自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
详见:https://www.aliyun.com/product/oss Hive:Apache Hive是基于 Hadoop的一个数据仓库工具,可以将结构化的数据 文件映射为一张数据库表,并提供简单的 SQL查询功能,可以将 SQL语句转换 为 MapReduce任务进行运行。其优点是学习成本低,可以通过类 SQL语句快速 实现简单的 MapReduce统计,不必开发专门的 MapReduce...
自建Hive数仓迁移到阿里云EMR
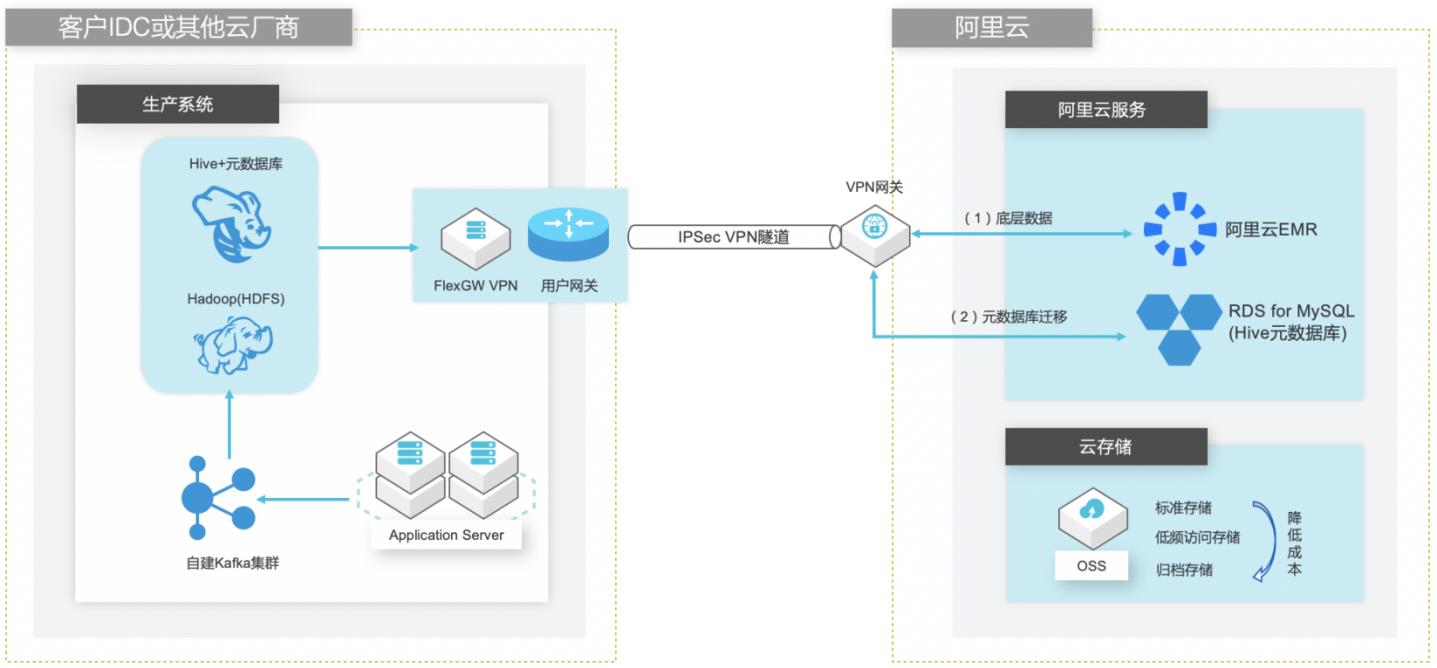
场景描述 客户在IDC或者公有云环境自建Hadoop集群构 建数据仓库和分析系统,购买阿里云EMR集群之 后,涉及到将数据仓库和Hive元数据的数据库迁 移上云。目前主流Hive数据仓库迁移场景为1.x 版本迁移到阿里云EMR(Hive2.x版本),涉及到 数据订正更新步骤。 解决的问题 Hive数据仓库的数据迁移方案 Hive元数据库的迁移方案 Hive跨版本迁移后的数据订正 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
名词解释 Hive Apache Hive是基于 Hadoop的一个数据仓库工具,可以将结构化的数据文件映 射为一张数据库表,并提供简单的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce任务进行运行。其优点是学习成本低,可以通过类 SQL语句快速实 现简单的 MapReduce统计,不必开发专门的 MapReduce应用,十分适合数据仓 库的统计分析...
