数据安全中心
敏感数据保护(Sensitive Data Discovery and Protection),在满足等保v2.0“安全审计”、等保v3.0及“个人信息保护”的合规要求的基础上,为客户提供敏感数据识别、分级分类、数据安全审计、数据脱敏、智能异常检测等数据安全能力,形成一体化的数据安全解决方案。
支持对结构化数据库RDS、DRDS、PolarDB、OceanBase、ECS自建数据库,非结构化数据存储OSS、OTS,大数据平台MaxCompute的数据审计与防护.覆盖各类云上数据源,实现统一数据安全管理.基于云原生能力,提供无代理Agentless模式,开箱即用,秒级接入,即刻防护您的云上数据.无需部署代理agent,不占用租户资源.《中华人民共和国...
来自:
云产品
数据安全解决方案
数据是企业的核心资产,如何保护企业的云上数据,是每个企业管理者都应当重视的课题。在云平台提供更为安全便捷的数据保护能力的同时,阿里云根据自身多年的经验积累,结合大量云上客户的最佳实践,提供了一套完整的数据安全解决方案,帮助企业提升云上数据风险防御能力,实现企业核心及敏感数据安全可控。
基于2019年发布的国家标准《GB/T 37988-2019 数据安全能力成熟度模型》中明确的“以数据为中心”的管理思路,从数据生命周期角度出发,针对企业常见的数据安全痛点,提供整体解决方案.以国家标准为顶层指导框架.围绕云上数据安全工作对“敏捷性”的要求,伴随着数据存储“复杂度”的挑战,重点关注“透明度”问题,从根本...
来自:
解决方案
利用交互式分析(Hologres)进行数据查询
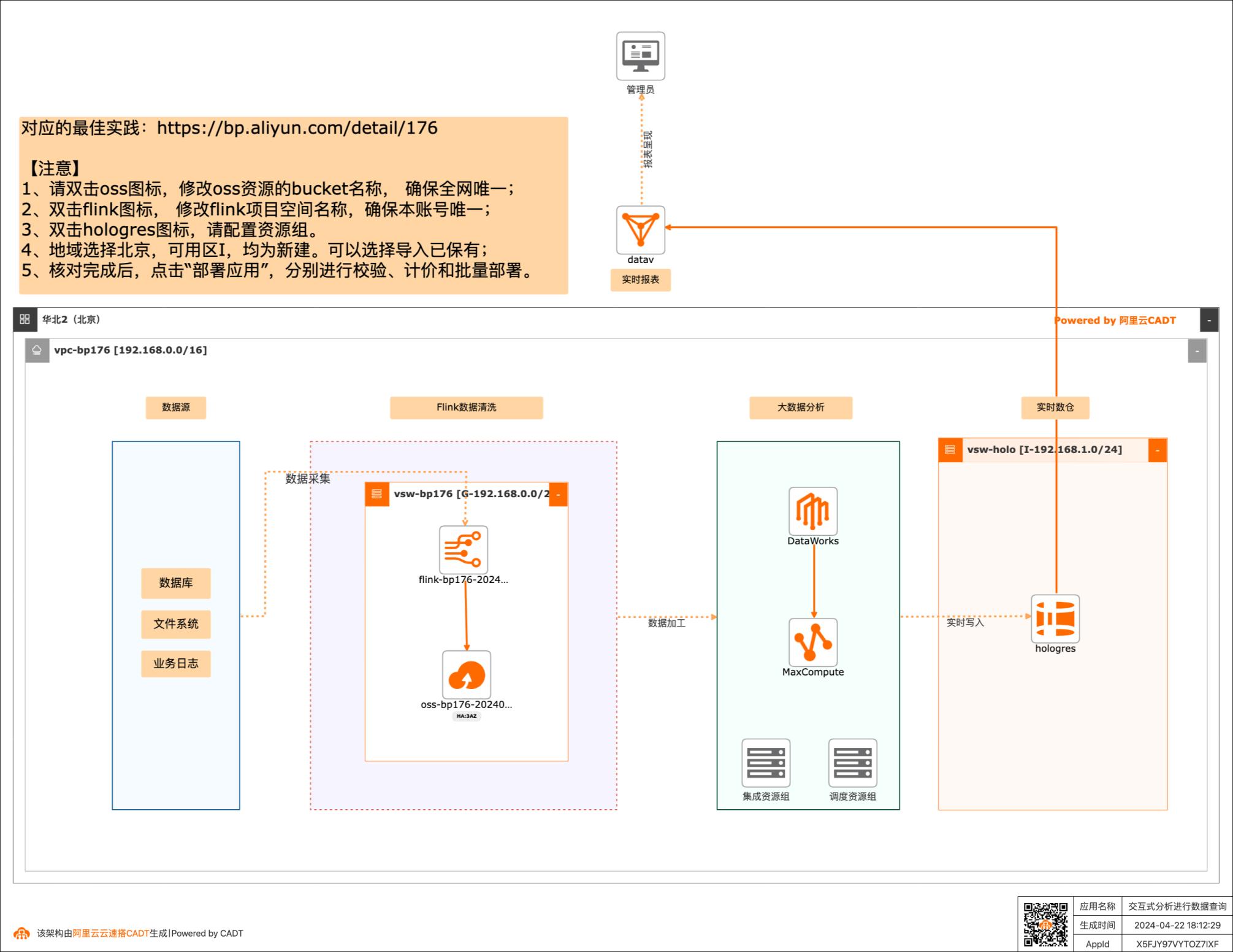
