自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 业务架构 场景描述 客户在 IDC或者公有云环境自建 Hadoop集群 构建数据仓库和分析系统,购买阿里云 Databricks数据洞察集群之后,涉及到数仓数 据和元数据的迁移以及 Hive版本的订正更新。方案优势 1.全托管 Spark集群免运维,节省人力成 本。2.Databricks数据洞察...
数据总线Datahub
数据总线(DataHub)服务是阿里云提供的流式数据(Streaming Data)服务,它提供流式数据的发布(Publish)和订阅(Subscribe)的功能,拥有高吞吐量、高稳定性、低成本等特点,与阿里云大数据生态系统完美打通,让您可以轻松构建基于流式数据的分析和应用。
多样化的数据接入和同步能力,灵活的数据缓存及交互方式.强大的数据同步能力.<查看全部产品.数据总线(DataHub)服务是阿里云提供的流式数据(Streaming Data)服务,它提供流式数据的发布(Publish)和订阅(Subscribe)的功能,让您可以轻松构建基于流式数据的分析和应用.通过数据总线,您可以实时接入APP、WEB、IoT和数据库等...
来自:
云产品
数据可视化DataV
数据可视化DataV是阿里云一款数据可视化应用搭建工具,旨让更多的人看到数据可视化的魅力,帮助非专业的工程师通过图形化的界面轻松搭建专业水准的可视化应用,满足您会议展览、业务监控、风险预警、地理信息分析等多种业务的展示需求。
图形化交互逻辑编排,帮您快速构建数据时代人机交互界面.蓝图低代码交互搭建.数据大屏一键投屏、秒级切换,为数据汇报带来全新高性能体验.可视化演播厅.DataV-孪生仿真.自研真三维地理空间渲染引擎,真实复刻物理世界信息;自研国产化三维引擎.自研三维重建算法,超大规模三维孪生城市秒级重建.智能化三维重建能力.支持多源...
来自:
云产品
向量检索与通义千问搭建专属问答服务
本方案介绍如何使用向量检索服务(DashVector)结合通义千问大模型来打造基于垂直领域专属知识等问答服务。解决大模型本身在处理特定领域的知识表示和应用时的局限性。为企业提供部署简单,便于集成,实时高效,专业稳定的应用服务。
方案介绍向量检索与通义千问搭建专属问答服务通过文本向量模型将其转化为高质量低维度的向量数据,再写入DashVector向量检索服务。数据的向量化采用灵积模型服务上的Embedding API实现。将提问文本向量化后,通过DashVector提取相关知识点的原文。将相关知识点作为“限定上下文+提问”一起作为prompt询问通义千问。解决问题...
来自:
解决方案
跨链数据可信连接服务
跨链数据连接服务 ODATS 是利用蚂蚁区块链领先技术实现的跨链数据连接服务。通过制定标准化的区块链UDAG全栈跨链协议,保证跨链交易的安全性、可扩展性及可靠性,打破区块链数据孤岛,实现同构及异构链之间的可信互通,助力企业之间可信协作,促进产业生态可信融合。
UDAG全栈跨链协议对异构链兼容性友好,支持蚂蚁区块链与其他类型联盟链,私有链,公链双向互通,促进多机构跨行业的生态融合.远程与其他同构/异构...业务逻辑可以在区块链编程层可以实现,通过跨链合约API进行数据调用和合约交互,完成多条区块链的协作,达到区块链的横向应用拓展.默认色值为#ededed,添加后将覆盖默认色值.
来自:
云产品
跨链数据连接服务解决方案
利用蚂蚁区块链领先技术实现的跨链数据连接服务 Open Data Access Trusted Service(ODATS)。通过制定标准化的区块链UDAG全栈跨链协议,保证跨链交易的安全性、可扩展性及可靠性,打破区块链数据孤岛,实现同构及异构链之间的可信互通,助力企业之间可信协作,促进产业生态可信融合。
利用蚂蚁区块链领先技术实现的跨链数据连接服务,通过制定标准化的区块链UDAG全栈跨链协议,保证跨链交易的安全性、可扩展性及可靠性,打破区块链数据孤岛,实现同构及异构链之间的可信互通,助力企业之间可信协作,促进产业生态可信融合.跨链数据连接服务解决方案.大规模商用的溯源营销服务平台,利用区块链和物联网技术,...
