自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 业务架构 场景描述 客户在 IDC或者公有云环境自建 Hadoop集群 构建数据仓库和分析系统,购买阿里云 Databricks数据洞察集群之后,涉及到数仓数 据和元数据的迁移以及 Hive版本的订正更新。方案优势 1.全托管 Spark集群免运维,节省人力成 本。2.Databricks数据洞察...
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。
然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据 库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓 MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。相关命令可 以下载后浏览:gitclonehttps:/best-practice:Abcd123456@codeup.aliyun....
基于函数计算FC实现阿里云Kafka消息轻量级ETL处理
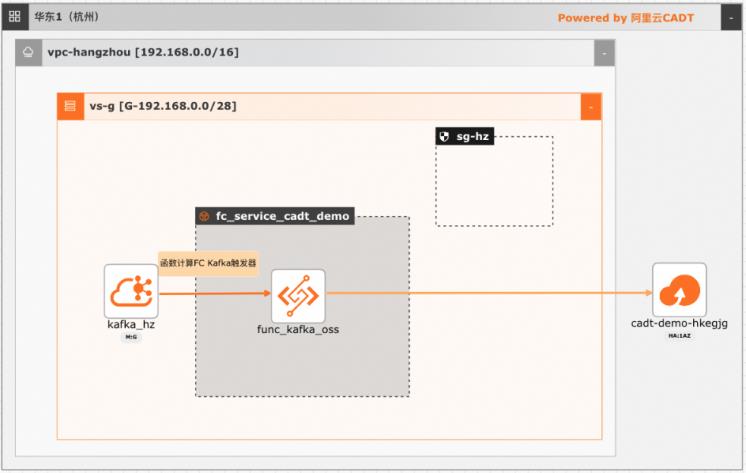
在大数据ETL场景,Kafka是数据的流转中心,Kafka中的数据一般是原始数据,可能存在多种数据混杂的情况,需要进一步做数据清洗后才能进行下一步的处理或者保存。利用函数计算FC,可以快速高效的搭建数据处理链路,用户只需要关注数据处理的逻辑,数据的触发,弹性伸缩,运维监控等阿里云函数计算都已经做了集成,函数计算FC也支持多种下游,OSS/数据库/消息队列/ES等都可以自定义的对接
利用函数计算 FC,可以快速高效的搭建数据处理链路,用户只需要关注数据处理的逻辑,数据的触发,弹性 伸缩,运维监控等阿里云函数计算都已经做了集成,函数计算 FC也支持多种下游,OSS/数据 库/消息队列/ES等都可以自定义的对接。方案优势 快速搭建起数据处理全链路 全链路自适应弹性,无需为流量峰谷做频繁的手工处理 ...
