云端影视渲染
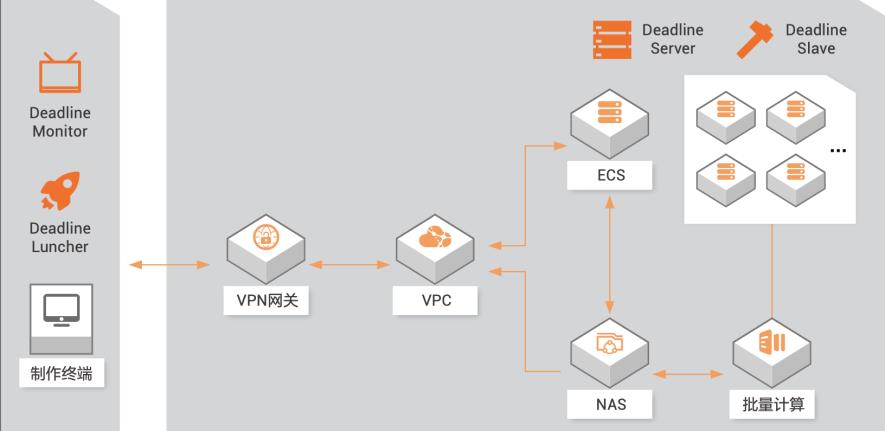
场景描述 本文介绍如何搭建一个完整的混合云渲染服务架构,本地与云端的网络以SSL-VPN方式进行互联。 解决问题 1、使用SSL-VPN构建本地网络与云上VPC环境的安全互联。 2、使用批量计算服务管理渲染计算集群,集群计算节点自动加入Deadline资源池。 3、使用Deadline做渲染任务管理。 4、批量计算集群计算节点根据Deadline渲染任务自动扩容和收缩,资源管理自动化。 产品列表 1、云服务器ECS 2、GPU云服务器GPU 3、批量计算BCS 4、专有网络VPC 5、弹性公网IP 6、文件存储NAS
4.批量计算集群计算节点根据 Deadline渲染 任务自动扩容和收缩,资源管理自动化。产品列表 云服务器 ECS GPU云服务器 GPU 批量计算 BCS 专有网络 VPC 弹性公网 IP EIP VPN网关 VPN 文件存储 NAS 阿里云最佳实践技术分享群 最佳实践频道 如二维码过期,请搜索群号:31852400 云服务器 ECS(产品名称)文档模板(手册名称)/...
EHPC药物筛选
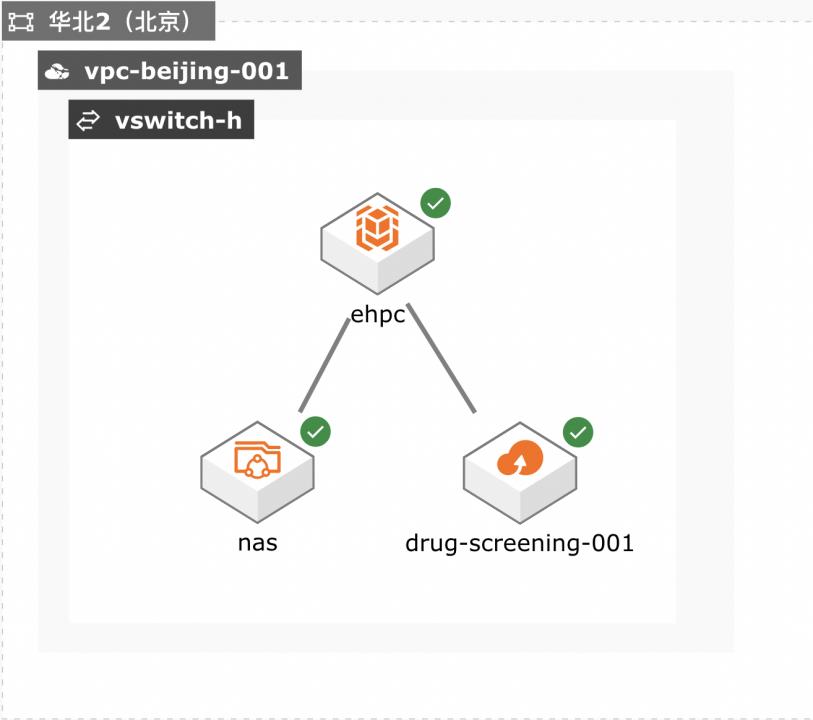
场景描述 本方案适用于使用弹性高性能计算 EHPC和文件存储NAS来搭建基础环 境,运行药物筛选应用AutodockVina 的场景中,这里采用批处理方式来提交 作业,并可以可视化计算结果。 方案架构 1.计算之前,将数据通过互联网/闪电立方/高速通道上传到阿里云OSS 2.计算时,将数据从OSS拉取到文件共享存储NAS上 3.计算时,在EHPC集群上进行,计算节点从NAS上读写数据 • 容量型NAS:低成本,大容量 • 性能型NAS:适合高IOPS应用,作为临时目录 • CPFS:适合超大规模,并行度极高的作业 4.计算节点: • 如果对计算时间不敏感,希望低成本运算,可选ECS实例 • 如果时效性要求高,建议采用SCC超级计算集群 5.可视化 • 如果可视化部分计算量不大,可以采用EHPC自带的可视化服务 解决问题 1.