自建ElasticSearch迁移阿里云
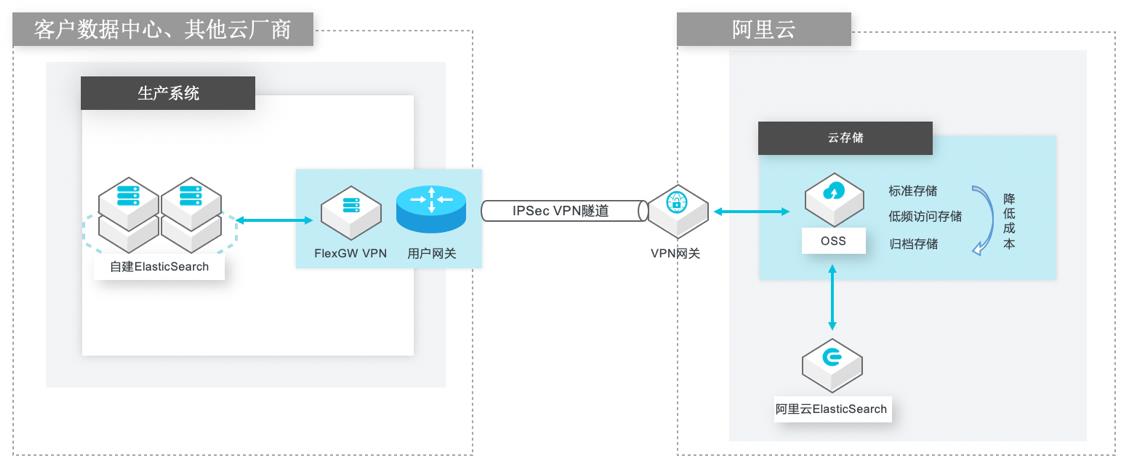
场景描述 以ElasticSearch为例,演示搭建模拟业务系统、 VPN网关和IPSecVPN隧道,介绍如何通过快照 的方式,将ElasticSearch索引数据安全备份到 阿里云OSS存储空间,以及介绍如何将备份在 OSS的快照仓库恢复到阿里云ElasticSearch实 例,进一步达到ElasticSearch迁移上云的目的。 解决的问题 自建ElasticSearch的云上/跨云备份需求。 自建ElasticSearch迁移到阿里云 ElasticSearch服务实例。 产品列表 VPC,ECS,VPN网关,OSS,阿里云ElasticSearch,云速搭CADT
通用场景 版本 5.5 支付方式 后付费 可用区数量 单可用区 规格族 云盘型 数据节点规格 elasticsearch.sn1ne.large 存储类型 SSD云盘 单点节点存储空 20GiB 间 数量 3 Kibana Kibana节点 勾选 节点规格 elasticsearch.sn1ne.large 文档版本:20210802 9 自建 ElasticSearch快照备份 OSS 基础环境搭建 其他选项 均不勾选 VPN ...
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。
相关命令可 以下载后浏览:gitclonehttps:/best-practice:Abcd123456@codeup.aliyun.com/best-practice/bp/199.git 使用场景 针对分析师如何利用MaxComputeIn-databaseML 能力,通过湖仓一体架构对海量OSS 非结构化、半结构化数据做数据分析和机器学习模型构建、训练和应用。业务架构基于湖仓一体架构使用MaxCompute对OSS湖...