通过ES兼容接口方式使用Kibana访问SLS数据
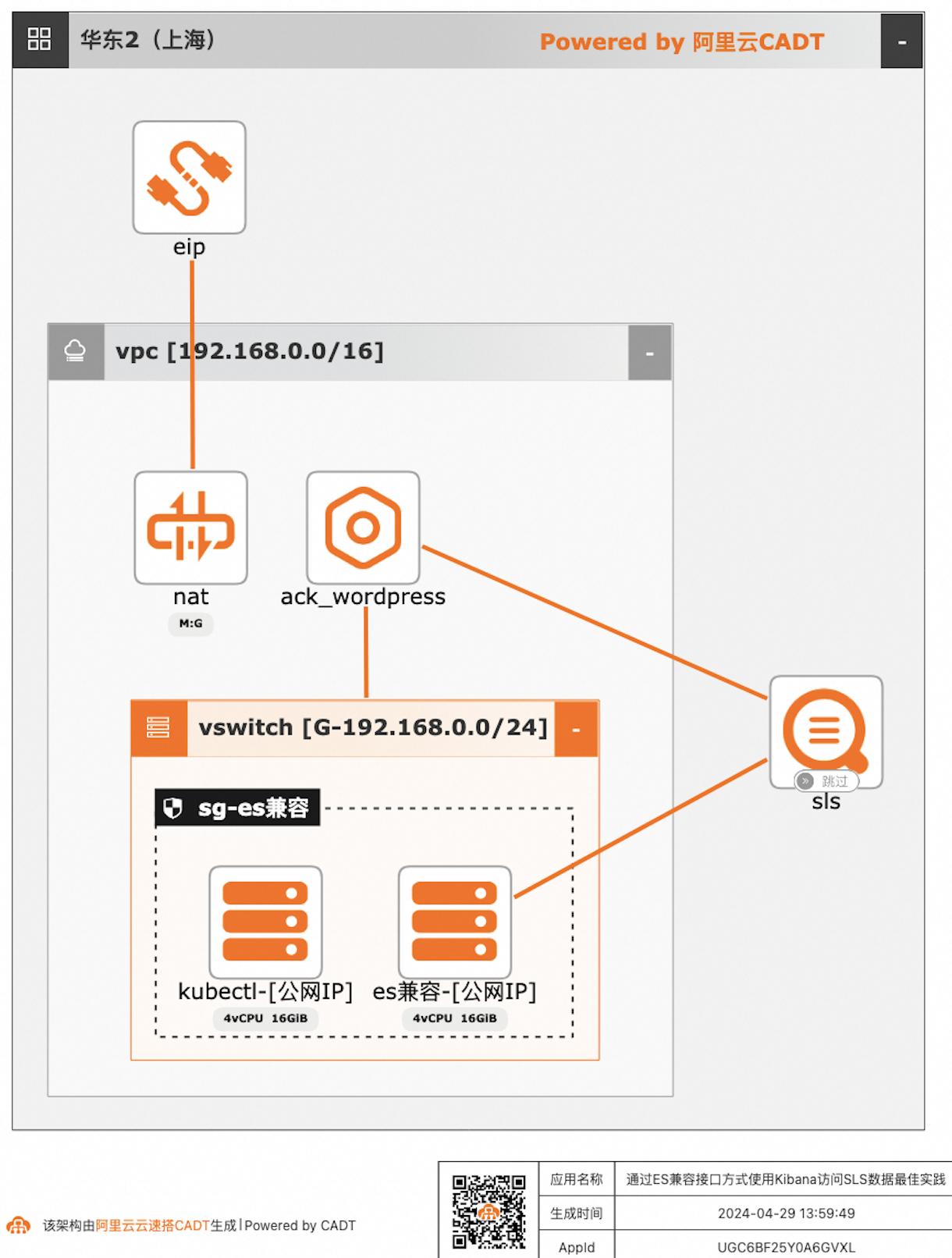
自建ELK日志系统的客户迁移到阿里云日志服务SLS后,对SLS查询分析语法不太熟悉的客户,可以继续沿用原有的查询分析习惯,在不改变使用方式习惯的情况下,通过Elasticsearch兼容接口的方式使用Kibana访问SLS。
产品列表 专有网络VPC 云服务器ECS 容器服务Kubernetes版 日志服务SLS 阿里云交换机 最佳实践频道 最佳实践分享群 SLS交流群 阿里云安全组 弹性公网IP NAT网关通过ES兼容接口方式使用 Kibana访问SLS数据 最佳实践 文档版本:20240418(发布日期)基于MSE云原生网关同城多活最佳实践 文档版本信息 ...
基于函数计算FC镜像部署Stable Diffusion大模型
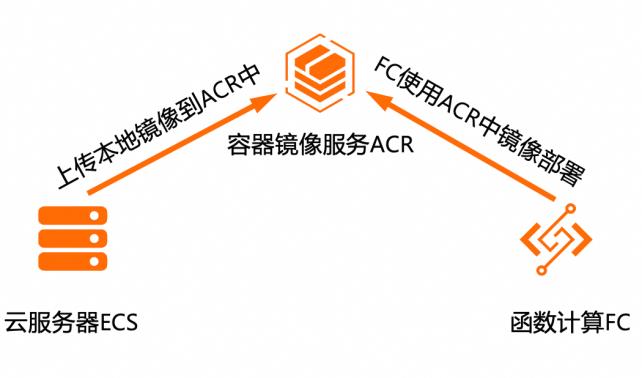
在现代AI应用中, Stable Diffusion等模型因其强大的功能而受到关注。然而,这些模型对计算资源的高需求和复杂的运维管理成为部署时的挑战。基于函数计算FC的无服务器计算模式为这类模型的部署提供了全新的解决方案。用户只需关注模型的部署和调用逻辑,而无需关心底层的服务器配置、资源分配和扩展性等问题。函数计算FC能够自动处理函数的执行环境,包括冷启动、弹性伸缩等,确保模型能够在大规模的请求下稳定运行。
FC镜像部署 SD大模型 场景验证 步骤3 用Docker tag命令为想要上传到 ACR的镜像打上新的标签 步骤4 在ECS上将输入下图对应的命令将本地镜像推送到 ACR 文档版本:20240426 6 基于函数计算 FC镜像部署 SD大模型 场景验证 在阿里云 ACR打开应用的镜像仓库,点击镜像版本,可以看到刚刚推送的版本,这 里镜像大小和本地不同是...