使用EHPC运行药物筛选应用 2.使用nas存储计算数据 3.使用OSS保存计算结果 • 通过分子对接(moleculardocking)模拟计算进行药物筛选,是模拟小分子配体和生物大分子受体的 相互作用,预测配体和受体的结合模式和亲和力。 • 通常,有很多已有的配体库,如商业化的Specs、Enamine和ChemDiv化合物库。提供大量配体,模 拟计算就是计算这些配体和给定受体的相互作用。 • 每次模拟计算通常处理一个配体和一个受体,不同配体之间没有依赖,因此可以同时大规模并行处 理。 本解决方案同样适用于有批量、高并发处理需求的其它生物、医药等场景。 产品列表 弹性高性能计算E-HPC 文件存储NAS 对象存储OSS
http://vina.scripps.edu/ Vina 使用 demo:http://vina.scripps.edu/tutorial.html 我们 EHPC 集 群 使 用 的 Linux CentOS 7.6 的 操 作 系 统,下 载 对 应 的 Vina 版 本:http://vina.scripps.edu/download/autodock_vina_1_1_2_linux_x86.tgz MGLTools 包括 AutoDock Tools(ADT)和 Python Molecular Viewer(PMV)。...
EHPC混合云渲染
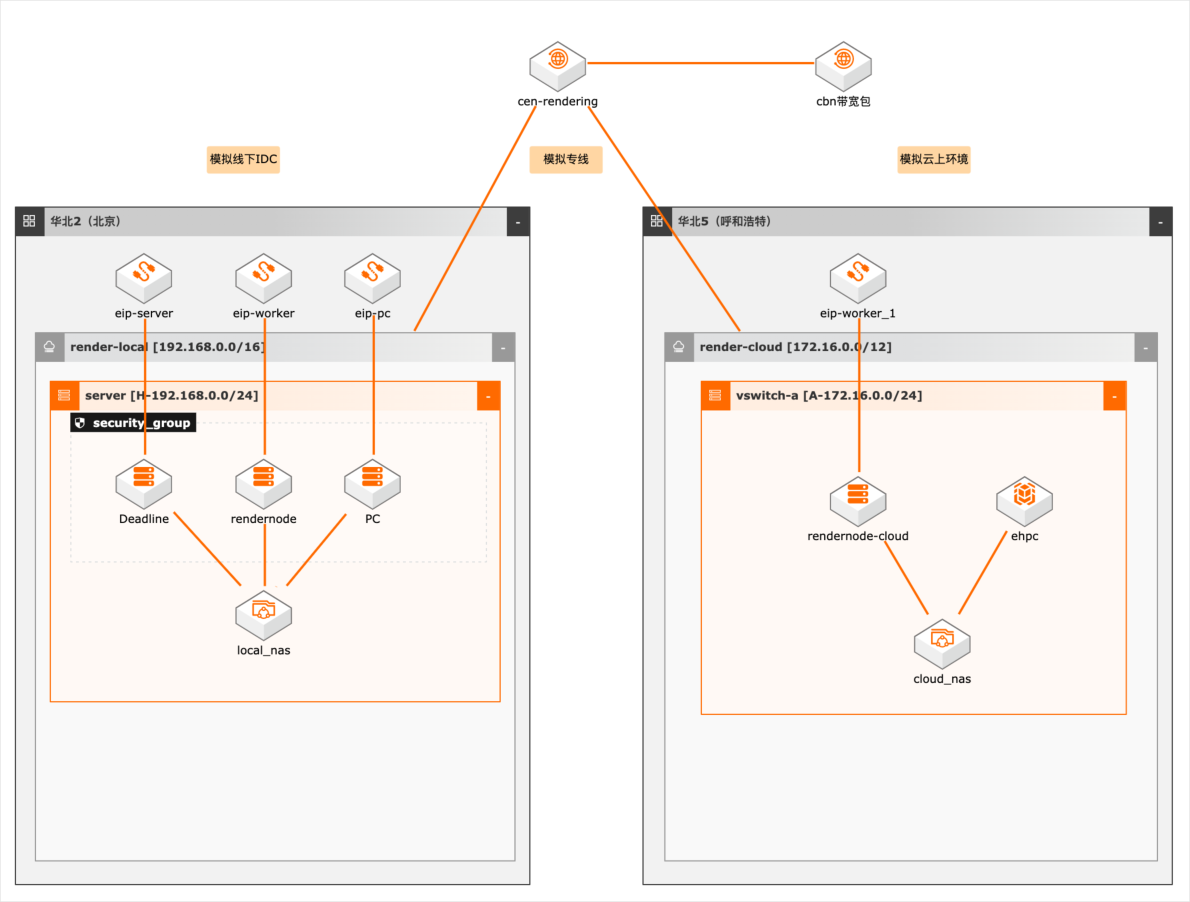
介绍在混合云环境下,利用E-HPC及其文件缓存机制,无缝读取线下存储中的项目资产,免去复杂繁琐的文件同步问题;充分利用云上资源弹性、按使用付费的优势,构建高性能、高可靠和可扩展的渲染服务。 解决问题 l混合云环境下本地集群与云端集群一体化的渲染服务。 l避免繁琐复杂的本地与云端的文件同步问题。 l低成本、高效率应对渲染业务峰值。 产品列表 l云服务器、GPU云服务器 l高性能计算E-HPC l专有网络VPC l云企业网CEN l弹性公网IP EIP l访问控制RAM l文件存储NAS