场景描述:随着收集数据的方式不断丰富,企业信息化 程度越来越高,企业掌握的数据量呈TB、 PB或EB级别增长。同时,数据中台的快 速推进,使数据应用主要为数据支撑、用户 画像、实时圈人及广告精准投放等核心业务 服务。高可靠和低延时地数据服务成为企业 数字化转型的关键。 Hologres致力于低成本和高性能地大规模 计算型存储和强大的查询能力,为您提供海 量数据的实时数据仓库解决方案和实时交 互式查询服务。 解决问题 1.加速查询MaxCompute数据 2.快速搭建实时数据仓库 3.无缝对接主流BI工具 产品列表 MaxCompute Hologres 实时计算Flink 专有网络VPC DataWorks DataV
MaxCompute致力于批量结构化数 据的存储和计算,提供海量数据仓库的解决方案及分析建模服务。由于单台服务器的处理能力有限,海量数据的分析需要分布式的计算模型。分布式的 计算模型对数据分析人员要求较高且不易维护。数据分析人员不仅需要了解业务需求,同时还需要熟悉底层分布式计算模型。MaxCompute为您提供完善的数据...
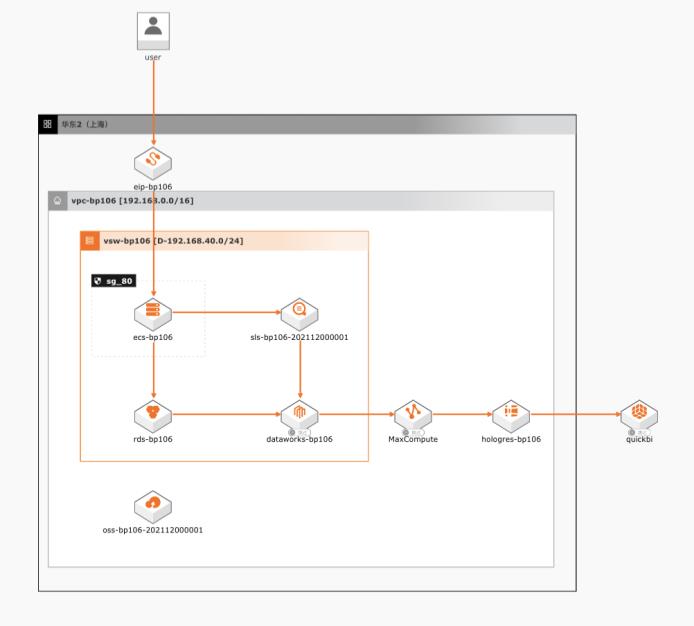
AnalyticDB MySQL湖仓版的用户运营分析实践
本方案只需一个湖仓版实例就能完成“数据入湖+作业开发+在线分析”的一站式用户运营数据分析,提供更高效的数据处理方案与更低的数据存储成本。
数据集成覆盖日志、消息、数据库、HDFS等结构化和非结构化的数据源,可以将多个数据源的数据进行整合,形成更为全面的数据视图。即席查询与自助分析实时数据可直接接入BI工具,实现实时自主分析,快速洞察数据,可帮助企业优化业务流程,提高效率,降低成本,同时增强企业在市场竞争中的竞争力。方案部署01部署准备完成账号...