基于函数计算实现直播流录制-存储-通知
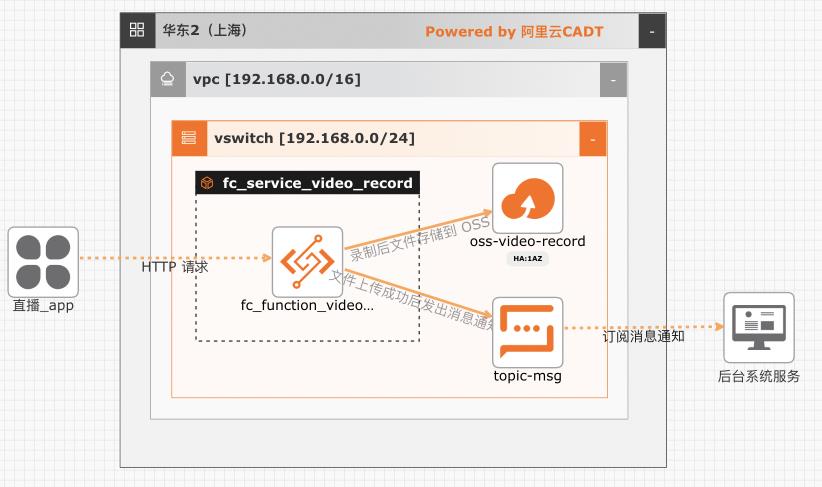
在互娱、教育、电商等行业都会有直播相关的业务,大部分场合都需要对直播相关的业务做安全审核,或者对直播的课程进行录制和转码。该方案实现了一种完全按需拉起、按量弹性、按实际使用付费的录制方案。基于本方案还可以扩展实现直播流截帧、自动化安全审核等能力
基于函数计算实现直播流录制-存储-通知最佳实践 业务架构 场景描述 基于阿里云函数计算实现对直播流的实时录制,录制结束后会把录制的结果写入 OSS 存储桶,并把录制的结果写到消息队列,下游服务可以通 过订阅的方式来消费消息 应用场景 在互娱、教育、电商等行业都会有直播相关的业 务,大部分场合都需要对直播相关的业务...
容器多云统一监控日志
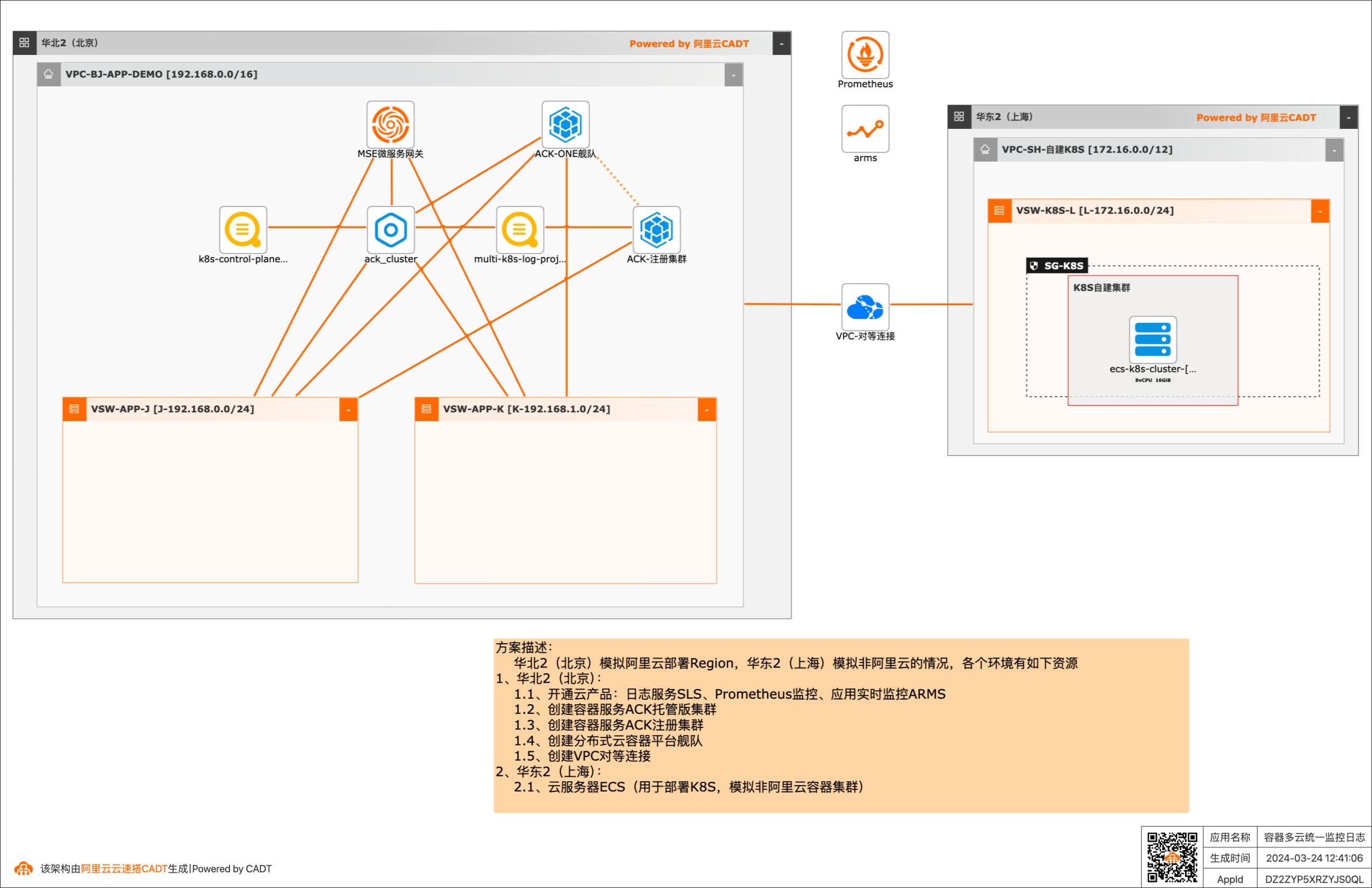
多云、混合云成为常态,Forrester 报告中指出,未来 89% 的企业至少使用两个云,74% 的企业至少使用三个甚至更多公有云,在面对多云/混合云这样大的趋势下,Gartner报告指出,安全、运维复杂性、财务复杂性是多云架构的主要挑战,本方案给出了在多云/混合云场景下,构建基于容器环境下的统一管理、统一监控和统一日志方案,解决多云、混合云场景下,运维复杂性问题。 应用场景 客户在阿里云以外的其他云服务商(AWS、Azure、GCP、TencentCloud、HuaweiCloud等)或者IDC基于容器(Kubernetes)运行业务系统,希望构建容器场景下的统一监控日志系统,方便做不同大屏和问题分析定位。 解决问题 •构建容器多云统一监控和日志系统,在一个平台可以看到不同环境系统的运行情况。
部署测试应用,收集查看阿里云和非阿里云应用监控和日志数据 3.测试验证完毕后一键进行销毁环境 部署架构 文档版本:20240322 1容器多云统一监控日志 最佳实践概述 架构说明 华北2(北京):模拟客户在阿里云北京Region部署业务 1.开通的云产品:日志服务SLS、应用实时监控ARMS、Prometheus监控 2.创建容器服务ACK托管版...