MaxCompute湖仓一体方案
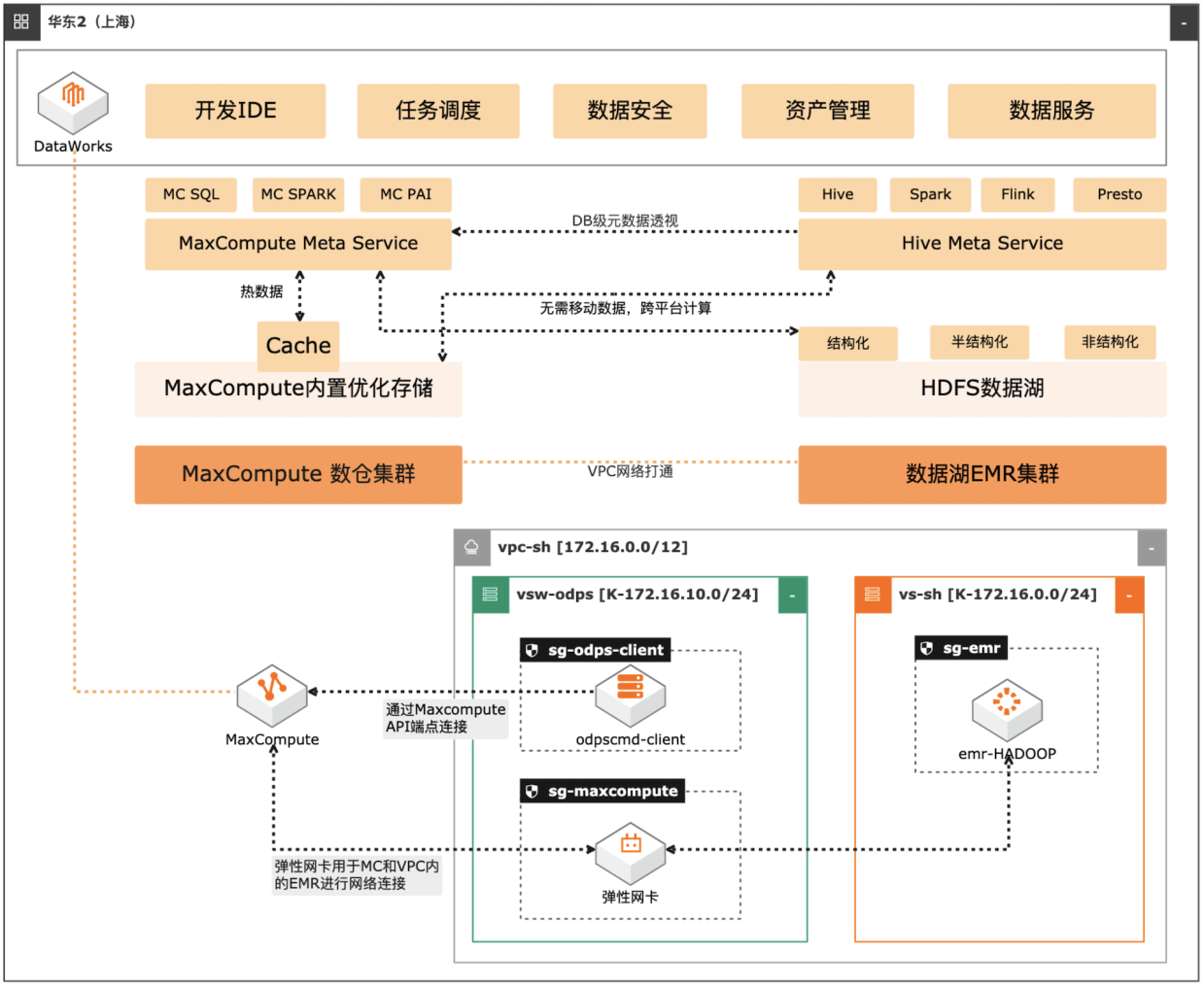
场景描述 自建数据湖与云数仓的融合解决方案,将 MaxCompute与自建的Hive集群做数据打 通,通过存储共享,元数据镜像等方式,解 决传统模式下的存储冗余,计算资源弹性能 力弱的痛点。可大幅度增强系统的资源弹 性,解决业务高峰期计算资源不足的问题。 方案优势 1.业务无侵入性:现有业务无需改造。 2.性能优化:MaxCompute在SQL上做 了大量优化与能力沉淀,可提高SQL 运行性能,降低计算成本。 3.灵活管理:元数据实时同步,无需额外 管理数据同步任务。 4.资源弹性:利用MaxCompute计算池 弹性进行海量数据计算。 解决问题 1.增强业务高峰期的资源弹性。 2.优化自建数据湖的数据治理能力。 3.减少跨平台数据处理的存储冗余。 产品列表 专有网络VPC 云服务器ECS 访问控制RAM 运维编排OOS MaxCompute(原ODPS) 云企业网CEN
Apache Hive:Apache Hive是基于 Hadoop的一个数据仓库工具,可以将结构化 的数据文件映射为一张数据库表,并提供简单的 SQL查询功能,可以将 SQL语 句转换为 MapReduce任务进行运行。其优点是学习成本低,可以通过类 SQL语 句快速实现简单的 MapReduce统计,不必开发专门的 MapReduce应用,十分适 合数据仓库的统计分析。...
开源大数据平台 E-MapReduce 技术解决方案
阿里云开源大数据平台 E-MapReduce 技术解决方案,帮助您快速了解如何利用这款弹性伸缩、存算分离的企业级大数据平台服务来提升业务效率,降低成本。