来自:
解决方案
数据集成 Data Integration
阿里云数据集成 Data Integration是跨异构数据、低成本、弹性扩展的数据采集同步平台,为DataX的商业版,支持ETL,支持50+数据源跨网络离线(全量/增量)同步。
主要通过定义数据来源和去向的数据源和数据集,提供一套抽象化的数据抽取插件(称之为 Reader)、数据写入插件(称之为 Writer),并基于此框架设计一套简化版的中间数据传输格式,从而达到任意结构化、半结构化数据源之间数据传输的目的.抽取、转换、导入.数据集成支持在数据抽取过程中进行简单的ETL数据转换操作(如日期...
来自:
云产品
游戏数据运营融合分析
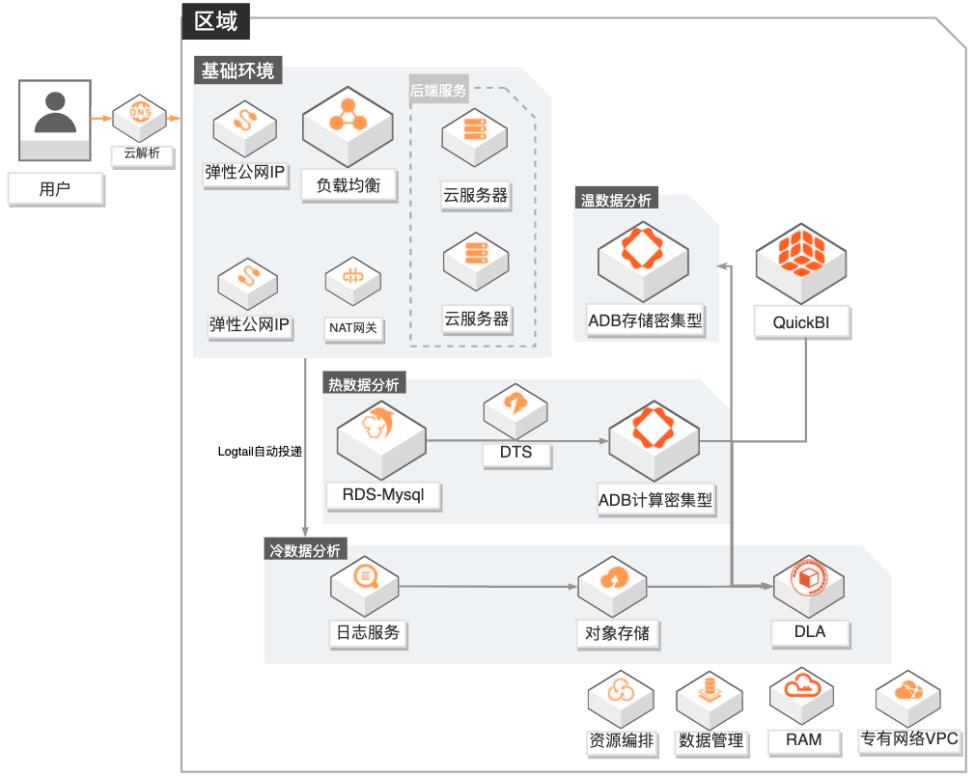
场景描述 1.游戏行业有结构化和非结构化数据融合分 析需求的客户。 2.游戏行业有数据实时分析需求的客户,无法 接受T+1延迟。 3.对数据成本有一定诉求的客户,希望物尽其 用尽量优化成本。 4.其他行业有类似需求的客户。 方案优势/解决问题 1.秒级实时分析:依托ADB计算密集型实例, 秒级监控DAU等数据,为广告投放效果提 供有力的在线决策支撑。 2.高效数据融合分析:打通结构化和非结构化 数据,支撑产品体验分析;广告买量投放效 果实时(分钟级)分析,渠道的评估更准确。 3.低成本:DLA融合冷数据分析+ADB存储密 集型温数据分析+ADB计算密集型热数据分 析,在满足各种分析场景需求的同时,有效 地降低的客户的总体使用成本。 4.学习成本低:DLA和ADB兼容标准SQL语 法,无需额外学习其他技术。 产品列表 专有网络VPC、负载均衡SLB、NAT网关、弹性公网IP 云服务器ECS、日志服务SLS、对象存储OSS 数据库RDSMySQL、数据传输服务DTS、数据管理DMS 分析型数据库MySQL版ADS 数据湖分析DLA、QuickBI