E-HPC缓存机制使用云 NAS作为缓存存储层,使得云上计算集 群可以直接挂载云下 NAS存储,按需读取所需的场景数据,解决了云端渲染需要将 场景数据先行同步到云端复杂、繁琐的问题;同时云上计算集群优先从缓存层读取数 据,大幅降低对云上云下网络互联链路的带宽需求。整体架构 文档版本:20220325 1 E-HPC混合云渲染最佳...
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
自定义 HDFS Sink.47 文档版本:20201020 IV 基于 Dataworks的大数据一站式开发及数据治理 最佳实践概述 最佳实践概述 概述 本实践基于 Dataworks做大数据一站式开发,包含数据实时采集到 kafka通过实时计 算对数据进行 ETL写入 HDFS,使用 Hive进行数据分析。通过 Dataworks进行数据 治理,数据地图查看数据信息和血缘关系...
数据湖-在线学习场景数据分析

场景描述 本场景以在线教育中一个答题闯关类的应用为 例,使用WebServer来模拟演示这类日志数据 的分析处理。通过Nginx和Pythonflask搭建 WebServer,模拟应用中的关键页面,比如登 录、课程内容等,之后构造若干用户使用的模拟 日志数据,投递到数据湖进行分析后获取应用 PV、UV、课程内容访问排行、平均得分等等。 解决问题 基于数据湖(EMR+OSS)搭建大数据平台。 EMR和OSS使用和配置。 数据统一存储到OSS。 产品列表 E-MapReduce 对象存储OSS 云服务器ECS 访问控制RAM 专有网络VPC
借助EMR 可以简单快速的构建一个基于 Hadoop,Spark,Hive等大数据产品的计算集群,而且可以按需使用,其所有 Job完 文档版本:20200331 5数据湖-在线学习场景数据分析 数据湖 成之后,销毁集群,因为所有的数据都保存在OSS。此外,对于Hadoop集群上的任务,不同类型的任务对于机器配置的要求不同,比如 推荐和算法业务可能...