基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步
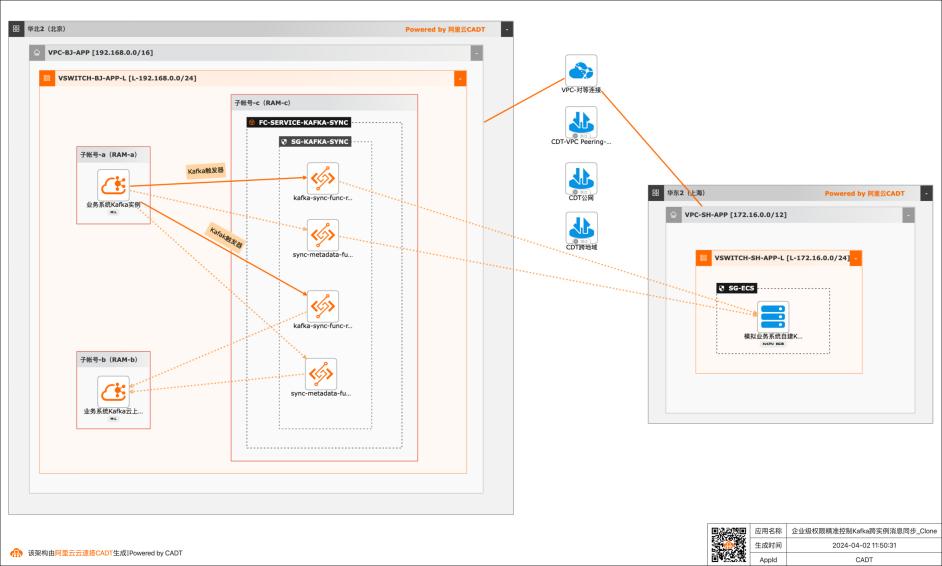
应用场景 在大数据场景,企业的Kafka实例可能存在多种情况,比如使用阿里云Kafka服务,可能是自建开源Kafka,或者是其他云上的云Kafka。不同的业务使用不同类型的Kafka实例,在这个前提下Kafka实例之间可能会需要消息同步的情况: 同帐号容灾场景:比如Kafka实例都是阿里云Kafka,但是Kafka实例会有主备之分,需要将主Kafka实例的消息实时同步到备Kafka。 跨帐号或异地容灾:这类场景比如主Kafka是阿里云Kafka,备Kafka是IDC开源自建Kafka,或者是其他云上的Kafka。 不同业务之间消息同步:因为现在的业务通常不会是信息孤岛,都需要消息互通,所以可能是A业务的Kafka实例消息需要同步到B业务的Kafka实例,并且这两个Kafka实例归属不同的RAM角色,有自己独自的权限控制。 解决问题 解决使用开源组件做消息同步的高成本问题。 解决使用开源组件做消息同步的并发性能、稳定性问题。 解决使用开源组件做消息同步的可靠性问题(重试机制,容错机制,死信队列等)。 大幅提升构建消息同步架构的效率,降低构建复杂度问题。
基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步最佳实践 场景描述 业务架构 基于阿里云函数计算FC实现同帐号阿里云Kafka实 例之间消息、元数据同步,跨帐号阿里云Kafka实例 之间消息、元数据同步,阿里云Kafka实例和IDC 自建Kafka(其他云Kafka)之间消息、元数据同步。应用场景 在大数据场景,企业的Kafka实例...