游戏行业有结构化和非结构化数据融 合分析需求的客户。2.游戏行业有数据实时分析需求的客 户,无法接受 T+1延迟。3.对数据成本有一定诉求的客户,希望 物尽其用尽量优化成本。4.其他行业有类似需求的客户。方案优势/解决问题 1.秒级实时分析:依托 ADB计算密集型 实例,秒级监控 DAU等数据,为广告 投放效果提供有力的在线...
基于Flink+ClickHouse构建实时游戏数据分析
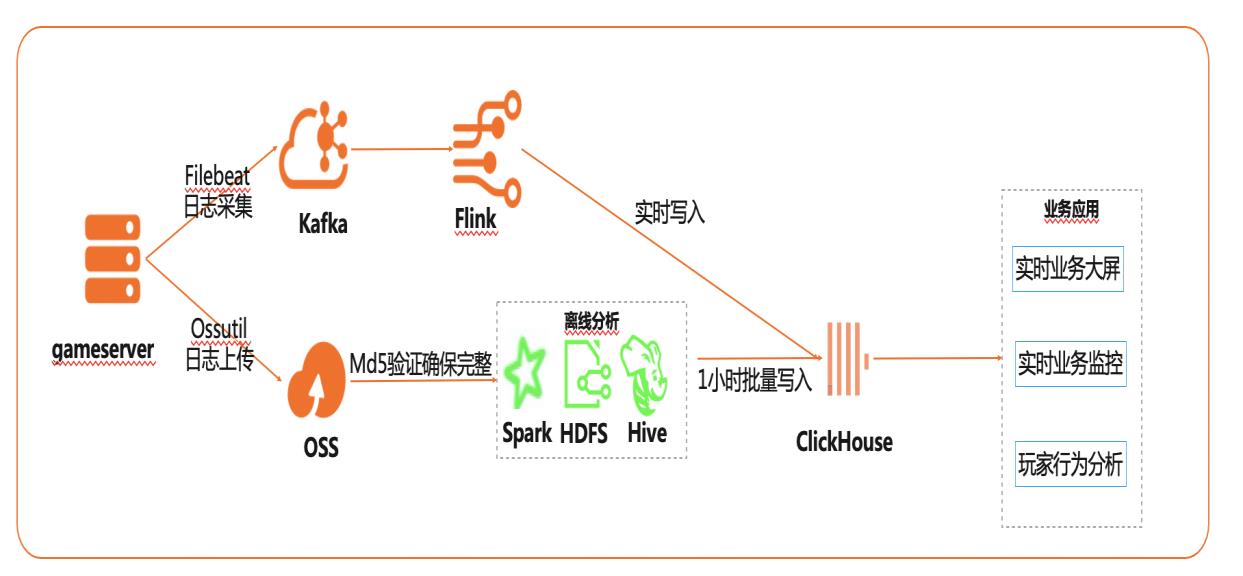
在互联网、游戏行业中,常常需要对用户行为日志进行分析,通过数据挖掘,来更好地支持业务运营,比如用户轨迹,热力图,登录行为分析,实时业务大屏等。当业务数据量达到千亿规模时,常常导致分析不实时,平均响应时间长达10分钟,影响业务的正常运营和发展。 本实践介绍如何快速收集海量用户行为数据,实现秒级响应的实时用户行为分析,并通过实时流计算Flink/Blink、云数据库ClickHouse等技术进行深入挖掘和分析,得到用户特征和画像,实现个性化系统推荐服务。 通过云数据库ClickHouse替换原有Presto数仓,对比开源Presto性能提升20倍。 利用云数据库ClickHouse极致分析性能,千亿级数据分析从10分钟缩短到30秒。 云数据库ClickHouse批量写入效率高,支持业务高峰每小时230亿的用户数据写入。 云数据库ClickHouse开箱即用,免运维,全球多Region部署,快速支持新游戏开服。 Flink+ClickHouse+QuickBI
Presto,支持 SQL 并提供了一个标准数据库的语法特性,但其不是一个通常意义上的 关系数据库,而是定位在数据仓库和数据分析业务的分布式 SQL引擎,为交互式查询 而设计,比较适合的应用场景有 ETL、Ad-Hoc查询、海量结构化数据与半结构化数据 分析以及海量多维数据聚合与报表。在如下的两个测试场景下,ClickHouse明显比 ...