应用场景基于开源生态构建大数据分析支撑 Hadoop 开源生态构建大数据分析方案,解决了传统 Hadoop 在扩展性、运维模式、成本优化方面的难题,覆盖离线分析、交互式查询、流式处理等多个数据管理场景,支持多种数据通道,全面覆盖日志、消息、数据库、HDFS 各种数据源接入。海量数据冷热分层大数据场景中有大量数据累积,...
来自:
云产品
开源大数据平台 E-MapReduce 产品概述
开源大数据平台 E-MapReduce是阿里云提供的云原生开源大数据平台,支持多种主流开源大数据组件,具备灵活弹性的资源调度和控制能力。适用于PB 级数据处理、交互分析和机器学习,帮助客户高效构建云端企业级数据湖技术架构。
EMR on ECSE-MapReduce Serverless StarRocks 版了解更多02猿辅导为了应对不同的业务场景,我们希望能够有一个引擎,可以完成在 AP 场景下的统一,这时就发现了 StarRocks,StarRocks 借助于它本身优秀的向量化引擎的能力,能够在大部分场景下性能提升显著,因此我们决定将更多的场景基于 StarRocks 来做。猿辅导大数据平台...
来自:
云产品
开源大数据平台 E-MapReduce 相关资源
阿里云大数据平台 E-MapReduce 提供详细的产品文档,面向开发者提供全方位的服务,有免费的实验课程和解决方案体验馆,帮助您快速上手。在阿里云 E-MapReduce 开发者社区,您可以和更多开发者交流。
查看详情前往帮助文档社区内容甄选基于EMR Serverless StarRocks一键玩转世界杯基于EMR离线数据分析数据湖构建DLF快速入门技术交流内容分类:博文问答电子书阿里云 EMR Serverless StarRocks OLAP 数据分析场景解析 阿里云 E-MapReduce Serverless StarRocks 版是阿里云提供的 Serverless StarRocks 全托管服务,提供高性能...