来自:
解决方案
数据湖-在线学习场景数据分析

场景描述 本场景以在线教育中一个答题闯关类的应用为 例,使用WebServer来模拟演示这类日志数据 的分析处理。通过Nginx和Pythonflask搭建 WebServer,模拟应用中的关键页面,比如登 录、课程内容等,之后构造若干用户使用的模拟 日志数据,投递到数据湖进行分析后获取应用 PV、UV、课程内容访问排行、平均得分等等。 解决问题 基于数据湖(EMR+OSS)搭建大数据平台。 EMR和OSS使用和配置。 数据统一存储到OSS。 产品列表 E-MapReduce 对象存储OSS 云服务器ECS 访问控制RAM 专有网络VPC
通过Nginx和Pythonflask搭建WebServer,模拟应用中的关 键页面,比如登录、课程内容等,之后构造若干用户使用的模拟日志数据,投递到数 据湖进行分析后获取应用PV、UV、课程内容访问排行、平均得分等等。方案优势 支持超过10亿条元数据规模的数据管理,同时支持高可靠和高可用。 支持元数据实时备份和重建集群快速恢复...
智能语音交互
阿里云智能语音交互(Intelligent Speech Interaction),提供语音识别、语音合成、自然语言理解等基础技术,应用于智能客服、智能质检、庭审实时记录、实时演讲字幕、访谈录音转写等场景。提供自学习平台等应用工具,辅助实现语音识别效果的定制优化。语音交互产品可进行公共云和私有化部署,在金融、保险、司法、电商等多个领域均有成功应用案例。
基于真人录音数据,通过API接口即可完成声音克隆,音频无需切分、无需标注,数小时即可完成模型训练,尤其适合集成使用.基于自研声纹识别算法,通过解析一段语音,将提取到的音频特征与之前注册的音频特征进行比对,来对说话人身份进行核验(类似人脸识别).声音事件检测.实现对上传音频(实时或离线)中所说的是哪种语言...
来自:
云产品
基于Flink+ClickHouse构建实时游戏数据分析
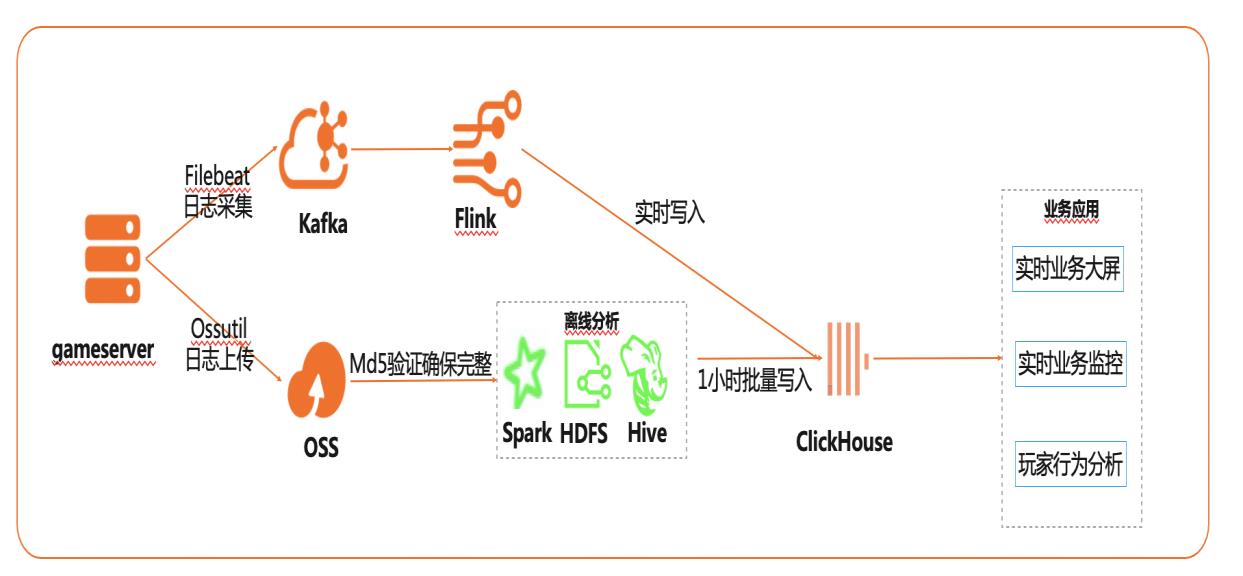
在互联网、游戏行业中,常常需要对用户行为日志进行分析,通过数据挖掘,来更好地支持业务运营,比如用户轨迹,热力图,登录行为分析,实时业务大屏等。当业务数据量达到千亿规模时,常常导致分析不实时,平均响应时间长达10分钟,影响业务的正常运营和发展。 本实践介绍如何快速收集海量用户行为数据,实现秒级响应的实时用户行为分析,并通过实时流计算Flink/Blink、云数据库ClickHouse等技术进行深入挖掘和分析,得到用户特征和画像,实现个性化系统推荐服务。 通过云数据库ClickHouse替换原有Presto数仓,对比开源Presto性能提升20倍。 利用云数据库ClickHouse极致分析性能,千亿级数据分析从10分钟缩短到30秒。 云数据库ClickHouse批量写入效率高,支持业务高峰每小时230亿的用户数据写入。 云数据库ClickHouse开箱即用,免运维,全球多Region部署,快速支持新游戏开服。 Flink+ClickHouse+QuickBI
