基于Flink+ClickHouse构建实时游戏数据分析
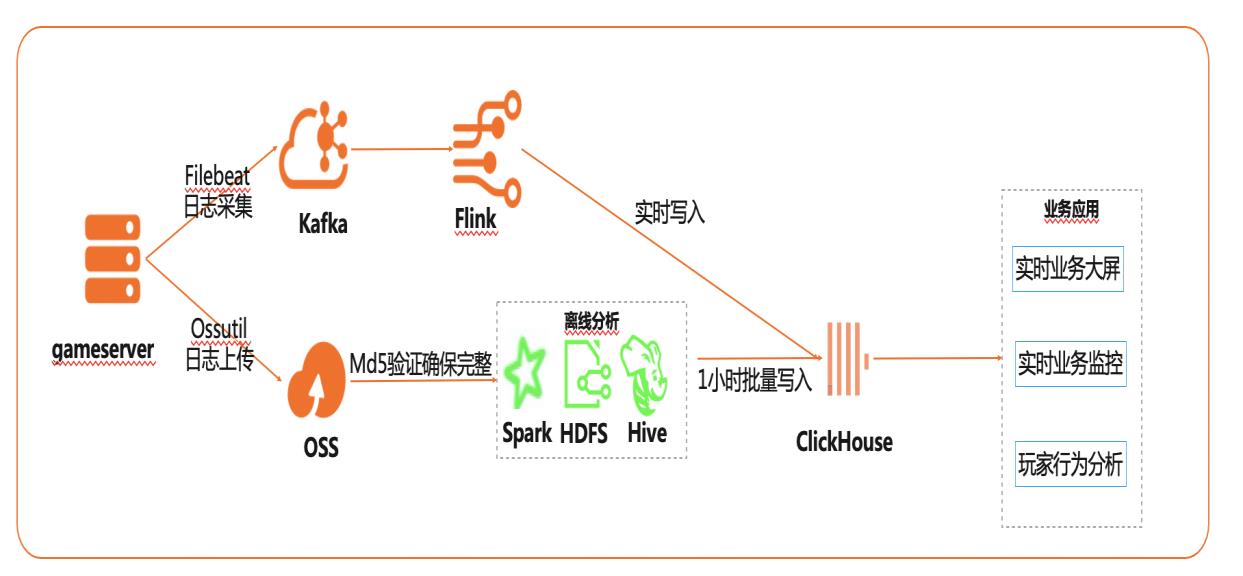
在互联网、游戏行业中,常常需要对用户行为日志进行分析,通过数据挖掘,来更好地支持业务运营,比如用户轨迹,热力图,登录行为分析,实时业务大屏等。当业务数据量达到千亿规模时,常常导致分析不实时,平均响应时间长达10分钟,影响业务的正常运营和发展。 本实践介绍如何快速收集海量用户行为数据,实现秒级响应的实时用户行为分析,并通过实时流计算Flink/Blink、云数据库ClickHouse等技术进行深入挖掘和分析,得到用户特征和画像,实现个性化系统推荐服务。 通过云数据库ClickHouse替换原有Presto数仓,对比开源Presto性能提升20倍。 利用云数据库ClickHouse极致分析性能,千亿级数据分析从10分钟缩短到30秒。 云数据库ClickHouse批量写入效率高,支持业务高峰每小时230亿的用户数据写入。 云数据库ClickHouse开箱即用,免运维,全球多Region部署,快速支持新游戏开服。 Flink+ClickHouse+QuickBI
4.数据生态:打通云上各个数据源,方便数据同步和迁移。数据可视化(QuickBI):是一个专为云上用户量身打造的新一代智能 BI服务平台。它可以提供海量数据实时在线分析服务,支持拖拽式操作和丰富的可视化效果,帮助您轻松自如地完成数据分析、业务数据探查、报表制作等工作。文档版本:20201224 8 基于 Flink+ClickHouse...