CDH迁移升级CDP最佳实践
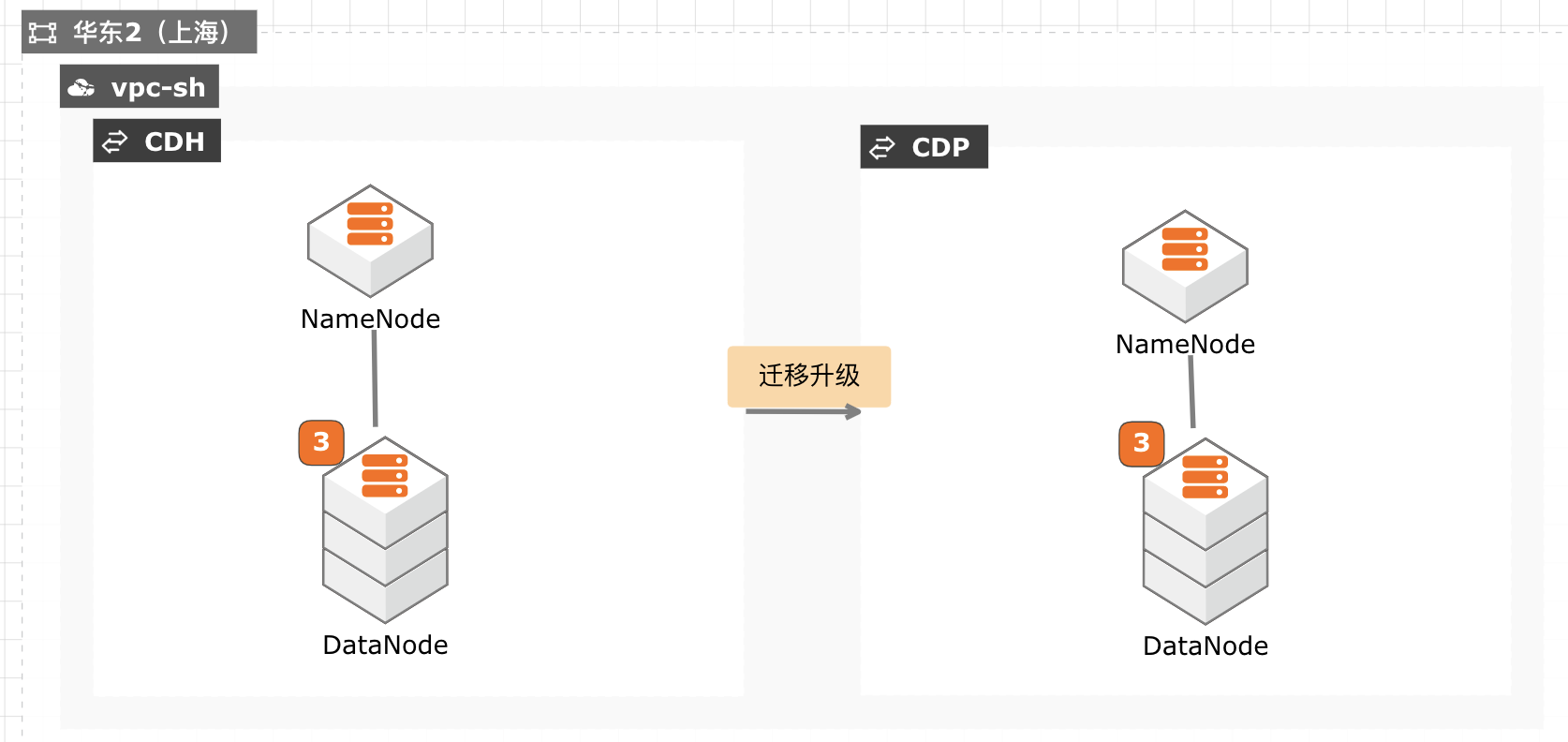
当前 CDH 免费版停止下载,终止服务,针对需要企业版服务能力并且CDH 升级过程对业务影响较小的客户,通过安装新的 CDP 集群,将现有数据拷贝至新集群,然后将新集群切换为生产集群,升级过程没有数据丢失风险,停机时间较短,适合大部分互联网客户升级使用。
否则,您的 计算集群队列配置将丢失,因为升级向导仅转换来自您的基本集群的队列。1.在 Cloudera Manager 中,导航到 Host>All Hosts。2.找到具有 ResourceManager 角色的主机,然后单击 YARN ResourceManager 角色。3.单击进程选项卡。文档版本:20211029 111 CDH迁移升级 CDP最佳实践 组件迁移 4.查找和保存 fair-...