自建Hive数仓迁移到阿里云EMR
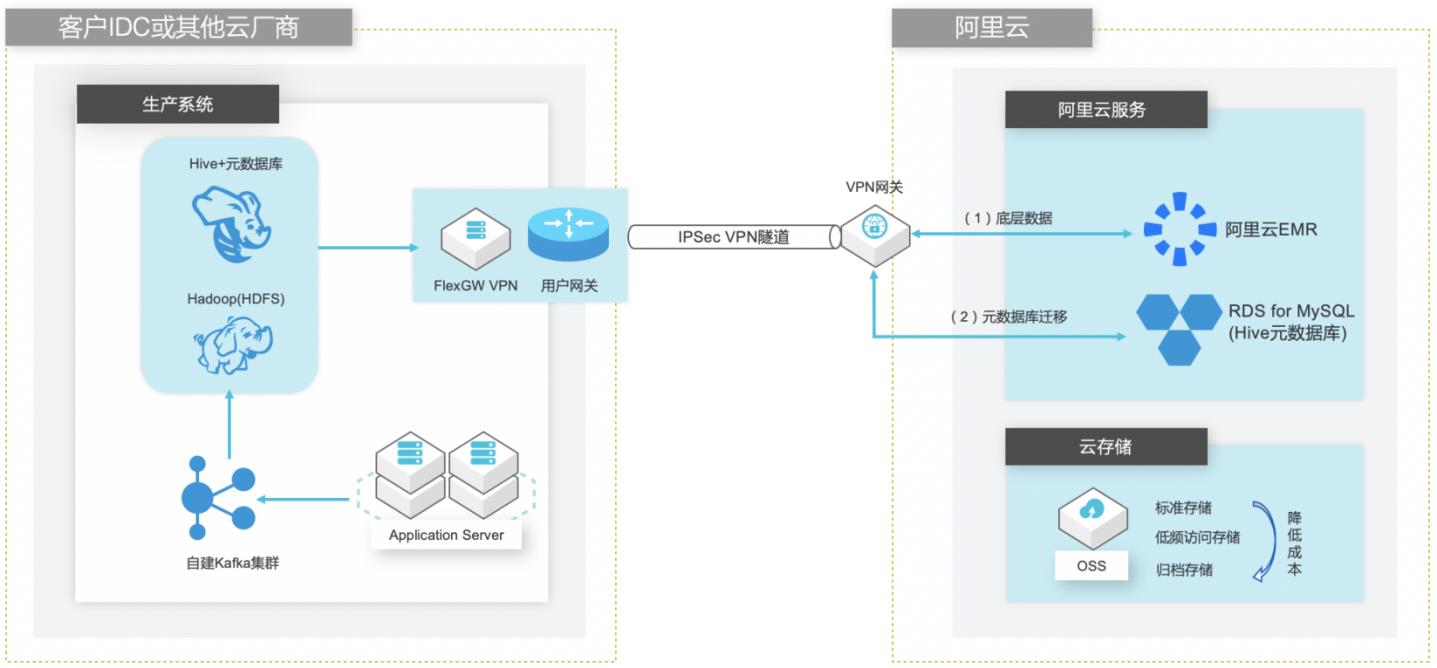
场景描述 客户在IDC或者公有云环境自建Hadoop集群构 建数据仓库和分析系统,购买阿里云EMR集群之 后,涉及到将数据仓库和Hive元数据的数据库迁 移上云。目前主流Hive数据仓库迁移场景为1.x 版本迁移到阿里云EMR(Hive2.x版本),涉及到 数据订正更新步骤。 解决的问题 Hive数据仓库的数据迁移方案 Hive元数据库的迁移方案 Hive跨版本迁移后的数据订正 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
建议将 HDFS文件系统的/user/hive/目录整体迁移到 EMR集群,在数据迁移的规 划上重点考虑以下几点:1.DistCp在 EMR集群执行,避免在源 Hadoop集群执行时增加负载。2.选择源 Hadoop集群业务低峰进行数据迁移操作,最小程度影响生产环境业务。文档版本:20210721 27 自建Hive数据仓库跨版本迁移到阿里云 EMR Hive数据迁移 3....
企业上云workshop
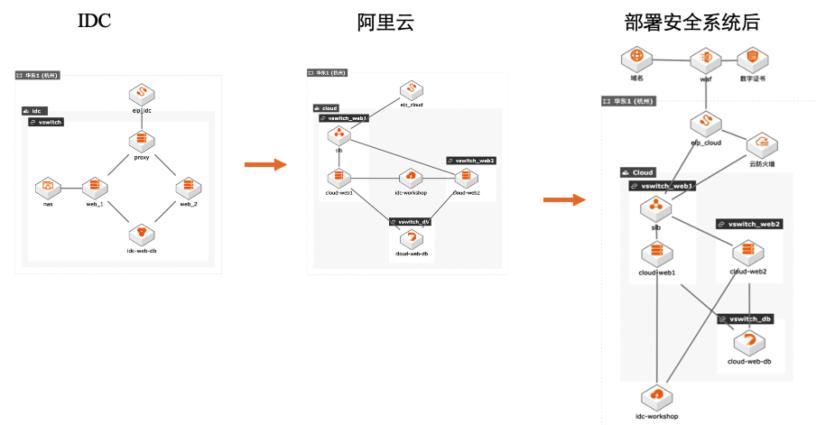
本文模拟了如下场景: 1. 线下 IDC 环境中部署了一个业务系统,业务是利用 wordpress 系统提供网站服务。 2. 本文详细介绍了如何将以上线下系统搬迁到云上, 包括如何在云上构建以上业务系统,如何迁移线下 系统到云上,如何割接。 3. 最后介绍了迁移上云后,如何部署安全系统。 解决问题 IDC 业务系统搬迁上云 云上构建业务系统 部署安全系统
注意不要勾选结构初始化和全量数据初始化。确认预检通过。文档版本:20200127 82 应用割接 企业上云 workshop-IDC业务迁移上云 确认同步作业正常运行中。12.4.更新域名解析,完成应用割接 在域名解析服务中,将 ws001.lustre.site 解析地址指向 SLB实例的 EIP即完成了服 务的割接上线。同时将本地 host中对域名的解析删除。...