E-MapReduce Serverless StarRocks 版
E-MapReduce Serverless StarRocks版简称EMR StarRocks,是阿里云提供的全托管服务,内核100%兼容StarRocks,性能比传统OLAP引擎提升3-10倍,助力企业高效构建湖仓分析、高并发查询及实时分析等大数据应用。
统一湖仓架构对接多种数据生态,支持联邦查询,可作为数据湖引擎的加速器,提供统一查询服务.极速统一 OLAP 分析.开箱即用,分钟级交付实例。根据客户业务特点提供丰富的存储能力选择,包括云盘、本地盘、对象存储。提供企业级 SLA 保障,极大降低了集群运维的复杂度.轻松易用的管控能力.灵活易用的实例扩缩容、升降配、...
来自:
云产品
云原生多模数据库Lindorm
云原生多模数据库Lindorm提供各规模、多模型的云原生数据库服务。可兼容HBase/Cassandra、OpenTSDB、Solr、SQL、HDFS等多种开源标准接口。支持海量数据的低成本存储处理和弹性按需付费,是互联网、IoT、车联网、广告、社交等场景首选数据库,也是为阿里核心业务提供支撑的数据库之一。
数据生态融合.面向海量KV、表格数据,具备全局二级索引、多维检索、动态列、TTL等能力,适用于元数据、订单、账单、画像、社交、feed流、日志等场景,兼容HBase、Phoenix(SQL)、Cassandra等开源标准接口.面向IoT、监控等场景存储和处理量测数据、设备运行数据等时序数据。提供HTTP API接口(兼容OpenTSDB API)、支持SQL查询...
来自:
云产品
云原生大数据计算服务MaxCompute
阿里云云原生大数据计算服务MaxCompute是面向分析的企业级云数仓,作为一体化大数据智能计算平台ODPS的大规模批量计算引擎,MaxCompute以 Serverless 架构提供快速、全托管的在线数据仓库服务,使您经济高效的分析处理海量数据,进行敏捷的业务洞察。
支持开放数据生态,以统一平台满足数据仓库、BI、近实时分析、数据湖分析、机器学习等多种场景需要.支持多种分析场景.支持开放接口和生态,为数据、应用迁移、二次开发提供灵活性;支持与AirFlow、Tableau等开源和商业产品灵活组合,构建丰富的数据应用.全托管的 Serverless 在线服务.对外以API方式访问的在线服务,开箱即...
来自:
云产品
云数据库MongoDB版
阿里云云数据库MongoDB版是完全兼容MongoDB协议、高度兼容DynamoDB协议的在线文档型数据库服务。支持单节点、双节点、副本集和分片集群四种部署架构,能够满足不同的业务场景需要。
数据生态:数据自由流转,应用更灵活.提供CPU利用率、IOPS、连接数、磁盘空间等实例信息实时监控及报警,随时随地了解实例动态.可视化管理平台.管理控制平台对实例重启、备份、数据恢复等高频高危操作可进行便捷地一键式操作.可视化DMS平台.专业的DMS数据管理平台,提供可视化的MongoDB数据管理,图形化轻松管理数据库...