专有宿主机DDH
专有宿主机提供基于阿里云虚拟化托管、物理主机独享的单租户环境、通过独享硬件资源方式可以满足安全、合规、自定义部署、自带许可证(BYOL)需求,在专有宿主机上可以创建多种规格的ECS实例,继承了ECS实例的规格选择灵活、性能稳定的优点和特性。
满足大型企业对于计算集群的灵活管理要求,分部门、业务制定不同资源使用方式.将多台DDH划分为不同集群的方式进行管理,实现不同部门,不同业务之间的资源隔离、成本隔离、风险隔离.自动部署功能可帮您自动选择一台有空闲资源的DDH宿主机部署ECS实例。减少手动选择的难度.支持将一台ECS实例在不同DDH之间的自由迁移,也包括...
来自:
云产品
触手可及,函数计算玩转 AI 大模型
AI的时代下,大模型类型丰富、功能强大,正推动着各行各业的智能化转型和创新突破。企业纷纷寻求部署自己的大模型,以满足特定业务需求,从而在激烈的市场竞争中获得优势。本方案介绍通过阿里云函数计算的按量付费、卓越弹性、快速交付能力,助力企业快速部署 AI 大模型。
极致弹性,按量付费 可调动大规模 GPU 集群资源,达到秒级弹性伸缩,轻松应对各种突发流量。按请求计费,毫秒计费粒度,只为实际使用资源付费。拥抱开源,助力创新 支持 Model Scope、Hugging Face 开源模型快捷部署,助力AI创新应用加速落地。方案架构 如何通过函数计算部署 AI 大模型 利用函数计算的无服务器架构,选择...
来自:
技术解决方案
智能应对流量变化,容器化集群的弹性攻略
本方案使用应用型负载均衡和容器服务Kubernetes版智能分配网络流量,提高应用的高可用性和吞吐量,使用Kubernetes的cluster-autoscaler社区开源组件以及Kubernetes的Horizontal Pod Autoscaler内置组件进行弹性伸缩,提升资源利用率,缩减资源成本。
导致费用有所变化,请以控制台显示的实际报价以及最终账单为准)容器服务Kubernetes版 负载均衡 日志服务 专有网络VPC ACK支持节点伸缩弹性和Pod伸缩弹性 在 Kubernetes(K8s)环境中,Pod是最小的部署单位,它代表着集群中可以被创建和管理的最小的可部署计算实例,一个Pod由一个或多个容器(例如 Docker 容器)组成,这些...
来自:
技术解决方案
云原生数据仓库 AnalyticDB 产品功能
阿里云云原生数据仓库AnalyticDB提供数据库生态兼容、高性价比和极致分析性能,具有稳定可靠、弹性扩展等性能特征,帮助企业打造全场景覆盖的一站式数据分析平台。
备份恢复AnalyticDB MySQL集群创建后会自动在后台开启数据备份功能,实现集群级别的数据备份,还支持通过源集群的已有备份克隆新集群。智能诊断AnalyticDB MySQL提供一键诊断、数据建模诊断、SQL Pattern、SQL诊断、库表结构优化等能力,能够显著提升查询性能。易适配,免调优AnalyticDB 支持SQL 2003,部分兼容Oracle语法...
来自:
云产品
基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步
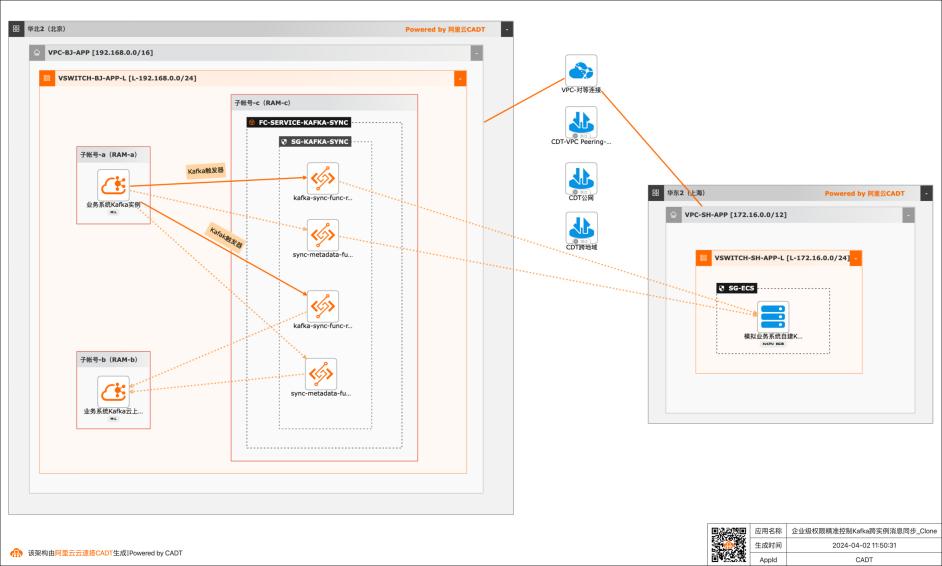
