Spark on ECI大数据分析

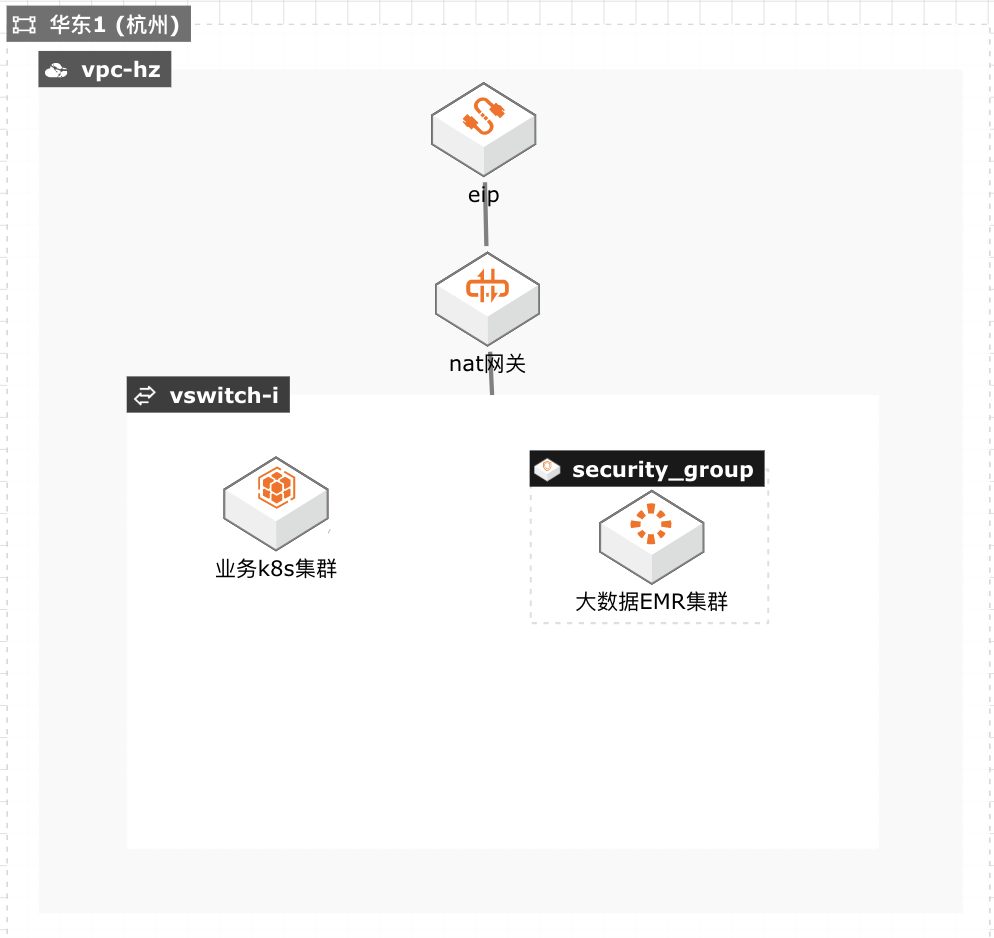
场景描述 方案优势 1.计算引擎弹性扩缩容,兼顾资源弹性与计 算资源成本优化。 2.计算与存储分离架构,结合阿里云原生云 存储产品,海量数据湖优势。 3.Kubernetes原生的调度性能优势,提升在 大规模分析作业时的分析性能优势分。 4.集群资源隔离和按需分配。 解决问题 1.计算资源弹性能力不足,计算资源成本管 控能力欠缺. 2.集群资源调度能力和隔离能力不足。 3.计算与存储无法分离,大数据量分析时出 现数据存储资源瓶颈。 4.Spark submit方式提交分析作业参数支持 有限等缺点。 产品列表 容器服务Kubernetes版(ACK) 弹性容器实例(ECI) 文件存储HDFS 对象存储OSS 专有网络VPC 容器镜像服务ACR
监控可以细化到每一次提交的作业,甚至可以到每个 driver以及 executor,在 ACK 控制台上都可以做到可视化的展现,用户如果有需要也还可以接入 Prometheus。日志能力强大,由于日志已经被 Kubernetes 自动收集,用户可以直接通过查看 Pod的日志就可以排查问题,而不需要像 on Yarn一样需要通过 Yarn的 Web页 面或者查看原始...