基于OSS Object FC实现非结构化文件实时处理最佳实践
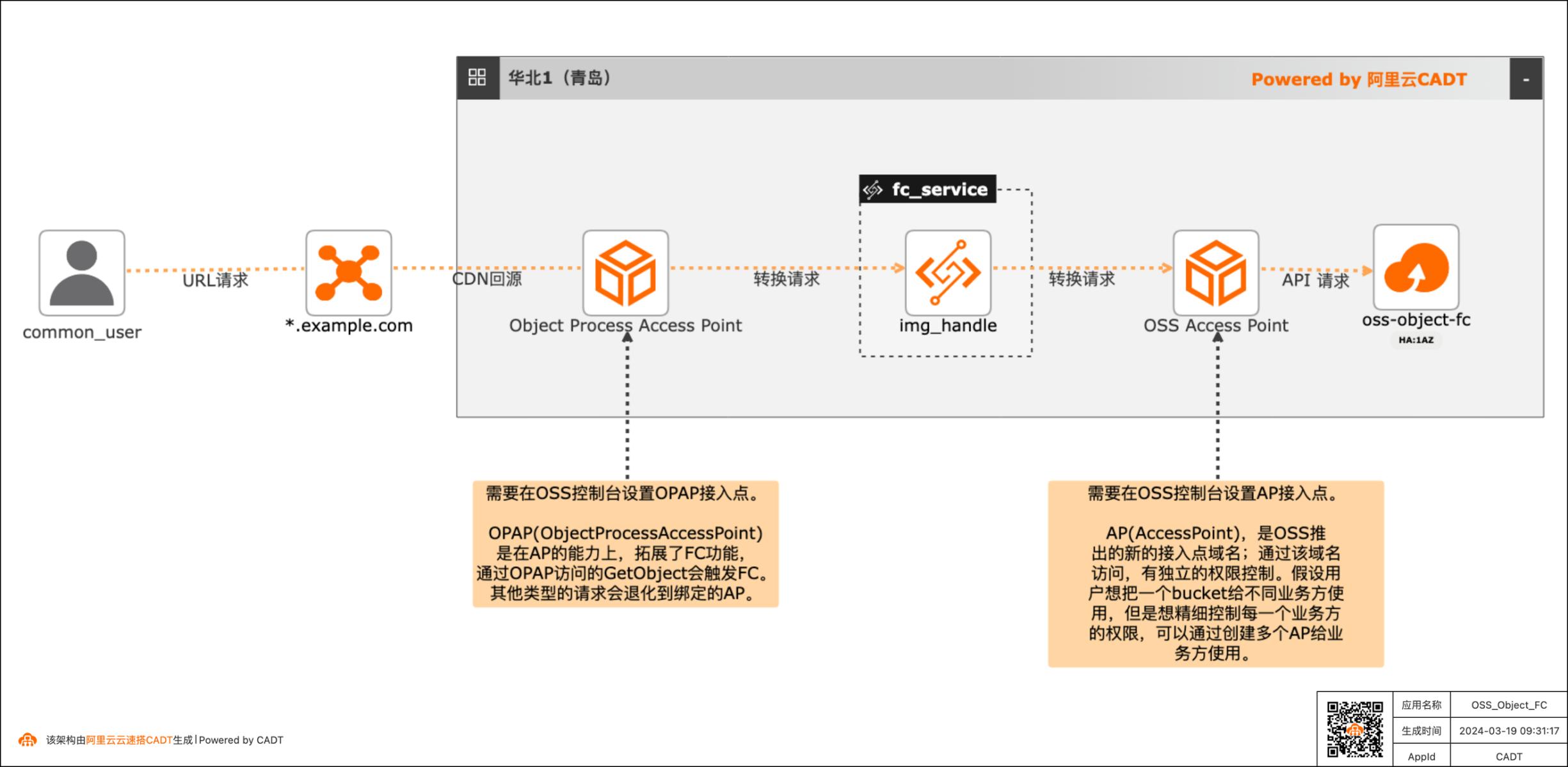
现在绝大多数客户都有很多非结构化的数据存在OSS中,以图片,视频,音频居多。举一个图片处理的场景,现在各种终端种类繁多,不同的终端对图片的格式、分辨率要求也不同,所以一张图片往往会有很多张衍生图,那如果所有的衍生图都存在OSS中,那存储的成本会增加,所以就可以通过OSS Object FC的方案,在不同的终端请求时,对OSS中的原图基于终端的要求做实时处理,然后响应返回,这样OSS中只需要存储原图即可。音视频也有类似的场景。
基于OSSObjectFC实现非结构化文件实时处理最佳实践 业务架构 场景描述 基于阿里云OSS和函数计算共同实现的产品化 集成解决方案OSSObjectFC,实现可以OSS 中的非结构化数据在读取时插入自定义业务逻 辑,对非结构化数据做实时处理后再返回。应用场景 现在绝大多数客户都有很多非结构化的数据存 在OSS中,以图片,视频,音频...