基于MaxCompute的大数据BI分析
场景描述 本文以电商行业为例,将业务数据和日志数据使用 MaxCompute做ETL之后,同步到ADB进行实时 分析,之后通过QuickBI进行快速可视化展示。 解决问题 1.互联网行业、电商、游戏行业等网站、App、 小程序应用内BI分析场景。 2.可扩展到各类网站BI分析场景使用。 产品列表 1.MaxCompute 2.分析型数据MySQL版 3.日志服务SLS 4.QuickBI 5.云服务器ECS 6.RDSMySQL版
文档版本:20211213 1 基于 MaxCompute的大数据 BI分析 最佳实践概述 方案优势 以 Hologres+QuickBI快速实时数据分析的核心能力为切入点,将客户的业务数 据、日志数据引导至阿里云的日志服务和分析性数据库。融合阿里云的日志服务 SLS 的生态,增强用户体验(如无缝对接 Flink、Elasticsearch、RDS、Hologres、EMR、dataV ...
云原生数据仓库AnalyticDB MySQL数据仓库
阿里云云原生数据仓库AnalyticDB MySQL版(简称AnalyticDB)是融合数据库、大数据技术于一体的云原生企业级数据仓库平台。云原生数据仓库AnalyticDB MySQL版支持数据实时写入和同步更新、实时计算和实时服务,可用于构建企业级报表系统、数据仓库和数据服务引擎。
不论在数据湖中的非结构化/半结构化数据,还是在数据库中的结构化数据,都可使用AnalyticDB MySQL同时完成高吞吐离线处理和高性能在线分析,真正做到数据湖的规模,数据库的体验。帮助企业构建数据分析平台,实现降本增效.PolarDB MySQL免费同步.云原生数据仓库AnalyticDB MySQL版.一份数据同时支持离线处理和在线分析,...