云上成本优化workshop
某金融科技公司,它主要提供信贷,理财,电商等 服务,目前已经拥有千万级注册用户。该公司在将 在线业务系统和大数据业务从自建 IDC 机房迁移 到阿里云后,今年大数据集群经历过多次因为资 源不足导致弹性扩容失败的故障,运维负责人非 常苦恼。由于该公司从事互联网金融的借贷业务, 白天的催收非常依赖晚上大数据计算的结果,若 因为资源不足导致计算结果失败则意味着白天催 收业务员无事可做,会对公司业务造成严重影响。 后来,通过阿里云解决方案架构师建议的方案,将 大数据集群迁移到资源较充足的可用区以及配置 弹性伸缩多规格 ECS 选型增加交付成功率等方 法,目前已阶段性的解决因资源不足导致弹性扩 容失败的问题,但该方案在 Spot 计算资源不足 时,启用大量按量收费算力,带来了较高的成本, 并且抢占式实例和按量付费实例都不保证资源 100%交付,还是存在交付失败的可能性,特别是 在双 11 期间由于其他客户的资源需求上升带来 的资源挤兑客观上存在,就进一步增加了弹性扩 容失败的风险,从而影响业务正常运行。
一站式提供数据采集、加工、分析、告警可视化与投递功能,全面提升研发、运维、运营和安全等场景数字化能力。详 见:https://www.aliyun.com/product/sls 抢占式实例 Spot:不是一种实例类型,而是一种付费方式,旨在为您降低部分场 景下使用 ECS实例的成本。如果使用得当,相对于按量付费实例,有较深的折扣 文档版本:...
来自:
最佳实践
相关产品:云服务器ECS,负载均衡 SLB,弹性公网IP,容器服务 ACK,日志服务(SLS),NAT网关,函数计算,E-MapReduce,云数据库PolarDB,弹性容器实例 ECI,存储容量单位包,预留实例券,Hologres
阿里云数据库快速搭建疫情分析系统最佳实践
疫情态势分析和防控任务迫在眉睫,如果快速搭建高效的疫情态势分析系统是众多部门和单位的难题,阿里云polardb for PG+Ganos解决方案可在极短时间内完成分析系统搭建,有效助力疫情防。 方案优势: 1、性能优越:Ganos作为自研的时空数据库引擎,相比postgis性能更优秀。 2、安全稳定:故障自动切换自愈,资源隔离,多副本存储。 3、简单易用:开箱即用,兼容postgresql,打通quickbi快速搭建数据分析展示。 4、功能强大:相比postgis在时空模型上做了较多扩充,支持几何模型,栅格模型,网络模型,时空轨迹模型,点云模型,拓扑网络模型。
更多信息,请参见:www.aliyun.com/product/ecs QuickBI:阿里云上客户都在用的 BI产品,无缝对接各类云上数据库和自建数据 库,大幅提升数据分析和报表开发效率,0代码鼠标拖拽式操作交互,让业务人员 也能轻松实现海量数据可视化分析。更多信息,请参见:www.aliyun.com/product/bigdata/bi Polardb:云原生关系型数据库 ...
基于SLS实现统一告警最佳实践
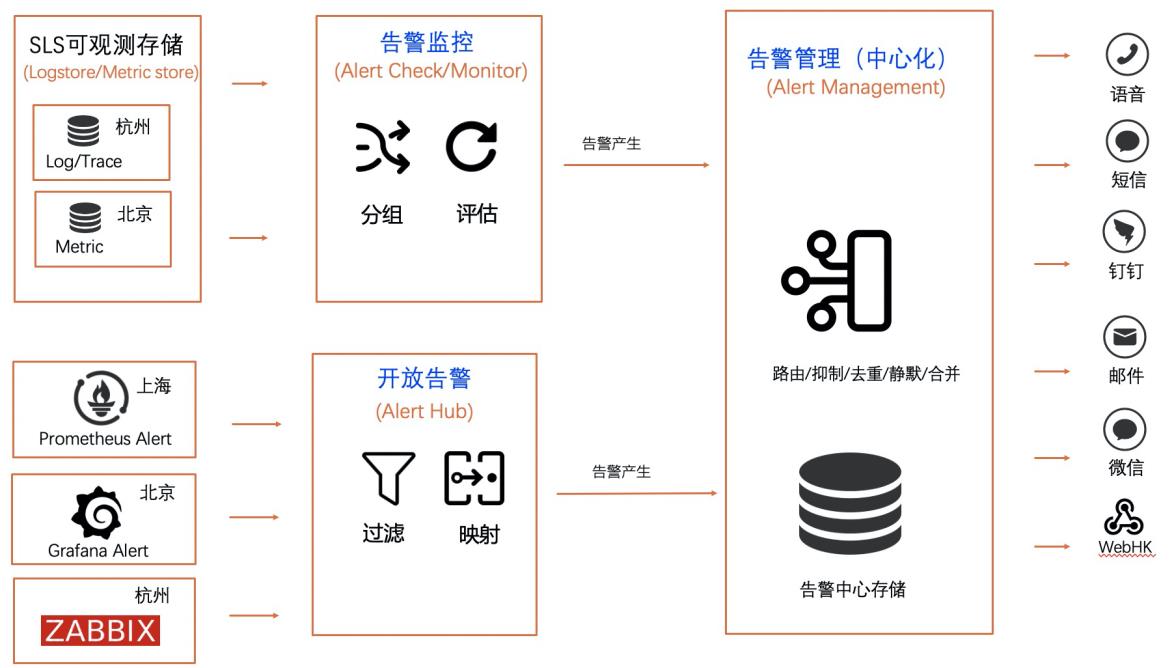