来自:
云产品
开源大数据平台 E-MapReduce 产品功能
阿里云开源大数据平台 E-MapReduce 为客户提供简单易集成的Hadoop、Hive、Spark、StarRocks、Flink、Presto、ClickHouse等开源大数据计算和存储引擎。EMR计算资源支持灵活的弹性控制。EMR支持on ECS、on ACK以及Serverless多种部署形态。
您现在可以修改在 EMR 集群上运行的应用程序的配置,包括 Apache Hadoop、Apache Spark、Apache Hive 和 Hue,而无需重新启动集群。EMR 应用程序重新配置功能让您可以即时修改应用程序,而无需关闭或重新创建集群。Amazon EMR 将应用您的新配置,并正常重启重新配置的应用程序。便捷集成您可以通过控制台、软件开发工具包或...
来自:
云产品
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
实时计算:实时计算(Alibaba Cloud Realtime Compute,Powered by Ververica)是阿里云提供的基于 Apache Flink 构建的企业级大数据计算平台。在 PB 级别 的数据集上可以支持亚秒级别的处理延时,赋能用户标准实时数据处理流程和行 业解决方案;支持 Datastream API 作业开发,提供了批流统一的 Flink SQL,简 化 BI 场景...
自建Hadoop迁移MaxCompute
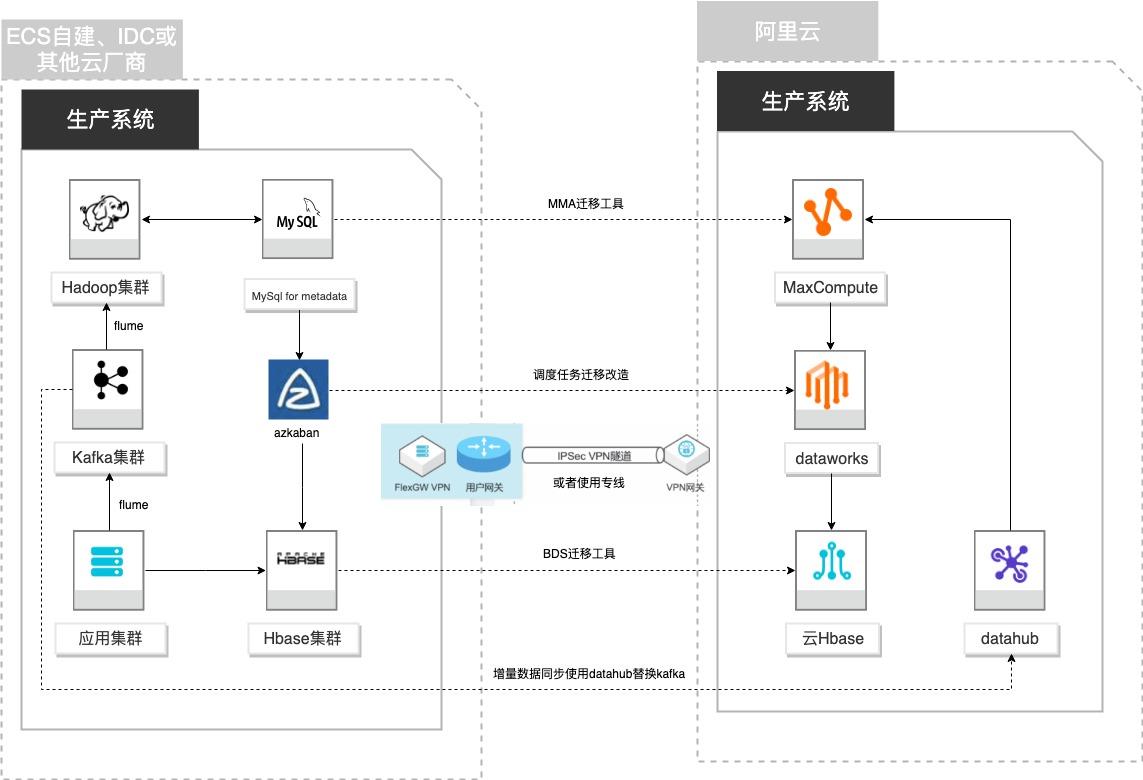
场景描述 客户基于ECS、IDC自建或在友商云平台自建了大数 据集群,为了降低企业大数据计算平台的成本,提高 大数据应用开发效率,更有效保障数据安全,把大数 据集群的数据、作业、调度任务以及业务数据库整体 迁移到MaxCompute和其他云产品。 解决的问题 自建Hadoop集群搬迁到MaxCompute 自建Hbase集群搬迁到云Hbase 自建Kafka或应用数据准实时同步到 MaxCompute 自建Azkaban任务迁移到Dataworks任务 产品列表 MaxCompute,Dataworks、云数据库Hbase版、Datahub、VPC,ECS。