基于MSE云原生网关同城多活
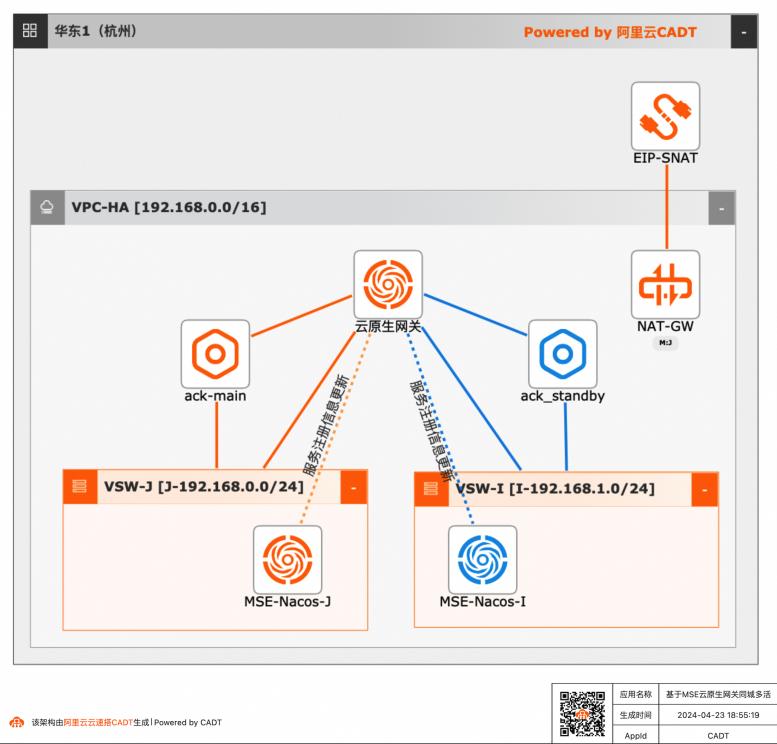
借助云原生微服务MSE网关,MSE配置注册中心的同城容灾多活微服务应用。构建一个经典的微服务场景,实现同城容灾的步骤,体现云原生相关产品在用户上云,高可用同城容灾多活场景下的能力。
文档版本:20240423 VI 基于MSE云原生网关同城多活最佳实践 最佳实践概述 产品介绍●专有网络 VPC(Virtual Private Cloud):是用户基于阿里云创建的自定义私有网络,不同的专有网络之间二层逻辑隔离,用户可以在自己创建的专有网络内创建和管理 云产品实例,比如 ECS、负载均衡、RDS等。容器服务 Kubernetes 版 ACK:容器...
阿里云最佳实践容器workshop

通过本篇最佳实践,可以熟悉容器及k8s的基本操作。基于eci的高弹性架构,能有效的应对业务流量洪峰,同时提升资源使用效率。
本例使用阿 里云提供的容器镜像服务。文档版本:20220301(发布日期)21 阿里云ACK容器服务workshop Docker实践 2.7.1.创建命名空间 步骤1 登录阿里云容器镜像服务控制台。(https://cr.console.aliyun.com/)步骤2 设置 Registry登录密码。文档版本:20220301(发布日期)22 阿里云ACK容器服务workshop Docker实践 步骤3 ...
自建Hive数仓迁移到阿里云EMR
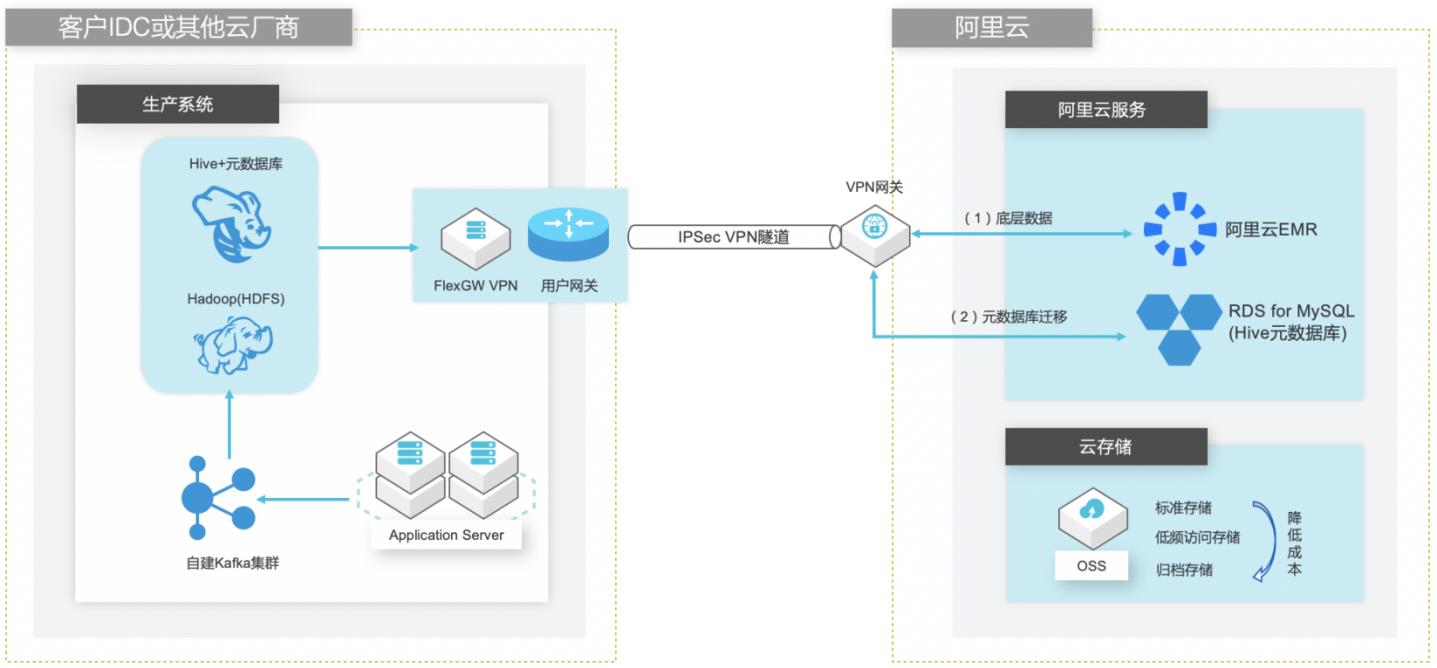
场景描述 客户在IDC或者公有云环境自建Hadoop集群构 建数据仓库和分析系统,购买阿里云EMR集群之 后,涉及到将数据仓库和Hive元数据的数据库迁 移上云。目前主流Hive数据仓库迁移场景为1.x 版本迁移到阿里云EMR(Hive2.x版本),涉及到 数据订正更新步骤。 解决的问题 Hive数据仓库的数据迁移方案 Hive元数据库的迁移方案 Hive跨版本迁移后的数据订正 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
自建 Hive数据仓库跨版本迁移到阿里云 EMR 场景描述 解决的问题 客户在IDC或者公有云环境自建Hadoop集群构建 Hive数据仓库的数据迁移方案 数据仓库和分析系统,购买阿里云 EMR集群之后,Hive元数据库的迁移方案 涉及到将数据仓库和Hive元数据的数据库迁移上 Hive跨版本迁移后的数据订正 云。目前主流 Hive数据仓库迁移场景...