来自:
最佳实践
相关产品:专有网络 VPC,云服务器ECS,云数据库RDS MySQL 版,对象存储 OSS,负载均衡 SLB,弹性公网IP,文件存储NAS,云数据库PolarDB,Web应用防火墙,云防火墙,SSL证书,云速搭
互联网业务全球化互通组网
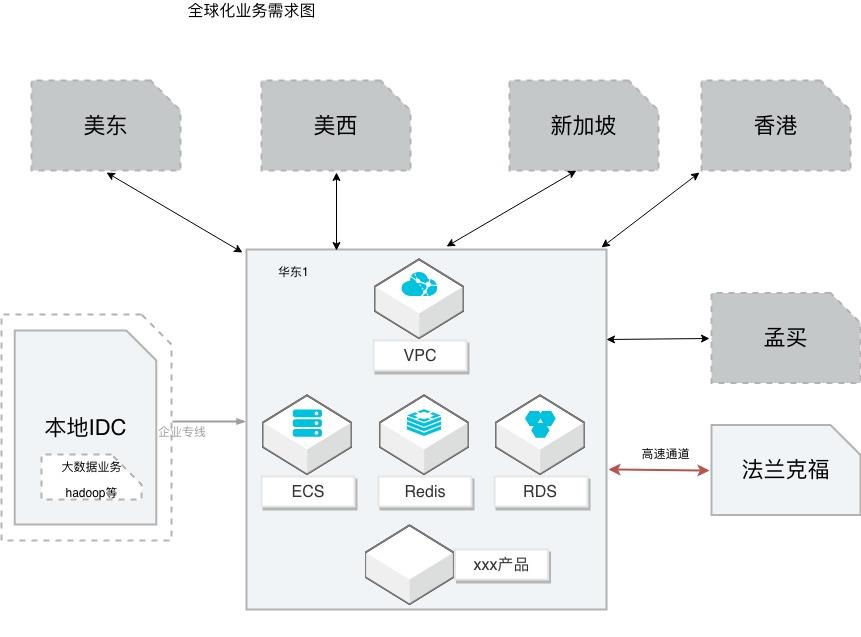
场景描述 本方案适用从事全球化业务的客户,希望借助全球 互通的网络,实现多地域的互通。 同时在全球互联的网络下,搭建应用多地部署。如果 业务中涉及到高速通道,提供高速通道迁移云企业网 的操作演练;涉及到跨账号多VPC下的数据迁移和 同步,本方案提供详细的操作步骤,帮助客户快速完 成演练。 解决问题 借助云企业网解决网络互通 高速通道到云企业网的平滑迁移 RDS的数据互通,特别是跨账号多VPC的数据同步 应用的快速部署 产品列表 云企业网(CEN)、云服务器(ECS)、数据库(RDS)、 数据库(Redis)、数据传输(DTS)、负载均衡(SLB) 块存储、专有网络(VPC)
性能类型 标准性能 存储类型 高性能内存型 节点类型 双副本 套餐类型 标准套餐 实例规格 2G主从版 说明:支持变配规格,变配过程会有 30秒内连接闪断及 1分 钟内的实例只读。密码设置 立即设置 输入密码 设置符合要求的密码,并再次输入进行确认。购买数量 1 实例名称 自定义,本实践设置为 pw_redis01。文档版本:20191217...