应用场景 在大数据场景,企业的Kafka实例可能存在多种情况,比如使用阿里云Kafka服务,可能是自建开源Kafka,或者是其他云上的云Kafka。不同的业务使用不同类型的Kafka实例,在这个前提下Kafka实例之间可能会需要消息同步的情况: 同帐号容灾场景:比如Kafka实例都是阿里云Kafka,但是Kafka实例会有主备之分,需要将主Kafka实例的消息实时同步到备Kafka。 跨帐号或异地容灾:这类场景比如主Kafka是阿里云Kafka,备Kafka是IDC开源自建Kafka,或者是其他云上的Kafka。 不同业务之间消息同步:因为现在的业务通常不会是信息孤岛,都需要消息互通,所以可能是A业务的Kafka实例消息需要同步到B业务的Kafka实例,并且这两个Kafka实例归属不同的RAM角色,有自己独自的权限控制。 解决问题 解决使用开源组件做消息同步的高成本问题。 解决使用开源组件做消息同步的并发性能、稳定性问题。 解决使用开源组件做消息同步的可靠性问题(重试机制,容错机制,死信队列等)。 大幅提升构建消息同步架构的效率,降低构建复杂度问题。
使用函数计 算,您无需采购与管理服务器等基础设施,只需编写并上传代码或镜像。函数计算为您准 备好计算资源,弹性地、可靠地运行任务,并提供日志查询、性能监控和报警等功能。 云消息队列Kafka 版:云消息队列Kafka 版是阿里云提供的分布式、高吞吐、可扩展的 消息队列服务。云消息队列Kafka版广泛用于日志收集、监控...
一键训练大模型及部署GPU共享推理服务
通过创建ACK集群Pro版,使用云原生AI套件提交模型微调训练任务与部署GPU共享推理服务。支持快速创建Kubernetes集群,白屏配置任务数据共享存储和下载,并通过命令行工具Arena快速提交模型训练任务、部署推理服务。使用云原生AI套件可以让模型训练和推理提效,提高GPU资源利用率。
通过创建ACK集群Pro版,使用云原生AI套件提交模型微调训练任务与部署GPU共享推理服务。支持快速创建Kubernetes集群,白屏配置任务数据共享存储和下载,并通过命令行工具Arena快速提交模型训练任务、部署推理服务。使用云原生AI套件可以让模型训练和推理提效,提高GPU资源利用率。一键训练大模型及部署GPU共享推理服务 通过...
来自:
技术解决方案
RDS MySQL迁移至PolarDB MySQL版
通过本方案,RDS MySQL的数据可在线实时同步到PolarDB MySQL版,并且升级切换后的PolarDB集群包含源RDS实例的账号信息、数据库、IP白名单和必要的参数。这样可实现不修改应用代码的情况下,将RDS MySQL数据库迁移升级至PolarDB MySQL版。
通过本方案,RDS MySQL...数据强一致性保证,满足金融级可靠性要求 PolarDB采用存储和计算分离的架构,支持秒级故障恢复、数据一致性和数据备份容灾等。优惠购买 阿里云为你推荐优惠购买云产品 优惠购买 10000011758 10000012051 10000012320 10000001502 免费试用 10000011871 10000005512 968649 推荐解决方案 推荐解决方案
来自:
技术解决方案
开源大数据平台 E-MapReduce 选型与定价
阿里云开源大数据平台 E-MapReduce 提供包年包月、按量付费两种计费方式,支持阿里云抢占式实例、预留实例券(RI)、混合计费等多种成本优化手段压缩成本支出。了解开源大数据平台 E-MapReduce 定价策略,持续管控和优化成本。
查看详情EMR on ACK根据集群实际使用的 POD 资源规格和数量,计算每小时需支付的服务费。查看详情EMR Serverless StarRocks支持包年包月和按量付费两种计费方式,计费项由计算CU费用、存储费用、BE费用(BE规格类型为高性能或大规格存储时)构成。查看详情EMR Serverless Spark 支持按量付费,按实际消耗的计算资源付费。...
来自:
云产品
- 产品推荐
- 这些文档可能帮助您