大模型RAG对话系统部署
大模型RAG对话系统最佳实践,旨在指引AI开发人员如何有效地结合LLM大语言模型的推理能力和外部知识库检索增强技术,从而显著提升对话系统的性能,使其能更加灵活地返回用户查询的内容。适用于问答、摘要生成和其他依赖外部知识的自然语言处理任务。通过该实践,您可以掌握构建一个大模型RAG对话系统的完整开发链路。
兼容 Greenplum开源数 据仓库,MPP全并行架构,广泛兼容 PostgreSQL/Oracle的语法生态,新一代向 量引擎性能超越传统数据库引擎 10倍以上,分布式 SQL优化器实现复杂查询语 句免调优。实现了对海量数据的即席查询分析、ETL 处理及可视化探索,是各行 业有竞争力的云上数据仓库解决方案。Hologres是一站式实时数据仓库引擎,...
云原生数据仓库AnalyticDB PostgreSQL版
阿里云MPP架构的云原生数据仓库,可提供PB级海量数据在线/离线分析服务,是面向各行各业的有竞争力的数仓方案,真正做到“人人可用的数据分析服务”。
用户现有的OLTP数据库实例,包括 RDS MySQL,PostgreSQL,或传统数据库实例 Oracle,SQL Server等,数据可以通过 数据传输服务 DTS,数据集成服务 Dataworks 等实时同步到云原生数据仓库AnalyticDB PostgreSQL版,构筑可线性扩展的在线企业数据仓库服务。同时可以结合 Dataworks 的 ETL 调度功能,基于 AnalyticDB for ...
来自:
云产品
基于云速搭CADT快速构建药物筛选批量计算环境-serverless版
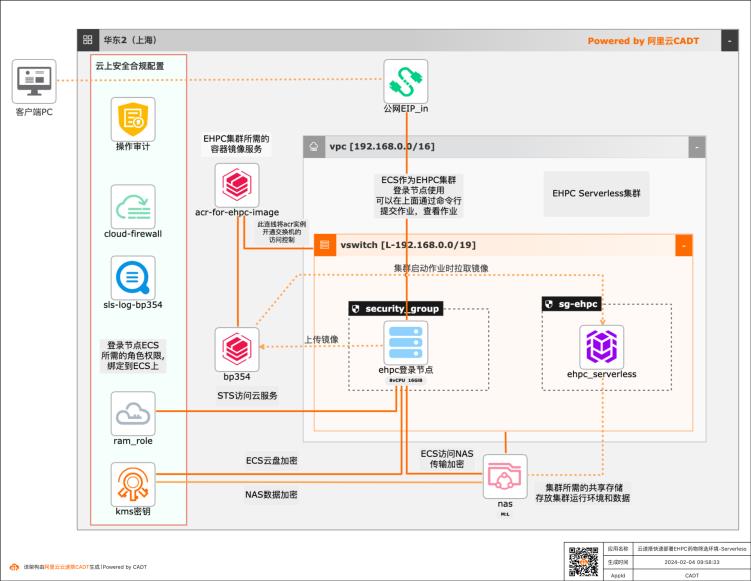
本方案基于云速搭 CADT提供一个快速构建云上Serverless版HPC批量计算环境的模板,针对生物制药领域的药物筛选场景,提供开箱即用的整套解决方案工具包,整个云上环境仅需1个小时即可完成自动化部署搭建。
产品列表 最佳实践频道 阿里云最佳实践分享群 弹性高性能计算 E-HPC Serverless版 文件存储 NAS 云速搭 CADT 容器镜像服务 ACR NAT网关 云服务器 ECS 钉钉扫描二维码或搜索钉群号 31852400入群 基于云速搭 CADT快速部署 药物筛选批量计算环境 Serverless版 文档版本:20240204(发布日期)基于云速搭 CADT部署药物筛选批量...