云上高并发系统改造
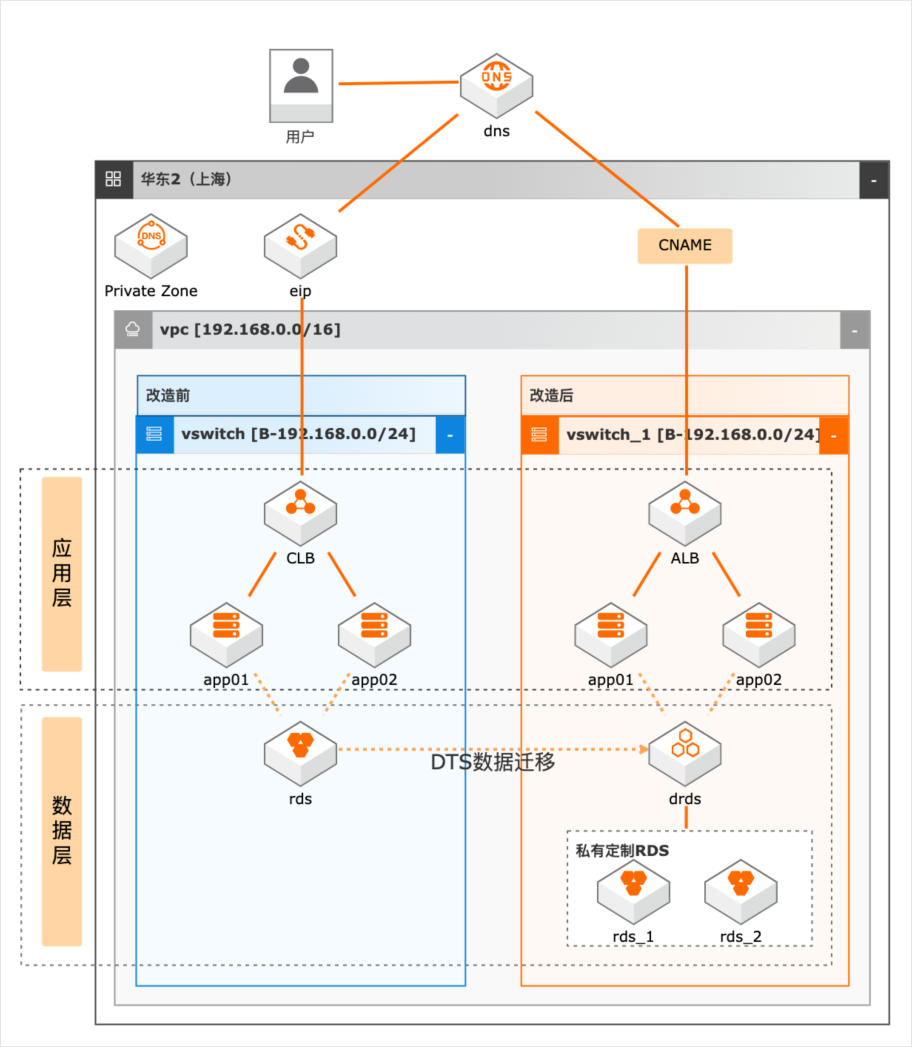
场景描述 随着业务的发展,系统并发压力越来越大,如何 进行系统改造以满足高并发场景的业务需求成 为了一个技术难题。本实践抽象于客户的实际场 景,提供高并发下系统改造的理论指导和部分实 操演示。主要适用于以下场景: 1.系统并发压力大,需要进行系统应用改造。 2.数据层并发压力大,需进行分库分表改造。 3.数据库数据量巨大,亟待分库分表解决查询 和写入瓶颈的场景。 方案优势/解决问题 1.在水平扩展阶段,我们除了通过SLB做负载 均衡外,我们可以通过SLB下挂nginx的方 式,增加负载均衡侧的可扩展性 2.在数据库拆分阶段,在做好数据规划后,我 们借助DTS进行数据迁移,通过DRDS将 RDS MySQL的数据拆分到多个分库和分 表中。 产品列表 专用网络VPC 负载均衡SLB 云服务器ECS 数据库RDSMySQL 数据传输服务DTS PrivateZone 分布式关系型数据库DRDS
找到中心数据结构中的核心表,基于 它的数据量,写入压力,判断是否需要拆分;3.数据均匀分散:按照选择的切分键进行切分,数据要能均匀分散到各个分片中,不然瓶颈仍然会存在;文档版本:20220506(发布日期)37 云上高并发系统改造 数据迁移和压测演练 4.尽可能避免跨库查询:关联查询的数据尽量分散到同一个分片中,跨库...