结论:云数据库 ClickHouse更加适合海量数据分析型业务、大宽表聚合查询分析、数 据 Hash对齐 Join场景、实时日志分析场景等等 文档版本:20201224 6 基于 Flink+ClickHouse构建实时游戏数据分析 架构设计 2.架构设计 2.1.架构图 本实践主要以流处理为主线,搭建实验环境,构建在线用户行为分析平台:2.2.核心模块 游戏服...
EMR本地盘实例大规模数据集测试
场景描述 阿里云为了满足大数据场景下的存储需求,在云 上推出了本地盘D1机型,这个系列提供了本地 盘而非云盘作为存储,提高了磁盘的吞吐能力, 发挥Hadoop的就近计算优势。阿里云EMR 产品针对本地盘机型,推出了一整套的自动化运 维方案,帮助用户方便可靠地使用本地盘机型, 不需要关注整个运维过程同时数据的高可靠和 服务的高可用。 解决问题 1.云盘多份冗余数据导致成本高 2.磁盘吞吐量不高 3.节点的高可靠分布问题 4.本地盘与节点的故障监控问题 5.数据迁移时自动决策问题 6.自动故障节点迁移与数据平衡问题 产品列表 EMR(E-MapReduce) 本地盘 VPC
Master节点 通常可以生成 1TB的数据进行基准性能测试,首先进入 hive-testbench目录下执行如 下脚本并加载测试数据 参数说明:数据集规模参数单位为 GB,1000表示生成的数据量为 1TB/tpcdata/tpcds 为表数据生成的目录,目录不存在就自动生成,如果不指定目录,数 据目录就默认生成到/tmp/tpcds目录下 cd hive-testbench#如果...
云原生数据湖分析DLA
阿里云云原生数据湖分析是新一代大数据解决方案,采取计算与存储完全分离的架构,支持对象存储(OSS)、RDS(MySQL等)、NoSQL(MongoDB等)数据源的消息实时归档建仓,提供Presto和Spark引擎,满足在线交互式查询、流处理、批处理、机器学习等诉求。内置大量优化+弹性,比开源自建集群最高降低50%+的成本,最快可1分钟级拉起300个计算节点,快速满足业务资源要求。
数据湖分析采用Serverless形态,无基础设施和管理成本,互联网直接访问,开箱即用,按需付费,不需要长期持有分析成本,升级期间对业务影响小,产品迭代敏捷快速.Presto引擎.Presto引擎是数据湖分析基于Presto打造的交互式分析引擎,接入MySQL协议,可使用任何兼容MySQL协议的工具来进行数据分析,适合Adhoc查询、BI分析、...