Kafka 的目的是通过 文档版本:20210723 III 自建Hadoop迁移MaxCompute 前言 Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提 供实时的消息。Flume Flume是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日 志数据。它具有基于流数据流的简单灵活的体系结构。它具有可调整的可靠性...
自建Hadoop迁移到阿里云EMR
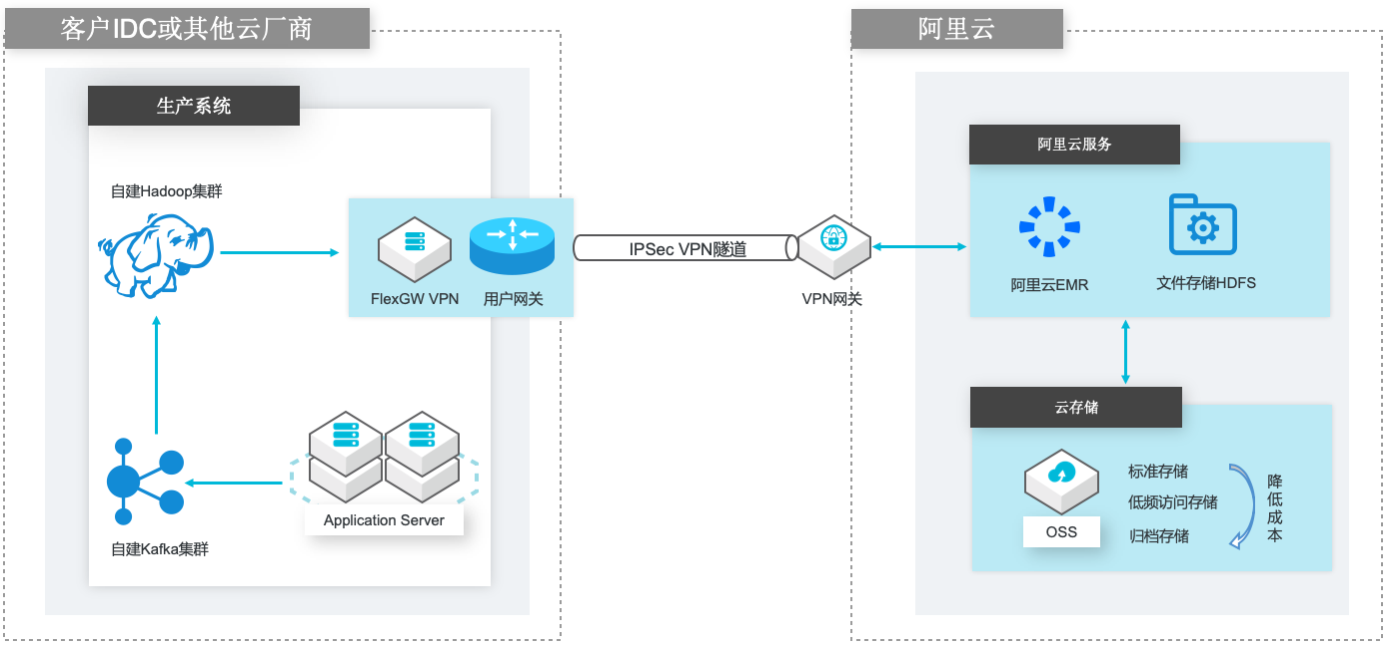
场景描述 场景1:自建Hadoop集群数据(HDFS)迁移到 阿里云EMR集群的HDFS文件系统; 场景2:自建Hadoop集群数据(HDFS)迁移到 计算存储分离架构的阿里云EMR集群,以OSS 和JindoFS作为EMR集群的后端存储。 解决的问题 客户自建Hadoop迁移到阿里云EMR集群的 技术方案; 基于IPSecVPN隧道构建安全和低成本数据 传输链路 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
将这些预配置好的配置文件复制到 Hadoop的 etc目录下覆盖 已有文件即可:cp-r/usr/local/hadoop-2.10.1/etc/hadoop/usr/local/hadoop-2.10.1/etc/hadoop_bak cp-rf*/usr/local/hadoop-2.10.1/etc/hadoop/文档版本:20210714 19 自建Hadoop数据迁移到阿里云 EMR 自建 Hadoop集群环境搭建 提示需要覆盖文件时输入 y进行确认。...
中小企业自建Hadoop集群上云解决方案