基于弹性计算的AI推理
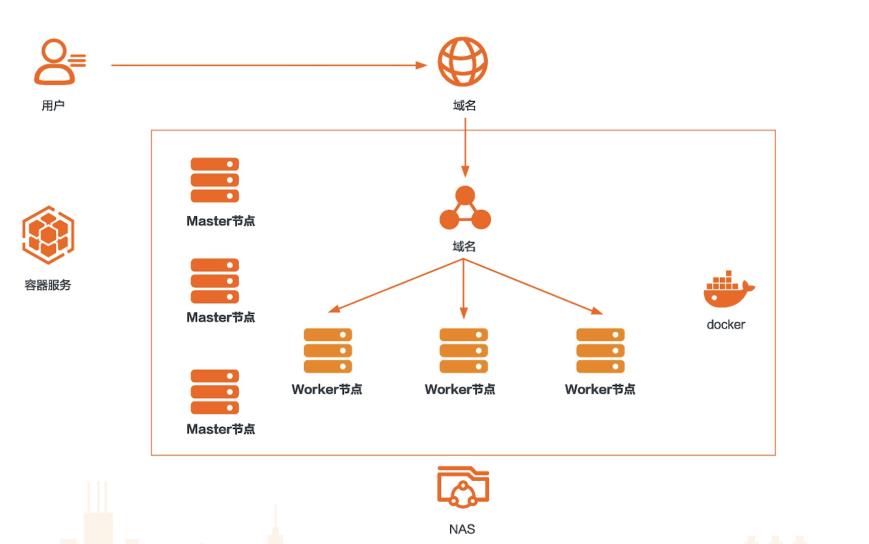
场景描述 本方案适用于使用GPU进行AI在线推理的场 景。在推理之前,模型已经训练完成。例如,刷脸 支付中,我们在刷脸的时候,就是推理的一个过 程。再比如图像分类,目标检测,语音识别,语 义分析等返回结果的过程。 解决问题 使用GPU云服务器搭建推理环境 使用容器服务Kubernetes版构建推理 环境 使用NAS存储模型数据 使用飞天AI加速推理工具加速推理 产品列表 GPU云服务器 容器服务Kubernetes版 NAS共享存储
input 模型输入节点的信息,结构如下:59 企业上云实践 基于弹性计算的 AI推理|部署飞天 AI加速推理工具的 demo 名称 描述 name:名称 data_type:输入数据类型,可选值包括:DT_FP32、DT_UINT8、DT_UINT16、DT_UINT32、DT_UINT64、DT_INT8、DT_INT16、DT_INT32、DT_INT64、DT_FP16 data_format:输入数据格式,可选值包括...