告警对于企业的开发运维,安全运维,业务运维有着至关重要的作用。然而很多企业在告警运维方面存在着重复建设、监控质量差、告警风暴、触达不人性化、无法闭环等问题。 针对企业在告警管理方面存在的痛点问题,SLS告警提供了一站式云上告警管理方案,具有弹性易用、稳定可靠、功能持续升级、成本更低、噪音更少等优势。企业可以将现有的监控方案系统无缝接入到SLS告警平台,实现在SLS上一站式管理告警。
一站式提供数据采集、加工、分析、告警可视 化与投递功能,全面提升研发、运维、运营和安全等场景数字化能力。详见:https://www.aliyun.com/product/sls OSS:阿里云对象存储 OSS(Object Storage Service)是一款海量、安全、低成 本、高可靠的云存储服务,提供 99.9999999999%(12个 9)的数据持久性,99.995%的数据可用性...
Salesforce Social Commerce
Salesforce Social Commerce(社交电商)一款专为中国市场打造的,由阿里云独家托管的商务产品。Salesforce 和阿里云携手提供工具,帮助企业在中国发展业务。
提供与Tableau的集成,使用Tableau可视化电子商务数据并调整您的业务,从而提高效率和转化率.托管在中国境内的阿里云上,有助于满足企业的合规性和数据本地化要求.API Requests(API 请求量).Annual Orders(年度订单量).API Requests per Additional SKU(标准产品订阅之外、可额外补充 购买的API请求量产品包).价格(含税)....
来自:
云产品
移动开发秘籍:云上高效构建App
使用移动研发平台EMAS和研发协同平台云效来提供一站式App的开发、测试、运维、运营等应用全生命周期的管理能力,提升开发效率,降低运维成本。
产品解决方案文档与社区权益中心定价云市场合作伙伴支持与服务了解阿里云备案控制台方案导读通过EMAS快速开发App方案介绍方案优势方案部署方案权益移动开发秘籍:云上高效构建App本方案使用移动研发平台EMAS和研发协同平台云效来提供一站式App的开发、测试、运维、运营等应用全生命周期的管理能力,提升开发效率,降低运维...
来自:
解决方案
移动开发平台 mPaaS
阿里云移动开发平台 mPaaS提供App开发、测试、运营及运维等云到端的一站式解决方案,帮助企业快速构建高质量的移动应用,阿里云快速开发平台提升企业产品生态发展。
查看详情阅读mPaaS文档,了解更多产品信息产品优势灵活高效降低开发难度,节约时间成本工程化的开发框架可以自动生成初始化代码,还提供模块化开发模式,可分可合,灵活机动。简化接入流程,能够让开发者搭积木似的快速搭建自己的 App。稳定可靠降低开发难度,节约时间成本组件都经历了支付宝高并发,大流量的检验,对弱网...
来自:
云产品
一站式快速开发多平台小程序
本方案使用阿里云多端低代码开发平台魔笔低代码快速搭建适配于多平台的小程序,帮助您提升开发效率、降低维护成本。
相关产品云服务器 ECS云数据库 RDS MySQL 版云解析 DNS云效多端低代码开发平台魔笔在线咨询方案优势开发效率高相比传统针对不同平台手动开发多套代码,魔笔的低代码可视化搭建,一次开发导出两套代码,提升了开发效率。维护成本低通过魔笔一套设计支持两个平台应用,一次修改全量更新,降低维护成本。部署效率高通过云效...
