数据湖-在线学习场景数据分析

场景描述 本场景以在线教育中一个答题闯关类的应用为 例,使用WebServer来模拟演示这类日志数据 的分析处理。通过Nginx和Pythonflask搭建 WebServer,模拟应用中的关键页面,比如登 录、课程内容等,之后构造若干用户使用的模拟 日志数据,投递到数据湖进行分析后获取应用 PV、UV、课程内容访问排行、平均得分等等。 解决问题 基于数据湖(EMR+OSS)搭建大数据平台。 EMR和OSS使用和配置。 数据统一存储到OSS。 产品列表 E-MapReduce 对象存储OSS 云服务器ECS 访问控制RAM 专有网络VPC
通过Nginx和Pythonflask搭建WebServer,模拟应用中的关 键页面,比如登录、课程内容等,之后构造若干用户使用的模拟日志数据,投递到数 据湖进行分析后获取应用PV、UV、课程内容访问排行、平均得分等等。方案优势 支持超过10亿条元数据规模的数据管理,同时支持高可靠和高可用。 支持元数据实时备份和重建集群快速恢复...
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 业务架构 场景描述 客户在 IDC或者公有云环境自建 Hadoop集群 构建数据仓库和分析系统,购买阿里云 Databricks数据洞察集群之后,涉及到数仓数 据和元数据的迁移以及 Hive版本的订正更新。方案优势 1.全托管 Spark集群免运维,节省人力成 本。2.Databricks数据洞察...
数据迁移上云
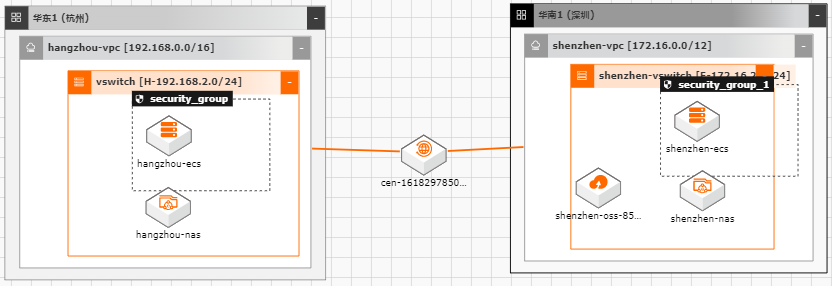
随着越来越多的企业选择将业务系统上云,各种类型的数据如何便捷、平滑的迁移上 云,成了用户上云较为关注的点;业务上云后,因为业务或者其他方面调整等因素, 也存在如跨区域,跨账号等数据迁移的场景。针对以上需求,阿里云上提供了较为丰 富的工具(如ossimport)、服务(在线迁移服务),旨在能够帮助客户便捷进行数据迁 移。 本文通过云架构设计工具CADT来快速创建云上基础资源,并以杭州区域来模拟线 下IDC(或友商),深圳区域模拟阿里云云上资源。通过云上的工具命令、服务来提 供常见数据迁移场景的最佳实践。
示例应用场景 线下 IDC数据 迁移至阿里云 OSS 线下 NAS数据迁移至阿里云 NAS 线上杭州区域 NAS数据通过 CEN迁 移至深圳区域 NAS 最佳实践频道 阿里云最佳实践分享群 云服务器 ECS(产品名称)文档模板(手册名称)/文档版本信息 阿里云 企业上云实践 数据迁移上云最佳实践 文档版本:20201013 文档版本:20150122(发布日期...
数据传输解决方案
数据传输解决方案支持关系型数据库、NoSQL、大数据(OLAP)等数据源间的数据传输。 它是一种集数据迁移、数据订阅及数据实时同步于一体的数据传输服务。数据传输致力于在公共云、混合云场景下,解决远距离、毫秒级异步数据传输难题。
DTS基于数据库日志监听解析的技术实现非侵入式的增量数据实时采集。可将MySQL,PostgreSQL、Oracle、DB2及SQLServer等数据库的增量日志实时采集,实现多种数据库的零停机上云迁移.支持多种数据库的零停机上云迁移.DTS可实现MySQL、Oracle、DRDS、PostgreSQL等多种数据源的实时同步,实现数据异地灾备。基于MySQL的实时双向...