来自:
云产品
SLS数据入湖Kafka最佳实践
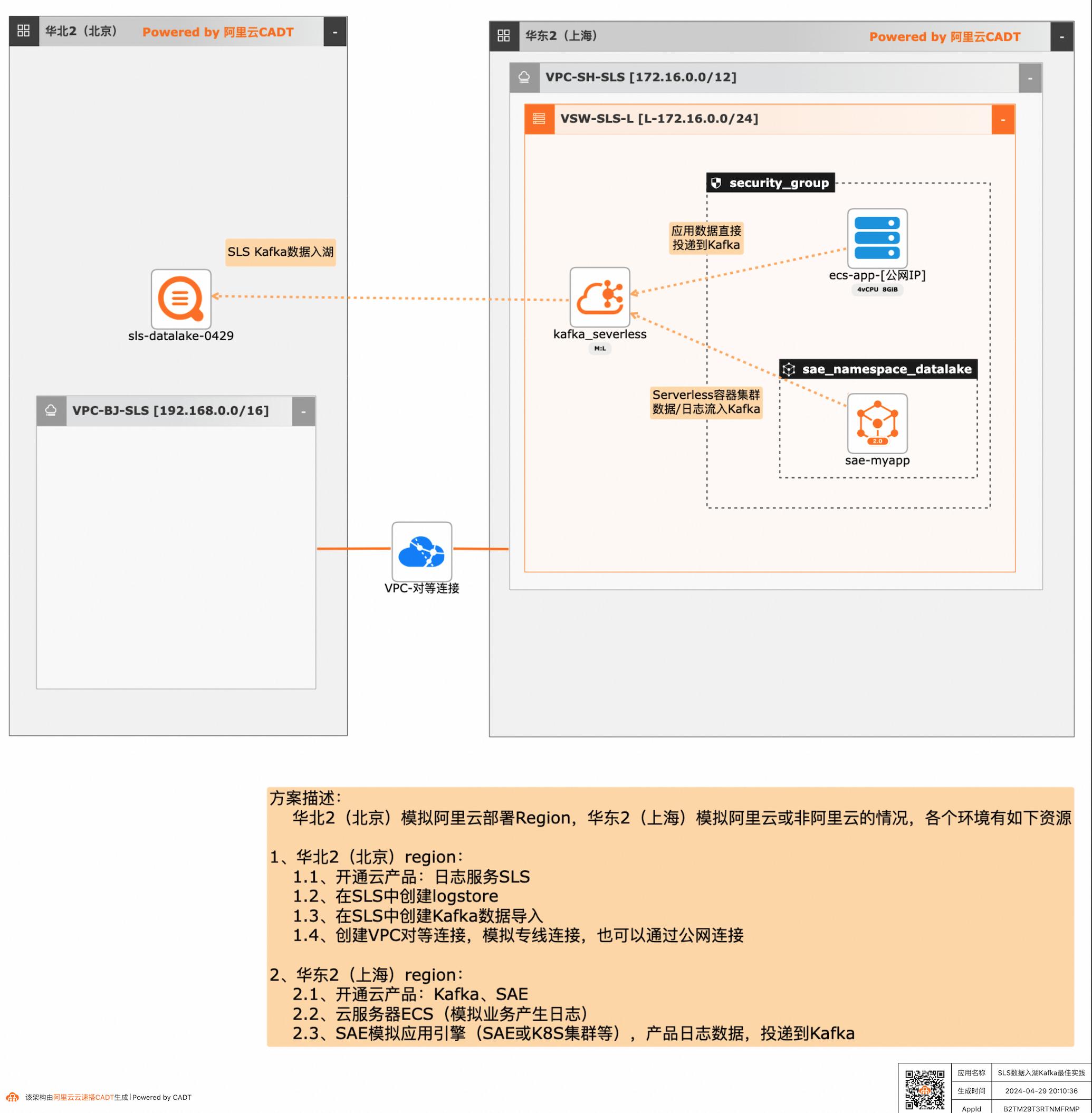
应用和数据分散在多云或混合云,在面对多云/混合云这样大的趋势下,数据无法进行统一的聚合、分析处理和导出等,本方案给出了在多云/混合云场景下,构建通过标准的Kafka协议和托管服务,SLS可以连接Kafka数据入湖导入,然后进行统一的海量数据的集中存储、智能转储、聚合分析查询等。
ECS-Kafka-SLS的数据入湖 步骤1通过CADT画布登录SLS(北京region)控制台,或者通过日志控制台Link访问(https://sls.console.aliyun.com/)步骤2查看在 ecs-app中投递到 kafka的数据(每次 10000条),已经通过 kafka-sls数 据入湖的通道,在sls已经可以查询到:文档版本:20240428 34SLS数据入湖Kafka最佳实践 场景验证 ...