来自:
云产品
数据安全解决方案
数据是企业的核心资产,如何保护企业的云上数据,是每个企业管理者都应当重视的课题。在云平台提供更为安全便捷的数据保护能力的同时,阿里云根据自身多年的经验积累,结合大量云上客户的最佳实践,提供了一套完整的数据安全解决方案,帮助企业提升云上数据风险防御能力,实现企业核心及敏感数据安全可控。
“终端”是各类实现数据采集、输入和使用的用户交互用设备,如APP、网页、应用程序等.数据安全中的“云管端”.安全能力“云、管、端”.数据采集阶段是组织内部系统中新产生数据,以及从外部系统收集数据的阶段。如何保证海量数据的安全可治理,是这一阶段的重点.数据采集阶段.数据安全中心服务.数据传输阶段是数据从一个...
来自:
解决方案
云Clickhouse冷热数据分层存储
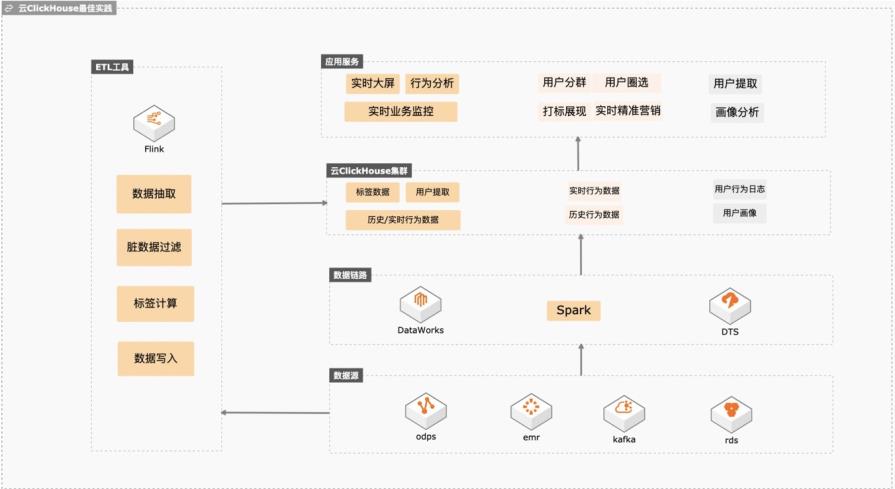
基于云ClickHouse可以给电商、游戏、互联网以及其他行业提供高性能、高稳定性、低维护成本、高性价比的实时数据分析、精准营销、业务运营、业务分析、业务预警、业务营销、数仓加速等场景化方案,本实践会向客户提供数据库低维护成本、数据库链路构建、冷热分层存储、快熟分析等操作实践。 解决问题 1. 维护成本低不用建设维护体系,稳定性高,数据倾斜自动均衡。 2. 完善的数据同步链路,可以平滑将业务库、大数据、日志服务的数据同步到Clickhouse,降低研发成本。 3. 平滑升级版本,业务中断小。 冷热分层后透明读取,帮客户节约整体数据存储成本。
云数据库 ClickHouse 冷热数据分层存储是一种更具性价比的单实例多类型并存的数 据存储方式,提供热数据存储和冷数据存储两种方式,以及不同数据存储介质之间的 转存策略。热数据指的是实时性查询要求高、访问频次较高的数据,采用 ESSD或高 效云盘存储,满足高性能访问的需求。冷数据指的是查询频度相对较低、访问频次较 ...