来自:
云产品
DTS数据同步集成MaxCompute数仓
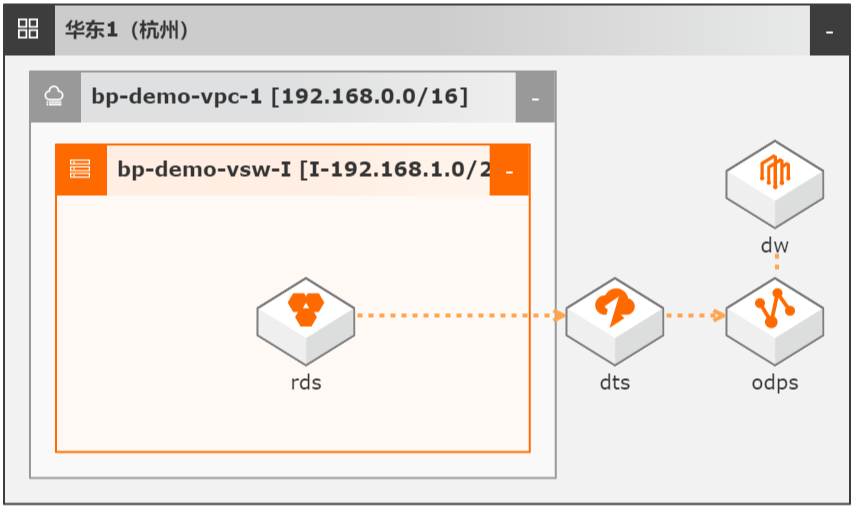
场景描述 本文Step by Step介绍了通过数据传输服务 DTS实现从云数据库RDS到MaxCompute的 数据同步集成,并介绍如何使用DTS和 MaxCompute数仓联合实现数据ETL幂等和数 据生命周期快速回溯。 解决问题 1.实现大数据实时同步集成。 2.实现数据ETL幂等。 3.实现数据生命周期快速回溯。 产品列表 MaxCompute 数据传输服务DTS DataWorks 云数据库RDS MySQL 版
数据抽取不幂等或容错率低,如凌晨 0:00启动的 ETL任务因为各种原因(数据库 HA切换、网络抖动或 MAXC写入失败等)失败后,再次抽取无法获取 0:00时的数 据状态。2.针对不规范设计表,如没有 create_time/update_time的历史遗留表,传统 ETL需 全量抽取。3.实时性差,抽取数据+重试任务往往需要 1-3小时。另外数据库的数据...
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
详见:https://www.aliyun.com/product/oss Hive:Apache Hive是基于 Hadoop的一个数据仓库工具,可以将结构化的数据 文件映射为一张数据库表,并提供简单的 SQL查询功能,可以将 SQL语句转换 为 MapReduce任务进行运行。其优点是学习成本低,可以通过类 SQL语句快速 实现简单的 MapReduce统计,不必开发专门的 MapReduce...
智能数据建设与治理Dataphin
Dataphin遵循阿里巴巴集团多年实战沉淀的大数据建设OneData体系(OneModel、OneID、OneService),集产品、技术、方法论于一体,一站式地为您提供集数据引入、规范定义、智能建模研发、数据萃取、数据资产管理、数据服务等的全链路智能数据构建及管理服务。助您打造属于自己的标准统一、资产化、服务化和闭环自优化的智能数据体系,驱动创新。