超级计算集群实现自然语言处理训练
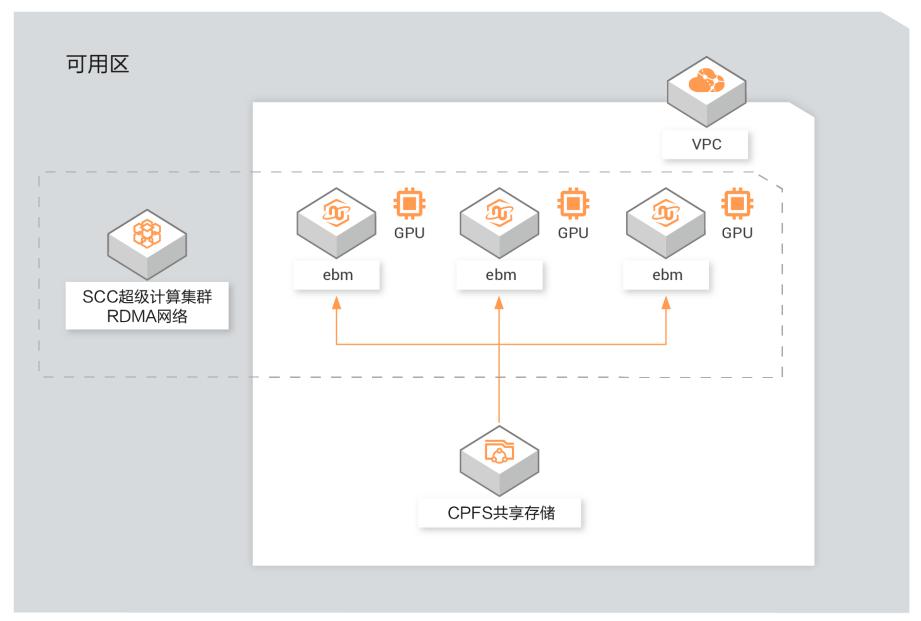
场景描述 本方案适用于自然语言训练场景,使用神龙 GPU云服务器(SCCGN6)+CPFS进行NLP的 训练,采用Bert模型。这里不使用容器,直接 使用裸机进行NLP的Bert训练,使用飞天AI加 速训练工具可以有效提升多机多卡的训练效率。 解决问题 使用神龙GPU云服务器搭建NLP训练环 境 使用SCC的RDMA网络 使用CPFS存储训练数据 使用飞天AI加速训练工具加速训练 产品列表 神龙GPU云服务器(SCCGN6) SCC超级计算集群 CPFS共享存储
15企业上云实践 基于超级计算集群的自然语言处理AI训练 步骤2 将要挂载cpfs的实例添加到挂载点对应的管理节点安全组。加入后,查看ECS的安全组信息,如下:16企业上云实践 基于超级计算集群的自然语言处理AI训练 步骤3 添加云服务器ECS实例到CPFS客户端集群。 登录NAS控制台。 在左侧导航栏,单击文件系统>文件系统列表...
云数据库Redis
云数据库 Redis 版是一种全托管、兼容Redis协议的内存数据库服务,包含社区版Redis和企业版Tair,支持主从、集群和读写分离架构,具备低延迟、大吞吐、弹性扩缩容的特点。Tair提供多种系列满足不同场景的性价比要求,更有全球多活、数据闪回、大热Key探测与优化、丰富的数据结构,赋能大规模高性能要求的在线数据业务。
系统工作时主节点(Master)和备节点(Slave)数据实时同步,主节点故障时系统自动秒级切换,备节点接管业务,全程自动且对业务无影响,主备架构保障系统服务具有高可用性.集群(cluster)实例采用分布式架构,每个节点都采用一主一从的高可用架构,自动容灾切换,故障迁移,多种集群规格可适配不同的业务压力,支持一键...
来自:
云产品
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
3.1.HDFS数据迁移 建议将 HDFS文件系统的/user/hive/目录整体迁移到 OSS,在数据迁移的规划上重点 考虑以下几点:1.选择源 Hadoop集群业务低峰进行数据迁移操作,最小程度影响生产环境业务。2.如果线下 IDC的 HDFS数据量在几十 TB甚至 PB级别,建议使用阿里云闪电立 方进行迁移。闪电立方详情请查看 ...
云数据库HBase
阿里云云数据库 HBase 版(ApsaraDB for HBase)是基于 Hadoop 且100%兼容HBase协议的高性能、可弹性伸缩、面向列的分布式数据库,轻松支持PB级大数据存储,满足千万级QPS高吞吐随机读写场景。
帮助用户整合分析用户交易、企业数据和爬虫抓取信息,构建反欺诈、用户画像库,提供大数据风控SaaS服务.HBase采用稀疏存储模式,支撑PB级结构化/非结构化存储,提供全量详单查询.Phoneix+二级索引支持实时OLTP查询,提供OLAP查询.海量数据HTAP处理.与传统数仓的B+树相比,HBase 支持LSM存储模式,专门应对高并发写入场景.云...