游戏数据运营融合分析
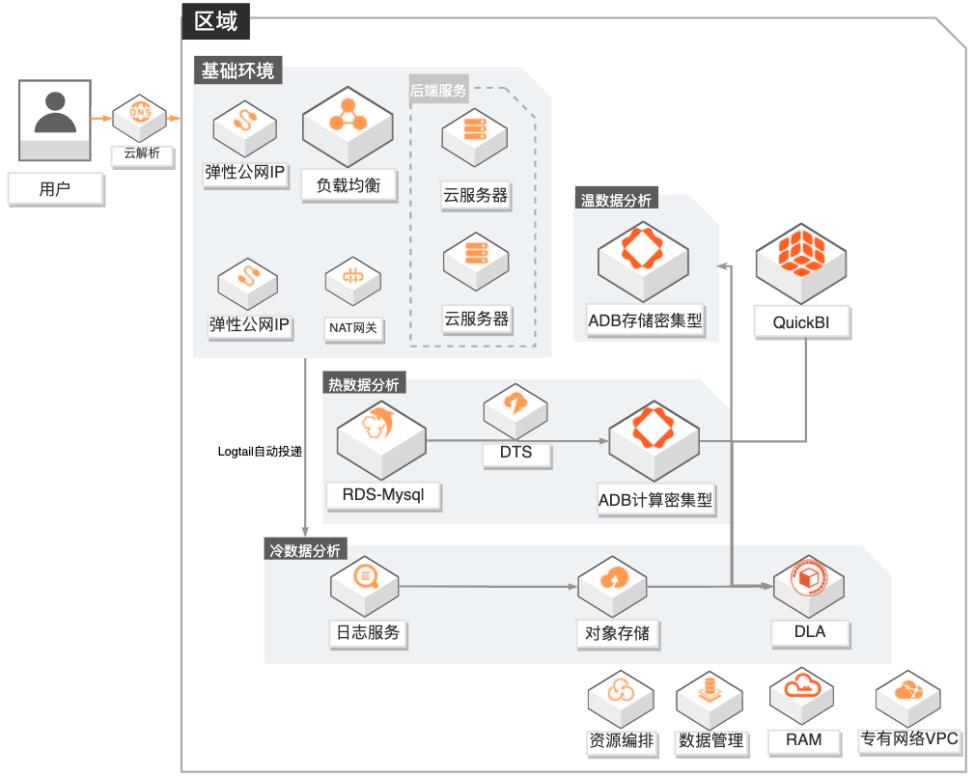
场景描述 1.游戏行业有结构化和非结构化数据融合分 析需求的客户。 2.游戏行业有数据实时分析需求的客户,无法 接受T+1延迟。 3.对数据成本有一定诉求的客户,希望物尽其 用尽量优化成本。 4.其他行业有类似需求的客户。 方案优势/解决问题 1.秒级实时分析:依托ADB计算密集型实例, 秒级监控DAU等数据,为广告投放效果提 供有力的在线决策支撑。 2.高效数据融合分析:打通结构化和非结构化 数据,支撑产品体验分析;广告买量投放效 果实时(分钟级)分析,渠道的评估更准确。 3.低成本:DLA融合冷数据分析+ADB存储密 集型温数据分析+ADB计算密集型热数据分 析,在满足各种分析场景需求的同时,有效 地降低的客户的总体使用成本。 4.学习成本低:DLA和ADB兼容标准SQL语 法,无需额外学习其他技术。 产品列表 专有网络VPC、负载均衡SLB、NAT网关、弹性公网IP 云服务器ECS、日志服务SLS、对象存储OSS 数据库RDSMySQL、数据传输服务DTS、数据管理DMS 分析型数据库MySQL版ADS 数据湖分析DLA、QuickBI
它底层的数据流基础设施为 文档版本:20210224 IV 游戏数据运营融合分析 前言 阿里双 11异地多活基础架构,为数千下游应用提供实时数据流,已在线上稳 定运行 5年之久。您可以使用数据传输轻松构建安全、可扩展、高可用的数据 架构。更多信息,请参见:help.aliyun.com/document_detail/26592.html RDS:云数据库 RDS MySQL...