中小企业自建 Hadoop 集群上云解决方案,助力自建 Hadoop 用户快速构建云上半托管开源大数据平台,在保持原组件使用习惯延续的同时,充分利用云上服务特点,更加便捷地迭代企业大数据平台架构,聚焦业务价值开发。
基于阿里云 E-MapReduce、OSS、边缘网络加速等产品及服务,帮助自建 Hadoop 用户快速构建云上半托管开源大数据平台,在保持原自建 Hadoop 组件使用习惯延续的同时,充分利用云上服务特点,更加便捷地迭代企业大数据平台架构,聚焦业务价值开发.谢赟辉,靖鑫,也树.中小企业自建Hadoop集群上云解决方案.本方案核心产品延续开源...
来自:
解决方案
基于弹性供应组构建大数据分析集群
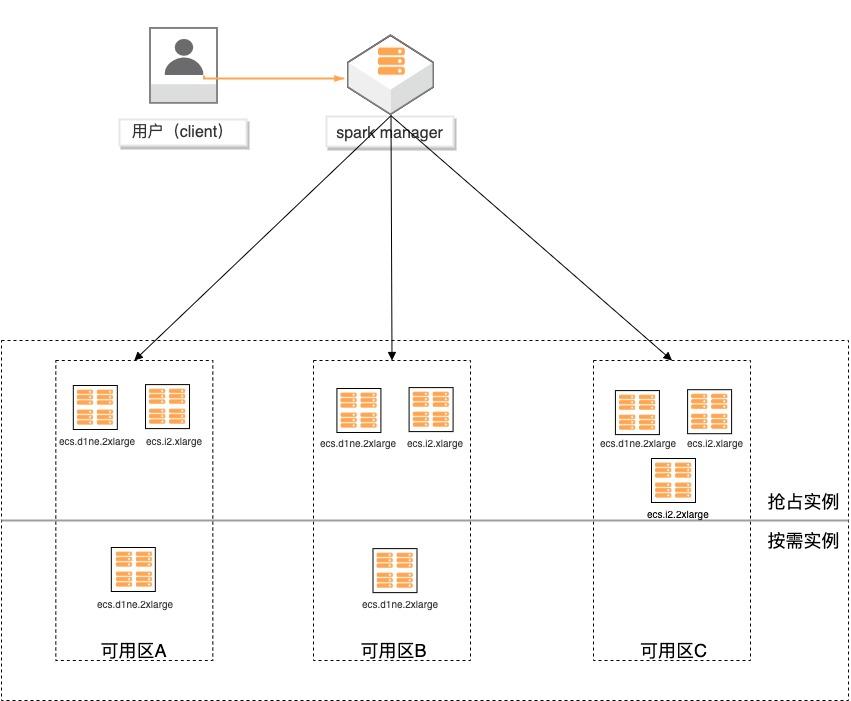
场景描述 基于弹性供应组(APG)搭建spark计算集 群,提供一键开启跨售卖方式、跨可用区、 跨实例规格的计算集群交付模式的实践。 方案优势 1.超低成本:跨售卖方式提供计算实 例,按秒计费,可全部使用spot实例 交付,最高可省90%成本。 2.稳定可靠:跨可用域、跨实例规格, 降低spot被集体释放的风险;自动托 管,分钟级巡检,动态保证集群的算 力。 3.快速交付:单次可在5分钟内交付 2000个实例。 4.多策略组合:可分别指定spot和按量 实例的交付策略,以及差额补足的策 略,包括成本最低、打散和折中。 解决问题 1.大规模计算集群成本高。 2.创建ECS实例方式单一,无法跨计费 方式、可用区及规格等核心参数。 3.当可用区资源紧张,无法自动保证基于 spot类型的稳定算力。 产品列表 专有网络VPC 云服务器ECS
文档版本:20200619 3 基于弹性供应组构建大数据集群分析 方案背景 方案背景 场景需求 随着大数据的兴起,越来越多的客户会尝试通过云服务器搭建自己的大数据分析平台,如 Hadoop、Spark等。但是用户通过种单例或批量创建 ECS,方式均缺乏灵活性,无法跨越计费方式、可用区及规格族等核心参数的限制,同时无法避免资源不足...
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。