自建ElasticSearch迁移阿里云
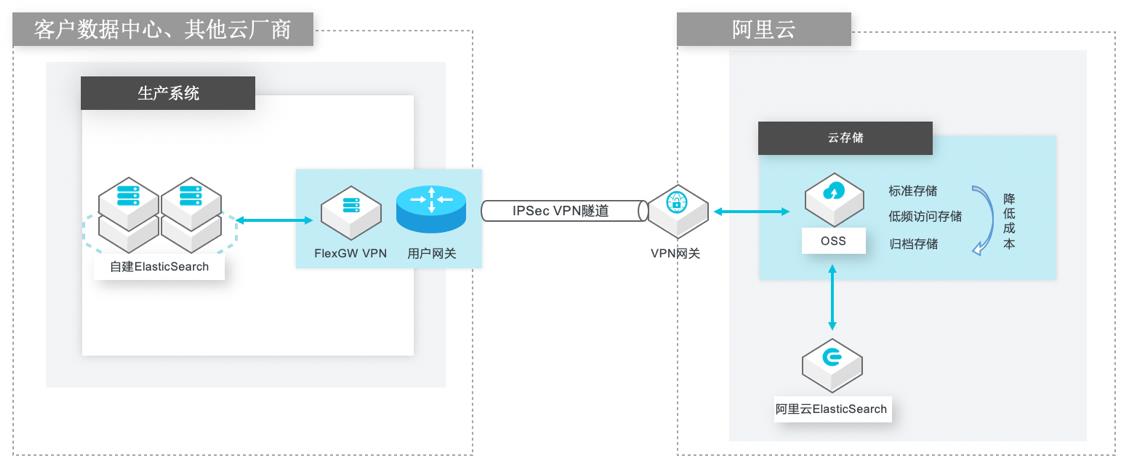
场景描述 以ElasticSearch为例,演示搭建模拟业务系统、 VPN网关和IPSecVPN隧道,介绍如何通过快照 的方式,将ElasticSearch索引数据安全备份到 阿里云OSS存储空间,以及介绍如何将备份在 OSS的快照仓库恢复到阿里云ElasticSearch实 例,进一步达到ElasticSearch迁移上云的目的。 解决的问题 自建ElasticSearch的云上/跨云备份需求。 自建ElasticSearch迁移到阿里云 ElasticSearch服务实例。 产品列表 VPC,ECS,VPN网关,OSS,阿里云ElasticSearch,云速搭CADT
最后介绍如果将备份在 OSS的快照仓 库恢复到阿里云 ElasticSearch实例 目标客户:IDC/公有云客户对自建 ELK日志系统有云上、跨云备份、迁移到阿里云 的 ElasticSearch的客户。技术架构 本实践基于如下图所示的技术架构和主要流程。方案优势 安全性 基于 IPSec VPN/专线的方式进行数据安全传输 低成本 可以在 OSS Bucket设置...
自建K8S迁移镜像、应用至阿里云ACK最佳实践

云原生技术K8S以其易管控,自动化操作,自修复等特点充分满足了企业的需求,越来越多的企业都加入容器化这个队伍中。但随着技术的更新迭代,自建的K8S相关的容器镜像服务、集群管理、稳定性保障也让企业IT人员感觉到压力,所以上云成了一些企业的选择,将底层的IAAS基础设施和K8S的基础PASS能力交给阿里云来管理,企业本身抽出更多精力聚焦业务的创新。针对以上需求通过使用image-syncer、velero来介绍如何平滑、便捷的迁移自建的K8S镜像和应用至阿里云容器镜像服务和ACK。 针对以上需求场景通过使用image-syncer、velero来介绍如何平滑、便捷的迁移自建的K8S镜像和应用至阿里云容器镜像服务和ACK;本文通过使用河源的ECS自建K8S集群和Harbor镜像仓库来模拟IDC环境
cp config.json registry-to-acr.json 注意点: 同步的最大单位是仓库(repo),不支持通过一条规则同步整个namespace以及registry 当源仓库字段中不包含 tag时,表示将该仓库所有 tag同步到目标仓库,此时目标仓库不能包含 tag 35 文档版本:20200525 自建 K8S迁移镜像、应用至阿里云 ACK 当源仓库字段中包含tag时...
- 产品推荐
- 这些文档可能帮助您