大数据近实时数据投递MaxCompute
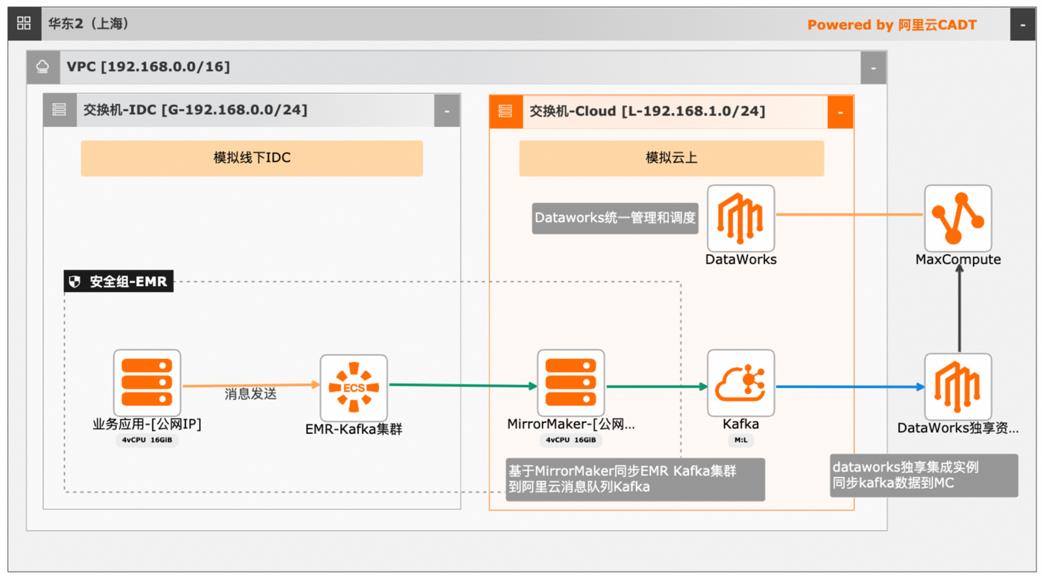
本文介绍离线大数据场景使MaxCompute构建云 上近实时数仓,打通云下数据上云链路,解决数据复杂类型支持和动态分区问题,满足高级数据处理需求的最佳实践。 l混合云环境下,现有业务系统零改造,打通数据上云链路。 l使用UDF实现复杂数据类型转换和数据动态分区。 l使用DataWorks配置周期调度业务流程,数据自动入仓。 l借助MaxCompute优化计算引擎,实现降本增效。 产品列表 云服务器ECS 专有网络VPC 访问控制RAM 数据总线DataHub E-MapReduceEMR DataWorks 大数据计算服务MaxCompute
上近实时数仓,打通云下数据上云链路,解决数据复 使用 UDF实现复杂数据类型转换和数据动态分 杂类型支持和动态分区问题,满足高级数据处理需求 区。的最佳实践。使用 DataWorks配置周期调度业务流程,数据自 产品列表 动入仓。借助 MaxCompute优化计算引擎,实现降本增 云服务器 ECS 效。云消息队列 Kafka 最佳实践频道 ...
Function Compute构建高弹性大数据采集系统
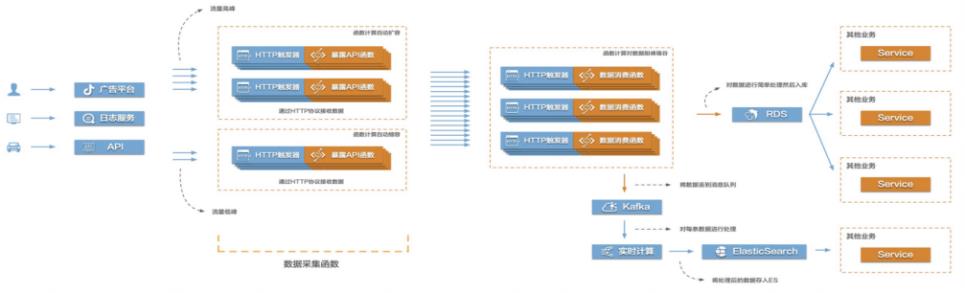
当前互联网很多场景都存在需要将大量的数据信息采集起来然后传输到后端的各类系统服务中,对数据进行处理、分析,形成业务闭环。比如游戏行业中的游戏发行、游戏运营,产互行业中的数字营销,物联网、车联网行业中的硬件、车辆信息上报等等。这些场景普遍存在数据采集量大、数据传输需要稳定且吞吐量大的特点,给整个数据采集传输系统带来很大的挑战。在这个场景中,有三个关键的环节,数据采集、数据传输、数据处理。该最佳实践主要涉
Function Compute构建高弹性大数据采集系统 最佳实践 业务架构 场景描述 当前互联网很多场景都存在需要将大量的数据 信息采集起来然后传输到后端的各类系统服务 中,对数据进行处理、分析,形成业务闭环。比 如游戏行业中的游戏发行、游戏运营,产互行业 中的数字营销,物联网、车联网行业中的硬件、车辆信息上报等等。这些...
- 产品推荐
- 这些文档可能帮助您