可用区M 支持导入已保 有资源 IPv4网段 192.168.0.0/24 安全组:系统默认配置,自动创建 基于模版新建 名称:project-emr 可选服务:如果更换地域 付费类型:按量付费 OSS-HDFS、Hadoop-Common、或者可用区,业务场景:新版数据湖 Hive、Spark3、Tez、YARM 注意规格 元数据:DLF统一元数据 EMR 集群存储根路径:勾选:挂载...
云原生大数据计算服务MaxCompute
阿里云云原生大数据计算服务MaxCompute是面向分析的企业级云数仓,作为一体化大数据智能计算平台ODPS的大规模批量计算引擎,MaxCompute以 Serverless 架构提供快速、全托管的在线数据仓库服务,使您经济高效的分析处理海量数据,进行敏捷的业务洞察。
相反,如果完全基于开源的Hadoop框架,从服务部署、可视化开发、代码管理、任务调度、集群运维等多方面,均需要大量的人力来开发与维护。基于阿里云MaxCompute,不论是人力成本,还是计算成本,还是运维成本,都降到了最低.联合创始人 徐佳义.随着业务量的增长,在原有的自建集群上,出现了海量数据处理效率下降,离线数据...
来自:
云产品
大数据系统基准性能测试最佳实践
本方案适用于在阿里云上进行大数据基准性能测试的场景,包括 Teragen和Terasort测试,TestDFSIO测试。本文采用CADT工具结合阿里云的E-MapReduce服务快速构建测试集群,并提供了Teragen和Terasort测试,TestDFSIO测试的测试脚本,便于迅速开展测试。
EMR构建于云服务器 ECS上,基于开源的 Apache Hadoop和 Apache Spark,让您可以方便地使用 Hadoop和 Spark生态系统中的其他周边系统分析和 处理数据。EMR还可以与阿里云其他的云数据存储系统和数据库系统(例如,阿 里云 OSS和 RDS等)进行数据传输。EMR的 SmartData组件是 EMR Jindo引 擎的主要存储部分,为 EMR各个计算...