基于数据架构和项目划分,可以以全局、流动、结构化模式可视化查看多业务视角的数据资产.提供多种资产对象的元数据查询及详情查看,支持字段血缘和表级血缘,支持相关任务和数据表的影响分析.提供数据标准、码表、词根的管理能力,并结合资产元数据支持落标映射,助力企业资产治理.针对引擎及多种数据源的表和字段,提供...
来自:
云产品
湖仓一体架构EMR元数据迁移DLF
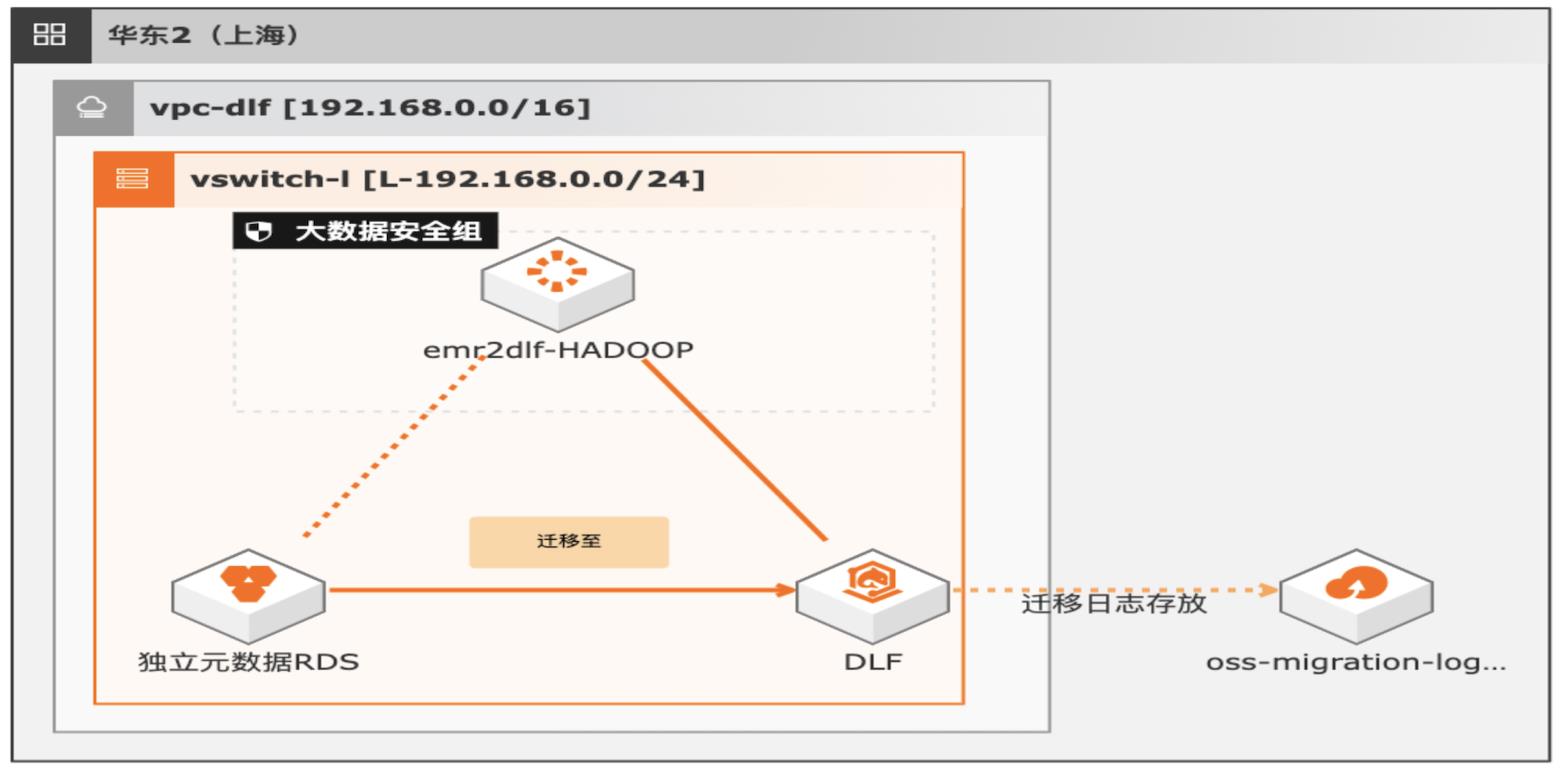
通过EMR+DLF数据湖方案,可以为企业提供数据湖内的统一的元数据管理,统一的权限管理,支持多源数据入湖以及一站式数据探索的能力。本方案支持已有EMR集群元数据库使用RDS或内置MySQL数据库迁移DLF,通过统一的元数据管理,多种数据源入湖,搭建高效的数据湖解决方案。
数据湖构建 Data Lake Formation(DLF):数据湖是一个集中式存储库,可存储 任意规模结构化和非结构化数据,支持大数据和 AI计算。数据湖构建(Data Lake Formation,DLF)作为云原生数据湖架构核心组成部分,帮助用户简单快速地构 建云原生数据湖解决方案。数据湖构建提供湖上元数据统一管理、企业级权限控 制,并无缝...
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。
相关命令可 以下载后浏览:gitclonehttps:/best-practice:Abcd123456@codeup.aliyun.com/best-practice/bp/199.git 使用场景 针对分析师如何利用MaxComputeIn-databaseML 能力,通过湖仓一体架构对海量OSS 非结构化、半结构化数据做数据分析和机器学习模型构建、训练和应用。业务架构基于湖仓一体架构使用MaxCompute对OSS湖...
- 产品推荐
- 这些文档可能帮助您