来自:
解决方案
基于SAE的一站式Web服务托管方案
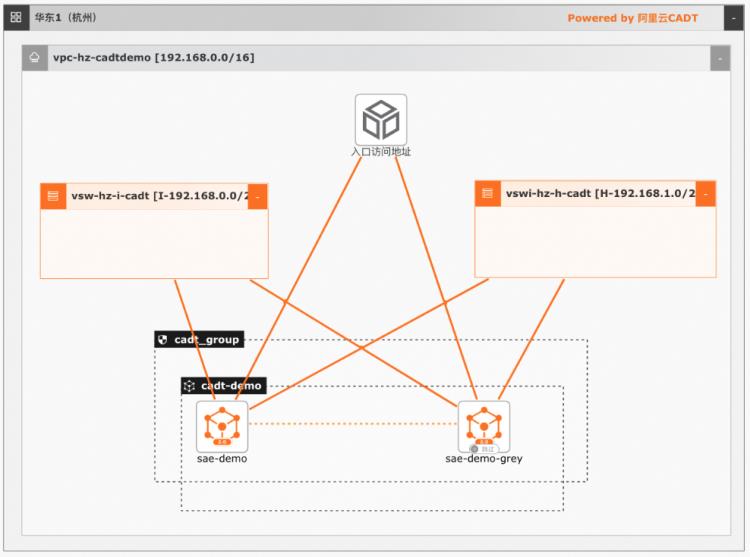
通过SAE提供的内置CICD能力,代码提交后可以触发自动构建,并部署应用到SAE,部署完成后,应用自动产生访问域名,外部请求通过域名可以直接访问应用。SAE提供了内置的可观测,灰度,回滚能力,通过控制台可以白屏化完成整个操作。SAE适合应用容器化快速上云,客户只需要提供代码仓库,后续的CICD,应用访问,弹性管理,运维监控,SAE都提供了内置的集成能力
基于SAE 2.0的一站式 Web服务托管方案 业务架构 场景描述 Web服务在互联网架构中有广泛的应用,通过 SAE提供的一站式方案,可以快速完成 CICD整 个流程,并且通过 SAE的内置能力,可以快速完 成灰度发布,应用观测,异常回滚等能力。应用场景 通过 SAE提供的内置 CICD能力,代码提交后可 以触发自动构建,并部署应用到 SAE...
基于FC实现的Web端视频录制最佳实践
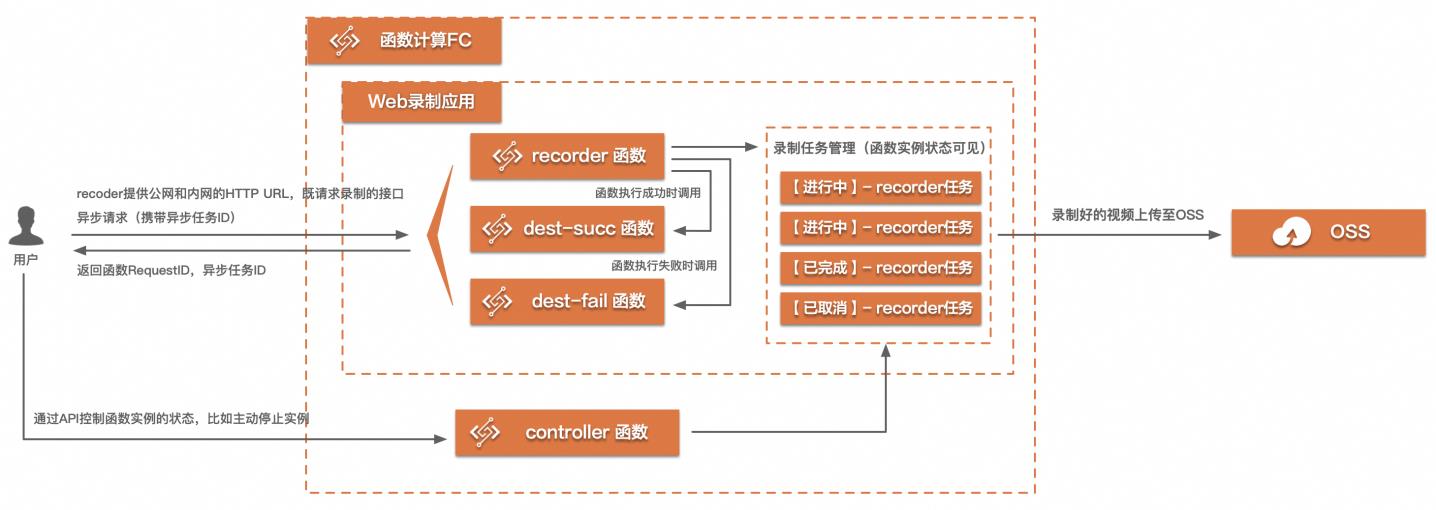
场景描述在很多互娱场景,在线教育领域会有直播视频录制的需求,但是往往一个页面上的内容是多种多样的,不止有直播流,可能还有白板,评论等其他元素,如果只是录直播流,那内容是不完整的,所以需要将整个屏幕的内容录制为视频。该最佳实践可以有效解决这个场景。
基于 FC实现的 Web端视频录制最佳实践 业务架构 场景描述 解决问题 在很多互娱场景,在线教育领域会有直播视频录制的 解决 Web端全屏录制复杂度高的问题。需求,但是往往一个页面上的内容是多种多样的,不 解决 Web端全屏录制灵活扩展性的问题。止有直播流,可能还有白板,评论等其他元素,如果 只是录直播流,那内容是不...