来自:
解决方案
云原生数据湖分析DLA
阿里云云原生数据湖分析是新一代大数据解决方案,采取计算与存储完全分离的架构,支持对象存储(OSS)、RDS(MySQL等)、NoSQL(MongoDB等)数据源的消息实时归档建仓,提供Presto和Spark引擎,满足在线交互式查询、流处理、批处理、机器学习等诉求。内置大量优化+弹性,比开源自建集群最高降低50%+的成本,最快可1分钟级拉起300个计算节点,快速满足业务资源要求。
拥有优越弹性,支持元数据发现,支持多源一键数据实时入湖分析等功能,直接使用SQL即可分析OSS等数十种源数据.多项企业级能力,涵盖各类业务需求.GUI工具丰富.支持Microstrategy、MySQL Workbench、DBeaver等多种MySQL GUI管理工具.多种可视化工具支持.与QuickBI、Tableau、DataV等BI工具集成度高、兼容性好.兼容标准SQL....
来自:
云产品
数据可视化DataV
数据可视化DataV是阿里云一款数据可视化应用搭建工具,旨让更多的人看到数据可视化的魅力,帮助非专业的工程师通过图形化的界面轻松搭建专业水准的可视化应用,满足您会议展览、业务监控、风险预警、地理信息分析等多种业务的展示需求。
在线客服咨询.DataV数据可视化.DataV-数据看板产品文档.DataV-数据看板.DataV-孪生仿真产品文档.DataV-孪生仿真.DataV-可视分析卡片产品文档.DataV-可视分析卡片.DataV-可视分析地图产品文档.DataV-可视分析地图.DataV在业务数据可视化领域,通过丰富的可视化组件、低代码蓝图系统、AI设计辅助、多种数据源接入的能力,帮助...
来自:
云产品
云Clickhouse冷热数据分层存储
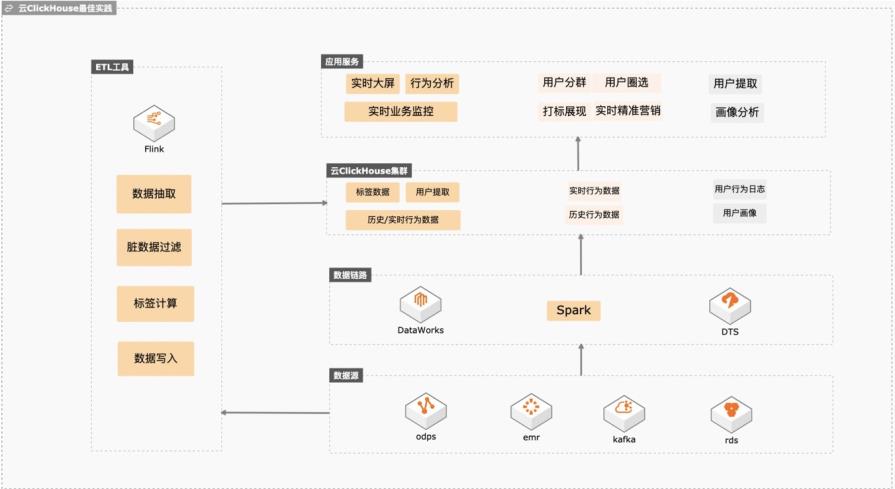
基于云ClickHouse可以给电商、游戏、互联网以及其他行业提供高性能、高稳定性、低维护成本、高性价比的实时数据分析、精准营销、业务运营、业务分析、业务预警、业务营销、数仓加速等场景化方案,本实践会向客户提供数据库低维护成本、数据库链路构建、冷热分层存储、快熟分析等操作实践。 解决问题 1. 维护成本低不用建设维护体系,稳定性高,数据倾斜自动均衡。 2. 完善的数据同步链路,可以平滑将业务库、大数据、日志服务的数据同步到Clickhouse,降低研发成本。 3. 平滑升级版本,业务中断小。 冷热分层后透明读取,帮客户节约整体数据存储成本。
热存可存储数据物理大小=云 ClickHouse集群磁盘 空间*(1-数 据 移 动 因 子),关 于 数 据 移 动 因 子描述 参 考:https://help.aliyun.com/document_detail/202879.html 通过该步骤创建一个宽表并写入大量数据,突破“热存可存储数据物理大小”,触发部 文档版本:20210416 42 云 ClickHouse冷热数据分层存储最佳实践 ...