通过ES兼容接口方式使用Kibana访问SLS数据
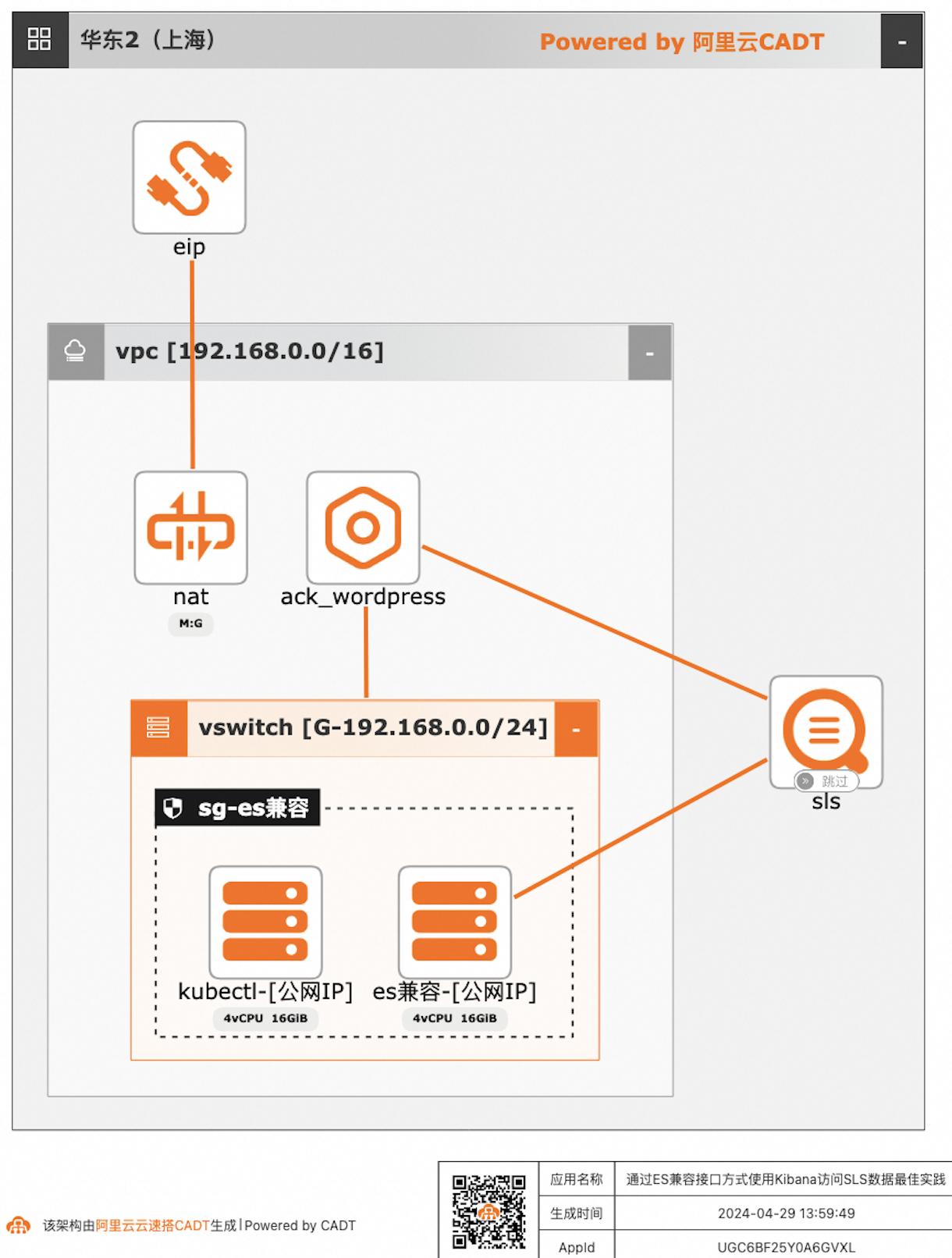
自建ELK日志系统的客户迁移到阿里云日志服务SLS后,对SLS查询分析语法不太熟悉的客户,可以继续沿用原有的查询分析习惯,在不改变使用方式习惯的情况下,通过Elasticsearch兼容接口的方式使用Kibana访问SLS。
方案优势●日志服务提供高可用的存储、查询引擎,全托管、无需运维投入●无需使用logstash中转数据,提高了日志查询的实时性●无需使用Kafka和Elasticsearch,避免占用机器资源,只需按量付费●兼容Elasticsearch生态、程序(Kibana、API访问等)部署架构 架构说明 2台ECS,1个ACK集群,1个EIP,1个NAT网关,1个SLS实例(跳...