数据湖-在线学习场景数据分析

场景描述 本场景以在线教育中一个答题闯关类的应用为 例,使用WebServer来模拟演示这类日志数据 的分析处理。通过Nginx和Pythonflask搭建 WebServer,模拟应用中的关键页面,比如登 录、课程内容等,之后构造若干用户使用的模拟 日志数据,投递到数据湖进行分析后获取应用 PV、UV、课程内容访问排行、平均得分等等。 解决问题 基于数据湖(EMR+OSS)搭建大数据平台。 EMR和OSS使用和配置。 数据统一存储到OSS。 产品列表 E-MapReduce 对象存储OSS 云服务器ECS 访问控制RAM 专有网络VPC
借助EMR 可以简单快速的构建一个基于 Hadoop,Spark,Hive等大数据产品的计算集群,而且可以按需使用,其所有 Job完 文档版本:20200331 5数据湖-在线学习场景数据分析 数据湖 成之后,销毁集群,因为所有的数据都保存在OSS。此外,对于Hadoop集群上的任务,不同类型的任务对于机器配置的要求不同,比如 推荐和算法业务可能...
EMR集群安全认证和授权管理
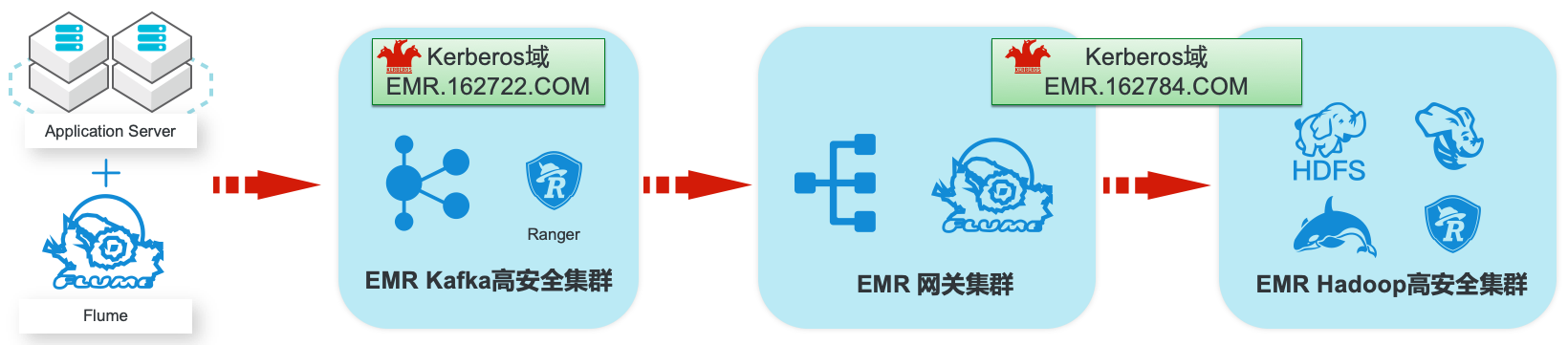
场景描述 阿里云EMR服务Kafka和Hadoop安全集群使 用Kerberos进行用户安全认证,通过Apache Ranger服务进行访问授权管理。本最佳实践中以 Apache Web服务器日志为例,演示基于Kafka 和Hadoop的生态组件构建日志大数据仓库,并 介绍在整个数据流程中,如何通过Kerberos和 Ranger进行认证和授权的相关配置。 解决问题 1.创建基于Kerberos的EMR Kafka和 Hadoop集群。 2.EMR服务的Kafka和Hadoop集群中 Kerberos相关配置和使用方法。 3.Ranger中添加Kafka、HDFS、Hive和 Hbase服务和访问策略。 4.Flume中和Kafka、HDFS相关的安全配 置。 产品列表:E-MapReduce、专有网络VPC、云服务器ECS、云数据库RDS版
本最佳实践方案中,相当于 Hadoop集群的 Kerberos域的 网关节点 Flume服务,访问 Kafka集群的 Kerberos域的 Kafka服务。步骤2 在两个 Kerberos域分别添加 Principal。Kafka安全集群 使用 root用户通过 SSH登录到 Kafka集群的 emr-header-1节点,进入 Kerberos 的 admin工具:sh/usr/lib/has-current/bin/hadmin-local.sh/...
- 产品推荐
- 这些文档可能帮助您