企业上云数据安全
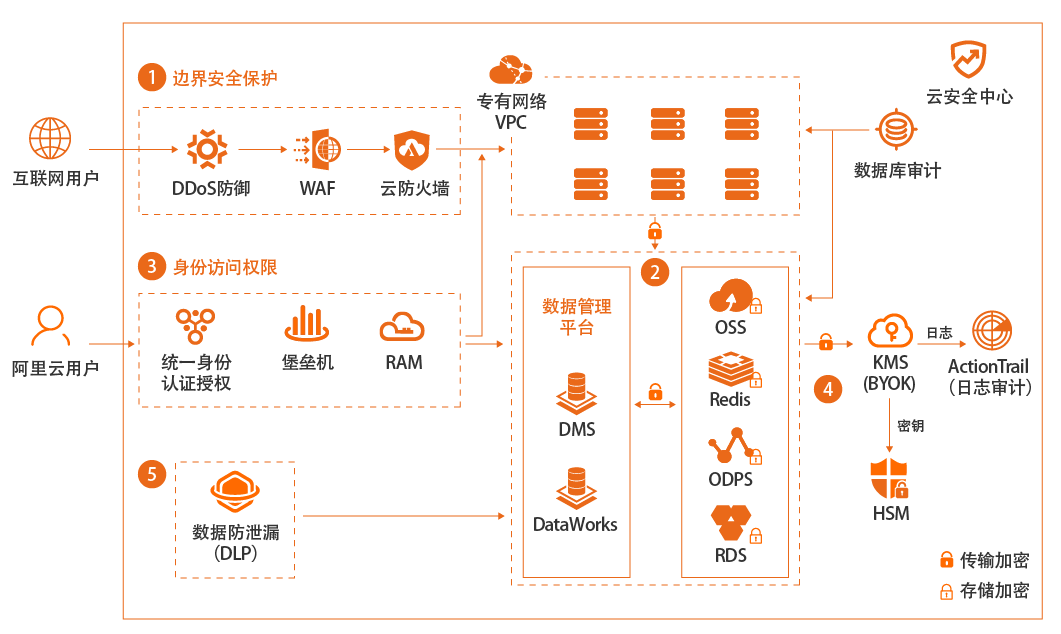
场景描述 企业是否选择上公共云,或者哪些系统或数据上 公共云,对数据安全的关心是重要因素之一。本 最佳实践重点在于介绍狭义的数据加密存储安 全范畴,即首先使用SDDP产品进行敏感数据发 现和分级分类,然后对高级别敏感数据进行按 需、不同类型的全链路加密存储。 解决问题 1.帮助客户发现敏感数据 2.对敏感数据进行分类、分级 3.对不同级别的数据如何选择加密方式 4.具体如何进行加密 产品列表 敏感数据识别SDDP 密钥管理服务KMS 云数据库RDS 对象存储OSS
本最佳实践重点在于介绍狭义的数据加密 存储安全范畴,即首先使用 SDDP产品进行敏 感数据发现和分级分类,然后对高级别敏感数 据进行按需、不同类型的全链路加密存储。解决问题 1.帮助客户发现敏感数据 2.对敏感数据进行分类、分级 3.对不同级别的数据如何选择加密方式 4.具体如何进行加密 产品列表 敏感数据识别 SDDP 密钥...
大数据近实时数据投递MaxCompute
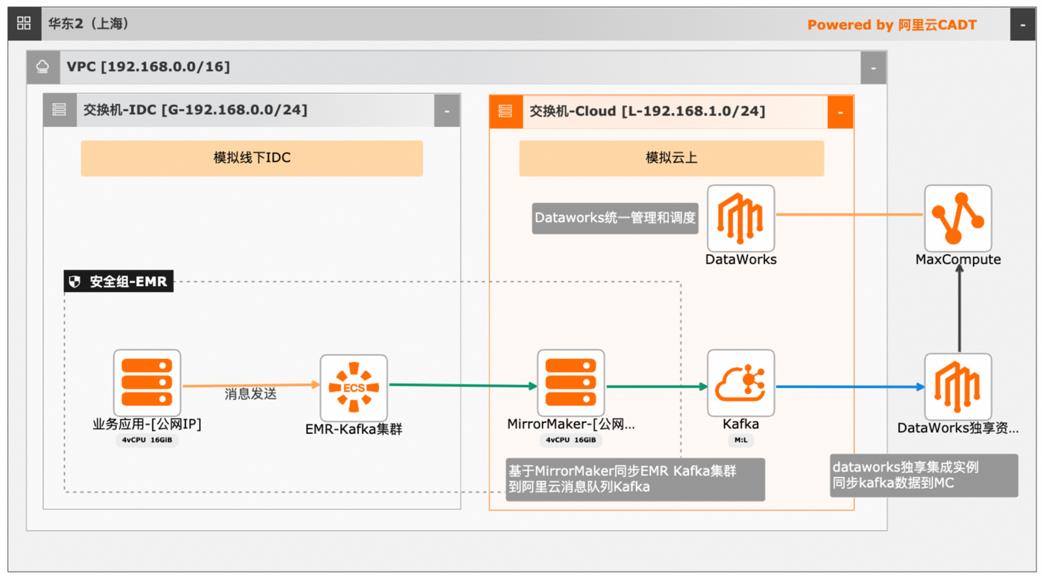
本文介绍离线大数据场景使MaxCompute构建云 上近实时数仓,打通云下数据上云链路,解决数据复杂类型支持和动态分区问题,满足高级数据处理需求的最佳实践。 l混合云环境下,现有业务系统零改造,打通数据上云链路。 l使用UDF实现复杂数据类型转换和数据动态分区。 l使用DataWorks配置周期调度业务流程,数据自动入仓。 l借助MaxCompute优化计算引擎,实现降本增效。 产品列表 云服务器ECS 专有网络VPC 访问控制RAM 数据总线DataHub E-MapReduceEMR DataWorks 大数据计算服务MaxCompute
文档版本:20240419 53 大数据近实时数据投递 MaxCompute 解析 tmp表数据至 final表节点周期实例列表界面,可以看到今天的周期实例已创 建,等待调度周期的时间后,定位到相应时间点,可以到到实例执行状态。在工作空间的数据开发界面,选择临时查询,打开之前创建的 ODPS SQL节点。文档版本:20240419 54 大数据近实时数据...