移动开发平台 mPaaS
阿里云移动开发平台 mPaaS提供App开发、测试、运营及运维等云到端的一站式解决方案,帮助企业快速构建高质量的移动应用,阿里云快速开发平台提升企业产品生态发展。
服务保障服务全球数亿 App 终端用户。相关产品移动开发平台 mPaaS在线咨询产品定价提供灵活的计费方式,帮您节省使用成本。免费试用计费方式mPaaS 产品按照使用量进行计费,提供以下计费模式:预付费定义:是指先付费,再使用服务的计费模式,支持资源包和包年包月两种预付费方式,您可以提前预留资源,同时享受更大的价格...
来自:
云产品
基于函数计算FC实现大语言模型部署

在现代AI应用中, Qwen /chatglm2-6b 和Stable Diffusion等模型因其强大的功能而受到关注。然而,这些模型对计算资源的高需求和复杂的运维管理成为部署时的挑战。基于函数计算FC的无服务器计算模式为这类模型的部署提供了全新的解决方案。用户只需关注模型的部署和调用逻辑,而无需关心底层的服务器配置、资源分配和扩展性等问题。函数计算FC能够自动处理函数的执行环境,包括冷启动、弹性伸缩等,确保模型能够在大规模的请求下稳定运行。
这些场景 通常需要处理大量的数据,并实时生成准确的响应。通过将 Qwen/chatglm2-6b等部署在函数计算 FC 上,提供了高效、弹性、低成本的部署解决方案。解决问题•简化模型部署流程•全链路自适应弹性,无需为流量峰谷做频繁的手工处理•内置CICD平台能力,灰度,回滚,监控开箱即用•按量付费模式,没有资源闲置费用 最佳...
基于函数计算FC实现阿里云Kafka消息轻量级ETL处理
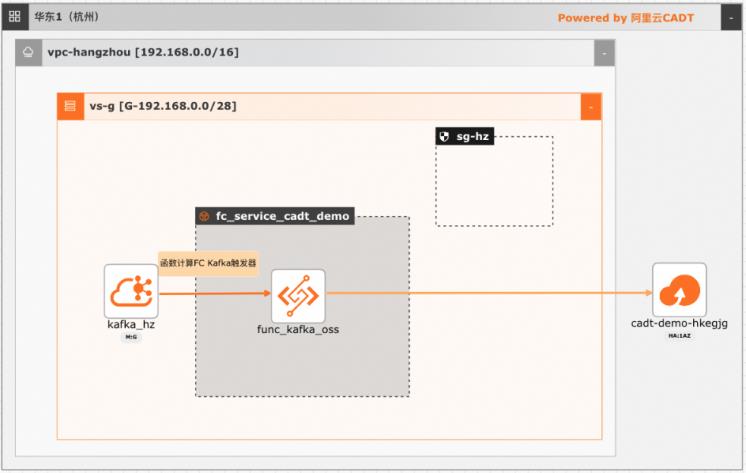
在大数据ETL场景,Kafka是数据的流转中心,Kafka中的数据一般是原始数据,可能存在多种数据混杂的情况,需要进一步做数据清洗后才能进行下一步的处理或者保存。利用函数计算FC,可以快速高效的搭建数据处理链路,用户只需要关注数据处理的逻辑,数据的触发,弹性伸缩,运维监控等阿里云函数计算都已经做了集成,函数计算FC也支持多种下游,OSS/数据库/消息队列/ES等都可以自定义的对接
云消息队列 Kafka 版广泛用于日志收集、监控数据聚合、流式数据处理、在线和离线分析等大数据领域,已成为大数据生态中不可或缺的部分。对象存储 OSS:对象存储 OSS 是一款具有行业领先的安全、稳定、高性价比、高性能的 云存储服务,可以帮助各行业的客户在互联网应用、大数据分析、机器学习、数据归档等 各种使用场景存储...