数据可视化DataV
数据可视化DataV是阿里云一款数据可视化应用搭建工具,旨让更多的人看到数据可视化的魅力,帮助非专业的工程师通过图形化的界面轻松搭建专业水准的可视化应用,满足您会议展览、业务监控、风险预警、地理信息分析等多种业务的展示需求。
孪生应用构建能力,利用自研云渲染引擎以及低代码开发工具链,为数字孪生应用提供稳定、高效的应用运行平台;城市联合仿真能力,利用云原生联合仿真调度平台,为城市提供车流、人流的联合仿真能力;DataV-孪生仿真.PolarDB PostgreSQL 版.数据资源平台.Ganos 时空数据库引擎.数字孪生城市.城市全要素实时管理.DataV在工业...
来自:
云产品
可观测可视化 Grafana 版
可观测可视化 Grafana 版作为云原生数据可视化平台,为运维SRE、研发工程师、产品经理、市场营销等不同角色提供开箱即用的一站式可视化平台,满足运维监控、经营分析、汇报展示等不同场景的查询、可视化、告警需求。
作为云原生数据可视化平台,可观测可视化 Grafana 版为运维SRE、研发工程师等不同角色提供一站式可视化平台,满足运维监控、经营分析、汇报展示等不同场景的数据查询、可视化、告警需求.Demo展示.可观测可视化 Grafana 版.更多产品与服务.ARMS应用监控-每月50GB免费额度,满足分布式应用监控与链路追踪需求.ARMS云拨测-每月...
来自:
云产品
PAI部署多形态的Stable Diffusion WebUI服务
为企业提供云上快速部署定制化的文生图应用。
具有分钟级部署上线,方便快捷、开箱即用,多版本部署方案,参数可定制化调整的优势。方案预估:体验本方案预计产生费用不超过15元。(假设您选择最低规格PAI-EAS资源,且资源运行时间不超过40分钟。如调整了资源规格,请以控制台显示的实际报价以及最终账单为准)方案部署一步步跟随方案教程,带你快速上手,进行方案部署...
来自:
解决方案
多端低代码开发平台魔笔
魔笔是面向全端(Web、H5、全平台小程序、App)场景,模型驱动的低代码开发平台,提供一站式的应用全生命周期管理,包括可视化开发、发布、运维;基于云原生架构的弹性扩展和低成本运维服务,帮助客户高效地解决应用研发、迭代、运维的问题。
通过可视化拖拉拽的方式进行主题配置、导航设置、页面布局、数据联动.可视化设计器-页面搭建.利用实体关系图(E-R图)进行数据建模,链接不同的数据实体和内存实体.可视化设计器-数据建模.通过可视化逻辑流设计器,设计前端逻辑流和后端逻辑流,完成复杂的逻辑操作.可视化设计器-逻辑流.通过可视化工作流设计器,设计审批流...
来自:
云产品
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
自定义 Sink Demo打包 步骤1 下载项目提供的 Demo,导入 IDEA(本例使用 IDEA作为开发工具,支持 JAVA的 IDE 都可)。文档版本:20201020 24 基于 Dataworks的大数据一站式开发及数据治理 日志实时 ETL写入HDFS 步骤2 使用 mvn clean install进行打包。步骤3 等待打包完成,下图所示即我们需要的 jar包。3.2.基于 dataworks...
高可用及共享存储Web服务
随着业务规模的增长,数据请求和并发访问量增大、静态文件高频变更,企业需要搭建一个高可用和共享存储的网站架构,以确保网站服务能够7*24小时运行的同时,可保障数据一致性和共享性,并降低数据重复存储的成本。
产品解决方案文档与社区权益中心定价云市场合作伙伴支持与服务了解阿里云备案控制台高可用及共享存储Web服务方案介绍方案优势应用场景方案部署方案权益高可用及共享存储Web服务随着业务规模的增长,数据请求和并发访问量增大、静态文件高频变更,企业需要搭建一个高可用和共享存储的网站架构,以确保网站服务能够7*24小时...
来自:
解决方案
- 产品推荐
- 这些文档可能帮助您