跨链数据可信连接服务
跨链数据连接服务 ODATS 是利用蚂蚁区块链领先技术实现的跨链数据连接服务。通过制定标准化的区块链UDAG全栈跨链协议,保证跨链交易的安全性、可扩展性及可靠性,打破区块链数据孤岛,实现同构及异构链之间的可信互通,助力企业之间可信协作,促进产业生态可信融合。
跨链数据连接服务 ODATS(Open Data Access Trusted Service)是利用蚂蚁区块链领先技术实现的跨链数据连接服务。通过制定标准化的区块链UDAG全栈跨链协议,保证跨链交易的安全性、可扩展性及可靠性,打破区块链数据孤岛,实现同构及异构链之间的可信互通,助力企业之间可信协作,促进产业生态可信融合.跨链数据连接服务 ...
来自:
云产品
DTS数据同步集成MaxCompute数仓
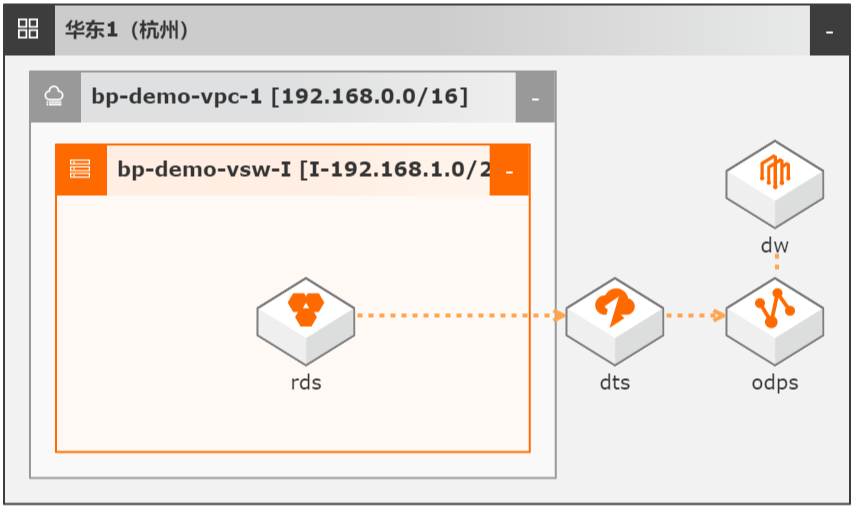
场景描述 本文Step by Step介绍了通过数据传输服务 DTS实现从云数据库RDS到MaxCompute的 数据同步集成,并介绍如何使用DTS和 MaxCompute数仓联合实现数据ETL幂等和数 据生命周期快速回溯。 解决问题 1.实现大数据实时同步集成。 2.实现数据ETL幂等。 3.实现数据生命周期快速回溯。 产品列表 MaxCompute 数据传输服务DTS DataWorks 云数据库RDS MySQL 版
数据抽取不幂等或容错率低,如凌晨 0:00启动的 ETL任务因为各种原因(数据库 HA切换、网络抖动或 MAXC写入失败等)失败后,再次抽取无法获取 0:00时的数 据状态。2.针对不规范设计表,如没有 create_time/update_time的历史遗留表,传统 ETL需 全量抽取。3.实时性差,抽取数据+重试任务往往需要 1-3小时。另外数据库的数据...
- 产品推荐
- 这些文档可能帮助您