MaxFrame
MaxFrame 是由阿里云自研的分布式计算框架,支持 Python 编程接口并可直接使用 MaxCompute 计算资源及数据接口,同时与 MaxCompute Notebook、镜像管理等功能共同构成了 MaxCompute 完整的 Python 开发生态。用户可以以更熟悉、高效的方式进行大规模数据处理、可视化数据分析及科学计算、ML/AI 开发等工作。
更熟悉的开发生态.MaxFrame 兼容 Pandas 接口且自动进行分布式处理,在保证强大数据处理能力的同时,大幅度提高数据处理规模及计算效率.更完善的算子支持.MaxFrame 可直连 MaxCompute 数据,运行时无需将数据拉取至本地计算,消除了不必要的本地数据传输,提高执行效率。MaxFrame 可直接使用 MaxCompute 海量弹性计算资源,...
来自:
云产品
基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步
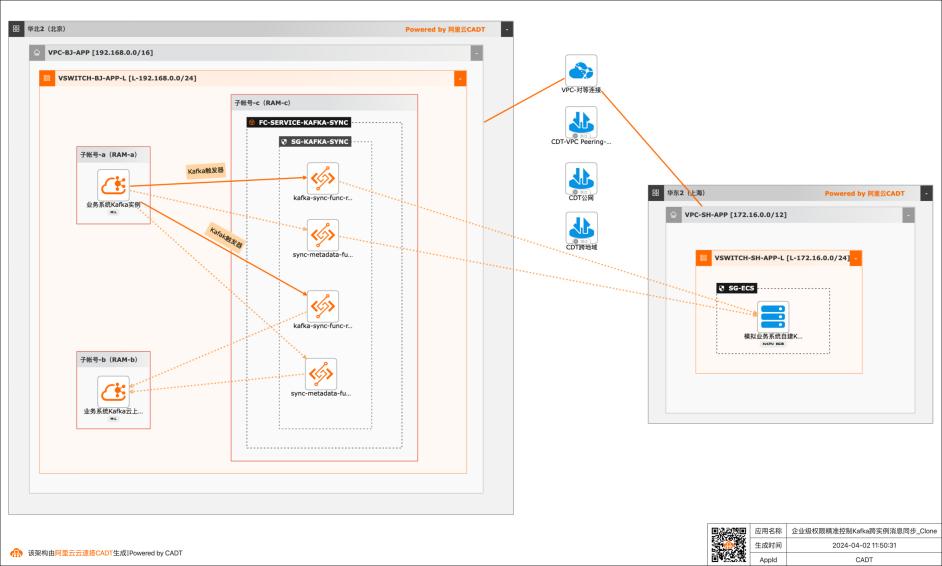
应用场景 在大数据场景,企业的Kafka实例可能存在多种情况,比如使用阿里云Kafka服务,可能是自建开源Kafka,或者是其他云上的云Kafka。不同的业务使用不同类型的Kafka实例,在这个前提下Kafka实例之间可能会需要消息同步的情况: 同帐号容灾场景:比如Kafka实例都是阿里云Kafka,但是Kafka实例会有主备之分,需要将主Kafka实例的消息实时同步到备Kafka。 跨帐号或异地容灾:这类场景比如主Kafka是阿里云Kafka,备Kafka是IDC开源自建Kafka,或者是其他云上的Kafka。 不同业务之间消息同步:因为现在的业务通常不会是信息孤岛,都需要消息互通,所以可能是A业务的Kafka实例消息需要同步到B业务的Kafka实例,并且这两个Kafka实例归属不同的RAM角色,有自己独自的权限控制。 解决问题 解决使用开源组件做消息同步的高成本问题。 解决使用开源组件做消息同步的并发性能、稳定性问题。 解决使用开源组件做消息同步的可靠性问题(重试机制,容错机制,死信队列等)。 大幅提升构建消息同步架构的效率,降低构建复杂度问题。
云消息队列Kafka版广泛用于日志收集、监控数据聚合、流式数据处理、在线和离线分析等大数据领域,已成为大数据生态中不可或缺的部分。 云服务器ECS(ElasticComputeService):是阿里云提供的性能卓越、稳定可靠、弹性扩 展的IaaS(InfrastructureasaService)级别云计算服务。云服务器ECS免去了您采购IT 硬件的前期准备...
- 产品推荐
- 这些文档可能帮助您