数据处理需求,实现计算和存储分离、资源解耦、数据移动减化,用以满足行业快速发展的需求和趋势,利用数据重塑其业务。
波克科技股份有限公司通过引入阿里云云原生实时数据仓库AnalyticDB,实现了每日百亿级游戏玩家行为数据的快速分析和处理,大幅降低数据分析成本,相比原有方案,数据处理性能提升10倍以上.网络安全升级支持IPV6.云原生数据仓库 AnalyticDB MySQL版.通过引入Hologres搭建的实时数仓,支撑了百亿级的业务数据复杂多维分析秒级...
来自:
云产品
数据可视化DataV
数据可视化DataV是阿里云一款数据可视化应用搭建工具,旨让更多的人看到数据可视化的魅力,帮助非专业的工程师通过图形化的界面轻松搭建专业水准的可视化应用,满足您会议展览、业务监控、风险预警、地理信息分析等多种业务的展示需求。
依托云原生时空数据引擎Ganos,数亿条空间数据查询计算也可秒级处理应用场景业务监控看板 数据分析报告 数字孪生城市 工业数字孪生 时空数据分析 跨系统数据一屏统管 DataV在业务数据可视化领域,通过丰富的可视化组件、低代码蓝图系统、AI设计辅助、多种数据源接入的能力,帮助业务开发人员能够快速完成自己业务看板的搭建...
来自:
云产品
数据迁移上云
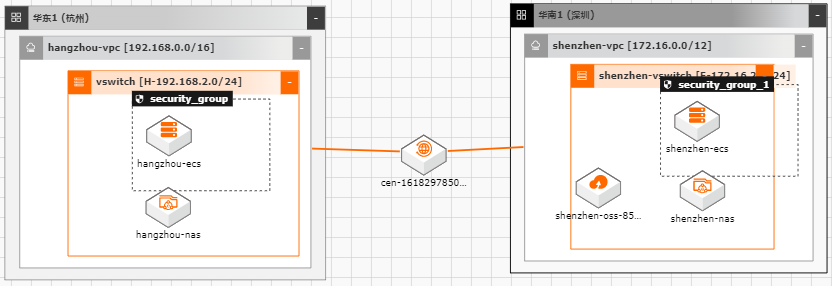
随着越来越多的企业选择将业务系统上云,各种类型的数据如何便捷、平滑的迁移上 云,成了用户上云较为关注的点;业务上云后,因为业务或者其他方面调整等因素, 也存在如跨区域,跨账号等数据迁移的场景。针对以上需求,阿里云上提供了较为丰 富的工具(如ossimport)、服务(在线迁移服务),旨在能够帮助客户便捷进行数据迁 移。 本文通过云架构设计工具CADT来快速创建云上基础资源,并以杭州区域来模拟线 下IDC(或友商),深圳区域模拟阿里云云上资源。通过云上的工具命令、服务来提 供常见数据迁移场景的最佳实践。
广泛应用于容器存储、大数据分析、Web 服务和内容管 理、应用程序开发和测试、媒体和娱乐工作流程、数据库备份。支持冷热数据分级 存储。详见:https://www.aliyun.com/product/nas 云服务器 ECS:云服务器 ECS(Elastic Compute Service)是一种弹性可伸缩的 计算服务,助您降低 IT 成本,提升运维效率,使您更专注于核心...
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
功能强大:支持 SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据 源计算等 Data Lake相关功能,以及各种流式及静态数据源关联查询。安全:原生的多租户系统,以项目进行隔离,所有计算任务在安全沙箱中运行。文档版本:20201020 2 基于 Dataworks的大数据一站式开发及数据治理 前置条件 前置条件 在进行本文操作...
EMR本地盘实例大规模数据集测试
场景描述 阿里云为了满足大数据场景下的存储需求,在云 上推出了本地盘D1机型,这个系列提供了本地 盘而非云盘作为存储,提高了磁盘的吞吐能力, 发挥Hadoop的就近计算优势。阿里云EMR 产品针对本地盘机型,推出了一整套的自动化运 维方案,帮助用户方便可靠地使用本地盘机型, 不需要关注整个运维过程同时数据的高可靠和 服务的高可用。 解决问题 1.云盘多份冗余数据导致成本高 2.磁盘吞吐量不高 3.节点的高可靠分布问题 4.本地盘与节点的故障监控问题 5.数据迁移时自动决策问题 6.自动故障节点迁移与数据平衡问题 产品列表 EMR(E-MapReduce) 本地盘 VPC
应用范围 需要使用阿里云 EMR+本地盘进行大数据业务前进行性能测试的用户 线下自建大数据集群用户需要迁移到阿里云云上 EMR+本地盘进行大数据分析性 能对比测试的用户 名词解释 VPC:Virtual Private Cloud,简称 VPC。基于阿里云创建的自定义私有网络,不 同的专有网络之间二层逻辑隔离,可以在自己创建的专有网络内创建和...
基于函数计算FC实现大语言模型部署

在现代AI应用中, Qwen /chatglm2-6b 和Stable Diffusion等模型因其强大的功能而受到关注。然而,这些模型对计算资源的高需求和复杂的运维管理成为部署时的挑战。基于函数计算FC的无服务器计算模式为这类模型的部署提供了全新的解决方案。用户只需关注模型的部署和调用逻辑,而无需关心底层的服务器配置、资源分配和扩展性等问题。函数计算FC能够自动处理函数的执行环境,包括冷启动、弹性伸缩等,确保模型能够在大规模的请求下稳定运行。
应用场景 在文本理解与创作、智能客服、情感分析等领域,Qwen/chatglm2-6b等模型的部署至关重要。这些场景 通常需要处理大量的数据,并实时生成准确的响应。通过将 Qwen/chatglm2-6b等部署在函数计算 FC 上,提供了高效、弹性、低成本的部署解决方案。解决问题•简化模型部署流程•全链路自适应弹性,无需为流量峰谷做频繁...
- 产品推荐
- 这些文档可能帮助您