来自:
云产品
资源管理
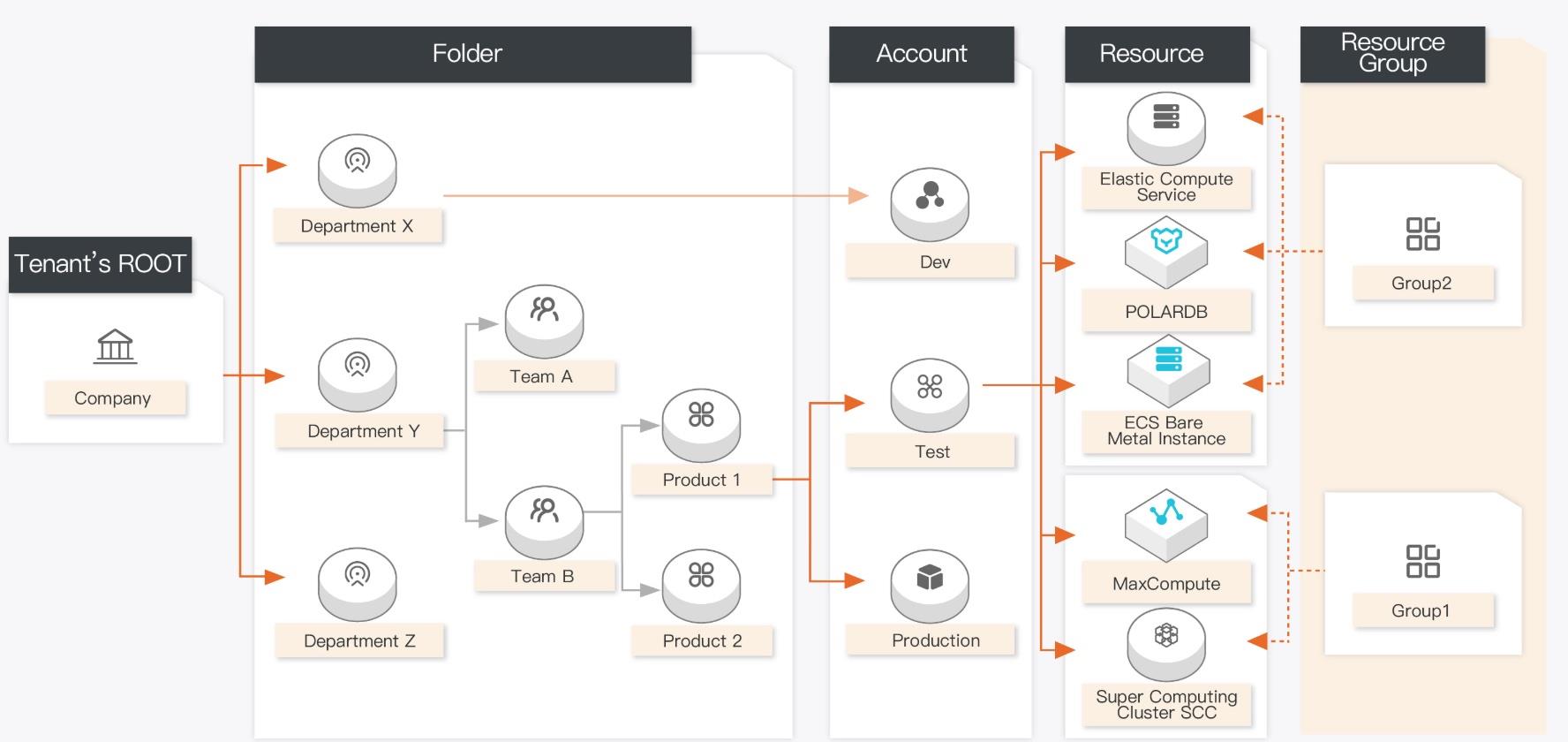
场景描述 随着企业IT成熟度不断提高、管理的云上资源 不断增多,如何对资源进行高效管理的问题就会 凸显出来。阿里云的资源管理服务支持您按照业 务需要搭建适合的资源组织关系,使用目录、资 源夹、账号、资源组分层次组织与管理您的全部 资源,更好的实现项目成功。 解决问题 1.按照企业组织结构管理账号体系。 2.指定结算账号进行统一结算 3.统一管理成员账号权限系统 4.账号下的资源按照资源组进行分类 5.可以按照自定义财务单元进行分账管理 产品列表 资源管理
其本 质是建立一套与您的企业相关的,基于资源使用的关系结构。详见:https://www.aliyun.com/product/entconsole 资源组:阿里云账号下进行资源分组管理的一种机制,资源组能够帮助您解决单 个云账号内的资源分组和授权管理的复杂性问题。详见:https://www.aliyun.com/product/entconsole 访问控制:(Resource Access ...
- 产品推荐
- 这些文档可能帮助您